基于CenterNet的半監督起落架自動標注
2023-05-04 02:43:22閆文君張婷婷
兵器裝備工程學報 2023年4期
方 偉,湯 淼,閆文君,張婷婷
(海軍航空大學, 山東 煙臺 264001)
0 引言
飛機降落的安全性是世界各國高度關注的問題之一,容易受到天氣、設備、自身完好性、飛行員操縱時機等多個方面因素的影響。其中,起落架收放狀態的好壞也會對降落的安全性產生不可估量的影響。因此,對起落架收放狀態進行自動檢測能有效地提高降落的安全性。
由于深度學習需要大量的標記樣本進行訓練,而關于飛機起落架檢測缺乏相關的訓練樣本,需要人工標注數據集,但利用標注軟件進行人工標注費時費力并且效率很低。半監督學習通過使用由標簽數據和無標簽數據混合而成的訓練數據來對相關模型進行訓練,可以較好地解決圖像自動標注問題。
目標檢測模型是半監督圖像標注的核心和基礎。近年來,基于深度學習的目標檢測算法因能夠自動地從圖像中提取目標的特征,具有學習能力強且識別速度快、精度高等優點,已得到大量廣泛應用。目前,流行的目標檢測算法主要有兩大類:基于有錨框的檢測算法和無錨框的檢測算法。基于錨框的方法主要有Faster R-CNN[1],SSD[2]和YOLO[3]系列算法。Faster R-CNN檢測精確度最高,但檢測速度很慢,不能滿足實時性的要求;SSD算法的檢測性能最低,但在目標定位上效果較好;YOLOv2[4]檢測精度和速度都超過了上一代,但檢測精度的提升并不明顯;YOLOv3[5]在檢測精度和速度之間取得了平衡;YOLOv4[6]擁有較高的精確度而且檢測速度也沒有下降。基于無錨框的方法主要采用關鍵點來估計目標信息,移除掉了錨框,減少了超參數,增加了網絡的靈活性,檢測精度也很高,典型的算法主要有CornerNet[7]、CenterNet[8]。CenterNet針對CornerNet的部分缺陷,進行了相關的改進,檢測速度和精度都有了一定水平的提高。在半監督圖像標注領域,謝禹等[9]提出基于SSD算法與半監督學習協同訓練的方法提高了車輛檢測中車輛標注的效率;王保成等[10]提出了基于LDA和卷積神經網絡的半監督圖像標注方法,并通過加入注意力機制和改進損失函數對卷積神經網絡進行優化使標注更加精確。稅留成等[11]提出基于生成式對抗網絡的圖像標注技術解決圖像語義標注問題,但不能直接用于目標檢測任務。本文將CenterNet目標檢測算法與半監督學習的思想結合起來對飛機的起落架進行自動標注,檢測得到的標注結果可直接轉化為xml文件構建VOC數據集,用于目標檢測任務。
1 基于CenterNet的自動標注
1.1 CenterNet網絡
CenterNet是一種端到端的無錨框的目標檢測算法,利用關鍵點估計的方法來找到目標物體的中心點,并回歸到其他目標屬性。CenterNet用到的編解碼網絡主要有沙漏網絡(hourglass network[12])、深層特征融合網絡(deep layer aggregation network[13])以及卷積殘差網絡(ResNet[14])。網絡結構如圖1所示。

圖1 CenterNet網絡結構Fig.1 The network structure of CenterNet

1.2 嵌入通道注意力機制
通道注意力機制能夠根據通道間的依賴性,自適應地分配給各通道權重,強化重要特征圖對結果的影響,弱化非重要特征的負面作用,結構簡單,效果較好。本文主要采用了ResNet50作為主干特征提取網絡,并嵌入了通道注意力SE(Squeeze-and-Excitation)[17]模塊,模塊結構圖如圖2所示。

