多模態圖像描述任務綜述
2023-07-29 07:23:06朱晨豪陸琪多
計算機仿真 2023年6期
朱晨豪,葉 霞,陸琪多
(火箭軍工程大學,陜西西安710025)
1 引言
近十年的時間里,深度學習技術飛速發展,2012年AlexNet[1]在ImageNet圖像識別大賽中一舉奪魁,正式拉開了深度學習技術快速發展的序幕,卷積神經網絡(CNN)和循環神經網絡(RNN)被更多學者認可,成為計算機視覺、自然語言處理、機器學習等領域進行科研實驗的主流方法。隨著研究人員數量上的增多,更多高效的網絡架構也被提出,例如:VGG[2]、Google Net[3]、ResNet[4]、LSTM[5]和GRU[6]等,逐步提高了深度學習技術在目標識別[21]、語義分割[37]等任務上的性能表現,也解決了許多現實生活中的許多問題并催生了實際應用,包括手機中的語音助手、具有人臉識別功能的門禁系統以及現在觸手可及的各種智能家居,都是深度學習技術發展為人類生活帶來的便利。
當深度學習技術在傳統的計算機視覺和自然語言處理領域取得巨大成功時,有越來越多的學者關注到了結合計算機視覺和自然語言處理領域的多模態任務,即嘗試讓機器通過構建能夠聯合多種模態信息的模型來捕捉不同模態之間的對應關系和語義特征,從而能夠同時處理多種形式的數據(圖像、音頻、文本等),加深機器對現實世界的感知。主要研究任務有多模態情感識別[42]、圖片描述[27,30,31]、視頻分類[56]、多模態對話系統[35]等,它們在現實生活中都有相應的研究背景和應用價值,以圖片描述為例,它在目標識別的基礎上,進一步提高了機器對圖像理解和描述能力的要求,不僅僅局限于識別圖像內的實體對象并給出其正確的分類標簽,而是嘗試讓機器關注圖像中實體之間的關系,以文本形式來展現圖像中所包含的信息,實現機器從看到圖像到看“懂”圖像、從感知智能到認知智能的轉變,這對人工智能無論是在技術層面的發展還是在工業應用上的推動都具有重要意義,該技術在圖片檢索、視頻描述、幫助視障人群和嬰幼兒早教方面都有極大的應用前景。
2 圖像描述方法的發展與分類
在本節中,將介紹圖像描述任務各類方法的發展情況,根據文本生成時是否依賴于人為制定的規則將所有方法分為兩大類:半自動化生成方法和自動化生成方法,在這兩類之下,又從生成規則、模型架構、模態融合等方面對各類方法進行詳細劃分,為了使讀者有更直觀清楚的閱讀體驗,方法分類結構如圖1所示。
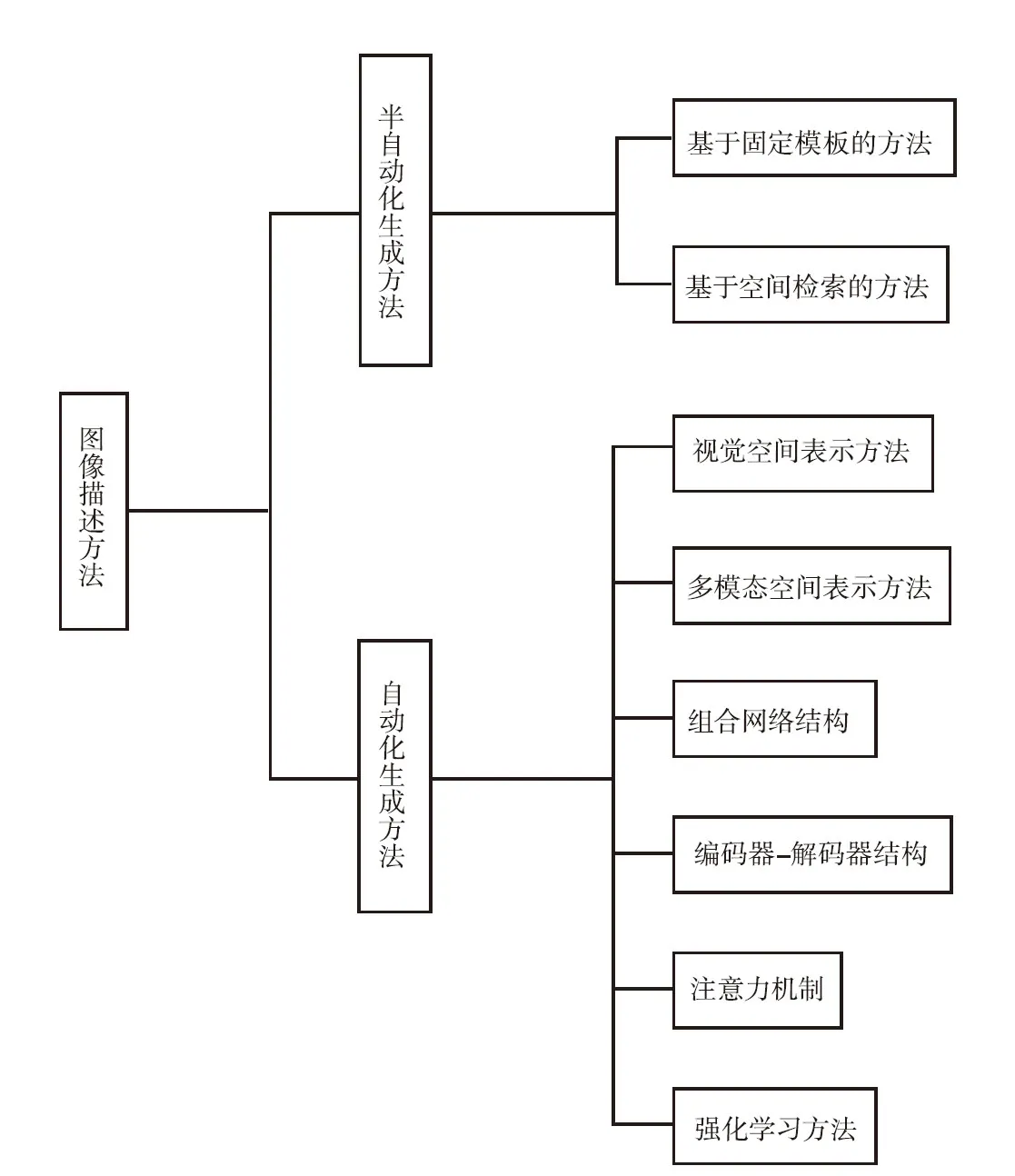
圖1 圖像描述任務的方法分類
2.1 半自動化生成方法
這類方法是圖像描述生成早期的方法,這類方法的特征是文本生成模型一般都有所依賴,要遵循已有的標題生成規則或圖像和標題的語料庫來生成圖像描述。按照生成規則的不同,又分為了基于固定模板的方法和基于空間檢索的方法。
2.1.1 基于固定模板的方法
