多尺度注意力引導(dǎo)的全景分割網(wǎng)絡(luò)
2023-11-27 05:35:26瞿紹軍
計(jì)算機(jī)工程與應(yīng)用 2023年22期
付 都,瞿紹軍,付 亞
1.湖南師范大學(xué) 信息科學(xué)與工程學(xué)院,長沙410081
2.國網(wǎng)湖南超高壓變電公司,長沙410004
圖像分割是計(jì)算機(jī)視覺領(lǐng)域一個(gè)基礎(chǔ)且非常重要的研究方向,對圖像分割算法的研究至今已有幾十年的歷史。早期的圖像分割通常是根據(jù)圖像的紋理、顏色等特征來進(jìn)行區(qū)域劃分,此類技術(shù)單一,使得計(jì)算機(jī)處理分割任務(wù)時(shí)常常遇到各種困難且分割準(zhǔn)確率也不高。隨著深度學(xué)習(xí)的蓬勃發(fā)展和廣泛應(yīng)用,圖像分割也發(fā)展到新的階段,實(shí)現(xiàn)了更高的準(zhǔn)確率。全景分割(panoptic segmentation)作為圖像分割的一個(gè)重要分支任務(wù),于2018 年由Facebook 人工智能實(shí)驗(yàn)室的Kirillov 等[1]提出,該任務(wù)實(shí)現(xiàn)了傳統(tǒng)意義上相互獨(dú)立的語義分割(semantic segmentation)和實(shí)例分割(instance segmentation)的統(tǒng)一。語義分割將圖像劃分成具有特定語義信息的區(qū)域塊,并將相應(yīng)的語義類別標(biāo)簽分配給這些區(qū)域塊,最后得到所有像素都被語義標(biāo)注的分割圖像[2];實(shí)例分割首先從圖像中檢測出不同類別的實(shí)例,然后在此基礎(chǔ)上結(jié)合目標(biāo)檢測在同一類別中進(jìn)行逐像素標(biāo)記以區(qū)分出單個(gè)實(shí)例對象,并給每個(gè)個(gè)體分配相應(yīng)的實(shí)例ID[3];全景分割則是基于這兩大類分割任務(wù),首先將圖像按其語義類別分成不同的區(qū)域塊并分配語義標(biāo)簽,然后在此基礎(chǔ)上區(qū)分出每個(gè)物體實(shí)例并標(biāo)記實(shí)例ID,最后將具有相同語義標(biāo)簽和實(shí)例ID的像素判定為屬于同一個(gè)目標(biāo),即實(shí)現(xiàn)了對圖像背景語義信息和前景實(shí)例對象的同時(shí)處理。
近幾年,全景分割任務(wù)因其新穎性及具有挑戰(zhàn)性,吸引了眾多研究者對其進(jìn)行探索,并取得了很大進(jìn)展。通過采用共享的主干網(wǎng)絡(luò)實(shí)現(xiàn)了架構(gòu)的統(tǒng)一,提高了資源利用率,但對于重疊的實(shí)例掩碼、重復(fù)的像素級語義預(yù)測等沖突問題,研究者們雖然已通過預(yù)測的置信度分?jǐn)?shù)[1]、類別之間的成對關(guān)系[4]來解決重疊的實(shí)例掩碼,或者是開發(fā)全景頭(panoptic head)等高級模塊來融合語義和實(shí)例分割結(jié)果[4-5]等,這些操作在一定程度上緩和了上述沖突問題,但由此也產(chǎn)生了一些額外的預(yù)測、后處理以及融合操作,這在一定程度上會減慢整個(gè)系統(tǒng)。因此研究者們開始致力于設(shè)計(jì)一個(gè)真正意義上的統(tǒng)一算法,使固定形狀的things實(shí)例對象和未定形的stuff區(qū)域能以相同的方式進(jìn)行分割預(yù)測,在一定程度上解決這個(gè)問題。基于此,Li等[6]提出了全卷積全景分割網(wǎng)絡(luò)(fully convolutional networks for panoptic segmentation,PanopticFCN),通過將每個(gè)things 實(shí)例對象或stuff 類別編碼為特定的卷積核權(quán)重,并與得到的高分辨率特征直接卷積結(jié)合來產(chǎn)生全景預(yù)測。PanopticFCN的關(guān)鍵思想是在完全卷積的管道中用生成的卷積核權(quán)重均勻地表示和預(yù)測things 和stuff,其在性能和效率方面也都優(yōu)于以往大多全景分割算法,但對于全景分割任務(wù)中前景實(shí)例對象特別是遠(yuǎn)距離小目標(biāo)分割精度不高的現(xiàn)象,仍無法有效改善,背景未定形區(qū)域的分割效果也有待進(jìn)一步優(yōu)化。
針對全景分割模型中存在的上述問題,本文以PanopticFCN 為基準(zhǔn)來進(jìn)行改進(jìn)優(yōu)化,提出一種多尺度注意力引導(dǎo)的全景分割網(wǎng)絡(luò)(multiscale attention-guided panoptic segmentation network,MAPSNet),主要包括如下兩個(gè)改進(jìn)工作:
