基于深度玻爾茲曼機的工業機器人齒輪箱故障診斷
2023-05-04 03:01:52喻其炳孔麗杰喻愷馳
兵器裝備工程學報 2023年4期
喻其炳,孔麗杰,白 云,喻愷馳
(1.重慶工商大學 教育部廢油資源化技術與裝備工程研究中心, 重慶 400067;2.重慶工商大學 管理科學與工程學院, 重慶 400067;3.北京理工大學 睿信書院, 北京 102401)
0 引言
工業機器人是智能制造行業中的重要技術裝備,其中齒輪箱作為工業機器人的重要組成部分,其能否正常運行直接影響工業機器人的健康狀態,工業機器人齒輪箱的故障診斷對于工業機器人的狀態運維至關重要[1]。
近年來,國內外學者對齒輪箱的狀況監測和故障診斷主要基于3種理念:模擬齒輪箱不同負載下的故障建模;采用時域、頻域、時頻域等方法進行信號處理;數據驅動的智能診斷方法[2]。前2種理念比較依賴先驗知識,應用對象相對簡單,難以分析海量數據中抽象的特征,因此,基于數據驅動的智能診斷方法成為故障診斷的重要工具。楊宇等[3]采用雙樹復小波包提取重構信號中的故障能量特征作為支持向量機診斷模型的輸入,有效提高降噪效果;Xiao等[4]訓練出由12個粒子群算法優化的BP神經網絡提高了齒輪箱故障診斷識別率;Shi等[5]提出了一種改進的K最近鄰算法的方法來界定合適的k值進行齒輪箱故障診斷。鑒于淺層機器學習診斷方法具有難以對信號進行深層次的特征提取和繁瑣的參數尋優的局限性,深度學習成為了故障診斷領域的研究熱點[6-7]。Guo等[8]提出一種基于改進深度卷積神經網絡,能有效對軸承故障模式和故障程度進行識別、評估;李濱等[9]采用 Dropout 優化后的深度信念網絡實現對磨損程度的精準預測;Shao等[10]提出用降噪自動編碼器和壓縮自動編碼器構造了一種新的深度自動編碼器,增強特征學習能力;曹正志等[11]提出利用改進的1D-CNN-LSTM模型并引入遷移學習模型,能夠以較快的速度對滾動軸承6種不同工作狀態進行分類識別。
其中,在以工業機器人齒輪箱為故障診斷對象的研究方法中,Chen等[12]設計了一種新型的具有頻譜計算和故障診斷功能的卷積神經網絡應用于重型工業機器人系統;Kim等[13]提出基于相位的時域平均方法對工業機器人中的齒輪箱進行故障檢測;趙威等[14]提出基于邊-云協同和深度學習的工業機器人齒輪箱等核心部件健康評估方法。然而,在面對結構復雜、運行條件多變、故障機制不明確等大型工業旋轉機械系統時,所構建的診斷模型仍存在挑戰。