Farhadi等人[22]提出了一個由物體、動作、場景組成的三元組模板填充方法,通過求解馬爾可夫隨機場(MRF)從圖像中檢測出相應的三元組元素,將其填充到模板相應的空白槽中來生成文本描述。Kulkarni等人[19]在此基礎上擴展介詞元素,組成四要素對模板進行填充。基于模板方法步驟分為:
1)預定義帶有空白槽的模板;
2)從圖像中檢測出對象、動作、場景等要素;
3)將上一步的要素填入空白槽生成標題。
由于該方法的模板結構和長度固定,不能根據特定圖像的需要生成變長語句描述,導致生成的文本句式固定,不同圖像描述任務生成的語句具有很高相似性,與人為自然化描述有較大差距,所以基于模板的方法不能完全勝任圖像描述的生成任務。
2.1.2 基于空間檢索的方法
空間檢索方法需要維護一定數量圖片和與之相匹配的標題組成的語料庫,將它作為圖像描述任務的檢索庫。例如,Hodosh等人[14]創建了由8000張圖片和40000條標題組成的語料庫,每張圖片有5個不同的標題來描述其中對象與事件,整個語料庫用于支撐圖片和文本的空間檢索方法。其方法概括為:
1)首先基于圖像搜索方法在檢索池中檢索相似圖像;
2)將相似圖像的標題作為候選的標題庫,然后從中選擇最為匹配語段組成標題。
該方法要花費較大的人力和時間去維護一個語料庫,如果語料庫數據范圍存在局限性導致與檢索圖像匹配度過低,則生成的標題會在語義和精確度上呈現出較差結果。而這種根據已有的標題進行檢索生成標題的方法顯然不能達到人工智能標準,因為它不能夠根據自己的理解創造性的為圖像生成標題。
2.2 自動化生成方法
隨著CNN和RNN在計算機視覺和機器翻譯任務上取得較好效果,在各大比賽中拔得頭籌時,這也直接影響了計算機視覺和自然語言處理交叉領域圖像描述任務的進展,有學者將其應用到多模態領域的圖像描述任務,提出了基于神經網絡的端到端模型,這種模型一般采用編碼器—解碼器架構,相較于基于固定模板或空間檢索的方法,該方法不依賴人為預定的生成規則或用于檢索的語料庫,生成的文本句式靈活、創新度高,對于不同圖像的描述任務有較高的泛化能力,逐漸成為研究熱點,本文從多角度將自動化生成方法分為不同類別。
2.2.1 視覺空間表示方法
該方法以卷積神經網絡學習到的視覺向量作為圖像和文本之間的媒介,將圖像特征向量和文本特征向量作為獨立輸入傳給解碼器,以生成文本。Fang等人[49]提出了詞檢測器模型,提取出圖像中可能存在的單詞表述詞集,基于這個詞集來生成文本描述。Lebret等人[50]提出用短語來表示圖像中的內容,基于短語集來生成文本描述。
2.2.2 多模態空間表示方法
單模態數據往往不能包含所有有效信息,例如:文本數據無法包含音頻中的語氣語調信息,音頻數據又無法包含視頻中的神態和肢體動作的信息。所以對于預測任務,不同模態數據之間存在語義上的互補性,多模態融合能實現信息的補充,使得預測結果更為精確。多模態數據的融合方法也成為了多模態任務中的基礎性問題,現有的融合方法主要分為三類:前端融合、中間融合和后端融合。其中圖片描述任務應用中間融合方法居多,這類方法的模態融合步驟為:
1)通過CNN和RNN,分別取得圖像特征向量和文本特征的詞向量;
2)將視覺特征向量和文本特征的詞向量映射到共同的多模態向量空間;
3)將多模態空間向量傳給語言模型解碼器生成文本描述。
Kiros等人[30]首次提出了多模態語言模型,基于對數雙線性模型提出了模態偏對數雙線性模型和三因子對數雙線性模型,該方法基于卷積神經網絡和多模態神經語言模型,通過學習圖片和文本的聯合表示來生成文本描述。在現在看了該融合方法雖然有不足之處,但它首次將多模態融合的數據表示方法引入學者視線中,對于圖像描述任務的發展仍有重大意義。Kiros等人[31]在文獻[30]的基礎之上將學習到的圖片和文本表示,通過一個全連接層映射到多模態空間,引入了結構-內容神經語言模型(Structure-Content Neural Language Model-s,SC-NLM)模型對多模態空間向量進行解碼生成標題,它能夠提取句子結構變量來指導標題的生成,降低語法錯誤概率。比較有意思的是,由于SC-NLM采用線性編碼器,學習得到的多模態空間向量也滿足加法運算性質。
Mao等人[40]提出了多模態循環神經網絡模型(M-RNN),該模型包含兩個詞向量層,一個RNN層,一個多模態層和一個SoftMax輸出層。多模態層將三個輸入(文本特征、循環層特征和圖像特征)通過元素相加的方式來映射到共同的多模態向量空間,該方法沒有考慮文本和視覺特征之間的語義關系,忽略了多模態融合時的語義對齊問題,這樣的映射處理過于粗糙會產生噪聲,對模型最終產生的結果會有負面影響,導致生成描述的準確性下降。
針對多模態融合時的語義對齊問題,Karp-athy等人[43]在文獻[36]的基礎上提出了視覺語義對齊模型,該模型由負責提取圖像視覺特征的R-CNN[21]、提取文本特征的雙向循環神經網絡(B-RNN)以及計算圖像與文本匹配得分的函數三部分組成,通過計算句子片段和圖像區域的向量點積來代表兩者的相似性度量,只將相似性最高的句子片段和對應的圖像區域進行匹配,以相互匹配的圖片區域和句子片段作為目標函數中的得分項,以不匹配的圖片區域和句子片段作為懲罰項,來不斷優化模型參數,達到語義對齊的效果。實驗結果表明,在將多模態信息進行語義對齊后,模型在圖像與句子的檢索和生成任務上的表現都有所提升。
Chen等人[51]研究了圖像和文本雙向映射的可能性,在為圖像生成描述的基礎上,嘗試讓機器能夠像人一樣通過文本描述而生成與之相匹配的畫面。在Mikolo等人[9,10]工作的基礎上做了結構上的創新,這里的模態融合把VGG網絡提取到的視覺特征作和RNN時間步t-1時刻隱藏層的輸出作為時間步t的輸入,計算出單詞Wt的概率。該文章主要貢獻分成兩個方面:
1)提出了一個全新的任務。不同于前期大家致力于由圖像生成對于描述的目標,該文獻提出了由文本描述生成對應視覺表示的全新任務;
2)提出一個可以實現文本和圖片相互轉化的雙向生成模型,該模型主要是在文獻[9,10]的基礎上增加了循環視覺隱藏層,它能根據上層RNN生成的文本來更新調整圖像內容,也可以將生成的圖像與輸入圖像視覺特征集進行比較,幫助RNN預測下一個詞語。
2.2.3 組合網絡結構
組合網絡架構[48-50,55]一般是由幾個獨立的模塊組成的非端到端模型,主要包括提取圖像特征的視覺模塊和生成文本的語言模型模塊,這類結構一般將圖片描述任務分成幾步來完成,其方法如下:
1)由CNN或其它視覺模塊提取圖像特征,包括場景、對象、屬性等信息;
2)語言模型根據步驟1中的信息生成候選文本描述;
3)根據圖片—文本相似度度量模型篩選出得分最高的文本描述。
Fang等人[49]采用bottom-up機制,整個模型由詞檢測器、最大熵語言模型和深度多模態相似模型(Deep Multimodal Similarity Model,DMSM)三部分組成,DMSM是在單模態深度結構化語義模型[59]的基礎上提出的,它由圖片模型和文本模型兩部分神經網絡組成,將文本和圖片模態數據映射到共同的語義空間,定義兩者的余弦相似度為生成描述和圖像之間的匹配程度。本文生成描述的方法為:
1)訓練詞檢測器。常用的圖像檢測方法智能檢測出圖像中的實體,而形容詞、動詞等描述性詞語很難檢測出了,為了從圖像中檢測出想要的詞,采用弱監督的多示例學習方法Noisy-OR MIL在由訓練標題組成的詞集上訓練詞檢測器;
2)提取單詞集。用訓練好的詞檢測器提取出圖像中所有可能存在的詞;
3)生成描述集。基于檢測出的單詞集,使用最大熵函數語言模型使生成的描述盡可能包含多的信息;
4)計算圖像—文本相似度。使用DMSM計算生成描述與圖片之間的相似度,選擇具有最高相似度的文本作為最終結果。
Ma等人[48]提出使用基于多層優化的多任務方法來生成〈對象,屬性,動作,場景〉的結構化詞語作為LSTM輸入生成描述。Lebret等人[50]認為圖像描述的關鍵要素是名詞短語,而名詞短語之間的作用關系則可以用介詞短語或動詞短語來表示,所以只要識別出圖像中的名詞短語、介詞短語和動詞短語后便能很好的對一副圖像進行描述,提出了一種檢測圖像短語描述的模型,由短語來生成文本描述。利用CNN從圖像中提取可能的短語集,將短語向量表示為短語中詞向量的平均值,采用約束語言模型生成文本描述,固定的生成規則會限制模型學習方向,無法學習更多自然描述方式來修飾句子,從而大大減小生成語句的靈活性。組合網絡結構的幾個組成模塊不能實現端到端訓練,需要分別學習各部分模型參數。
2.2.4 編碼器—解碼器結構
編碼器—解碼器結構是一種端到端的學習機制,網絡接收輸入圖像之后的輸出結果便是對該圖像的描述,一般由CNN視覺編碼器和LSTM語言解碼器組成,如圖2所示。