(1)多數(shù)圖像分割任務(wù)均采用殘差網(wǎng)絡(luò)(ResNet)[7]作為主干網(wǎng)來進(jìn)行特征提取,然后添加特征金字塔網(wǎng)絡(luò)(feature pyramid networks,F(xiàn)PN)[8],通過自頂向下上采樣操作和橫向連接,將高層強(qiáng)語義信息融合到低層特征中,以獲取豐富的多尺度特征。但高層特征中仍缺少低層細(xì)節(jié)信息,因此參照自頂向下路徑的操作,添加一條自底向上的輔助路徑,通過逐級下采樣操作和橫向連接,將低層細(xì)節(jié)信息融合到高層特征中,獲取圖像豐富的細(xì)節(jié)信息,進(jìn)一步增強(qiáng)主干網(wǎng)絡(luò)的圖像特征獲取能力。
(2)在卷積核權(quán)重生成過程中,提出一種注意力模塊ASAM,通過聚合多尺度空間特征信息和關(guān)注通道特征信息來引導(dǎo)卷積核權(quán)重的生成,提高匹配準(zhǔn)確率,進(jìn)而提高實(shí)例級分割準(zhǔn)確率及全景分割預(yù)測質(zhì)量。
1 相關(guān)工作
早期的全景分割算法主要遵循文獻(xiàn)[1]的處理方法,將已有的語義分割和實(shí)例分割算法中性能表現(xiàn)較好的獨(dú)立模型進(jìn)行組合,然后通過融合處理來得到全景分割結(jié)果。雖然這類算法在全景分割性能上也均獲得了不同程度的提升,但因使用了完全不同的網(wǎng)絡(luò)模型,在實(shí)例分割和語義分割之間幾乎不執(zhí)行任何共享計(jì)算,使得整體模型計(jì)算復(fù)雜,計(jì)算量和占用內(nèi)存也較大。Xiong等[4]提出了一個(gè)統(tǒng)一的全景分割網(wǎng)絡(luò)(unified panoptic segmentation network,UPSNet)。該模型以特征金字塔網(wǎng)絡(luò)[8]作為共享主干來提取圖像豐富的多尺度特征,采用了基于可變形卷積[9]的語義分割頭和Mask R-CNN[10]風(fēng)格的實(shí)例分割頭,最后還引入了一個(gè)無參數(shù)的全景頭,通過其融合兩個(gè)子任務(wù)來解決全景分割任務(wù)。UPSNet以更快的推理速度實(shí)現(xiàn)了性能的提升,但其未充分有效地利用高分辨率特征圖中的細(xì)節(jié)信息,對圖像中的小目標(biāo)分割效果不是很理想。特征金字塔全景分割網(wǎng)絡(luò)(panoptic feature pyramid networks,PanopticFPN)[5]、注意力引導(dǎo)的統(tǒng)一全景分割網(wǎng)絡(luò)(attention-guided unified network for panoptic segmentation,AUNet)[11]以及輕量級全景分割網(wǎng)絡(luò)(lightweight panoptic segmentation network,LPSNet)[12]等也均是采用了類似分支結(jié)構(gòu)來實(shí)現(xiàn)全景分割任務(wù),通過增強(qiáng)主干網(wǎng)、添加注意力機(jī)制以及建立分支子任務(wù)之間的聯(lián)系等各種方法來進(jìn)一步提高全景分割性能。但這些方法都忽略了目標(biāo)位置的重要性。針對此問題,Chen等[13]提出了空間流(SpatialFlow),通過構(gòu)建能在各個(gè)子任務(wù)中進(jìn)行傳遞的多級空間信息流,將圖像中對象的空間位置信息應(yīng)用到整體模型中,依次增強(qiáng)了網(wǎng)絡(luò)提取對象位置細(xì)節(jié)的能力,提升了網(wǎng)絡(luò)理解輸入圖像的能力,使模型能夠?qū)崿F(xiàn)空間位置感知。Cheng等基于DeepLabv3plus[14]設(shè)計(jì)了一個(gè)簡單、快速的全景分割網(wǎng)絡(luò)Panoptic-DeepLab[15]。它采用了特定于語義和實(shí)例分割的雙空洞空間金字塔池化(dual-atrous spatial pyramid pooling,Dual-ASPP)和雙解碼器(Dualdecoder)結(jié)構(gòu)來進(jìn)行分割預(yù)測,具有較快的推理速度,同時(shí)還可以實(shí)現(xiàn)與其他方法相當(dāng)?shù)男阅堋7纸M卷積全景分割網(wǎng)絡(luò)(grouped convolutional panoptic segmentation network,GCPSNet)[16]在此基礎(chǔ)上進(jìn)一步對Dual-ASPP 結(jié)構(gòu)中空洞卷積的擴(kuò)張率進(jìn)行調(diào)整,以此來提高模型對特定分割任務(wù)的適應(yīng)性,并對Dual-decoder結(jié)構(gòu)進(jìn)行分組整合以實(shí)現(xiàn)單路分組解碼,這樣不僅簡化了網(wǎng)絡(luò)模型結(jié)構(gòu),降低了解碼網(wǎng)絡(luò)參數(shù)量,還不會影響圖像的語義和實(shí)例特征表達(dá)。