圖卷積神經網絡及其在圖像識別領域的應用綜述
2023-11-27 05:34:40李文靜楊瞻源
計算機工程與應用 2023年22期
李文靜,白 靜,2,彭 斌,楊瞻源
1.北方民族大學 計算機科學與工程學院,銀川750021
2.國家民委圖形圖像智能處理實驗室,銀川750021
近年來,卷積神經網絡(convolutional neural network,CNN)[1-2]作為深度學習的重要算法之一,具有良好的特征提取和泛化能力,在圖像識別、分割等計算機視覺任務中不斷取得突破。然而,如圖1(a)所示,CNN依賴于卷積核的平移不變性提取輸入圖像的特征,只能處理歐式空間中的規則數據。但圖像識別等領域的實際應用場景中存在大量非結構化數據。在此背景下,學者們提出了如圖1(b)所示的圖卷積神經網絡(graph convolutional network,GCN),利用圖的節點和邊表征復雜的非結構化數據,利用圖卷積提取各個子圖的局部結構信息,并通過子圖間的共享節點完成數據傳播,最后利用圖聚合運算提取全局結構特征,實現了深度學習方法與數據傳播思想的結合,把卷積等操作擴展到了圖等非結構數據的處理中。
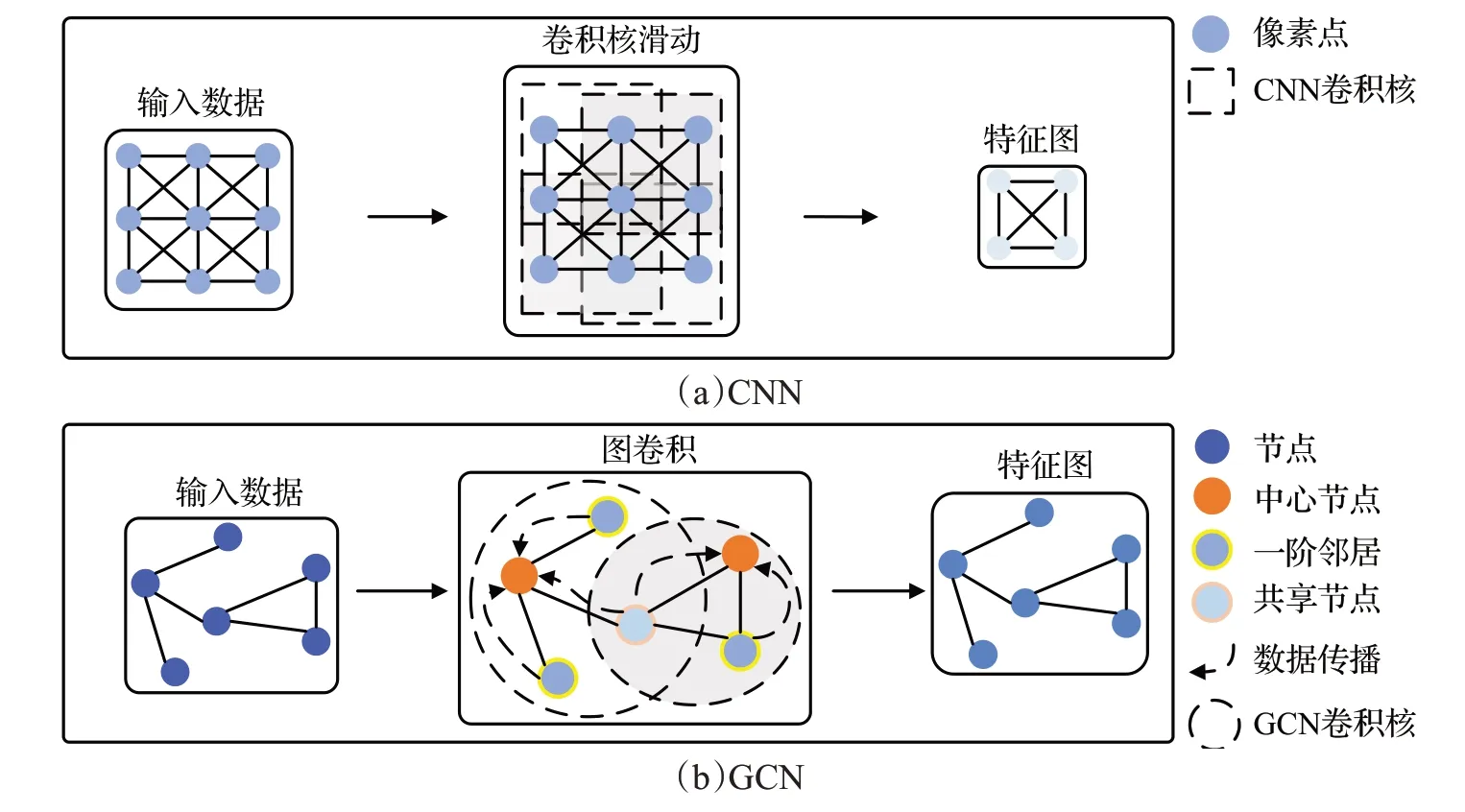
圖1 CNN與GCN結構Fig.1 CNN and GCN structure
隨著GCN 在非結構化數據處理中不斷取得突破,其受到越來越多關注,并涌現出大量算法,這為解決圖像識別任務提供了新的思路和方案。例如,Chen等人[3]將GCN應用于多標簽圖像識別,提出了ML-GCN,在該領域公開且常用的兩個數據集上性能取得顯著提升,其mAP較之前最優的CNN分別提高了5.7個百分點和1.2個百分點;Yan 等人[4]將GCN 應用于動作識別,提出的ST-GCN(spatial-temporal graph convolutional network)與CNN 相比,在動作識別領域的公開數據集上獲得了彼時最先進的性能;Qin 等人[5]將GCN 應用于高光譜圖像分類,提出的S2GCNs(spectral-spatial graph convolutional networks)在該領域的兩個公開數據集上獲得了優秀的識別精度。總體而言,GCN 已被成功應用于圖像識別領域的多項復雜子任務中,并取得突破性進展。
相應的,從2019 年到2022 年,先后出現了多篇GCN 的綜述論文[6-10],推動了相關領域的發展。其中一類綜述[6-8]圍繞GCN 的發展、應用和未來趨勢進行總結與探討,另一類綜述[9-10]聚焦于GCN 在計算機視覺領域的整體應用與發展,較為寬泛。然而最近幾年,針對圖像識別這一子領域,每年都會涌現出很多優秀的工作,它們針對不同任務做出不同改進,具備不同特點,極大地推進了圖像識別以及GCN本身的發展。現有的面向計算機視覺領域的GCN 綜述覆蓋范圍廣,難以對圖像識別GCN的相關工作給出全面而深入的總結分析。為此,本文圍繞這一主題,在充分介紹GCN最新發展的前提下,重點闡明GCN在圖像識別子領域的應用及趨勢,為相關學者提供有益參考。
本文的組織結構如圖2所示,在GCN的基本研究現狀下,將本文分為基礎研究和應用研究兩部分。其中,在基礎研究中,根據網絡原理的不同,將GCN分為基于譜域的GCN和基于空域的GCN;在應用研究中,以多標簽圖像識別、基于骨架的動作識別和高光譜圖像分類任務為代表,重點介紹GCN在圖像識別領域的應用。
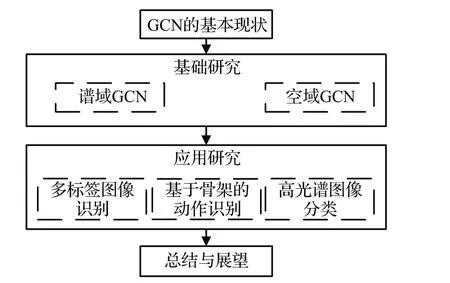
圖2 組織結構Fig.2 Organizational structure
1 基于譜域的GCN
1.1 基本原理
基于譜域的GCN旨在將非結構化的節點域數據轉換至結構化的譜域,從而進行深度學習以實現對非結構化數據的表征學習。具體的,如圖3 所示,基于譜域的GCN 包含三個關鍵步驟:首先借助傅里葉變換將節點域數據變換為譜域數據;然后在譜域通過卷積操作完成信息提取;最后利用傅里葉逆變換將譜域數據轉換回節點域數據,解決了節點域數據平移不變性的缺失導致卷積無法實現的問題。
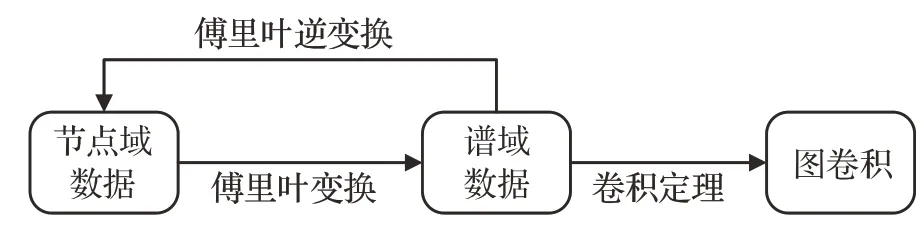
圖3 譜域GCN基本原理Fig.3 Basic principle of spectral GCN
(1)傅里葉變換與逆變換
輸入節點域數據f,其傅里葉變換為:
其中,是f變換到譜域后的信號;是n個相互正交的特征向量組成的向量矩陣,特征向量ui由圖的拉普拉斯矩陣分解得到;UT是U的轉置。
相應的,譜域信號在圖上的逆傅里葉變換為:
(2)圖卷積
根據卷積定理[11],卷積的傅里葉變換等于傅里葉變換的乘積,因而對節點域信號f作用卷積h的傅里葉變換可表征為:
其中,*為卷積,⊙為哈達瑪乘積。
基于式(1),可進一步推導得到節點域信號f的卷積:
進一步的,將UTh看作以θ為參數的卷積核hθ,則圖卷積公式可擴展為:
1.2 譜域GCN的基礎模型結構及改進
2013 年,Bruna 等人[12]針對手寫體數字識別任務提出了首個譜域圖卷積神經網絡Spectral CNN,在分類誤差降低為1.8%的情況下,參數量減少到5×103,為譜域GCN的研究奠定了基礎。研究學者們在此基礎上提出眾多的改進工作,并在非結構化數據的處理中取得了良好的效果。
盡管Spectral CNN在當時取得了非常顯著的性能,但是細究其技術可以發現該網絡還存在一些不足。首先,其卷積的實現依賴于拉普拉斯矩陣分解,沒有利用含有鄰居信息的鄰接矩陣,導致卷積核不具備局部性;其次,其卷積計算每次都需要對拉普拉斯矩陣進行分解,時間復雜度為O(n3),計算開銷較大。
為此,學者們以譜論知識作為理論指導,提出眾多改進模型。圖4 總結了現有工作對譜域GCN 的改進思路,并將其劃分為針對卷積核的改進和針對網絡結構的改進兩個角度,表1提供了譜域GCN的不同思想、優勢、局限性和復雜度等信息(其中“—”代表未知數據)。學者可通過單獨使用或組合不同的改進方法來提高GCN的準確率和訓練速度。本節將從上述兩個角度出發,綜述相關改進工作。
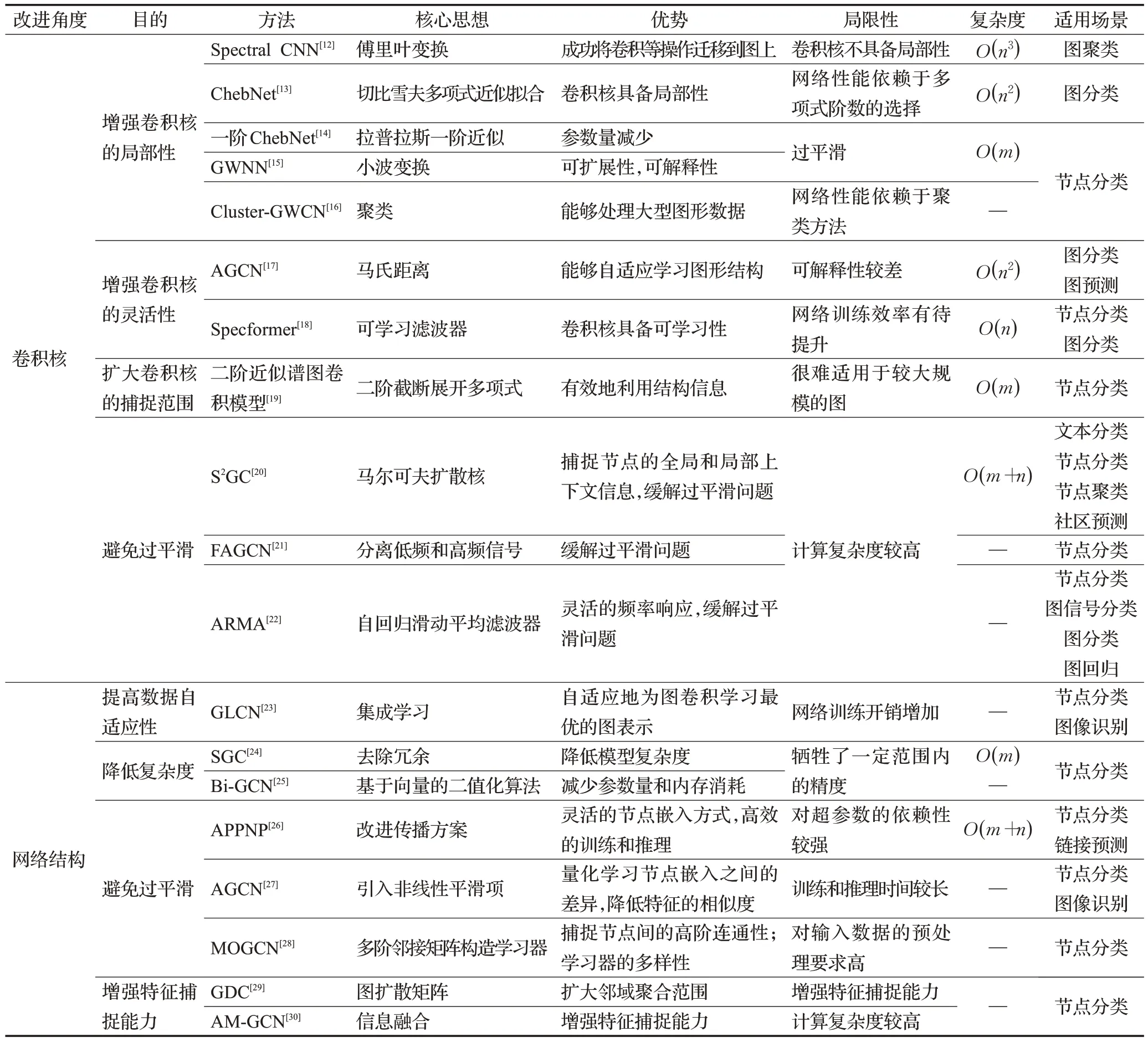
表1 譜域GCN及改進模型Table 1 Related improvement work of spectral GCN
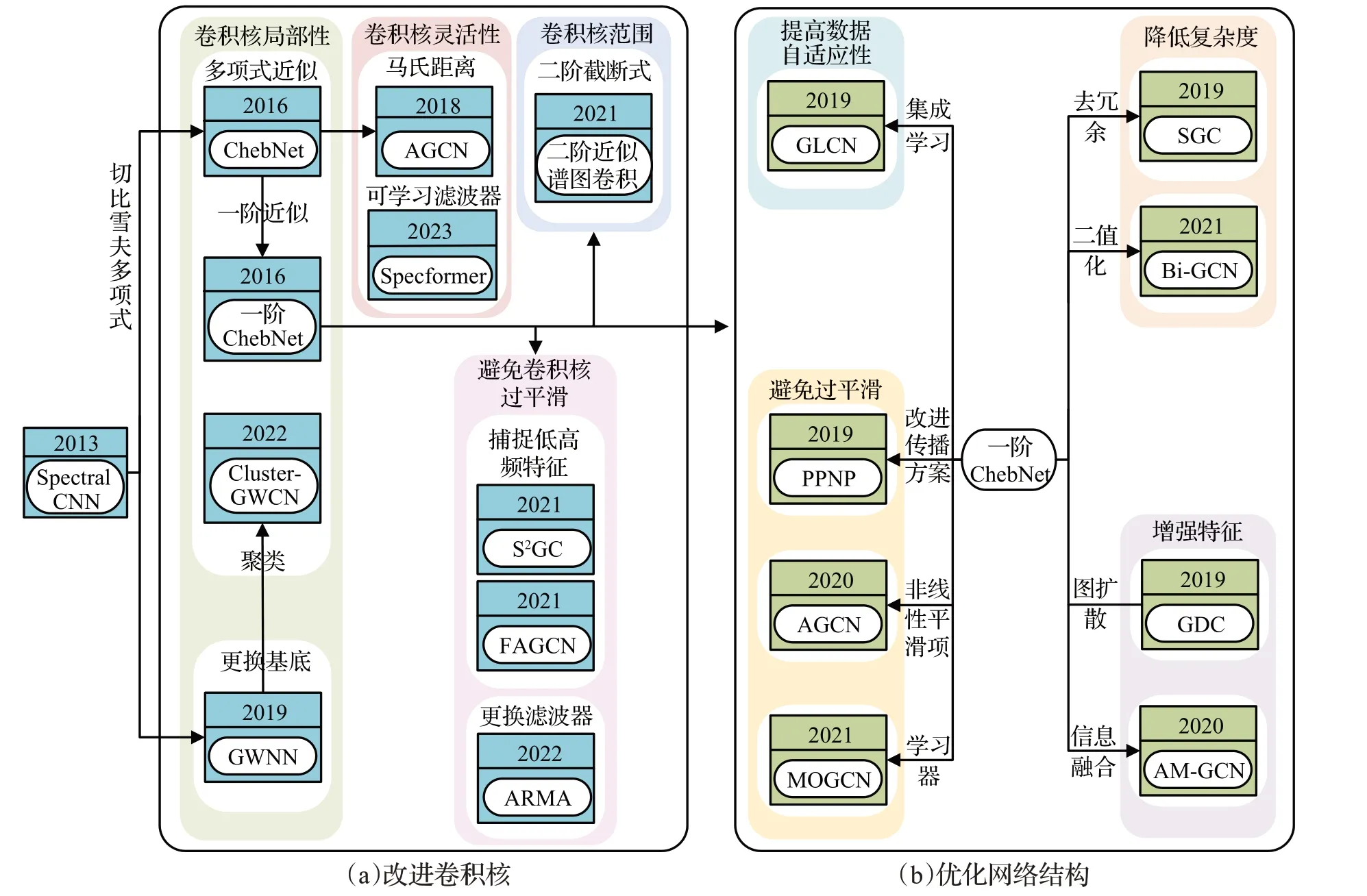
圖4 譜域GCN的相關改進工作Fig.4 Related improvement work of spectral GCN
1.2.1 改進卷積核
如圖4(a)所示,根據目的不同,可將卷積核的改進分為增強卷積核的局部性、靈活性、擴大卷積核作用范圍和緩解網絡過平滑四方面。
(1)增強卷積核的局部性
通過使用多項式近似求解卷積核和更換基底的方式,可以使卷積核在具備局部性的同時降低計算復雜度,為構建更復雜的網絡提供支持。
多項式近似:Defferrard等人[13]使用切比雪夫多項式逼近卷積核函數,構造了ChebNet,使用多項式展開近似計算圖卷積,將卷積核的參數量從節點數n減小為多項式階數k,使得卷積核具備了局部性,并且降低了模型的復雜度,但采用k次迭代的切比雪夫多項式進行替換擬合,使得模型性能高度依賴于k的選擇,因此需要經過一定的參數調整才能取得較好的性能。Kipf 等人[14]進一步提出了一階ChebNet,使用局部一階近似處理卷積核,進一步增強了網絡的局部連通性,同時使得網絡只需學習濾波器參數矩陣,參數量降為1;并加入歸一化操作提高了網絡的泛化性能。該模型依賴于數據傳播思想,擁有良好的歸納能力,在未訓練時對一些任務也能取得明顯的分類效果,成為譜域GCN 的里程碑。但一階ChebNet只能保留局部鄰域信息,對于全局的拓撲信息不夠敏感,存在網絡過平滑等問題,為此出現了大量的改進工作。
更換基底:Xu 等人[15]從更換網絡基底的角度出發提出GWNN(graph wavelet neural network),使用具有局部性的小波變換代替全局性的傅里葉變換實現圖卷積,通過切比雪夫多項式近似小波變換避免拉普拉斯矩陣特征分解的高昂代價,且利用小波變換的稀疏性進一步降低了網絡的計算復雜度,在節點分類任務的Cora、Citeseer和Pubmed上,GWCN的準確率比Spectral CNN分別提高了9.5個百分點、12.8個百分點和5.2個百分點。
聚類:為了進一步提高分類精度,Inatsuki 等人[16]提出了Cluster-GWCN,將聚類的思想與GWCN 相結合,通過多尺度小波變換處理聚類后的子圖,將圖形信號分解成不同頻率范圍的分量,從而提供更有效的局部信息。實驗結果表明,在節點分類任務中,該網絡比GWCN在Cora和Citeseer上的準確率分別提高了1.7個百分點和2.4個百分點。