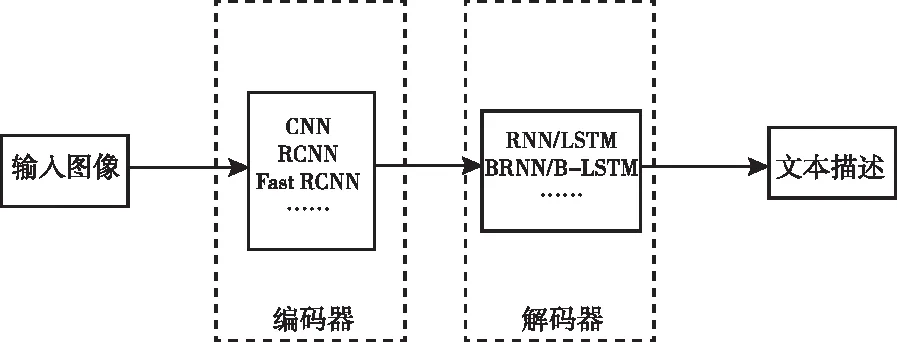
圖2 編碼器—解碼器結構示意圖
Kiros等人[31]受機器翻譯和多模態學習最新方法的啟發,將編碼器和解碼器引入了圖像描述任務,提出使用CNN和LSTM組成的編碼器學習圖片和文本表示,SC-NLM模型對多模態空間向量進行解碼生成標題。Vinyals等人[41]提出了一種神經圖像標題生成器(Neural Image Caption Generator,NIC)模型,NIC是典型的端到端模型,由CNN和LSTM組成編碼器和解碼器,CNN隱藏層的輸出作為LSTM編碼器的輸入。Wang等人[34]提出了并行RNN-LSTM結構,進一步提高了解碼效率。
經典LSTM在生成長序列時的生成效果會下降,主要問題在于CNN編碼器傳入的圖像信息只在t0時刻傳入LSTM,隨著時間步的增加,圖像信息的指導作用會逐漸減弱,LSTM也不能保留所有時間步的信息,會遺忘之前的已經生成的文本,只能結合當前時間步的輸入以及之前一定范圍內的隱藏狀態預測輸出。針對此問題,Jia等人[37]主要對LSTM提出了改進,在原有遺忘門、輸入門、輸出門的基礎之上增加了一個從圖像中提取的全局語義信息作為額外輸入,這樣LSTM的每個單元中每個門都有全局語義信息的輸入,使圖像信息能夠持續的指導文本生成,提高生成的文本與圖像內容的契合度。g-LSTM根據全局語音信息的不同又細分為基于檢索指導、語義向量指導和圖像指導。
LSTM對當前輸出的預測依賴于視覺特征和前一時刻隱藏層信息,無法根據下文信息推斷當前的輸出。為了利用上下文信息提高預測的準確率,Wang等人[53]使用雙向長短期記憶網絡(Bidirectional LSTM,b-LSTM),整個模型由負責圖像編碼的CNN,文本編碼的b-LSTM和多模態LSTM三部分組成,b-LSTM分別按照順序和倒序對輸入文本編碼,同視覺特征向量輸入多模態LSTM層嵌入到共同語義空間,并解碼成文本描述。
不難看出對于編碼器—解碼器結構的改進,主要從圖像特征提取的編碼器和生成描述的解碼器部分入手,嘗試使用性能更強大的網絡來提取圖像內的信息(圖像中的對象、對象之間的聯系等)。解碼器部分對RNN或LSTM的改進也是為了根據編碼器的輸出生成更精確的描述。未來隨著目標檢測和機器翻譯技術的進一步發展,基于編碼器—解碼器的圖像描述方法也會隨之取得更好的效果。
2.2.5 注意力機制