Axial-DeepLab[17]則引入了自我注意的思想,提出將經(jīng)典的二維自我注意力沿著高度軸和寬度軸分解為兩個(gè)一維的自我注意力,這樣處理不僅降低了計(jì)算復(fù)雜度,還能夠在更大甚至是全局區(qū)域內(nèi)進(jìn)行注意,將分解后的自我注意力與添加了相對位置編碼的位置敏感型自我注意進(jìn)行融合,產(chǎn)生的位置敏感的軸對稱注意力(Axial-attention)大大減少了全景分割模型的參數(shù)量和計(jì)算復(fù)雜度。
全景分割任務(wù)盡管已提出了各種有效的改進(jìn)算法,但仍存在計(jì)算效率和精度不足的問題,Mohan 等[18]在EfficientNet[19]的基礎(chǔ)上提出了高效全景分割(efficient panoptic segmentation,EfficientPS)算法,該算法采用雙向FPN構(gòu)建了一種更強(qiáng)大的共享主干網(wǎng)絡(luò),能夠?qū)φZ義豐富的多尺度特征進(jìn)行有效的編碼和融合,并以端到端方式聯(lián)合優(yōu)化整個(gè)網(wǎng)絡(luò),得到了更高效、更快速的全景分割結(jié)果。
目前,學(xué)者們對于全景分割算法的研究,已涵蓋主干網(wǎng)絡(luò)、特定任務(wù)特征細(xì)化處理以及計(jì)算優(yōu)化等各個(gè)方面,提出了各種類型的分割算法,全景分割任務(wù)的綜合性能也在不斷提升。但通過研究分析發(fā)現(xiàn),不管是PanopticFCN 還是上述這些分支式全景分割算法,其在Cityscapes 數(shù)據(jù)集上均存在前景實(shí)例對象分割不夠準(zhǔn)確,實(shí)例級全景分割質(zhì)量不高的現(xiàn)象。針對這些問題,本文提出一種基于PanopticFCN 改進(jìn)的全景分割網(wǎng)絡(luò)。首先,對特征提取網(wǎng)絡(luò)進(jìn)行增強(qiáng)處理;其次,對卷積核權(quán)重生成模塊進(jìn)行優(yōu)化,通過提出一種注意力模塊提高卷積核權(quán)重的匹配準(zhǔn)確率,有效提高了實(shí)例級分割準(zhǔn)確率,進(jìn)而提升了全景分割的綜合性能。
2 多尺度注意力引導(dǎo)的全景分割網(wǎng)絡(luò)
2.1 網(wǎng)絡(luò)整體結(jié)構(gòu)
PanopticFCN 是一個(gè)端到端的圖像全景分割網(wǎng)絡(luò),它實(shí)現(xiàn)了以統(tǒng)一的方式來表示和預(yù)測前景實(shí)例對象和背景未定形區(qū)域。本文遵循該網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行改進(jìn)優(yōu)化,設(shè)計(jì)了多尺度注意力引導(dǎo)的全景分割網(wǎng)絡(luò)MAPSNet。如圖1 所示,MAPSNet 模型主要由四部分組成,分別是基于殘差網(wǎng)絡(luò)和特征金字塔網(wǎng)絡(luò)優(yōu)化的特征提取主干網(wǎng)、特征編碼器、卷積核生成器以及卷積核融合模塊。
MAPSNet 分別采用ResNet-50 和ResNet-101 作為主干網(wǎng)絡(luò),因?yàn)轫攲犹卣魉奶卣餍畔⑤^為單一,為了獲取豐富的多尺度特征,在ResNet 之后采用FPN來聚合多尺度信息,并得到多個(gè)不同尺度的獨(dú)立特征圖,可為后續(xù)多階段迭代處理提供不同特征層上豐富的特征圖[8]。為了進(jìn)一步增強(qiáng)主干網(wǎng)絡(luò)的特征提取能力,本文額外添加一條自底向上的優(yōu)化輔助路徑。關(guān)于此路徑將在2.2 節(jié)詳細(xì)介紹;在卷積核生成器中,位置頭(Position Head)用于同時(shí)預(yù)測實(shí)例對象和無定形區(qū)域的定位和分類。核心頭(Kernel Head)則是根據(jù)對象中心和無定形區(qū)域的位置來產(chǎn)生相應(yīng)的卷積核權(quán)重,為了提高所生成卷積核權(quán)重的準(zhǔn)確度,借鑒DeepLabv3plus中ASPP[14]思想、擠壓和激勵網(wǎng)絡(luò)(squeeze-and-excitation networks,SENet)[20]中通道注意力思想,提出了引導(dǎo)卷積核權(quán)重生成的注意力模塊(ASPP-SE attention module,ASAM)。