開源自然語(yǔ)言處理工具綜述
2023-11-27 05:34:44廖春林張宏軍廖湘琳李大碩
計(jì)算機(jī)工程與應(yīng)用 2023年22期
廖春林,張宏軍,廖湘琳,程 愷,李大碩,王 航
中國(guó)人民解放軍陸軍工程大學(xué) 指揮控制工程學(xué)院,南京210007
隨著計(jì)算機(jī)技術(shù)的發(fā)展和應(yīng)用模式的改變,需要對(duì)大量的人類語(yǔ)言數(shù)據(jù)進(jìn)行處理和分析,以滿足不同程度的研究和應(yīng)用需求。自然語(yǔ)言處理(natural language processing,NLP)是計(jì)算機(jī)科學(xué)和人工智能領(lǐng)域的一個(gè)重要研究方向,主要的目標(biāo)便是實(shí)現(xiàn)人與計(jì)算機(jī)用自然語(yǔ)言進(jìn)行有效交互。
語(yǔ)言數(shù)據(jù)中文本數(shù)據(jù)占據(jù)極大的比重,故現(xiàn)在自然語(yǔ)言處理的研究對(duì)象主要針對(duì)文本數(shù)據(jù)。文本數(shù)據(jù)的處理分析一般需要分成不同的子任務(wù)來(lái)進(jìn)行,例如既需要文本標(biāo)準(zhǔn)化、文本清洗等預(yù)處理操作,也包括對(duì)詞法、語(yǔ)義等層面的具體分析,還需要像機(jī)器翻譯、信息抽取等能投入生產(chǎn)的應(yīng)用任務(wù)。
為方便對(duì)文本的處理和研究,加快相關(guān)應(yīng)用的落地部署,許多研究機(jī)構(gòu)和開發(fā)人員對(duì)自然語(yǔ)言處理領(lǐng)域中的子任務(wù)進(jìn)行了不同程度的實(shí)現(xiàn)和集成,從而構(gòu)建和迭代了效果良好、功能豐富的自然語(yǔ)言處理工具。早期的自然語(yǔ)言處理工具有賓夕法尼亞大學(xué)計(jì)算機(jī)與信息科學(xué)系開發(fā)的NLTK,它設(shè)計(jì)的初衷是為了方便計(jì)算語(yǔ)言學(xué)課程教學(xué)[1]。同一時(shí)期,斯坦福大學(xué)自然語(yǔ)言處理課題組也展開相關(guān)的研究,后來(lái)在2014 年左右集成發(fā)布了全面的工具CoreNLP[2]。國(guó)內(nèi)也同樣開展了自然語(yǔ)言處理工具的研究與構(gòu)建,其中具有代表性的便是哈爾濱工業(yè)大學(xué)社會(huì)計(jì)算與信息檢索研究中心構(gòu)建的LTP[3-4],清華大學(xué)自然語(yǔ)言處理實(shí)驗(yàn)室開發(fā)的THUNLP一系列工具。一些個(gè)人開發(fā)者也對(duì)自然語(yǔ)言處理工具做出了貢獻(xiàn),例如Wang 等人開發(fā)的面向中文文本的處理工具SnowNLP。
隨著自然語(yǔ)言處理領(lǐng)域研究的迅速發(fā)展,不少工具對(duì)子任務(wù)以往的實(shí)現(xiàn)方法進(jìn)行了改進(jìn),新的方法和處理范式正在被提出和應(yīng)用。每種工具對(duì)子任務(wù)具有不同程度上的支持,在應(yīng)用任務(wù)和背景方面又有一定的側(cè)重。面對(duì)日益增長(zhǎng)的各類文本處理需求,尋找符合需求的文本處理工具比較耗費(fèi)時(shí)間和精力。目前國(guó)內(nèi)外已經(jīng)發(fā)布多款開源的自然語(yǔ)言處理工具,只有少數(shù)博客對(duì)其中的幾款經(jīng)典工具進(jìn)行簡(jiǎn)單的介紹,缺乏相關(guān)的論文對(duì)這些工具進(jìn)行系統(tǒng)的整理。為了給從事自然語(yǔ)言處理相關(guān)工作的研究和開發(fā)人員提供參考,現(xiàn)圍繞國(guó)內(nèi)外23款開源自然語(yǔ)言處理工具主要完成以下工作:
(1)依照文本處理中的處理順序和作用把各項(xiàng)子任務(wù)劃分為輔助任務(wù)、基礎(chǔ)任務(wù)、應(yīng)用任務(wù)并進(jìn)行介紹。
(2)根據(jù)工具所面向的處理語(yǔ)言對(duì)工具進(jìn)行分類介紹,概括各種工具支持的編程語(yǔ)言、調(diào)用方式等信息,對(duì)比工具以及在各項(xiàng)任務(wù)上的特點(diǎn)。
(3)對(duì)各種工具支持子任務(wù)的實(shí)現(xiàn)原理進(jìn)行探究,按照規(guī)則方法、統(tǒng)計(jì)學(xué)習(xí)方法、神經(jīng)網(wǎng)絡(luò)方法以及基于它們的組合方法四個(gè)類別進(jìn)行比較。
(4)根據(jù)當(dāng)前自然語(yǔ)言處理工具的不足之處,展望自然語(yǔ)言處理工具未來(lái)的發(fā)展方向。
1 自然語(yǔ)言處理工具任務(wù)
自然語(yǔ)言處理領(lǐng)域的一大特點(diǎn)是任務(wù)種類紛繁復(fù)雜,任務(wù)之間又有一定的層次關(guān)系,并且任務(wù)有多種劃分方式。從處理的順序以及作用角度,可以將任務(wù)分為對(duì)文本預(yù)處理和規(guī)范的輔助類任務(wù),在字詞、句法和語(yǔ)義維度上的基礎(chǔ)類任務(wù),以及與現(xiàn)實(shí)生產(chǎn)實(shí)際密切相關(guān)的應(yīng)用類任務(wù)。
1.1 輔助類任務(wù)
輔助類任務(wù)一般在基礎(chǔ)任務(wù)和輔助任務(wù)前發(fā)揮作用,文本形式和內(nèi)容往往豐富多樣,主要針對(duì)文本進(jìn)行清洗和規(guī)范化,為后續(xù)任務(wù)提供部分功能計(jì)算接口,將文本轉(zhuǎn)換為方便計(jì)算機(jī)處理的形式和提取一些特殊文本特征,對(duì)較少的語(yǔ)料進(jìn)行擴(kuò)展。
文本規(guī)范處理:文本數(shù)據(jù)來(lái)源廣泛,需要對(duì)不同來(lái)源的文本進(jìn)行統(tǒng)一。一些文本中的字體形式不同,需要對(duì)文本進(jìn)行全半角轉(zhuǎn)換。中文領(lǐng)域由于歷史文化等差異,不同地區(qū)和不同時(shí)期的文本在字符上存在差異,例如古漢語(yǔ)繁體與現(xiàn)代白話文簡(jiǎn)體、我國(guó)港澳臺(tái)地區(qū)與內(nèi)陸地區(qū)用語(yǔ),有時(shí)也需要對(duì)繁體和簡(jiǎn)體中文進(jìn)行相互轉(zhuǎn)換。
字符特征提取:漢語(yǔ)拼音是根據(jù)普通話讀音的組成規(guī)則,將韻母、聲母以及聲調(diào)合并成音節(jié)。象形字起源于圖畫文字,是一種最為古老的造字方式,漢字由象形字演變而來(lái),漢字的一些部首偏旁保留著對(duì)語(yǔ)言潛在規(guī)律的刻畫。劉夢(mèng)迪等人[5]表明將漢字的拼音和偏旁部首作為特征對(duì)一些子任務(wù)效果有所提升。
相似度計(jì)算:文本相似度計(jì)算主要目標(biāo)是量化比較文本之間在語(yǔ)義上的相似程度,自然語(yǔ)言處理領(lǐng)域許多任務(wù)都需要用到相似度計(jì)算。機(jī)器翻譯任務(wù)中相似度被用來(lái)衡量翻譯的精確度,在智能問答領(lǐng)域中使用相似度來(lái)評(píng)定問題與答案之間的語(yǔ)義匹配,文本聚類任務(wù)中也被用來(lái)作為聚類標(biāo)準(zhǔn)。
文本嵌入:當(dāng)前自然語(yǔ)言處理領(lǐng)域主流的方法是深度學(xué)習(xí),首先需要進(jìn)行文本嵌入工作。文本嵌入主要實(shí)現(xiàn)文本由符號(hào)形式轉(zhuǎn)換為向量形式,從而方便計(jì)算機(jī)處理,同時(shí)文本嵌入也是實(shí)現(xiàn)單詞語(yǔ)義推測(cè)、句子情感分析等目的的一種手段,例如根據(jù)現(xiàn)有詞語(yǔ)推測(cè)出新詞,如“機(jī)場(chǎng)-飛機(jī)+火車=火車站”。
詞形還原:印歐語(yǔ)系的語(yǔ)言往往具有復(fù)雜的詞性變化,一些語(yǔ)義上相近的單詞(computer 和computing)由于組成的細(xì)微差異被認(rèn)為是不同的單詞,為了減少詞表大小,降低計(jì)算復(fù)雜度,需要對(duì)單詞進(jìn)行詞形還原或者詞干提取等任務(wù)。
數(shù)據(jù)增強(qiáng):數(shù)據(jù)增強(qiáng)可以理解為通過有限的數(shù)據(jù)生成更多的數(shù)據(jù),增加樣本的數(shù)量以及多樣性,從而間接提升方法和模型的魯棒性。當(dāng)前熱門神經(jīng)網(wǎng)絡(luò)方法需要大量的數(shù)據(jù)來(lái)提升模型方法的泛化能力,因此需要做數(shù)據(jù)增強(qiáng)增加數(shù)據(jù)量。
1.2 基礎(chǔ)類任務(wù)
基礎(chǔ)類任務(wù)聚焦于文本的詞法、句法以及語(yǔ)義層面的分析,每個(gè)層面中又有具體的子任務(wù),許多任務(wù)之間具有順序性和關(guān)聯(lián)性,這些任務(wù)大多是應(yīng)用類任務(wù)實(shí)現(xiàn)的前提。
