引入稀疏自注意力的目標跟蹤算法
2023-11-27 05:35:14王金棟張驚雷
計算機工程與應用 2023年22期
王金棟,張驚雷,2,文 彪
1.天津理工大學 電氣工程與自動化學院,天津300384
2.天津理工大學 天津市復雜系統控制理論及應用重點實驗室,天津300384
視覺目標跟蹤是計算機視覺的一項基本任務,旨在準確預測連續視頻幀中給定感興趣目標的位置和形狀。它在視頻監控、軍事偵察與打擊、人機交互、智能交通等領域有著廣泛的應用[1]。跟蹤任務在外觀變形、光照變化、外觀相似、運動模糊、遮擋、尺度變化等方面有著公認的研究困難,如何找到一種行之有效的方法,能夠具有足夠的魯棒性處理以上可能存在的各種復雜情況成為當下亟待解決的問題[2]。
卷積神經網絡是一種特殊的深層前饋網絡[3]。隨著卷積神經網絡和深度學習在目標檢測領域取得成功,越來越多的研究者將其運用到目標跟蹤中,并取得了很好的效果[4]。受基于深度殘差學習的圖像識別算法[5]啟發,孿生網絡算法[6]開始被提出,因其在速度與精度上取得了良好平衡,受到學者們的廣泛關注。SiamFC[7]作為孿生類算法代表,將目標跟蹤視為圖像對匹配任務,將感興趣的目標圖像作為模板,在后續幀中通過相關操作找尋匹配度最高的樣本,表現出了不錯的效果,此類算法在訓練階段完全離線,保證了跟蹤速度。SiamRPN[8]在孿生結構的基礎上引入應用于目標檢測的區域提議網絡(region proposal network,RPN)來預測目標的位置和置信度,使得孿生網絡具備多尺度檢測的能力,并且可以準確地回歸目標的位置和大小。SiamRPN++[9]在SiamRPN[8]的基礎上進行改進,采用均勻分布的采樣方式來解決網絡的平移不變性問題,同時采用深度交叉互相關操作來解決SiamRPN[8]網絡中分類與回歸分支中模板圖像與搜索圖像的特征維度不對稱的問題,進一步提升了跟蹤精度。SiamMask[10]提出了一種使用Mask輸出來跟蹤物體,對跟蹤目標進行分割,通過分割就可對目標進行動作以及行為預測,能夠更好地適應目標運動場景的跟蹤任務。SiamBAN[11]去掉了預定義的錨框,使得模型的參數量下降,提升跟蹤器對感興趣目標的跟蹤速度。SiamFC++[12]在SiamFC 網絡上增加了分類與狀態估計分支,去除先驗知識的同時明確分類得分,提升了跟蹤器的性能。Siam R-CNN[13]將兩段式結構與重檢測用于跟蹤,重檢測的方法能夠更好地應對目標變化帶來的挑戰,更適合于長時跟蹤的任務。這些進一步的改進算法大都在孿生網絡的基礎上添加額外的分支,使用更深的網絡,利用無錨結構。此外,一些流行的在線跟蹤器,如ECO[14]、ATOM[15]和DiMP[16],也嚴重依賴相關性運算。因此,主流的跟蹤框架大致可以分為兩部分:一是用于提取圖像特征的主干網絡;二是計算模板和搜索區域相似度的相關性網絡。
