面向SD-DCN 的OpenFlow 分組轉發能效聯合優化模型
2023-03-27 13:39:24趙錦元
計算機研究與發展 2023年3期
關鍵詞:模型
羅 可 曾 鵬 熊 兵 趙錦元
1(長沙理工大學計算機與通信工程學院 長沙 410114)
2(長沙師范學院信息科學與工程學院 長沙 410199)
軟件定義網絡(software-defined networking,SDN)作為一種新興網絡架構,將網絡控制功能從數據交換設備中解耦出來,形成邏輯上集中的控制平面.SDN 控制平面負責構建并維護全局網絡視圖,根據網絡拓撲結構制定流規則,并通過以OpenFlow 為代表的南向接口協議下發到數據交換設備中,從而實現靈活高效的數據傳輸.基于OpenFlow 的SDN 技術有力地打破了傳統網絡的封閉和僵化問題,大大提升了網絡的靈活性、可管控性和可編程能力,被普遍認為是未來網絡最有發展前景的方向之一[1-2].經過十來年的不斷發展與演進,SDN 技術已廣泛應用于各種網絡場景,尤其是數據中心網絡.軟件定義數據中心網絡(software-defined data center network,SDDCN)顯著簡化了網絡功能管理,降低了部署成本,提高了數據傳輸效率,優化了網絡應用性能,為數據中心的優化部署提供了新的技術方案[3-4].
數據中心作為承載海量數據處理的重要基礎設施,廣泛應用于在線購物、網絡電視、短視頻分享等數據密集型產業,目前已進入井噴式的高速建設和發展時期[5].然而,在數據中心規模飛速擴張的同時,能耗問題已成為制約其可持續發展的瓶頸.在數據中心能耗中,網絡設備產生的能耗占比可達50%以上[6],主要由提供高速數據傳輸服務的交換機產生.在SD-DCN 網絡中,OpenFlow 交換機通常采用三態內容可尋址存儲器(ternary content addressable memory,TCAM)存儲流表以支持快速通配查找,其查找能耗高(15~30 W/Mbit)[7-8],約為 靜態存儲器的50 倍[9].同時,SD-DCN 網絡采用等價多路徑路由機制,將產生不少額外的流規則并存儲到TCAM 中,導致能耗問題更加凸顯.因此,如何設置OpenFlow 交換機的TCAM容量,以平衡分組轉發時延和TCAM 查找能耗,是SD-DCN 實際部署需要解決的一個關鍵問題.
目前已有不少研究工作關注OpenFlow 交換機的TCAM 能耗問題.為降低TCAM 查找能耗,部分研究人員采用內容可尋址存儲器(CAM)緩存流表中的活躍流[10-11],進而直接轉發大多數分組,以大幅度減少TCAM 流表查找操作.然而,CAM 同樣采用并行查找方式,查找能耗仍高.也有研究者利用過濾器預測流表查找失敗情形[9],減少不必要的TCAM 查找操作,但只能過濾每條流的首個分組,節能效果極為有限.還有研究人員關注OpenFlow 交換機的TCAM 流表優化模型[12-13],但卻主要關注流超時設置、流規則放置等問題,缺乏對其最優容量的考量.此外,許多工作關注OpenFlow 交換機的分組轉發時延,利用排隊論構建OpenFlow 分組轉發性能模型[14-15],但卻同樣忽略了TCAM 容量對分組轉發時延的影響.
針對上述問題,本文面向SD-DCN 網絡場景,擬提出一種OpenFlow 分組轉發能效聯合優化模型,以求解TCAM 最優容量.為此,本文首先描述了一個典型的SD-DCN 網絡部署場景,分析其分組轉發過程和排隊特性,構建OpenFlow 分組轉發時延模型.然后,根據數據中心網絡中的流分布特性,建立TCAM 命中率模型,進而求解OpenFlow 分組轉發時延與TCAM容量的關系式.進一步,結合TCAM 查找能耗,建立OpenFlow 分組轉發能效聯合優化模型,并設計對應的優化算法求解TCAM 最優容量.最后,通過模擬實驗評估本文所提OpenFlow 分組轉發時延模型,并利用優化算法求解不同參數配置下的TCAM 最優容量.