工業機器人是集機械、傳感器、計算機、控制器、人工智能等多學科技術于一體的典型復雜工業設備[15],所處的運行環境也隨著社會生產生活的應用場景的多樣性,對信號采集具有更高的要求。然而復雜的工業機器人結構和極端工況導致齒輪箱的故障特征易受到噪聲干擾,同時,機械設備運行過程中收集到的信號存在無標簽的樣本,而DBM可以從大量未標記的數據中學習深層特征,在DBM的逼近和求導過程中,除了自下而上的傳播外,還包括自上而下的反饋,使DBM能夠更好地傳播輸入數據的特征[16]。因此,本文中將DBM應用于不同工況下工業機器人齒輪箱的故障診斷。
本文中基于BRTIRUS1510A工業機器人實驗平臺,在不同工況下分別收集了6種故障模式的信號,分別測試了單一工況和復雜工況的故障診斷效果。同時,與其他經典故障診斷模型:人工神經網絡(artificial neural network,ANN)、深度置信網絡(deep belief network,DBN)、棧式自編碼器(stacked autoencoder,SAE)、K最近鄰(k-nearest neighbor,KNN)、支持向量機(support vector machine,SVM)進行比較,進一步驗證DBM模型的故障診斷性能。
1 相關理論基礎
1.1 振動信號的統計特征提取
小波包變換可以有效提高信號中的統計參數的性能,從而反映機械設備在一段時間內的健康狀況[17]。因此,本文中采用WPT對故障產生時的振動信號x進行預處理,將每個樣本包含的振動信號進行小波分解,從而得到每個節點的小波包能量X(i),再對其進行統計特征的提取,N為節點能量的長度,具體統計參數信息如表1所示。

表1 時域特征Table 1 Time domain characteristics
1.2 DBM模型定義
DBM是由多個受限玻爾茲曼機(restricted boltzmann machine,RBM)串聯堆疊而形成的一個深層神經網絡,如圖1所示,DBM由d個RBM組成,其中,RBM1由可視層v和隱藏層h1組成,可視層用于數據輸入,隱藏層用于提取數據特征,層間節點對稱連接,同層節點間無連接,同時,RBM1的隱藏層h1又作為后面的RBM2的可視層,以此類推組成由多個RBM堆疊而成的DBM網絡。與深度信念網絡相區別的是,DBM的任意兩層之間都是雙向連接的,代表了特征信號可以雙向傳遞[18]。
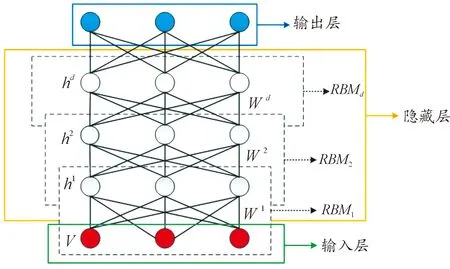