雖然孿生網絡類算法結構簡單,但采用的相關操作為一個線性匹配過程,會導致特征間語義信息丟失,這無法滿足跟蹤器捕獲模板與搜索區域之間的非線性交互信息。因此,以往的模型必須在孿生網絡的基礎上采用必要的手段來提升網絡的非線性表示能力,提出一種較相關性操作更好的特征融合方法是非常有必要的。為了解決上述問題,研究人員將可變形的注意力架構引入目標跟蹤任務中。2021年,基于可變形注意力架構的目標跟蹤算法TransT(transformer tracking)[17]被提出。該算法基于孿生網絡的輸入,在特征融合時采用自注意增強模塊與交叉注意模塊來取代經典孿生網絡類算法中的互相關操作,對提取的重要特征進行加強關注,對特征進行了自注意力和互注意力的運算,有效提升了算法的準確率[18]。該方法有效融合了模板和搜索區域之間的特征,產生了較相關操作時更多的語義特征圖,在公開測試數據集上取得了有競爭力的跟蹤指標得分和良好的跟蹤效果。
針對TransT 算法在特征增強過程中對輸入的每一個特征映射序列進行注意力分數的計算且多次融合時需要多次計算,易產生非常大的計算參數量,導致大量算力資源被消耗的問題,本文結合實際目標跟蹤任務對算法有效性以及經濟性的需求,提出了一種稀疏自注意力算法,由粗到細地計算注意力,實現近似線性的自注意力計算。此外,在特征提取部分本文在原骨干網絡中加入金字塔切分注意力模塊,可有效直接提取不同尺度的上下文特征信息,改變孿生類網絡采用多尺度方法提取圖像特征的處理方式。在多個公開測試集上的實驗表明,本文算法較現有主流跟蹤算法結果更優,并且滿足實時跟蹤需求。
1 TransT算法
Chen 等人在2021 年提出TransT[17]算法,該算法在孿生網絡的基礎上引入Transformer特征融合網絡代替傳統孿生網絡中的互相關操作,算法一經發布,就以優異的性能受到廣泛關注。
TransT 算法首先以ResNet50 為主干進行圖像特征的提取,特征圖像通過1×1 卷積來進行通道降維,降維后的圖像展平為特征向量,輸入到自注意增強模塊(egocontext augment,ECA)與交叉注意力模塊(cross-feature augment,CFA)來進行特征增強與特征融合,最后利用頭部預測網絡進行前景與背景的分類以及目標位置的歸一化預測,其過程如圖1所示。
TransT 算法通過Transformer 架構來對模板圖像與搜索圖像進行特征的融合,使得經過融合后的輸出不再是相似得分圖,而是真正的融合特征圖像。TransT的特征融合部分采用自注意模塊(ECA)和交叉注意模塊(CFA)構成Transformer架構,通過注意力機制來關注圖像的重要信息,同時建立起遠距離特征之間的依賴關系,可以捕捉到全局的信息。在預測部分采用二分類方法對輸入的特征融合后的向量進行分類與回歸。
TransT 算法在具有挑戰性的大規模數據集上有著不錯的表現,但在進行非常關鍵的特征增強時,擁有龐大的參數量以及計算復雜度,這就要求實驗或實際應用系統有更大的內存容量以及強勁的多進程運算處理能力,實際使用成本偏高。因此迫切需要設計一種近乎線性的自注意力計算方法,以實現跟蹤精度與計算復雜度之間的有效平衡。
2 本文算法
