改進SSD特征融合的目標檢測算法研究
2023-11-27 05:35:20葛海波黃朝鋒
計算機工程與應用 2023年22期
葛海波,李 強,周 婷,黃朝鋒
西安郵電大學 電子工程學院,西安710121
隨著計算機視覺的快速發展,目標檢測越來越受到關注。自從DNN(deep neural networks)[1]被引入以來,在目標檢測上比傳統方法具有更高的魯棒性和準確性。近年來,相繼出現了多種基于深度學習的目標檢測算法,如Faster R-CNN(faster region-based convolutional neural network)[2]、SSD(single shot multibox detector)[3]、DSSD(deconvolutional SSD)[4],YOLO(you only look once)[5]系列等。不同的目標檢測算法對同一物體檢測的結果也有所不同。
SSD 算法基于VGG(visual geometry group)[6]的主干網絡,從Conv4_3、FC7、Conv8_2、Conv9_2、Conv10_2、Conv11_2中提取了6組不同尺度的特征,通過非極大值抑制進行篩選,根據篩選出的default box在檢測圖像中繪制檢測框,并標出類別和得分[7]。SSD 網絡結構如圖1 所示。但是SSD 模型用于檢測的低層特征層只有一層,特征細節信息較少,導致圖像的分辨率顯著降低,目標遮擋或背景污染會導致檢測效果變差。Fu 等人[8]提出DSSD 模型,采用特征提取能力更強的ResNet-101主干網絡。DSSD 保持了SSD 目標檢測的6 個特征圖,直接將最深層的特征層用于分類回歸,然后經過反卷積模塊與前一層特征逐層元素相乘并進行輸出,但由于DSSD 模型網絡層數更深,大大降低了物體檢測速度,使得實時性較差。同時期RSSD(rainbow SSD)[9]通過增加特征圖的通道數來提高檢測效果,在淺層特征圖中通過池化融合到深層中,在深層特征通過反卷積融合到淺層中,因為每一層的感受野不同,需要歸一化來融合每個層的尺度,從而達到檢測的效果。FSSD(feature pyramid SSD)[10]則是通過對FPN(feature pyramid networks)進行改造,將來自不同尺度的特征連接在一起,使用批量歸一化對特征值進行歸一化,通過下采樣生成新的特征金字塔進行預測。因此,如何將高低層特征融合來提高檢測精度和速度成為一大挑戰。
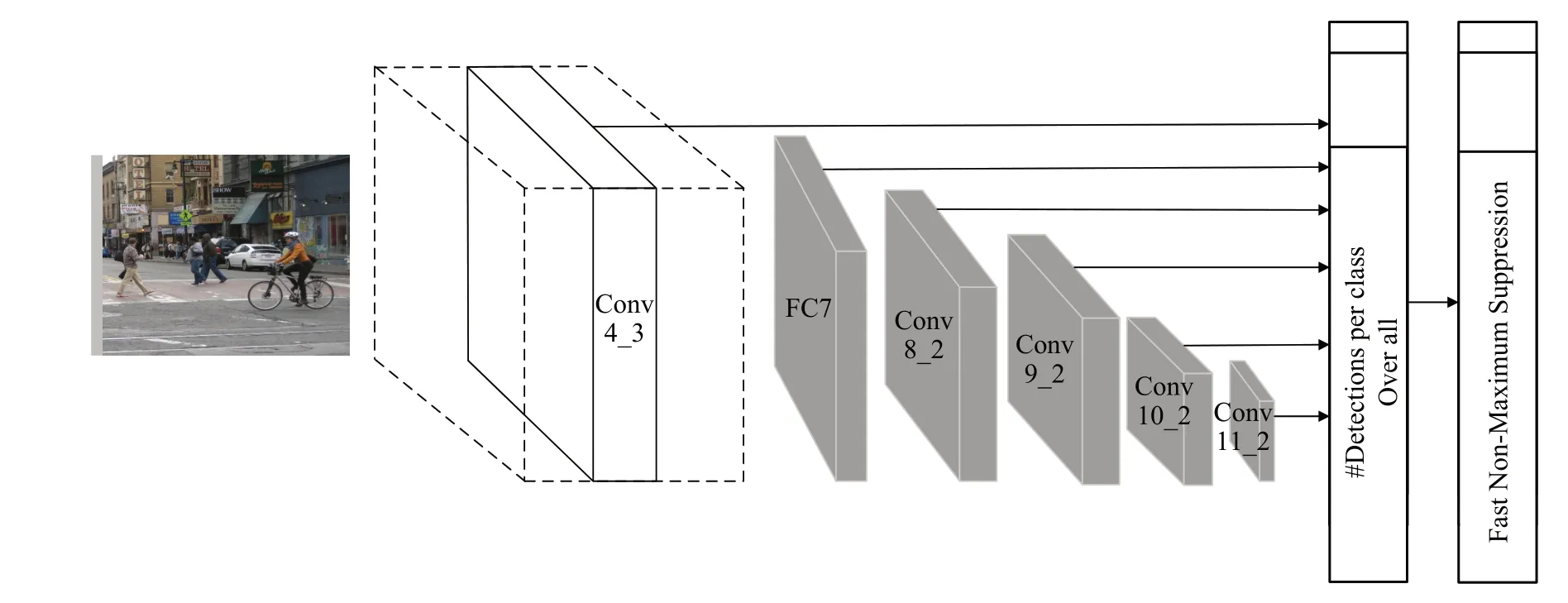
圖1 SSD網絡結構Fig.1 SSD network structure
為了減少網絡的深度,同時提高檢測的速度和準確性,研究人員對感受野進行了研究。感受野的應用增強了大腦表征這個地區。Liu等人[11]提出結合多分支結構卷積的感受野模塊的RFB-Net(receptive field block net)模型,通過將RFB 替換SSD 的頂部卷積層,并使用空洞卷積進一步增強目標檢測能力。Inception[12]通過使用不同大小卷積核,提取不同尺度特征,使用3 個不同分支,不同分支分別使用1×1、3×3和5×5不同的卷積核和膨脹率為1、3、5的空洞卷積獲得不同的感受野,然后將所有的特征圖連接起來。將RFB模塊融合到SSD中可以提高目標檢測精度。