(2)增強卷積核的靈活性
馬氏距離:針對ChebNet采用固定的拉普拉斯矩陣分解,導致卷積核無法適用于不同結構和尺寸的圖數據的問題,Li 等人[17]提出了AGCN(adaptive graph convolution network),通過馬氏距離學習矩陣間最優距離度量參數,利用訓練好的度量對不同樣本動態地構造拉普拉斯矩陣,提高了卷積核的靈活性。該網絡在復雜的圖分子預測任務中展現出良好的性能。
可學習濾波器:現有譜域GCN 的卷積核通常是基于固定階數多項式構造的,其表達能力和靈活性受到限制。對此,Bo等人[18]提出了Specformer,利用Transformer對所有特征值集進行編碼,并在譜域通過自注意力機制構建了一個可學習的集合到集合的卷積核。該網絡以置換等變的方式有效地捕獲特征值的大小和相對依賴性,并且可以執行非局部圖卷積。實驗證明,Specformer在Cora和Citeseer上的準確率相比一階ChebNet分別提高了1.43個百分點和1.63個百分點。這表明Specformer的表達能力更強,靈活性更高,并且能夠更好地適應不同的圖結構和數據分布。
(3)擴大卷積核的捕捉范圍
二階截斷式:一階ChebNet的卷積核的捕捉范圍僅限于中心節點的一階鄰居,忽視了非直接鄰居節點信息。對此,公沛良等人[19]提出了二階近似譜圖卷積模型,使用切比雪夫遞推式構造二階截斷展開多項式構造卷積核,擴大卷積核的作用范圍,并對模型進行參數精簡,從而更有效地利用結構信息,在節點分類任務中,比一階ChebNet在Citeseer、Cora、Pubmed和Nell上的準確率分別提高了1.5個百分點、1.1個百分點、0.8個百分點和1.2個百分點。
(4)避免過平滑
一階ChebNet 將鄰居節點的信息通過求均值后傳遞給中心節點,隨著層數的加深,節點表征存在丟失局部信息、表示趨于一致的問題,即過平滑。由于低頻信息反映節點之間的相關性,高頻信息反映節點之間的差異性,學者們通過構造特定的卷積核自適應地捕獲低頻和高頻信息,從而緩解一階ChebNet存在的過平滑問題。
捕捉低高頻特征:Zhu 等人[20]提出了S2GC(simple spectral graph convolution),利用改進的馬爾可夫擴散核設計了新的卷積核,兼具低通、高通濾波器的作用,充分捕捉每個節點的全局和局部上下文信息,并為每個節點的最近鄰域賦權重,有效地限制了過平滑問題。實驗結果表明S2GC在文本分類、節點分類、節點聚類和社區預測任務中均具有一定的競爭力。Bo等人[21]提出了FAGCN(frequency adaptation graph convolutional networks),通過增強的卷積核從原始特征中分離低頻和高頻信號,利用注意力機制來學習低頻和高頻信號的比例,進一步防止了節點表示變得難以區分。該網絡在節點分類任務的Cora、Citeseer和Pubmed上,準確率分別比一階ChebNet提高了2.6個百分點、2.4個百分點和0.4個百分點。
更換濾波器:多項式濾波器的平滑性導致其無法對頻率響應的急劇變化進行建模,對此,Bianchi 等人[22]提出了一種新的圖卷積層,使用自回歸滑動平均(autoregressive moving average,ARMA)濾波器替換多項式濾波器,提供了更靈活的頻率響應,對噪聲更魯棒。實驗表明,該網絡在節點分類、圖信號分類、圖分類和圖回歸任務中的性能對比基于多項式濾波器的GCN有明顯的提升。
在譜域GCN 中,卷積操作被轉換為傅里葉域中的點乘操作,以對輸入數據執行卷積操作。然而,傳統的譜域GCN 在實踐中存在一些局限性,導致無法取得網絡理想效果。
一方面,譜域GCN 的卷積操作依賴于拉普拉斯矩陣的分解,而拉普拉斯矩陣的特征向量對應的是圖結構的全局拓撲信息,故傳統譜域GCN 的卷積核不具備局部性和靈活性,且卷積核作用范圍有限。對此,學者們提出利用多項式濾波器來增強卷積核的局部性,通過學習最優度量和可學習參數使得卷積核具備靈活性,使用切比雪夫遞推式構造二階截斷展開多項式完成卷積核的構建,擴大卷積核的作用范圍。
另一方面,譜域GCN的一個常見問題是過平滑,即在處理圖像時可能會將相鄰像素的特征平滑成相似的值,導致網絡無法捕捉到圖像中的細節和局部特征。學者們通過構造特定卷積核以提高網絡對不同尺度的特征的感知能力,幫助網絡更好地捕捉圖像中的細節和局部特征,緩解網絡過平滑問題。
1.2.2 優化網絡結構
2016 年提出的一階ChebNet 引起學者們對譜域GCN 的廣泛關注。此后,學者們以一階ChebNet 為基礎,提出一系列改進工作。如圖4(b)所示,根據改進目的的不同,這些工作又可以進一步細分為四類,分別聚焦于提高數據自適應性、降低復雜度、避免過平滑和增強特征捕捉能力。
(1)提高數據自適應性
集成學習:一階ChebNet所處理的圖結構數據獨立于網絡的訓練,不能保證最好地服務于網絡的學習。對此,Jiang等人[23]首次嘗試為半監督學習建立統一的圖學習-卷積網絡體系結構,提出了GLCN(graph learningconvolutional networks),將圖學習和圖卷積同時集成在一個統一的網絡結構中,從而為圖卷積學習自適應或最優的圖表示,在節點分類和圖像識別任務中均展現出卓越的性能。
(2)降低復雜度
隨著網絡層數的加深,一階ChebNet在譜域處理圖結構數據時計算量增大,網絡復雜度升高。學者們通過在網絡中去除冗余、二值化處理和采樣節點的方式,達到有效簡化模型、構建輕量化網絡的目的。
去除冗余:一階ChebNet的表征能力依賴于數據傳播而不是非線性變換,過多的非線性部分成為冗余。對此,Wu等人[24]提出的SGC(simple graph convolution)通過去除GCN層之間的非線性激活函數并壓縮連續層之間的權重矩陣,有效降低了模型的復雜度。實驗顯示,SGC在節點分類精度基本持平其他方法的前提下,計算時間比大模型快1~2個量級左右,表明SGC擁有高效的計算效率。
二值化:數據讀取過程是使用一階ChebNet處理大規模圖數據時主要的內存消耗。對此,Wang 等人[25]提出了Bi-GCN(binary graph convolutional network),通過基于向量的二值化算法將網絡參數和輸入節點特征二值化,有效地學習和保留了信息,與一階ChebNet 相比,Bi-GCN 的網絡參數和輸入數據的內存消耗平均約為一階ChebNet的1/30,推理速度平均提高約47倍。
(3)避免過平滑
除了改進卷積核以解決一階ChebNet 過平滑的問題,學者們還從優化網絡結構的角度出發,提出改進傳播方案、引入非線性平滑項和加入學習器的方法來緩解該問題。
改進傳播方案:Klicpera 等人[26]針對一階ChebNet的過平滑問題和模型表征能力有限的問題,提出了APPNP(approximate personalized propagation of neural predictions)。該模型利用一階ChebNet 和PageRank 之間的關系推導出基于個性化PageRank 的改進傳播方案,無需引入其他參數且避免了網絡過平滑;同時將預測和傳播解耦,解決消息傳遞范圍有限的問題。在節點分類任務中,APPNP 在Pubmed 和MSAcademic 上的分類準確率比一階ChebNet 分別提高了2.08 個百分點和1.62個百分點。
引入非線性平滑項:鑒于各向異性擴散在圖像和網格去噪中的良好性能[31-34],Mesgaran等人[27]提出了AGCN(anisotropic graph convolutional network),在GCN 特征擴散規則中引入非線性平滑項,基于局部圖結構和節點特征學習非線性表示,量化學習節點嵌入之間的差異,降低特征的相似度,從而減輕過平滑。在節點分類和圖像識別任務中的實驗證明了該方法的有效性。
加入學習器:Wang 等人[28]提出了MOGCN(mixedorder graph convolutional networks),利用多階鄰接矩陣構造多個簡單的GCN 學習器,直接捕捉節點間的高階連通性,同時使用來自不同GCN 學習器的未標記節點的偽標記來增加學習器之間的多樣性,以緩解過平滑問題。該網絡在節點分類中的Citeseer和Pubmed上的準確率比一階ChebNet提高了3.7個百分點和10.8個百分點。
(4)增強特征捕捉能力
圖擴散:一階ChebNet將每一層的消息傳遞限制在一跳鄰域內,導致模型捕捉信息的范圍無法擴大。對此,Gasteiger等人[29]提出了GDC(graph diffusion convolution),采用基于廣義圖擴散矩陣的稀疏矩陣替換傳統的鄰接矩陣,以從更大的鄰域內聚合信息。實驗表明,該網絡在節點分類任務中提高了準確性,并且只需要較少的超參數調優。