(1)字詞分析
分詞:詞是最小的能獨(dú)立使用的音義結(jié)合體,是能夠獨(dú)立運(yùn)用并表達(dá)語(yǔ)義的最基本單元,因此分詞標(biāo)記(token)是多項(xiàng)自然語(yǔ)言處理子任務(wù)的基礎(chǔ)。在以英語(yǔ)為代表的印歐語(yǔ)系中,詞之間通常以空格、標(biāo)點(diǎn)符號(hào)等分隔符進(jìn)行區(qū)分。而在以中文為代表的東亞語(yǔ)系中,詞與詞之間并沒有明顯的界限,中文分詞(Chinese word segmentation)任務(wù)便是將一串中文字序列切分成中文詞序列。
詞性標(biāo)注:詞性作為對(duì)詞的一種泛化,在句法分析、語(yǔ)言識(shí)別、文本生成等任務(wù)中發(fā)揮著重要作用。詞性標(biāo)注(part-of-speech tagging)是對(duì)句子中的每個(gè)詞都分配合適的詞性,如副詞、動(dòng)詞、名詞等。
命名實(shí)體識(shí)別:命名實(shí)體識(shí)別(named entity recognition)指的是在句子的詞序列中定位并識(shí)別人名、地名、機(jī)構(gòu)名等實(shí)體范圍,命名實(shí)體對(duì)信息抽取、機(jī)器翻譯等任務(wù)有著重要作用。
詞典庫(kù)構(gòu)建:詞典庫(kù)是常用詞語(yǔ)、領(lǐng)域詞語(yǔ)等構(gòu)成的集合,通常由人工進(jìn)行整理,具有極高的可靠性,可直接用于分詞等任務(wù)或作為高質(zhì)量訓(xùn)練數(shù)據(jù)。
(2)句法分析
句法分析通過分析語(yǔ)言單位內(nèi)成分之間的相關(guān)關(guān)系揭示其句法規(guī)律與結(jié)構(gòu),句法分析又分為成分句法分析(constituency parsing)、依存句法分析(dependency parsing)。
成分句法分析:成分是一種抽象,它將語(yǔ)法作用相似的一些詞合并為一個(gè)短語(yǔ)單元,如名詞短語(yǔ)作用與名詞相似,可以在句子中作為主語(yǔ)或賓語(yǔ)成分。成分句法分析旨在解析出由詞構(gòu)成短語(yǔ),再由短語(yǔ)構(gòu)成句子的過程。
依存句法分析:依存句法理論認(rèn)為詞語(yǔ)之間存在著主從關(guān)系,即在句子中一個(gè)詞修飾并依附于另一個(gè)詞,通過依存分析能揭示句子詞語(yǔ)中的主謂關(guān)系、動(dòng)賓關(guān)系、核心關(guān)系等,從而進(jìn)一步理解語(yǔ)義來(lái)提升更深層次的任務(wù)效果。
規(guī)則庫(kù)構(gòu)建:規(guī)則是依據(jù)具體任務(wù)對(duì)語(yǔ)言規(guī)律的總結(jié),特定的規(guī)則對(duì)具體任務(wù)有很強(qiáng)的匹配性,對(duì)效果要求較高的任務(wù)通常需要規(guī)則庫(kù)進(jìn)行矯正。規(guī)則庫(kù)在基礎(chǔ)任務(wù)和應(yīng)用任務(wù)中都有被應(yīng)用。
(3)語(yǔ)義分析
語(yǔ)義角色標(biāo)注:語(yǔ)義角色標(biāo)注(semantic role labeling)是淺層次的語(yǔ)義分析任務(wù),主要目標(biāo)是對(duì)給定謂詞標(biāo)注其在句子中的短語(yǔ)論元,如施事、受事、時(shí)間和地點(diǎn)等,對(duì)智能問答、自動(dòng)翻譯和信息抽取等應(yīng)用產(chǎn)生推動(dòng)作用。
語(yǔ)義依存分析:語(yǔ)義依存分析(semantic dependency parsing)與依存句法分析相似,通過詞語(yǔ)所承載的語(yǔ)義框架來(lái)描述該詞語(yǔ),從而刻畫句子語(yǔ)義,從語(yǔ)義層面分析句子中語(yǔ)言單位之間的依存關(guān)聯(lián)。語(yǔ)義依存跨越了句法結(jié)構(gòu)的表層限制,獲取的是深層的語(yǔ)義信息。
抽象意義表示:抽象意義表示(abstract meaning representation,AMR)是一種將句子的意義表示為以概念為節(jié)點(diǎn)的單源有向無(wú)環(huán)圖的語(yǔ)言學(xué)框架。AMR正在引起學(xué)術(shù)界越來(lái)越廣泛的關(guān)注,已經(jīng)出現(xiàn)許多利用AMR進(jìn)行機(jī)器翻譯、關(guān)系提取等應(yīng)用的工作。
1.3 應(yīng)用類任務(wù)
應(yīng)用類任務(wù)的研究是推動(dòng)自然語(yǔ)言處理發(fā)展的直接因素,其他任務(wù)大多圍繞應(yīng)用類任務(wù)而產(chǎn)生,應(yīng)用類任務(wù)與人們的生活息息相關(guān),一般可以直接投入現(xiàn)實(shí)生產(chǎn)中,提高語(yǔ)言文字類相關(guān)工作的效率。
信息抽取:信息抽取(information extraction)是當(dāng)前自然語(yǔ)言處理研究中的一個(gè)熱門方向。信息抽取同時(shí)也是一個(gè)寬泛的概念,狹義的信息抽取指的是實(shí)體、實(shí)體之間的關(guān)系以及二者所構(gòu)成的事件提取,而廣義的信息抽取還包括關(guān)鍵詞提取、新詞發(fā)現(xiàn)以及文本摘要等從文本中抽取出任務(wù)所需的特定信息。
文本分類與聚類:文本聚類(text clustering)是無(wú)監(jiān)督聚簇過程,它將文本轉(zhuǎn)換成數(shù)字信息形成高維空間點(diǎn),再計(jì)算空間點(diǎn)間距離,將距離較近的聚成一個(gè)簇,同一簇的文本具有較強(qiáng)的相似性。文本分類(text classification)則讓計(jì)算機(jī)按照一定的分類體系或標(biāo)準(zhǔn)將文本歸入預(yù)先定義類別中的一個(gè)或若干個(gè)。
指代消解:將代表同一實(shí)體的不同指稱劃分到等價(jià)集合的過程稱為指代消解(co-reference resolution)。指代消解在機(jī)器閱讀理解、信息抽取、多輪對(duì)話等任務(wù)中都起到重要作用,能夠有效解決文本當(dāng)中的實(shí)體具有多個(gè)指代名稱的問題。
情感分析:情感分析(sentiment analysis)是指對(duì)含有主觀性的情感色彩文本進(jìn)行分析處理、歸納以及推理的過程。互聯(lián)網(wǎng)中用戶對(duì)人物、事件、產(chǎn)品等產(chǎn)生大量的評(píng)論文本,有豐富的輿論和商業(yè)價(jià)值,需要情感分析相關(guān)技術(shù)對(duì)這類文本挖掘出有價(jià)值的信息。
機(jī)器翻譯:機(jī)器翻譯(machine translation)又稱為自動(dòng)翻譯,是利用計(jì)算機(jī)把一種自然源語(yǔ)言轉(zhuǎn)變?yōu)榱硪环N自然目標(biāo)語(yǔ)言的過程,一般指自然語(yǔ)言之間句子和全文的翻譯。
文本糾錯(cuò):語(yǔ)音識(shí)別、OCR以及用輸入法打字等諸多場(chǎng)景中都會(huì)出現(xiàn)字詞錯(cuò)誤,這不僅影響人和機(jī)器的理解,錯(cuò)誤傳播也會(huì)影響后續(xù)任務(wù)的效果,因此需要文本糾錯(cuò)任務(wù)(text correction)對(duì)文本中不符合語(yǔ)言規(guī)則的地方進(jìn)行修正。
文本對(duì)抗攻擊:機(jī)器學(xué)習(xí)模型的輸入是數(shù)值型向量,文本對(duì)抗攻擊(textual confrontation)便是利用這一點(diǎn)生成對(duì)抗樣本,對(duì)原始的樣本數(shù)據(jù)添加針對(duì)性但不會(huì)影響人類感知的微小擾動(dòng),使機(jī)器學(xué)習(xí)模型產(chǎn)生錯(cuò)誤的輸出,該任務(wù)可在情緒分析、售后評(píng)價(jià)等實(shí)際應(yīng)用中歪曲客觀事實(shí)。
文本生成:文本生成(text generation)的早期定義指的是接收非語(yǔ)言形式的信息作為輸入,生成可讀的文字表述,廣義的文本生成則是將輸入來(lái)源擴(kuò)展為文本、圖像等數(shù)據(jù)形式。
自動(dòng)問答:自動(dòng)問答(question answering,QA)是利用計(jì)算機(jī)自動(dòng)回答用戶所提出的問題以滿足用戶知識(shí)需求的任務(wù)。QA不同于現(xiàn)有的信息檢索只返回基于關(guān)鍵詞匹配內(nèi)容排序結(jié)果,而是提供更加精準(zhǔn)的自然語(yǔ)言答案。
