判別卷積神經(jīng)網(wǎng)絡(luò)的手寫字符識別模型
2023-11-27 05:35:08屈喜文胡冕軍
計算機工程與應(yīng)用 2023年22期
關(guān)鍵詞:模型
屈喜文,吳 響,胡冕軍,黃 俊
安徽工業(yè)大學(xué) 計算機科學(xué)與技術(shù)學(xué)院,安徽 馬鞍山243000
根據(jù)輸入數(shù)據(jù)的類型,手寫字符識別可分為聯(lián)機手寫字符識別和離線手寫字符識別兩種。聯(lián)機手寫字符識別的數(shù)據(jù)是坐標(biāo)序列,通常被應(yīng)用于人機交互設(shè)備中,例如手寫板、智能手機、平板電腦等。離線手寫字符識別的處理對象是圖像類數(shù)據(jù),已經(jīng)被廣泛應(yīng)用于銀行支票識別、字體識別、信函分揀、各類統(tǒng)計數(shù)據(jù)表格處理以及手寫文稿識別。目前詩歌、手寫文本等的識別也可被分割為字符,然后結(jié)合語義上下文進行識別,因此手寫字符識別有廣泛的應(yīng)用價值。手寫字符識別的研究已經(jīng)持續(xù)多年,并且取得了很多卓越的研究成果[1-3],近年來深度學(xué)習(xí)在聯(lián)機/離線手寫字符識別領(lǐng)域展現(xiàn)出了明顯的優(yōu)勢[3-4]。
在離線手寫字符識別方面,Yang 等提出了原型卷積網(wǎng)絡(luò),為了使原型網(wǎng)絡(luò)獲取判別能力,結(jié)合多種原型學(xué)習(xí)損失函數(shù)(如最小分類誤差損失函數(shù)、基于邊緣的分類損失函數(shù)、基于距離的交叉熵損失函數(shù)以及一對多損失函數(shù))設(shè)計了多種判別損失函數(shù)[5]。該卷積原型網(wǎng)絡(luò)可以端到端聯(lián)合訓(xùn)練卷積網(wǎng)絡(luò)和每個類的優(yōu)化原型,相較于softmax 損失函數(shù),在公開的手寫字符數(shù)據(jù)集上獲得了更高的識別精度。文獻[5]提出的判別損失函數(shù)相比softmax 損失函數(shù)顯著提高了模型判別能力,但是在參數(shù)優(yōu)化過程中softmax 求導(dǎo)更為方便,模型更容易收斂。
在聯(lián)機手寫字符識別方面,卷積神經(jīng)網(wǎng)絡(luò)的輸入是圖像,而聯(lián)機手寫字符是由坐標(biāo)序列構(gòu)成,因此基于卷積神經(jīng)網(wǎng)絡(luò)的模型需要先將坐標(biāo)序列轉(zhuǎn)換為圖像,如轉(zhuǎn)換為八方向特征模式圖[6]。而坐標(biāo)序列到圖像的轉(zhuǎn)換往往要結(jié)合具體領(lǐng)域知識挖掘上下文信息[7-9],轉(zhuǎn)換過程難免造成信息丟失。另外,現(xiàn)有的基于卷積神經(jīng)網(wǎng)絡(luò)的模型在增加卷積層后往往會因為參數(shù)膨脹而導(dǎo)致訓(xùn)練困難,識別精度下降。