信息融合:一階ChebNet在每一層的相鄰節點之間傳遞消息,聚合后形成下一層的嵌入,信息捕捉方式單一,導致模型的表征能力受限。為此,Wang等人[30]提出了AM-GCN(adaptive multi-channel graph convolutional network),同時從節點特征、拓撲結構及其組合中提取特定和常見的嵌入,并使用注意機制來學習嵌入的自適應權重。實驗結果顯示,該模型在節點分類任務中展現出卓越的分類性能,在Citeseer上的準確率比一階ChebNet提高了1.08個百分點。
一階ChebNet是一種處理圖數據的方法,可以通過半監督和無監督學習來提取圖的特征,并被廣泛應用。但其網絡結構相對簡單,網絡性能可能受到一定影響。為了解決該問題,學者們通過集成學習建立了輸入數據和網絡結構之間的關聯關系,使網絡能夠自適應地學習最優的圖表示。此外,他們還通過去除冗余信息和使用二值化算法來實現輕量化網絡;通過改進傳播方案、引入非線性平滑項和介入學習器等方法對網絡結構進行優化,緩解網絡過度平滑問題;使用圖擴散和信息融合策略增強了網絡的特征捕捉能力。以上改進使得以一階ChebNet 為基礎的網絡在非結構化數據的特征提取中取得了出色的性能,適用于節點分類等任務。
表1總結了各類譜域GCN的主要特征、局限性及復雜度等信息。由于Spectral CNN需要進行特征值分解,時間復雜度為O(n3()n為節點的數目)。其他方法中每個節點vi表征的計算涉及到其鄰居di,并且所有節點上的di之和等于邊數,因此其他方法的時間復雜度等價,如果圖的鄰接矩陣為稀疏矩陣,則為O(m()m為邊的數目),否則為O(n2)。
2 基于空域的GCN
2.1 基礎模型及架構
為探索化合物結構與性質的關聯關系,Micheli[35]提出了首個空域圖卷積神經網絡NN4G(neural network for graphs)。該網絡選取中心節點的一階鄰居作為鄰域,直接累加鄰域節點信息完成聚合,應用殘差連接和跳躍連接記憶每一層的信息,將每一層的節點特征通過特定函數融合后得到圖特征。
此后,學者們提出了各種各樣的空域圖卷積神經網絡,但是一直沿用了NN4G[35]的基本架構。圖5(a)展示了該架構的基本流程,主要包括三個關鍵步驟:首先選取中心節點,并確定其鄰域信息;然后重復多次,使用聚合策略向中心節點傳播鄰域信息以提取節點特征;最后將節點特征經過特定函數融合后得到圖特征(根據面向任務的不同,可選擇是否進行特征融合)。表2 提供了三個步驟對應的空域GCN的不同思想、優勢、局限性以及適用場景和復雜度等信息,為相關學者提供參考(其中“—”代表未知數據)。時間復雜度的表征中,n為節點的數目,m為邊的數目。
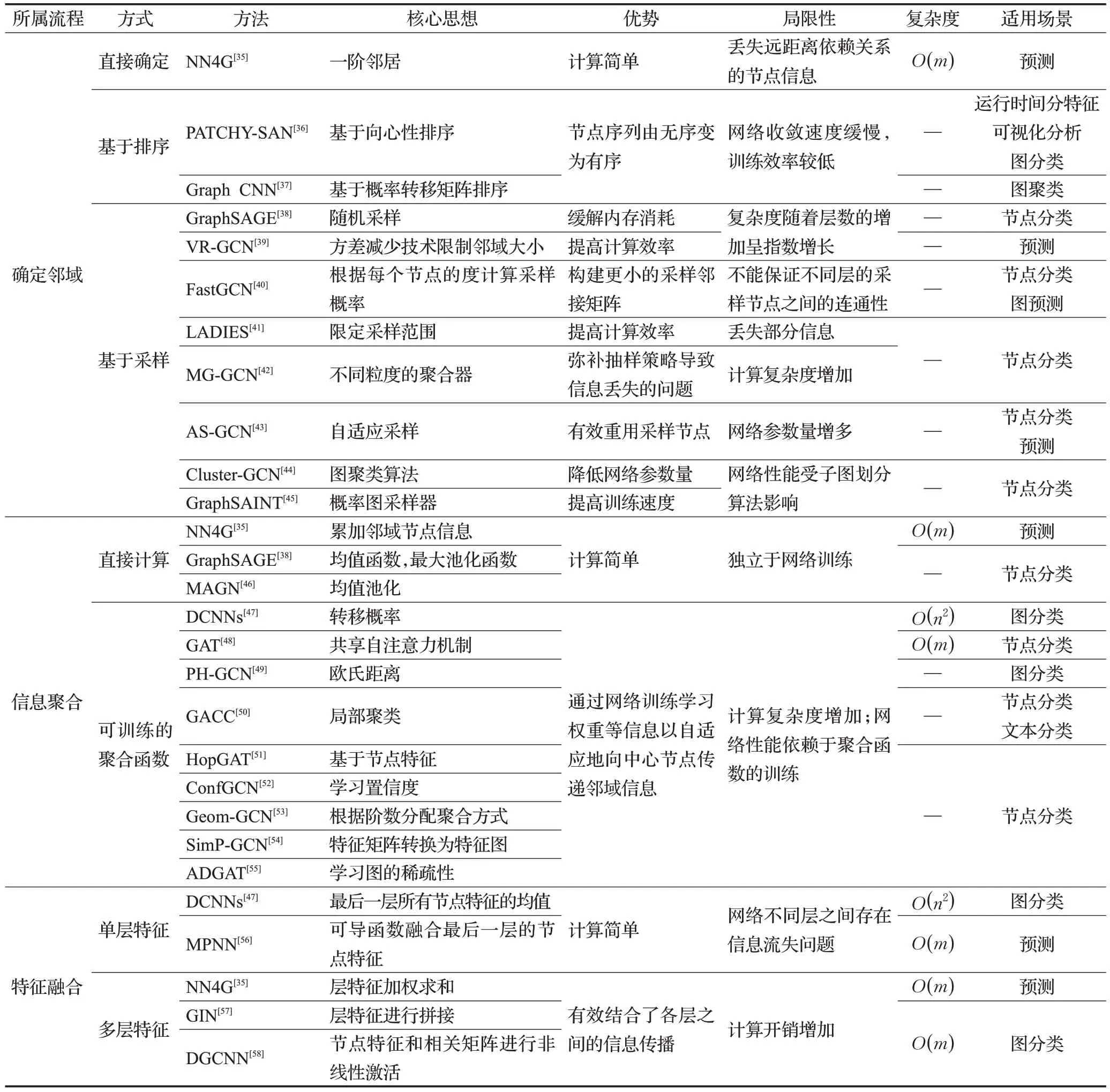
表2 空域GCN相關模型Table 2 Spatial GCN related models
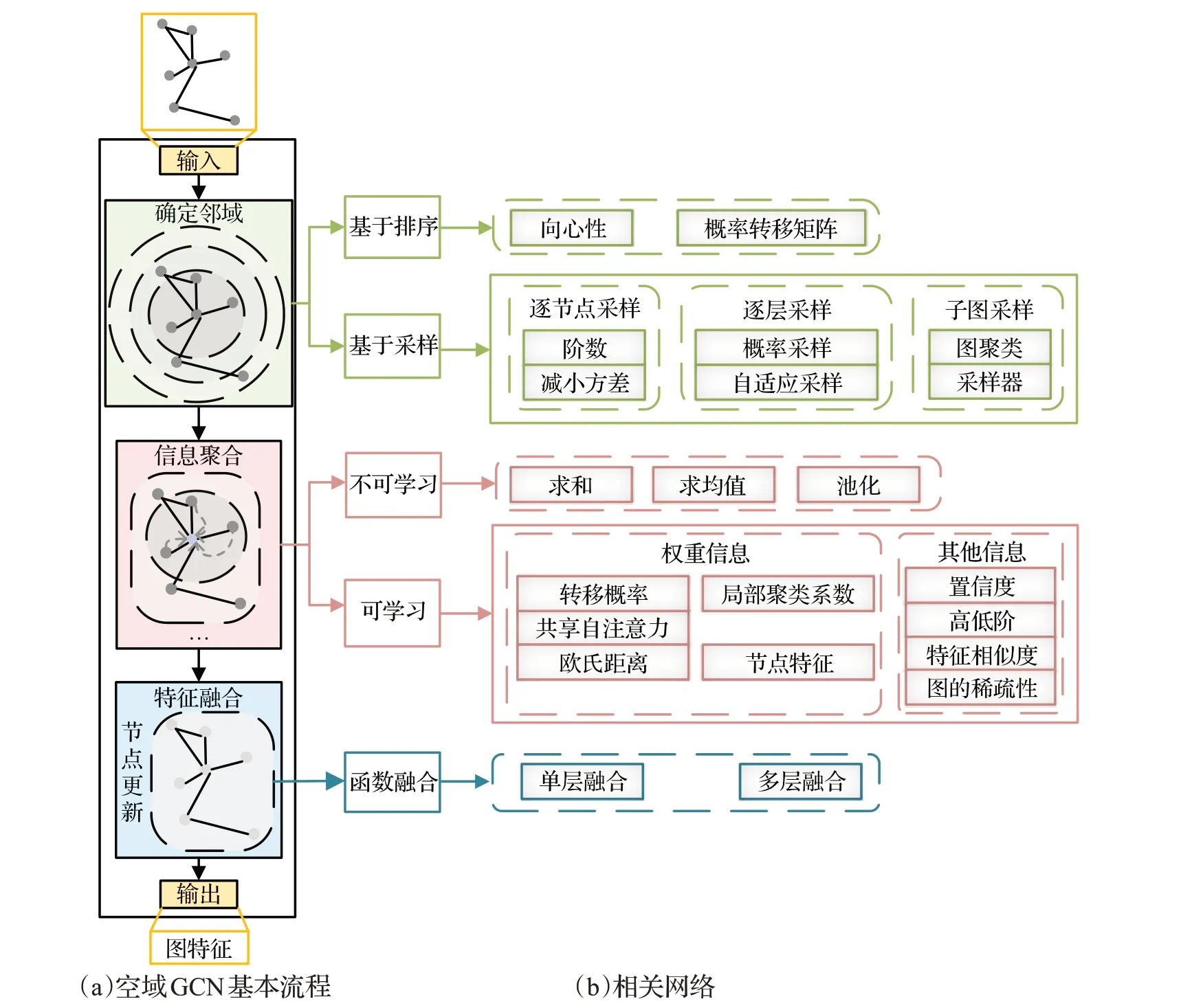
圖5 空域GCN基本結構及相關網絡Fig.5 Basic structure and related network of spatial GCN
2.2 空域GCN的改進
如圖5(b),圍繞空域圖卷積的三個關鍵步驟,學者們提出了各種各樣的新方案,誕生了許多優秀的模型,下面分別進行介紹。
2.2.1 確定鄰域
圖中各個節點的相鄰節點數目各不相同,為采用固定模式完成局部空間區域的信息聚合,彌補圖結構數據在空域平移不變性的缺失,給定一個圖結構數據G={V,E,A},其中V表示節點集合,E表示邊集合,A表示鄰接矩陣(定義節點間的連接關系),首先需要為每個中心節點vi∈V確定固定數目的鄰域節點。本節按照鄰域節點選取原理的不同,將其分為基于排序和基于采樣兩類。
(1)基于排序
基于排序的鄰域確定方法以節點屬性或連通性對全局或局部區域的節點排序,并對每個中心節點提取前k個節點組成其鄰域。
向心性:Niepert 等人[36]提出了PATCHY-SAN,將鄰域的確定分為以下三步:首先根據中心化度量(節點的度、PageRank 算法或Weisfeiler-Lehman 算法)將圖中節點映射為有序的節點序列,間隔s選取w個節點作為中心節點;然后對于每一個中心節點,利用廣度優先搜索至少k個鄰居節點構成鄰域;最后利用鄰域節點到中心節點的距離進行圖標記以對鄰域進行歸一化,完成從圖到向量映射的預處理。實驗結果表明,該網絡在圖分類問題中展現出優秀的特征提取能力和泛化能力。
概率轉移矩陣:為將CNN 推廣到圖結構數據的處理,Hechtlinger等人[37]提出的Graph CNN設計了另外一種基于排序的鄰域節點選取方式,遍歷圖結構數據,將每一個節點作為中心節點,以基于隨機游走的概率轉移矩陣為基礎,為每個節點選擇相連的前k個最近鄰居組成鄰域,在分子預測和手寫體數字識別任務中展現出良好的性能。
(2)基于采樣
基于排序的GCN 通常使用全批次方法進行訓練,導致網絡訓練效率低下且通常帶來高昂的計算和內存成本,網絡可擴展性較差。為此,學者們提出了基于采樣的鄰域確定方法,根據節點屬性或連通性將節點選擇性地歸入中心節點鄰域中,減少了網絡需要處理的節點數量,在可接受的精度損失下,降低了GCN訓練的計算和存儲成本。根據采樣策略的不同,可分為逐節點采樣、逐層采樣和子圖采樣的方式。
逐節點采樣:逐節點采樣以隨機采樣為基礎,指定采樣階數k和各階采樣的上限節點數n,為中心節點從1到k逐階采樣,形成其鄰域節點。Hamilton等人[38]提出了GraphSAGE,對鄰居進行隨機采樣,每一跳抽樣的鄰居數不多于n,緩解了時間和內存需求。為了減輕由鄰域表示的遞歸計算引起的感受野的指數增長,Chen 等人[39]提出了VR-GCN(graph convolutional networks with variance reduction),利用方差減少技術將采樣鄰居的大小限制為任意小的數量,只需采樣兩個鄰居節點即可完成節點估計,在Reddit上的運行時間僅是GraphSA-GE的1/7。
逐層采樣:逐層采樣方法(層指GCN不同深度的網絡層)是對節點抽樣方法的改進。首先在每一層將圖結構數據展平,節點之間的連接轉化為層與層之間節點的連接,同一層的節點之間彼此獨立。然后采用自上至下的逐層采樣策略,根據采樣概率或自適應算法同時采樣多個節點,避免了鄰居的指數擴展,顯著降低了采樣過程的時間成本。
①概率采樣:Chen 等人[40]提出了FastGCN,根據每個節點的度計算采樣概率,并相應地為每個層采樣固定數量的節點來構建更小的采樣鄰接矩陣。Zou等人[41]提出了LADIES(layer-dependent importance sampling),將下一層的采樣范圍限定為與當前層節點相連的節點來提高計算效率,該網絡在Cora、Citeseer、Pubmed 和Reddit 上的準確率比FastGCN 分別提高了0.3 個百分點、1.5個百分點、2.4個百分點和3.3個百分點。Huang等人[42]提出了MG-GCN(mix-grained GCN),在FastGCN的基礎上,增加不同粒度的聚合器,收集不同層次的鄰域信息,彌補抽樣策略導致信息丟失的問題。與Fast-GCN相比,該網絡在Cora、Citeseer、Pubmed和Reddit上的準確率分別提高了2.5 個百分點、0.4 個百分點、1.1 個百分點和1.3個百分點。總體而言,通過概率采樣,以上網絡在節點分類任務中保持較高分類準確性的同時,顯著降低了網絡的復雜度和計算成本。
②自適應采樣:Huang等人[43]提出了AS-GCN,以自上而下的方式對每一層中固定數量的節點進行采樣,使用參數化的采樣器,根據上層的節點自適應地對下層的節點進行采樣,而不是在每一層中進行獨立采樣,確保了采樣節點的有效重用,顯式地降低了采樣方差。在節點分類任務中,該網絡在有效性和準確性上優于Graph-SAGE和FastGCN。
子圖采樣:在子圖采樣方法中,采用圖劃分算法直接形成或特定采樣算法組合而成子圖,并針對GCN 訓練中的每個小批次采樣一個或多個子圖,以顯著降低訓練復雜度。Chiang 等人[44]提出了Cluster-GCN,使用圖聚類算法將原始圖劃分為多個聚類子圖,并限制子圖中的鄰域搜索,在節點分類任務中的參數量為GraphSAGE的1/4。Zeng等人[45]提出了GraphSAINT(graph sampling based inductive learning method),通過概率圖采樣器來構建小批量子圖,在5個大型圖上展現出卓越的準確性和訓練效率。