基于深度學習的目標檢測算法依然存在一些被遮擋的目標或者小目標識別效果較差,檢測精度不高。本文基于SSD目標檢測算法進行高低層特征融合,設計了一種既能提高目標檢測精度又能保證檢測速度的算法。該算法是將深層Conv9_2、Conv10_2、Conv11_2 三層特征層進行反卷積得到新的Conv10_2、Conv11_2,在深層特征中使用反卷積是為了將深層特征融合輸出后而不影響特征層圖尺寸大小。輸出新的特征層Conv10_2以及新的Conv11_2是將原有的特征層以及相鄰的特征層特征疊加,還原操作后特征圖分辨率變小的問題,有利于進行目標定位。使用RFB模塊提高感受野的同時減少參數計算量,由于淺層生成的小目標特征缺乏足夠的語義信息,對于淺層的小目標檢測依賴上下文信息,故將淺層Conv4_3、FC7、Conv8_2分別在卷積操作后進行特征連接,提高小目標的信息特征。最后對改進的SSD 結構進行再訓練。本文選取輸入尺度相差不大的SSD、DSSD模型做對比實驗,通過比較mAP值和檢測幀數FPS(frames per second)來驗證改進算法的檢測結果。
1 相關工作
1.1 算法改進
SSD網絡生成的預測框質量較低,導致復雜環境下目標定位失敗,影響檢測結果[13]。本文提出一種新的特征融合的SSD算法,其網絡框架如圖2所示。該算法主要設計了三個模塊來增強特征圖尺度信息。首先,使用淺層特征融合模塊來增強保留的特征細節信息,從而提高對復雜背景或者小目標檢測的能力。因為在SSD 算法中靠前的特征層卷積次數較少,相對靠后的有效特征層包含的語義信息少,導致在檢測小目標時信息不夠全面以及將圖片resize 到300×300 的尺寸時,同樣對于小目標的尺寸也會隨之減少,可能會使小目標失真,從而影響整個網絡的檢測精度。然后,通過反卷積模塊獲得上下文信息增強的同時,將特征圖還原為原來特征圖尺寸的大小,避免還原后的特征圖分辨率變小。為了融合不同的特征信息,使用不同膨脹率的卷積來增強網絡感受野。在SSD 算法中Conv4_3 層的先驗框默認為38×38×4,FC7 層的先驗框默認為19×19×6,改進的算法使用RFB 模塊后將Conv4_3 和FC7 層融合后得到的先驗框總數為38×38×6。選取了Conv4_3層中的網格數38×38,同時選中FC7層中的rate=6的先驗框可以減少參數計算量,增加Conv4_3 層和FC7 層之間的關聯,不同于在網絡中提取不同尺度的特征進行獨立預測。另外RFB是鑲嵌在改進算法中,在改進算法中融合多個不同尺度的特征層,故檢測精度也隨之提升。對于在小目標檢測能力不足的情況下,通過特征連接將Conv4_3、FC7、Conv8_2 大特征圖尺寸使用不同層的附加特征作為上下文,在連接融合之前對上下文特征執行反卷積,使其具有與目標特征相同的空間大小。同時利用反卷積操作將Conv9_2 與Conv10_2,Conv10_2 與Conv11_2二者特征融合在一起,得到新的特征層,經過感受野增強模塊捕獲更多的目標區域特征。其中圖2 灰色部分為提取的特征圖,紅色部分則是融合后的特征圖。最后,經過非極大值抑制進行分類篩選,得到檢測結果。