圖2 SE-ResNet網絡架構Fig.2 The network of SE-ResNet
對于輸入特征圖X,通道空間大小為H×W,通道數為C,將SE單元模塊嵌入到殘差塊的分支上,通過全局平均池化操作將通道空間大小擠壓為1×1,然后經過第一個全連接層操作后特征圖的維度變為1×1×C/r,再通過ReLU激活函數和又一個全連接層重新回到原來的維度,這有利于減少參數量和運算量;經過sigmoid層完成對特征圖的激勵操作后得到各通道之間的歸一化權重,輸出的特征圖維度為1×1×C;最后通過Scale操作將歸一化權重與原圖像相乘,將每個通道賦予新的權重,得到的最終特征圖的維度為H×W×C。這樣在主干特征提取網絡上嵌入SE單元模塊,能夠提高主干網絡對圖像重要特征的提取,抑制無關特征,得到更高質量的特征圖,提升整個網絡對飛機起落架的檢測精度。
1.3 損失函數
CenterNet的損失函數[18-19]由3個部分組成,分別是目標中心的損失函數、目標中心的偏置損失、目標大小的損失。中心損失函數的整體思想和Focal Loss[20]類似,表示為:

(1)

由于主干特征提取網絡對圖像進行了R倍的下采樣,該操作得到的特征圖在重新映射到原始圖像后會產生細節丟失,因此,采用中心點偏置值來對每個中心點進行補償。目標中心的偏置損失表示如下:
(2)

目標大小的損失是通過回歸熱力圖與特征圖,最終得到每個目標的長寬值,計算公式為
(3)

總損失如下:
Ldet=Lk+λsizeLsize+λoffLoff
(4)
式中:λsize為目標大小預測損失權重,取0.1;λoff為目標中心點偏移損失權重,取1。
2 半監督學習
目標檢測模型需要用到大量標注數據進行訓練,而對飛機起落架的檢測由于缺少相關的標注數據集,需要進行大量的人工標注。半監督學習[21]在目標檢測領域可以使用少量有標注的樣本數據訓練目標檢測器,利用無標注數據來輔助訓練模型,從而達到提高模型性能的效果。因此,本文將半監督學習與計算機視覺中的目標檢測模型結合起來完成對大量無標簽數據的自動標注。
本文采用的標注方法如圖3所示。

圖3 自動標注流程Fig.3 The process of automatic labeling
步驟1對含有起落架的飛機圖像進行處理,把其中一部分圖像的起落架通過LabelImg標注工具進行手工標注矩形框,自動生成包含類別和位置信息的xml文件,構建目標檢測數據集,數據集采用VOC2007數據集格式。
步驟2將部分人工標注的飛機起落架圖像作為訓練數據輸入,通過訓練得到飛機起落架目標檢測模型,此時該模型的檢測能力較低,泛化能力也較弱。
步驟3將未標注的飛機起落架圖像輸入到得到的目標檢測模型中進行檢測,得到自動標注的起落架圖像,判斷得到標注圖像的置信度,對得到的問題標注數據(包括漏標記、標記錯誤、標記框位置不準確和標記置信度低于0.4的樣本)進行人工修正,得到修正后正確的標注結果,典型問題樣本如圖4所示。圖4(a)、圖4(b)、圖4(c)中前起落架均未被檢測出來,圖4(b)中將飛機尾鉤誤檢測為起落架,圖4(c)中左側起落架與尾鉤誤檢測為同一目標。