排序確定鄰域的方法使得節點從無序變為有序,可依據面向任務的不同選取不同的排序策略,但在處理大規模圖結構數據時,網絡計算復雜度和內存消耗過大;而基于采樣確定鄰域大大減少了鄰居節點的數量,緩解了內存壓力,提高了網絡訓練效率,但采樣過程中丟失部分信息,導致網絡精度在一定范圍內下降。
2.2.2 聚合鄰域信息
定義節點i的鄰域為N(i),第k層節點i的特征為,聚合鄰域信息就是利用N(i)的信息更新形成中心節點i的新特征。聚合策略的選取決定了節點之間信息傳播的效果,是影響網絡性能的重要因素,根據聚合函數是否依賴于網絡訓練,分為不可學習聚合和可學習聚合。
(1)不可學習的信息聚合
不可學習的信息聚合采用獨立于網絡訓練的特定函數聚合中心節點及其鄰域特征,形成更新后的中心節點特征。常用的函數有:GraphSAGE 中提出的以鄰居節點特征平均值作為中心節點的特征均值函數(等價于AveragePooling),取鄰居節點特征線性變換結果最大值的最大池化函數(MaxPooling)。基于特定函數的方式十分簡單有效,直到2021年,Zhang等人[46]提出的MAGN仍然利用均值池化運算對多尺度特征傳播的輸出進行聚合,在半監督節點分類任務中取得了具有競爭性的性能。
(2)可學習的信息聚合
可學習的信息聚合通過網絡訓練學習權重等信息以自適應地向中心節點傳遞鄰域信息,完成中心節點的更新。
自適應權重學習:此方式在聚合過程中考慮不同節點的重要性,自適應地為鄰居節點分配權重,對鄰居節點特征進行加權線性變換完成信息聚合。Atwood等人[47]提出了DCNNs(diffusion-convolutional neural networks),利用隨機行走后得到的k跳轉移概率定義權重,在圖分類任務中展現出良好的泛化能力。Veli?kovi? 等人[48]提出了GAT(graph attention networks),通過使用共享自注意力機制計算中心節點與鄰居節點的注意力系數,在節點分類任務中體現出良好的分類能力。Jiang 等人[49]針對人物重識別任務提出了PH-GCN(part-based hierarchical graph convolutional network),權重的確定依賴于節點之間的歐氏距離,在人物重識別任務中取得彼時最優精度。針對GAT僅考慮節點之間的鄰居內連通性而忽略中心節點的鄰域性質的問題,Yadav 等人[50]提出了GACC,適當地權衡節點的自循環,將節點的鄰域性質編碼到節點本身,其權重由局部聚類系數確定,在節點分類任務的Citeseer、Cora和Pubmed上的準確率比GAT 分別提高了0.5 個百分點、3.4 個百分點和1.5 個百分點。由于一般注意力模型無法自動從不同跳值的鄰居節點學習有效的語義信息,Ji 等人[51]提出了HopGAT(hop-aware supervision graph attention networks),權重基于節點特征確定,在Citeseer和Pubmed上的準確率比GAT分別提高了1.1個百分點和1.4個百分點。
其他信息的自適應學習:除權重外,網絡也可學習其他信息完成信息聚合。Vashishth等人[52]提出了ConfGCN,為每個節點學習置信度,并將其作用在節點相關性上,修正聚合函數,在節點分類任務取得較優精度。Pei 等人[53]提出了Geom-GCN(geometric graph convolutional networks),根據階數分配不同的聚合方式。在低階,通過聚合函數將處于同一鄰域且具有相同幾何關系的節點特征聚合到虛擬節點;在高階,通過聚合函數進一步聚合虛擬節點的特征,自適應地將相鄰節點信息融合,保證了圖結構數據的置換不變性,在節點分類任務中展現出強有力的分類能力和泛化性。Jin等人[54]提出了SimPGCN,根據成對節點特征之間的余弦相似度生成KNN圖,將特征矩陣轉換為特征圖,然后將特征圖與原始圖集成到GCN 聚合過程中,通過特征相似度聚合機制自適應地集成圖結構和節點特征,利用自監督學習來捕捉節點之間復雜的特征相似性和差異關系,在節點分類任務中展現出優秀的特征提取能力。隨著層數的增加,GAT的性能受到限制,對此,Zhou等人[55]提出了ADGAT,根據圖的稀疏性自適應地選擇層數,在Cora、Citeseer和Pubmed 上的平均準確率分別比GAT 提高了1.0 個百分點、1.1個百分點和1.7個百分點。
在聚合鄰域信息時,不可學習的聚合方式計算簡單,不會給網絡帶來額外的內存和計算消耗,但獨立于網絡訓練,不能保證所采取的聚合方式是最優的;可學習的聚合方式通過損失函數約束網絡自適應地學習最優聚合函數,但網絡訓練效率下降,且聚合函數的選擇對網絡性能產生較大影響。
2.2.3 特征融合
對于圖級別的任務,如圖分類,僅獲得節點特征無法完成最終的分類決策,還需要對節點特征進行融合,獲得圖級別的特征表示FG。具體的,輸入各個中心特征,特征融合過程依據特征融合的層數,分為融合單層特征和融合多層特征,現有工作大多沿用此兩類方式。
融合單層特征:此類方式只針對網絡最后一層的節點特征進行融合。Atwood等人[47]提出的DCNN直接采用最后一層所有節點特征的均值作為FG。Gilmer 等人[56]提出的MPNN(message passing neural networks)使用可導函數融合最后一層的節點特征以計算FG,且該函數滿足置換不變性。
融合多層特征:定義f(k)是第k層特征,此類方法將第k層所有節點特征經過線性或非線性處理后生成f(k),將所有層特征f(i)(i=1,2,…,K)融合后得到FG。Micheli 等人[35]提出的NN4G 將第k層所有節點特征求均值以計算f(k),將所有層特征加權求和后得到FG。Xu等人[57]提出了GIN(graph isomorphism network),f(k)通過第k層所有節點特征求和得到,所有層特征進行拼接得到FG。Zhang 等人[58]提出的DGCNN(deep graph convolutional neural network)將節點特征和相關矩陣經過非線性激活后得到f(k),拼接所有層的輸出特征作為FG。
在進行特征融合時,融合單層特征的計算復雜度較小,但網絡不同層之間存在信息流失問題;融合多層特征的方式有效結合了各層之間的信息傳播,但與融合單層特征相比,計算量和內存開銷增加。
3 GCN在圖像識別領域的應用
當前GCN 在計算機視覺領域取得了突破性進展,并被廣泛應用于圖像識別任務。其中在多標簽圖像識別、基于骨架的動作識別和高光譜圖像分類任務中使用最廣,涌現出大量優秀模型。本章將以這三個任務為代表,對GCN在圖像識別領域的應用進行總結。
3.1 多標簽圖像識別任務
所謂多標簽圖像識別,就是同時預測一張圖像中出現的多個物體的標簽,即同時完成一張圖像內部多個物體的識別。鑒于物體的內在聯系,以及場景同物體間的關聯性,物體的出現往往不是完全獨立的,因而對標簽之間的共現依賴關系進行有效建模便成為提高多標簽圖像識別的核心問題,而圖恰恰是最合適的一種表征方式[59-60]。具體的,學者們將標簽作為節點,將節點間的關聯作為邊,通過GCN 捕獲標簽間的直接、間接關系,進一步建模標簽的共現依賴關系,以提高多標簽圖像識別的精度。下面將從數據集、評價指標及相關網絡模型等方面對相關工作進行介紹。
3.1.1 多標簽圖像識別數據集及評價指標
目前公開且常用的多標簽圖像識別數據集有MS-COCO 2014和VOC 2007,表3給出了詳細信息。

表3 多標簽圖像識別任務中不同數據集對比Table 3 Comparison of different datasets in multi-label image recognition task
MS-COCO 2014 數據集[61]:包含80 個常見對象類別的1 222 183 張圖像,其中82 081 張用作訓練,40 137張用作驗證。
VOC 2007 數據集[62]:包含20 個常見對象類別的9 963 張圖像,4 952 張用作訓練,2 501 張用作驗證,2 510張用作測試。
評價指標:本文選用三個綜合指標[3]mAP、OF1、CF1對相關算法進行評價。其中mAP為各類精確度的平均值。F1定義如下:
式中,帶入總體查全率和查準率時,可得總體F1,即OF1;帶入各類查全率和查準率時,可得平均每類F1,即CF1。
3.1.2 網絡對比及分析
(1)GCN作為分類器
Chen 等人[3]針對多標簽的共現依賴關系提出了ML-GCN,首次將GCN 用作分類器提取標簽圖的節點間的相互依賴關系,在MS-COCO 2014上和VOC 2007上的mAP分別達到83.0%和94.0%,為GCN在多標簽圖像識別領域的研究奠定了基礎。其整體結構可抽象為圖6(a1)所示的CNN-GCN 雙分支網絡。其中CNN 分支提取圖像視覺特征;GCN 分支通過詞嵌入將標簽作為圖節點,采用概率統計方法計算相關矩陣,然后通過基于GCN的映射函數從標簽表示中學習相互依賴的對象分類器;最終將分類器與圖像特征融合獲得預測分數,完成圖像內的多標簽識別。