本文的主要貢獻有4 個方面:
1)針對SD-DCN 網絡典型部署場景,在分析其分組到達和處理過程的基礎上,為OpenFlow 交換機構建了多優先級M/G/1 排隊模型,進而建立了一種更準確的OpenFlow 分組轉發時延模型;
2)基于SD-DCN 網絡中的流量分布特性,為OpenFlow 交換機建立了TCAM 命中率模型,以求解OpenFlow 分組轉發時延與TCAM 容量的關系式;
3)以分組轉發時延和能耗為優化目標,建立OpenFlow 分組轉發能效聯合優化模型;
4)證明了優化目標函數的凸性質,進而設計了優化算法求解TCAM 最優容量,為SD-DCN 實際部署提供有效指導.
1 相關工作
針對OpenFlow 交換機的TCAM 能耗問題,部分研究人員設計了TCAM 流表節能查找方案.Congdon等人[10]根據網絡流量局部性,為交換機的每個端口設置CAM 緩存,存儲包簽名與流關鍵字之間的映射關系,以預測包分類結果,使大部分分組繞過TCAM查找過程.然而,CAM 存儲器同樣采用并行查找方式,查找能耗仍高.針對OpenFlow 多流表的流水線查找模式,Wang 等人[11]利用馬爾可夫模型選取每個流表中的活躍表項,并集中存放到流水線前的Pop 表中,使大部分分組查找命中Pop 表,以避免復雜的多流表查找過程.Kao 等人[9]提出了基于布魯姆過濾器的流表查找方案TSA-BF,通過優化設計布魯姆過濾器以預測流表查找失敗情形,使新流分組繞過TCAM失敗查找操作.但該方案只能過濾每條流的首個分組,節能效果極為有限.
同時,許多研究工作利用排隊論建立OpenFlow分組轉發時延模型.針對OpenFlow 交換機的分組處理過程和SDN 控制器的Packet-in 消息處理過程,Xiong等人[14]將其分別建模為MX/M/1 和M/G/1 排隊模型,Abbou 等人[15]則分別建模成M/H2/1 排隊模型和M/M/1排隊模型,Chilwan 和Jiang[16]分別建模成M/M/1/∞和M/M/1/K 排隊模型,進而推導OpenFlow 平均分組轉發時延.針對多控制器部署場景,Zhao 等人[17]為SDN控制器集群和OpenFlow 交換機分別建立M/M/n 和M/G/1 排隊模型,分析平均分組轉發時延,并結合SDN控制器集群的部署成本,求解最優控制器數量.然而,文獻[14-17]所述模型未考慮不同類型網絡分組的優先級差異.對此,Rahouti 等人[18]將SDN 網絡建模成帶反饋機制的雙隊列排隊系統,將分組劃分成多個優先級隊列,以提供差異化的QoS 服務.Li 等人[19]為OpenFlow 虛擬交換機的分組轉發過程建立排隊系統,以分析丟包率、流表查找失敗概率、分組轉發時延等關鍵性能指標,進而利用多線程處理、優先制隊列設置、分組調度策略和內部緩存區設置等多種方法優化分組轉發性能.然而,文獻[18-19]所述模型均未考慮TCAM 容量對OpenFlow 分組轉發時延的影響.
進一步,已有部分研究工作關注OpenFlow 交換機的TCAM 流表優化模型.Metter 等人[20-21]建立基于M/M/∞排隊系統的流表解析模型,分析不同網絡流量特性下流超時時長對Packet-in 發送消息速率和流表占用率的影響.進一步,AlGhadhban 等人[12]為流安裝過程建立基于類生滅過程的解析模型,分析流表匹配概率的影響因素,進而推導不同流超時時長下的流表容量.Zhang 等人[13]采用M/G/c/c 排隊系統分析流超時時長對流規則的截斷時間、冗余時間和安裝失敗率的影響,進而提出自適應流超時算法,以提高TCAM 流表資源利用率.然而,文獻[12-13,20-21]所述模型未考慮TCAM 容量優化設置問題.對此,Shen等人[22]將流表項生命周期劃分為Packet-in 消息發送、控制器處理和流表項超時3 個階段,并分別建立M/M/1,M/M/1 和M/G/c/c 排隊模型,進而提出流表空間估計模型,求解流安裝失敗概率約束下的TCAM最小容量.然而,該工作僅關注TCAM 容量對流安裝成功率的影響,卻沒有考慮流表命中率和分組轉發時延等關鍵性能指標.本文則考慮TCAM 容量對分組轉發時延和能耗的影響,建立OpenFlow 分組轉發能效聯合優化模型,求解TCAM 最優容量,為SDDCN 實際部署提供參考依據.