圖1 DBM結構圖Fig.1 DBM structure diagram
RBM的訓練過程實際上是求出一個最能產生訓練樣本的概率分布。求出的分布函數需要滿足這個分布下產生訓練樣本的概率最大,由于這個分布的決定性因素在于權值系數(W1,W2,…,Wd),因此訓練RBM的過程就是運用對比散度算法尋找最佳的權值的過程。
DBM是基于能量的模型,模型變量的聯合概率分布由能量函數參數化。其中v和h分別表示可見層和隱藏層的神經元集合,代θ={W,b,c}表模型待定參數,b和c分別為可見層和隱藏層神經元的偏置,(v,h)的聯合概率由下式給出:
在給定可視層v時,可通過聯合概率分布推導出隱藏層第j個節點開啟(激活狀態設置為1)或關閉(抑制狀態設置為0)的概率。同理,在給定隱層h時,也容易推導出可視層第i個節點為1或者0的概率:
假定給模型輸入G個樣本,通過最大化重現輸入,即最大化帶權值懲罰的對數似然目標函數來求模型參數。使用上式中的隱藏層和可見層的概率來建立概率目標函數L(θ),并通過最大化當前觀測樣本的概率來選擇一組模型參數θ*:
模型訓練通過對比散度算法(contrastive divergence,CD)[19]進行。首先,可見單元的狀態被設置成一個訓練樣本,計算隱藏層單元的二值狀態,在所有隱藏單元狀態確定了之后,再來確定每個可見單元取值為1的概率,進而得到可見層的一個重構。具體步驟為:取初始值,其中t=1,2…,k,利用P(h|v(t-1))采樣出h(t-1),再利用P(v|h(t-1))采樣出v(t),接著對每個參數求偏導:
根據以下規則更新權重:
W∶W+λ(P(h(0)=1|v(0))v(0)T-P(h(1)= 1|v(1))v(1)T)
1.3 基于DBM的故障診斷系統
基于DBM的工業機器人齒輪箱故障診斷系統如圖2所示。具體流程如下:
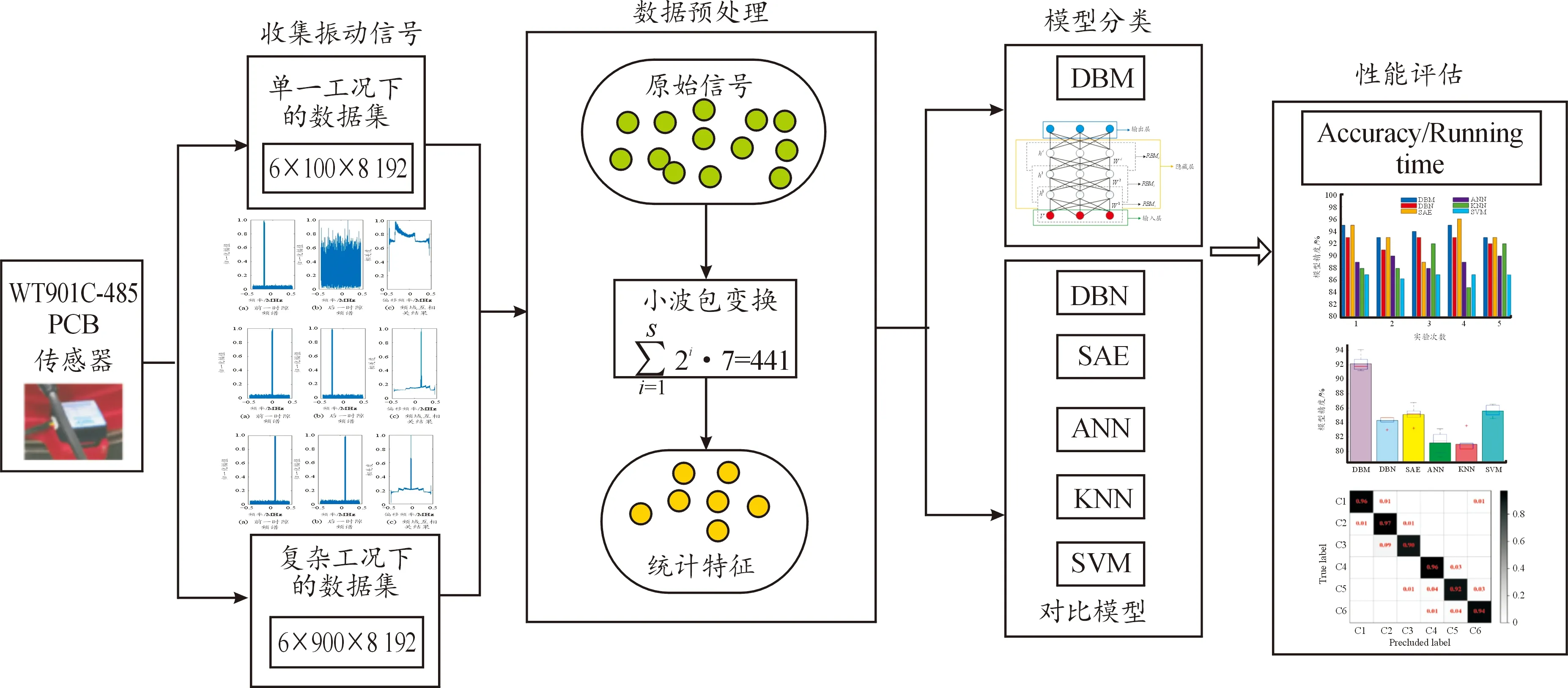
圖2 DBM故障診斷系統Fig.2 DBM fault diagnosis system
1) 分別在單一和復雜的工況下收集原始數據集x。
2) 原始振動信號x通過小波包變換進行處理,獲得統計特征矩陣X(i)。
3) 使用統計特征矩陣及其相應的故障類別標簽來訓練DBM,并與其他故障分類模型對比。
4) 調整模型參數后,獲得每個模型的精度和運行時間,評估DBM的應用性能。
2 實驗測試
2.1 基于單一工況的實驗