基于循環(huán)神經(jīng)網(wǎng)絡(luò)的模型擅長處理序列數(shù)據(jù),可以端到端識別聯(lián)機手寫字符[10-11],避免了因為數(shù)據(jù)格式轉(zhuǎn)換導(dǎo)致的信息損失。循環(huán)神經(jīng)網(wǎng)絡(luò)模型能夠挖掘時序數(shù)據(jù)中上下文關(guān)系,但是缺乏獲取字符宏觀結(jié)構(gòu)信息的能力,由于網(wǎng)絡(luò)結(jié)構(gòu)限制,也不能識別離線手寫字符。相對于循環(huán)神經(jīng)網(wǎng)絡(luò),卷積神經(jīng)網(wǎng)絡(luò)模型既可以識別離線手寫字符,也可以識別在線手寫字符,更擅長學(xué)習(xí)字符的宏觀結(jié)構(gòu)信息,結(jié)合具體領(lǐng)域知識和數(shù)據(jù)格式變換技術(shù),卷積神經(jīng)網(wǎng)絡(luò)在聯(lián)機手寫字符識別方面有望進一步提高識別精度。另一方面,現(xiàn)有的應(yīng)用于手寫字符識別的深度模型,不管是基于卷積神經(jīng)網(wǎng)絡(luò)的模型,還是基于循環(huán)神經(jīng)網(wǎng)絡(luò)的模型,一般是使用softmax 損失函數(shù)進行訓(xùn)練。softmax 損失函數(shù)缺乏從不同類樣本中學(xué)習(xí)判別信息的能力[9-10]。手寫字符中存在大量的相似字,它們之間的差別很小,需要采用更強判別能力的分類模型進行識別。
綜上所述,為了在增加模型深度的同時盡可能控制模型參數(shù)數(shù)量,本文提出的模型分為編碼器和解碼兩部分。編碼器將原始數(shù)據(jù)轉(zhuǎn)換為固定數(shù)量的特征圖,避免了由于卷積層不斷擴張堆疊造成參數(shù)劇增、難以訓(xùn)練的問題。為進一步提高模型的判別能力,本文提出了一種判別損失函數(shù)。該損失函數(shù)通過最小化每一個訓(xùn)練樣本與其同類的優(yōu)化原型的余弦距離獲取判別信息。因為優(yōu)化原型由最小化分類誤差算法[12]學(xué)習(xí)得到,本身具有判別信息,所以判別損失函數(shù)訓(xùn)練模型時,其全連接層的輸出特征向量向優(yōu)化原型靠攏,從而提升了模型的判別能力。本文的主要貢獻總結(jié)如下:
(1)提出了編碼器與解碼器組成的深度卷積神經(jīng)網(wǎng)絡(luò)模型,該模型有效增加了網(wǎng)絡(luò)深度且易于訓(xùn)練;
(2)提出了一種判別損失函數(shù),該函數(shù)保留了softmax易于收斂的優(yōu)點,和softmax不同的是,該損失函數(shù)能夠從不同類樣本中獲取判別信息;
(3)提出的判別卷積神經(jīng)網(wǎng)絡(luò)模型既適用于在線手寫字符識別,也可用于離線手寫字符識別。
1 判別卷積神經(jīng)網(wǎng)絡(luò)的手寫字符識別流程