關(guān)于ASAM 將在第2.3 節(jié)詳細(xì)介紹。對于特征編碼器和卷積核融合模塊則遵循PanopticFCN 中的設(shè)置。首先通過語義FPN[5],將主干網(wǎng)輸出的多個(gè)特征圖P3~P5 上采樣恢復(fù)至P2 的大小,再通過相加進(jìn)行融合,生成高分辨率特征Fh,然后特征編碼器應(yīng)用Coord[21]策略對高分辨率特征Fh編碼位置線索并生成編碼特征Fe,卷積核融合模塊則將生成的多個(gè)階段的重復(fù)卷積核權(quán)重進(jìn)行合并得到K,最后將卷積核權(quán)重K與編碼特征Fe進(jìn)行卷積操作即可得到最終的全景預(yù)測結(jié)果。
2.2 增強(qiáng)的特征提取主干網(wǎng)
MAPSNet的主干網(wǎng)基于殘差網(wǎng)絡(luò)和特征金字塔網(wǎng)絡(luò)進(jìn)行擴(kuò)展優(yōu)化來提取豐富的多尺度特征,其結(jié)構(gòu)如圖2所示。圖中藍(lán)色框中主要采用ResNet-50和ResNet-101中相應(yīng)模塊,其詳細(xì)結(jié)構(gòu)如表1所示,輸入圖像首先經(jīng)過Stem 模塊,即步長為2 的7×7 卷積,以及3×3 的最大池化層,輸出通道數(shù)為64;然后依次經(jīng)過多個(gè)Res 模塊獲取多個(gè)階段特征,Res具體結(jié)構(gòu)如圖3所示(以Res2為例),由一個(gè)卷積塊ConvBlock和n-1 個(gè)基本塊Base-Block(Res2中為2個(gè))組成,每個(gè)塊都包含殘差結(jié)構(gòu),其中卷積塊ConvBlock 通過Shortcut 增加維度。基本塊BaseBlock 則不改變維度,表1 中矩陣外的“ ×n”(Res2為“×3”)即表示每個(gè)Res結(jié)構(gòu)中ConvBlock和BaseBlock的數(shù)量和。
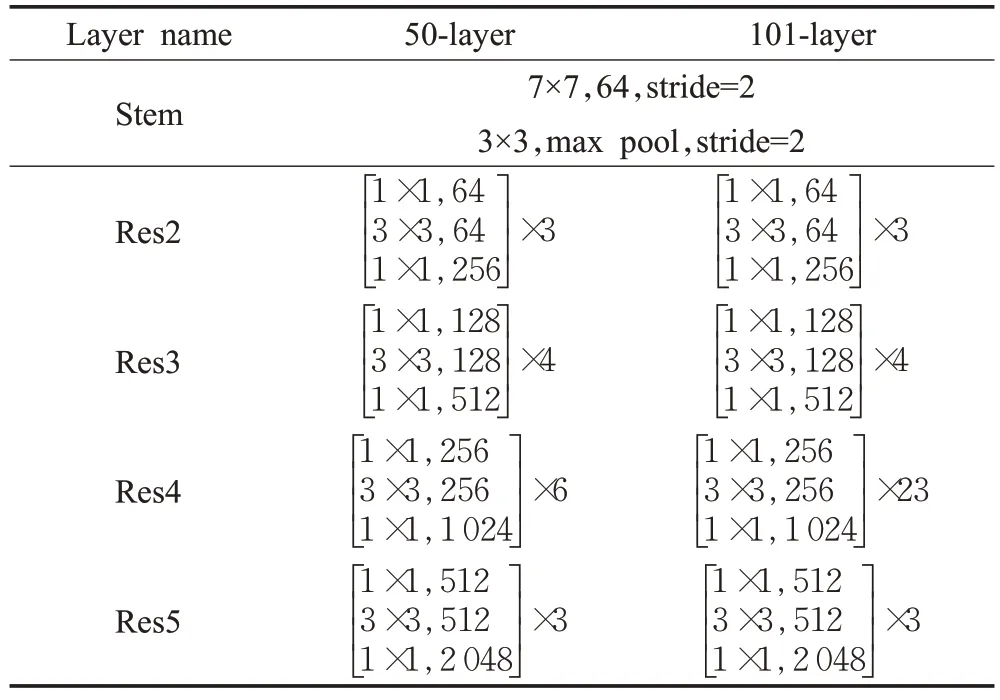
表1 ResNet-50和ResNet-101的結(jié)構(gòu)Table 1 Structure of ResNet-50 and ResNet-101

圖2 增強(qiáng)的特征提取主干網(wǎng)Fig.2 Enhanced feature extraction backbone
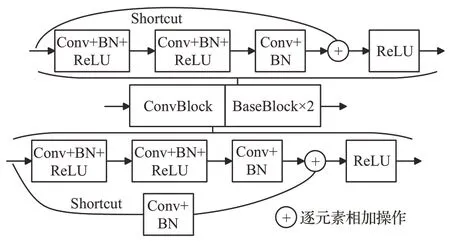
圖3 主干網(wǎng)中的Res模塊結(jié)構(gòu)Fig.3 Structure of Res module in backbone
由殘差網(wǎng)絡(luò)產(chǎn)生的高層特征語義強(qiáng)但分辨率低,特征金字塔網(wǎng)絡(luò)通過自頂向下進(jìn)行上采樣操作,然后將上采樣后得到的特征與橫向連接中相鄰低層高分辨率特征依次求和,將高層強(qiáng)語義信息附加到各低層特征中,生成了高分辨率且語義強(qiáng)的多尺度特征表示。FPN 以一種比較簡單的方法指出了不同層之間特征融合的重要性,但對于各層特征信息的利用仍不夠充分,高層特征中缺少低層特征豐富的細(xì)節(jié)信息。路徑聚合網(wǎng)絡(luò)(path aggregation network,PANet)[22]、NAS-FPN[23]、BiFPN[24]以及Bi-Yolov3-tiny[25]等研究遵循FPN的思想,嘗試了各種融合方法來充分利用各層特征中包含的豐富圖像信息,借鑒這些思想,針對FPN中存在的不足,通過在原始FPN 自頂向下操作的基礎(chǔ)上添加一條自底向上輔助路徑,將低層細(xì)節(jié)信息附加到各高層特征中,來生成包含豐富細(xì)節(jié)信息的多尺度特征表示,進(jìn)一步實(shí)現(xiàn)特征增強(qiáng)。如圖4 所示,將原始圖像(a)分別輸入到FPN 主干網(wǎng)和改進(jìn)后的主干網(wǎng)中進(jìn)行處理,并將高層特征圖(P5)提取出來進(jìn)行可視化對比。從圖中可以看出,后者得到的效果(c)相比于前者效果(b)獲取到了更多的特征信息,所包含的細(xì)節(jié)信息也明顯要更加豐富。其結(jié)構(gòu)如圖2中紅色框所示,具體操作類似于自頂向下模塊,不同之處在于與橫向連接進(jìn)行聚合時(shí),采用求均值而不是求和的方式來得到與原始FPN各階段輸出同尺度的特征,最后再將兩者求均值得到具備各種豐富信息的多尺度特征,即低層特征具有了強(qiáng)語義信息,高層特征也包含了豐富的細(xì)節(jié)信息。
2.3 引導(dǎo)卷積核權(quán)重生成的注意力模塊