本文算法對TransT 網絡結構進行改進,總體結構如圖2所示。特征提取網絡DEPSANe(tdouble enhance pyramid split attention net)在殘差網絡ResNet50 的基礎上進行改進,在特征融合部分采用了增強的自注意增強模塊(EECA)替代原網絡中的自注意增強模塊(ECA),降低自注意力計算復雜度的同時減少長序列在向后傳輸的過程中造成的信息丟失。
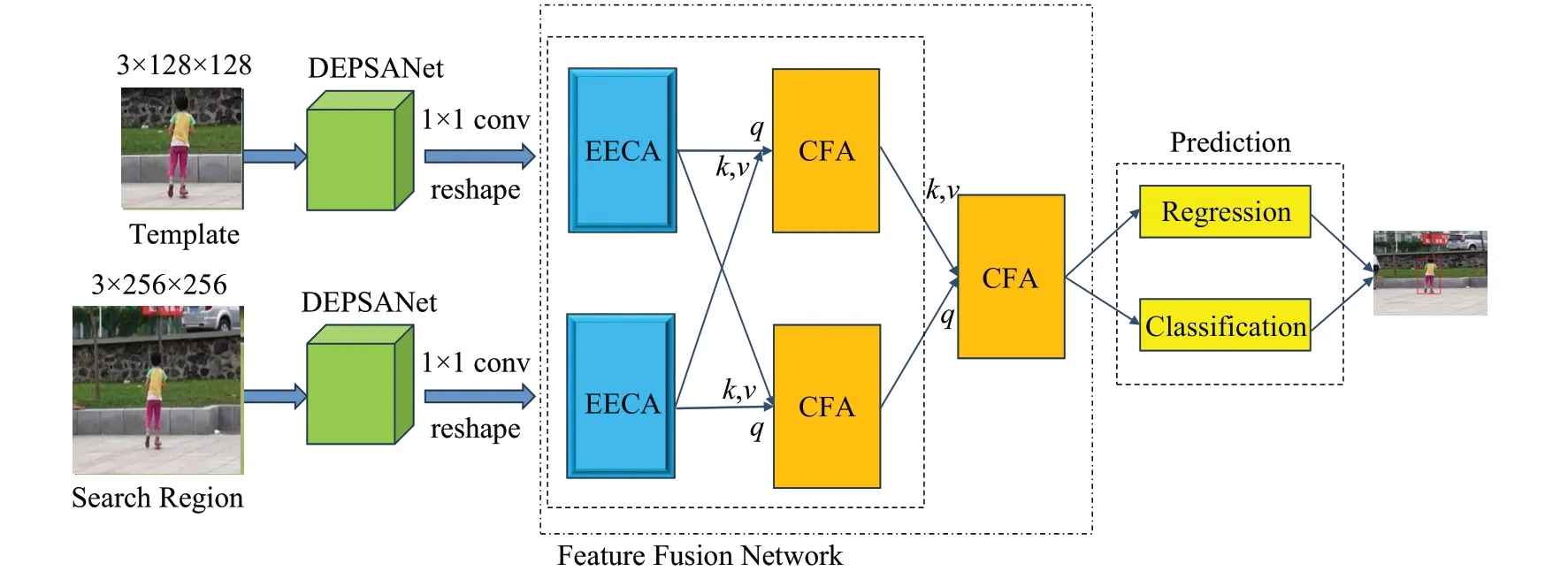
圖2 E-TransT的算法結構Fig.2 Algorithm structure of E-TransT
2.1 改進的特征提取網絡DEPSANet
TransT 算法采用ResNet50 作為骨干網絡提取特征,提取出的特征信息無法體現遠距離的依賴關系,特征空間信息較弱,在特征融合時無法聚焦更多有關聯的信息,影響跟蹤器的性能。
本文對原骨干網絡結構ResNet50 進行了改進,引入金字塔切分注意力模塊(pyramid split attention,PSA),同時去掉ResNet50 網絡的最后一個階段,將第四階段輸出當作最終輸出,DEPSANet的網絡設計與ResNet50的網絡設計對比如表1所示。
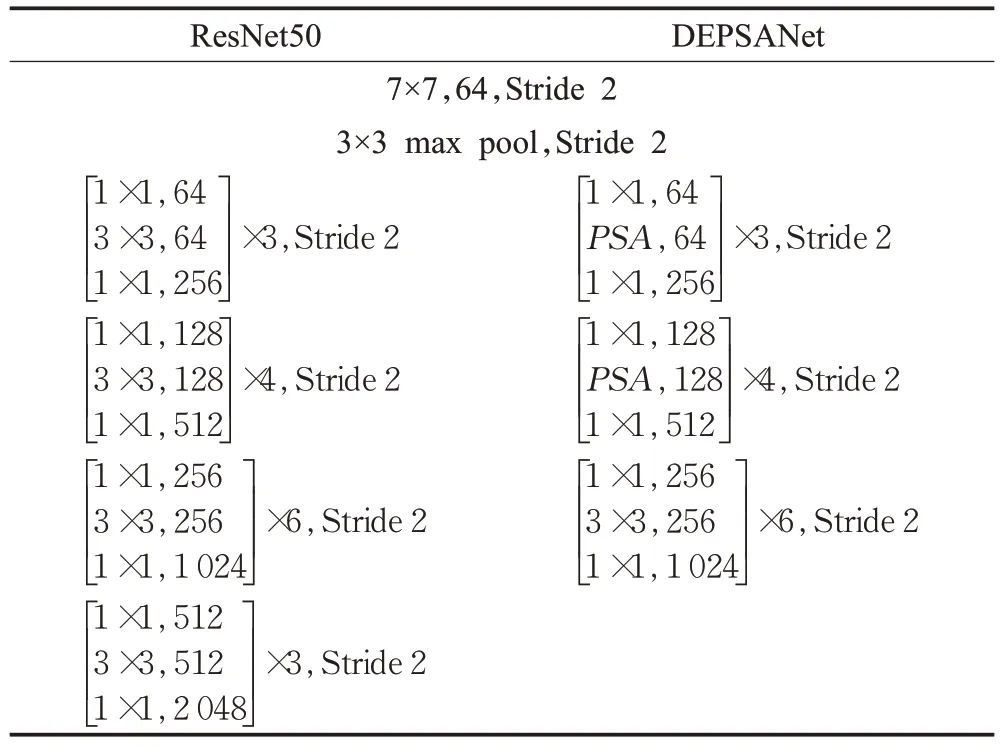
表1 DEPSANet與ResNet50網絡對比Table 1 Comparison of DEPSANet and ResNet50 network
PSA模塊首先將輸入圖像在通道上進行分組,對每一分組采用不同卷積核大小來進行卷積操作,將卷積后的特征圖像在通道上進行拼接,再通過空間權重增強(SE weight module)來獲得不同尺度特征圖的注意力權值,由此可使得提取的特征獲得不同尺度的上下文信息以及像素級的關注。PSA整體架構如圖3所示。
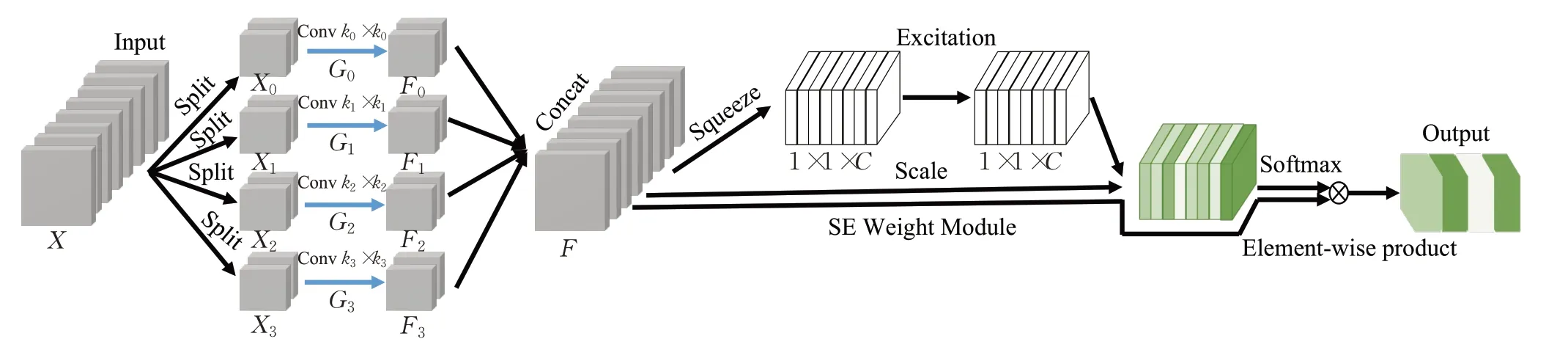
圖3 金字塔切分注意力架構Fig.3 Pyramid split attention architecture
圖3 中,Xi表示輸入切分而成的tensor,Fi表示不同分組卷積所提取的特征圖,F為融合多尺度特征信息的特征圖。K0、K1、K2、K3分別為不同大小的卷積核,實驗中設置K0為3,K1為5,K2為7,K3為9;G0、G1、G2、G3分別為輸入切分而成的分組數量,實驗中設置它們依次為1、4、8、16。
目標跟蹤任務需在視頻圖像序列首幀選取感興趣目標,目標被視為前景,除此之外都被視為背景。由于視頻序列之間有著時間以及空間上的聯系,每一幀圖像都與前后幀圖像在不同尺度空間上有著信息依賴,對特征提取網絡進行重新設計,為圖像提供不同尺度的空間信息來豐富特征空間,使得特征融合網絡可以捕獲更關鍵的信息,提升算法的跟蹤精度與魯棒性。
如表1所示,通過將PSA模塊代替原ResNet50網絡第二以及第三階段的3×3卷積操作,同時將第四階段的下采樣單元的卷積步長由2 變為1,并將這一階段作為最終的輸出,以此來形成新的骨干網絡DEPSANet。雖然引入較少的參數,但是獲得了全局的空間信息以及允許更大的特征分辨率圖像的輸入。
2.2 稀疏自注意力
