結(jié)合顯著特征篩選和ViT的面部表情識(shí)別方法
2023-11-27 05:35:04封紅旗黃偉鎧張登輝
計(jì)算機(jī)工程與應(yīng)用 2023年22期
封紅旗,黃偉鎧,張登輝
1.常州大學(xué) 計(jì)算機(jī)與人工智能學(xué)院,江蘇 常州213100
2.浙江樹人大學(xué) 信息科技學(xué)院,杭州310000
人臉面部表情是人類表達(dá)情感狀態(tài)和意圖最有力、最自然和最普遍的信號(hào)之一[1]。面部表情識(shí)別技術(shù)在社交機(jī)器人、醫(yī)療診斷、疲勞監(jiān)測(cè)等人機(jī)交互領(lǐng)域有著非常廣泛的應(yīng)用[2]。目前異地獨(dú)居人口日益增多[3],幫助他們獲得情感慰藉是當(dāng)前社會(huì)重點(diǎn)關(guān)注的問題。一些研究人員將研究重心傾注在情感交互機(jī)器人上,其原因?yàn)榍楦袡C(jī)器人能夠從文字、語(yǔ)音、人臉面部特征等多方面理解人類情感狀態(tài)并與之交互,從而能在人們獨(dú)居生活中給予他們貼心的互動(dòng)交流。然而在真實(shí)的人機(jī)交互過程中,人們通常會(huì)執(zhí)行一系列動(dòng)態(tài)行為(轉(zhuǎn)頭、行走、拿取物品、開關(guān)燈等),這可能會(huì)導(dǎo)致機(jī)器人通過攝像頭捕捉到的面部圖像受到遮擋、姿態(tài)變化、光照等因素影響,進(jìn)而降低表情識(shí)別的準(zhǔn)確率。
受Transformer 在計(jì)算機(jī)視覺領(lǐng)域成功應(yīng)用的啟發(fā),本文提出了一種結(jié)合顯著特征篩選和視覺轉(zhuǎn)化器的優(yōu)化模型(distinguishing feature filtering and vision transformer,DFFViT),通過篩選顯著人臉面部特征并映射為特征單詞序列,來更準(zhǔn)確地描述在不利因素影響下的面部情感狀態(tài)。首先,采用加權(quán)求和光照歸一化方法(weighted sum illumination normalization,WSIN)削弱光照對(duì)表情識(shí)別的影響,并利用卷積神經(jīng)網(wǎng)絡(luò)來提取圖像的面部特征。其次,采用顯著特征篩選模塊(distinguishing feature filtering,DFF)聚合面部的局部-全局上下文,過濾特征中的無效信息,篩選顯著細(xì)節(jié)信息,提高表情識(shí)別性能。緊接著,通過切片、展平和投影操作,將二維特征映射為一維單詞序列,并饋送到多層Transformer編碼器(multi-layer transformer encoder,MTE)中加強(qiáng)面部特征之間的聯(lián)系,從而提高模型的特征學(xué)習(xí)能力。最后,使用Softmax函數(shù)對(duì)學(xué)習(xí)結(jié)果進(jìn)行表情預(yù)測(cè)。
1 相關(guān)工作
1.1 面部表情識(shí)別
人臉面部表情識(shí)別主要包括三個(gè)階段[2]:人臉圖像收集與檢測(cè)、面部特征提取和表情識(shí)別。在真實(shí)環(huán)境下,面部圖像會(huì)受到遮擋、姿態(tài)變化等因素的影響,因此準(zhǔn)確提取面部特征是至關(guān)重要的環(huán)節(jié)。
