粒向量驅動的隨機森林分類算法研究
2024-03-03 11:21:30張錕濱陳玉明吳克壽侯賢宇
計算機工程與應用 2024年3期
關鍵詞:特征
張錕濱,陳玉明,吳克壽,侯賢宇
廈門理工學院 計算機與信息工程學院,福建 廈門 361024
1979年,美國科學家Zadeh首次提出并討論了模糊信息粒度化問題[1]。這一概念的提出,引發了不同領域的學者對信息粒化的探索與研究。1988年,Lin提出了鄰域系統并研究了其與關系數據庫的關系[2],1996 年,Lin 第一次提出了粒計算(granular computing)的概念,他給出了信息處理中一種新的概念與計算范式,并在數據挖掘領域進行應用實踐[3]。在Lin的研究基礎上,Yao定義了一種鄰域關系[4],進而提出了鄰域粒計算[5],并將其應用于數據挖掘等領域。2000年后,隨著粒計算熱度不斷提高,國內學者也加大了對粒計算的研究力度。苗奪謙等人對知識的粒計算進行研究,給出了屬性重要度啟發式的屬性最小約簡算法,及基于協調度的決策樹構造方法[6]。胡清華等人分析了鄰域的約簡,在文獻[7]中提出了一種基于鄰域關系的粒化方式,從而實現了實數空間中的粒計算,并在此基礎上設計了鄰域分類器[8-9]。Chen在文獻[10-12]中提出了基于單特征模糊粒化結合卷積的分類模型和基于信息粒的隨機模糊粒度決策樹算法,將模糊粒化與機器學習算法結合,進行聚類與分類,并分析了粒的不確定性和距離度量。從信息粒度的角度分析,不難發現聚類和分類有很大的相通之處:聚類是在一個統一的粒度下進行計算,而分類是在不同的粒度之下進行計算[13-14]。粒和粒化是符合人類認知特性的范式,在大數據、數據挖掘以及復雜數據建模中有著重要作用,并廣泛應用于諸多領域[15-17]。
隨機森林(random forest,RF)[18]是一種集成分類算法,其核心思想是通過建立多個決策樹來降低單個決策樹的過擬合風險。每個決策樹都是在不同的樣本和特征集上訓練,這種隨機性可以減少算法的方差,并提高模型的泛化能力。這些決策樹可以并行訓練。在隨機森林中,每個決策樹的輸出被視為一個投票。在分類問題中,隨機森林會將實例分配給獲得最多投票的類別,具有高穩定性、模型泛化能力強,易并行化等優點,并且由于其在分類任務上相比于其他算法具有更好的表現,因此廣泛應用于檢測系統[19]、推薦系統[20]、診斷系統[21]。隨機森林的起始性能往往比較差,特別是只有一個基學習器時,這是因為基學習器的訓練過程中加入了屬性擾動,導致基學習器的性能降低[22]。但是,隨著基學習器的個數增加,隨機森林產生的集成學習器的性能會得到很大的提升,即最終泛化誤差會收斂到最小。根據文獻[18],當樹的數目足夠大時,隨機森林的泛化誤差的上界收斂于下面的表達式:
其中,是樹之間的平均相關系數,s是度量樹型分類器強度的量。通過分析式(1)可知,隨機森林的過擬合風險可以通過Bagging 和特征隨機選擇來控制,但仍然存在一定的過擬合風險。相關性的存在使得隨機森林的泛化誤差略高于獨立決策樹的誤差。此外,決策樹和隨機森林本身也有一定的偏差,特別是在復雜模式或特定樣本分布的情況下。針對以上問題,本文在隨機森林分類算法中引入粒向量,提出了基于粒向量的隨機森林分類算法,該算法主要有以下優勢:
(1)高維特征表示:粒向量引入了高維特征表示,將數據點映射到一個更大的特征空間。這有助于捕捉更多的數據關系和模式,尤其在處理復雜的非線性關系時效果更好。
(2)參照樣本選擇的隨機性:隨機森林算法在每棵決策樹構建時隨機選擇特征,而粒向量每個維度都對應多個隨機選擇的參照樣本特征。這種隨機性有助于減少過擬合,增加模型的泛化能力。
(3)模型多樣性:隨機森林通過集成多棵決策樹來進行預測,每棵決策樹都是使用不同的數據子集和特征子集構建的。引入粒向量后,每棵決策樹的特征子集也是隨機選擇的。這樣可以增加模型的多樣性,減少模型的方差,提高模型的魯棒性。
在下文將首先詳細介紹粒向量的定義和算法,以及其在隨機森林中的應用。隨后,提出基于粒向量的隨機森林分類算法。最后,使用UCI數據集對基于粒向量的隨機森林分類算法與傳統隨機森林算法和其他方法進行性能對比,驗證粒向量算法的正確性和有效性,為隨機森林算法的優化探索了一個新方向。
1 相關工作
1.1 粒子與粒向量
傳統隨機森林算法的輸入對象為樣本,在粒計算理論中,輸入則為一個由粒子組成的粒向量。文獻[23]提出了粒的構造方法,可在列(屬性)上進行粒化;文獻[17]提出了在單特征上粒化為粒子,多特征上粒化構造粒向量的具體方法,并進一步給出了粒的結構、距離度量等定義。
設數據集為U=(X?P,C),其中X={x1,x2,…,xn}為訓練樣本集;P={p1,p2,…,pk}?X為隨機抽取的局部樣本作為粒化參照樣本;m維特征集合為C={c1,c2,…,cm} 。給定單樣本x∈X,對于單特征c∈C,v(x,c)∈[0,1]表示樣本x在特征c上歸一化后的值。則x與p在單特征c上的相似度為:
定義1給定數據集U=(X?P,C),對于任一樣本x∈X和參照樣本集P={p1,p2,…,pk},以及任一單特征c∈C,則x在參照樣本p中的特征c上進行粒化,形成的粒子定義為:
其中,rj=sc(x,pj)表示樣本x以pj為參考,在單特征c上的相似度。易知sc(x,pj)∈[0,1],因此rj∈[0,1]。粒子由粒核組成,gc(x)稱為粒子,則gc(x)j稱為第j個粒核。若?rj=1,則為1-粒子,簡寫為1;若?rj=0,則為0-粒子,簡寫為0。
定義2設為數據集U=(X?P,C),對于任一樣本x∈X,任一特征子集A?C,設A={a1,a2,…,am},則在特征子集A上的粒向量x定義為:
其中,gam(x)是樣本x在特征am上的粒子。為方便計,特征集A={a1,a2,…,am}用整數標記,則粒向量表示為GA(x)=(g1(x),g2(x),…,gm(x))T。
粒向量由粒子組成,粒子又由粒核構成。因此,粒向量可以是一個粒核矩陣的形式,表示為:
與原數據集相比,粒核矩陣的大小受參照樣本數量的影響:參照樣本越多,粒核矩陣越大;參照樣本越小,則粒核矩陣越小。粒向量也可以用另外一種形式表示為:
其中,g(x)j=(g1(x)j,g2(x)j,…,gm(x)j)T。粒向量由粒子組成,而粒子是一個集合的形式。因此,粒向量的元素是集合,與傳統向量不一樣,傳統向量的元素是一個實數。
1.2 粒的運算
上節主要闡述隨機抽取部分樣本作為參照樣本,然后對訓練集樣本在參照樣本中進行粒化后,構造出粒子與粒向量。這一小節定義粒的相關運算與距離度量,建立基于粒向量的隨機森林運算基礎.