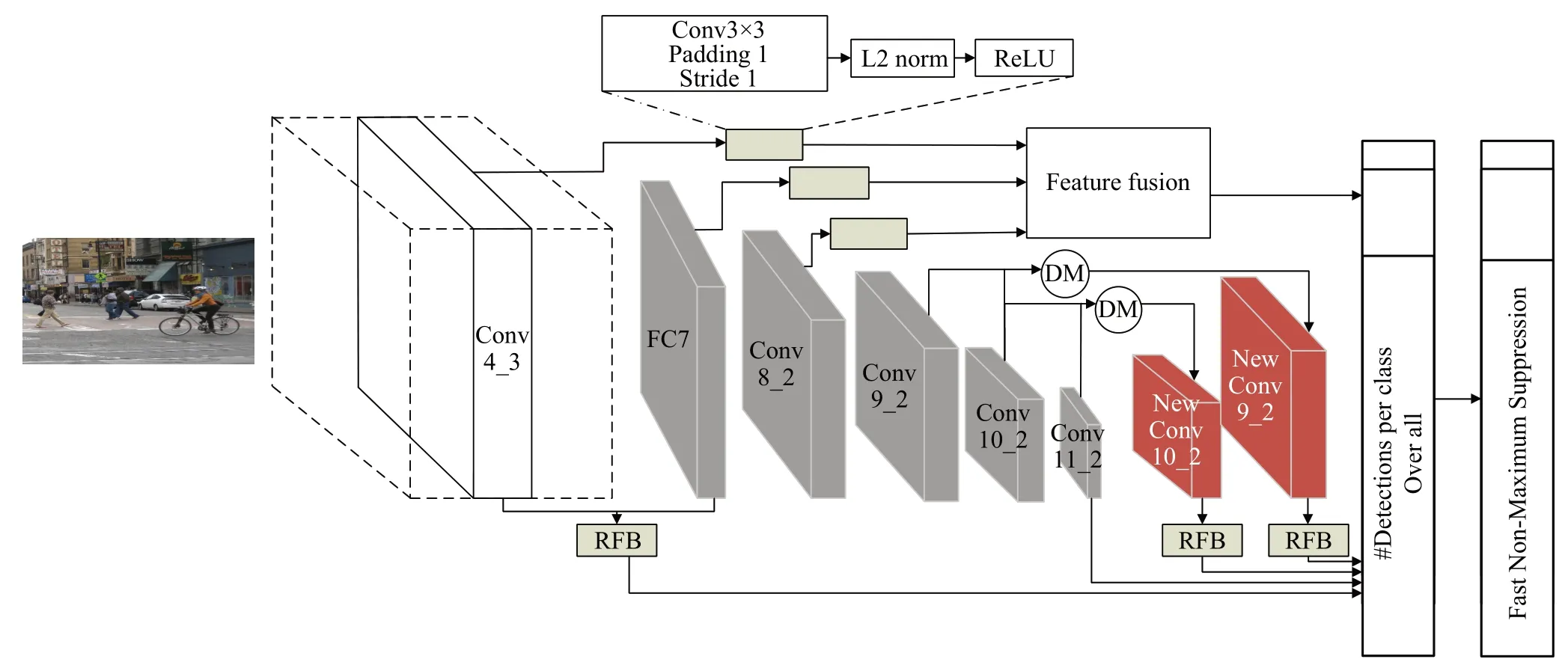
圖2 改進的SSD網絡結構Fig.2 Improved SSD network structure
1.1.1 RFB模塊
RFB模塊中引入了空洞卷積,主要作用是增加感受野,應用在檢測任務中來獲得較大的感受野,提高網絡的特征提取能力。使用RFB在增加感受野的同時能夠減少參數量。這是因為RFB模塊上有多個分支,每個分支的第一層都由特定大小卷積核構成。不同點在于引入3個dilated卷積層(比如3×3Conv rate=1)。RFB結構是一個并聯的結構,輸入有5 個并行的分支,第一個是進行1×1的卷積,然后進行膨脹率為1的3×3卷積,第二個是1×1的卷積,然后進行普通的3×3卷積,第三個是一個膨脹率為3的3×3卷積,以及其他分支的卷積。目的是大幅度減少參數量來提高檢測速率,將這些分支的結果堆疊并進行1×1 的卷積再加上殘差結構,得到一個RFB模塊的輸出。RFB結構如圖3所示。
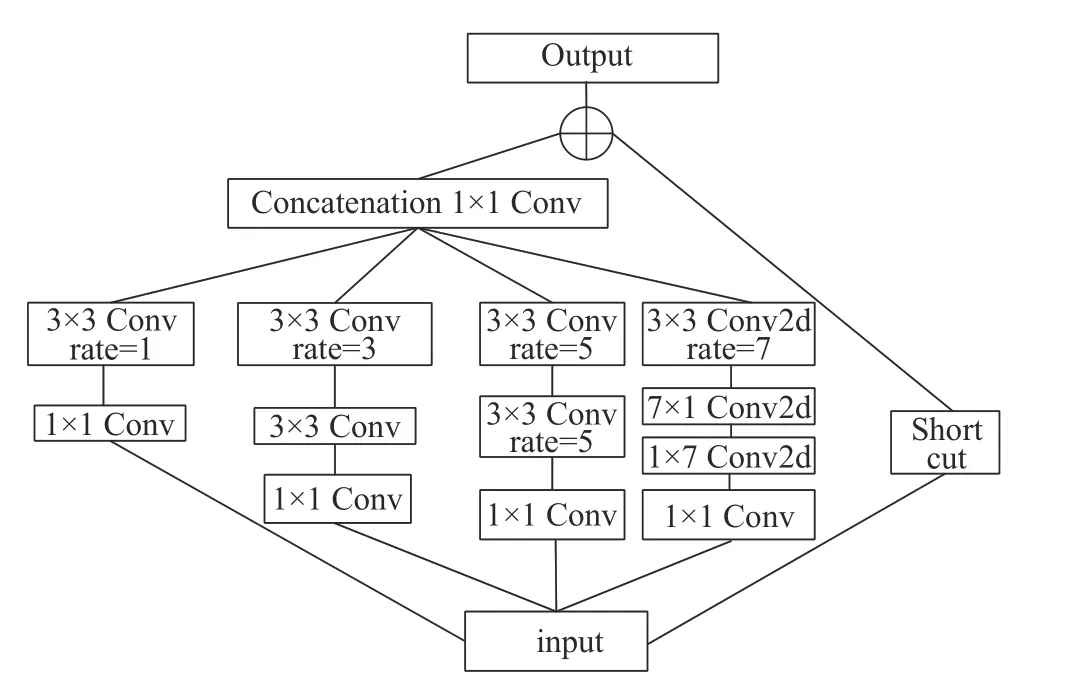
圖3 RFB結構Fig.3 RFB structure
1.1.2 特征連接
特征連接是為了給定特征映射用上下文信息,因此進行融合的是來自更高層次的特征映射目標特征層。在改進的網絡結構中,給定的目標特征來自Conv4_3,上下文特征來自淺層特征層FC7 和Conv8_2,如圖2 所示。雖然特征融合可以推廣到任何目標特征,但這些特征圖的空間大小不同,因此提出如圖4 所示的融合方法。在連接特征進行融合之前,對上下文特征進行反卷積,使其具有與目標特征相同的空間大小。將上下文特征通道設置為目標特征的一半,因此上下文信息的數量就不會超過目標特征本身。此外,在連接特征之前,歸一化步驟是非常重要的,因為不同層的每個特征值有不同的尺度,所以在每一層之后執行批處理歸一化和ReLU。最后,通過疊加特征來連接目標特征和上下文特征。新生成的特征層包含了目標特征Conv4_3 層以及FC7 和Conv8_2 兩個不同層的全局上下文信息和局部上下文信息,通過特征連接的方式將淺層特征融合,擴大連接特征圖的分辨率以及利用上下文的特征,能夠交互多尺度的特征信息,增強小目標信息的連續性的同時,保留了Conv4_3、FC7、Conv8_2不同層的特征信息。
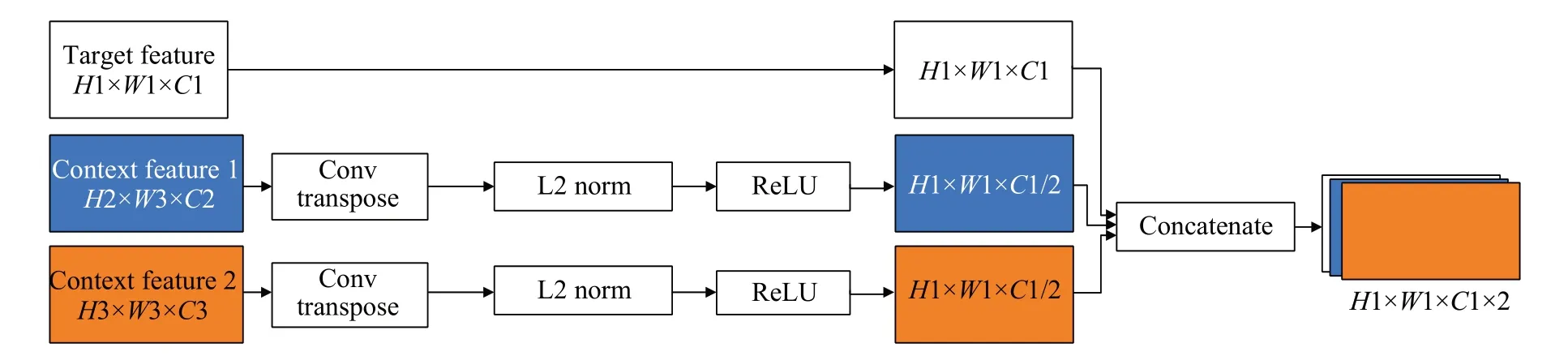
圖4 特征連接Fig.4 Feature connection
1.1.3 深層特征融合