本文離線/聯(lián)機手寫字符識別算法流程如圖1所示,包括預(yù)處理、提取八方向特征模式圖、判別卷積神經(jīng)網(wǎng)絡(luò)幾部分。對于離線手寫字符,本文直接將原始數(shù)據(jù)作為模型輸入。對于聯(lián)機手寫字符,本文使用八方向特征提取算法[6]將坐標(biāo)序列轉(zhuǎn)換為八方向特征模式圖,然后輸入神經(jīng)網(wǎng)絡(luò)模型。因此本文提出的模型既適用于聯(lián)機手寫字符識別,也適用于離線手寫字符識別。
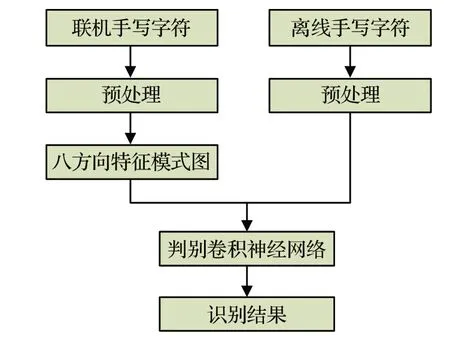
圖1 算法流程Fig.1 Algorithm flow chart
1.1 預(yù)處理
由于不同書寫者的書寫風(fēng)格各不相同,寫出的同類字符有的高有的矮,有的寬有的窄,有的端正有的傾斜,這種類內(nèi)的差異會降低分類器識別率,需要對原始數(shù)據(jù)進行預(yù)處理,以減少類內(nèi)偏差。
對于聯(lián)機手寫字符本文采取的預(yù)處理步驟總結(jié)如下:(1)將原始坐標(biāo)映射到64×64像素大小的圖像上,并用點生成算法bresenham連接離散點。(2)采用非線性規(guī)范方法[13]使坐標(biāo)點分布更加均衡。(3)經(jīng)過上述步驟處理的字符軌跡可能包含一些重復(fù)點和斷點,通過對比前后點的坐標(biāo),刪除重復(fù)點,并使用bresenham算法連接斷點。(4)對字符坐標(biāo)序列重新采樣,重采樣間隔為2個坐標(biāo)點。聯(lián)機手寫字符“徽”的預(yù)處理效果如圖2所示,從左往右依次是原始字符和步驟(1)到(4)的處理結(jié)果。

圖2 預(yù)處理示例Fig.2 Example of preprocessing
由于離線手寫字符數(shù)據(jù)是圖像,本文對于離線手寫字符的預(yù)處理是將離線手寫字符圖像統(tǒng)一為固定大小圖像,然后輸入卷積網(wǎng)絡(luò)進行識別。
1.2 提取八方向特征模式圖
經(jīng)過預(yù)處理后,本文采用八方向特征投影技術(shù)[6]將聯(lián)機手寫漢字坐標(biāo)序列中連續(xù)兩個點的方向矢量分解投影到八個方向上,每個方向?qū)?yīng)一個方向模式圖,方向模式圖的大小為64×64。為了盡可能保存原始數(shù)據(jù)中的信息,本文對八方向特征模式圖不經(jīng)過濾波處理,直接將投影得到的八方向特征模式圖作為卷積神經(jīng)網(wǎng)絡(luò)的輸入。“安徽”兩字的八方向模式圖如圖3所示,從左往右依次是原始字符及其相應(yīng)的八個方向的特征模式圖。
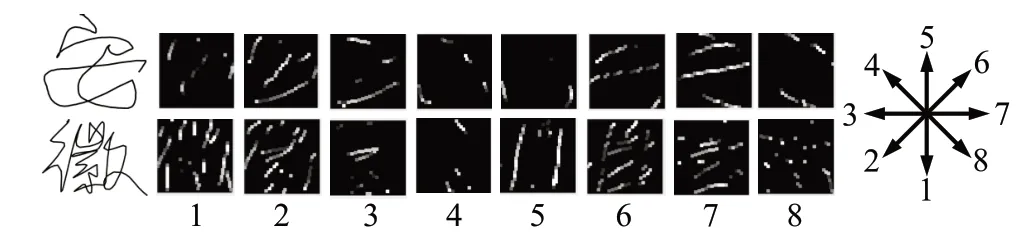
圖3 八方向模式圖示例Fig.3 Example of 8-directional pattern maps
1.3 卷積神經(jīng)網(wǎng)絡(luò)模型的搭建