2 面向SD-DCN 的OpenFlow 分組轉發時延模型
本節在描述SD-DCN 網絡典型部署場景的基礎上,為OpenFlow 交換機的分組處理過程構建多優先級M/G/1 排隊模型,進而建立OpenFlow 分組轉發時延模型.
2.1 SD-DCN
隨著在線購物、網絡電視、視頻分享、搜索引擎等數據密集型應用的日益盛行,數據中心作為承載海量數據處理的重要基礎設施,其規模不斷擴大,網絡通信量正快速增長[23].傳統數據中心網絡因擴展性差、缺乏靈活的管理,無法滿足數據處理業務中日益增長的網絡需求.基于OpenFlow 的SDN 技術將控制邏輯與數據轉發相解耦,進而對網絡設備進行邏輯上集中的管理和控制,并為上層應用提供統一的編程接口,大大提升了網絡的靈活性、開放性和可管控能力,為構建高性能數據中心網絡提供了新的解決思路.SD-DCN 具備動態路由控制、服務質量管理、安全智能連接等技術優勢,降低了數據中心網絡的部署成本,有助于構建更加靈活高效的數據中心,已成為一種新的發展趨勢[24].
圖1 描述了一種典型的SD-DCN 網絡架構,分為基礎設施平面、數據平面、控制平面和應用平面.基礎設施平面包含眾多服務器,提供強大的存儲和計算能力.數據平面大多采用fat-tree 拓撲結構組網[25-26],交換機自下而上分為邊緣交換機、匯聚交換機和核心交換機,為眾多服務器提供高性能的網絡互聯和數據傳輸服務.在數據平面中,每個交換機根據控制平面下發的流規則,快速轉發網絡分組.控制平面根據上層應用需求,基于全局網絡視圖制定流規則,并通過以OpenFlow 為代表的南向接口協議下發到各個交換機中,指導分組轉發行為.應用平面基于控制平面提供的北向接口,實現服務編排、安全控制、QoS管理、資源調度等功能.

Fig.1 Network architecture of SD-DCN圖1 SD-DCN 網絡架構
在圖1 所示的SD-DCN 網絡場景中,OpenFlow交換機根據SDN 控制器制定的流規則轉發分組.對于每個到達的分組,交換機從分組首部提取匹配字段,進而查找流表.若查找成功,則依據流表項中給定的動作集轉發分組.否則,交換機判定該分組屬于新流,將其首部信息或整個分組封裝成流安裝請求發送到控制器.控制器根據全局網絡視圖生成流規則,并下發到流傳輸路徑上的各個交換機中.交換機將流規則安裝至流表,并據此轉發該流后續到達的分組.
2.2 OpenFlow 交換機排隊模型
在SD-DCN 數據平面中,來自服務器的大量分組匯聚到OpenFlow 交換機,形成隊列等待處理.OpenFlow交換機的分組排隊和處理過程如圖2 所示.對于到達的每個分組,交換機首先將其緩存到入端口隊列,然后逐個解析分組首部信息,提取關鍵字段,以計算流標識符.再根據流標識符查找OpenFlow 流表,以定位對應的流表項.若查找成功,交換機在ACL 應用、計數器更新等一系列相互獨立的操作后,將分組發送到出端口等待轉發;若查找失敗,交換機發送Packetin 消息給控制器,待收到相應的Flow-mod 消息后,將其中的流規則安裝到TCAM 流表,并據此轉發該流后續到達的分組.控制器下發的Flow-mod 消息同樣以分組的形式到達交換機,但優先級高于數據分組,以保證分組轉發行為的一致性和高效性.