在計算機視覺應用中,輸入數據集中的圖像在經過基礎網絡處理后,輸出的圖像尺寸會變小。這是由于在VGG 基礎網絡上會將一張圖像劃分為多個候選框,導致目標檢測時可能會存在漏檢的情況。由于淺層特征表達能力不強,需要用到上采樣方法,常用的上采樣方法是反卷積,以此來提升分辨率。深層特征圖的感受野較小,語義信息表征能力弱[14],為了提高檢測的準確性,將圖2中的深層特征層Conv9_2和Conv10_2,Conv10_2和Conv11_2 通過DM(deconvolutional module)模塊進行深度特征融合,使用目標的上下文信息也可以指導定位區域的選擇,從而提高準確率,如圖5 所示。將其中一個Conv10_2層先進行2×2×256的反卷積操作,3×3×256的卷積層再進行歸一化操作BN(batch normalization),添加BN 是為了起到緩沖的作用,保證網絡的穩定性[15]。Conv9_2經過3×3×256的卷積和BN,再經過ReLU(rectified linear unit)激活函數、卷積操作、BN,將不同層的特征圖通過元素對應點積(element-wise-product),通過ReLU 完成得到特征細節信息更多的新特征圖,使用DM 模塊進行深層特征融合,在不影響小目標檢測精度的前提下不改變特征層的大小,再使用RFB 模塊增大感受野。利用Inception的多分支結構,即使用膨脹率為[1,3,5,7]這種組合使得采樣點交錯,解決信息丟失的問題,不會對部分點重復采樣,同時有利于學習更多的局部信息,可以更好地獲得實例細節處的邊界特征[16]。感受野越大,改進網絡輸出的特征強度越好,對于大目標的檢測性能也就越好。
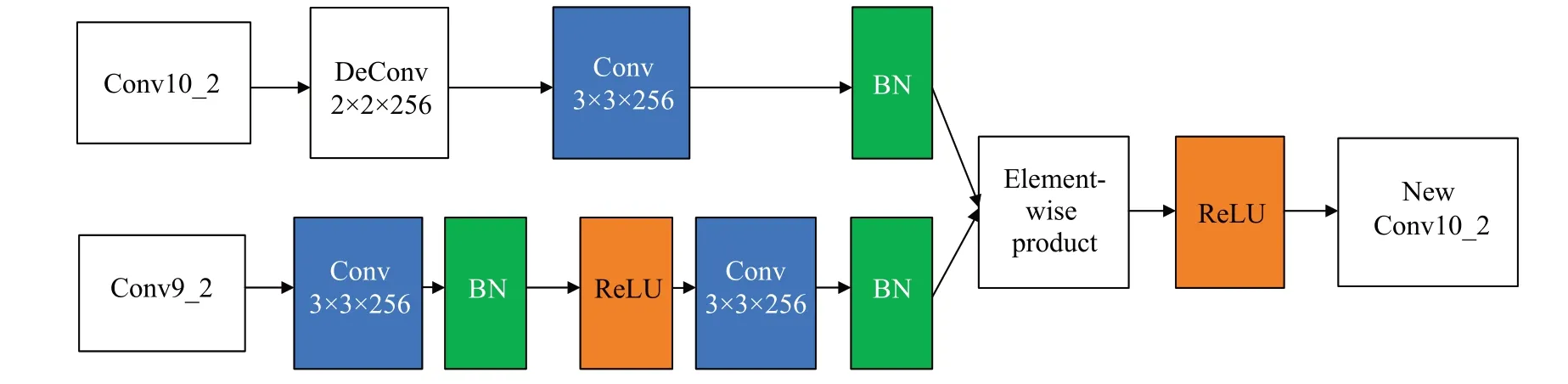
圖5 DM模塊Fig.5 DM module
1.1.4 RFB特征融合
特征對應元素相加使用RFB模塊,選擇在Conv4_3和FC7 層添加RFB 模塊,是因為淺層特征圖感受野較小,有助于提高目標檢測,插入深層特征圖時,可以減少計算參數數量。在改進網絡結構的基礎上進行詳述,如圖6 所示,在Conv4_3 層獲取的特征層大小是38×38×512。SSD 目標檢測中會直接進行預測,而改進后的算法將一系列特征提取到FC7 層,然后對FC7 層進行卷積,得到19×19×256的特征,再通過38×38的上采樣,卷積通道數為256,與Conv4_3 層通過38×38 卷積通道數為256進行一個堆疊,使用RFB模塊來提高有效特征層的提取能力。通過一個rate=6的先驗框,相比SSD的先驗框,在增加了不同層之間特征映射關系的同時,也保留了相對完整的語義信息,提高了網絡對目標的檢驗準確率。
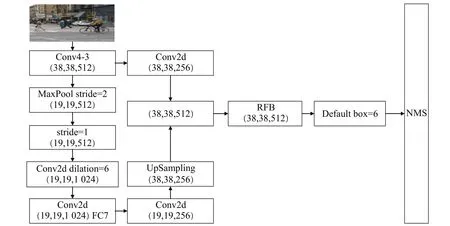
圖6 RFB特征融合Fig.6 RFB feature fusion
1.2 模型訓練設計
1.2.1 先驗框設置
改進后網絡模型訓練的主要目的在于增加正樣本和采用數據增強策略,其中先驗框與SSD 網絡相近似。300×300的輸入會產生數千個先驗框,按照傳統的匹配方法,只有少數先驗框可以與實際標簽框重疊,這意味著負樣本的數量會遠大于正樣本的數量。為了平衡樣本,在所有先驗框與真實標簽框中設置一個交并比(intersection over union,IoU)。在目標檢測過程中,通過前一個盒子和真實目標之間的匹配度交集來確定。先驗框如果與真實標簽框的重合率大于0.5,則記為正樣本,否則為負樣本。