近兩年對(duì)自然語(yǔ)言處理應(yīng)用任務(wù)的相關(guān)研究成績(jī)斐然,信息抽取任務(wù)因?yàn)榫哂卸鄻拥某槿∧繕?biāo)和復(fù)雜的結(jié)構(gòu),需要根據(jù)具體的任務(wù)設(shè)計(jì)特定的模型結(jié)構(gòu)和標(biāo)注標(biāo)簽,比較耗費(fèi)時(shí)間和資源,百度和中國(guó)科學(xué)院聯(lián)合提出的USM方法旨在通過統(tǒng)一的模型方法完成信息抽取任務(wù)[6]。在文本理解和生成、自動(dòng)問答領(lǐng)域最大的突破當(dāng)屬OpenAI推出的ChatGPT和GPT4模型,GPT4支持圖文語(yǔ)義化的解讀以及更好的回答組織能力,而ChatGPT則帶來(lái)語(yǔ)言的深層次理解。機(jī)器翻譯字符序列很長(zhǎng),對(duì)計(jì)算資源的需求很大,Carrión等人[7]提出一種準(zhǔn)字符集機(jī)器翻譯的建模方法,其粒度介于字符與字詞之間,從而緩解機(jī)器翻譯中災(zāi)難性遺忘問題,同時(shí)與字符級(jí)建模方法相比更為高效。
自然語(yǔ)言處理中的各類任務(wù)不是彼此獨(dú)立,各類任務(wù)存在聯(lián)系,例如文本在分析前需要進(jìn)行預(yù)處理操作,分詞又是很多任務(wù)的基礎(chǔ),基于分詞才能對(duì)文本進(jìn)行詞法、語(yǔ)法層面的分析。文本糾錯(cuò)等應(yīng)用類任務(wù)同樣也可以反過來(lái)為輔助類任務(wù)提供支持,在文本清洗中發(fā)揮作用,從而提供質(zhì)量更高的語(yǔ)料。各子任務(wù)之間的關(guān)系如圖1所示。
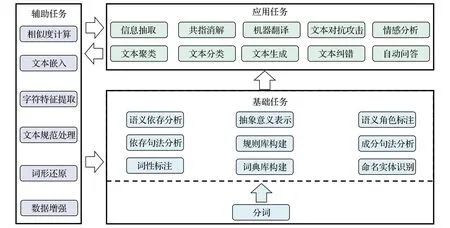
圖1 子任務(wù)結(jié)構(gòu)關(guān)系Fig.1 Subtask structure relationships
1.4 相關(guān)任務(wù)數(shù)據(jù)集
表1 整理了一些常用于訓(xùn)練和評(píng)測(cè)的自然語(yǔ)言處理子任務(wù)數(shù)據(jù)集,并給出數(shù)據(jù)集所支持的相關(guān)任務(wù)、鏈接地址、語(yǔ)料來(lái)源等信息以供參考。
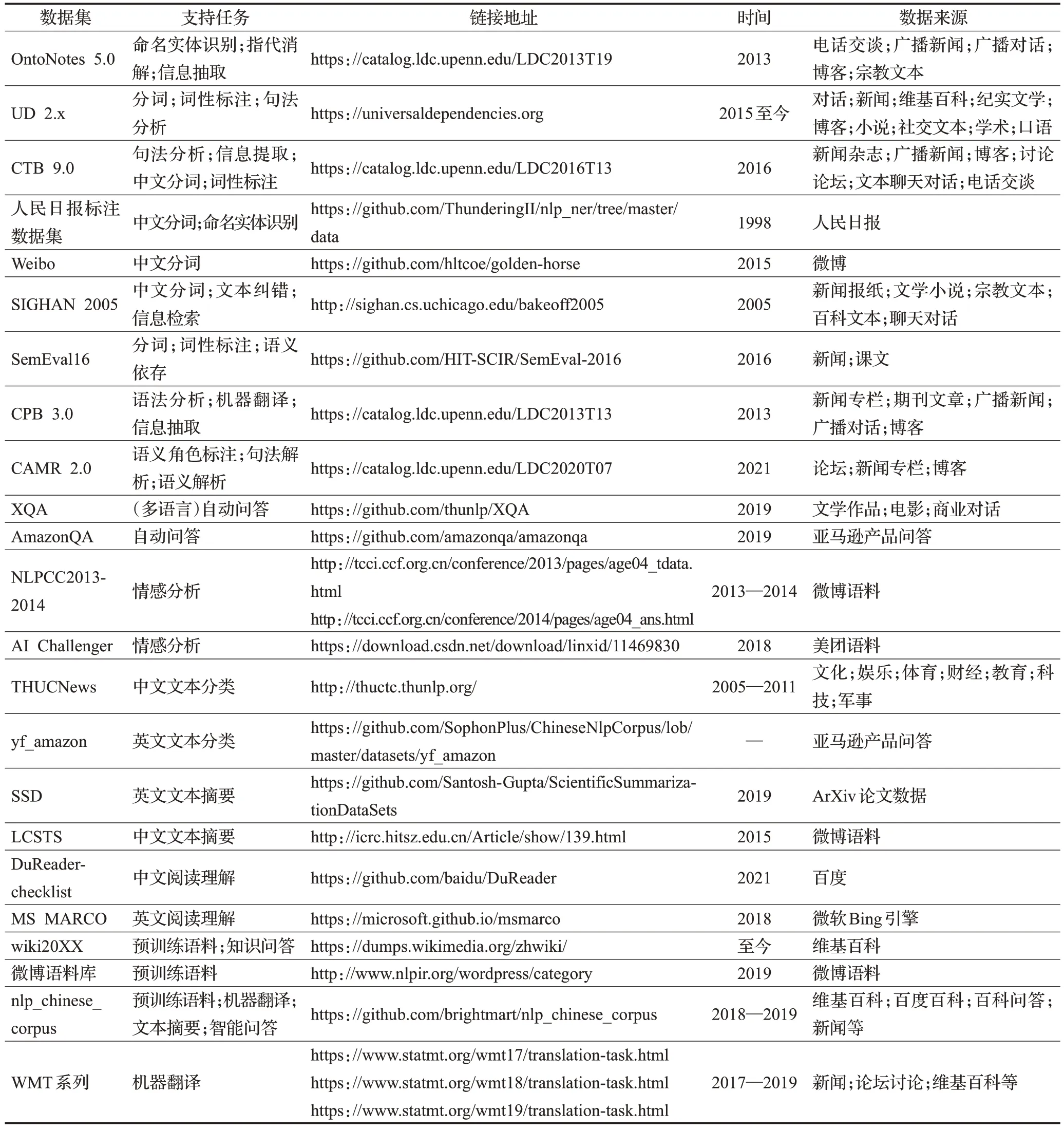
表1 相關(guān)任務(wù)數(shù)據(jù)集對(duì)比Table 1 Comparison of relevant task datasets
2 主流工具分析
當(dāng)前國(guó)內(nèi)外從事自然語(yǔ)言處理領(lǐng)域研究的機(jī)構(gòu)和一些個(gè)人開發(fā)者發(fā)布了多款自然語(yǔ)言處理工具,本文選取了其中的23款工具作為調(diào)查對(duì)象。在選取工具時(shí)考慮以下幾個(gè)方面:具有一定知名度與影響力(GitHub 的star數(shù)為1 000以上),如NLTK;面向具體領(lǐng)域的文本進(jìn)行分析和處理,如JiaYan;在任務(wù)實(shí)現(xiàn)上采取較為新穎的方法,如Graph4NLP;支持的子任務(wù)較為全面,實(shí)現(xiàn)方法較為豐富,如Hanlp。
2.1 工具分類
自然語(yǔ)言處理工具豐富多樣,現(xiàn)根據(jù)工具所面向的處理領(lǐng)域?qū)⒐ぞ邉澐譃橛⑽念I(lǐng)域處理工具、中文領(lǐng)域處理工具以及多語(yǔ)言處理工具進(jìn)行介紹。
(1)英文領(lǐng)域處理工具
英文領(lǐng)域的自然語(yǔ)言處理研究開展最早,也最先構(gòu)建相關(guān)的集成工具。賓夕法尼亞大學(xué)為方便計(jì)算語(yǔ)言學(xué)研究和教學(xué)使用Python 構(gòu)建了NLTK,提供WordNet等50 多個(gè)語(yǔ)料庫(kù)資源下載和預(yù)處理接口,可用于文本分類、語(yǔ)義解析和推理等任務(wù)的文本處理庫(kù),還對(duì)同一子任務(wù)提供多種算法以供使用者針對(duì)不同的需求進(jìn)行選擇。
艾倫人工智能研究所基于Pytorch開發(fā)的NLP框架AllenNLP[8],它為NLP中的常見任務(wù)和模型提供高級(jí)抽象和簡(jiǎn)單易用的API,模塊化的設(shè)計(jì)使得開發(fā)者可以輕松擴(kuò)展自己的模型,也方便初學(xué)者能夠快速實(shí)驗(yàn)。AllenNLP 同樣致力于多模態(tài)研究,從圖像和自然語(yǔ)言學(xué)習(xí)聯(lián)合模型以實(shí)現(xiàn)圖片問答任務(wù)。
近年來(lái)圖深度學(xué)習(xí)開始興起,一些的自然語(yǔ)言處理問題能夠以圖結(jié)構(gòu)進(jìn)行建模,從而得到更好的解決。吳凌飛等人構(gòu)建的工具Graph4NLP 被用于在圖深度學(xué)習(xí)和自然語(yǔ)言處理的交叉研究。它為研究人員和開發(fā)人員提供靈活的接口,也支持構(gòu)建全管道支持的自定義模型。Graph4NLP除了提供實(shí)現(xiàn)文本分類、語(yǔ)義解析等功能外,還能實(shí)現(xiàn)知識(shí)圖譜補(bǔ)全和求解一些由自然語(yǔ)言描述的簡(jiǎn)單數(shù)學(xué)問題。
(2)中文領(lǐng)域處理工具
哈爾濱工業(yè)大學(xué)較早對(duì)中文領(lǐng)域自然語(yǔ)言處理進(jìn)行研究,LTP便是其研制的一套開放中文自然語(yǔ)言處理系統(tǒng),先后歷經(jīng)四大版本,實(shí)現(xiàn)方法也從早期的規(guī)則和統(tǒng)計(jì)學(xué)習(xí)方法到最新的基于預(yù)訓(xùn)練模型微調(diào)。LTP 面向基礎(chǔ)任務(wù)由下到上提供一整套的性能良好的語(yǔ)言處理模塊,還可通過Web 端對(duì)依存圖等處理結(jié)果進(jìn)行可視化。
THUNLP不是具體的工具名,而是由清華大學(xué)研制推出的一系列單獨(dú)NLP 工具[9-13],包括支持高效分詞和詞性標(biāo)注分析的THULAC;實(shí)現(xiàn)文本對(duì)抗攻擊全過程的OpenAttack;可一鍵運(yùn)行的開源關(guān)系抽取OpenNRE;能夠自動(dòng)高效地實(shí)現(xiàn)用戶自定義的文本分類語(yǔ)料的訓(xùn)練、評(píng)測(cè)、分類功能的THUCTC;支持多語(yǔ)言機(jī)器翻譯和提供完善訓(xùn)練支持的THUMT等工具。
復(fù)旦大學(xué)的fastNLP[14]對(duì)文本的預(yù)處理、嵌入、訓(xùn)練以及模型評(píng)測(cè)等過程進(jìn)行封裝,并提供相應(yīng)的接口體現(xiàn)出它的簡(jiǎn)潔易用性。支持部分?jǐn)?shù)據(jù)集自動(dòng)下載和相應(yīng)的預(yù)處理,提供多種神經(jīng)網(wǎng)絡(luò)的復(fù)現(xiàn)模型和預(yù)訓(xùn)練模型的調(diào)用接口,還可以通過fitlog相配合,方便捕獲異常和記錄實(shí)驗(yàn)結(jié)果。將該工具應(yīng)用于研究中可以快速構(gòu)建更復(fù)雜的模型,提供的分布式接口也能使得模型在多卡設(shè)備上快速訓(xùn)練。
BaiduLAC是百度公司語(yǔ)言處理研究部門研發(fā)的一款聯(lián)合的詞法分析工具,主要面向中文實(shí)現(xiàn)詞法分析等功能[15],具有效果好、效率高、調(diào)用便捷等特點(diǎn)。其中的超輕量級(jí)模型可支持移動(dòng)端,大小僅有2.0×106,在普通手機(jī)上單線程性能達(dá)每秒鐘200的查詢量,支持多數(shù)移動(dòng)端應(yīng)用的需求,同等體積量級(jí)效果業(yè)內(nèi)領(lǐng)先。
微覓科技公司參考各大工具的優(yōu)缺點(diǎn)對(duì)相關(guān)任務(wù)技術(shù)進(jìn)行集成推出工具Jiagu,使用大規(guī)模語(yǔ)料訓(xùn)練任務(wù)模型。該工具不但覆蓋詞法分析、文本生成、情感分析等常見自然語(yǔ)言處理任務(wù),還通過關(guān)系抽取、關(guān)鍵詞抽取為知識(shí)圖譜的構(gòu)建提供支撐。
中文領(lǐng)域大多NLP 工具由大學(xué)研究機(jī)構(gòu)或公司進(jìn)行集成和開發(fā),并且一些行業(yè)愛好者同樣對(duì)工具的發(fā)展做出了貢獻(xiàn)。Wang等人開發(fā)了純面向處理中文文本工具SnowNLP,能夠進(jìn)行基本的詞法分析、文本摘要,對(duì)購(gòu)物評(píng)價(jià)提供情感分析支持。ChineseNLP 基于C++和Python 開發(fā),不僅處理速度相對(duì)更快,還能實(shí)現(xiàn)同義詞詞林的消歧、自動(dòng)文本生成、信息檢索等功能。DeepNLP基于TensorFlow深度學(xué)習(xí)平臺(tái)并結(jié)合最新的一些算法,支持NLP基礎(chǔ)模塊和其他更加復(fù)雜任務(wù)的拓展,提供通用、娛樂和O2O 領(lǐng)域的命名實(shí)體識(shí)別模型。Sean 開發(fā)的xmnlp同樣能夠?qū)崿F(xiàn)豐富的功能,提供電商場(chǎng)景下的情感識(shí)別,支持通用、金融和國(guó)際場(chǎng)景下的文本糾錯(cuò)和相似度計(jì)算,從漢字中提取偏旁部首也是xmnlp的特色功能。