本文提出的判別卷積神經(jīng)網(wǎng)絡(luò)模型如圖4所示,由編碼器和解碼器兩部分構(gòu)成。對于聯(lián)機手寫字符輸入是八方向特征模式圖,對于離線手寫字符輸入是統(tǒng)一尺寸后的圖像,網(wǎng)絡(luò)的所有卷積層都使用批規(guī)范化[14]解決分布變化問題,并加速神經(jīng)網(wǎng)絡(luò)的訓(xùn)練。激活函數(shù)采用非線性Leaky-ReLU[15]。
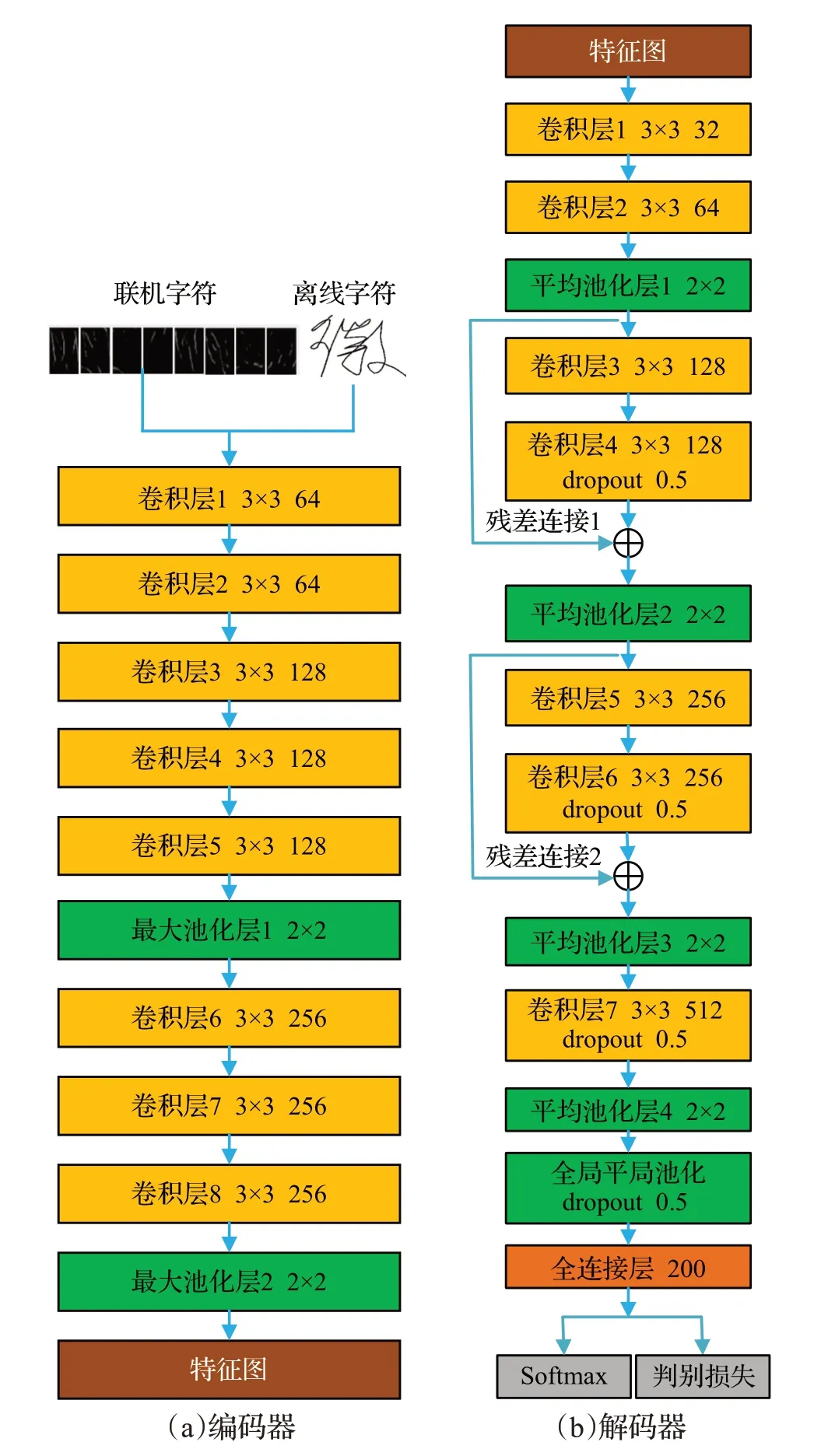
圖4 判別卷積神經(jīng)網(wǎng)絡(luò)模型Fig.4 Discriminative convolutional neural network model
1.3.1 編碼器
如圖4(a)所示,編碼網(wǎng)絡(luò)共有8 個卷積層,所有卷積核的大小為3×3,步長為1,填充為1。在第5和第8卷積層之后使用最大池化,最大池化大小為2×2,步長為2。在編碼網(wǎng)絡(luò),本文將特征圖數(shù)量從輸入的8張?zhí)卣髂J綀D或者離線字符的8張圖像增加到256。將編碼器輸出特征圖數(shù)量設(shè)置為256,并作為解碼器的輸入,從而避免了直接堆疊卷積層網(wǎng)絡(luò)時特征圖數(shù)量增加導(dǎo)致的參數(shù)劇增,有利于控制參數(shù)數(shù)量,增加網(wǎng)絡(luò)深度。
1.3.2 解碼器
解碼網(wǎng)絡(luò)如圖4(b)所示,共有7 層卷積層,卷積層參數(shù)設(shè)置與編碼網(wǎng)絡(luò)相同。為了提高計算效率,從編碼網(wǎng)絡(luò)提取的特征圖通過第一層卷積投影到32 張?zhí)卣鲌D,特征圖數(shù)量從32增加到512。為提高網(wǎng)絡(luò)模型對手寫字符多變的筆劃順序和結(jié)構(gòu)的魯棒性,使用平均池化,平均池大小為2×2,步長為2。在全連接層前使用了全局平局池化[16]以兼顧手寫字符的整體結(jié)構(gòu),減少參數(shù)數(shù)量。通過向解碼網(wǎng)絡(luò)中添加殘差連接1和殘差連接2以解決梯度消失問題,加快網(wǎng)絡(luò)的訓(xùn)練速度[17]。在卷積層4、卷積層6、卷積層7以及全局池化層使用了dropout[18],dropout 的隨機丟失率設(shè)置為0.5,以提高網(wǎng)絡(luò)的泛化能力,防止過擬合。最后,使用softmax 層和判別softmax層進行分類。本文網(wǎng)絡(luò)的訓(xùn)練步驟如下:先使用訓(xùn)練數(shù)據(jù)預(yù)訓(xùn)練圖4所示卷積神經(jīng)網(wǎng)絡(luò)模型,之后去掉softmax層,將上述網(wǎng)絡(luò)模型作為特征提取器,提取每個訓(xùn)練樣本的特征,由于最后一個全連接層有200 個節(jié)點,提取的特征是200 維的向量。使用提取的特征向量和最小化分類誤差算法[12]學(xué)習(xí)每個類的優(yōu)化原型,然后最小化特征向量與優(yōu)化原型之間的余弦距離再次訓(xùn)練網(wǎng)絡(luò)模型。由于優(yōu)化原型具有判別信息,判別的softmax 可以使深度神經(jīng)網(wǎng)絡(luò)獲得判別能力,即同類之間更加緊縮,不同類之間更加分離。