卷積神經(jīng)網(wǎng)絡(luò)憑借強(qiáng)大的特征提取能力取代了傳統(tǒng)方法,成為面部特征提取的主流方法之一。文獻(xiàn)[4]提出了一種基于改進(jìn)神經(jīng)網(wǎng)絡(luò)與支持向量機(jī)相結(jié)合的優(yōu)化模型,與傳統(tǒng)方法相比,具有良好的魯棒性。文獻(xiàn)[5]提出了一種改進(jìn)的LeNet-5 卷積神經(jīng)網(wǎng)絡(luò),將低層次特征和高層次特征相結(jié)合,取得了較好的性能。雖然研究人員使用卷積神經(jīng)網(wǎng)絡(luò)彌補(bǔ)了傳統(tǒng)工程方法在面部表情特征提取上的缺點(diǎn),但是當(dāng)面部圖像出現(xiàn)不確定因素時(shí),該方法很難準(zhǔn)確提取到反映真實(shí)面部表情的特征。
為此一些研究人員將注意力機(jī)制應(yīng)用于網(wǎng)絡(luò)模型中,使其能夠關(guān)注面部圖像中顯著的特征。Li等人[6]提出了一種帶有注意力機(jī)制的卷積神經(jīng)網(wǎng)絡(luò)(attention convolution neural network,ACNN),可以感知人臉的遮擋區(qū)域,并關(guān)注最具判別性的未遮擋區(qū)域。Wang等人[7]提出了區(qū)域注意網(wǎng)絡(luò)(region attention networks,RAN),能夠自適應(yīng)地捕捉面部區(qū)域在遮擋和姿態(tài)變化中的重要性。Wang等人[8]提出了自修復(fù)網(wǎng)絡(luò)(self-cure network,SCN),采用樣本排序正則化和低權(quán)重樣本的重標(biāo)簽機(jī)制,有效地抑制真實(shí)環(huán)境下面部表情識(shí)別的不確定性。上述研究雖然有效解決了遮擋、姿態(tài)等不利因素的影響,卻忽略了模型的特征學(xué)習(xí)能力。
為此,Amir 等人提出了深度注意中心損失算法(deep attentive center loss,DACL),在深度度量學(xué)習(xí)方法中集成注意機(jī)制,自適應(yīng)地選擇顯著特征,并增強(qiáng)特征學(xué)習(xí)的泛化能力。Ma 等人[10]提出了基于特征融合的視覺轉(zhuǎn)化器(visual transformers with feature fusion,VTFF),通過聚合多分支特征以豐富面部特征的表達(dá)能力,并采用多層Transformer 編碼器建立特征之間的聯(lián)系,有效提高了模型的學(xué)習(xí)能力。
1.2 光照歸一化
受光照條件的影響,不同圖像的對(duì)比度可能會(huì)存在差異。因此,即便是同一個(gè)人表現(xiàn)出相同的面部表情,但在不穩(wěn)定的光源環(huán)境下,識(shí)別結(jié)果也可能會(huì)產(chǎn)生較大的偏差[2]。為了削弱光照的影響,Ioannis 等人[11]提出了雙向重光照(bidirectional relighting)算法,以最小化紋理之間的光照差異,該方法具有更少的約束條件,有助于更廣泛地適用于一般光照歸一化。Virendra等人[12]采用低頻帶離散余弦變換[13]和對(duì)數(shù)變換相結(jié)合,自適應(yīng)地對(duì)圖像進(jìn)行光照歸一化。相關(guān)研究表明,結(jié)合直方圖均衡化的光照歸一化可以獲得更好的識(shí)別性能。但是對(duì)圖像采用單一的直方圖均衡化可能會(huì)導(dǎo)致圖像的局部對(duì)比度過度增強(qiáng),為此,本文采用文獻(xiàn)[14]提出的直方圖均衡化和線性變換加權(quán)求和的光照歸一化方法。
1.3 注意力機(jī)制