當(dāng)前通用的中文NLP 工具多以現(xiàn)代漢語(yǔ)為核心語(yǔ)料,從而造成對(duì)古漢語(yǔ)的處理效果并不理想。Jiayan工具的目標(biāo)便是輔助古漢語(yǔ)信息處理,幫助古漢語(yǔ)的相關(guān)研究人員和愛好者更好地分析和利用文言語(yǔ)料。工具包支持詞庫(kù)構(gòu)建、自動(dòng)分詞、詞性標(biāo)注、文言文斷句和標(biāo)點(diǎn)五項(xiàng)功能,而古漢語(yǔ)到現(xiàn)代漢語(yǔ)的翻譯等功能正在開發(fā)中。
原始文本語(yǔ)料因?yàn)閬?lái)源廣泛、內(nèi)容形式豐富等不能直接分析,需要對(duì)語(yǔ)料進(jìn)行清洗和格式規(guī)范。JioNLP便派上用場(chǎng),它注重于文本預(yù)處理,支持提取HTML 文件標(biāo)簽中的內(nèi)容;發(fā)現(xiàn)處理文本中的異常字符;提取E-mail、IP地址、手機(jī)電話號(hào)碼等形式的內(nèi)容;還支持從中解析出諸如電話號(hào)碼歸屬地、運(yùn)營(yíng)商,身份證號(hào)碼所含信息等;除了對(duì)文本繁簡(jiǎn)、拼音轉(zhuǎn)換外,也能實(shí)現(xiàn)全半角等格式規(guī)范。對(duì)某些語(yǔ)料稀少不易獲取的特殊領(lǐng)域,也可以進(jìn)行數(shù)據(jù)增強(qiáng)。
(3)支持多語(yǔ)言處理工具
據(jù)統(tǒng)計(jì),目前世界上有5 651種語(yǔ)言,其中形成文字的有2 769 種,地區(qū)之間又發(fā)展出特有的語(yǔ)系。一些工具不局限于針對(duì)一種語(yǔ)言進(jìn)行處理和分析,而盡可能面向多語(yǔ)言研究,探究自然語(yǔ)言之間的共性。
北京理工大學(xué)發(fā)布的NLPIR 支持文字圖片、文檔、語(yǔ)音等多種形式的數(shù)據(jù)導(dǎo)入和分析處理,并在此基礎(chǔ)上執(zhí)行信息抽取、文本挖掘、知識(shí)關(guān)聯(lián)等中間任務(wù)為情報(bào)分析、知識(shí)圖譜、文檔智能提供支撐[16]。NLPIR支持GBK、UTF8等多種編碼標(biāo)準(zhǔn),覆蓋了中文、英文、阿拉伯語(yǔ)、印度烏爾都語(yǔ)、多哥語(yǔ)等“一帶一路”沿線語(yǔ)言的自然語(yǔ)言處理。除能運(yùn)行在Linux、Windows、IOS、安卓等操作系統(tǒng)上外,還對(duì)國(guó)產(chǎn)系統(tǒng)中麒麟以及龍芯、飛騰、華為鯤鵬等國(guó)產(chǎn)芯片提供不同程度的任務(wù)支持。
Hanlp[17]是面向NLP生產(chǎn)環(huán)境的工具,支持PyTorch和TensorFlow 雙深度學(xué)習(xí)框架。目標(biāo)是實(shí)現(xiàn)最前沿的NLP技術(shù)落地,主體面向中文,同時(shí)也支持英語(yǔ)、法語(yǔ)等130種語(yǔ)言上的10項(xiàng)聯(lián)合任務(wù)以及多項(xiàng)單任務(wù),具備精度準(zhǔn)確、性能高效、語(yǔ)料時(shí)新、架構(gòu)清晰、可自定義的特點(diǎn)。數(shù)據(jù)集有時(shí)會(huì)采用不同的標(biāo)注標(biāo)準(zhǔn),例如中文詞性標(biāo)注相關(guān)的數(shù)據(jù)集就擁有CTB、PKU、863 三套標(biāo)準(zhǔn)。大多工具的子任務(wù)模型一般只支持一套標(biāo)注標(biāo)準(zhǔn),Hanlp盡可能對(duì)各項(xiàng)子任務(wù)的各項(xiàng)標(biāo)準(zhǔn)提供支持,也同樣對(duì)部分自然語(yǔ)言處理數(shù)據(jù)集提供下載和預(yù)處理接口。
OpenNLP 是Apache 基金會(huì)下面的一個(gè)用于處理英、法、意、德以及荷蘭文本的工具,支持對(duì)CoNLL、OntoNotes等數(shù)據(jù)集的處理,包含詞法分析等多個(gè)組件,可以構(gòu)建完整的自然語(yǔ)言處理管道。出于工程層面以及任務(wù)效果的考慮,絕大多數(shù)子任務(wù)組件使用最大熵來(lái)實(shí)現(xiàn)。OpenNLP 除了能夠使用編程接口外也提供命令行界面執(zhí)行相關(guān)任務(wù),也能通過這兩種方式根據(jù)要求自訓(xùn)練組件模型。
FLAIR是德國(guó)洪堡大學(xué)牽頭開發(fā)的輕量NLP框架,旨在促進(jìn)最先進(jìn)的序列標(biāo)注、文本分類和語(yǔ)言模型的訓(xùn)練和分發(fā),對(duì)英語(yǔ)、德語(yǔ)、丹麥語(yǔ)、西班牙語(yǔ)、法語(yǔ)等語(yǔ)言具有不同程度的任務(wù)支持[18]。文本嵌入是FLAIR 一大特色,它幾乎囊括了通用的文本嵌入方式,從字符嵌入到文檔級(jí)別的嵌入。該框架還實(shí)現(xiàn)了標(biāo)準(zhǔn)模型訓(xùn)練和超參數(shù)選擇例程,以及一個(gè)數(shù)據(jù)獲取模塊,可以下載公開可用的語(yǔ)料數(shù)據(jù)集并將其轉(zhuǎn)換為數(shù)據(jù)結(jié)構(gòu),以便快速設(shè)置實(shí)驗(yàn)。FLAIR對(duì)命名實(shí)體識(shí)別也極為關(guān)注,除對(duì)不同語(yǔ)言通用領(lǐng)域的命名實(shí)體識(shí)別進(jìn)行研究,還對(duì)法律尤其生物醫(yī)學(xué)領(lǐng)域提供命名實(shí)體識(shí)別模型。
UDPipe[19-20]是捷克共和國(guó)查爾斯大學(xué)數(shù)學(xué)與物理學(xué)院與應(yīng)用語(yǔ)言學(xué)研究所發(fā)布的一款開源工具包,主要用于句子分割、詞性標(biāo)記、詞形還原和依賴解析。UD(universal dependencies)樹庫(kù)項(xiàng)目旨在為多種語(yǔ)言開發(fā)跨語(yǔ)言一致的形態(tài)和句法樹庫(kù)注釋。UDPipe正是基于UD 樹庫(kù)訓(xùn)練出的模型處理相關(guān)任務(wù),到目前為止一共提供覆蓋69 種語(yǔ)言的123 個(gè)模型。UDPipe 基于一個(gè)多任務(wù)框架,使用多種方式將文本進(jìn)行嵌入,然后聯(lián)合學(xué)習(xí)和預(yù)測(cè)相關(guān)的任務(wù)使得它在性能上得到一定的提升。
spaCy的定位是工業(yè)級(jí)自然語(yǔ)言處理庫(kù),它對(duì)66種語(yǔ)言提供不同程度的子任務(wù)支持。通過一個(gè)或多個(gè)按順序調(diào)用的管道組件可自定義實(shí)現(xiàn)對(duì)文本的解析處理。為了更好地節(jié)省內(nèi)存和提高處理速度,spaCy用Cpython對(duì)內(nèi)存管理部分進(jìn)行重構(gòu)。引入先進(jìn)的神經(jīng)網(wǎng)絡(luò)模型,用于分詞標(biāo)記、句法解析、文本分類等子任務(wù),使用BERT[21]等預(yù)訓(xùn)練模型進(jìn)行多任務(wù)學(xué)習(xí),以及生產(chǎn)就緒的訓(xùn)練系統(tǒng)和簡(jiǎn)單的模型打包、部署和工作流管理。
CoreNLP 是斯坦福大學(xué)提供的一款獨(dú)立且擁有一系列強(qiáng)大語(yǔ)言分析處理的工具。對(duì)任意的文章段落能夠?qū)崿F(xiàn)快速分析,并且效果相對(duì)穩(wěn)定、可信賴,對(duì)文本整體化的分析保持高質(zhì)量表現(xiàn)。能夠?qū)崿F(xiàn)詞法、句法分析以及情感分析等任務(wù),并在提供的網(wǎng)頁(yè)和客戶端上將結(jié)果進(jìn)行可視化。除了分析處理英文,也為阿拉伯語(yǔ)、漢語(yǔ)、法語(yǔ)、匈牙利語(yǔ)、德語(yǔ)和西班牙語(yǔ)提供不同級(jí)別的支持。Stanza[22]可以看作CoreNLP的一個(gè)升級(jí)版本,CoreNLP中大多任務(wù)主要采用統(tǒng)計(jì)模型,Stanza采用深度學(xué)習(xí)的方式獲取更深層次的語(yǔ)義信息,從而使得子任務(wù)的效果得到提升。為了促進(jìn)生物和醫(yī)學(xué)相關(guān)研究,Stanza還提供生物醫(yī)學(xué)文獻(xiàn)文本和臨床筆記的句法分析和命名實(shí)體識(shí)別的模型。
2.2 工具任務(wù)模型結(jié)構(gòu)
工具的任務(wù)模型結(jié)構(gòu)是指子任務(wù)在學(xué)習(xí)和調(diào)用時(shí)的實(shí)現(xiàn)構(gòu)型,目前主要分為單任務(wù)和多任務(wù)兩大類。單任務(wù)方式是在學(xué)習(xí)時(shí)根據(jù)具體的子任務(wù)和數(shù)據(jù)選取不同的模型進(jìn)行學(xué)習(xí),而多任務(wù)則是采用同一個(gè)模型,如圖2所示。