近幾年,注意力機(jī)制被廣泛應(yīng)用于圖像分割、自然語言處理、圖像識別等各種深度學(xué)習(xí)任務(wù)中,其主要思想是借鑒人類視覺系統(tǒng)的選擇性這一特點(diǎn),對卷積神經(jīng)網(wǎng)絡(luò)中的特征圖進(jìn)行差異性處理,從而能將有限的計(jì)算資源重點(diǎn)投入到模型的主要任務(wù)中,并能根據(jù)任務(wù)結(jié)果來反向指導(dǎo)特征圖的權(quán)重更新,達(dá)到高效快速地完成相應(yīng)任務(wù)的目的[26-27]。
根據(jù)注意機(jī)制的這一特性,并結(jié)合空洞空間金字塔池化ASPP 和SENet 中通道注意力的思想,提出在卷積核權(quán)重生成過程中建立新的注意力模塊ASAM,來引導(dǎo)生成準(zhǔn)確度更高的卷積核權(quán)重。其詳細(xì)結(jié)構(gòu)如圖5 所示,ASAM通過利用不同擴(kuò)張率的空洞卷積對輸入特征進(jìn)行多尺度并行采樣處理,以捕捉圖像多個(gè)不同尺度的空間上下文信息,將其聚合可有效獲取圖像的全局特征信息,增強(qiáng)像素之間的依賴性,其特征圖可視化結(jié)果如圖6(c)所示,相比圖(b)PanopticFCN中直接通過3個(gè)3×3卷積操作而不進(jìn)行多尺度處理的方式,所得圖像整體效果明顯更佳;然后在此基礎(chǔ)上再進(jìn)行擠壓操作,將全局信息壓縮到各通道中進(jìn)行處理,最后通過激活函數(shù)得到代表每組特征圖重要性程度的權(quán)重向量,并利用此向量來激勵特征圖,引導(dǎo)權(quán)重不斷向著有利于任務(wù)的方向更新[27],縮小對任務(wù)來說不重要的特征的權(quán)重,同時(shí)放大對于任務(wù)更加重要的特征的權(quán)重,將單個(gè)階段處理后的256個(gè)通道的權(quán)重提取出來進(jìn)行融合,然后作用于圖像并進(jìn)行可視化,得到如圖6(d)所示效果。通道注意力思想的引入,使網(wǎng)絡(luò)關(guān)注到圖像不同通道之間的關(guān)系,并學(xué)習(xí)不同通道的重要程度,進(jìn)一步加強(qiáng)對圖像局部特征信息的捕獲。
ASAM模塊的具體操作如式(1)~(3)所示:
式(1)中輸入Xi指的是主干網(wǎng)中輸出的獨(dú)立多尺度特征圖(P3~P7)。Concat表示級聯(lián)拼接操作。f1表示1×1卷積和組標(biāo)準(zhǔn)化(group normalization,GN)操作,采用1×1 卷積是為了防止空洞率過大而造成卷積核參數(shù)不能完全利用[2],而組標(biāo)準(zhǔn)化也是一種深度學(xué)習(xí)標(biāo)準(zhǔn)化方式,解決了批標(biāo)準(zhǔn)化(batch normalization,BN)操作對批次大小依賴的影響,因此可以替代BN。f2表示采用不同擴(kuò)張率的空洞卷積來擴(kuò)大圖像感受野,通過實(shí)驗(yàn)驗(yàn)證,當(dāng)擴(kuò)張率取值為(12,24,36)時(shí)取得的綜合效果最佳,具體實(shí)驗(yàn)細(xì)節(jié)將在第3.3節(jié)中詳細(xì)介紹。P表示全局平均池化操作(global average pooling)。式(2)和式(3)即是對拼接后的特征進(jìn)行具體通道注意操作。首先通過全局平均池化操作P對每張?zhí)卣鲌D進(jìn)行擠壓,得到一個(gè)具有特征圖上全局注意力信息的實(shí)數(shù),將得到的擠壓實(shí)數(shù)進(jìn)行組合,構(gòu)成每組特征圖的權(quán)重向量,將此向量依次通過全連接層fc1與ReLU 激活函數(shù)R,全連接層fc2與sigmoid激活函數(shù)S進(jìn)行歸一化處理;最后再利用Softmax激活函數(shù)即可得到代表特征圖重要性程度的向量。
3 實(shí)驗(yàn)
3.1 數(shù)據(jù)集和評估指標(biāo)
本文模型在實(shí)驗(yàn)時(shí)使用城市街道場景數(shù)據(jù)集Cityscapes,該數(shù)據(jù)集記錄了來自50 個(gè)世界不同城市的街道場景,擁有5 000張高質(zhì)量像素級標(biāo)注的圖像,被分為包含2 975張圖片的訓(xùn)練集、500張圖片的驗(yàn)證集以及1 525張圖片的測試集,包括地面類、車輛類、自然類、建筑類、天空類、小物體類、人類和道路標(biāo)志類等8 個(gè)大類,具有19 個(gè)類別的密集像素標(biāo)注[28],給研究者們提供了無人駕駛場景下的圖像分割數(shù)據(jù)。Cityscapes中每張圖像的分辨率均為1 024×2 048,為了更好地衡量模型對小目標(biāo)的有效性,基于各類目標(biāo)的尺寸,將pole、traffic light、traffic sign、person、rider、motorcycle、bicycle 等小于32×32像素的類別定義為小目標(biāo),所有其他12種類別均定義為大目標(biāo)[29-30]。