對于每個網格點都存在若干個先驗框,根據每個有效特征層的網格點來獲取不同的先驗框。由于目標大小不同以及形狀各異,需要對每個特征圖根據目標大小的不同,設置不同尺度的先驗框。這里根據SSD算法設定的先驗框規則來進行錨框選擇。選擇先驗框尺寸的原則如下:
1.2.2 損失函數
損失函數由每個先驗框的標簽和坐標偏差來控制,通過反向傳播算法來調整網絡中的參數。具體而言,即通過將網絡操作結果中的預測框坐標、類別置信度和先驗框與目標結果進行比較來計算偏差。改進后的模型目標損失函數被定義為Confidence Loss(Lconf) 和Localization Loss(Lloc)的加權和,即:
其中,α是權重參數,通常默認為1,c為置信度,g為真框,l為預測框,Lconf為置信度損失,Lloc為位置損失,N為匹配的候選框數量。置信度損失是通過計算多類對象置信度的Softmax 損失獲得的,該損失表示公式如下所示:
邊界盒回歸實際上就是調整預測盒的過程,得到的預測幀通常與待檢測圖像中的目標區域存在一定的誤差。其中位置誤差計算公式[17]如下:
其中,g=(gcx,gcy,gw,gh)表示真實位置,d=(dcx,dcy,dw,dh)表示候選框位置。
DSSD 網絡模型有多尺度特征提取網絡,但DSSD對不同尺度特征采用非歧視的方法,選擇少數特征層進行預測,不考慮淺層和深層卷積層包含不同的局部細節,而且因網絡層數更深導致訓練難度增加。因此,DSSD 網絡模型目標特征的檢測能力不足。改進后的網絡將驗證集和訓練集的比例設置為1∶9,隨著訓練網絡的不斷迭代,改進后的損失函數值迅速低于原始的損失函數值,并且最終逐漸降低。設置權重衰減系數為0.000 5,學習率為0.001。最后,通過非極大值抑制算法只保留重疊較少的預測框。當最大迭代次數達到20 000時,兩個損失函數之間的距離達到最小值。從訓練開始到損失收斂穩定的時間基本相同,改進后的網絡模型收斂速度更快,如圖7所示。
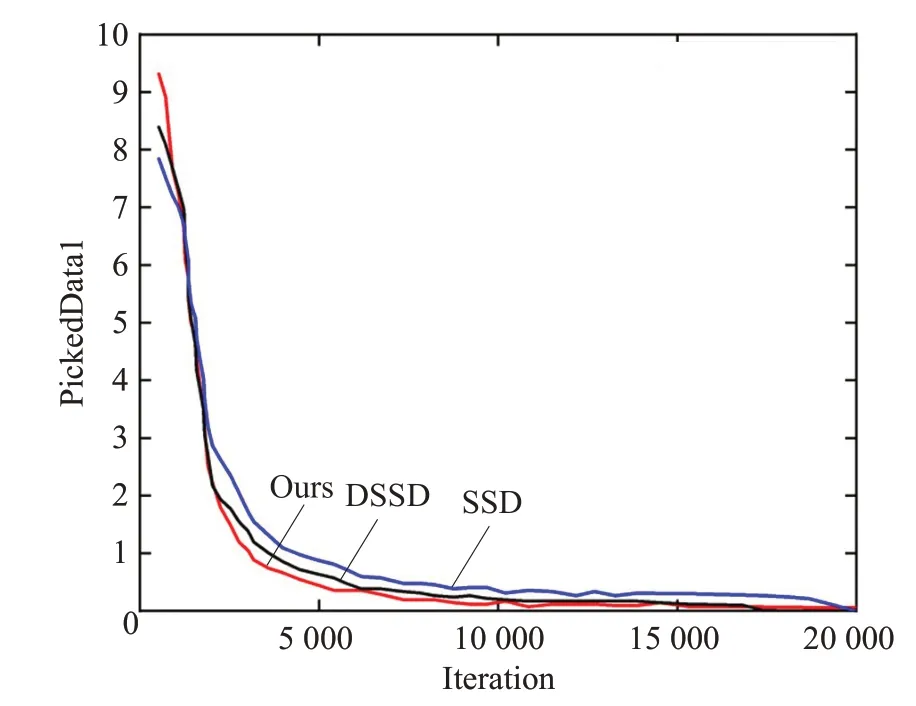
圖7 改進前后損失曲線Fig.7 Loss curves before and after improvement
1.2.3 評估指標
為了比較算法模型的優劣,將測試的圖像放入經過訓練的網絡中標記并測試結果。選擇精度、召回率作為檢測準確率的評價指標。評價指標的定義如下:
式中,TP 是正類預測為正類的數量,FP 是負類預測為正類的數量,FN 是實際正類預測為負類的數量。Precision 為查準率,是指預測正標簽樣本中的準確率。Recall為召回率,體現了預測為負樣本中標簽為正的程度。mAP是平均精度,其值越高,表示檢測結果越好。
2 實驗結果與分析
2.1 數據集與實驗環境