搭建的實驗平臺基于負載可達10 kg、擁有1 500 mm臂展的BRTIRUS1510A六自由度工業機器人。其中,一軸、二軸和三軸被稱其為機器人的手臂,四軸、五軸和六軸被稱其為它的手腕。機械臂的運動是將交流伺服電機作為其動力源,機械臂與機械臂之間通過RV減速器連接,最終可以保證機械臂精確、可靠的運行。
表2是工業機器人在運行期間的工況信息設置。實驗平臺如圖3所示,實驗在第二軸和第三軸減速器上模擬了不同故障,詳見表3。
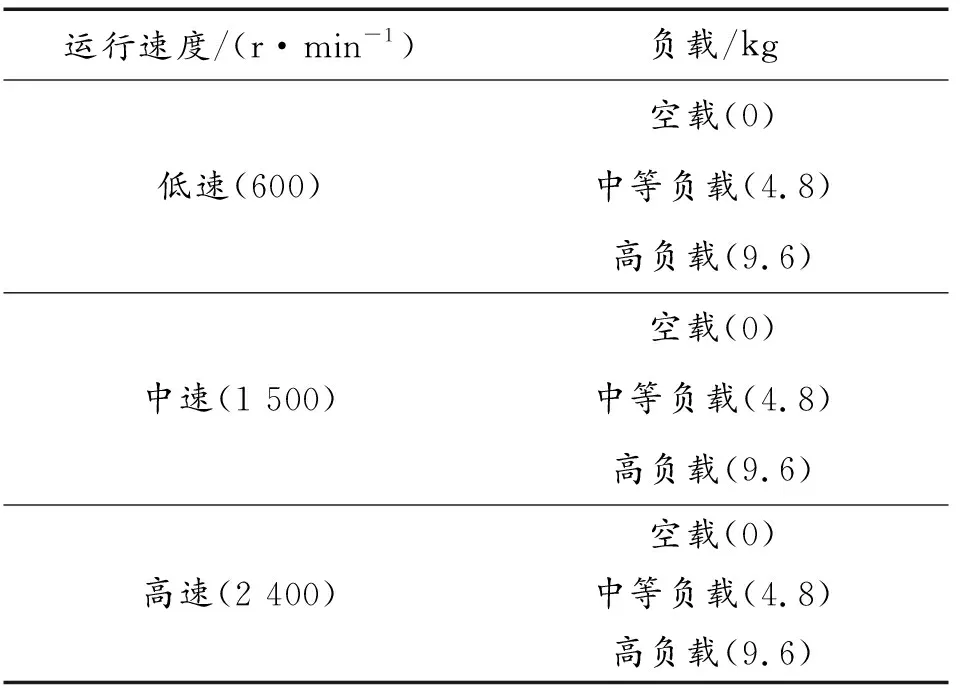
表2 工況信息Table 2 Condition information

圖3 工業機器人實驗裝置Fig.3 Industrial robot experimental device
由于工業機器人的每個部分都是剛性連接的,其運行過程中的振動信號可以傳輸到每個位置,所以將采集振動信號的加速度傳感器分別放置于第2軸和3軸的故障位置處,可采集到大量有價值的數據。加速度傳感器通過網線與筆記本相連接之后,可以從筆記本里面的上位機軟件(即采集系統)對傳感器內置的參數進行設置、實時數據進行查看以及采集數據的保存,從而監測齒輪的健康狀況。加速度傳感器的采樣頻率為100 kHz,采樣時間為20 s,測量精度為1%,所產生的器件噪聲可能對振動信號的采集有較大干擾。
常見的齒輪箱傳動失效形式有斷齒和點蝕,如圖4所示,圖4(a)是將行星輪通過銑削加工的方式來模擬出斷齒故障;圖4(b)是將太陽輪通過激光點焊的加工方式來模擬出點蝕故障。

圖4 故障模擬圖Fig.4 Fault simulation
在本次實驗中,將每個輪齒的單一故障定義為一種故障模式,如表3所示,本次實驗總共設置了6種故障模式,分別標記為C1、C2、C3、C4、C5和C6。本表還詳細介紹了本次實驗所模擬的齒輪故障類型、故障位置以及故障程度等相關信息。
實驗2.1選擇工業機器人在低速(600 r/min)和空載(0 kg)下運行的振動信號作為診斷單一工況下齒輪箱的故障類別的樣本。圖5顯示了加速傳感器在上述單一工況下收集的6種故障的原始信號示例,由于不同信號之間振動的間隔時間具有不同的連續性,所以C1和C5的原始振動信號圖明顯不同。
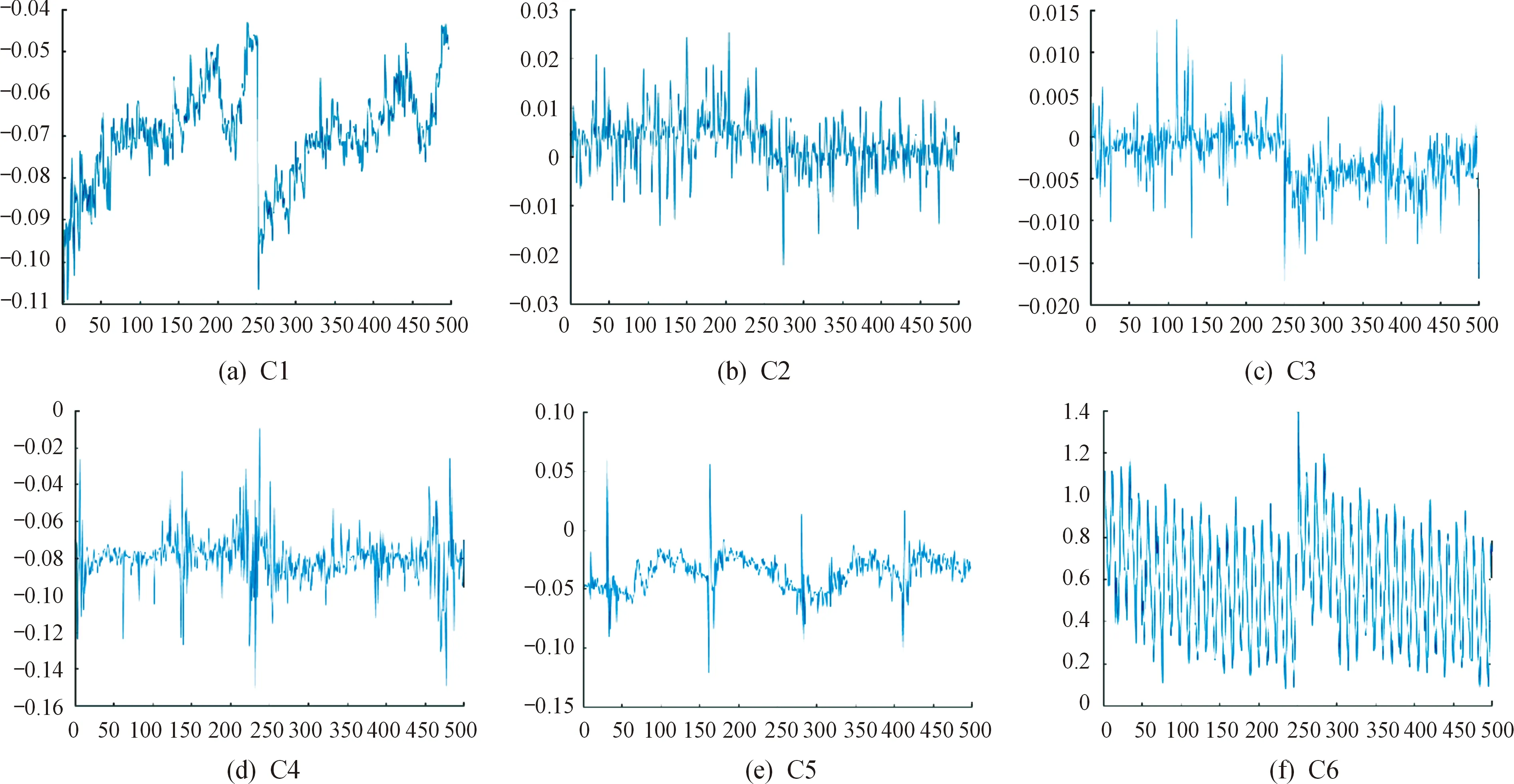
圖5 6種故障信號的樣本示例Fig.5 Sample examples of six fault signals