TransT 算法在特征融合時進行了多次特征增強操作,雖然可以捕獲全局信息,但所有的輸入序列進行計算帶來大的內存占用和高的計算復雜度,以及復雜度與跟蹤精度不呈線性相關等問題。本文根據目標跟蹤算法的經濟性與實際承載平臺,提出一種稀疏性的自注意力計算方式,選擇性地進行自注意力計算,實現對有用信息的關注以及無關信息的跳過,使跟蹤器的精度與復雜度之間達成平衡。
首先,對輸入特征圖進行圖像嵌入,嵌入后的維度為Dx,長度為N的序列通過線性變換得到查詢向量q(query)、鍵向量k(key)與值向量v(value)。之后,這些向量分別與相應的初始化矩陣相乘得到注意力機制中的查詢矩陣Q(query)、鍵矩陣K(key)、值矩陣V(value)。整個過程如式(1)所示。
其中,Wq、Wk、Wv為可學習的權重參數,由于計算機中乘法的計算速度比加法慢,在衡量計算復雜度時主要考慮乘法帶來的影響。對于矩陣乘法(a,b)×(b,c),計算復雜度為O(abc)。通常情況下,查詢矩陣Q、鍵矩陣K與值矩陣V的維度相同,即Dq=Dk=Dv=d,則此過程的計算復雜度為O(2DkNDx+DvNDx)=O(NDx(2Dk+Dv))=O(N)。
注意力分數的計算如式(2)所示。
其中,C為矩陣的維度。在自注意力計算時,其特殊在于Q=K=V,該過程可視為輸入的圖像特征本身之間進行相似度計算,再計算自注意力的分數,該數值決定了深度學習網絡對重點特征信息的關注程度。此過程的計算復雜度為O(2DkNDx+DvNDx+N2Dk+1+DxN2)=O(N2)。由此可見,自注意力計算會產生二次型的計算復雜度。
稀疏自注意力(sparse self-attention)通過選擇特定的Q與K進行自注意力計算來減少計算量。實現高效計算的同時減少長序列輸入在特征增強過程中產生的信息丟失,計算稀疏自注意力分數的公式如式(3)所示。
其中,為第L個采樣層的第i個查詢矩陣Q,為第L個采樣層篩選出與查詢矩陣Q進行自注意力得分最高的j個鍵矩陣K,為第L個采樣層j個值矩陣V。
整個稀疏自注意力的過程是先對輸入的特征圖進行下采樣操作,對下采樣的每個層進行自注意力的計算,每一個采樣層的查詢向量qi在計算注意力分數之后,篩選出與之計算的注意力得分最高的j個鍵向量k,然后在下采樣過程中將查詢向量qi與這j個鍵向量k的子向量進行計算,最后通過加權平均不同采樣層的自注意力來得到全局關注信息。此過程的計算復雜度為O(2DkNDx+DvNDx+2NDk+1+2NDx)=O(N)。由此可見,通過稀疏自注意力的計算可將二次型的計算復雜度降低為線性復雜度。每一個采樣層通過部分序列的自注意力的計算聚焦重要消息,該過程可表示為:
其中,為第L層所關注的重要信息,分別為下采樣不同層之間參與稀疏自注意計算的所有鍵矩陣K和值矩陣V疊加而成的矩陣。T iL為不同采樣層進行稀疏注意計算的向量,在不同采樣層之間采用不同顏色表示。計算過程的示例如圖4所示。

圖4 稀疏信息聚合架構展示Fig.4 Illustration of sparse message aggregation architecture