注意力機(jī)制能夠選擇性地聚焦具有鑒別性的細(xì)節(jié)信息,是提高模型魯棒性和識(shí)別性能的一個(gè)重要手段[15]。Woo 等人[15]提出了卷積塊注意力模塊(convolutional block attention module,CBAM),從通道和空間兩個(gè)維度依次計(jì)算注意力權(quán)重,并通過權(quán)重對(duì)特征進(jìn)行自適應(yīng)細(xì)化。Hu 等人[16]提出了擠壓與激勵(lì)模塊(squeeze-andexcitation,SE),通過顯式建模卷積特征通道之間的相互依賴關(guān)系,從而提高模型的表達(dá)能力。Dai 等人[17]提出了多尺度通道注意力模塊(multi-scale channel attention module,MS-CAM),利用注意力機(jī)制聚合局部特征和全局特征的上下文信息,并通過網(wǎng)絡(luò)的學(xué)習(xí)使融合權(quán)重最優(yōu)化,自適應(yīng)地關(guān)注具有判別性的特征。但本文實(shí)驗(yàn)發(fā)現(xiàn),將MS-CAM 模塊應(yīng)用于表情識(shí)別任務(wù)時(shí)會(huì)出現(xiàn)過擬合現(xiàn)象。
1.4 視覺轉(zhuǎn)化器
Transformer[18]憑借優(yōu)越的序列建模能力和全局信息感知能力,在自然語(yǔ)言處理領(lǐng)域得到廣泛使用,越來越多的研究人員開始將Transformer應(yīng)用到計(jì)算機(jī)視覺領(lǐng)域。Alexey等人[19]提出了視覺轉(zhuǎn)化器(vision transformer,ViT),這是Transformer 第一次被應(yīng)用于圖像任務(wù)。研究人員在此基礎(chǔ)上進(jìn)行深入探索,從而衍生出了許多ViT 的變體。Wang 等人[20]提出了金字塔視覺轉(zhuǎn)化器(pyramid vision transformer,PVT),能夠?qū)ransformer移植到各類密集預(yù)測(cè)任務(wù)。Wu等人[21]提出了卷積視覺轉(zhuǎn)化器(convolution vision transformer,CVT),將ViT與卷積運(yùn)算相結(jié)合,使卷積網(wǎng)絡(luò)的特性和Transformer的優(yōu)點(diǎn)得以融合。本文的DFFViT模型同樣為ViT的變體,通過加入光照歸一化和特征注意力模塊,使其適用于人機(jī)交互場(chǎng)景下的表情識(shí)別任務(wù)。
2 DFFViT模型
2.1 模型整體架構(gòu)
DFFViT 模型的總體架構(gòu)如圖1(a)所示,給定一個(gè)大小為3×H×W的面部表情圖像ImgORI,首先采用光照歸一化方法得到光照適中圖像ImgILL。緊接著采用在MS-Celeb-1M人臉數(shù)據(jù)集上預(yù)訓(xùn)練的ResNet18作為特征提取主干網(wǎng),以此提取大小為的特征映射XILL,其中Cout為輸出的通道數(shù),DS為下采樣的倍率,為了簡(jiǎn)化描述,定義。利用顯著特征篩選模塊聚合局部-全局上下文來關(guān)注大小為Cout×HDS×WDS的顯著特征XF。將顯著特征XF按特定大小切片成M個(gè)二維特征塊,并通過線性投影映射為一維特征向量,在特征向量頭部嵌入可學(xué)習(xí)的分類編碼[class],同時(shí)添加可學(xué)習(xí)的位置編碼Pos以保留位置信息,以此得到長(zhǎng)度為M+1 的視覺單詞序列,將單詞序列饋送到多層Transformer 編碼器,從而加強(qiáng)面部特征之間的聯(lián)系。