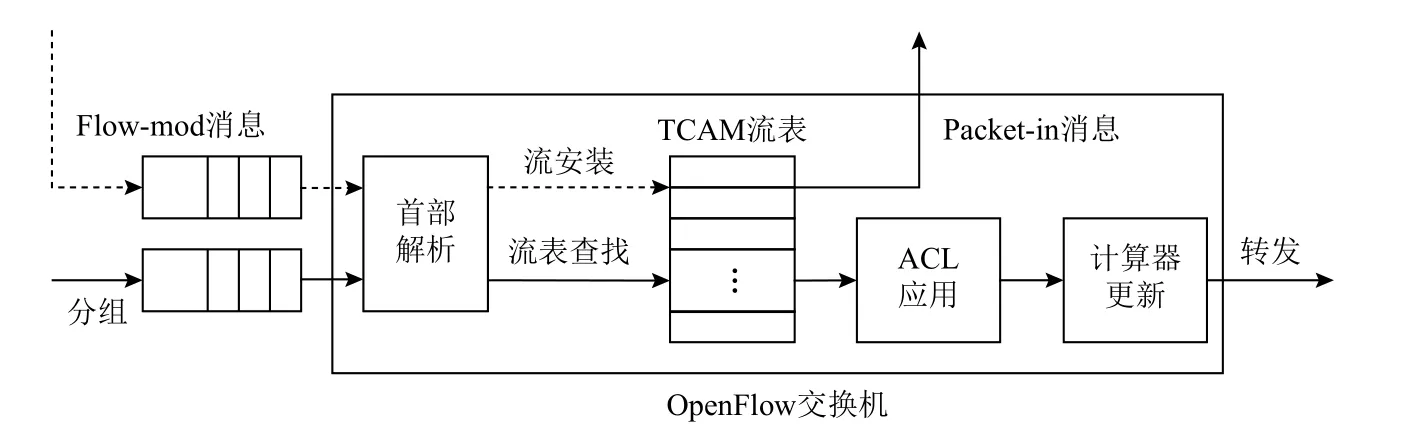
Fig.2 The queueing and processing of packet in the OpenFlow switch圖2 OpenFlow 交換機的分組排隊和處理過程
網絡測量結果表明:在數據中心等大規模網絡場景下,流量匯聚程度高,并發流數量龐大,趨于相互獨立[27-28].因此,OpenFlow 交換機的分組到達過程和流到達過程均可視為泊松過程[17,22].在Open-Flow 分組轉發過程中,所有新流的首個分組在Open-Flow 交換機中的處理步驟相同,且處理過程相互獨立.根據Burke 定理[29],交換機發送的Packet-in 消息流仍為泊松流.假設每臺交換機發送的Packet-in 消息流相互獨立,根據泊松流的可加性,匯聚到控制器的Packet-in 消息流可疊加為泊松流.控制器為每個Packet-in 消息獨立生成流規則后,以Flow-mod 消息的形式下發至流路徑上的各個交換機.因此,Open-Flow 交換機的Flow-mod 消息到達過程同樣為泊松過程.假定控制器收到交換機Sk發送的Packet-in 消息后,生成流規則并下發Flow-mod 消息給交換機Si的概率為δik,則有δii=1.若交換機Sk的Packet-in 消息發送速率為 λ(in),控制器共管理K臺交換機,則交換機Si的Flow-mod 消息到達速率如式(1)所示:
OpenFlow 交換機的分組處理過程可分解為首部解析、流表查找、計數器更新等相互獨立的步驟,不妨假設其共有M步.假設交換機Si中第j(1≤j≤M)步的處理時間Tij服從速率為μij的負指數分布,則其均值E(Tij)=1/μij,方差D(Tij)=1/.由于每個步驟相互獨立,因此交換機Si的分組處理時間Ti服從一般分布,其均值E(Ti)如式(2)所示:
因此,交換機Si的平均分組處理速率和分組處理時間方差分別如式(3)(4)所示:
基于以上排隊分析,本文將OpenFlow 交換機的分組處理過程建模為多優先級M/G/1 排隊模型:1)交換機Si的Flow-mod 消息和分組到達過程為泊松過程,到達速率分別為;2)OpenFlow 交換機的入端口有Flow-mod 消息高優先級隊列和分組低優先級隊列,按非搶占式多優先級調度策略依次處理;3)交換機Si的分組處理時間服從一般分布,分組處理速率和分組處理時間方差,分別如式(3)(4)所示.根據排隊論,可計算出Flow-mod 消息和分組在交換機中的平均逗留時間為,分別如式(5)(6)所示:
2.3 OpenFlow 分組轉發時延模型
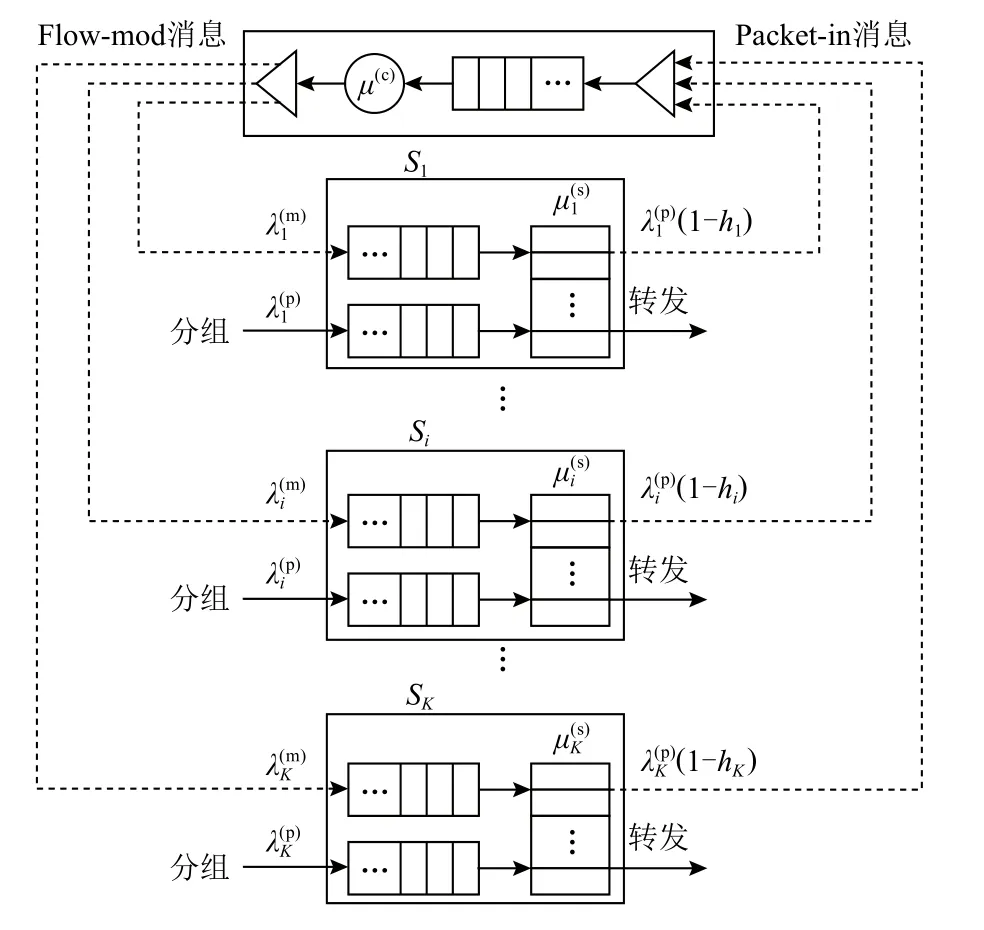
Fig.3 OpenFlow-based packet forwarding queueing system圖3 OpenFlow 分組轉發排隊系統
在上述OpenFlow 分組轉發排隊系統中,到達控制器的Packet-in 消息流相互獨立,其到達過程為泊松過程,且控制器對每個Packet-in 消息的處理過程相互獨立,處理時間可視為服從負指數分布[30-31].因此,可將控制器的Packet-in 消息處理過程建模為M/M/1 排隊模型,進而可知Packet-in 消息在控制器中的平均逗留時間W(c)如式(8)所示:
根據上述OpenFlow 交換機的分組處理排隊模型和控制器的Packet-in 消息處理排隊模型,可推導出交換機Si的平均分組轉發時延.根據OpenFlow 分組轉發過程可知,交換機Si中的分組轉發過程可分為2 種情況:直接轉發和請求控制器安裝流規則的間接轉發.分組直接轉發時延即為分組在交換機中的逗留時間.分組間接轉發時延包含分組在交換機中的逗留時間、Packet-in 消息在控制器中的逗留時間W(c)、Flow-mod 消息在 交換機 中的逗 留時間,以及Packet-in 消息和Flow-mod 消息在交換機到控制器之間的總傳輸時延.因此,交換機Si的平均分組轉發時延可表達如式(9)所示:
將式(5)(6)(8)代入式(9)可得,交換機Si的平均分組轉發時延Di如式(10)所示:
3 面向SD-DCN 的OpenFlow 分組轉發能效聯合優化模型
本節根據SD-DCN 中的網絡流分布特性建立TCAM 命中率模型,進而結 合 2.3 節所述 的OpenFlow 分組轉發時延模型,建立OpenFlow 分組轉發能效聯合優化模型,以求解TCAM 最優容量.