首先在單一工況下采集工業機器人的6種故障模式對應的振動信號,每種故障模式采集819 200個數據點,設置樣本長度為8 192,構建6×100×8192的樣本特征矩陣;然后,對每個樣本進行5層小波包變換,并在每層的計算中獲得表1所示的7個統計參數,因此,經過小波包變換后的樣本維度為,最終得到特征矩陣大小為 600×441。如表4所示,每100個樣本對應一種故障類型。

表4 相同工況下的樣本信息Table 4 Sample information under the same working condition
隨機選擇數據集的 500 個樣本用于 DBM 模型和其他深度模型的訓練,其余100個樣本用于測試。
2.2 基于復雜工況的實驗
實驗2.2進一步評估了所提出的DBM模型在復雜工況下的性能表現。對于每類故障樣本,復雜工況下的實驗選擇工業機器人在3種運行速度(600、1 500、2 400 r/min)和3種載荷(0、4.8、9.6 kg)共9種工況下運行的振動信號進行混合,從而得到同一故障類別下,包含所有工況的故障信號,作為診斷復雜工況下齒輪箱故障的樣本。
實驗數據收集參數設置與上述第2.1節相同,在6種故障類型和9個工況下,分別選擇 819 200個數據點,每個樣本長度設置為8 192,原始特征矩陣為5 400×8 192的矩陣。經過5層小波包變換后,特征矩陣的大小轉換為5 400×441,即5 400個樣本,每個樣本長度為441。其中,每900個樣本對應一種故障,共6種故障樣本,然后根據5∶1的比例將樣本分為訓練集和測試集。
2.3 對比實驗
本文中選擇了5種模型參與對比實驗:ANN具有非線性自適應信息處理能力,在模式識別[20]中表現出良好的智能特性;DBN是由多個受限玻爾茲曼機RBM堆疊的深度學習模型,它是一種代表性的無監督學習方法,可用于特征學習或預訓練網絡,與DBM的差別在于前者使用逐層貪婪方法進行訓練,時間較長,后者的特征信號一直往上傳,低層分布求解依賴于高層的分布[21];SAE是由多層自編碼網絡堆疊而成的深度網絡,前一層自編碼器的輸出作為其后一層自編碼器的輸入[22],能更好地學習輸入數據的特征表示;KNN主要是根據樣本空間中最近的K個樣本的數據類別[23]確定預測樣本的數據類別。由于其算法復雜度低、簡單有效,被廣泛應用于數據挖掘和機器學習;SVM使用核函數將原始數據映射到高維Hibbert空間,解決原始空間中的線性不可分離性問題[24],對非線性系統具有良好的學習能力和推廣能力。