全景分割任務(wù)在提出的同時(shí),為了更好地衡量任務(wù)執(zhí)行的性能表現(xiàn),引入了全景質(zhì)量(panoptic quality,PQ)度量標(biāo)準(zhǔn)[1]。全景質(zhì)量能綜合衡量全景分割的關(guān)鍵性能特征,它以統(tǒng)一的方式對待所有的實(shí)例對象和未定形區(qū)域,其詳細(xì)計(jì)算方式如式(4)所示。
其中,IoU(p,g)是預(yù)測對象p和真值g之間的交并比(intersection over union)。交并比即檢測相應(yīng)物體準(zhǔn)確率的一個(gè)測量標(biāo)準(zhǔn),是對象類別分割問題的標(biāo)準(zhǔn)性能度量[31]。TP(true positive)表示正確匹配的區(qū)塊,即預(yù)測塊與真值標(biāo)注塊之間的IoU 達(dá)到閾值0.5 以上的區(qū)域。FP(false positive)和FN(false negative)則分別表示被模型判定為正值的負(fù)樣本和被判定為負(fù)值的正樣本,二者被添加到分母中以懲罰沒有正確匹配的部分。
如式(5)所示,為了更好地解釋分割結(jié)果,可將PQ分解為分割質(zhì)量(segmentation quality,SQ)和識別質(zhì)量(recognition quality,RQ),它可以看作是SQ和RQ的乘積,SQ 表示匹配后的預(yù)測塊與真值標(biāo)注塊之間的平均IoU,RQ則是用來計(jì)算全景分割中每個(gè)實(shí)例對象識別的準(zhǔn)確性[1]。但最終PQ 并不是簡單的組合語義和實(shí)例分割度量,而是針對每一類實(shí)例對象和未定形區(qū)域按照式(5)分別進(jìn)行計(jì)算,測量出單個(gè)類別的PQ、SQ 和RQ值,然后再將得到的所有類別的相應(yīng)值分別取均值,如式(6)所示,其中Nc為總共計(jì)算的類別數(shù),后續(xù)實(shí)驗(yàn)結(jié)果中的PQ、SQ 和RQ 值均為式(6)中的PQavg、SQavg、RQavg。
3.2 實(shí)驗(yàn)設(shè)置
本文實(shí)驗(yàn)基于PyTorch-1.6.0+CUDA-10.1框架實(shí)現(xiàn),由于Cityscapes 的訓(xùn)練圖像相對較少,使用在ImageNet數(shù)據(jù)集上預(yù)先訓(xùn)練的權(quán)重來對模型進(jìn)行初始化操作。首先對圖片進(jìn)行尺度裁剪等預(yù)處理操作,將大小調(diào)整為512×1 024 作為網(wǎng)絡(luò)的輸入,然后在兩張Tesla-T4 GPU上以8張圖像的批量大小來訓(xùn)練模型(每張GPU 4張圖像),在訓(xùn)練過程中采用焦點(diǎn)損失(focal loss)[32]優(yōu)化對象中心和未定形區(qū)的位置信息,如式(7)所示:
其中WDLoss 表示加權(quán)骰子損失函數(shù),Pj和分別表示分割預(yù)測結(jié)果和真實(shí)值;N表示全部實(shí)例對象和未定形區(qū)卷積核權(quán)重產(chǎn)生的實(shí)例預(yù)測數(shù)量。將兩者相結(jié)合作為網(wǎng)絡(luò)的損失函數(shù),如式(9)所示:
其中λpos和λseg為平衡因子,分別設(shè)為1.0和3.0來平衡位置損失和分割損失之間的權(quán)重。模型其他相關(guān)參數(shù)則根據(jù)實(shí)際訓(xùn)練情況遵循實(shí)驗(yàn)PanopticFCN 在Detectron2框架中的配置規(guī)律進(jìn)行調(diào)整。具體來說,將初始學(xué)習(xí)率設(shè)置為0.01,動量和權(quán)重衰減系數(shù)設(shè)置為0.9和1.0×10-4,然后進(jìn)行6.5×104次迭代訓(xùn)練。
3.3 實(shí)驗(yàn)定量分析