PASCAL VOC 數據集[18]是開源的用于圖像檢測的數據集,包含2007和2012兩個版本。本文選用VOC2007數據集中的圖片在訓練階段設置驗證集和訓練集的比例為1∶9。選用CSV數據集和COCO2017數據集進行驗證。實驗中使用顯卡為Nvidia RTX3090,軟件為Pycharm,版本號Python=3.6,實驗框架為Tensorflow1.13.1,在GPU環境下根據顯卡配置對應的CUDA和CUDNN。
2.2 檢測性能比較
在NMS 算法中,需要手動設置IoU 閾值,IoU 閾值的設置與網絡模型的檢測性能密切相關,在本文中設置此閾值為0.5。圖8 表示SSD 和DSSD 以及本文算法的精度召回曲線圖。P-R 曲線分別使用召回率和查準率作為水平和垂直坐標。當召回率為90%時,可以看出本文算法檢測精度高于SSD和DSSD。
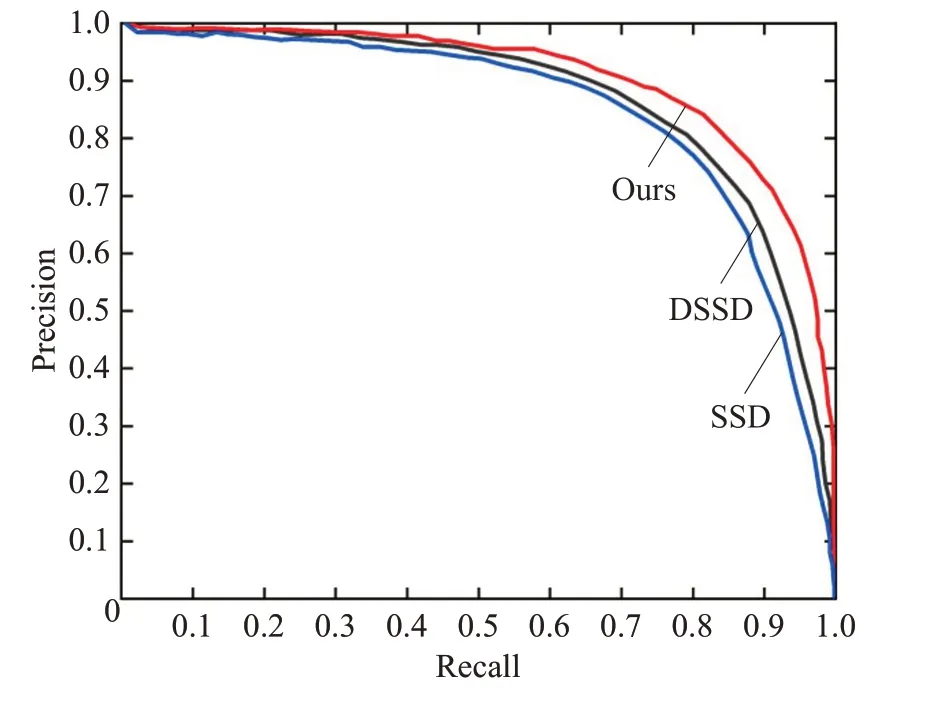
圖8 改進前后精度召回曲線Fig.8 Precision-recall curves before and after improvement
為了驗證改進后的算法精度與速度,將SSD、DSSD與改進后SSD算法進行比較,對輸入圖片進行處理得到300×300 像素大小的數據集。采用VOC2007、CSV 和COCO2017 數據集進行驗證。同為單階段目標檢測算法的YOLOv4模型、YOLOv7模型、SSD模型、DSSD模型以及改進后算法在不同場景下對應的檢測結果如圖9、圖10、圖11、圖12所示。

圖9 VOC2007物體檢測對比Fig.9 Comparison of VOC2007 object detection

圖10 隱藏物體檢測對比Fig.10 Comparison of shelter object detection

圖11 夜間檢測對比Fig.11 Comparison of night detection

圖12 COCO2017小目標檢測對比Fig.12 Comparison of COCO2017 small target detection
通過對比可以發現,本文模型相較于YOLO系列模型、DSSD模型、SSD模型可以更加精確地檢測到復雜環境下的物體。第一列是YOLOv4[19]模型的檢測效果,明顯可以得到在COCO 數據集中模糊背景條件下檢測效果較差。第二列是YOLOv7模型,2022年被YOLOv4的同一團隊[20]提出,無論在VOC2007數據集還是在COCO數據集中相比第一列模型檢測精度較高,尤其是在夜間檢測精度上,但在COCO小目標數據集上檢測效果不如本文算法。第三列為SSD 模型,在VOC2007 中并沒有檢測到被遮擋的物體以及小目標,仍然存在漏檢的問題,以及在COCO數據集中并沒有檢測到環境背景下的“person”。第四列為DSSD模型,檢測小物體并不完整,尤其夜間檢測性能并沒有較大的提高。而且相比SSD算法模型,DSSD檢測速度過度損耗,這是因為DSSD算法進行卷積特征和反卷積特征融合之前存在卷積特征計算的時間等待。而第五列為改進算法,在VOC2007數據集中看出完全可以檢測到小物體,也沒有出現誤檢狀況,在COCO2017 數據集中不僅可以檢測到所有的“bird”,對于背景影響下的“person”也可以完全檢測到,并沒有出現漏檢的狀況。本文算法檢測速度達到了49.1 FPS,遠高于DSSD 算法。通過特征融合來實現目標檢測,與傳統SSD、DSSD 算法相比,本文算法的目標檢測精度與速度顯著增強。