圖4 典型問題樣本Fig.4 Typical problem sampl
步驟4將問題樣本的xml文件中的起落架位置信息人工修正后與相對應的圖像組成數據集加入到已標注的數據集中開始訓練新的目標檢測模型,起到監督訓練的效果,該模型的檢測精確率會有所更高,泛化能力也應該更強。
步驟5重復步驟3、步驟4的操作,不斷更新數據集訓練得到新的目標檢測模型,直到全部未標注的飛機起落架圖像都迭代進模型中完成檢測時或精確率達到95%同時平均準確率達到90%終止迭代,此時檢測的平均準確率達到最高的模型為最終的檢測模型。
步驟6將網絡上隨機選取的飛機起落架圖像輸入到最終得到的檢測模型中去,驗證檢測效果。
3 實驗過程與結果分析
本文采用的數據集是飛機降落過程中含起落架的圖像數據,共有1 800張圖片,其中800張圖片進行了手動標注,1 000張圖片未經過手動標注,再從網絡中隨機選取飛機起落架圖片對模型效果進行測試。
3.1 實驗環境
本文采用CPU為Intel core i9處理器,32 GB的內部存儲器,GPU處理器為NVIDIARTX 3080Ti;實驗平臺為Windows 10;軟件環境是Python 3.7,Anaconda 3,CUDA11.0。輸入圖像尺寸統一為512×512像素,訓練參數設置為每次迭代訓練樣本數為4,最小學習率為0.000 01,最大學習率為0.001,訓練次數設為100次,置信度設為0.4。
3.2 評價指標
本文采用精確率(Precision)、召回率(Recall)、平均精確度(mAP)來評價起落架檢測模型的性能。精確率與召回率的公式為:
(5)
(6)
其中:TP表示被正確預測為起落架的正樣本的數量;FP表示被預測為起落架,但實際上為假樣本的樣本數量;FN表示被預測為假樣本,但實際為正樣本起落架的樣本數量。精確率表示模型檢測出來的起落架并且真正為起落架的數量占模型檢測為起落架的比例,體現了模型檢測的準確性。召回率表示模型檢測出真實為起落架的數量占所有真實為起落架的比例,體現了模型識別真實起落架的能力;但是,精確率與召回率相互制約,很難同時提高,因此,引入了更具說服力的平均精確率mAP來評價算法的檢測性能,mAP越高,性能越好。
3.3 實驗結果分析
為了更好地評估Se-CenterNet網絡模型的檢測效果,分別選用了YOLOv3、YOLOv4、CenterNet三種目標檢測模型進行對比實驗,訓練數據集為800張人工標注的飛機起落架圖像,圖像尺寸為512×512像素,不同模型得到的檢測結果如表1所示。

表1 不同檢測模型的檢測結果Table 1 Test results of different test models
由表1可知,模型Se-CenterNet與YOLOv3、YOLOv4網絡相比的召回率較低,但檢測精確率高達94.62%,平均準確率mAP也達到了86.19%;YOLOv3、YOLOv4雖然召回率更高,但檢測精度與平均準確率相差較大,無法滿足需求。與原CenterNet模型相比,嵌入SE模塊后,mAP提高了3.6%。綜合來看,相比于其他幾種檢測模型,模型Se-CenterNet在對起落架的檢測上檢測效果更好。
為了驗證SE模塊在本文數據集中對CenterNet網絡檢測精度的提升效果,特設計消融實驗將其與CBMA、ECA兩種注意力機制進行對比,實驗結果如表2所示。實驗結果表明,在本文數據集中,嵌入SE模塊后得到的mAP為86.19%,比嵌入CBMA、ECA兩個模塊的mAP分別提升了2.8%、1.7%,檢測效果較好。因此,后續實驗中將采用Se-CenterNet模型來對起落架進行自動標注。
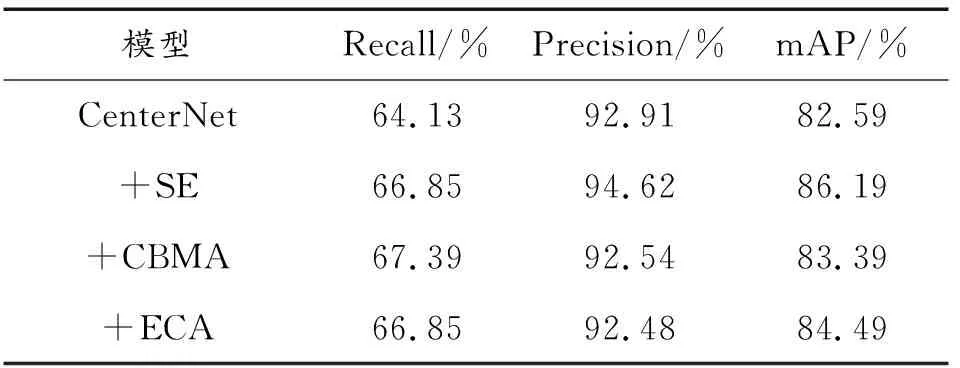
表2 不同注意力模型檢測結果比較Table 2 Comparison of test results of different attention models
在上述實驗的基礎上對迭代模型的訓練效果進行分析,將1 000張未標記的飛機起落架圖像平均分成5個部分,每個部分200張圖像。將由800張標記圖像組成的數據集1訓練得到的檢測模型記為模型1;將200張圖像輸入到模型1中進行測試,對測試結果中不準確的標記信息手動修正后組成1 000張圖像的數據集2重新訓練得到新的檢測模型記為模型2;將數據集2+200張手動修正圖像組成數據集3在模型2的基礎上訓練得到模型3;將數據集3+200張手動修正圖像組成數據集4在模型3的基礎上訓練得到模型4;以此類推,分別得到模型5與模型6。實驗過程中,發現在模型5時精確率達到95.29%、mAP達到92.16%,滿足迭代終止條件。因此,模型5為最終得到的目標檢測模型。每個模型輸出的準確率與mAP如表3所示。