為了驗(yàn)證所添加的自底向上輔助路徑和引導(dǎo)卷積核生成的注意力模塊的有效性,比較MAPSNet 模型的改進(jìn)效果,保持使用相同的環(huán)境并設(shè)置相同的學(xué)習(xí)率、迭代次數(shù)等參數(shù),采用ResNet-50 作為網(wǎng)絡(luò)主干,在Cityscapes 數(shù)據(jù)集上進(jìn)行相關(guān)消融和對比實(shí)驗(yàn),結(jié)果如表2 所示。在單獨(dú)添加自底向上輔助路徑后,網(wǎng)絡(luò)的IoU 提高了約1 個(gè)百分點(diǎn),推理500 張圖像時(shí)的單張圖像平均計(jì)算時(shí)間也稍有降低,但全景分割質(zhì)量并未提升;而在單獨(dú)添加注意力模塊后,網(wǎng)絡(luò)的全景質(zhì)量提升了1.63個(gè)百分點(diǎn),IoU也稍有提升,但效果不太明顯,其平均計(jì)算時(shí)間有所損耗;綜合這兩個(gè)模塊的優(yōu)勢和不足,同時(shí)將其添加到網(wǎng)絡(luò)中,如表2中第2行和第5行所示,全景質(zhì)量提高了1.94 個(gè)百分點(diǎn),IoU 也提高了1.13個(gè)百分點(diǎn),其單張圖像的平均計(jì)算時(shí)間也和基準(zhǔn)網(wǎng)絡(luò)相當(dāng),模型的綜合性能達(dá)到最佳。此外,MAPSNet中的小物體如交通燈(traffic light)和摩托車(motorcycle)的分割準(zhǔn)確率顯著提高了4.4個(gè)百分點(diǎn)和8.3個(gè)百分點(diǎn),對于大面積的未定形區(qū)域如墻體(wall)提高了8.8 個(gè)百分點(diǎn),道路、圍欄等其他類別也稍有提升,具體各類別的準(zhǔn)確率如表3 所示。MAPSNet 在犧牲少量參數(shù)量和內(nèi)存的輕微代價(jià)下,實(shí)例級分割質(zhì)量顯著提高了2.74個(gè)百分點(diǎn)(表4 中第五、第六行)。綜合來說MAPSNet 的整體效果明顯優(yōu)于PanopticFCN,證明所提模型可以更好地提升圖像前景實(shí)例、背景未定形區(qū)域的分割準(zhǔn)確率乃至全景分割綜合性能。
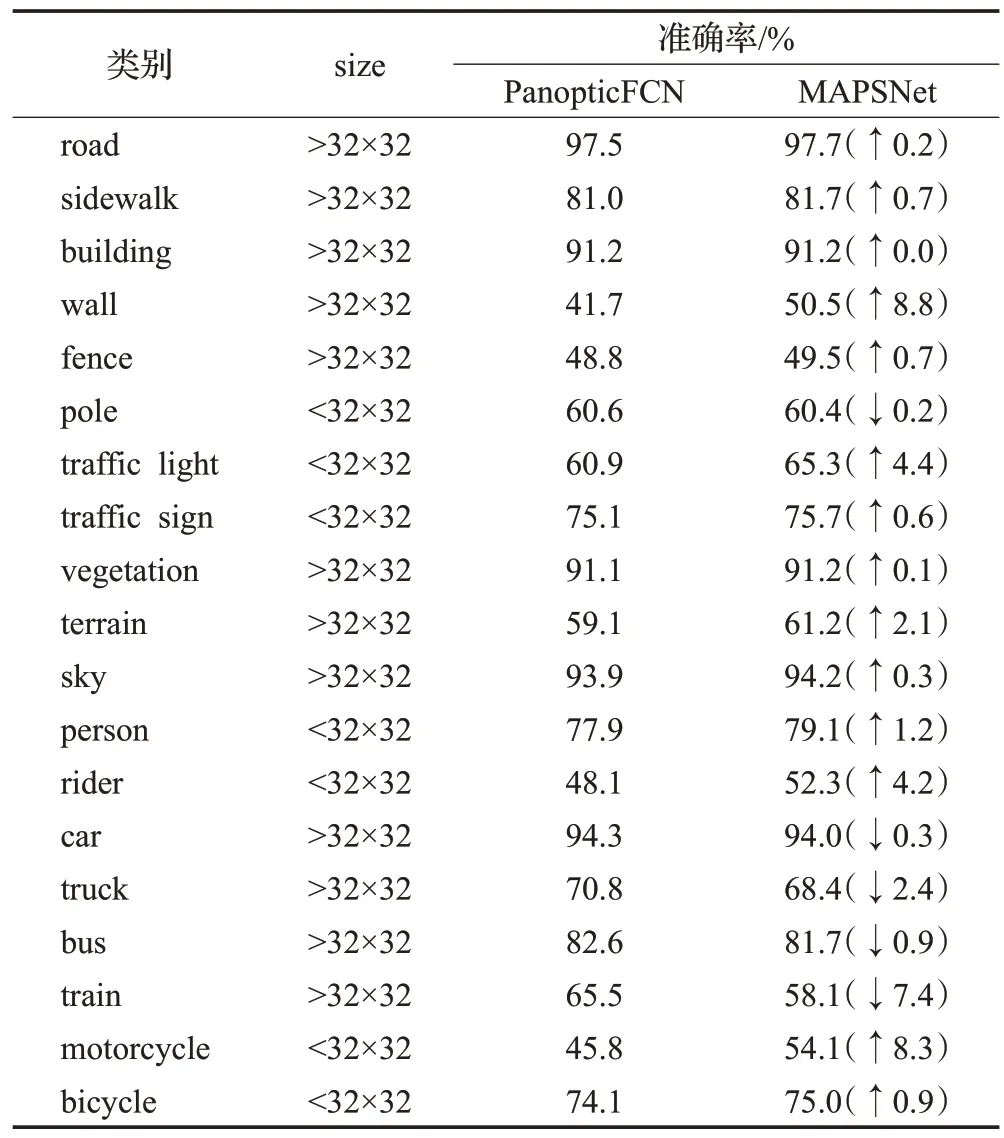
表3 Cityscapes數(shù)據(jù)集上各個(gè)類別的準(zhǔn)確率Table 3 Accuracy for each category on Cityscapes dataset
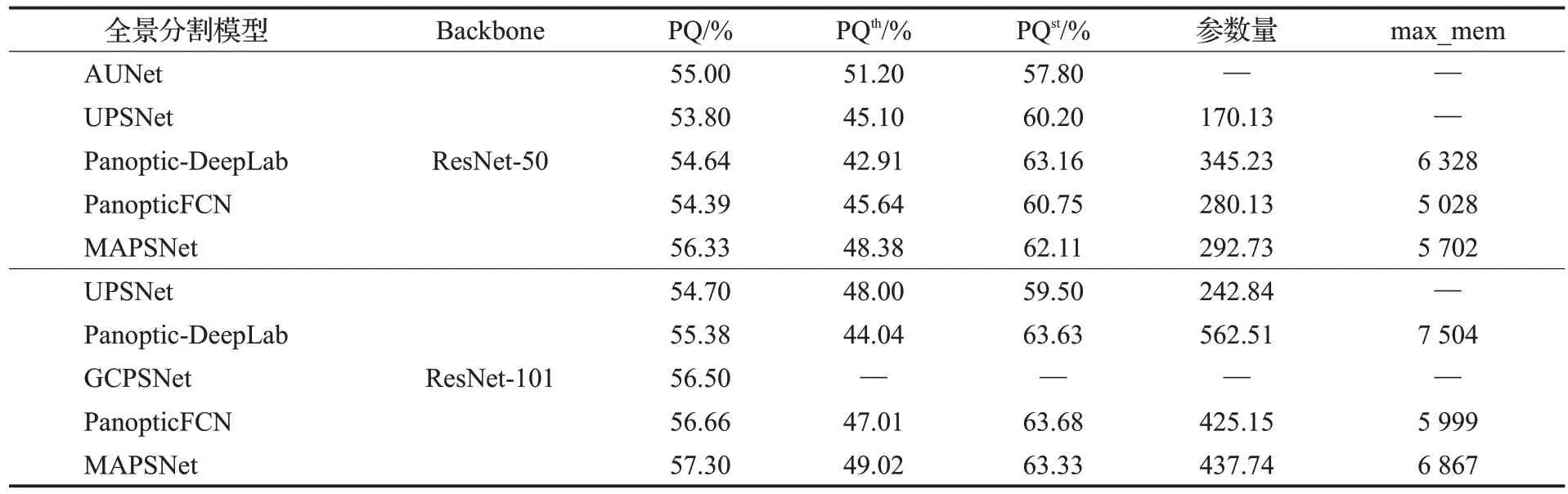
表4 MAPSNet與其他全景分割模型的實(shí)驗(yàn)對比Table 4 Experimental comparison between MAPSNet and other panoptic segmentation models
在相同的實(shí)驗(yàn)環(huán)境及配置下,將MAPSNet 模型與其他以ResNet-50和ResNet-101為主干的全景分割模型進(jìn)行對比,如表4所示。MAPSNet得到的全景分割性能不僅要優(yōu)于PanopticFCN,與UPSNet 相比,全景質(zhì)量分別提高2.53 個(gè)百分點(diǎn)和2.6 個(gè)百分點(diǎn),對比Panoptic-DeepLab整體效果則提升更多,在參數(shù)量和內(nèi)存都更低的情況下全景質(zhì)量也還分別高出1.69 個(gè)百分點(diǎn)和1.92個(gè)百分點(diǎn),即使與AUNet 等在更好的硬件環(huán)境下(8 個(gè)GPU)訓(xùn)練的網(wǎng)絡(luò)相比也能達(dá)到相當(dāng)性能水平。
ASAM 中使用了不同擴(kuò)張率的空洞卷積的級聯(lián)。空洞卷積是指在卷積層中通過引入擴(kuò)張率來增加處理數(shù)據(jù)時(shí)各值之間的間距。原始普通卷積如圖7(a)所示,擴(kuò)張率為3 和6 的空洞卷積分別如圖7(b)(c)所示。空洞卷積能夠擴(kuò)大感受野以減少圖像冗余信息,通過設(shè)置多個(gè)不同擴(kuò)張率的空洞卷積,可以獲得更加豐富,精度更高的多尺度信息。考慮到不同擴(kuò)張率所達(dá)到的效果不同,對ASAM中采用不同擴(kuò)張率組合的空洞卷積進(jìn)行對比實(shí)驗(yàn),結(jié)果如表5所示。隨著空洞卷積擴(kuò)張率的整體增大,全景質(zhì)量也不斷提升,表明通過空洞卷積增大感受野對于特征增強(qiáng)是有效的,其不僅很好地過濾了一定的特征冗余信息,同時(shí)對于有用特征信息的提取也在增多。但當(dāng)擴(kuò)張率增大到一定大小后,由于擴(kuò)張率的持續(xù)擴(kuò)大會損失信息的連續(xù)性,反而導(dǎo)致特征冗余信息的增多,因此其增強(qiáng)效果也開始變緩甚至降低[16]。如表5中最后一行數(shù)據(jù)所示,在擴(kuò)張率增大到(12,24,36)時(shí),識別質(zhì)量SQ 開始降低,未定形區(qū)域全景質(zhì)量PQst的增長也變緩,故在后續(xù)實(shí)驗(yàn)中即采用擴(kuò)張率為(12,24,36)的空洞卷積。