1.4 判別損失函數(shù)
本文預(yù)訓(xùn)練時使用的softmax損失函數(shù)如下:
其中L表示損失,m表示批量訓(xùn)練時每一批樣本的數(shù)量,s=1,2,…,m,ys=1,2,…,C,ys是樣本xs的類標(biāo),C表示類別總數(shù),bys和bj是偏置項,wj是對應(yīng)于第j個類的模型參數(shù),j=1,2,…,C。式(1)中的softmax 損失函數(shù)易于求導(dǎo),在訓(xùn)練模型過程中易于收斂,但是該損失函數(shù)不具備從不同類樣本中學(xué)習(xí)判別信息的能力。為了提高卷積神經(jīng)網(wǎng)絡(luò)的判別能力,本文提出了判別損失函數(shù),具體如下:
其中τ為調(diào)節(jié)因子。式(2)中的dj可由下式求得:
其中qj是第j個類的優(yōu)化原型。式(2)中的判別損失函數(shù)和softmax 損失函數(shù)相同之處在于易于求導(dǎo),訓(xùn)練過程中,神經(jīng)網(wǎng)絡(luò)模型易于收斂。和softmax 損失函數(shù)不同之處在于最小化式(2)中判別損失函數(shù)時,dj也就相應(yīng)最小化,即等價于最小化式(3)中表示的樣本特征與優(yōu)化原型之間的余弦距離。優(yōu)化原型由最小化分類誤差算法學(xué)習(xí)得到,具有判別信息,因此由該判別損失函數(shù)訓(xùn)練得到的模型也就具備了更強的判別能力。對比式(1)和式(2)可以看出,softmax損失函數(shù)中有權(quán)值,而判別損失函數(shù)中沒有權(quán)值,因此判別損失函數(shù)比softmax損失函數(shù)節(jié)省存儲空間。
1.5 最小化分類誤差算法
最小化分類誤差算法[12]是一種優(yōu)化分類器參數(shù),提高分類器判別能力的算法。該算法基于分類器分類規(guī)則定義了一個損失函數(shù),并使用隨機梯度下降法在給定訓(xùn)練集上最小化該損失函數(shù),以尋求最佳分類器參數(shù)。特征提取器提取的特征向量xci∈R1×200,其中ci表示第c類的第i個樣本,且c=1,2,…,C。K-NN分類器在K=1 時的分類規(guī)則為:
其中j=1,2,…,C,qj表示第j個類的優(yōu)化原型。每個樣本xci的分類損失可定義為:
其中qc是樣本xci所屬第c類的優(yōu)化原型,qr是的最近對手類的優(yōu)化原型,r=1,2,…,C且r≠c。的分類損失可寫為:
其中?是調(diào)節(jié)因子。優(yōu)化目標(biāo)函數(shù)為:
其中N表示訓(xùn)練樣本總數(shù),nc表示第c個類的訓(xùn)練樣本數(shù)。本文通過隨機梯度下降法求解式(7)中所有類的優(yōu)化原型qc,c=1,2,…,C。由式(6)對類別原型qc和qr求偏導(dǎo)可得:
在隨機梯度下降法求解過程中,因為樣本xci僅僅涉及兩個類的原型qc和qr,所以qc和qr可由式(9)更新:
其中σ(t)是學(xué)習(xí)率,t是迭代次數(shù)。將式(8)帶入到式(9)得:
式(10)中σ(t)包含了調(diào)節(jié)因子?。在本文后面的實驗中,每個類的原型數(shù)量根據(jù)經(jīng)驗確定為1,每次迭代后的衰減率為σ(t+1)=0.95×σ(t),迭代終止條件為 |l0(t+1)-l0(t)|<0.001。通過本節(jié)所述優(yōu)化算法即可學(xué)習(xí)得到每個類的優(yōu)化原型。
2 實驗結(jié)果與分析
2.1 數(shù)據(jù)集
本文在公共數(shù)據(jù)集IAHCC-UCAS2016[4]和MNIST[19]上進行實驗。MNIST 是離線手寫字符識別經(jīng)典數(shù)據(jù)集,該數(shù)據(jù)集涉及0~9 共10 個類,分為訓(xùn)練集和測試集兩部分,訓(xùn)練集有60 000個訓(xùn)練樣本,測試集包含10 000個測試樣本。
IAHCC-UCAS2016 是一個空中手寫漢字數(shù)據(jù)集,該數(shù)據(jù)集包含GB/T2312—1980 一級字庫的3755 個字符類,另外還包含二級字庫中的56個常用漢字,每個類有115 個樣本。在IAHCC-UCAS2016 數(shù)據(jù)集上進行5折交叉驗證,最終識別率為5次實驗平均實驗結(jié)果。
2.2 模型參數(shù)設(shè)置
本文所有的實驗都是在RTX-2080ti 上進行,基于PyTorch 平臺構(gòu)建網(wǎng)絡(luò)模型,使用平臺的默認參數(shù)進行初始化。優(yōu)化器使用Adam[20],最小批量設(shè)置為256,初始學(xué)習(xí)率設(shè)置為0.001。當(dāng)訓(xùn)練集上的準確度不再增加或緩慢增加時,降低學(xué)習(xí)率(衰減率為0.1)。在優(yōu)化原型學(xué)習(xí)階段,式(10)中初始學(xué)習(xí)率σ(1)在MNIST 數(shù)據(jù)集上取0.05/nc,在空中手寫數(shù)據(jù)集IAHCC-UCAS2016上取1/nc,nc表示第c個類的訓(xùn)練樣本數(shù)量。本文通過實驗選擇調(diào)節(jié)因子τ。為快速找出合適的調(diào)節(jié)因子,在IAHCC-UCAS2016中選擇前300個類進行實驗。MNIST中使用訓(xùn)練數(shù)據(jù)進行實驗,實驗結(jié)果如圖5 所示。從圖5 可以看出MNIST 上調(diào)節(jié)因子在0.5 附近,IAHCCUCAS2016 上調(diào)節(jié)因子在12 附近能夠達到更高的識別率。本文在兩個數(shù)據(jù)集上調(diào)節(jié)因子分別取0.5和12.5。