定義3設粒子為,其大小定義為:
由粒子的定義可知rj∈[0,1],因此0 ≤| |
gc(x) ≤k。
定義4設為樣本x在特征a,b上的兩個粒子,則兩個粒子的加、減、乘、除運算定義為:
定義5設為樣本x,y在特征a上的兩個粒子,則兩個粒子的加、減、乘、除運算定義為:
兩個粒子的加減乘除運算結果為一個粒子。定義4是針對同一個樣本在不同特征集合上粒化后不同粒子的運算,而定義5則是應用在不同樣本在同一特征集合上粒化后粒子上的運算。
定義6設為兩個粒子,則粒子的歐氏距離度量為:
定義7設GC(x)=(g1(x),g2(x),…,gm(x))T,GC(y)=(g1(y),g2(y),…,gm(y))T為兩個粒向量,則粒向量的歐氏距離度量為:
其中,o(gi(x),gi(y))為粒子的歐氏距離。
1.3 粒范數
本節進一步定義粒范數。粒范數可用于衡量特征的重要性和稀疏性。通過引入粒范數作為正則化項,可以促使模型選擇具有較大權重的特征,同時抑制那些具有較小權重或冗余的特征。這有助于降低模型的復雜性,避免過擬合,并提高泛化能力。
定義8設為粒子,則粒子的范數定義為:
(1)粒子-1范數
(2)粒子-2范數
(3)粒子-p范數
(4)粒子-max范數
(5)粒子-min范數
定義9設m維粒向量為,則粒向量范粒子定義為:
(1)粒向量-1范粒子
(2)粒向量-2范粒子
(3)粒向量-p范粒子
粒向量的范粒子運算結果為粒子,提供了一條由粒向量轉化為粒子的途徑。
定義10設m維粒向量為,則粒向量的范數定義為:
(1)粒向量-11范數
(2)粒向量-12范數
(3)粒向量-21范數
(4)粒向量-22范數
粒向量的范數運算結果為實數,粒子的范數運算結果也為實數,這些運算提供了粒向量與粒子轉化為實數的途徑。
2 基于粒向量的隨機森林算法
基于粒向量的隨機森林分類算法是有監督分類算法,它結合粒計算理論以及隨機森林思想,將可并行的粒與集成學習融合,對多特征描述下的粒向量進行分類,以提高隨機森林的性能。為了設計基于粒向量的隨機森林分類算法,需先定義基于粒向量的隨機森林結構,闡述基于粒向量的隨機森林分類算法的原理。
2.1 基于粒向量的隨機森林原理
根據定義1 和定義2,數據集將以粒矩陣的形式輸入隨機森林。經相似度粒化的隨機森林算法隨機選出的粒向量和粒子,參照文獻[16]的思想構造粒決策樹。本文根據公式(2)進行相似度粒化,原數據通過粒化生成的粒向量以局部參照樣本進行粒化,可以通過局部信息構造相關系數較低的相似度粒核矩陣;在所有樣本上進行粒化,所以算法能夠把握全局信息進行決策,進而能夠有效提高算法的準確率。通過公式(1)分析傳統隨機森林存在的問題,本文提出的基于粒向量的隨機森林算法具有以下優勢:
(1)GvRF 可構造的決策樹數量是RF 算法中的|g(x) |倍,能快速提高基學習器數量,以提高隨機森林的收斂速度。
(2)由于參照樣本的選取具有隨機性,生成的粒矩陣能夠提供多個相關性較弱的分類器,能有效降低相關系數ρˉ。
(3)用于構建粒向量的參照樣本均來自原始數據,通過隨機選取可以更好擬合原始數據分布,以提高算法在復雜模式或不同分布的數據集中的性能。
2.2 基于粒向量的隨機森林模型結構
參考隨機森林的結構,基于粒向量的隨機森林模型分為五個部分:輸入層、粒化層、抽樣層、并行層、決策層、輸出層,其模型結構如圖1所示。

圖1 基于粒向量的隨機森林模型結構Fig.1 Granule vector based random forest model structure