為了使生成描述能夠更加細致的,研究人員在原有方法的基礎上引入了注意力機制[23-29,66-72],以在特征提取方面取得更好的效果。Xu等人[27]受機器翻譯任務啟發,提出了一種基于注意力機制模型,該模型提出了軟確定性和硬隨機性兩種注意力方法。文獻[70]在文獻[27]的基礎上提出了改進,將全連接層替換為分組卷積的注意力機制。Pedersoli等人[24]提出了一種區域注意力模型,該模型使用基于空間Transformer的卷積變體來提取圖像的注意區域,將注意區域與生成的詞聯合起來,對下一時刻的生成詞和注意區域進行預測。文獻[65]提出一種多層注意力模型,多層注意力結構與多層LSTM交叉連接組成多層次的語言模型,由Faster-RCNN提取不同區域的圖像特征,分層依次傳入多層次語言模型生成描述。
在注意力驅動模型的情況下,體系結構隱式地選擇在每個時間步驟中關注哪些區域,但它不能從外部進行監督,無法控制描述哪些區域以及每個區域的重要性。Cornia等人[45]提出了一種區域可控的注意力模型,通過Fast-RCNN得到區域序列,再由排序網絡(SortingNetwork)得到排序后的區域序列,在原有LSTM基礎上增加了語塊轉換門和自適應注意力機制的視覺哨兵,前者選擇下一時間步的圖像區域,哨兵向量控制模型在預測詞語時是否根據圖像區域進行預測。
2.2.6 強化學習方法
以上所提及的工作都是監督學習方法,這些方法都存在共性問題,訓練出來的模型受限于標注的數據集,所以模型生成的文本與數據集的描述很相似,這種現象成為暴露偏差,成因是模型的輸入在訓練和推斷時的不一致造成的。在訓練時每一個詞輸入都來自真實樣本,但是在推斷時輸入用的卻是上一個詞的輸出。為解決這個問題,研究人員引入了強化學習方法。Ren等人[73]提出了基于政策網絡和價值網絡的圖像描述方法,分別起到局部和全局指導的作用,其中政策網絡根據當前狀態預測下個詞語,價值網絡評估當前狀態的可能拓展評估獎勵價值,使用了一種新的視覺語義嵌入獎勵的actor-critic強化學習方法來訓練這個模型。Ranzato等人[74]針對暴露偏差問題,提出一種新的序列訓練方法,在解碼器部分采用了基于強化學習的混合增量交叉熵增強方法 (Mixed Incremental Cross-Entropy Reinforce,MIXER),在訓練時通過隨機采樣的方法使用前一時刻預測的高概率詞語作為下一時刻的輸入,避免因訓練和測試時輸入不同問題導致生成描述的準確性降低。Rennie等人[75]提出了自我批判序列訓練(self-critical sequence training,SCST)優化算法,該方法使用貪婪搜索的方法計算獎勵信號,利用測試時的輸出獎勵規范獎勵信號,這樣可以避免估計獎勵信號和獎勵歸一化,實驗結果表明,該方法能夠提升模型訓練效果。
2.3 小結
本節從多角度對圖像描述任務方法進行分類,為了對各方法的具體效果有更直觀的展示,從各類別中選出幾個方法在MS COCO數據集上的效果進行對比,見表1。
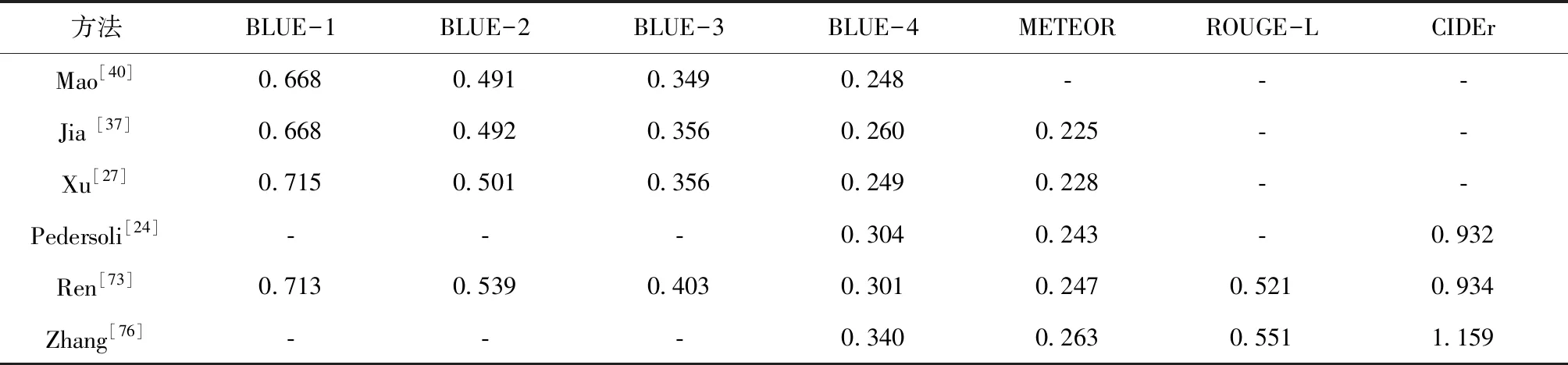
表1 不同方法在MS COCO數據集上的對比
3 常用數據集和評價指標
3.1 常用數據集