2.3 消融實驗
為了檢測三個模塊提升檢測精度的效果,分別將三個模塊依次添加到網絡中,測試數據集為PASCAL VOC2007,輸入圖像統一為300×300 的分辨率,訓練方式如第1.3 節所述。將Conv4_3、FC7、Conv8_2 三個淺特征層進行特征連接,但并未加入深層特征層中的反卷積模塊以及RFB 模塊,根據圖13(a)中的熱力圖[21]可以發現,已經可以檢測到小目標,這是由于通過淺層特征連接將小目標特征信息進行增強,但是熱力圖中的亮度不夠明顯。熱力圖中的亮度越明顯,則表示它的特征越強。特征連接的主要目的就是在淺層特征層提高對小目標的檢測能力。在SSD 算法中小目標檢測能力不足是因為對原圖進行了縮放,導致可用的anchor 比較少。改進算法將前三層進行特征連接,使得淺層的感受野比較小,保留了圖像的細節信息。從圖13(b)中的熱力圖可以看出,在特征連接的基礎上加入深層特征的反卷積融合成新的Conv9_2、新的Conv10_2,這樣在增強感受野的同時而不會影響原來特征圖尺寸的大小。從圖13(b)中可以看出,在不影響小目標檢測性能的同時可以增加一些中大目標的概率得分,因為圖13(b)中明顯大目標中心位置熱力圖分布定位面積較大。在特征連接的基礎上,將反卷積模塊加入深層特征中是為了提高它的感受野,而高層的特征圖負責大目標檢測,在加入特征連接以及反卷積的前提下加入RFB模塊后,一方面可以減少計算量來提高檢測效率,另一方面將Conv4_3和FC7層進行融合增強小目標檢測,在淺層特征層中主要增強邊緣信息。三層淺層信息的連接使小目標的語義信息位置信息增強,解決了整個場景下的局部信息不足問題,有助于提高各個目標分類的準確率,進而提高整體的檢測精度。可以看出圖13(c)中小目標上顏色變得明亮,而并沒有影響大目標上的亮度。表1 為三種不同消融策略檢測的精度對比,圖13 為采用三種不同融合方法后分別經過NMS算法進行分類顯示的熱力圖對比。

表1 消融實驗對比Table 1 Comparison of ablation experiments

圖13 熱力圖可視化Fig.13 Visualization of thermodynamic diagram
2.4 不同融合的消融分析
根據圖2 所示選擇融合的特征層(C),將不同特征圖調整到相同的尺度以及對不同層的特征圖進行融合。
其中,xi∈C表示需要融合的特征圖,fi為融合前特征圖變換函數,φf為不同特征圖的融合函數。本節對不同的融合模塊進行了消融實驗分析。由表2可知,即使最差的融合方式也可以使SSD算法檢測精度提升8.3個百分點。最好的融合方式是使用反卷積來調整特征圖的尺度,以及通過RFB模塊來減少不同特征層之間參數量的計算,然后通過特征連接融合不同特征圖,該方法使得檢測精度提升12.1個百分點。由圖13和圖14對比可知,使用不同的融合方法得到的檢測精度也有所不同,在融合前同樣使用RFB模塊,再使用特征連接以及元素求和兩種方法進行不同方式的融合,可以看出元素點積的方式比元素求和的方式在mAP 上略高0.8 個百分點。這是因為元素點積的方式可以突出特定區域的特征,對于小型目標檢測更加有力,本文選用元素點積的方式來進行特征融合。