3.1 TCAM 命中率模型
在分組交換網絡中,網絡流量存在明顯的局部性特點,大部分分組集中分布在少數流中[32].以數據中心網絡為例,眾多測量研究結果表明:20%的top流占據分組總數的80%以上[33].根據網絡流量局部性,眾多研究利用Zipf 分布刻畫網絡流中的分組數量分布特性[34-37].假設網絡中有N條流,則可按照流大小即流的分組數量依次遞減排序為(f1,f2,…,fN).根據Zipf 分布可知,流fr的分組數量Q(r)與其大小排名r(r=1,2,…,N)存在式(11)所示的冪律關系.
其中C和α均為大于0 的常數,α表示分組在網絡流中分布的傾斜程度.假設OpenFlow 交換機的TCAM容量為n條流表項,且存儲所有網絡流中排名靠前的n條流,則TCAM 命中率h(n)如式(12)所示:
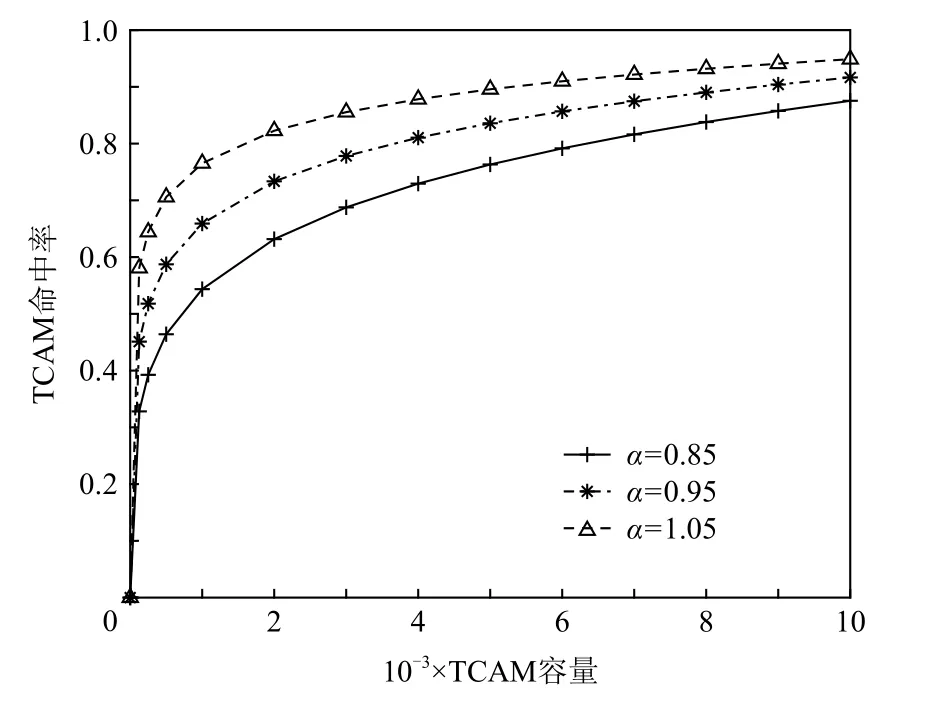
Fig.4 Estimated relationship between TCAM hit rate and TCAM capacity圖4 TCAM 命中率與TCAM 容量的估計關系
從圖4 中可看出:α越大,相同容量下的TCAM命中率越高,即相同數量top 流所占據的分組比例越高,網絡流量局部性越明顯.當TCAM 容量為4 000條流表項,即可存儲前20%的流時,若α=0.95,則TCAM 命中率可達81.05%,與數據中心網絡中的流量測量結果基本一致.