深度學習技術的發展是建立在大型數據集的基礎之上,如果沒有數據集提供給模型進行訓練,模型的各種性能的比較就無從提起。本節介紹了圖像描述領域常用的6個數據集,從圖片數量、平均標注數量、實體類別、是否分組四個方面進行對比,見表2。
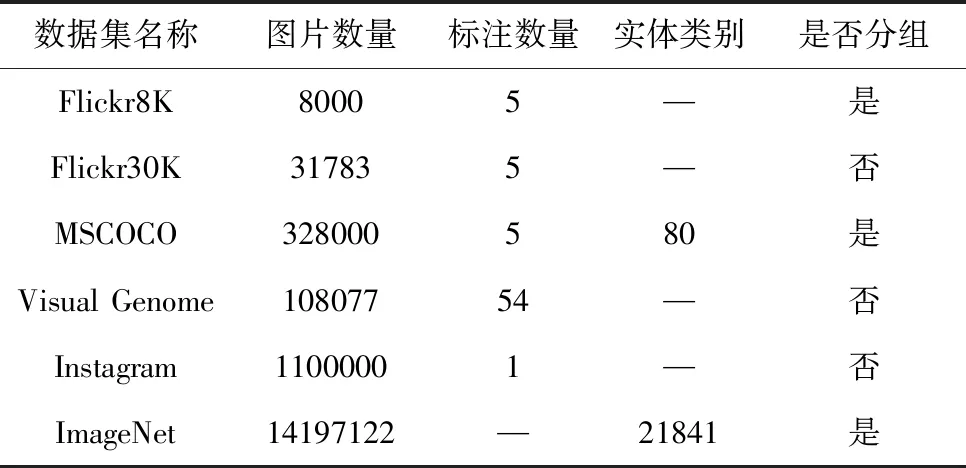
表2 數據集對比
3.1.1 Flickr8K
Flickr8K數據集總共包含8000張圖片,每張圖片配有5個不同的標注,對圖片中的內容進行了描述。其中6000張圖片和對應的標注組成訓練數據集,2000張用于測試和開發。
3.1.2 Flickr30K
Flickr30K數據集包含31783張圖像,每個圖像有五條不同的標注,共計158915句話,它沒有劃分好訓練集和測試集,訓練集和測試集的大小和內容可以由研究人員按需確定。
3.1.3 MSCOCO
MS COCO是由微軟團隊提供的用于圖像識別、語義分割和圖像標注的數據集,有超過30萬張圖片、200多萬條標注,圖像分為80種類別并且已經劃分好了訓練集和測試集。
3.1.4 Visual Genome
Visual Genome數據集是斯坦福大學李飛飛團隊于2016年發布的大規模圖片語義理解數據集,共計10.8萬多張圖片,每張圖像平均包含35個對象、26個屬性和21個對象之間的成對關系。標注工作主要包括七個部分:區域描述、對象、屬性、關系、區域圖、場景圖和問答對。
3.1.5 Instagram
Instagram數據集是由Tran等人[55]和Chunseong等人[56]提出的兩個數據集組成,包含來自Instagram應用上的約1萬張圖片,大部分是名人的照片。后者提出的數據集主要應用于標簽預測任務,包含了110萬條主題廣泛的帖子和一個來自6300多個用戶的標簽列表。
3.1.6 ImageNet
ImageNet數據集是深度學習圖像研究領域經常使用的大型可視化數據庫。超過1400萬的圖像URL被ImageNet手動注釋,來標注出圖像中的對象,在至少一百萬個圖像中,還提供了邊界框。ImageNet包含2萬多個類別,每個類別包含數百個圖像。
3.2 評價指標
由于圖像描述任務生成的是文本描述,不同于目標檢測任務,文本打分并沒有一個完美的評判標準,其中最重要的還是人類對生成描述的評價,但由于人與人的看法不同,難以有一個統一的評判標準,所以對于圖像描述任務采用有固定標準的評價機制,常用的評價指標有BLEU、ROUGE、METEOR和CIDEr。
3.2.1 BLEU
BLEU(Bilingual Evaluation Understudy)實際上是判斷兩個句子的相似程度,基于n-gram來判斷譯文與參考譯文的n元組匹配個數,得分范圍是0~1,得分越高代表模型效果越好,根據n的不同又分為不同指標,如,BLEU-1、BLEU-2等,一般只計算BLEU-1~4的得分。
3.2.2 ROUGE