3 實驗結果和分析
上述的所有實驗的訓練和測試過程均使用Matlab 2016b 編程,并在配置Intel?Core (TM) i5-4590 CPU @ 3.3GHz處理器和16 GB RAM的電腦上執行。
3.1 基于單一工況的實驗結果
不同故障診斷模型的主要參數設置如表5所示,其中,I、H、O分別表示網絡輸入層、隱藏層和輸出層。

表5 模型主要參數設置Table 5 Model main parameter settings
對于每個模型,在相同的參數下都進行了5次平行試驗。具體的實驗結果如圖6和表6所示,其中,基于DBM的故障診斷模型在對比實驗中達到了最高的平均識別精度;通過比較表6中6個模型的平均計算時間,可知在同一樣本數據集中,由于深度網絡結構的復雜性高于淺層網絡,深度神經網絡的計算時間略高于其他分類模型,但準確性普遍較高,而在深層網絡中,DBM在工業機器人的故障診斷和分析中表現了更強的識別能力。

表6 不同模型故障診斷結果Table 6 Fault diagnosis results of different models

圖6 基于單一工況的故障診斷精度圖Fig.6 Fault diagnosis accuracy based on single working condition
3.2 基于復雜工況的實驗結果
在復雜工況下進行實驗,得到不同故障診斷模型的主要參數設置如表7所示,其中,I、H、O分別表示網絡輸入層、隱藏層和輸出層。

表7 模型主要參數設置Table 7 Model main parameter settings

續表(表7)
同理,對于每個模型,在相同參數下進行了5次試驗。圖7使用盒形圖可視化地總結每個模型精度的數值分布,可以看出,DBM的方框處于其他5種模型的上方,且方框的長度較短,意味著模型的精度值分布較為集中,進一步說明了在復雜工況下,DBM捕獲的特征信息更具有代表性。

圖7 故障診斷模型精度對比Fig.7 Accuracy comparison of fault diagnosis models
由表8可知,在復雜工況下,基于DBM模型的故障診斷平均識別率仍然是對比實驗所得結果中的最高精度,最高為94.11%;平均診斷精度排在第二的是SAE,為85.13%;隨后依次是SVM、DBN、ANN、KNN。
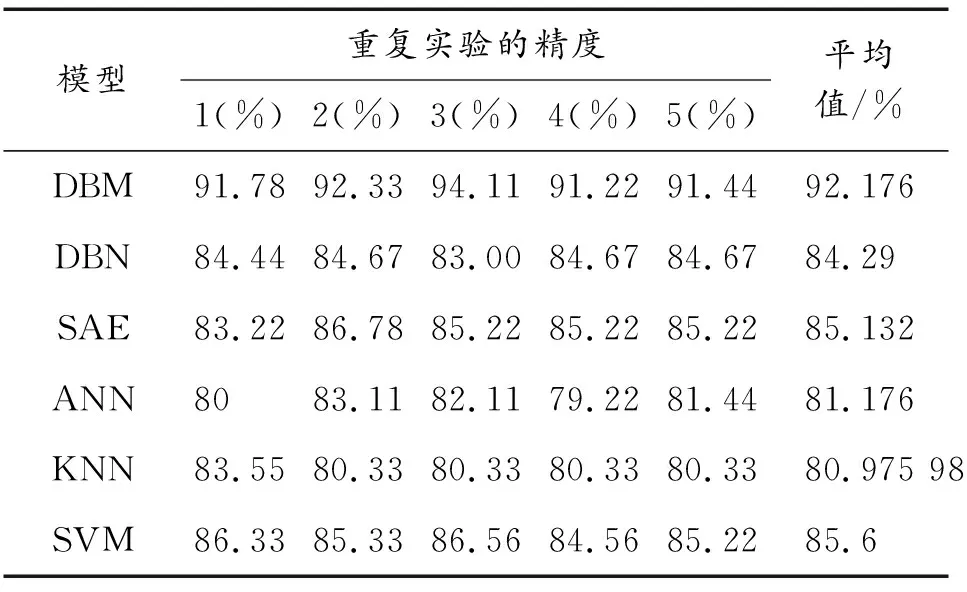