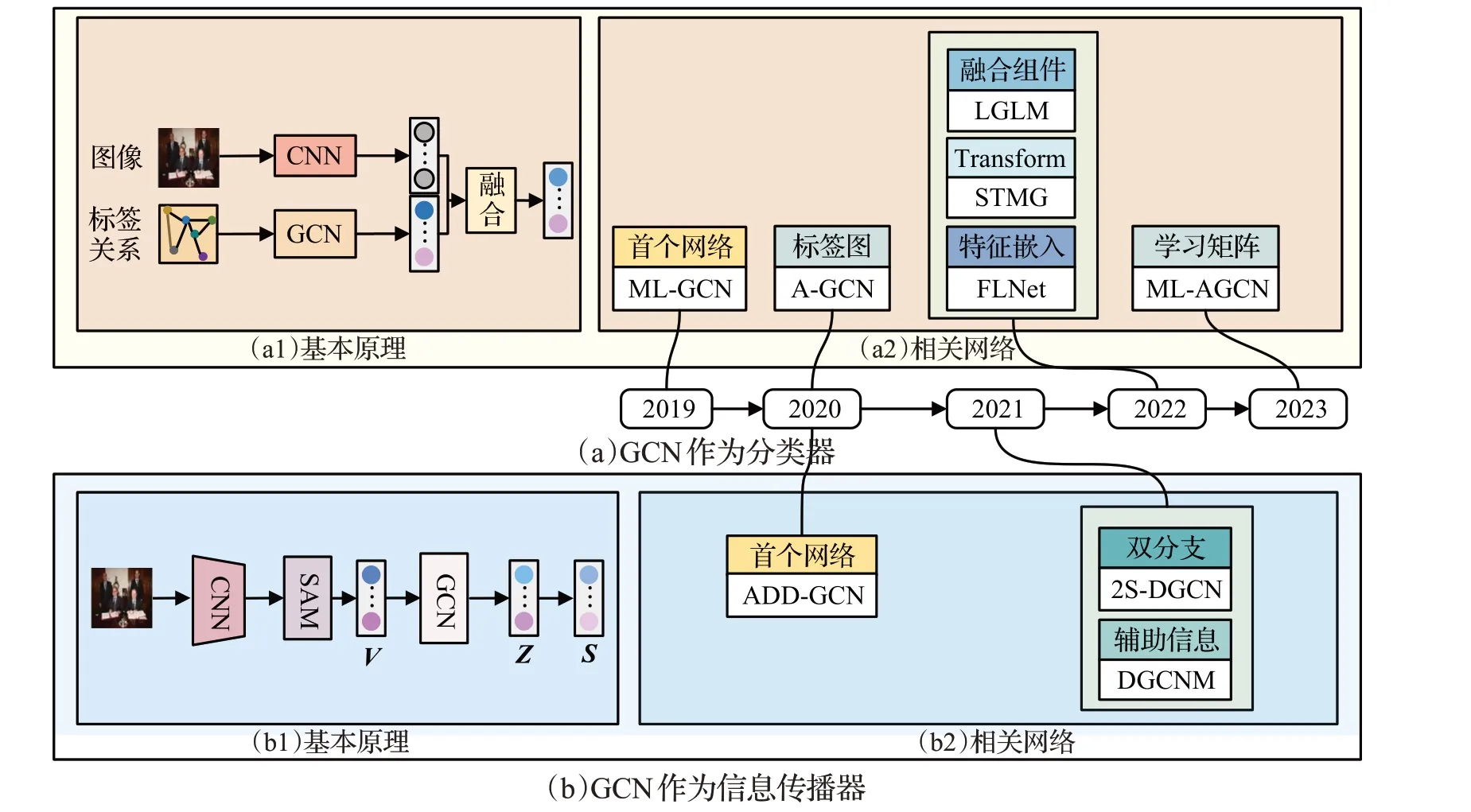
圖6 GCN在多標簽圖像識別任務中的發展Fig.6 Development of GCN in multi-label image recognition task
此后,學者們采用CNN-GCN 雙分支網絡結構,圍繞提高網絡靈活性和特征提取能力,提出了一系列改進工作,構建了多種多樣的多標簽圖像識別網絡。圖6(a2)展示了其中的代表性工作。表4 給出了各方法在MS-COCO 2014和VOC 2007上的具體性能。
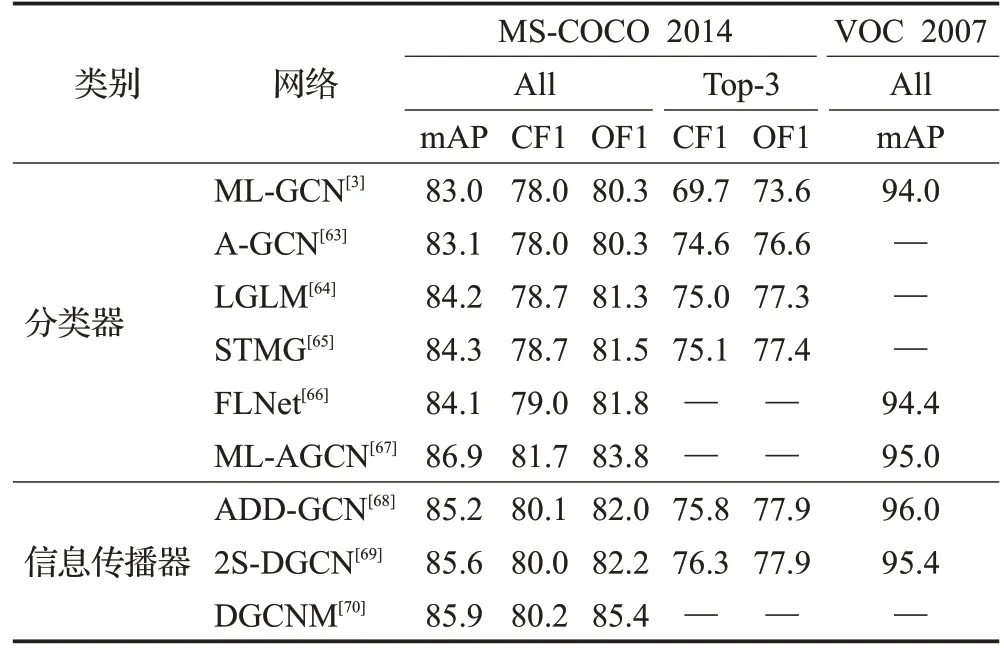
表4 各方法在兩個數據集上的性能對比Table 4 Performance comparison of each method on two datasets 單位:%
Li 等人[63]針對ML-GCN 的標簽關聯圖由人工設計導致網絡靈活性降低的問題,提出了A-GCN,引入即插即用標簽圖模塊學習單詞嵌入的標簽相關性,擺脫了人工預設的限制,提高了網絡的靈活性,其在MS-COCO 2014 上的mAP 相較于ML-GCN 提高了0.1 個百分點。Xie 等人[64]針對ML-GCN 和A-GCN 都采用點積完成圖像特征與標簽共現嵌入的融合,嚴重限制了模型收斂性的問題,提出了LGLM(label graph learning model),在跨模態融合模塊中引入了多模態融合組件,高效地融合圖像特征和標簽共現嵌入,在MS-COCO 2014 上的mAP相比ML-GCN和A-GCN分別提高了1.2個百分點和1.1個百分點。
此外,針對ML-GCN中將CNN和GCN作為兩個完全獨立模塊,忽略語義特征(GCN提取特征)對圖像特征(CNN提取特征)指導的問題,Sun等人[65]提出了FLNet,將GCN聚合的語義特征嵌入到CNN中,指導CNN學習標簽相關的圖像特征,從而為每個圖像標簽學習相互依賴的分類器,在MS-COCO 2014 上和VOC 2007 上的mAP與ML-GCN相比分別提高了1.1個百分點和0.4個百分點。為了學習圖像的全局特征,同時捕捉目標之間的標簽相關性,Wang 等人[66]提出了STMG,使用Swin Transformer 代替CNN,為每幅多標簽圖像自適應地生成圖像特征;使用GCN 自適應地捕獲標簽依賴關系以輸出標簽共現嵌入,提高網絡特征提取能力,實驗數據表明其在MS-COCO 2014 上的mAP 相比ML-GCN 和A-GCN分別提高了1.3個百分點和1.2個百分點。
Singh等人[67]發現目前GCN作為分類器處理多標簽圖像時,圖的拓撲結構是預先定義的,對于GCN而言可能不是最適合或者最優的,而且GCN 的聚合傾向于修改原始特征空間中的節點相似度,導致信息丟失[54]。為了克服這些問題,他們提出了ML-AGCN(multi-label adaptive graph convolutional network),以端到端的方式學習兩個額外的鄰接矩陣,第一個鄰接矩陣通過注意力機制為不同的節點分配權重,第二個鄰接矩陣學習節點特征之間的相似性,克服了連續卷積帶來的信息損失。實驗結果顯示,該網絡對比ML-GCN在MS-COCO 2014 和VOC 2007 上的mAP 分 別提高了3.9 個百分點和1.0個百分點。
(2)GCN作為信息傳播器
Ye等人[68]針對已有工作采用靜態方式構造相關矩陣,降低了模型泛化性的問題,提出了ADD-GCN(attentiondriven dynamic graph convolutional network),初次采用動態圖卷積網絡作為信息傳播器,對語義注意模塊(semantic attention module,SAM)生成的關系進行建模和信息傳播。實驗結果表明,ADD-GCN在兩個數據集上的評價指標對比ML-GCN均有提升。其整體結構可抽象為圖6(b1)所示的單分支串行網絡。其中CNN旨在提取每幅圖像的特征,輸入至SAM 后構建c個類別的初始類別表示V=[v1,v2,…,vc],而后GCN以V為節點,隨機初始化鄰接矩陣和狀態更新權重矩陣進行訓練,輸出c個類別的特征H=[h1,h2,…,hc]。由于每個類別的特征向量都是與其特定類對齊的,并且包含了與其他向量的信息,只需將每個類別向量放入分類器可預測其類別得分S=[s1,s2,…,sc],完成最終分類。
此后,學者們以單分支網絡結構為基礎,從網絡結構和信息擴增兩方面對ADD-GCN進行改進,構建識別性能更優越的網絡,圖6(b2)展示了其中的經典工作,表4給出了具體性能。
Cao等人[69]指出現有工作在學習特征空間中忽略了類別信息的整體結構和標簽判別向量的監督,影響模型準確性,故提出了具有上-下雙分支結構的網絡2SDGCN(two-stream dynamic graph convolution network),其上分支通過ADD-GCN 獲取預測類別的上分支置信度得分,下分支通過橫向嵌入V和標簽判別向量重構出新的圖特征節點,將其輸入到D-GCN中,產生預測類別的下分支置信度得分;融合兩個置信度得分得到包含類別信息整體結構的預測得分。該網絡在MS-COCO 2014上與ML-GCN和ADD-GCN相比mAP分別提高了2.6 個百分點和0.4 個百分點,在VOC 2007 上與MLGCN相比mAP提高了1.4個百分點。
Lan等人[70]分析發現ML-GCN和ADD-GCN側重于從圖像中捕獲標簽之間的關系屬性,而同時使用圖像和文本對圖像進行標記更為準確,故引入文本描述作為輔助信息,提出了DGCNM。該網絡利用預先訓練的描述模型提取文本特征,并將文本特征與ADD-GCN模型生成的視覺特征進行融合,為網絡擴增了輸入信息,將合并后的特征導入到動態圖卷積網絡中完成標簽間的信息傳播,在MS-COCO 2014 上 的mAP 與ML-GCN 和ADD-GCN相比分別提高了2.9個百分點和0.7個百分點。
總體來看,針對多標簽圖像識別任務,學者們分別以ML-GCN 和ADD-GCN 為基礎,將GCN 的用途分為兩大類:一類是將GCN 作為分類器,構建雙分支網絡,通過CNN和GCN分別提取視覺和語義特征,最終通過融合后的信息完成識別;另一類是將GCN 作為信息傳播器,首先通過CNN 提取初始特征,然后進一步利用GCN 建模標簽之間的依賴關系,輸入分類器后完成圖像識別。
如表4 所示,綜合來看,GCN 作為信息傳播器的綜合性能優于GCN 作為分類器。通過分析發現,這是因為當GCN 作為信息傳播器時,無需考慮圖像特征和語義特征之間的融合特征,直接將CNN 提取的特征映射分解為內容感知的類別表示,并通過靜態圖和動態圖分別捕獲全局粗粒度和局部細粒度的類別依賴關系,顯著提高了圖像識別精度。而將GCN 作為分類器時,CNN與GCN 提取的特征相較而言更加獨立,如何高效完成信息融合仍具挑戰。而GCN 作為信息傳播器時,需要處理靜態圖和動態圖,與GCN作為分類器相比,其計算復雜度和內存開銷增加。
3.2 基于骨架的動作識別
人體骨架各個關節彼此關聯,在對基于骨架的動作進行識別時,有效建模,進而利用關節之間的關聯關系對提高其識別準確性具有積極的意義。而與CNN 相比,GCN 更擅長建模節點之間的內在聯系并捕獲擁有依賴關系的時序信息,故被廣泛運用于基于骨架的動作識別任務中。下面將從數據集、評價指標及相關網絡模型等方面對相關工作進行介紹。
3.2.1 基于骨架的動作識別數據集及評價指標
目前公開且常用的動作識別數據集包括NTURGB+D 60、NTU-RGB+D 120 和Kinetics-Skeleton,詳細信息如表5所示。
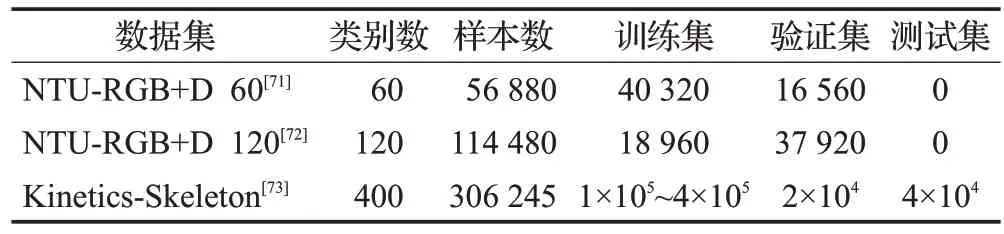
表5 基于骨架的動作識別任務中不同數據集對比Table 5 Comparison of different datasets in skeleton-based action recognition task
NTU-RGB+D 60[71]:該數據集包含60 個種類的動作,共56 880個樣本,其中有40類為日常行為動作,9類為與健康相關的動作,11類為雙人相互動作,該數據集通過3個相機采集,一幀骨架序列包含25個人體關節作為節點,以三維關節位置作為初始特征。以該數據集為基礎,又建立了兩種不同的測試標準。(1)X-Sub,數據集中包含40 個類別,其中40 320 個樣本用作訓練,16 560個樣本用作測試;(2)X-View,用攝像機2 和3 采集的37 920 個樣本用作訓練,用攝像機1 采集的18 960 個樣本用作測試。