ROUGE(recall-oriented understanding for gisting evaluation)是評估自動文摘以及機器翻譯的一組指標。它將生成的描述與人工描述進行比對,統計二者之間相同的基本單元的數目,來評價摘要的質量,得分越高代表模型效果越好,常用的評價標準有:Rouge-N、Rouge-L、Rouge-S等。
3.2.3 METEOR
METEOR是基于單精度的加權調和平均數和單字召回率的度量方法,它將語序納入打分范圍,通過比對生成文本與參考文本的單個詞的重疊部分,當兩者不同時適當給予懲罰來降低分數,同樣也是得分越高代表模型效果越好。
3.2.4 CIDEr
與以上方法不同,CIDEr是為圖像描述專門提出的一種評價方法,其基本工作原理就是通過度量帶測評語句與其它大部分人工描述句之間的相似性來評價相似性,CIDEr首先根據n-grams編碼參考句子中的出現頻率,根據信息熵公式,數據集中圖片出現頻率越高其包含的信息量越少,相應的其權重也應降低,通過TF-IDF計算每個n-gram的權重。將句子用n-gram表示成向量形式,每個參考句和生成句之間通過計算TF-IDF向量的余弦距離來度量其相似性。
4 結論
本文回顧了近年來多模態領域圖像描述任務的發展,對其方法從多角度進行了分類總結,深度學習的方法和強化學習方法的引入,使得圖像描述效果得到很好地提升,也產生了許多應用,但距離真正意義上使機器能夠智能化描述圖像還有不小的差距。基于目前發展趨勢,以下幾個方面可能會成為未來研究重點。
1)從監督學習轉向無監督學習圖像描述方法研究。機器監督學習需要使用有標注的圖像數據集,但圖像數據集的標注是一項耗時耗力的工作,現有標注的數據集容量遠小于未標注的數據,由于無監督學習方法可以擺脫數據集限制,使用未標注數據進行訓練,所以為了取得更好的效果,無監督學習方法可能會成為未來圖像描述任務的研究熱點。
2)帶有情感的多樣化圖像描述生成研究。通過數據集訓練得到的描述模型,其描述風格在一定程度上與數據集中描述的風格相類似,無法做到像人類一樣根據看到圖像時的情感來生成多樣化的描述,在未來的研究中,可以考慮將情感作為額外的輸入信息,來指導編碼器結構生成描述文本,從而生成多樣化圖像描述。
3)去復雜化的圖像描述模型研究。自從引入深度學習技術后,圖像描述任務的模型不斷復雜化,從組合網絡到編碼器—解碼器結構,在編碼器—解碼器的基礎上又加入了注意力機制,而且神經網絡層數的加深會導致誤差累積而降低訓練效果。模型復雜化會提高對設備的算力要求,不利于圖像描述技術在手機、車載電腦等微端的應用。所以為了使圖像描述技術更好的應用于現實生活中,模型的去復雜化研究可能成為未來的研究方向。
猜你喜歡
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
語文知識(2014年1期)2014-02-28 21:59:13