首先,輸入信息空間IS=(U,F),其中樣本集為U={x1,x2,…,xn},屬性集為F={f1,f2,…,fm},對樣本集進行歸一化操作。GvRF模型的粒化層隨機選取參照樣本構成參照樣本集P={p1,p2,…,pk},并使用公式(2)在所有屬性下進行粒化,將原數據集粒化成為一個粒核矩陣GT={G(x1),G(x2),…,G(xn)},粒核矩陣的大小由參照樣本的多少決定。粒化過后的相似粒矩陣GT通過隨機抽取粒向量用于構造決策樹根節點的訓練數據,隨機抽取粒子進行節點的分裂。在并行層,粒核矩陣GT將被處理成多個新的粒核矩陣GTk},其中k為樣本的個數。每個粒核矩陣用于構造粒決策樹,構造好的粒決策樹可進行并行運算。最后通過預測層得出每棵樹決策的類別,形成決策集,最后通過投票在輸出層確定該樣本的輸出類別。
2.3 基于粒向量的隨機森林算法流程
2.2 節主要分層具體描述GvRF 算法模型結構。本節主要闡述基于粒向量的隨機森林算法流程。
算法1基于粒向量的隨機森林算法
根據算法1,GvRF 算法中N和k共同決定了隨機森林中基學習器的數量。與傳統隨機森林算法相同,基于粒向量的隨機森林算法的時間復雜度主要包括基學習器的訓練和預測階段。在訓練階段,需要構建多個決策樹。每個決策樹的構建時間復雜度通常為,其中m是屬性數量,n是樣本數量。粒具有可并行化的特性,對于基學習器的個數N和參照集大小k,算法采用并行化處理,總體時間復雜度約為。在預測階段,隨機森林中的每棵決策樹都需要遍歷,時間復雜度為。因此,GvRF 算法的總體時間復雜度約為。對于每棵決策樹,存儲的空間復雜度為O(m)。而基學習器的個數N和參照集大小k也會增加存儲開銷。因此,GvRF 算法的總體空間復雜度約為O(Nkm)。通過以上分析,GvRF 算法相比于傳統隨機森林算法而言,由于其粒的特性,在增加模型輸入信息的同時,沒有增加模型的時間復雜度,這也是將粒向量引入隨機森林算法的優勢之一。
傳統隨機森林算法中每個基學習器只使用部分樣本和特征進行訓練。這樣可以增加樣本和特征之間的差異性,減少模型對于訓練集的過擬合。通過集成多個基學習器的預測結果,可以降低方差并提高模型的穩定性和泛化能力。由于引入了參照集選擇的隨機性,GvRF 算法在傳統隨機森林算法的基礎上,進一步提供了多個高差異性的基學習器,這使得GvRF算法相比于傳統隨機森林算法具有快速收斂的性質,同時也進一步提高了模型的泛化能力。
分析算法1可知,相比于傳統隨機森林算法,GvRF算法需要額外指定參照集大小k,即算法所需的超參數有:基學習器的個數N和參照集大小k。它們共同決定了模型的學習器大小,以及算法時間與儲存開銷。參數的變化對算法的分類結果和運行性能有很大的影響,因此需要選擇合適的數值。通過實驗結果表明,綜合考慮分類效果以及算法成本,GvRF 算法中基學習器的個數N的合理取值范圍為0~50,參照集大小k的合理取值范圍為4~10。
3 實驗與分析
為驗證所設計基于粒向量的隨機森林算法(GvRF)的綜合有效性,本文采用了UCI中的多個高維小樣本數據集進行實驗,所有數據集的描述性信息如表1所示。

表1 實驗采用的UCI數據集Table 1 UCI dataset used in experiment
由于每個數據集中特征量綱不同,所以需要對每個數據集進行最大最小值歸一化處理,將每個特征數據變換到[0,1]的區間之中。歸一化公式如下:
預處理結束后,對預處理的數據進行相似度粒化,單特征上形成粒子,多特征上形成粒向量,GvRF算法的輸入即為多個粒向量組成的相似粒矩陣。本文使用GvRF算法與RF算法在UCI數據集上,將算法分類效果作為評價指標進行對比。本文還討論了兩個超參數:基學習器個數N,參照集大小k對提出算法的影響。
3.1 GvRF與RF對比實驗