NTU-RGB+D 120[72]:該數據集與NTU-RGB+D 60相比,通過添加另外60 類和另外57 600 個視頻樣本進行擴展,即NTU-RGB+D 120 總共有120 類和114 480個樣本,并由32 臺攝像機拍攝,對應兩個測試標準。(1)X-Sub,數據集中包含53個類別,其中63 026個樣本用作訓練,剩下的樣本用作測試;(2)X-View,具有偶數標識的樣本用作訓練,具有奇數標識的樣本用作測試。
Kinetics-Skeleton[73]:該數據集有400 個類別,共有306 245個視頻,分為三部分,訓練集每個類250~1 000個視頻,驗證集每個類50個視頻,測試集每個類100個視頻。
評價指標:NTU-RGB+D 60和NTU-RGB+D 120數據集的子集都使用Top-1準確率衡量;Kinetics-Skeleton使用Top-1準確率和Top-5準確率衡量。
3.2.2 網絡對比及分析
圖7根據各個工作突出重點的不同,將基于骨架的動作識別網絡分為提取豐富信息、提高模型靈活性、關注重點信息三大類,并以時間為序展示了各種方法及其關鍵改進。表6 對比了這些方法在NTU-RGB+D 60、NTU-RGB+D 120 和Kinetics-Skeleton 上的識別性能。下面將分別進行介紹。
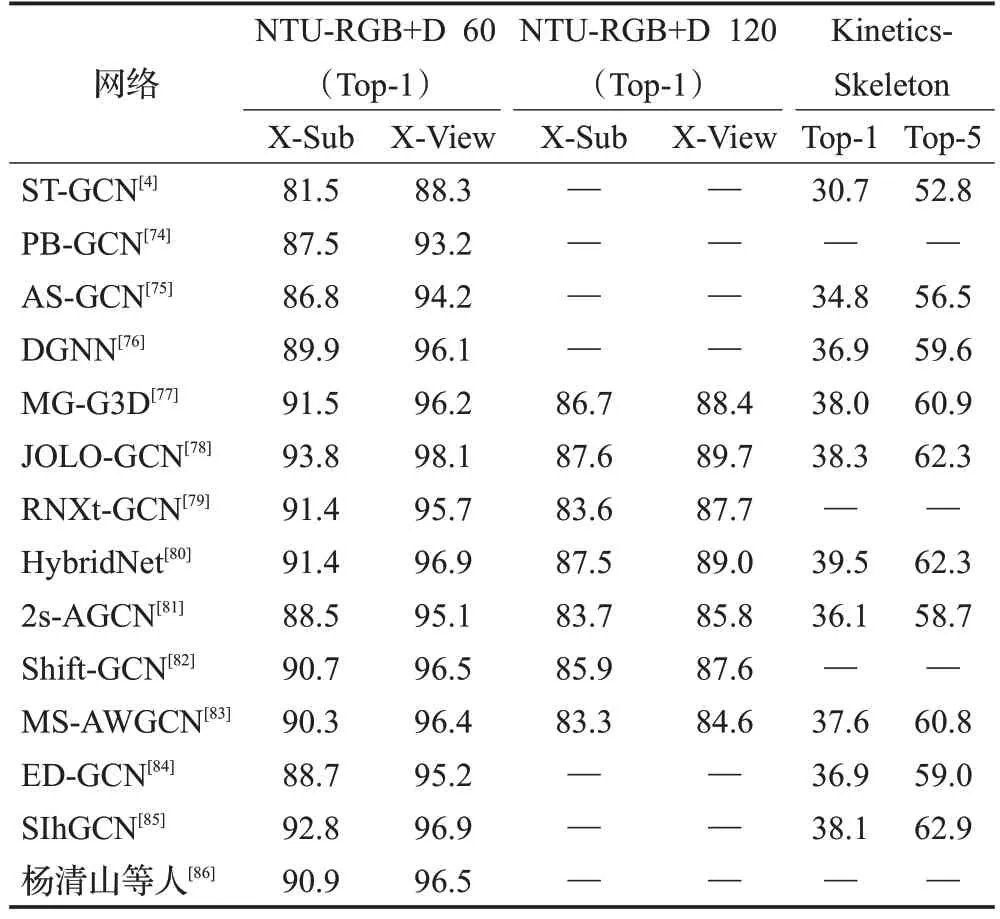
表6 各方法在三個數據集上的性能對比Table 6 Performance comparison of each method on three datasets 單位:%
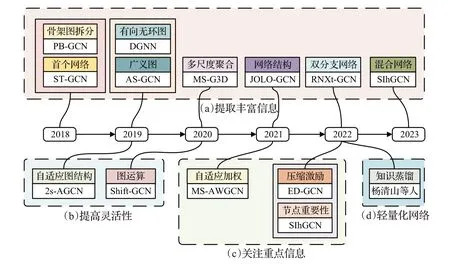
圖7 GCN在骨架動作識別任務中的發展Fig.7 Development of GCN in skeleton-based action recognition task
(1)提取豐富信息
較CNN而言,GCN可捕捉骨架節點及其關聯關系,提取更加豐富的信息。Yan 等人[4]提出的ST-GCN 首次將GCN應用于動態骨架建模,以關節為節點,以人體結構和時間上的自然連通性為邊,構造時空圖,使用多層時空圖卷積沿空間和時間維度集成信息,提高了動作識別任務的精度,同時模型具備更強的表達能力和泛化能力。Thakkar 等人[74]針對ST-GCN 忽略了人體骨架內部關聯關系的問題,提出了PB-GCN(part-based graph convolutional network),將骨架圖分為4 個共享連接點的子圖,匹配人體骨架結構及其連接關系,在NTURGB+D 60數據集的兩個子集上分別獲得了較ST-GCN高6.0個百分點和4.9個百分點的準確率增益。
Li等人[75]針對ST-GCN丟失了長距離節點特征的問題,提出了AS-GCN(actional-structural graph convolution network),構建廣義圖將A-links(actional links)擴展到高階鄰域以提取更豐富的關節依賴關系,比ST-GCN在NTU-RGB+D 60 和Kinetics-Skeleton 上準確率分別提高了5.3個百分點、5.9個百分點、4.1個百分點和3.7個百分點。Shi等人[76]指出現有方法結合關節和骨骼信息的能力仍有待提高,提出了DGNN(directed graph neural network),基于人體中關節和骨骼之間的運動學依賴關系,將骨骼數據表示為有向無環圖(directed acyclic graph,DAG),用于提取關節、骨骼及其相互關系的信息,并根據提取的特征進行預測。該網絡在NTU-RGB+D 60和Kinetics-Skeleton上準確率比ST-GCN分別提高了8.4個百分點、7.8個百分點、6.2個百分點和5.8個百分點。
Liu 等人[77]分析認為ST-GCN 等現有方法捕獲遠距離關節信息的能力有限,且獨立捕捉時間和空間信息的結構嚴重阻礙了跨時空的直接信息流。為此,他們提出了MS-G3D,通過多尺度聚合方案將不同鄰域中節點的重要性分解以進行有效的遠程建模,構建了時空圖卷積算子G3D,利用密集的跨時空邊緣作為跳過連接實現時空圖上的直接傳播信息,在NTU-RGB+D 60、NTURGB+D 120 和Kinetics-Skeleton 三個數據集上的準確率均明顯優于以前的最新方法。
此外,有學者從網絡結構的角度進一步提高骨架動作識別模型的信息提取能力。具體的,針對骨骼動力學無法捕捉細微運動特征的問題,Cai等人[78]提出了JOLOGCN,加入JFP(joint-aligned optical flow patches)捕捉關節周圍的局部細微運動,并將其提取的特征作為關鍵視覺信息,采用基于GCN的雙流網絡結構,獨立處理骨架序列和JFP 序列并線性混合兩分支的預測分數完成分類,在NTU-RGB+D 60和Kinetics-Skeleton上準確率比ST-GCN分別提高了12.3個百分點、9.8個百分點、7.6個百分點、9.5個百分點。Liu等人[79]針對ST-GCN 不能利用時間信息學習相似動作間差異的問題,提出了雙分支網絡RNXt-GCN,將人體骨架轉換為時空圖和Skele-Motion圖像,分別輸入到ST-GCN和ResNeX中,提高模型提取相似動作差異性的能力,比ST-GCN在NTU-RGB+D 60上的準確率分別提高了9.9個百分點和7.4個百分點。
盡管現有基于GCN的方法具有捕捉人體骨骼結構信息的能力,但由于通道間共享鄰接矩陣以及時空塊之間的稀疏連接,使得該方法建模時空線索的效率較低;CNN 可以在時空斑塊上建立密集的連接,在不同的通道上建立不同的相關性,但無法利用存在于自然人類骨骼結構中的有價值的線索。因此,Yang等人[80]認為CNN和GCN的結合可以為基于骨架的動作識別任務帶來明顯的改善,并提出了HybridNet。首先通過GCN對人體骨骼結構信息和節點的隱式拓撲進行建模,而后通過CNN探索關節在不同動作下的復雜依賴關系。該混合網絡保留了自然骨骼結構的信息,同時有效捕捉了復雜多樣的時空特征。實驗證明,該網絡比ST-GCN 在NTU-RGB+D 60上準確率提高了9.9個百分點和8.6個百分點,在Kinetics-Skeleton 上準確率提高了8.8 個百分點和9.5個百分點。
(2)提高模型靈活性
ST-GCN 將骨架圖拓撲結構固定,導致模型靈活性降低。為此,Shi 等人[81]提出了2s-AGCN(two-stream adaptive graph convolutional network),將骨骼的長度和方向作為二階信息,將固定圖替換為基于節點相關性的自適應圖結構,提高了圖形構建模型的通用性,相比ST-GCN 在NTU-RGB+D 60 上準確率提高了7.0 個百分點和6.8個百分點,Kinetics-Skeleton上準確率提高了5.4 個百分點和5.9 個百分點。Cheng 等人[82]提出了Shift-GCN(shift graph convolutional network),由Shift圖運算和輕量級的逐點卷積組成,為空間圖和時間圖提供了靈活的感受野,計算復雜度約為ST-GCN 的1/10,NTU-RGB+D 60 上識別準確率提高了9.2 個百分點和8.2個百分點。
(3)關注重點信息
盡管2s-AGCN 取得了彼時最好的性能,但是它將圖的鄰接矩陣劃分為三個權重相同的子圖,阻礙了子圖之間更深層的語義學習。對此,Xu 等人[83]提出了MSAWGCN(multi-scale skeleton adaptive weighted graph convolution network),采用多尺度骨架圖卷積網絡提取豐富的空間特征,將融合階段手工生成的鄰接矩陣替換為可學習矩陣自適應地學習圖的潛在拓撲,并根據不同的采樣策略采用加權學習的方式突出重點信息,聚合節點特征以生成更加豐富的骨架圖特征。實驗結果表明,相較于2s-AGCN,MS-AWGCN 在NTU-RGB+D 60 上和Kinetics-Skeleton 上的準確率分別提高了1.8 個百分點、1.3個百分點、1.5個百分點和2.1個百分點。
同樣是針對2s-AGCN網絡,Alsarhan等人[84]認為該網絡提取的特征區分度不夠,且網絡不能捕捉到不同的運動時間特征,為此,提出了ED-GCN(enhanced discriminative graph convolutional network)。該網絡引入了壓縮激勵模塊,使得網絡能夠使用全局信息來選擇性地增強重要特征,同時通過自適應時間模塊捕獲時間運動特征,與空間建模相輔相成,提高識別精度。實驗結果顯示,ED-GCN比2s-AGCN在NTU-RGB+D 60上準確率提高了0.2個百分點和0.1個百分點,在Kinetics-Skeleton上準確率提高了0.8個百分點和0.3個百分點。