表8 基于復雜工況的不同模型故障診斷精度對比Table 8 Comparison of fault diagnosis accuracy of different models based on complex working conditions
圖8所示的混淆矩陣進一步分析了每個模型對每一類故障樣本的分類情況。混淆矩陣的每行對應標簽的真實值,每列對應模型的預測值,當混淆矩陣對角線上的比值較高時,意味著該類樣本的分類效果較好。

圖8 混淆矩陣Fig.8 Confusion matrix
顯然,圖8(a)所示的DBM對每一類故障的分類情況比其他模型更好。在DBM的混淆矩陣中,誤判率最高的情況為C3被錯誤地歸類為C2,其誤判率為9%,這是由于C2和C3為模擬的同種故障類型,即斷齒,同時,由于C5和C4的故障位置都為第三軸太陽輪,所以也出現了誤判。
其他故障診斷模型出現的誤判也主要發生在相同故障類型之間、同一故障位置之間的故障類別。綜合來看,DBM的混淆矩陣的誤判率在6個模型中較小,其故障診斷性能優于其他模型。
實驗結果表明:具有深層網絡結構的DBM、SAE和DBN通過隱藏層的學習和高效的參數優化算法提取到了數據中抽象而全面的特征信息,均表現出了較好的診斷性能,而SVM比DBN略好1.31%的平均識別率,說明基于高斯徑向基函數的分類器在復雜工況的實驗中也能表現較好的分類能力。在處理同一樣本數據集的過程中,由于深度網絡結構的復雜性高于淺層網絡,所以深度神經網絡的計算時間略高于其他分類模型,但深度網絡的分類準確性普遍較高。綜合來看,基于DBM的模型能夠更全面地學習信號表示,在故障診斷實驗中表現出較好的魯棒性。
4 結論
本文中將基于DBM的故障診斷系統應用于結構復雜、高度精密的六自由度工業機器人,實驗證明DBM能獲取故障信號中更復雜、抽象的潛在表示,提升故障分類的識別準確率。同時,通過在單一工況和復雜工況下與其他故障分類模型進行對比分析,結果表明基于DBM的故障診斷模型具有最好的模式識別性能,可以有效地應用于工業機器人齒輪箱的多工況多故障分類問題。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
電子制作(2018年11期)2018-08-04 03:25:42
汽車維護與修理(2016年10期)2016-07-10 08:17:41
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