每個采樣層聚焦的信息進行疊加,最終得到自注意力所關注的重要信息,整個過程可表示為:
其中,m為自注意力所關注的重要信息,為可學習的權重平均矩陣。在此引入可學習的權重平均矩陣目的是防止產生大的注意偏移。
不同采樣層有目標的區域通過自注意力的計算來獲得特征信息增強,在顏色區域以外跳過自注意力的計算,整個過程的參數量由之前的2.31×108減少到現在的1.57×108,滿足感興趣區域信息增強的同時降低無關區域計算引入的算力消耗,內存占用由12 GB降低到8 GB,訓練時長由7天縮減為3天。實驗結果還表明自注意力的稀疏化計算保留了前景區域需要增強的特征及其參數,使得訓練出的跟蹤器能夠穩定準確地發揮性能。同時,這樣做還可以降低Transformer 架構長序列輸入時可能會出現的傳輸過程中的特征信息缺失,可最大程度上保留全局信息的完整性。
2.3 自注意增強模塊EECA
原TransT 算法中采用多頭自注意力(multi-head self-attention)來進行自注意力計算,整個過程帶給模型非常高的計算成本,在實際訓練過程中表現出模型復雜度與跟蹤器性能非線性的問題。因此,本文算法采用稀疏自注意力來構建新的自注意增強模塊EECA。本文算法中的EECA模塊的結構如圖5所示。
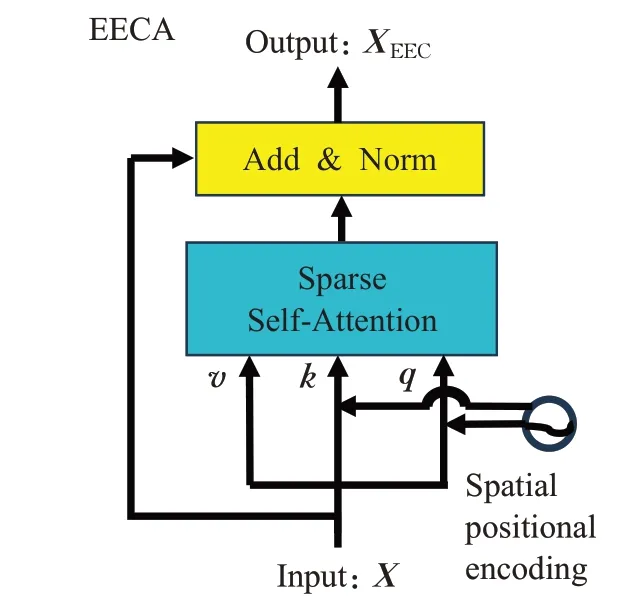
圖5 改進的自注意增強模塊EECAFig.5 Improved self-attention enhancement module EECA
整個EECA模塊可以總結為式(6),其中PX為正弦函數的絕對位置編碼。
EECA 模塊采用殘差形式,利用稀疏自注意力,聚合特征圖不同位置的信息,在此過程中對自注意力計算增強后的特征圖與原特征圖進行殘差計算,可產生更多帶有關注特征的特征圖。在消融實驗中,稀疏自注意力替代多頭自注意力使得算法的性能變得更好,由此可見,EECA模塊在算法結構中具有有效性。
本文在骨干網絡中引入金字塔切分注意力,使得提取的特征更能體現空間上的依賴關系,在特征融合時可關注到特征信息的空間細節。自注意力對特征信息進行細節關注與信息增強,對于后續特征融合非常重要,但自注意力計算有著非常龐大的參數量。因此,本文算法采用稀疏自注意力的方式來計算自注意力分數,跳過了無前景區域的自注意計算,降低了計算復雜度,減少了信息在傳輸過程中的丟失,最大程度地保留了信息的完整性。
3 實驗結果
為評估改進后的算法性能,本文使用LaSOT、TrackingNet、Got-10k、OTB-2015、VOT系列等不同屬性的測試集進行測試,并與基準TransT[17]算法,經典深度學習算法SiamFC[7]、SiamRPN[8]、SiamRPN++[9]、SiamMask[10]、SiamBAN[11]、SiamFC++[12]、SiamR-CNN[13]、ECO[14]、ATOM[15]、DiMP[16]進行對比。本文算法使用Python3.7 實現,深度學習框架使用Pytorch1.2.0,實驗平臺為NVIDIA GeForce 1080Ti 的Linux 服務器,使用LaSOT 與Got-10k 等比例選取作為訓練集進行訓練。