表3 不同模型的精確率與mAPTable 3 Precision and mAP of different models
隨著迭代次數的增加,模型的精確率與平均準確率mAP都呈現上升趨勢,達到了很高的水平,起到了監督訓練的效果,對飛機起落架的檢測效果也不斷增強,滿足預期的設想。
為評估最終得到的目標檢測模型的性能,從網上選取一張飛機圖像對起落架進行標注,標注效果如圖5所示。從圖5中可以看出,模型對各個起落架的檢測概率不同,這主要是由于背景遮擋的不同引起的,前起落架背景遮擋較為嚴重,檢測概率僅為51%,左側起落架次之,檢測概率為59%,右側起落架效果較好,檢測概率為75%。從標注的整體效果看,沒有發生錯誤標注和漏標注的情況,細微的偏差也不會影響起落架的標注結果,都可以準確地定位到飛機的3個起落架,達到了自動標注的目的,說明采用嵌入通道注意力機制的CenterNet目標檢測模型與半監督學習相結合的方法可以完成對飛機起落架的自動標注。

圖5 標注效果Fig.5 Annotation effect
4 結論
本文針對人工標注飛機起落架費時費力的問題,提出了嵌入通道注意力機制的CenterNet目標檢測算法并比較了幾種檢測算法和注意力模塊的性能,實驗結果表明該模型具有較好的檢測性能;將其與半監督學習結合起來解決自動標注問題,通過標注數據訓練模型,無標注數據用于檢測,測試結果用來生成xml文件,每次模型訓練都疊加手動修改的問題樣本擴充數據集,起到監督訓練的效果,經過不斷地迭代訓練,模型的精確率與平均準確率不斷上升,迭代5次后精確率達到95.29%,平均準確率達到92.16%,對飛機起落架的檢測達到了較好的效果,為后續大量飛機起落架數據集的制作提供了算法基礎。下一步工作將繼續優化算法,提高算法對背景遮擋較為嚴重的飛機起落架的檢測能力,并將其應用于起落架標注工作中去,為提升飛機降落的安全性提供一定的參考。
猜你喜歡
環球時報(2022-05-30)2022-05-30 15:16:57
中老年保健(2021年12期)2021-11-30 02:58:01
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
當代陜西(2019年11期)2019-06-24 03:40:28
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
作文周刊·小學一年級版(2017年9期)2017-06-20 00:19:33
Coco薇(2016年8期)2016-10-09 02:11:50