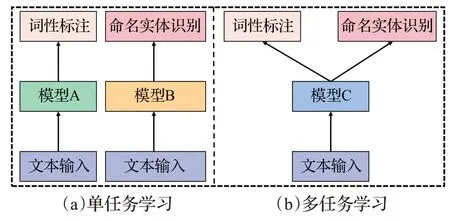
圖2 任務(wù)模型結(jié)構(gòu)Fig.2 Task model structure
當(dāng)前許多NLP工具采取對(duì)單任務(wù)學(xué)習(xí)的方式,因?yàn)槠湫Ч啾榷嗳蝿?wù)更好,但對(duì)多個(gè)單任務(wù)采用單模型往往會(huì)增加內(nèi)存開銷,導(dǎo)致處理速度不如多任務(wù)學(xué)習(xí)。同時(shí)單任務(wù)學(xué)習(xí)忽略了各任務(wù)之間的知識(shí)共享,子任務(wù)之間存在很強(qiáng)的相關(guān)性,比如分詞能力更強(qiáng)的模型在詞性標(biāo)注、命名實(shí)體識(shí)別等任務(wù)上表現(xiàn)會(huì)更好,可以通過多任務(wù)學(xué)習(xí)在多個(gè)語(yǔ)料庫(kù)上共享知識(shí)從而提升子任務(wù)性能[14]。LTP、fastNLP 等一些工具便采用多任務(wù)框架,子任務(wù)通過共享編碼器實(shí)現(xiàn)原輸入到向量的轉(zhuǎn)換,不同子任務(wù)采用不同的任務(wù)解碼器。
2.3 工具對(duì)比
通過對(duì)各種工具的調(diào)研,本文對(duì)各工具支持的語(yǔ)言、調(diào)用接口等信息進(jìn)行匯總以供參考。但由于不同的自然語(yǔ)言處理工具在適用領(lǐng)域、覆蓋的語(yǔ)言范圍以及對(duì)子任務(wù)的標(biāo)注標(biāo)準(zhǔn)上存在差異,同時(shí)一些工具并未公布子任務(wù)模型的訓(xùn)練語(yǔ)料來(lái)源,要準(zhǔn)確量化比較工具的性能差異非常困難。為對(duì)工具子任務(wù)的性能進(jìn)行大致的比較,依據(jù)機(jī)器之心(https://sota.jiqizhixin.com)收錄的SOTA評(píng)估指標(biāo)和效果設(shè)定簡(jiǎn)單的評(píng)估標(biāo)準(zhǔn)以供參考,在表2中進(jìn)行具體的評(píng)估說(shuō)明。
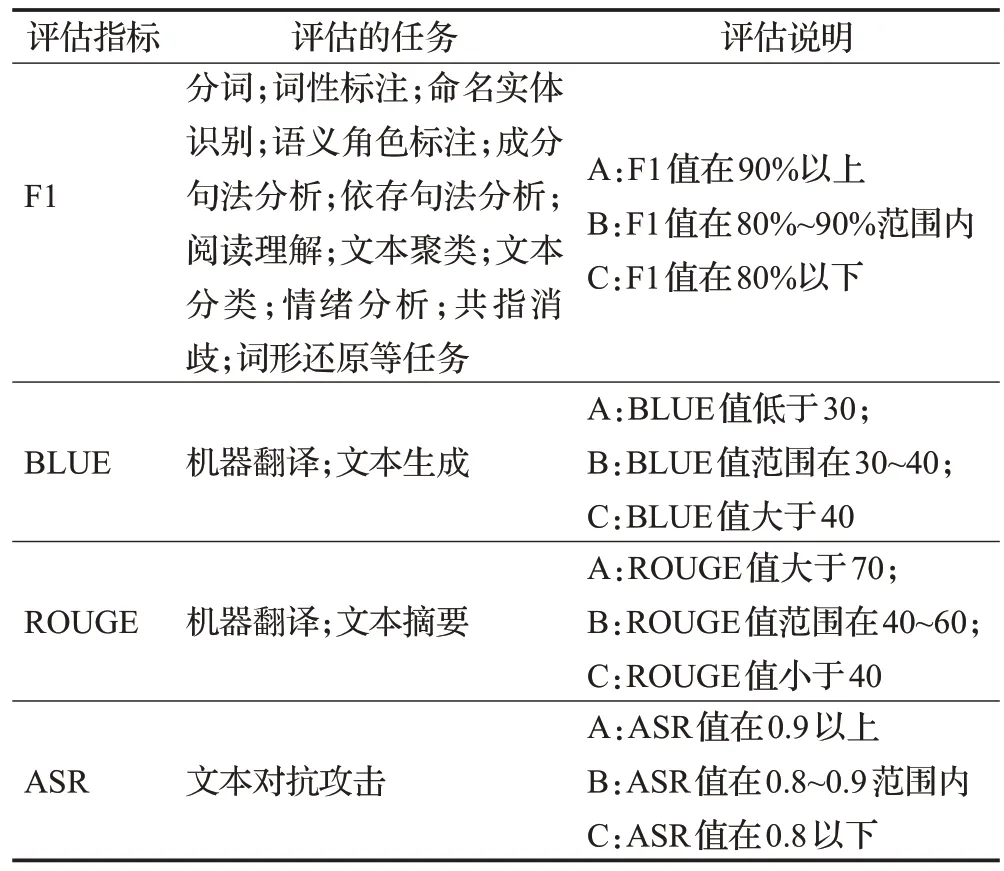
表2 工具任務(wù)評(píng)估說(shuō)明Table 2 Tool task evaluation description
各工具的對(duì)比信息由表3給出。
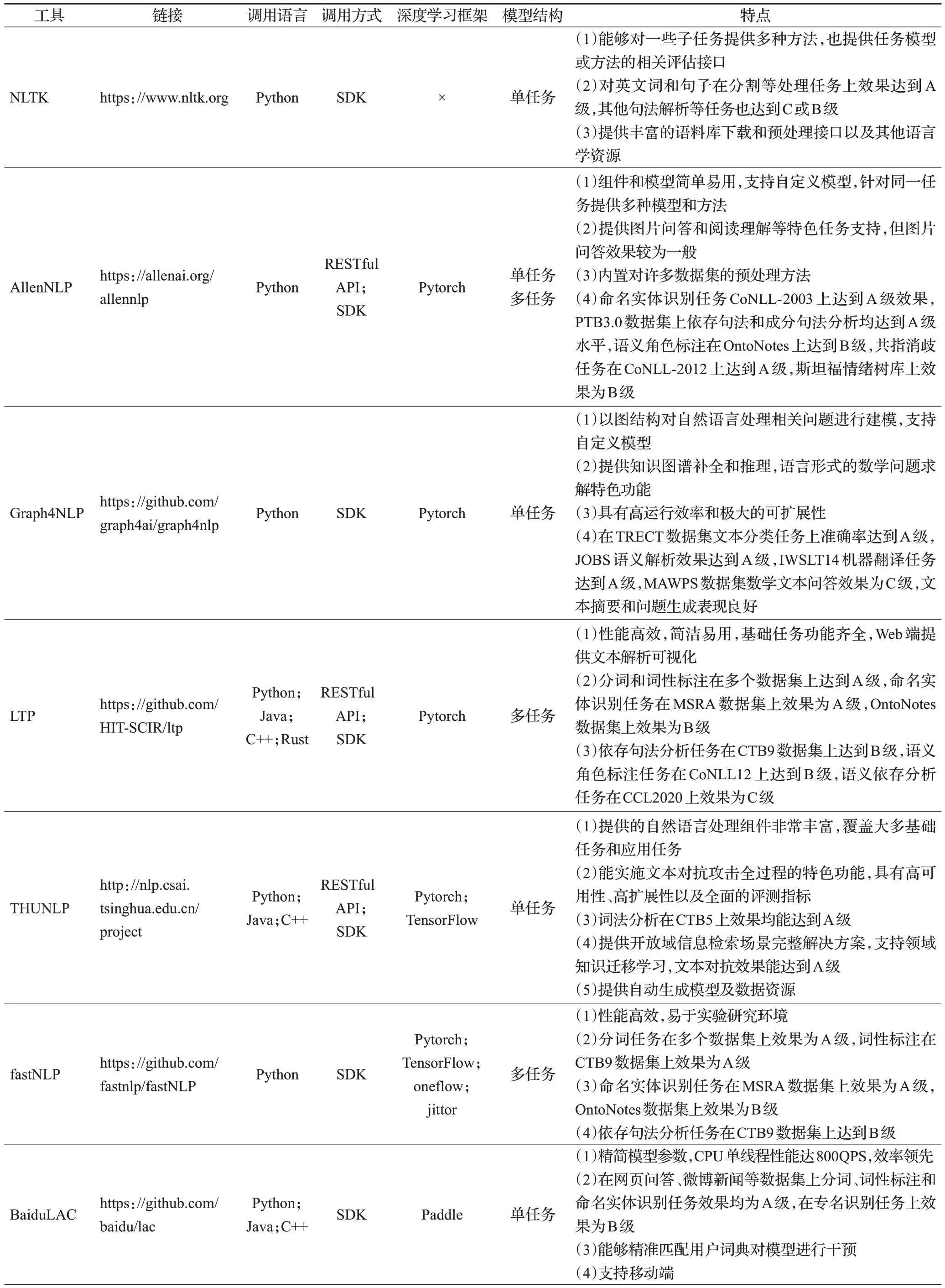
表3 工具基本信息Table 3 Basic information of tools
由于Python的簡(jiǎn)潔性和強(qiáng)大的功能庫(kù),近年來(lái)逐漸成為科學(xué)研究的熱門工具,從表3中可以看出Python是各NLP工具支持最多的語(yǔ)言,其他支持的語(yǔ)言也集中在Java和C++,主要的原因可能是方便部署以及能夠進(jìn)行快速處理。各NLP 工具的調(diào)用方式也以SDK 為主,極少數(shù)支持客戶端。一些工具也提供RESTful API,這是一種流行的調(diào)用方式,即用URL定位資源,用HTTP行為描述操作,通過簡(jiǎn)潔的代碼獲取服務(wù)器資源。NLP工具中采用這種方式能夠減少本地模型部署,同時(shí)一些暫不開源的功能也能通過這種方式供用戶調(diào)用。不少工具以深度學(xué)習(xí)框架為基礎(chǔ)進(jìn)行構(gòu)建,支持最多的深度學(xué)習(xí)框架為Pytorch,其次為TensorFlow。
3 任務(wù)實(shí)現(xiàn)模型和方法
不同工具對(duì)上述的子任務(wù)各有不同程度的支持,通過對(duì)各種開源工具的調(diào)研發(fā)現(xiàn),方法和模型的發(fā)展影響和促進(jìn)著工具的迭代。斯坦福大學(xué)開發(fā)的工具CoreNLP在早期版本使用基于規(guī)則和統(tǒng)計(jì)方法來(lái)實(shí)現(xiàn)自然語(yǔ)言處理中的子任務(wù),而在它最近新開發(fā)的工具Stanza中多應(yīng)用深度學(xué)習(xí)方法,達(dá)到更好的效果。大多數(shù)工具會(huì)根據(jù)子任務(wù)的特性采取不同的原理方法,同一子任務(wù)也具有多種實(shí)現(xiàn)方式,Hanlp在分詞任務(wù)上提供CNN+CRF[23]、預(yù)訓(xùn)練語(yǔ)言模型微調(diào)等多種方法選擇。
自然語(yǔ)言處理工具中各子任務(wù)的原理方法大致分為四種類型,即規(guī)則方法、統(tǒng)計(jì)學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)以及在這三種類型上的混合方法。
3.1 規(guī)則方法
早期的自然語(yǔ)言處理思路是根據(jù)人類語(yǔ)言學(xué)知識(shí)和相關(guān)領(lǐng)域知識(shí)總結(jié)相關(guān)的規(guī)則,然后應(yīng)用到具體任務(wù)上,基于匹配和基于任務(wù)特點(diǎn)是兩種基本的策略。
基于匹配的方法是最樸素的思路,如中文分詞任務(wù)中,依照詞典對(duì)文本序列進(jìn)行匹配分割,為了提升分割的正確率,衍生出正向最大匹配、逆向最大匹配以及雙向掃描等方法,一些早期的信息抽取系統(tǒng)也是通過歸納總結(jié)出觸發(fā)詞定位目標(biāo)信息。
基于任務(wù)特點(diǎn)的策略是觀察任務(wù)數(shù)據(jù)的規(guī)律,然后對(duì)規(guī)律進(jìn)行抽象并總結(jié)出規(guī)則算法。基于規(guī)則的新詞發(fā)現(xiàn)算法利用詞性之間的組合關(guān)系作為規(guī)則來(lái)找到新詞,例如AB為字符串,根據(jù)名詞的構(gòu)詞規(guī)則,A為名詞,B為動(dòng)詞、名詞或形容詞,則AB可能為新詞。一些相似度計(jì)算方法則根據(jù)知識(shí)庫(kù)中定義的規(guī)則,將詞匯分解成同義、反義等詞匯特征進(jìn)行相似度計(jì)算。NLTK等工具在較早版本的不少子任務(wù)中采取基于任務(wù)特點(diǎn)的方法,JioNLP中也基于規(guī)則完成豐富的文本預(yù)處理和信息提取任務(wù)。
規(guī)則方法具有描述明確、表達(dá)清晰等優(yōu)點(diǎn),能夠使用語(yǔ)言模型的組成成分和結(jié)構(gòu)清楚明了地將很多語(yǔ)言事實(shí)都表示出來(lái),在自然語(yǔ)言處理中有很好的研究和應(yīng)用價(jià)值。
3.2 統(tǒng)計(jì)方法
基于規(guī)則的方法在實(shí)際應(yīng)用場(chǎng)合的表現(xiàn)往往不如統(tǒng)計(jì)學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò),因?yàn)楹髢煞N方法能夠根據(jù)實(shí)際數(shù)據(jù)不斷地學(xué)習(xí)和調(diào)整,具有較強(qiáng)的泛化能力,而基于規(guī)則的方法通常由人工進(jìn)行整理歸納,進(jìn)行調(diào)整比較困難。統(tǒng)計(jì)學(xué)習(xí)與深度學(xué)習(xí)的基本思想是從一定數(shù)量的觀測(cè)樣本出發(fā),選擇合適的模型或方法擬合樣本數(shù)據(jù)的潛在規(guī)律,再利用擬合出的規(guī)律處理和分析相似的數(shù)據(jù)。
分詞、詞性標(biāo)注和命名實(shí)體識(shí)別等絕大多數(shù)自然語(yǔ)言處理任務(wù)常被轉(zhuǎn)化為序列標(biāo)注問題進(jìn)行處理,序列標(biāo)注問題的輸入一般為原始文本也被稱為觀測(cè)序列,輸出是任務(wù)對(duì)應(yīng)的標(biāo)記序列也被稱為狀態(tài)序列。問題的目標(biāo)是學(xué)習(xí)一個(gè)模型,使它能夠針對(duì)觀測(cè)序列給出標(biāo)記序列作為預(yù)測(cè)。統(tǒng)計(jì)學(xué)習(xí)方法在解決序列標(biāo)注問題中應(yīng)用較多的有最大熵(maximum entropy,MaxEnt)[24]、隱馬爾可夫模型(hidden Markov model,HMM)[25]、條件隨機(jī)場(chǎng)(conditional random field,CRF)[26]以及基于它們的改進(jìn)或衍生方法。常見的統(tǒng)計(jì)學(xué)習(xí)模型結(jié)構(gòu)如圖3所示。
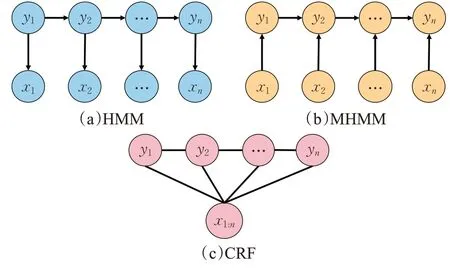
圖3 常用統(tǒng)計(jì)學(xué)習(xí)模型結(jié)構(gòu)Fig.3 Structure of common statistical learning models