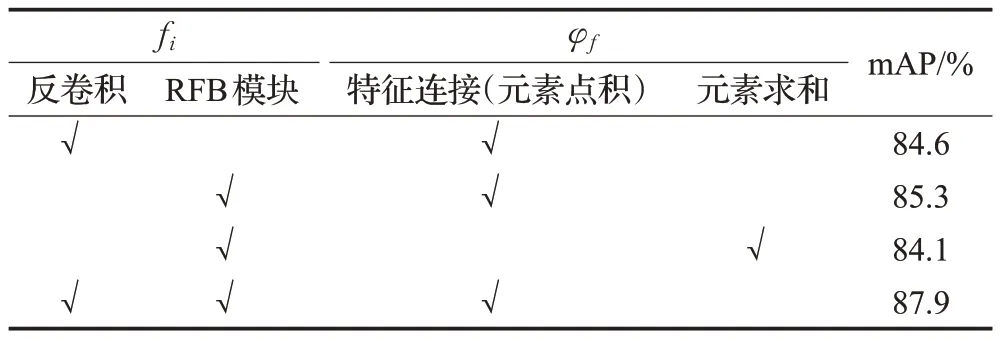
表2 不同融合方法的檢測性能Table 2 Detection performance of different fusion methods

圖14 不同融合的熱力圖可視化分析Fig.14 Visual analysis of different fused thermal diagrams
VOC2007數據集上每一類別的AP如表3所示。本文算法與SSD、DSSD 以及YOLO 系列經典目標檢測算法進行比較,從表3 中可以看出,本文算法在檢測精確度方面大幅度提升,其mAP 比DSSD 提高了6.6 個百分點,比SSD 提升了12.1 個百分點,比YOLOv7 算法提升了5.4個百分點。
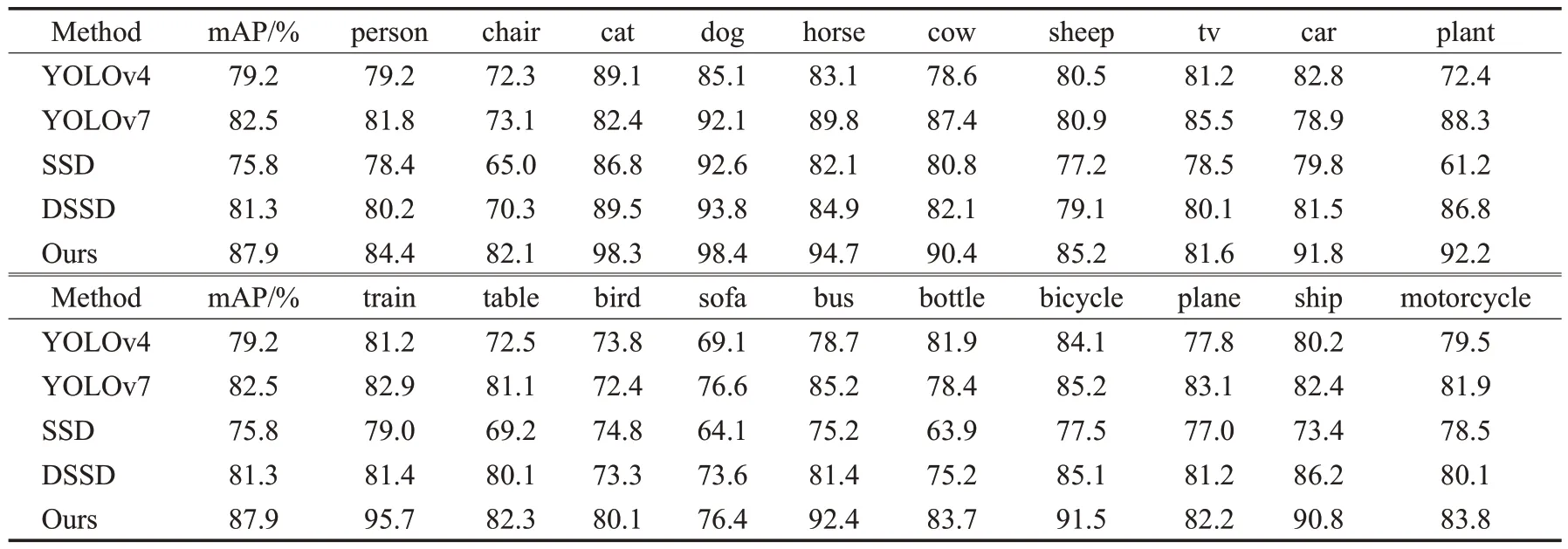
表3 VOC2007數據集中不同種類AP值Table 3 Different types of AP values in VOC2007 dataset
改進網絡的評價指標除mAP 之外,還有檢測圖像中幀率的大小,如表4 所示。SSD300 檢測圖像速度為53.5 FPS,DSSD檢測圖像速度為9.2 FPS,本文檢測圖像速度為49.1 FPS。由表3 可知,改進后的算法在精度上得到較大的提升。同時從表4中可以看出,在精度大幅度提升的基礎上,本文模型檢測速度與SSD相比僅損耗4.4 FPS。綜上,說明本文提出的改進算法不僅保證了檢測速度,同時滿足了高精度和高實時性。
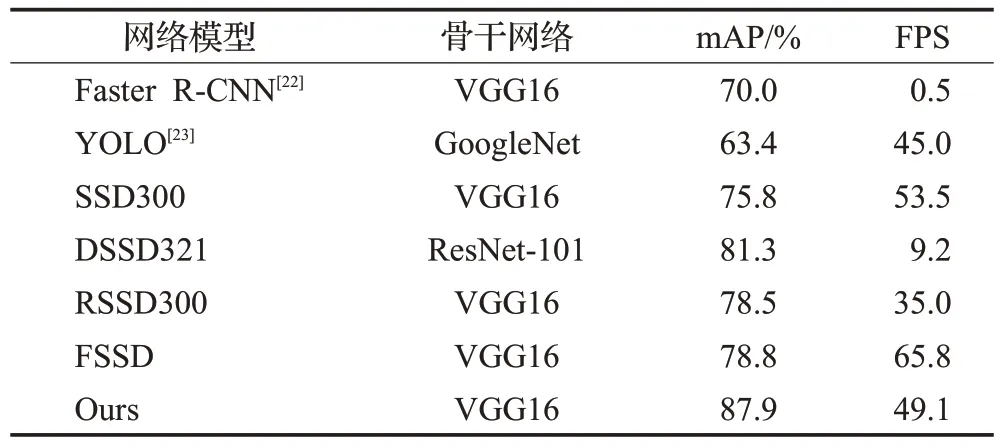
表4 模型之間FPS比較Table 4 FPS comparison between models
3 結束語
本文針對SSD 和DSSD 在復雜環境下目標檢測效果差的問題,根據DSSD 算法的反卷積思想,通過加入RFB 模塊提高感受野,加強語義信息的提取,使用特征連接將淺層特征圖進行特征融合,在反卷積模塊下將深層特征圖進行融合,使用RFB模塊減少參數計算量并進行再訓練。該算法對復雜環境具有良好的魯棒性和適應性,對于外界因素的影響具有較強的抗干擾能力。從實驗結果來看,本文算法檢測精度優于SSD 模型,在mAP 上比DSSD 提高了6.6 個百分點,比SSD 提升了12.1個百分點。在確保高精度的同時,也能夠平衡檢測速度,相比SSD檢測幀率僅損耗4.4 FPS。
未來的工作中,考慮基于改進后的網絡結構,結合NMS算法通過IoU進行評估。IoU存在一定缺陷,嘗試將目標尺度以及距離引入IoU中,進一步提高目標檢測的效果。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