對于表1 中的8 個UCI 數據集,實驗采用提出的基于粒向量的隨機森林算法(GvRF)和隨機森林算法(RF)進行分類效果的比較。對比實驗中包含準確率、召回率和F1 分數三種評估指標,每個指標的值都是均值(Mean)加上標準差(Std)。數據集首先通過公式(16)進行歸一化,輸入RF 算法的為歸一化后的數據,輸入GvRF 算法的數據則還需要經過公式(2)的粒化操作轉換成粒核矩陣。本次實驗的超參數設置如下:基學習器數量N設定為25,參照集大小k設定為5,其他條件均保持一致,所有實驗均采用十折交叉驗證。結果如表2所示。可以看出,在7 個數據集上,GvRF 方法在準確率、召回率和F1 分數三個評價指標上均優于RF 方法。具體來看,在準確率方面,GvRF 方法的提高范圍在0.56%到2.62%之間。在召回率方面,GvRF方法的提高范圍在1.92%到3.86%之間,平均提高2.80%。在F1 分數方面,GvRF 方法的提高范圍在1.54%到3.35%之間,平均提高2.34%。這表明GvRF 對比于RF 在提高模型分類性能的廣度和深度上都取得了較好效果。
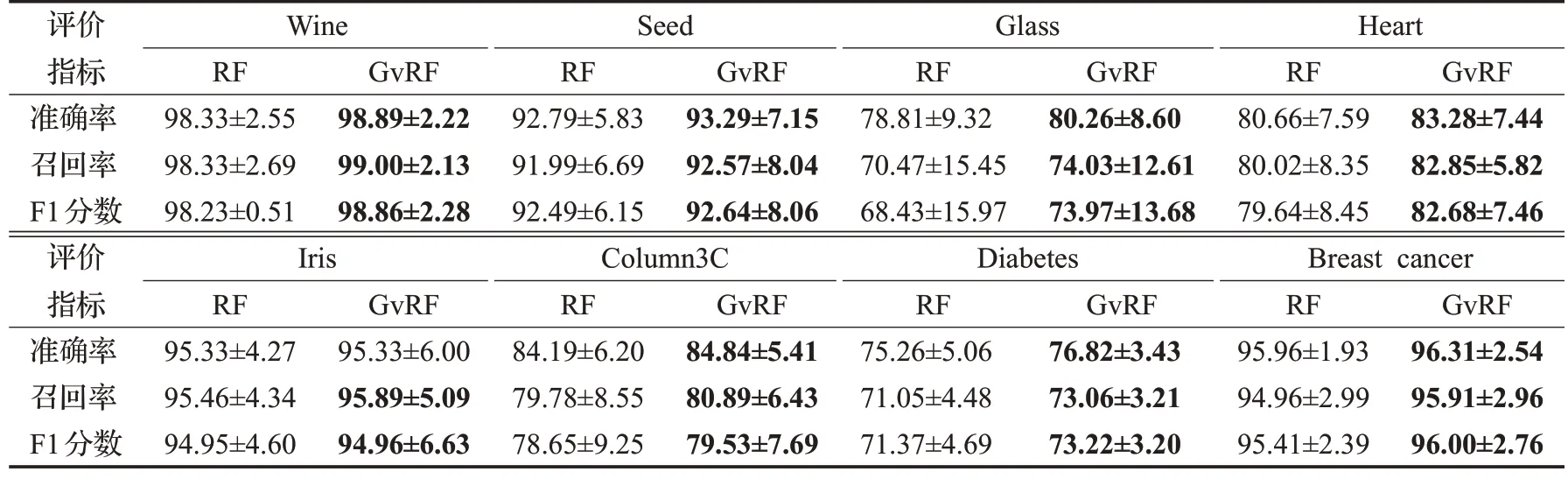
表2 GvRF與RF在不同數據集中的性能對比(Mean±Std)Table 2 Performance comparison of GvRF and RF across different datasets(Mean±Std) 單位:%
但是,GvRF 方法的提高幅度在不同數據集的評價指標之間也存在差異。例如,GvRF與RF的提高幅度在數據集Heart 與數據集Iris 上存在明顯差異。在數據集Heart 上,GvRF 方法的召回率提高2.87%,F1 分數提高3.04%,而在數據集Iris上,這兩個指標的提高幅度僅為0.43%和0.01%。這表明GvRF 方法在高維數據集上表現出更強的優勢,這主要是因為高維數據集可以結合相似度粒化方法提供更豐富的信息以供其進行決策。
綜上,表2結果顯示GvRF方法相比RF方法在高維小樣本數據分類性能上獲得了較為全面和穩定的提高。同時,也應注意到算法性能的提高在不同數據集和評價指標之間的差異,這需要在算法比較和選擇時綜合考慮其他因素包括參照樣本數量k、基學習器數量N以及對不同數據集采用不同的策略,以做出更加準確的決策。
3.2 參數的影響
對于GvRF 和RF 算法,不同基學習器的數量同樣影響算法的分類效果。本文提出的GvRF 算法主要由基學習器數量N和參照樣本數量k兩個超參數共同作用,本節通過實驗討論這兩個參數對GvRF算法的具體影響。
3.2.1 基學習器數量N
為探索不同大小的基學習器數量N對算法的影響,本小節在每個數據集上以不同的基學習器數量進行實驗。實驗以[2,100]為區間,2為步長確定基學習器數量N,參照樣本數量k為固定值5 進行,其余條件均保持不變,每組實驗均進行十折交叉驗證。圖2 為GvRF在不同數據集中不同基學習器數量N的實驗結果。

圖2 GvRF在不同基學習器數量N 的準確率Fig.2 Accuracy of GvRF with different N
根據圖2可知,在所有數據集的實驗中,GvRF對于RF 算法在不同基學習器數量下準確率均有一定的提升。從收斂速度看,由于GvRF算法采用相似度粒化使數據集以粒向量形式擴充基學習器,其收斂速度在各數據集上均優于RF 算法,尤其在Heart 數據集上較為明顯,Iris 數據集由于樣本數與特征數都相對較小,GvRF算法最開始就處于最優值,并在之后小幅震蕩。從收斂趨勢來看,除了Glass數據集仍然處于上升趨勢,其他數據集均趨于收斂。可以觀察到,多數情況下,GvRF算法收斂結果要高于傳統RF算法,但在基學習器數量N的值超過50 后,部分數據集上的指標也出現了小幅下降的趨勢,但總體指標仍然高于RF。這說明基學習器數量N的變化并沒有明顯影響GvRF算法對于RF算法的性能提升。
3.2.2 參照樣本數量k