隱馬爾可夫模型描述由隱藏馬爾可夫鏈生成不可觀測(cè)的狀態(tài)序列,再由各個(gè)狀態(tài)生成一個(gè)觀測(cè)而產(chǎn)生觀測(cè)序列的過程。SnowNLP、ChineseNLP 分別在詞性標(biāo)注、分詞任務(wù)上采用隱馬爾可夫模型來(lái)實(shí)現(xiàn)。然而隱馬爾可夫模型假設(shè)相對(duì)比較簡(jiǎn)單,它假設(shè)任意時(shí)刻的隱藏狀態(tài)只依賴于前一時(shí)刻的隱藏狀態(tài),在處理諸如實(shí)體嵌套、分詞等問題時(shí)表現(xiàn)不佳。Fine等人[27]對(duì)模型進(jìn)行改進(jìn),使用多層隱馬爾可夫模型進(jìn)行計(jì)算,底層模型為高層模型的參數(shù)提供支持,實(shí)現(xiàn)更好的泛化和擴(kuò)展。張華平等人將這一方法應(yīng)用到中文領(lǐng)域的部分處理子任務(wù)并集成到NLPIR工具中[28]。
最大熵遵循的原則是在學(xué)習(xí)時(shí)模型盡可能地滿足已有的事實(shí),而對(duì)未知的事實(shí)使用均勻分布去描述,這樣使得從數(shù)據(jù)中學(xué)習(xí)到的模型更加客觀,OpenNLP 大多任務(wù)便是采用最大熵的思想進(jìn)行實(shí)現(xiàn)。
基于最大熵模型和隱馬爾可夫模型融合的最大熵馬爾可夫模型(maximum entropy Markov models,MEMM)[29]對(duì)隱馬爾可夫模型的假設(shè)做出了改變,即認(rèn)為當(dāng)前時(shí)刻隱藏狀態(tài)同時(shí)取決于上一時(shí)刻隱藏狀態(tài)和當(dāng)前時(shí)刻的觀測(cè)狀態(tài),故將文本的前后信息引入到模型的學(xué)習(xí)和預(yù)測(cè)中,LTP在較早版本便應(yīng)用了這一模型[4]。最大熵馬爾可夫模型雖然解決了觀測(cè)序列元素之間嚴(yán)格獨(dú)立產(chǎn)生的問題,但是局部歸一化處理,使得產(chǎn)生標(biāo)注偏置問題。
條件隨機(jī)場(chǎng)舍棄了隱馬爾可夫模型中的兩個(gè)基本假設(shè),使之可以容納任意的上下文信息,同時(shí)用全局歸一化代替局部歸一化消除最大熵馬爾可夫模型中的不足之處。條件隨機(jī)場(chǎng)相對(duì)復(fù)雜的設(shè)計(jì)使得需要訓(xùn)練的參數(shù)更多,也導(dǎo)致了訓(xùn)練時(shí)間長(zhǎng)、計(jì)算復(fù)雜度更高的缺點(diǎn),但優(yōu)異的表現(xiàn)卻仍然讓很多工具中的子任務(wù)使用它來(lái)完成。
統(tǒng)計(jì)方法在自然語(yǔ)言處理中的應(yīng)用不止上述的模型,早期工具在進(jìn)行依存句法分析時(shí)也會(huì)用到概率上下文無(wú)關(guān)方法[30],文本摘要和關(guān)鍵詞提取任務(wù)常用TextRank[31]方法,還有一些工具在任務(wù)中使用較為少見的統(tǒng)計(jì)方法。
3.3 神經(jīng)網(wǎng)絡(luò)方法
隨著神經(jīng)網(wǎng)絡(luò)的出現(xiàn),人們開始考慮將它應(yīng)用在自然語(yǔ)言處理上。Bengio提出的NNLM 標(biāo)志著采用神經(jīng)網(wǎng)絡(luò)對(duì)語(yǔ)言實(shí)現(xiàn)表示和處理的開始[32]。Chen 等人[33]提出一種將詞、詞性標(biāo)簽以及依存關(guān)系特征拼接作為輸入的淺層神經(jīng)網(wǎng)絡(luò),構(gòu)建貪心依存句法解析器,并被作為CoreNLP中句法解析的一種方法。
卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)[34]多用于計(jì)算機(jī)視覺領(lǐng)域,因具有良好的特征提取能力遂被引入自然語(yǔ)言處理領(lǐng)域。spaCy文本分類任務(wù)就是采用CNN 與注意力機(jī)制結(jié)合實(shí)現(xiàn)。Kim[35]針對(duì)句子分類提出的TextCNN 也取得良好的效果,DeepNLP 用它實(shí)現(xiàn)文本分類,THUNLP、lightNLP 用它進(jìn)行信息抽取相關(guān)任務(wù)。CNN計(jì)算速度非常快,注重采用卷積、池化等步驟對(duì)局部信息的提取進(jìn)行整合,得到整體信息,對(duì)情感分析這一類由關(guān)鍵短語(yǔ)決定的任務(wù)處理效果比較好[36]。但CNN 的模型輸入輸出大小相對(duì)固定,同時(shí)對(duì)語(yǔ)義的理解往往需要考慮較遠(yuǎn)距離上的字詞,因此CNN 不善于處理具有較長(zhǎng)距離依賴的不定長(zhǎng)序列數(shù)據(jù)。
循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN)[37]主要針對(duì)序列數(shù)據(jù)建模,能夠?qū)χ皶r(shí)刻的序列信息進(jìn)行記憶并與當(dāng)前時(shí)刻序列元素作用進(jìn)行計(jì)算,計(jì)算結(jié)果作為下一時(shí)刻輸入的一部分從而影響后續(xù)序列。但是RNN 由于共享同一套參數(shù)和連乘效應(yīng),導(dǎo)致存在梯度消失或爆炸以及信息丟失問題。針對(duì)這些問題先后設(shè)計(jì)出能夠有選擇性篩除不重要信息的長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(long short-term memory,LSTM)[38],以及對(duì)LSTM 進(jìn)行改進(jìn)使得收斂更快、參數(shù)較少的門控循環(huán)單元(gated recurrent unit,GRU)[39]。不過之前的RNN 結(jié)構(gòu)在計(jì)算過程中只考慮前文的信息,為了利用后文的信息設(shè)計(jì)出雙向結(jié)構(gòu)BiLSTM、BiGRU使得模型的學(xué)習(xí)能力進(jìn)一步提升[40]。lightNLP、Hanlp、DeepNLP、Stanza 等工具多使用BiLSTM,因?yàn)樗谟?xùn)練數(shù)據(jù)量較大時(shí)表現(xiàn)更好,而BiGRU由于計(jì)算速度更快,NLPIR、UDPipe將它作為實(shí)現(xiàn)手段。除對(duì)內(nèi)部結(jié)構(gòu)的改進(jìn)外,針對(duì)任務(wù)的需要,對(duì)RNN 的輸入輸出結(jié)構(gòu)進(jìn)行改變,出現(xiàn)了用于標(biāo)注任務(wù)的N-N型、針對(duì)圖片生成文字的1-N型、文本分類的N-1 型,以及可用于翻譯的N-M型。RNN 演化結(jié)構(gòu)如圖4所示。
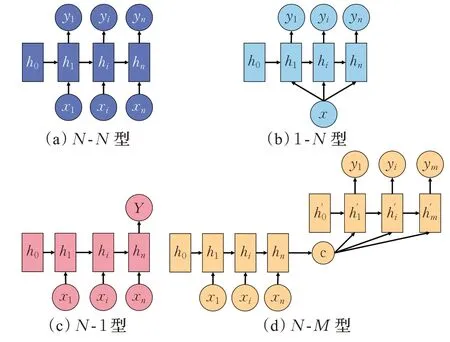
圖4 RNN演化結(jié)構(gòu)Fig.4 RNN evolution structure
3.4 組合方法
N-M型也被稱為Seq2Seq,即編碼器-解碼器結(jié)構(gòu)[41]。由于輸入輸出序列長(zhǎng)度不受限制適合生成類任務(wù),lightNLP 將其應(yīng)用到機(jī)器翻譯和文本生成任務(wù)中,ChineseNLP將其應(yīng)用在文本摘要任務(wù)中。雖然RNN內(nèi)部結(jié)構(gòu)的改進(jìn)使模型學(xué)習(xí)到信息也相對(duì)更多,但隨著序列過長(zhǎng)會(huì)使較遠(yuǎn)距離的信息被遺忘,Seq2Seq 常與注意力機(jī)制結(jié)合用于篩選任務(wù)相關(guān)的重要信息[42]。Vaswani等人[43]在Seq2Seq 與注意力機(jī)制的啟發(fā)下提出著名的Transformer模型用于機(jī)器翻譯,模型中的多頭自注意力機(jī)制不僅能解決RNN 由于循環(huán)結(jié)構(gòu)不能并行計(jì)算問題,還能捕捉相對(duì)較長(zhǎng)序列中的信息。由于其性能較好,THUNLP、LTP、spaCy以及Hanlp等工具將其改造用于一些子任務(wù)。
上述的深度學(xué)習(xí)方法在提取歐氏空間里的數(shù)據(jù)特征時(shí)有非常良好的表現(xiàn),但是不少圖結(jié)構(gòu)的數(shù)據(jù)并非如一些模型假設(shè)那樣彼此獨(dú)立,因此這些方法有時(shí)并不適合處理非歐氏空間中的數(shù)據(jù)。為了將深度學(xué)習(xí)方法在圖結(jié)構(gòu)上擴(kuò)展,圖神經(jīng)網(wǎng)絡(luò)(graph neural network,GNN)[44]應(yīng)運(yùn)而生。圖卷積網(wǎng)絡(luò)(graph convolution network,GCN)[45]將卷積運(yùn)算從傳統(tǒng)的文本、圖像數(shù)據(jù)推廣到圖數(shù)據(jù),也是眾多復(fù)雜神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)。注意力機(jī)制也被應(yīng)用到圖神經(jīng)網(wǎng)絡(luò)中來(lái)放大數(shù)據(jù)中重要部分的影響,其中比較有影響力的是注重于節(jié)點(diǎn)鄰域權(quán)重的圖注意力網(wǎng)絡(luò)(graph attention network,GAT)[46]和使用自注意力機(jī)制為每個(gè)頭部分計(jì)算不同權(quán)重的門控注意力網(wǎng)絡(luò)(gated attention network,GaAN)[47]。