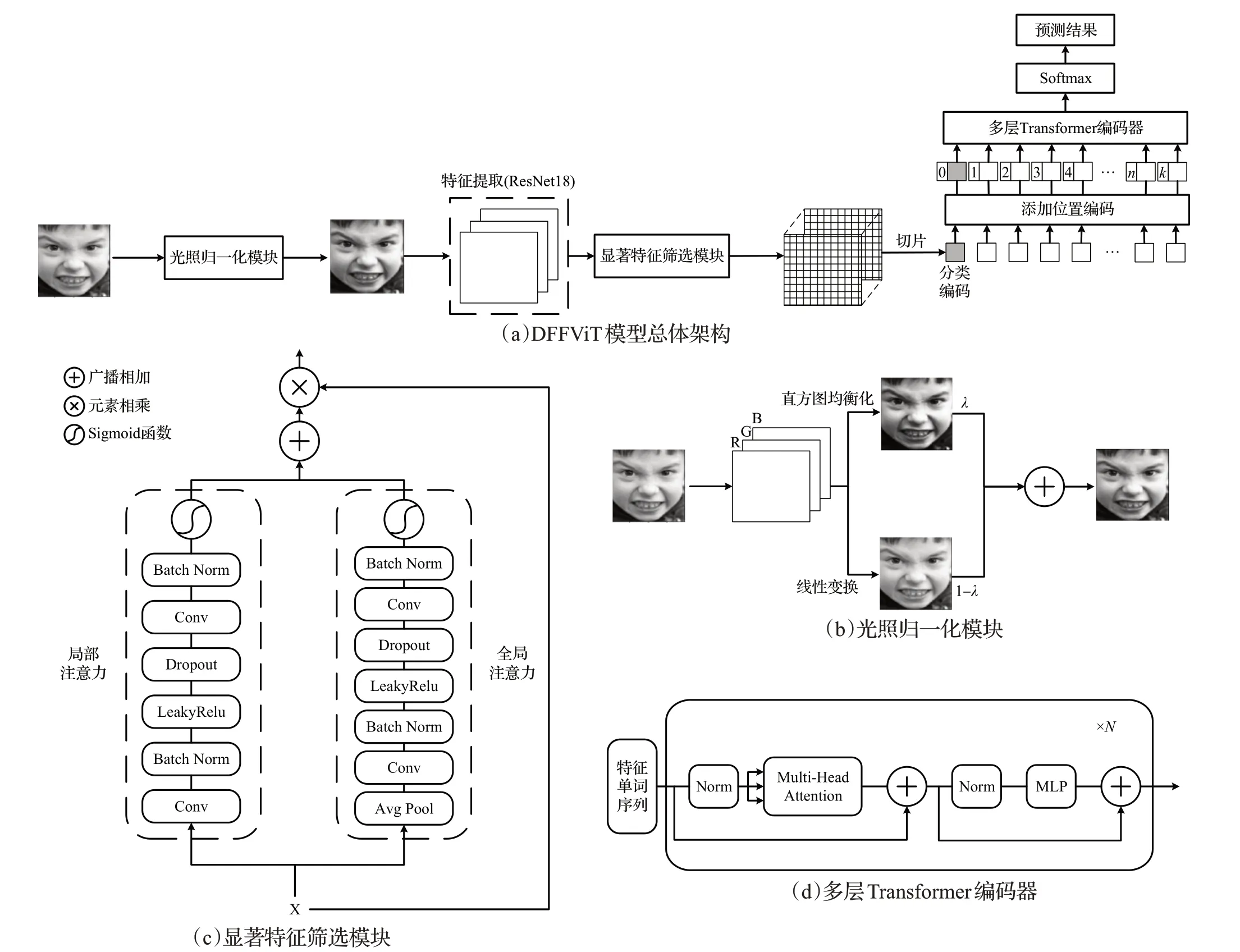
圖1 DFFViT模型總體架構(gòu)及模塊Fig.1 Overall architecture and modules of DFFViT model
2.2 光照歸一化模塊
真實(shí)環(huán)境下攝像頭捕捉的面部表情圖像通常都會(huì)受到不同光照的影響,這可能會(huì)阻礙模型的訓(xùn)練。為得到光照適中的面部圖像,本文采用了直方圖均衡化[22]和線性變換(將最小和最大像素映射到區(qū)間[0,1])加權(quán)求和的歸一化方法。如圖1(b)所示,給定一個(gè)大小為3×H×W的面部表情圖像ImgORI,首先分別獲得直方圖均衡化圖像ImgHE和線性變換圖像ImgHN,緊接著將ImgHE和ImgHN按適當(dāng)?shù)臋?quán)重融合成光照適中圖像ImgILL,具體可表示為:
式(1)中,δ表示權(quán)重因子,本文設(shè)置δ=0.5。三種光照歸一化方法的效果如圖2 所示。由圖可見單獨(dú)使用直方圖均衡化會(huì)過度增強(qiáng)圖像局部對(duì)比度,單獨(dú)使用線性變換在個(gè)別圖像上的效果并不理想。

圖2 三種光照歸一化方法的效果對(duì)比Fig.2 Comparison of effects of three illumination normalization methods
2.3 顯著特征篩選模塊
為了能夠自適應(yīng)地關(guān)注細(xì)微的表情變化和重要的面部特征,本文設(shè)計(jì)了DFF模塊。該模塊由局部注意力通道和全局注意力通道組成,模塊整體結(jié)構(gòu)如圖1(c)所示。給定特征映射,經(jīng)過雙分支注意力通道可計(jì)算得到局部注意力權(quán)重Local(X)∈和全局注意力權(quán)重Global(X),具體可表示為:
式(2)(3)中,AP表示全局自適應(yīng)平均池化,用于過濾無效面部信息;Conv1和Conv2表示逐點(diǎn)卷積(卷積核大小為1),以提取細(xì)節(jié)特征;BN表示批歸一化處理;D表示Dropout層,用于抑制過擬合,在本文中設(shè)置dropout=0.3;? 表示LeakyRelu 激活函數(shù);σ表示Sigmoid 函數(shù)。將雙分支注意力權(quán)重通過廣播加法進(jìn)行融合,得到局部-全局注意力權(quán)重LG(X),使用殘差連接,篩選出顯著特征。
DFF 模塊可視化如圖3 所示,可以看出未應(yīng)用DFF模塊時(shí)注意力分布較為分散,無法有效地關(guān)注具有辨別性的特征,而使用DFF模塊后注意力集中于表情細(xì)微變化位置。

圖3 DFF模塊的注意力可視化Fig.3 Attention visualization with DFF module
2.4 多層Transformer編碼器
其中,Conv表示輸入通道為Cout,輸出通道為Cf,卷積核與步長(zhǎng)為(P,P)的卷積層,用于分割顯著特征并進(jìn)行可學(xué)習(xí)的線性映射;Flatten表示展平操作。在特征序列頭部嵌入可學(xué)習(xí)的情感分類編碼[class],同時(shí)為該序列中的每個(gè)特征單詞添加可學(xué)習(xí)的位置編碼Pos∈以保留其位置信息,該特征序列可表示為:
采用多層Transformer 編碼器對(duì)特征序列Z0進(jìn)行處理,加強(qiáng)面部特征之間的關(guān)聯(lián)性,編碼器整體結(jié)構(gòu)如圖1(d)所示,每層Transformer 編碼器由多頭自注意模塊(multi-head attention,MHA)和多層感知器模塊(multilayer perceptron,MLP)組成,在每個(gè)模塊之前應(yīng)用歸一化,在每個(gè)模塊之后加入殘差連接,具體可表示為:
式(7)(8)(9)中k=1,2,…,N,表示在第k層經(jīng)過MHA模塊和殘差連接后得到的面部特征序列,Zk表示在第k層經(jīng)過MLP模塊和殘差連接后得到的面部特征序列,LN 表示歸一化,ZN表示經(jīng)過N層Transformer編碼器后得到的面部特征序列。本文中設(shè)置多頭數(shù)L=12,層數(shù)N=12。
最終,得到經(jīng)過多層Transformer 編碼器處理后的面部特征序列y,使用其頭部的情感分類編碼[class]以預(yù)測(cè)面部表情結(jié)果。
3 實(shí)驗(yàn)
3.1 數(shù)據(jù)集描述
RAF-DB[23]是真實(shí)世界的面部表情數(shù)據(jù)集,包含30 000張人臉面部圖像,其中每張面部圖像由40名訓(xùn)練有素的工作人員進(jìn)行標(biāo)注。RAF-DB 包含基本表情子集和復(fù)合表情子集,本實(shí)驗(yàn)只使用了具有6個(gè)基本情緒和1個(gè)中性情緒的基本表情子集,該集合涉及12 271個(gè)訓(xùn)練樣本和3 068個(gè)驗(yàn)證樣本。圖4為RAD-DB數(shù)據(jù)集示例圖像。

圖4 RAF-DB數(shù)據(jù)集中7種表情示例圖像Fig.4 7 kinds of facial expression images in RAF-DB dataset
FERPlus[24]是對(duì)FER2013數(shù)據(jù)集的擴(kuò)展,包含28 709個(gè)訓(xùn)練樣本和3 589 個(gè)驗(yàn)證樣本,其中每張面部圖像由10名工作人員進(jìn)行投票標(biāo)注,為了公平比較,采用多數(shù)投票策略為每張圖像篩選標(biāo)簽(篩除unknown和非人臉圖像)。圖5為FERPlus數(shù)據(jù)集示例圖像。

圖5 FERPlus數(shù)據(jù)集8種表情示例圖像Fig.5 8 kinds of facial expression images in FERPlus dataset
AffectNet[25]是目前最大的公共面部表情數(shù)據(jù)集,包含從互聯(lián)網(wǎng)上收集的45萬張面部圖像。本實(shí)驗(yàn)選取由手工標(biāo)注的具有8類基本情緒的圖像,其中包含286 621個(gè)訓(xùn)練樣本和4 000個(gè)驗(yàn)證樣本。圖6為AffectNet數(shù)據(jù)集示例圖像。

圖6 AffectNet數(shù)據(jù)集8種表情示例圖像Fig.6 8 kinds of facial expression images in AffectNet dataset
3.2 實(shí)現(xiàn)細(xì)節(jié)
本文采用Pytorch 搭建深度學(xué)習(xí)模型,實(shí)驗(yàn)環(huán)境參數(shù)(軟硬件配置)如表1所示。

表1 實(shí)驗(yàn)環(huán)境配置Table 1 Experimental environment configuration