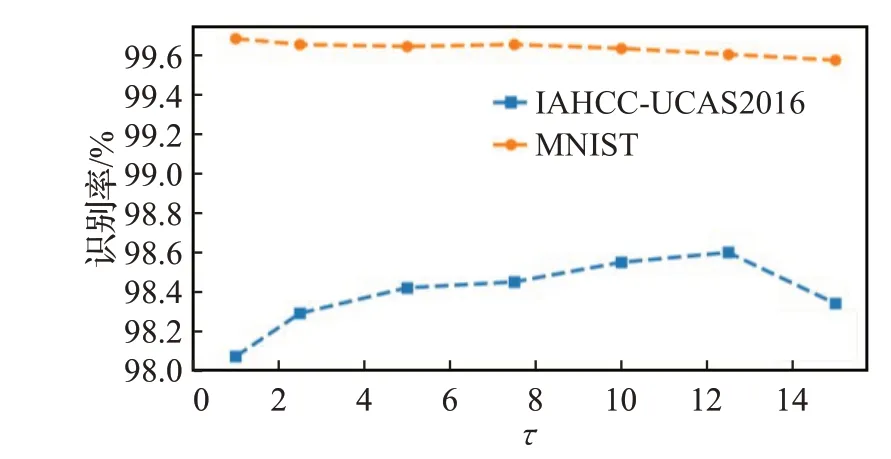
圖5 不同調(diào)節(jié)因子在兩種數(shù)據(jù)集上的識別率Fig.5 Recognition rate of different regulatory factors on two datasets
2.3 實驗結(jié)果及分析
本文中計算識別準確率R的公式為:
其中Nt表示測試集中樣本總數(shù),Nc表示測試集中識別結(jié)果正確的樣本數(shù)。
本文在兩個數(shù)據(jù)集上比較了softmax損失函數(shù)和提出的判別損失函數(shù)的識別率,識別結(jié)果如表1所示。

表1 兩種損失函數(shù)在不同數(shù)據(jù)集上的識別率Table 1 Recognition rate of two loss functions on different datasets 單位:%
從表1 中可以看出,提出的判別損失函數(shù)訓(xùn)練得到的模型在IAHCC-UCAS2016 數(shù)據(jù)集上的識別率比softmax 損失函數(shù)高1.04 個百分點。在MNIST 數(shù)據(jù)集上,在識別率高達99.5%以上的情況下,提出的判別損失函數(shù)仍然比softmax損失函數(shù)高出0.14個百分點。分析實驗結(jié)果中使用softmax損失函數(shù)識別錯誤的字符可以發(fā)現(xiàn),相似字的存在是影響識別精度進一步提高的主要因素,由于相似字之間的差異很小,如“己”和“已”,加上書寫過程中連筆和省略等因素,導(dǎo)致寫成的文字極難區(qū)分。空中手寫數(shù)據(jù)集IAHCC-UCAS2016的相似字樣本如圖6 所示。判別損失函數(shù)通過將樣本特征向優(yōu)化原型收縮,從而加強了網(wǎng)絡(luò)的判別能力,提高了對相似字的識別能力,從而獲得了更高的識別率。從式(1)和式(2)中可以看出,softmax 需要存儲權(quán)值,而提出的判別損失函數(shù)沒有權(quán)值,因此softmax 比提出的損失函數(shù)多消耗0.01 MB的存儲空間。

圖6 數(shù)據(jù)集IAHCC-UCAS2016中樣本示例Fig.6 Sample examples in IAHCC-UCAS2016 dataset
本文將提出的模型與相似模型以及近幾年出現(xiàn)的高性能分類器進行了對比。表2 和表3 分別是本文模型和其他模型在數(shù)據(jù)集MNIST 和IAHCC-UCAS2016上的對比結(jié)果。

表2 不同方法在數(shù)據(jù)集MNIST上的識別率Table 2 Recognition accuracy of different methods on MNIST dataset 單位:%
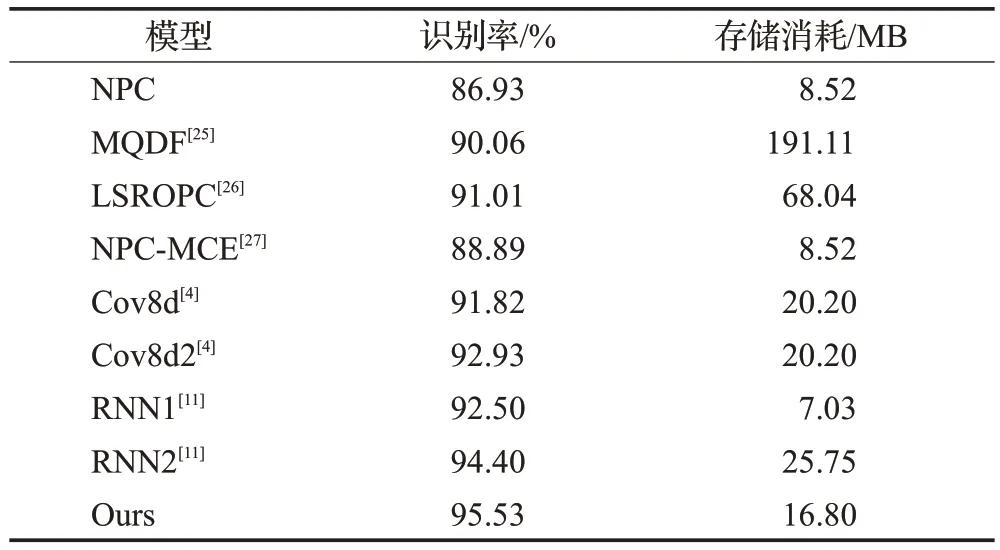