規(guī)則方法、統(tǒng)計(jì)學(xué)習(xí)方法和神經(jīng)網(wǎng)絡(luò)方法各自具有特點(diǎn),有不同的適用場(chǎng)景,在應(yīng)用研究中為了達(dá)到更好的效果,有時(shí)需要針對(duì)不同子任務(wù)的特點(diǎn)對(duì)方法進(jìn)行改進(jìn)或者選取合適的方法組合。
分詞任務(wù)上便有采用詞典+有向無(wú)環(huán)圖+HMM 的組合方法。最開始通過Trie 樹[48]依據(jù)詞典得到句子中字所有可能組成詞情況,并構(gòu)建為有向無(wú)環(huán)圖,再根據(jù)登錄詞詞頻使用動(dòng)態(tài)規(guī)劃查找最大概率路徑的切分組合,針對(duì)未登錄詞采用HMM 模型進(jìn)行預(yù)測(cè)處理[28]。這種組合方法不但支持自定義詞典提高特定詞的識(shí)別率,充分利用已知詞典信息實(shí)現(xiàn)快速切分提高整體分詞速度,還對(duì)未登錄詞結(jié)合統(tǒng)計(jì)信息進(jìn)行預(yù)測(cè),保證一定的正確性。
2015 年Huang 等人[49]提出BiLSTM+CRF 的方式進(jìn)行序列標(biāo)注任務(wù),BiLSTM 對(duì)文本序列信息進(jìn)行解析,然后對(duì)輸出序列中每個(gè)字或詞輸出屬于不同標(biāo)簽的得分。但BiLSTM缺乏對(duì)標(biāo)簽間關(guān)系的約束,導(dǎo)致得分最高的標(biāo)簽并不一定是正確的標(biāo)簽,因此需要加入CRF學(xué)習(xí)標(biāo)簽間的約束關(guān)系,從而做出更準(zhǔn)確的預(yù)測(cè)。從不少工具子任務(wù)的實(shí)現(xiàn)原理中可以看到BiLSTM+CRF的方式掀起了很大的熱度,對(duì)計(jì)算性能要求較高、運(yùn)行環(huán)境特殊的BaiduLAC 和NLPIR 使用BiGRU 替換BiLSTM實(shí)現(xiàn)分詞等任務(wù),而在句法分析任務(wù)中,Stanza和FLAIR等采用雙仿射注意力機(jī)制Biaffine[50]代替CRF提升效果。
以往模型方法需要針對(duì)具體的任務(wù)標(biāo)記大量的數(shù)據(jù)訓(xùn)練得到效果較好的模型,而預(yù)訓(xùn)練語(yǔ)言模型在訓(xùn)練階段獲得了大量通用知識(shí),在預(yù)訓(xùn)練模型的基礎(chǔ)上結(jié)合其他方法進(jìn)行微調(diào)便可提升許多子任務(wù)的效果。
神經(jīng)網(wǎng)絡(luò)的預(yù)訓(xùn)練技術(shù)可追溯至前文提到的NNLM,為了方便計(jì)算機(jī)進(jìn)行處理,需要對(duì)文本中的字詞進(jìn)行向量化,這一過程也被稱為文本嵌入。文本嵌入對(duì)任務(wù)效果影響較大,自然語(yǔ)言處理工具基本都提供嵌入接口,其中UDPipe和Graph4NLP提供的嵌入方式較為豐富。
較早時(shí)期的文本嵌入采用獨(dú)熱編碼對(duì)詞進(jìn)行表示,但是這種方式不僅存在維度災(zāi)難和數(shù)據(jù)稀疏等問題,還完全割裂了詞之間的聯(lián)系。Mikolov等人[51]對(duì)NNLM進(jìn)行簡(jiǎn)化獲得詞的低維稠密嵌入表示W(wǎng)ord2Vec,并提出兩種訓(xùn)練方式。其中CBOW是用一定窗口范圍的上下文詞預(yù)測(cè)中心詞,而Skip-gram與之原理相同,只不過是用中心詞預(yù)測(cè)固定窗口的上下文。但Word2Vec無(wú)法解決未登錄詞問題,F(xiàn)acebook 對(duì)此提出了fastText[52],將能組成單詞的詞根或詞綴整理為集合,并對(duì)集合中的每個(gè)元素進(jìn)行向量化表示,然后通過詞根或詞綴向量相加的方式表示詞,此方法使得未在訓(xùn)練集中出現(xiàn)的詞也能通過這種方式進(jìn)行表示。這種基于上下文窗口的方法產(chǎn)生的詞向量只學(xué)習(xí)了局部詞之間的關(guān)系,缺乏對(duì)詞在全局層面進(jìn)行刻畫,Pennington 等人[53]提出融合全局信息的詞嵌入模型GloVe。GloVe統(tǒng)計(jì)出全局詞的共現(xiàn)概率比,以此呈現(xiàn)詞之間的相關(guān)性,然后學(xué)習(xí)滿足共現(xiàn)概率比的詞向量參數(shù)。
上述基于上下文窗口和基于融合全局信息的嵌入方法又被稱為靜態(tài)嵌入,這類方法忽略了詞序信息,也只能生成一個(gè)固定的向量,無(wú)法結(jié)合上下文信息進(jìn)行調(diào)整,不能解決一詞多義問題。ELMo[54]模型開啟了動(dòng)態(tài)詞嵌入的篇章,推動(dòng)了語(yǔ)言預(yù)訓(xùn)練技術(shù)的發(fā)展,它能夠根據(jù)詞所處的上下文信息對(duì)詞產(chǎn)生不同的映射。隨后的BERT、GPT[55]、ERNIE[56]等系列模型通過對(duì)大規(guī)模語(yǔ)料庫(kù)的預(yù)訓(xùn)練,得到上下文詞的語(yǔ)法和語(yǔ)義等通用信息。GPT 是基于Transformer 的解碼器部分演變成的自回歸模型,根據(jù)上文或下文內(nèi)容預(yù)測(cè)當(dāng)前詞進(jìn)行預(yù)訓(xùn)練任務(wù),因此適合文本摘要等生成類任務(wù)。BERT 則是由Transformer中的編碼器改造而來(lái)的自編碼模型,它將輸入文本中的部分詞語(yǔ)進(jìn)行隨機(jī)掩蓋,并讓模型去預(yù)測(cè)被掩蓋的詞,同時(shí)判斷兩個(gè)句子是否具有上下文關(guān)系,通過這兩個(gè)任務(wù)使模型學(xué)習(xí)到文本的通用信息。
當(dāng)下大多數(shù)預(yù)訓(xùn)練語(yǔ)言模型便是對(duì)兩類模型方法進(jìn)行衍生和改進(jìn)。自回歸模型是通過擴(kuò)大模型參數(shù)量和語(yǔ)料庫(kù),并增加訓(xùn)練任務(wù)難度的方式進(jìn)行優(yōu)化,如GPT-2、GPT-3 等[57-58];自編碼模型是調(diào)整掩碼策略或句子連續(xù)預(yù)測(cè)任務(wù),如RoBERTa[59]、ALBERT[60]。近來(lái)引發(fā)關(guān)注的Electra則是引入替換標(biāo)記檢測(cè)任務(wù),用生成器預(yù)測(cè)詞匯并替代標(biāo)記,再用判別器檢測(cè)生成器產(chǎn)生的詞與替換前是否相同從而學(xué)習(xí)參數(shù)[61]。基于Transformer 衍生的預(yù)訓(xùn)練模型如圖5所示。
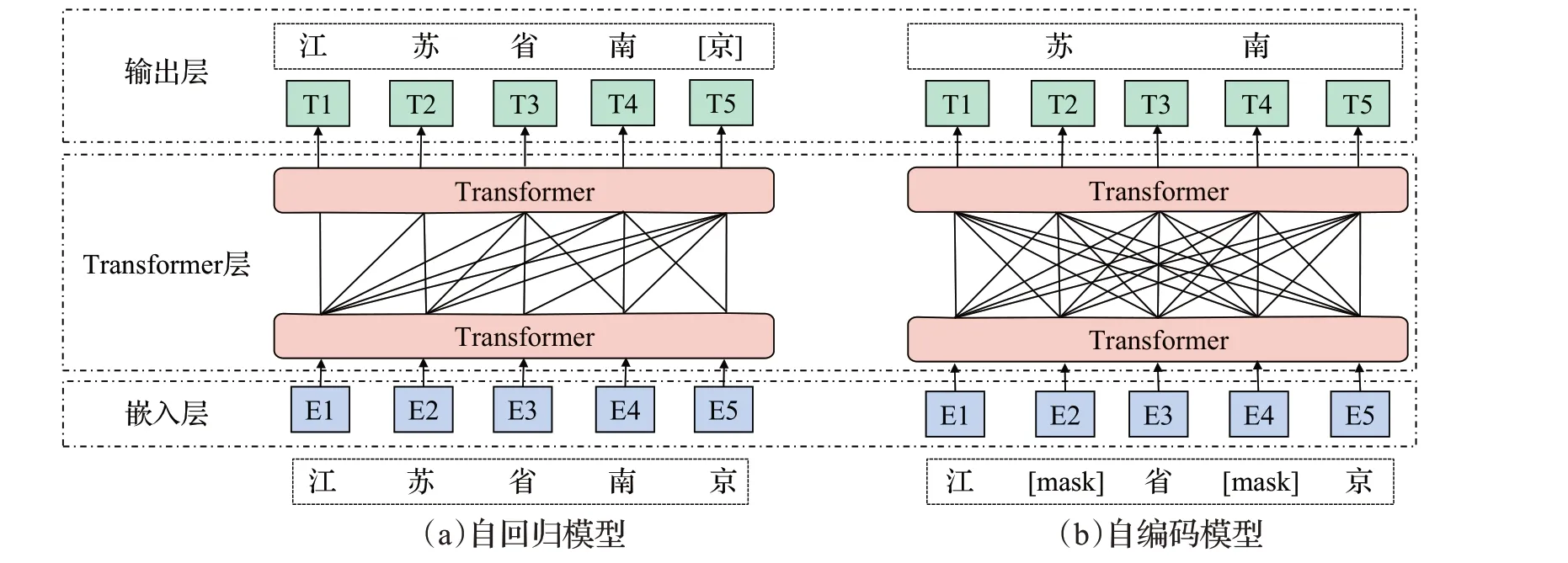
圖5 基于Transformer衍生的預(yù)訓(xùn)練模型Fig.5 Pre-training model derived from Transformer
基于預(yù)訓(xùn)練模型微調(diào)的方式逐漸成為自然語(yǔ)言處理的新范式。LTP在最新的版本中全然采用這種方式,選取預(yù)訓(xùn)練模型Electra作為基礎(chǔ),結(jié)合線性回歸進(jìn)行分詞和詞性標(biāo)記,對(duì)依存句法分析和語(yǔ)義依存分析使用Biaffine進(jìn)行解碼。fastNLP也使用類似的方式,不同的是使用基于BERT改進(jìn)后的預(yù)訓(xùn)練模型,解碼任務(wù)也大多采用CRF來(lái)完成[14]。
不同類型的方法具有不同的特點(diǎn),表4是對(duì)四大類方法的總結(jié)。
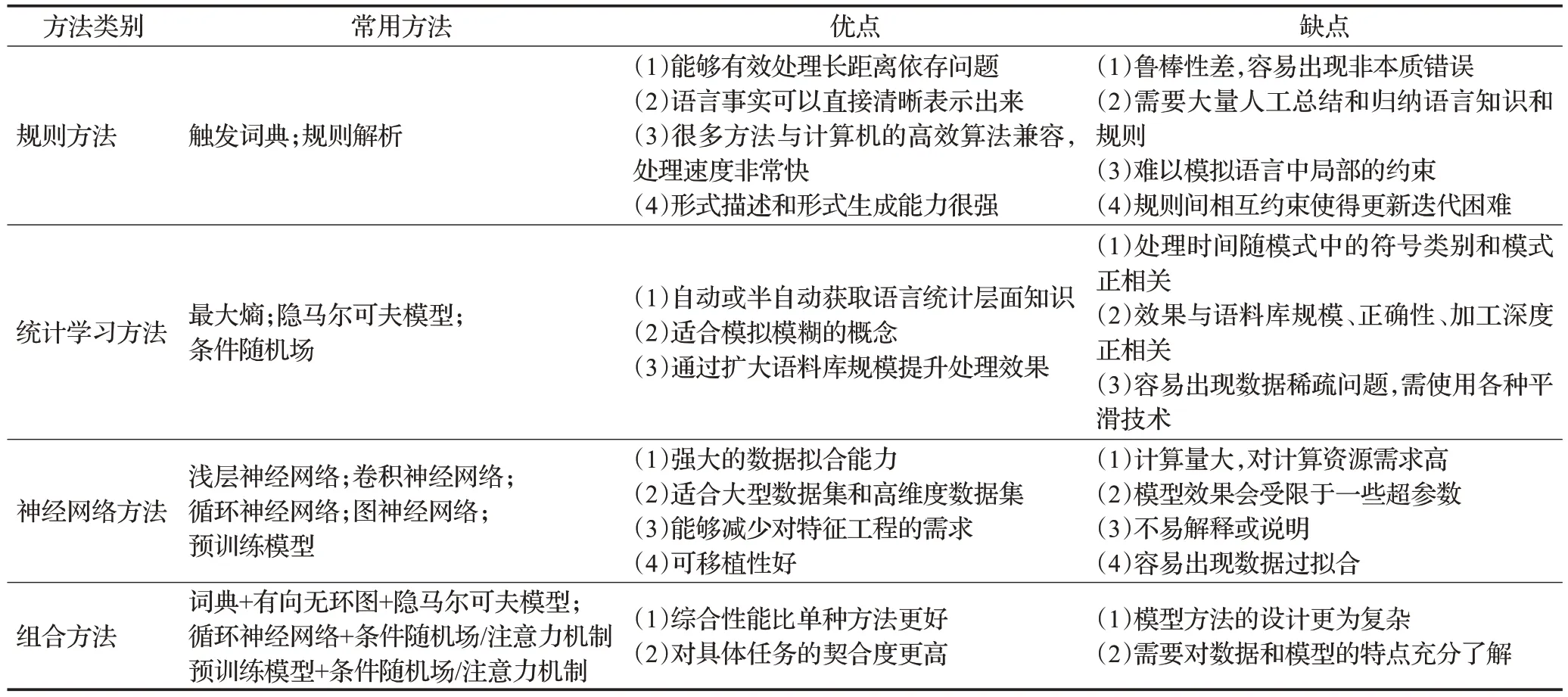
表4 方法特點(diǎn)比較Table 4 Comparison of method characteristics
3.5 工具子任務(wù)具體原理對(duì)比
在調(diào)研過程中,同樣對(duì)每種工具子任務(wù)的具體實(shí)現(xiàn)原理進(jìn)行記錄,根據(jù)前文對(duì)子任務(wù)的分類標(biāo)準(zhǔn)整理為表5~表7。表中,×表示工具對(duì)該任務(wù)暫未實(shí)現(xiàn)和支持,Y*表示該工具該功能有所實(shí)現(xiàn),未列出是因?yàn)檫@部分工具未完全開源,只提供免費(fèi)調(diào)用接口。
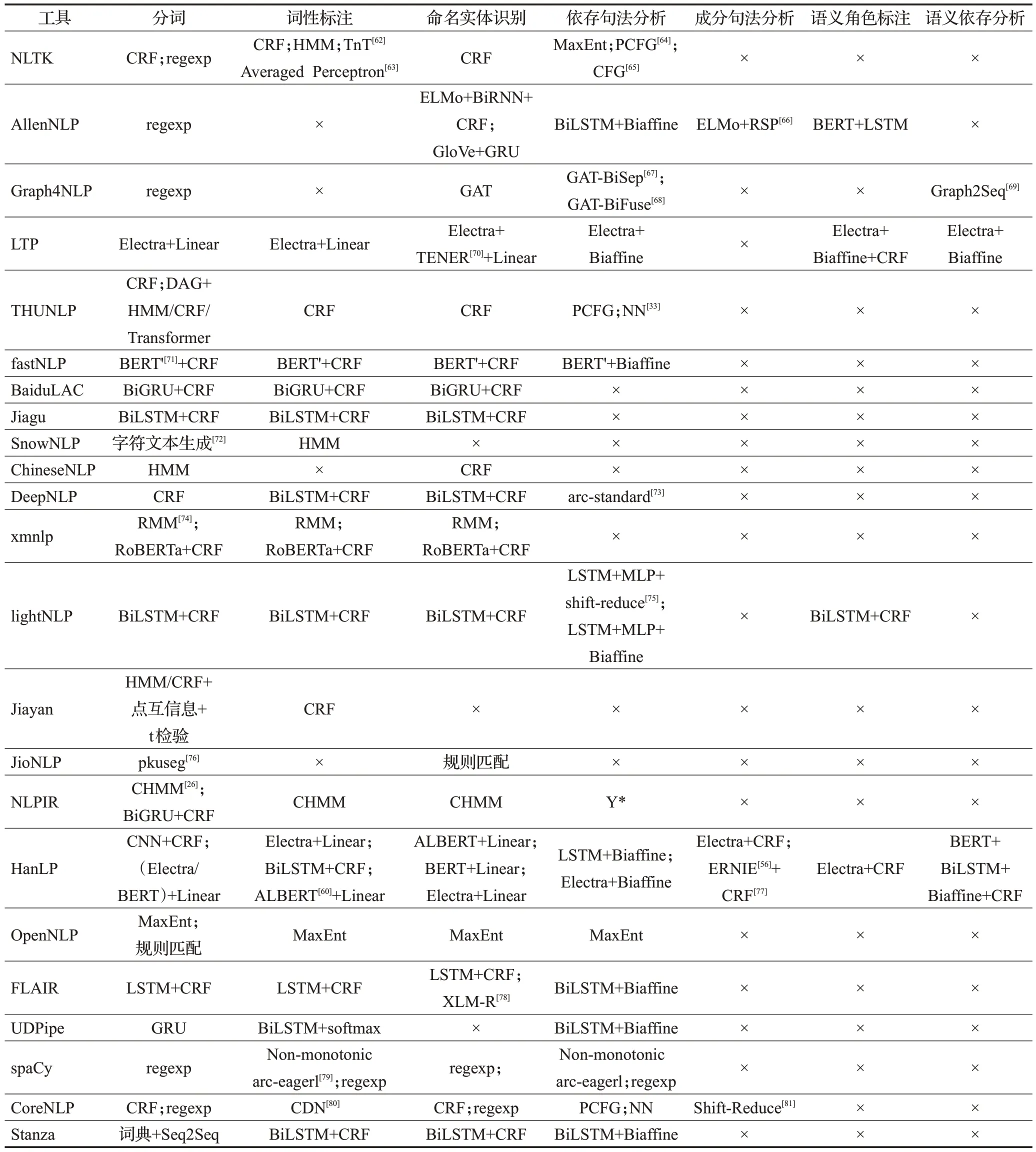
表5 基礎(chǔ)任務(wù)原理和方法Table 5 Principles and methods of basic tasks