本實(shí)驗(yàn)使用MTCNN 網(wǎng)絡(luò)[26]定位面部圖像中的人臉位置并裁剪,將裁剪后的圖像大小調(diào)整為256×256。進(jìn)行訓(xùn)練時(shí),將人臉圖像的大小隨機(jī)裁剪為224×224,并進(jìn)行隨機(jī)水平翻轉(zhuǎn),進(jìn)行測(cè)試時(shí),將人臉圖像的大小中心裁剪為224×224。
如圖7 所示,每隔100 批次獲取AffectNet數(shù)據(jù)集訓(xùn)練樣本的分布情況,并隨機(jī)展示其中的5 次分布結(jié)果,圖中X軸表示樣本批次,Y軸表示樣本數(shù)量。由圖7(a)可以看出AffectNet 數(shù)據(jù)集的訓(xùn)練樣本分布極度不平衡,因此采用Pytorch 提供的加權(quán)隨機(jī)過采樣策略(weighted random sampler)來平衡訓(xùn)練樣本,處理后的結(jié)果如圖7(b)所示,樣本分布與處理前相比得到了極大改善,削弱了樣本分布不平衡帶來的不利影響。
采用ResNet18 作為主干網(wǎng)絡(luò),在MS-Celeb-1M 人臉識(shí)別數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練,并使用最后一個(gè)池化層提取所需的面部特征,多層Transformer 編碼器加載在ImageNet21K 數(shù)據(jù)集上預(yù)訓(xùn)練權(quán)重。在所有的數(shù)據(jù)集上,批量大小設(shè)置為32,學(xué)習(xí)率初始化為0.000 5,采用余弦退火學(xué)習(xí)率衰減策略,學(xué)習(xí)率衰減周期設(shè)置為5,訓(xùn)練總輪次設(shè)置為50。使用AdamW優(yōu)化網(wǎng)絡(luò)模型,權(quán)重衰減值設(shè)置為0.000 1,并利用交叉熵?fù)p失函數(shù)對(duì)模型進(jìn)行評(píng)估,實(shí)驗(yàn)參數(shù)設(shè)置如表2所示。

表2 實(shí)驗(yàn)參數(shù)Table 2 Experimental parameters
3.3 實(shí)驗(yàn)結(jié)果與分析
DFFViT 模型在RAF-DB、FERPlus 和AffectNet 面部表情數(shù)據(jù)集上得到的各類別表情識(shí)別結(jié)果和識(shí)別準(zhǔn)確率曲線如圖8、圖9所示。
圖8所示的3個(gè)混淆矩陣,表明DFFViT模型在3個(gè)面部表情數(shù)據(jù)集上取得的各類表情識(shí)別準(zhǔn)確率。其中RAF-DB 有7 種表情類別,F(xiàn)ERPlus 和AffectNet 有8 種表情類別。X軸表示面部表情的預(yù)測(cè)標(biāo)簽,Y軸表示面部表情的真實(shí)標(biāo)簽,矩陣的主對(duì)角線表示各類表情的識(shí)別精度,其余位置表示各類表情誤判率。由圖8可以看出,3個(gè)數(shù)據(jù)集上恐懼和驚訝是容易混淆的,其誤判率分別為12.2%、16.7%、13.8%,這是因?yàn)榭謶趾腕@訝有著相似的面部變化,會(huì)導(dǎo)致有許多重疊的面部特征,使得網(wǎng)絡(luò)難以學(xué)習(xí)。FERPlus數(shù)據(jù)集上輕視(31.2%)的識(shí)別準(zhǔn)確率偏低且易被誤判為中性(50.0%)。主要原因是輕視大多表現(xiàn)為嘴角上揚(yáng),輕微挑眉,面部變化不明顯,從而不易與中性表情區(qū)分。導(dǎo)致上述情況的另一個(gè)原因是FERPlus數(shù)據(jù)集中相應(yīng)表情樣本數(shù)量較少。