3.1 測試數據集
LaSOT 包含1 400 個視頻序列,每個視頻平均包含的幀數達到了2 512 幀,每一幀都做了精細的人工標注。數據集分為70 個類別,每個類別由20 個視頻序列組成,其中1 120 個視頻序列用作訓練集,280 個視頻序列作為測試集,評價指標為成功率(AUC)、歸一化精度(Pnorm)和精度(precision,P)。TrackingNet是YouTubeBB稀疏標注的目標測試集的子集,包含30 643個視頻,21種目標類別,且包含詳細的運動特征,評價指標與LaSOT數據集評價指標一致。GOT-10k 包含10 000 個訓練集視頻,其中分別有180 個數據集被作為測試集以及驗證集,包含563 個目標種類,評價指標包括平均重合度(average overlap,AO)、成功率(success rate,SR,有0.5和0.75兩個閾值),以及幀率(Speed)。
VOT 數據集是現階段針對實際目標跟蹤任務遇到的不同挑戰的評測數據集,且每年都進行一定程度的更新。實驗中采用了VOT2016、VOT2018、VOT2018-LT以及VOT2019數據集對算法進行測試評估。這些數據集都包含60個視頻序列,評價指標包括準確度(accuracy,Acc),魯棒性(robustness,Rob,跟蹤目標的穩定性,數值越大,穩定性越差),丟失數量(lost number,LB),平均重疊率(expected average overlop,EAO)。特別地,在VOT2018-LT測試集上采用精確度(precision,Pre)、召回率(recall,Rec)、二分類精確度指標(F1)評價指標。與其他數據集不同,該數據集是模擬實際跟蹤任務中的長時跟蹤場景,且在之前的數據屬性基礎上增加了兩種挑戰:完全遮擋和超出視野。當目標在幀圖像中完全消失時,需要跟蹤器能判斷目標是否消失并在目標出現時能夠重新檢測。這些挑戰的適時補充將在很大程度上逼近真實跟蹤任務可能遇到的場景。
OTB-2015 數據集共有100 個視頻序列,共58 897幀。該數據集包含長序列與短序列,囊括了光照變化、尺度變化、遮擋、形變、運動模糊、快速運動、平面內旋轉、平面外旋轉、完全消失、相似背景、低分辨率等11種跟蹤難點。評價指標包括:成功率圖(success plot,指交疊比)與精確度圖(precision plot,用中心位置偏差來表示)。評價方式分為三種:一遍過評測(one-pass evaluation,OPE)、時域魯棒性評測(temporal robustness evaluation,TRE)以及空域魯棒性評測(spatial robustness evaluation,SRE)。
3.2 測評結果
在大規模數據集上的測試結果如表2 所示。本文算法在LaSOT數據集上的評價指標均達到了最好的結果;在TrackingNet 數據集的測試結果中,以82.2%的成功率、87.4%的歸一化精度、81.5%的精度超越了現有的主流目標跟蹤算法。本文算法在GOT-10k 數據集的速度評價指標上雖然不是最優結果,但達到了55 FPS,較原算法實時性更高。