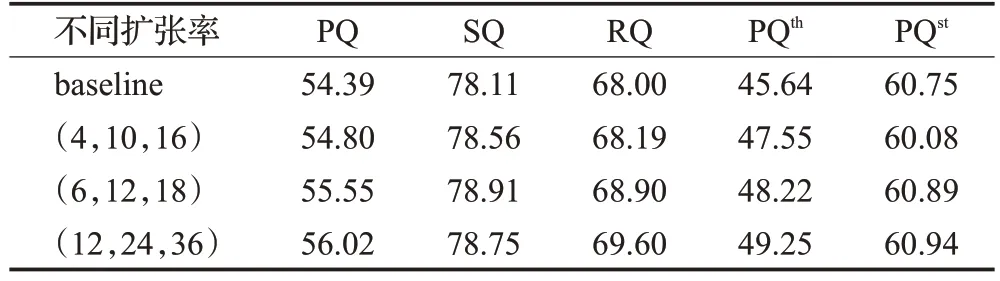
表5 ASAM中采用不同擴(kuò)張率的實(shí)驗(yàn)對比Table 5 Experimental comparison of different dilation rates in ASAM 單位:%
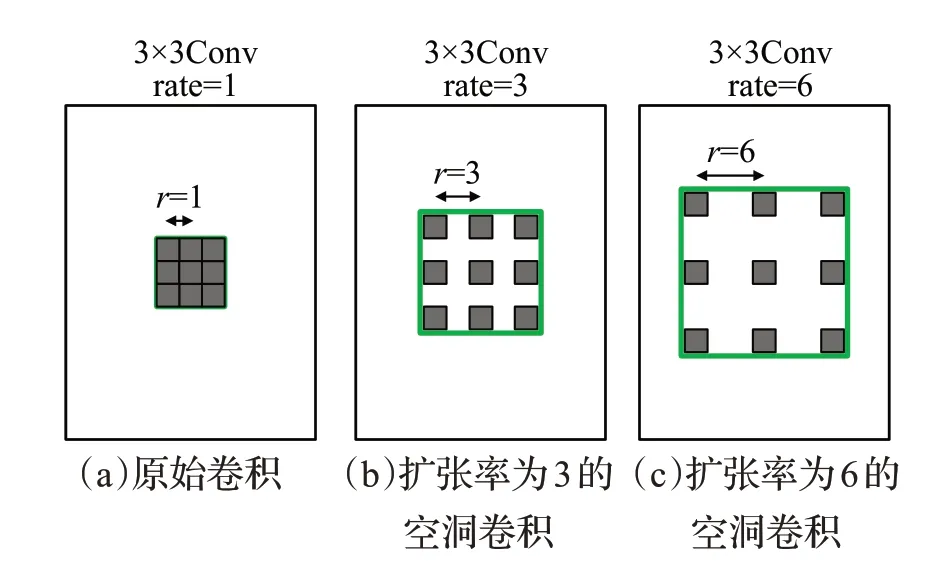
圖7 不同擴(kuò)張率的空洞卷積對比Fig.7 Comparison of atrous convolutions with different dilation rates
對于第2.2節(jié)介紹到的自底向上輔助路徑采用的聚合方式,為了比較不同聚合方式對于網(wǎng)絡(luò)模型實(shí)際效果的影響,分別采用求和及求均值的方式來進(jìn)行實(shí)驗(yàn)對比驗(yàn)證,結(jié)果如表6 所示。不難看出,在采用求均值的聚合方式時(shí),模型整體效果更佳。
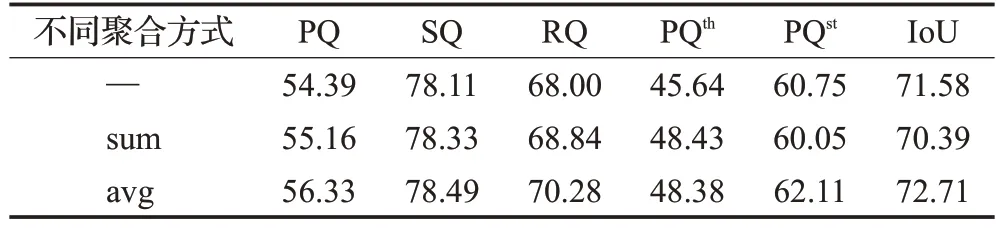
表6 輔助路徑中不同聚合方式實(shí)驗(yàn)對比Table 6 Experimental comparison of different aggregation methods in auxiliary path 單位:%
3.4 實(shí)驗(yàn)定性分析
圖8 直觀地展示了PanopticFCN 和MAPSNet 模型在Cityscapes數(shù)據(jù)集上的可視化全景分割效果對比。從圖中的紅色框標(biāo)記可以看出,圖(c)中PanopticFCN模型對于圖像中遠(yuǎn)距離的交通標(biāo)識、信號燈等小物體未能正確檢測出來,而在圖(d)中MAPSNet模型則將其準(zhǔn)確地識別并分割出來。此外,從第二行和第四行中的黃色框標(biāo)記可以看出,MAPSNet模型對于人、小型車等前景實(shí)例對象的識別分割準(zhǔn)確率更高,而對于背景未定形區(qū)域,從第一行和第三行中的黃色框標(biāo)記可以看出,MAPSNet模型在處理區(qū)域邊緣時(shí)相較PanopticFCN 要更清晰完整,但對于復(fù)雜的邊界仍然無法很好地進(jìn)行分割(如第一行和第四行中綠色框標(biāo)記所示)。因?yàn)橄噜彽南袼貙?yīng)感受野內(nèi)的圖像信息太過相似,若其均屬于目標(biāo)分割區(qū)域的內(nèi)部,那么是有利于分割的,但若相鄰像素剛好位于目標(biāo)分割區(qū)域的邊界上,則會導(dǎo)致邊緣分割的不準(zhǔn)確問題。目前針對此問題采用的主要方法為對網(wǎng)絡(luò)輸出的分割邊界增加額外的損失,或在網(wǎng)絡(luò)中添加邊緣檢測子任務(wù)以進(jìn)行精細(xì)處理。后續(xù)將對邊緣檢測方法進(jìn)行進(jìn)一步深入研究,并在當(dāng)前研究的基礎(chǔ)上進(jìn)一步提出相應(yīng)詳細(xì)的改進(jìn)方法。
綜上所述,MAPSNet相比PanopticFCN可以更好地增強(qiáng)全景分割中實(shí)例對象的分割效果,且同時(shí)不會影響甚至能提高圖像背景未定形區(qū)域的分割質(zhì)量,進(jìn)而提升全景分割綜合性能。
4 結(jié)束語
針對全卷積全景分割網(wǎng)絡(luò)在Cityscapes數(shù)據(jù)集上前景實(shí)例對象分割準(zhǔn)確率不高的問題,本文提出了一種改進(jìn)的全景分割模型,通過在主干網(wǎng)絡(luò)中融合添加一條自底向上的輔助路徑,增強(qiáng)了網(wǎng)絡(luò)的特征提取能力,豐富了多尺度特征。同時(shí)還提出了一種引導(dǎo)卷積核生成的注意力模塊,在不影響圖像背景未定形區(qū)域分割質(zhì)量的情況下,提高了前景實(shí)例尤其是遠(yuǎn)距離小物體的分割準(zhǔn)確率,進(jìn)而提升了全景分割綜合性能。實(shí)驗(yàn)結(jié)果表明,在相同的環(huán)境配置下,相較于基準(zhǔn)全景分割網(wǎng)絡(luò)模型PanoptiFCN,本文所提出的多尺度注意力引導(dǎo)的全景分割網(wǎng)絡(luò),在一定程度上有效提高了模型的實(shí)例級全景分割質(zhì)量以及綜合全景質(zhì)量。但本文模型還存在一定的不足,對于背景未定形區(qū)域,大部分類別的提升效果甚微,且對于復(fù)雜的邊界仍然無法很好地進(jìn)行分割。未來將進(jìn)一步研究改善這些問題,并在保證分割質(zhì)量的同時(shí)進(jìn)一步提高分割效率,簡化模型的復(fù)雜度,增強(qiáng)模型的實(shí)時(shí)性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