表3 在IAHCC-UCAS2016上不同方法的性能比較Table 3 Performance comparison of different methods on IAHCC-UCAS2016 dataset
從表2 和表3 中可以看出,本文模型在兩個數(shù)據(jù)集IAHCC-UCAS2016和MNIST上均獲得了最高的識別精度,識別率分別達到了95.53%和99.73%,從而證明了本文模型既適用于離線字符識別,也適用于聯(lián)機手寫字符識別。
相較于經(jīng)典的傳統(tǒng)模型MQDF[25]和LSROPC[26],本文模型識別率提高了4.5個百分點以上。由于神經(jīng)網(wǎng)絡(luò)模型對于各個類實現(xiàn)了參數(shù)共享,而MQDF和LSROPC等傳統(tǒng)方法各個類的分類參數(shù)是獨立的,因此本文模型存儲消耗僅16.8 MB,遠小于MQDF 的191.11 MB 和LSROPC 的68.04 MB。相比較應(yīng)用于空中手寫漢字識別的卷積神經(jīng)網(wǎng)絡(luò)模型Cov8d[4]和循環(huán)神經(jīng)網(wǎng)絡(luò)模型RNN1[11],本文模型在識別精度上分別提高了3.71 個百分點和3.03 個百分點。相對于使用了樣本增強技術(shù)的卷積神經(jīng)網(wǎng)絡(luò)模型Cov8d2[4]和使用了分類器組合技術(shù)的循環(huán)網(wǎng)絡(luò)模型RNN2[11],本文模型不僅識別率分別提高了2.60個百分點和1.13個百分點,并且存儲消耗也更小。
3 結(jié)束語
針對現(xiàn)有的基于卷積神經(jīng)網(wǎng)絡(luò)的手寫字符識別模型在卷積層堆疊過程中造成參數(shù)劇增和精度下降問題,本文提出了一種結(jié)合解碼器和編碼器的卷積神經(jīng)網(wǎng)絡(luò)模型。該模型通過控制解碼器輸出特征圖數(shù)量,避免了模型參數(shù)因為網(wǎng)絡(luò)深度增加而劇增的問題。為進一步提高模型判別能力,本文提出了一種判別損失函數(shù)。實驗結(jié)果表明,提出的判別損失函數(shù)比softmax 損失函數(shù)可以有效提高識別精度。與現(xiàn)有的手寫字符識別模型相比,本文提出的判別卷積神經(jīng)網(wǎng)絡(luò)模型在聯(lián)機/離線手寫字符識別上獲得了更高的識別精度。
但是本文提出的模型仍然需要結(jié)合領(lǐng)域知識將聯(lián)機手寫字符的坐標(biāo)序列轉(zhuǎn)換為圖像,這種轉(zhuǎn)換不可避免地造成了信息損失。在保證識別精度情況下,不經(jīng)過數(shù)據(jù)格式轉(zhuǎn)換,通過改變卷積核尺寸,端到端識別聯(lián)機手寫字符的卷積神經(jīng)網(wǎng)絡(luò)模型將是進一步的研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