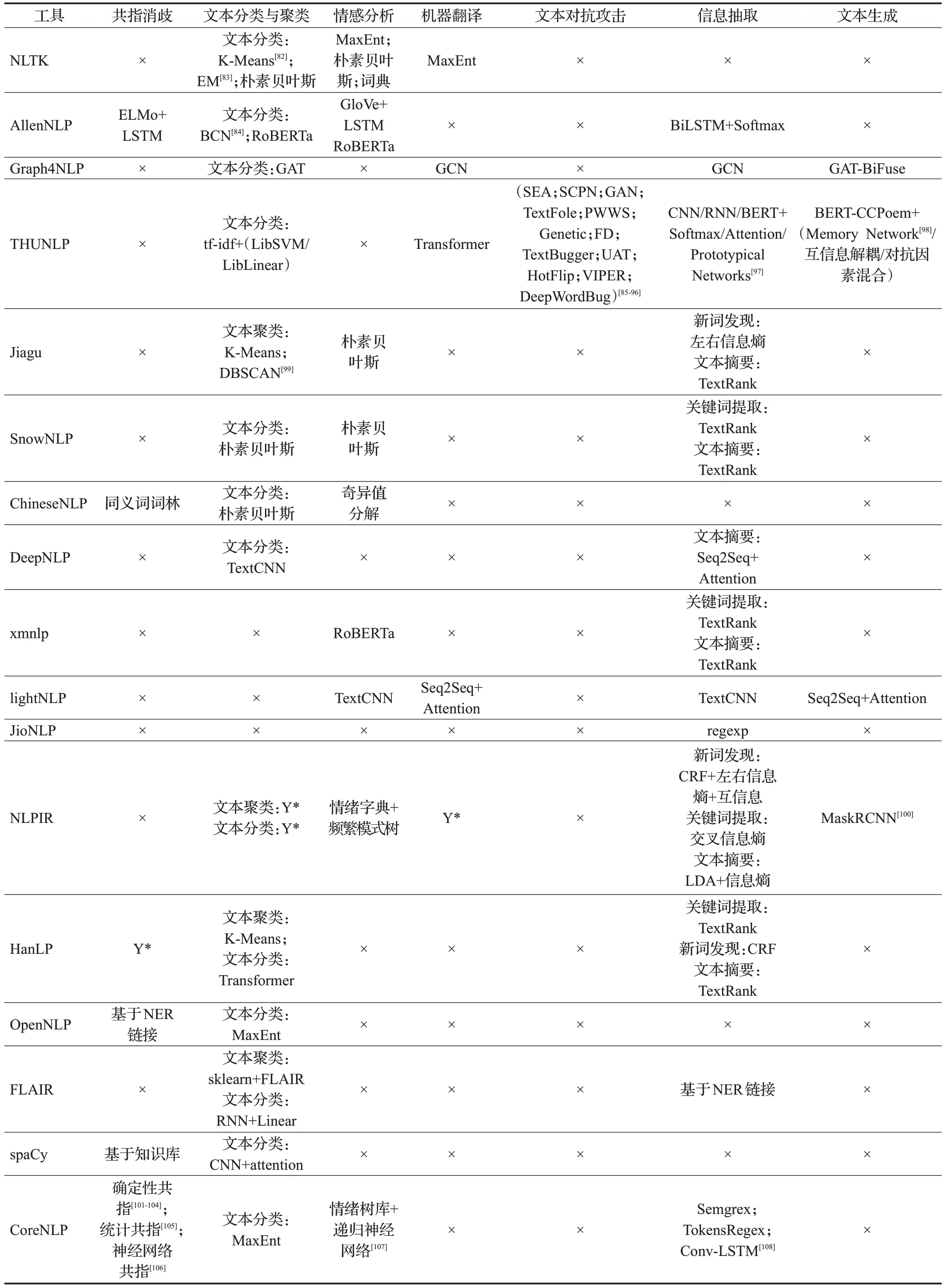
表6 應(yīng)用任務(wù)原理和方法Table 6 Principles and methods of application tasks
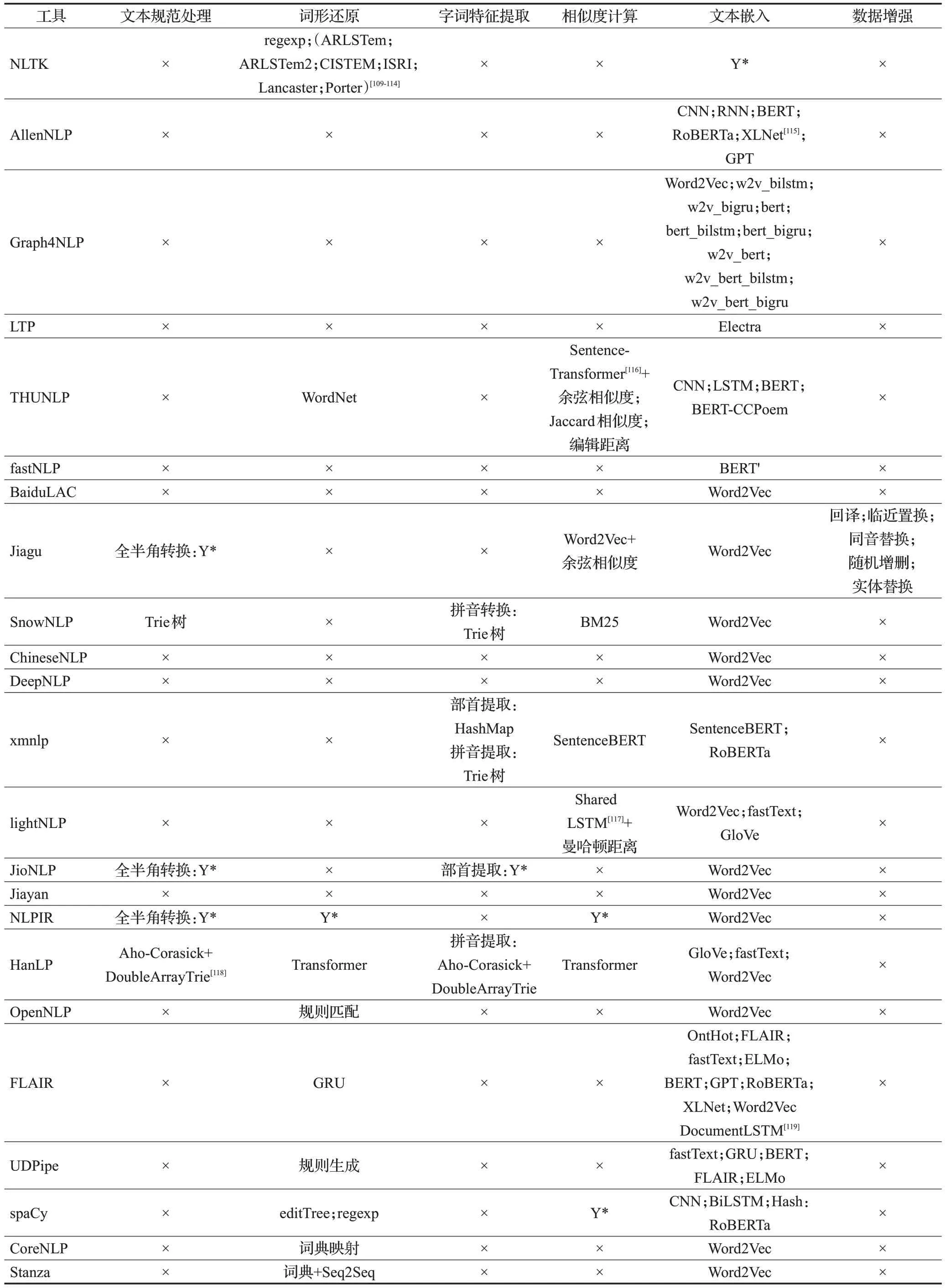
表7 輔助任務(wù)原理和方法Table 7 Principles and methods of auxiliary tasks
基礎(chǔ)任務(wù)的實(shí)現(xiàn)主要集中在詞法分析和依存句法分析,對(duì)語(yǔ)義的分析只有LTP、xmnlp、Hanlp等工具才提供支持,原因是語(yǔ)義層面的分析任務(wù)相對(duì)詞法分析更為困難,并且相關(guān)的標(biāo)注數(shù)據(jù)集較少,尤其是在中文領(lǐng)域。另一方面縱然有很多對(duì)語(yǔ)義分析相關(guān)方法的研究成果,但構(gòu)建工具時(shí)并未將其納入工具的實(shí)現(xiàn)范圍內(nèi)。
應(yīng)用任務(wù)方面多在文本聚類與分類、信息抽取、情感分析等任務(wù)上有實(shí)現(xiàn),對(duì)共指消歧、機(jī)器翻譯與文本糾錯(cuò)等任務(wù)少有工具能提供。應(yīng)用任務(wù)實(shí)現(xiàn)的方法原理多以機(jī)器學(xué)習(xí)和規(guī)則匹配為主,某些處理性能較好的工具通常將機(jī)器學(xué)習(xí)和規(guī)則相結(jié)合,也從側(cè)面說(shuō)明工具在實(shí)際應(yīng)用中更應(yīng)該注重配合,發(fā)揮出各自的優(yōu)勢(shì)。
輔助任務(wù)在研究熱度上相對(duì)較低,但大多輔助任務(wù)對(duì)文本預(yù)處理和特征提取具有重要作用,從而對(duì)基礎(chǔ)任務(wù)和應(yīng)用任務(wù)具有促進(jìn)作用。各工具主要在相似度計(jì)算和文本嵌入方面有較多支持。漢語(yǔ)輔助處理方面如繁簡(jiǎn)轉(zhuǎn)換、拼音轉(zhuǎn)換,更多考慮的是轉(zhuǎn)換速度。
4 總結(jié)與展望
本文首先依據(jù)對(duì)文本的處理順序和處理作用將自然語(yǔ)言處理中常見的子任務(wù)歸為基礎(chǔ)任務(wù)、應(yīng)用任務(wù)、輔助任務(wù)三個(gè)類別,并對(duì)任務(wù)的概念進(jìn)行描述,介紹一些任務(wù)相關(guān)的數(shù)據(jù)集。調(diào)研國(guó)內(nèi)外23款開源自然語(yǔ)言處理工具,按照工具所面向的處理領(lǐng)域劃分為英文、中文以及多語(yǔ)言進(jìn)行介紹,對(duì)工具的支持環(huán)境、調(diào)用方式以及在子任務(wù)上的優(yōu)缺點(diǎn)等進(jìn)行匯總。最后對(duì)實(shí)現(xiàn)子任務(wù)常用的原理和方法進(jìn)行探究,并對(duì)各種工具中子任務(wù)具體的實(shí)現(xiàn)原理進(jìn)行分類整理對(duì)比。
目前自然語(yǔ)言處理工具在諸多任務(wù)上取得較好的性能表現(xiàn),但仍然存在亟待解決和改進(jìn)的問題。現(xiàn)從自然語(yǔ)言處理的理論研究和工程實(shí)現(xiàn)兩大角度對(duì)自然語(yǔ)言處理工具未來(lái)的發(fā)展提出以下展望:
(1)多模態(tài)融合
當(dāng)前自然語(yǔ)言處理的研究主要集中于文本數(shù)據(jù),但文本數(shù)據(jù)對(duì)語(yǔ)義的表達(dá)具有局限性,因?yàn)槿祟愂窃诙嗄B(tài)的環(huán)境下進(jìn)行學(xué)習(xí)和使用語(yǔ)言。要使計(jì)算機(jī)對(duì)語(yǔ)言的理解更加充分,需要結(jié)合語(yǔ)音、圖像等其他模態(tài)的信息,因此基于多模態(tài)的自然語(yǔ)言處理方法將會(huì)是一個(gè)重要的研究方向。
(2)大語(yǔ)言模型
現(xiàn)有的自然語(yǔ)言處理工具只能處理詞句以及篇章級(jí)的任務(wù),在人機(jī)交互、知識(shí)問答等任務(wù)中表現(xiàn)一般。ChatGPT和GPT4的相繼問世將自然語(yǔ)言處理推向一個(gè)新的高度,這類大語(yǔ)言模型具有自主學(xué)習(xí)能力,所支持的任務(wù)效果在大規(guī)模數(shù)據(jù)驅(qū)動(dòng)學(xué)習(xí)下得到極大的提升。然而大語(yǔ)言模型也存在對(duì)語(yǔ)言中的事實(shí)缺乏認(rèn)知、邏輯推理能力弱等問題,如何提升大語(yǔ)言模型的智能水平,使其充分理解人類的情感和意圖,從而為各種語(yǔ)言任務(wù)提供有效支撐將是今后研究的熱點(diǎn)。
(3)領(lǐng)域效果融合與提升
自然語(yǔ)言處理所涉及到的內(nèi)容相當(dāng)寬泛與復(fù)雜,以中文領(lǐng)域?yàn)槔瑥臅r(shí)間維度包含先秦著作到現(xiàn)代漢語(yǔ),從地理角度不同地區(qū)又存在差異。漢語(yǔ)一直處于發(fā)展過程中,新的詞和用語(yǔ)習(xí)慣也在不斷產(chǎn)生,社會(huì)分工發(fā)展出現(xiàn)法律、醫(yī)學(xué)等不同的領(lǐng)域。雖然不少工具在通用領(lǐng)域具有一定良好的表現(xiàn),但應(yīng)用在一些具體領(lǐng)域效果卻不甚理想。即便是目前火熱的ChatGPT,它在特殊領(lǐng)域中很多任務(wù)效果十分不理想,因此應(yīng)該給予具體領(lǐng)域更多的關(guān)注或者推動(dòng)通用領(lǐng)域融合發(fā)展。
(4)模型壓縮與高效計(jì)算
近來(lái)自然語(yǔ)言處理領(lǐng)域傾向于設(shè)計(jì)越來(lái)越復(fù)雜的網(wǎng)絡(luò),網(wǎng)絡(luò)越復(fù)雜,參數(shù)越多,對(duì)數(shù)據(jù)的擬合效果也越好。然而復(fù)雜的模型對(duì)硬件設(shè)備要求較高,在移動(dòng)端上部署困難,同時(shí)復(fù)雜大模型也存在計(jì)算速度慢等問題。對(duì)此常采取的思路是將大而深或者集成的網(wǎng)絡(luò)通過知識(shí)蒸餾的方式轉(zhuǎn)移到小的網(wǎng)絡(luò)上,另外一種常見思路是通過共享參數(shù)的方式進(jìn)行壓縮。但目前在保證效果的前提下對(duì)模型進(jìn)行壓縮卻比較困難。
(5)語(yǔ)料稀缺
自然語(yǔ)言處理任務(wù)的實(shí)現(xiàn)效果不但與任務(wù)方法和模型有關(guān),還受到任務(wù)語(yǔ)料質(zhì)量的影響。許多工具雖在任務(wù)語(yǔ)料上表現(xiàn)出良好的性能,但并不具備很強(qiáng)的泛化能力。任務(wù)語(yǔ)料建設(shè)又需要耗費(fèi)大量的人力物力,中文相關(guān)的任務(wù)語(yǔ)料更為稀缺,如何利用有限的數(shù)據(jù)集提高模型的泛化能力,讓計(jì)算機(jī)充分理解文本中語(yǔ)義信息來(lái)實(shí)現(xiàn)任務(wù)是未來(lái)發(fā)展的關(guān)鍵。
(6)標(biāo)準(zhǔn)化與簡(jiǎn)潔性
正如前文提到存在數(shù)據(jù)集標(biāo)注標(biāo)準(zhǔn)多樣化問題,同一子任務(wù)不同的標(biāo)注標(biāo)準(zhǔn)會(huì)導(dǎo)致分析處理結(jié)果的差異。像Hanlp 針對(duì)不同標(biāo)準(zhǔn)訓(xùn)練不同的模型固然是一種解決方式,但也為工具的部署運(yùn)行增加了負(fù)擔(dān)。此外,某些相似的任務(wù)也可以考慮進(jìn)行融合實(shí)現(xiàn)或者進(jìn)行多任務(wù)學(xué)習(xí),例如將中文分詞、詞性標(biāo)注以及命名實(shí)體識(shí)別看作同一序列標(biāo)注問題,從而減少任務(wù)開銷。綜上,實(shí)現(xiàn)標(biāo)注標(biāo)準(zhǔn)統(tǒng)一和融合相似任務(wù)是語(yǔ)言處理工具需要考慮的一個(gè)重點(diǎn)。
猜你喜歡
文苑(2020年4期)2020-05-30 12:35:30
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學(xué)生作文(中高年級(jí)適用)(2018年3期)2018-04-18 01:24:47
華北電力大學(xué)學(xué)報(bào)(社會(huì)科學(xué)版)(2016年4期)2016-12-01 03:59:30
Coco薇(2016年2期)2016-03-22 02:42:52
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
少兒科學(xué)周刊·少年版(2015年4期)2015-07-07 21:11:17
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