在不同參照樣本數量的實驗中,將基學習器數量N設定為固定值25,參照樣本數量設定在[1,20]區間內,步長為1,其他條件均保持不變,每個實驗均進行十折交叉驗證,結果如圖3所示。

圖3 GvRF在不同參照樣本數量k 的準確率Fig.3 Accuracy of GvRF with different k
對圖3 分析可知,在所有數據集上,GvRF 相對于RF 在準確率指標上均有出不同程度的提升,其中在Glass 和Heart 數據集上提升幅度尤為明顯,在Iris 和Diabetes 上提升幅度較小,且不同數量的參照樣本對同一數據的決策準確率有著較大幅度的影響。從趨勢上分析,隨著參照樣本個數的不斷提升,GvRF算法性能在初期(k∈[4,10])可以快速提升,在出現峰值數據后,部分數據集例如Seed 和Diabetes 數據集的準確率趨于穩定,在其他數據集上的準確率呈下降趨勢。
結合圖2 和圖3 實驗內容可以看出,基學習器數量N和參照樣本數量k兩個超參數共同決定了GvRF 算法的分類精度,并且由于參照樣本的選擇具有隨機性,參數k對提出的算法具有更大的影響。根據泛化誤差公式(5),本文提出的GvRF算法的優勢在于:可以隨機選擇參照樣本并通過相似度粒化的方式快速構造出多個相關系數較低的基學習器,在減少了泛化誤差的同時提高了其收斂速度。值得注意的是,當N和k的值相對偏大時,GvRF的性能出現下降的趨勢,這個現象在變化參數樣本數量k時尤為明顯。綜合以上分析,本文提出的GvRF 算法在所實驗的數據集中均有不同程度的提升,主要受到基學習器數量N和參照樣本數量k兩個超參數的影響。其中對于高維小樣本數據的提升幅度更大,這充分說明了GvRF 算法的正確性和有效性。考慮算法效率等因素,推薦在高維小樣本數據集中,參數k的值選擇較小的參數,例如[4,10]。參數N的值則由于其收斂后具有較穩定的分類表現,可以根據不同數據集進行范圍較大的自由選擇。
3.3 GvRF與其他方法對比實驗
本節主要對比了提出的基于粒向量的隨機森林分類算法和以下對比算法:
(1)傳統隨機森林(random forest):建立多個決策樹來降低單個決策樹的過擬合風險。每個決策樹都是在不同的樣本和特征集上訓練。
(2)極限隨機樹[24(]extra-trees):極限隨機樹是一種對傳統隨機森林的改進,其在構建決策樹時,會隨機選擇特征和切分點,而不是使用最優的選擇。不同樣本實驗中統一設置特征采樣數為總特征數的平方根個特征。
(3)旋轉森林[25(]rotation forest):旋轉森林是一種利用特征旋轉增加模型多樣性的方法,每棵樹都在經過特征旋轉變換后的特征空間上構建,旋轉變換通過主成分分析(PCA)等方法實現。不同樣本實驗中統一設置旋轉次數為3,隨機旋轉的角度范圍。
(4)XGBoost[26](extreme gradient boosting):XGBoost是一種基于梯度提升樹的集成學習算法,在梯度提升樹的基礎上引入了正則化項,通過控制模型的復雜度來防止過擬合。不同樣本實驗中統一設置學習率為0.1,采用L2正則化。
本次實驗中,GvRF 將基學習器數量設置為25,參照樣本數量設置為4。除了不同算法特有的超參數,決策樹部分超參數統一設置如下:基學習器數量為25,最小分割樣本數為2,最小葉子節點樣本數為1,樹的最大深度為3,分裂標準為基尼系數(gini) 。表3 比較了GvRF算法和其他4種算法:RF、ET(文獻[24]方法)、RoF(文獻[25]方法)、XGBoost(文獻[26]方法)在8個不同數據集上的分類準確率。

表3 GvRF與其他算法在不同數據集上的對比分類準確率Table 3 Accuracy comparison of GvRF and other algorithms on different datasets 單位:%