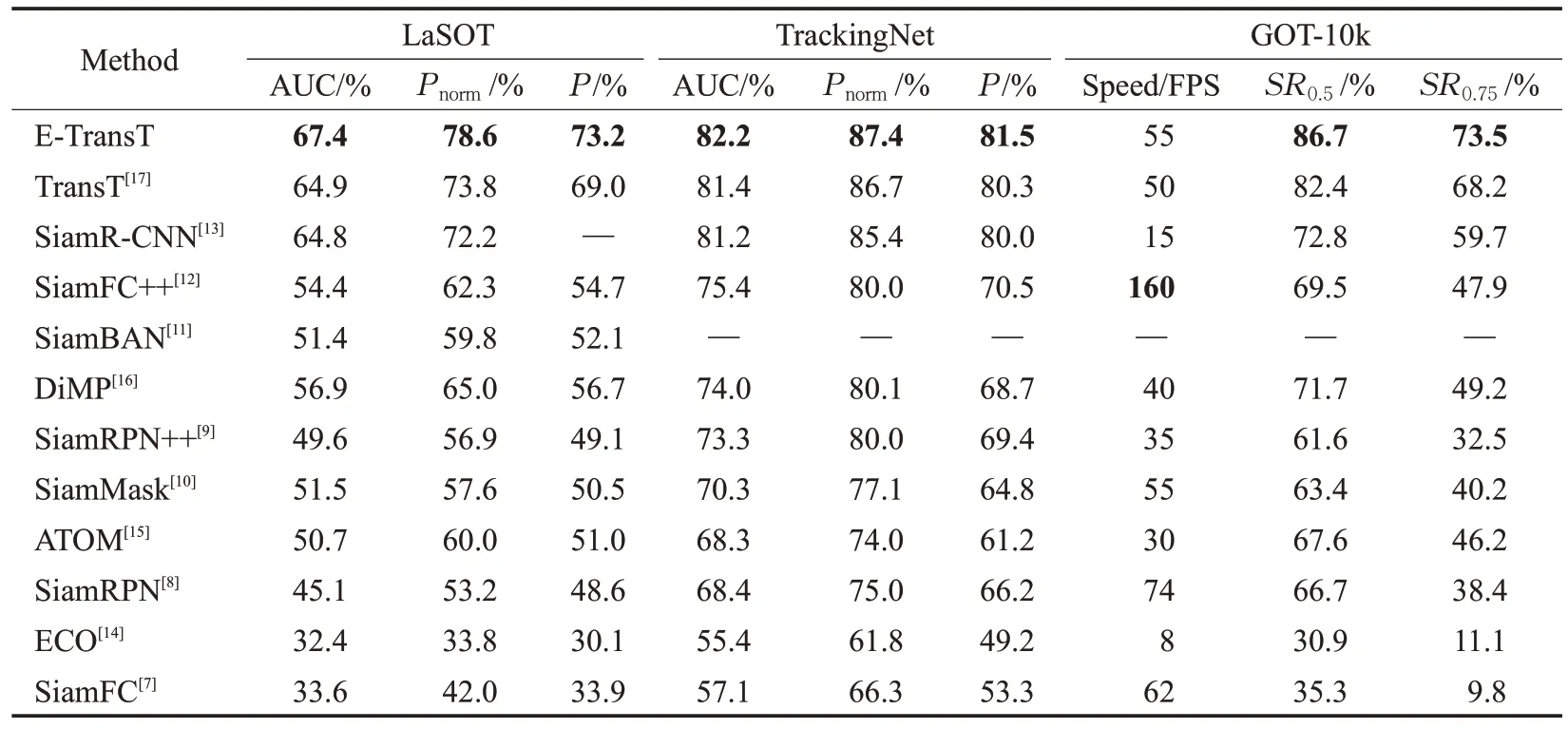
表2 大規模數據集測試結果Table 2 Evaluation results on large datasets
通常情況下,視頻數據的數據流是非常穩定的,即固定的采樣速率,在此背景下,只要算法每秒處理的圖片數量大于每秒采樣的圖片數量,就認為算法能夠實時處理。因此,對跟蹤任務而言,如果算法每秒處理的圖像數量大于視頻每秒采集圖像的數量,那么就認為算法可以實時跟蹤目標。通過對目標跟蹤算法進行分析研究,發現滿足實時性的算法都具有幾個共同的特征:在GPU上運行;采用深度學習框架;稀疏的更新策略。
本文算法在擁有GPU 的服務器上進行訓練與測試,采用了Pytorch的深度學習框架,依托于稀疏且快速的學習算法,具備以上所述特征。同時,算法的幀率超過了GOT-10k中視頻流的速率,故認為算法滿足跟蹤的實時性要求。
為了說明本文算法針對目標遮擋、形變、快速移動、尺度變化等的有效性,實驗中針對表3列舉的4種VOT系列的不同數據集進行了測試。在短時視頻序列數據集VOT2016、VOT2018 以及VOT2019 中,本文算法較TransT 算法在VOT 數據集3 個評價指標中均有不同程度的提升。在長時序列數據集VOT2018-LT中,本文算法較TransT算法在精確度指標上有著1.3個百分點的性能提升。

表3 VOT數據集測試結果Table 3 Evaluation results on VOT datasets 單位:%
VOT 系列數據集中完全消失這一跟蹤挑戰數據量很少,大都偶遮擋但沒有消失,同時短序列的數量遠大于長序列的數量,樣本分布不均,會對跟蹤器性能造成一定程度的影響。因此,為進一步驗證算法的泛化性與可靠性,將本文算法在OTB-2015測試上進行算法評測,成功率圖和精確度圖分別如圖6和圖7所示。結果表明本文算法跟蹤成功率與準確度最優。
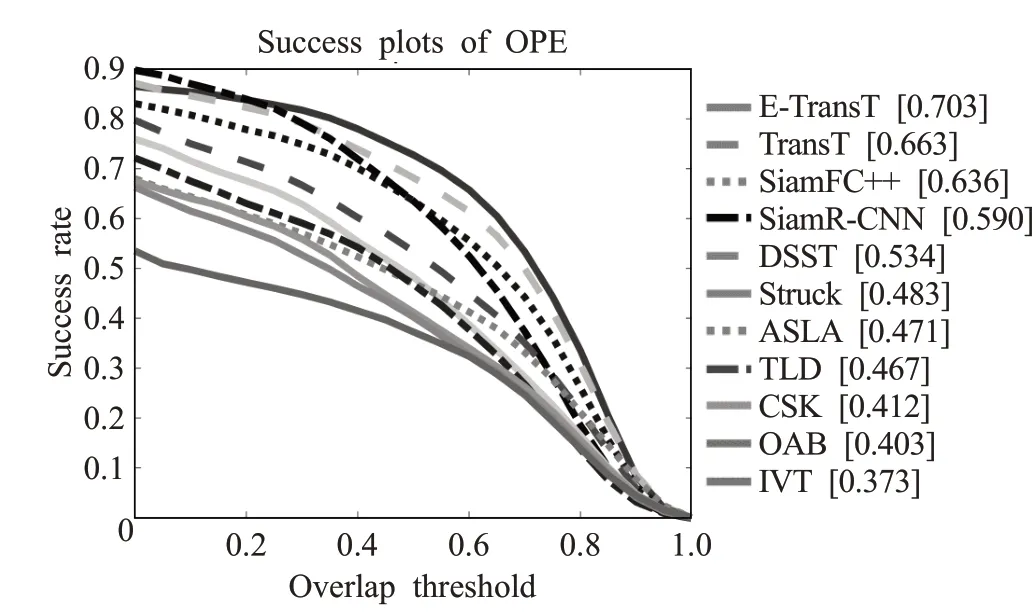
圖6 多種算法在OTB-2015上平均重合度歸一化測試結果Fig.6 Average overlap(AO)normalization evaluation results for many algorithms on OTB-2015
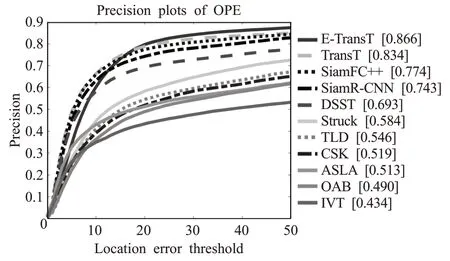
圖7 多種算法在OTB-2015上不同閾值歸一化測試結果Fig.7 Different thresholds normalization evaluation results for many algorithms on OTB-2015
3.3 消融實驗