此外,Setiawan等人[85]分析認為,已有動作識別模型在特征聚合期間忽略了不同階信息的重要性,存在信息丟失問題,同時這些模型使用標準的拉普拉斯矩陣或鄰接矩陣將圖的屬性編碼為一組向量,在表征圖不變量時有一定的局限性。為此,他們提出了SIhGCN(inter-hop graph convolution neural network),通過特征聚合過程中賦予節點不同重要性來增強基于圖的卷積神經網絡,使用SIFA(sequential inter-hop feature aggregation)從每一跳中捕獲有價值的信息,并且利用歸一化拉普拉斯矩陣將圖信息編碼為矩陣形式來增強現有的GCN。該網絡獲得了當前最先進的性能,在NTU-RGB+D 60 的X-Sub 和X-View 上分別獲得了92.8%和96.9%的Top-1準確率,在Kinetics-Skeleton 上的Top-1 和Top-5 分別達到了38.1%和62.9%。
(4)輕量化網絡
現行方法在大型數據集以及實際應用中魯棒性較差,且計算復雜度較高。為此,楊清山等人[86]提出了一種基于知識蒸餾的輕量化時空圖卷積動作識別融合模型,利用分組卷積等設計參數量較少的時空卷積子模型,并將2s-AGCN和DGNN分別作為教師模型指導學生子模型進行骨架信息的更新;為了增加模型的魯棒性,訓練和測試時使用了仿射變換等數據增強技術,用于數據增強。實驗結果表明,該網絡的兩個學生子模型相較于教師網絡參數量均下降50%左右,與其他優秀的前沿方法相比,在NTU-RGB+D 60上同樣擁有較強的競爭力。
總體上看,針對基于骨架的動作識別任務,研究者們以ST-GCN 為基礎,分別以提高模型提取信息的能力、提高模型靈活性、關注重點信息的能力和輕量化網絡為目的提出一系列改進措施。早期改進主要針對骨架圖的拆分與轉換等方式處理輸入數據,以此提高網絡的識別性能;近期的改進工作主要通過增加額外的功能模塊和采取不同的特征融合方式為網絡提供更多的信息,達到提高網絡整體性能的效果。
然而,如表6 所示,現有方法在Kinetics-Skeleton 上的識別精度比在NTU-RGB+D 60和NTU-RGB+D 120上整體較低。通過分析發現,這是由于Kinetics-Skeleton數據集規模較大,涵蓋相當數量的交互式動作,識別難度較大;而GCN在處理骨架圖時,將每個人體關節視為一個節點,導致其復雜度與輸入數據中的人類數量呈線性關系,內存需求也隨之增長,限制了GCN識別多人場景的能力。因此,如何有效提升GCN 在復雜動作數據集上的識別能力值得深究。
3.3 高光譜圖像分類
與普通圖像相比,高光譜圖像(hyperspectral images,HSI)由數百個連續的光譜波段組成,每個像素都含有大量光譜特征,能同時獲得地面物體的光譜信息和空間信息,在醫學診斷、植被檢測、軍事監控等領域有著廣泛的應用。現有的深度學習模型大多是針對歐幾里德數據設計的,忽略了相鄰光譜信息之間的內在相關性,限制了網絡的識別性能。將像素點或者超像素點作為節點,HSI編碼成圖結構數據,GCN可以明確地利用相鄰光譜信息之間的相關性,更高效地模擬HSI 的空間背景結構,故在高光譜圖像分類任務中得到廣泛應用。下面將從數據集、評價指標及相關網絡模型等方面對相關工作進行介紹。
3.3.1 高光譜圖像分類數據集及評價指標
目前公開且常用的高光譜圖像分類數據集包括和Salinas,詳細信息如表7所示。

表7 高光譜圖像分類任務中不同數據集對比Table 7 Comparison of different datasets in hyperspectral image classification task
Indian Pines:該數據集于1992 年由機載可見/紅外成像光譜儀傳感器收集,記錄了印度的西北部信息,共包含16 個類別,其中一張圖片像素大小為145×145,空間分辨率為20 m×20 m,去噪后在波長范圍0.4~2.5 μm內保留200個光譜通道。
University of Pavia:該數據集于2001年通過ROSIS傳感器捕獲了意大利帕維亞大學的信息,共包含9個類別,其中一張照片的像素大小為610×340,空間分辨率為1.3 m×1.3 m,去噪后在波長范圍0.43~0.86 μm內保留103個光譜通道。
Kennedy Space Center:該數據集由AVIRIS傳感器在美國佛羅里達州地區收集,共包含13個類別,其中一張照片的像素大小為614×512,空間分辨率為18 m×18 m,去噪后在波長范圍0.4~2.5 μm內保留176個光譜通道。
Salinas:該數據集由AVIRIS 傳感器在美國加利福尼亞州薩利納斯谷地區收集,共包含16個類別,其中一張照片的像素大小為512×217,空間分辨率為3.7 m×3.7 m,去除薩利納斯場景的20 個光譜通道(224,154~167和108~112)。
評價指標:在高光譜圖像分類任務中,主要采用總體精度(OA)、平均精度(AA)和Kappa 系數(KPP)作為分類性能的評價指標。其中OA 為總體識別正確測試樣本的準確率,AA為所有類別的每類精確度的平均值,KPP由正確分類和錯誤分類樣本個數綜合計算得到,旨在衡量網絡預測結果與真實值標注之間的一致性情況。
3.3.2 網絡對比及分析
如圖8 所示,根據編碼圖結構數據的不同,本小節將高光譜圖像分類網絡分為基于圖像的GCN方法和基于超像素的GCN 方法,并以時間為序展示了各種方法及其關鍵改進。表8 對比了這些方法在Indian Pines、University of Pavia、Kennedy Space Center和Salinas上的識別性能,下面將分別進行介紹。
(1)基于圖像的GCN方法
基于圖像的方法將HSI的每個像素視為一個頂點,并在整個HSI 像素上構建圖結構數據。Qin 等人[5]首次將GCN應用于HSI分類,提出了S2GCNs,根據相鄰像素的光譜相似度和空間距離在相鄰像素之間傳播信息,充分利用了當前像素的空間信息。實驗結果表明,與彼時基于CNN 的最優算法相比,S2GCNs 在Indian Pines 和Kennedy Space Center上的OA、AA和KPP分別提高了5.11 個百分點、11.51 個百分點、5.69 個百分點和3.22 個百分點、3.72個百分點、3.59個百分點,為GCN在高光譜圖像分類領域的研究奠定了基礎。
Mou 等人[87]認為現有深度網絡需要足夠標注的訓練實例以完成監督學習,導致訓練成本增加,故提出了Nonlocal GCN(nonlocal graph convolutional network)。該網絡將整個圖像(包括標記和未標記的數據)作為輸入,通過度量特征空間中頂點(包括標記和未標記像素)之間的相似性來構造圖數據,該數據具備非局部性和數據驅動性,并且能夠以端到端的方式自適應地學習。實驗證明,該網絡能夠提供有競爭力的準確率和高質量的分類圖。
光譜模型的多樣性增加了HSI 波段之間復雜度和冗余度,同時帶來額外的存儲消耗。Bai 等人[88]提出了DAGCN(deep attention graph convolutional network),針對高光譜數據中波段較多且波段間關系復雜的特點,設計了核光譜角映射器和光譜信息發散(kernel spectral angle mapper and spectral information divergence,KSAM-SID),以實現對相似光譜的有效聚類。實驗顯示,該網絡在Indian Pines 上的OA、AA 和KPP 對比S2GCNs 相比分別提高了6.97 個百分點、4.09 個百分點和8.00個百分點。
現有方法大多將不同樣本的不同尺度的重要性視為一致,同時所采用的Softmax 函數削弱了HSI 的內部緊湊性,網絡判別性特征的提取,從而降低了分類的準確性。為應對上述挑戰,Xi等人[89]提出了X-GPN(crossscale graph prototypical network)。該網絡構造多尺度鄰接矩陣,捕捉豐富的光譜信息和精確的空間上下文信息,采用SBAA(self-branch attentional addition)模塊自適應地組合多個分支產生的高級特征以自動地對不同尺度的樣本分配不同的重要性,使用一種新的基于時間熵的正則化器(temporal entropy-based regularizer,TER)協同生成更具鑒別性的表示,在Indian Pines和Kennedy Space Center數據集上實現了更高精度的高光譜圖像分類。
(2)基于超像素的GCN方法