從表3 數據可知,GvRF 算法在大多數數據集上表現較好,特別是在Wine、Glass、Column3C數據集上的準確率最高,分別為98.89%、77.46%、84.19%。在Seed 和Diabetes 數據集上,GvRF 算法的準確率與XGBoost 相等。在Heart數據集上,XGBoost略優于GvRF。另一方面,綜合數據集數據,可以看出GvRF 算法在小樣本數據集(如Iris)和大樣本數據集(如Diabetes)上表現都比較好,同時也能處理特征數相對較多的問題(如Breast cancer),這表明GvRF 算法具有較強的泛化能力,對樣本量和特征數量較不敏感,能夠較好地擴展到不同規模和結構的數據集。與XGBoost 相比,GvRF 處理小樣本數據集的能力更強,XGBoost則在高維特征數據集上表現較好,因此GvRF更適合樣本量不足的場景。綜合來看,GvRF算法相比其他算法有更好的泛化能力,能夠在不同類型的數據集上都獲得較高的分類準確率。
為了進一步驗證GvRF 算法的泛化性能,分別以Heart和Breast cancer兩個數據集為例,比較了GvRF與其他算法在不同基學習器數量N下的分類準確率,如圖4展示。結果表明:在Heart數據集中,當基學習器數量較小時,各算法的分類準確率較低,都在0.80~0.82,但GvRF略高于其他算法。隨著N的增加,所有算法的準確率均有提升。當N達到100時,GvRF算法的準確率為0.85,高于XGBoost與其他算法。這表明隨著基學習器數量的增加,GvRF 算法的優勢逐漸增加。在Breast cancer 數據集中,各算法的分類準確率維持在0.94~0.96的較高水平,GvRF僅比RF略高0.52個百分點。隨著N的增加,GvRF的準確率穩步提升,在N=100 時GvRF 的準確率高于傳統隨機森林與旋轉森林,低于XGBoost算法。這也說明在此類數據集中,基學習器數量的增加對GvRF 準確率提升具有一定的幫助。值得注意的是,提升GvRF的基學習器數量在提高準確率的同時也相應增加了算法開銷,在具體應用時需要針對不同數據集進行參數尋優。綜上,增加基學習器數量N,可以一定程度上提升GvRF算法的分類準確率,在較小基學習器數量時,快速增加模型的收斂速度,但在某些數據集中其收斂速度明顯小于XGBoost等算法。

圖4 不同基學習器數量下的性能對比Fig.4 Performance comparison of different N
4 結束語
本文通過分析隨機森林算法,結合相似度粒化理論,在單特征上構造粒子,在多特征上由粒子形成粒向量,定義粒子與粒向量的大小、距離和運算方法。將相似度粒化技術引入隨機森林算法中,設計基于粒向量的隨機森林算法。由于粒子具有多角度、可并行的特點,通過隨機選取參照樣本構造多個相關系數較低的基學習器,可以提高隨機森林算法的性能。最后在多個不同類型數據集上進行實驗,充分驗證了文章所提出算法的正確性與有效性。未來階段將重點針對以下幾個問題展開研究:
(1)現階段粒化理論存在一定的隨機性,下一階段將深入研究更具魯棒性的粒化算法,構建包含更豐富的約束條件和先驗知識的算法框架,采用非監督學習等方法,增強算法的泛化能力和魯棒性。
(2)現階段粒化理論計算成本相對較高,下一步將采用分布式計算等方法降低算法的計算復雜度,探索更合適的數據結構和搜索策略來優化算法的時間和空間復雜度。
(3)未來需要進一步提升提出的算法對基學習器的適應性,以拓寬其應用場景。后續研究將繼續深入研究,提出算法的理論框架,豐富算法的理論基礎。同時在更廣泛的數據集和應用場景上驗證算法效果,發現算法的潛在問題,不斷改進算法,提高算法的精度、泛化能力,豐富算法的功能。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