為驗證本文算法中各改進算法的有效性,在OTB-2015 數據集上設計了消融實驗。為更明確各改進模塊在不同架構與不同參數下的有效性,采用了4種評價指標:MOP(mean overlap precision,平均重合度精度,閾值為0.5),MDP(mean distance precision,20 像素的平均距離精度);MCLE(mean center location error,平均中心位置誤差)以及FPS(幀率)。在網絡結構方面,隨著卷積層的加深,訓練參數量也隨之增加,為了更好地適應跟蹤任務的需求。淺層網絡是本文算法開展研究的前提。綜上,設計的消融實驗配置如表4所示。

表4 消融研究配置Table 4 Configurations of ablation study
為了探究PSA 模塊對骨干網絡的有效性以及稀疏自注意力替換多頭自注意力的橫向比較有效性,設計了如表4所述的4種不同類型的跟蹤器。通過控制PSA的數量以及自注意力模塊來實現消融過程。
消融實驗結果如表5 所示。在骨干網絡中引入PSA模塊后,平均重合度精度較原網絡有著2個百分點的提升,且隨著PSA 的引入數量增加,可實現平均重合度精度的進一步提升;在引入稀疏自注意力后,在平均重合度精度、20像素的平均距離精度和平均中心位置誤差這3個指標中最優。可見,改進的模塊在模型性能優化過程中具有有效性與可依賴性。此過程還完成了稀疏注意力與多頭注意力的橫向對比,驗證了稀疏自注意力能夠更適應跟蹤任務需求。

表5 消融實驗結果Table 5 Results of ablation study
3.4 結果可視化
算法可視化結果如圖8 所示。圖8(a)中,第108 和126 幀,由于目標被遮擋,TransT 跟蹤框已經發生偏移,第439幀由于目標姿態發生變化,TransT跟蹤框僅框定目標部分,而本文算法仍能框定目標。在快速運動與目標形變的圖8(b)中,從首幀時的整個手掌張開,到第36幀手掌快速移動,到第59幀時目標發生形變,本文算法都能準確框定目標,TransT 僅能標定目標一部分,整個過程也未能完整框定目標,表明本文算法對目標快速移動和目標外形變化跟蹤時有較強的魯棒性。圖8(c)中,第159幀由于目標從左側行駛至右側,過程中目標正臉被遮擋,但所有算法均未受到太大影響,第1 265幀由于鏡頭變化導致目標尺度發生變化,TransT跟蹤框發生偏移,而本文算法可精確框定目標。圖8(d)中,第33幀和105 幀由于目標發生形變與姿態變化,TransT 跟蹤框產生跟蹤偏移,至251 幀相似目標出現,TransT 跟蹤框完全偏移目標,而本文算法更加精確地跟蹤目標。
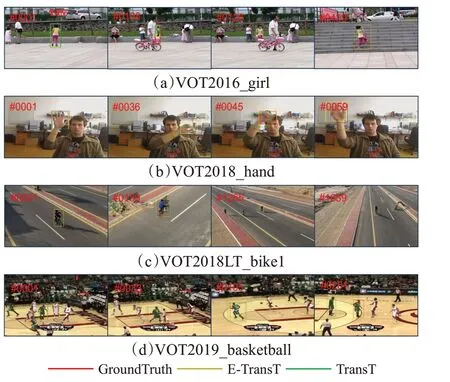
圖8 算法對比可視化結果Fig.8 Comparison of algorithm visualization results
4 結束語
本文在經典TransT算法的基礎上,提出一種基于稀疏自注意力的Transformer架構目標跟蹤算法E-TransT,減少了多次特征增強時參與運算的參數量,在降低算力消耗的同時改進了雙輸入結構對于圖像多尺度信息的處理方式。實驗表明,本文算法在多個測試集中有著最好的性能評價指標,這將有利于后續對算法的進一步改進提升。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