由圖9直觀顯示,本文提出的DFFViT模型在3個(gè)公共面部表情數(shù)據(jù)集上分別取得了88.36%、89.13%和62.08%的識(shí)別準(zhǔn)確率。其中X軸表示訓(xùn)練迭代輪次,Y軸表示表情識(shí)別準(zhǔn)確率(RAF-DB 和FERPlus 采用總體精度評(píng)估模型,AffectNet采用平均分類精度評(píng)估模型)。
基于在RAF-DB、FERPlus 和AffectNet 面部表情數(shù)據(jù)集上取得的識(shí)別準(zhǔn)確率,本文將DFFViT 模型與其他幾種方法進(jìn)行了對(duì)比,結(jié)果如表3所示。其中g(shù)ACNN[6]沒有FERPlus數(shù)據(jù)集的實(shí)驗(yàn)數(shù)據(jù),對(duì)應(yīng)位置用“—”標(biāo)記,最優(yōu)的識(shí)別結(jié)果以粗體標(biāo)記。DFFViT模型在RAF-DB上達(dá)到了88.36%的識(shí)別準(zhǔn)確率,比SCN[8]和VTFF[10]分別提升了1.33 個(gè)百分點(diǎn)和0.22 個(gè)百分點(diǎn)。本文提出的DFFViT模型在FERPlus數(shù)據(jù)集上取得了89.13%的識(shí)別準(zhǔn)確率,與RAN和VTFF相比分別提升了0.58個(gè)百分點(diǎn)和0.32個(gè)百分點(diǎn)。上述結(jié)果說明了DFFViT模型在小規(guī)模數(shù)據(jù)集上具有良好的性能。DFFViT模型在AffectNet數(shù)據(jù)集上得到了62.08%的識(shí)別準(zhǔn)確率,較VTFF提高了0.23 個(gè)百分點(diǎn),該結(jié)論表明DFFViT 對(duì)大規(guī)模數(shù)據(jù)集同樣具有良好的泛化能力。

表3 DFFViT與其他先進(jìn)方法的識(shí)別準(zhǔn)確率比較Table 3 Comparison of recognition accuracy between DFFViT and other advanced methods 單位:%
3.4 消融實(shí)驗(yàn)
為驗(yàn)證DFFViT 模型中各模塊的有效性,本實(shí)驗(yàn)采用控制變量法,在RAF-DB數(shù)據(jù)集上實(shí)驗(yàn)并進(jìn)行識(shí)別性能對(duì)比,變量設(shè)置與實(shí)驗(yàn)數(shù)據(jù)如表4所示。其中最優(yōu)的識(shí)別結(jié)果以粗體標(biāo)記,編號(hào)a為基線方法(在MS-Celeb-1M數(shù)據(jù)集上預(yù)訓(xùn)練的ResNet18)。

表4 RAF-DB數(shù)據(jù)集上的消融實(shí)驗(yàn)Table 4 Ablation experiments on RAF-DB dataset
本文通過設(shè)置a、d、e、h 四組實(shí)驗(yàn),來驗(yàn)證WSIN 模塊的有效性。由(a,e)對(duì)比可知,僅添加WSIN模塊時(shí),識(shí)別準(zhǔn)確率比基線方法提升了0.88個(gè)百分點(diǎn)。通過(d,h)對(duì)比可得,在已存在其他模塊的基礎(chǔ)上加入WSIN模塊后,識(shí)別性能提升了0.13個(gè)百分點(diǎn)。該結(jié)果表明WSIN模塊能夠有效地中和對(duì)比度,最小化光照對(duì)面部圖像的影響,對(duì)提高模型的識(shí)別準(zhǔn)確率具有重要的作用。