基于超像素的方法的核心思想是預先將HSI 分割成具有相似特征的小區域,即超像素,并將它們視為一個頂點以緩解高內存成本。基于此,Wan等人[90]提出了MDGCN(multiscale dynamic GCN),通過簡單線性迭代聚類(simple linear iterative clustering,SLIC)算法對HSI 進行預處理,并分割成多個同質超像素,在超像素上以不同的空間尺度構造圖,聚合多尺度光譜-空間特征,并逐步細化輸入圖,將屬于同一類的超像素在嵌入空間中進行聚集。實驗表明,該網絡在Indian Pines 和Kennedy Space Center 上的OA、AA 和KPP 與S2GCNs相比分別提高了1.83 個百分點、1.32 個百分點、2.14 個百分點和4.16個百分點、5.48個百分點、4.64個百分點。
MDGCN 中的超像素是通過啟發式超像素生成技術形成的,在整個分類過程中可能不精確,并且無法改變,進而導致網絡不能細化圖節點之間的連接關系。對此,Wan等人[91]提出了CAD-GCN(context-aware dynamic graph convolutional network),通過投影和重投影步驟自適應地學習超像素,動態更新連接不同圖像區域的圖形邊緣,以便進一步利用上下文關系,同時能夠更好地匹配圖像中的物體外觀;利用改進的相似性度量和邊緣濾波器,細化圖的邊緣權值和圖像區域之間的連接關系,以適應圖的每個卷積層生成的表示。該網絡在Indian Pines 上的OA、AA 和KPP 與MDGCN 相比分別提高了0.66個百分點、0.14個百分點和0.74個百分點。
針對現有GCN 方法計算成本較高,且易出現過平滑問題,Ding等人[92]提出了一種具有自回歸移動平均濾波器(autoregressive moving average,ARMA)和上下文感知學習(context-aware learning,CAL)算法DARMACAL 用于HSI 分類,ARMA 濾波器能較好地捕捉全局圖結構,對噪聲具有較強的魯棒性且計算復雜度低,DARMA-CAL提取ARMA中每一層產生的有用的局部信息。該網絡在University of Pavia上的OA、AA和KPP與MDGCN相比分別提高了2.03個百分點、4.41個百分點和3.99個百分點。
MDGCN的圖卷積在不同的空間尺度上分別進行,卷積作用范圍限制在固定的鄰域內,對多尺度空間信息的利用仍存在欠缺。Wan 等人[93]針對此提出了DIGCN(dual interactive GCN),引入雙交互GCN分支來捕獲不同尺度的空間信息,一個GCN 分支中包含的邊緣信息可以通過合并來自另一個分支的特征表示來細化,通過融合來自GCN分支的邊緣信息,可以在GCN分支中生成改進的特征表示,從而利用多尺度空間信息的相關性來細化圖信息。實驗表明,該網絡保持了較高的準確率。
現有GCN 算法大都圍繞著如何聚合非同一類別節點周圍的節點特征展開,忽視了同一類別的所有節點都在局部區域的特征提取。Zhu 等人[94]對此提出了SLGConv(short and long range graph convolution),可以提取長程(全局)和短程(局部)空間光譜特征,保證節點的特征在卷積過程中不被平滑。該網絡在高光譜圖像分類任務中獲得了具有競爭力的結果。
針對MDGCN等基于GCN的方法側重于提取局部信息,在理解圖的全局和上下文信息方面存在欠缺的問題,Ding 等人[95]提出了SAGE-A(graph sample and aggregate-attention),采用了多級圖樣本和聚合網絡,靈活地聚合任意結構的非歐幾里德數據中的新鄰居節點,并捕獲遠程上下文關系,利用圖的注意機制來表征空間相鄰區域之間的重要性,從而通過聚焦重要的空間目標來自動學習圖的深層上下文和全局信息。該網絡在University of Pavia 上的OA、AA 和KPP 與MDGCN相比分別提高了0.51個百分點、3.03個百分點和1.75個百分點。
隨著網絡層數的增加,GCN 模型通常會出現過平滑問題,表征能力受限。對此,Yu等人[96]將GCN和CNN結合,提出了雙分支網絡TBDGCN(two-branch deeper GCN),在GCN 分支中,采用DropEdge 技術和殘差連接來緩解過平滑和過擬合問題;在CNN分支中,為了捕獲空間位置信息和信道信息,構造了一種混合注意力機制來提取基于注意力的光譜-空間特征。通過雙分支結構,TBDGCN 可以有效地捕捉小空間窗口內的局部像素關系和不同區域之間的長程上下文關系,提高了網絡的特征提取能力。實驗證明,該網絡在高光譜圖像分類任務中取得了具有競爭力的效果。
總體來說,基于GCN 的方法在HSI 分類中依據輸入數據的不同,可分為基于圖像的方法和基于超像素的方法。基于圖像的方法將整張HSI 輸入網絡,HSI 中蘊含豐富的圖像信息,但當HSI 過大時,內存消耗和計算復雜度迅速增長。基于超像素的方法將HSI 數據進行預處理后得到具有相似特征的超像素區域,降低了輸入數據的規模,但HSI在數據預處理過程中會損失部分細節信息,導致網絡識別精度下降。
雖然GCN 在HSI 分類中已經顯示出潛力,但訓練樣本有限仍是限制網絡性能的主要原因。由于在真實場景中對大量的訓練樣本進行人工標注費時費力,如表7所示,高光譜圖像分類領域的四個常用數據集中,未標記像素的數量遠超標記像素,如何基于GCN 針對該標簽不平衡問題完成分類任務是未來的研究熱點。
4 總結與展望
近年來,GCN 的相關研究取得了顯著的進展。圍繞GCN,本文首先介紹了兩類GCN 的基本原理和基礎模型架構;然后分別總結了近年來的相關改進工作;最后從多標簽圖像識別、基于骨架的動作識別和高光譜圖像識別三方面介紹了GCN在圖像識別領域中的應用。
在圖像識別領域的實際任務中,圖像數據是高度復雜和多樣化的,盡管GCN 在圖像識別領域取得了優秀的識別精度,但其自適應性、輕量化、與其他模型的有效結合等方面仍存在一些問題。因此,本文將從這三個角度出發,對GCN 在圖像識別領域的未來發展方向進行展望,希望能夠促進該領域的發展。
(1)GCN的自適應性。目前,GCN在非結構化數據的特征提取中表現出卓越的性能,但靈活性較低,對輸入數據的規模等有著嚴格的限制條件,即使改進后的GCN 具備一定的處理多樣性數據的能力,但前提是對數據進行預處理和規范化,這可能導致丟失部分拓撲結構信息。在圖像識別領域中,圖結構數據存在結構變化較大的情況,類間和類內的數據也存在一定的差異性。例如,一個大規模場景中包含的對象數目及其關聯關系各不相同,一個零件裝配圖包含的零部件數目及其裝配關系可能多種多樣,這都會導致轉化后的非結構化數據呈現多樣性。針對此類問題,若要確保信息的完整性,就需要根據的差異設計不同的卷積定義和設計,這無疑限制了GCN 在相關領域的適用性;若通過預處理等實現數據一致性表征,又不可避免造成信息損失,影響后續任務性能。因此,如何有效構建自適應的GCN,使得網絡具備處理不同輸入數據的能力,同時盡可能保留原始數據的拓撲結構信息,是GCN 在圖像識別領域中亟待解決的問題之一。
(2)GCN 的輕量化。圖像數據的大小通常比非結構化數據大得多,因此GCN 在圖像識別任務中需要處理的圖像數據的數量和規模較大;同時,圖像數據通常具有高度的局部性和復雜性,卷積核需要具有更大的感受野和更復雜的結構才能捕捉到圖像中的更多信息。上述問題導致網絡計算和存儲需求的顯著增加,限制了GCN在大規模圖像數據上的應用。隨著深度學習和人工智能技術的發展,模型輕量化成為必然趨勢。通過改進模型體系結構和優化算法,降低模型大小和計算復雜度,可以進一步使GCN 在大規模圖像數據上得到有效應用。因此,如何提高GCN的計算和存儲效率,以適應大規模圖像數據的處理需求,是一個重要的問題。
(3)GCN 與其他模型的有效結合。大部分現實生活中的圖像數據都包含拓撲結構信息和視覺信息。GCN 主要關注節點之間的連接關系,難以有效地捕捉到圖像中的細節信息,造成在圖像識別領域的性能有限。CNN等深度學習網絡提取的圖像視覺特征或預訓練獲取的語義特征等可以為GCN 提供額外信息,輔助GCN 更高效準確地完成相應任務。然而,GCN 只能處理圖結構數據,難以與規則網格上表示的結構化數據相結合。在多標簽識別任務中,如何將類別間的關系和圖像特征有效融合仍具挑戰;在基于骨架的動作識別中,節點間的關聯關系與動作時序信息的結合同樣存在難點;在高光譜圖像分類任務中,如何高效利用數量龐大的像素信息仍是研究的重難點。因此,在圖像識別領域,如何將各類模型有效結合,發揮各自的優勢,更加高效準確地完成特征提取將是值得學者們繼續研究的問題。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