本文通過設(shè)置a、b、j、h 四組實(shí)驗(yàn),來檢驗(yàn)DFF 模塊的有效性。從(a,b)對(duì)比可以得出,通過DFF 模塊關(guān)注原圖顯著特征時(shí),性能較基線方法提高了1.24 個(gè)百分點(diǎn)。由(j,h)對(duì)照可知,當(dāng)使用DFF 模塊關(guān)注ILL 特征時(shí),識(shí)別性能顯著提升。實(shí)驗(yàn)結(jié)果顯示DFF模塊能夠聚合局部-全局上下文信息,以關(guān)注面部顯著特征,從而提升模型性能。
為評(píng)估多層Transformer 編碼器的性能,設(shè)置a、b、c、d、f、h 六組實(shí)驗(yàn)。通過(a,c)對(duì)比可知,應(yīng)用多層Transformer編碼器后,識(shí)別性能比基線方法高出1.46個(gè)百分點(diǎn)。由(b,d)和(f,h)兩兩對(duì)照可得,識(shí)別準(zhǔn)確率較采用多層Transformer 編碼器前分別提高了0.84 個(gè)百分點(diǎn)和0.62 個(gè)百分點(diǎn)。由此得出結(jié)論,多層Transformer編碼器能夠有效地提高模型學(xué)習(xí)特征間聯(lián)系的能力,對(duì)提升性能有極大的幫助。
多層Transformer 編碼器包括N個(gè)相同的層,每層中有L個(gè)單頭自注意力模塊,為驗(yàn)證不同N和L對(duì)模型性能的影響,本實(shí)驗(yàn)在RAD-DB數(shù)據(jù)集上設(shè)置了五組不同N、L進(jìn)行識(shí)別精度對(duì)比,變量設(shè)置與實(shí)驗(yàn)數(shù)據(jù)如表5所示,其中最優(yōu)的識(shí)別結(jié)果以粗體標(biāo)記。由(a,b,c)三組實(shí)驗(yàn)分析可知,適當(dāng)?shù)卦黾幼宰⒁饬δK的頭數(shù)能夠更好地捕捉面部特征序列的深層表示,以取得更高的識(shí)別精度。由(c,d,e)三組實(shí)驗(yàn)分析可知,增加N的層數(shù)會(huì)導(dǎo)致識(shí)別性能下降,原因是層數(shù)的增加會(huì)使得參數(shù)量過于龐大,導(dǎo)致模型過擬合。
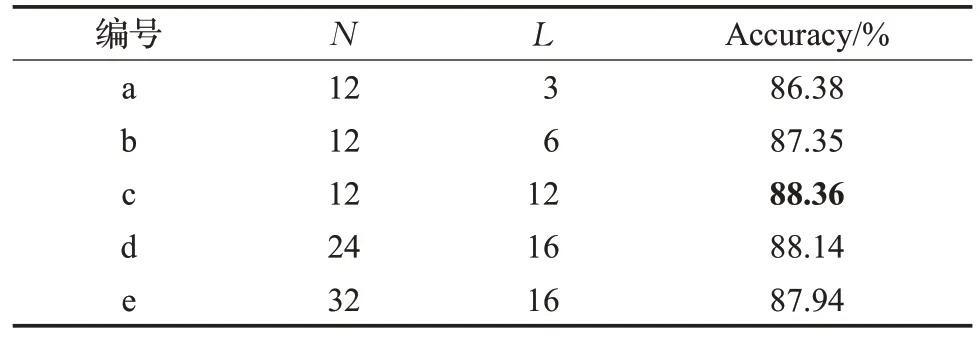
表5 RAF-DB數(shù)據(jù)集上的不同N 和L 的對(duì)比實(shí)驗(yàn)Table 5 Comparative experiments of different N and L on RAF-DB dataset
4 結(jié)束語(yǔ)
為解決真實(shí)的人機(jī)交互環(huán)境下面部圖像受各種不確定因素影響而導(dǎo)致準(zhǔn)確率降低的問題,本文提出了結(jié)合顯著特征篩選和視覺轉(zhuǎn)化器的面部表情識(shí)別模型。采用CNN 和顯著特征篩選模塊提取光照適中圖的特征,并動(dòng)態(tài)地聚合局部-全局上下文信息,以得到鑒別性更強(qiáng)的表情特征,并利用多層Transformer 編碼器加強(qiáng)特征間的關(guān)聯(lián)性,以提高識(shí)別性能。實(shí)驗(yàn)結(jié)果表明,該模型在三個(gè)公開的面部表情數(shù)據(jù)集上均取得較好的識(shí)別準(zhǔn)確率。后續(xù),將研究如何把本文所提出的模型進(jìn)一步應(yīng)用于情感交互機(jī)器人中。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