3.2 OpenFlow 分組轉發能效聯合優化模型
在OpenFlow 分組轉發過程中,每個到達交換機的分組都需要查找TCAM 流表,進而實現分組轉發處理.根據2.3 節所述的OpenFlow 分組轉發時延模型和3.1 節所述的TCAM 命中率模型可知:TCAM 容量越大,存儲的流規則越多,TCAM 命中率越高,即TCAM 流表查找成功的分組占比越大,平均分組轉發時延越小.因此,平均分組轉發時延與TCAM 容量呈負相關關系.由于TCAM 采用并行匹配方式查找整個流表,查找能耗基本上與其容量成正比,假定分組轉發過程中的其他能耗固定,則分組轉發能耗可視為與TCAM 容量呈正線性相關關系.因此,可將TCAM 容量作為決策變量,以分組轉發時延和能耗為優化目標,建立能效聯合優化模型求解TCAM 最優容量.
對于TCAM 容量為n的OpenFlow 交換機,根據式(12)所示的TCAM 命中率,定義TCAM 流表命中失敗概率q(n)=1-h(n).進而結合式(10),可求出交換機的平均分組轉發時延D(n):
同時,根據式(12)給出的TCAM 命中率,可建立OpenFlow 交換機的分組轉發能耗模型.假定每條TCAM 流表項的平均查找能耗為e1,由于TCAM 容量為n條流表項,且采用并行查找方式,因此每個分組的TCAM 查找能耗為ne1.若分組轉發過程中的其他處理能耗為e0,則交換機的平均分組轉發能耗E(n)如式(15)所示:
以式(13)和式(15)分別給出的平均分組轉發時延和能耗為優化目標,可建立式(16)所示的Open-Flow 分組轉發能效聯合優化模型,求解TCAM 最優容量.
其中約束條件為
式(16)優化模型包含3 個約束條件:1)平均分組轉發時延D(n)不能超過QoS 規定的最大時延Dmax;2)平均分組轉發能耗E(n)不能超過上限值Emax;3)TCAM 容量n為正整數.
3.3 優化模型求解
OpenFlow 分組轉發能效聯合優化模型是一個不等式約束下的多目標優化模型.在該模型中,以TCAM 容量n為決策變量,平均分組轉發時延D(n)可通過定理1 證明具有單調遞減性,平均分組轉發能耗E(n)顯然單調遞增.而約束條件限定了D(n)和E(n)的最大值,即決定了TCAM 容量的最小值nmin和最大值nmax,進而可求得D(n)和E(n)的最小值分別為Dmin=D(nmax)和Emin=E(nmin).
定理1.對于式(13)中的平均分組轉發時延D(n),若其參 數均為 正,且ρ(m)+ρ(p)=ρ(s)<1,ρ(c)=λ(c)/μ(c)<1,則D(n)具有單調遞減性,即D′(n)<0.
證明.對于式(13),不妨假設n為連續自變量,利用復合函數求導法,可得D(n)的一階導數:
進而可知1-a1q(n)>0.由于ρ(m)+ρ(p)=ρ(s)<1,則有1-a1q(n)-ρ(p)=1-ρ(s)>0.帶入式(20)(21)中可得
加之各項參數為正,因此式(19)等號右邊的每項均為正,進而可得D′(q(n))>0.對q(n)求導有
將上述結論帶入式(18)可知:D′(n)<0.
證畢.
此時,可將優化目標D(n)和E(n)分別進行歸一化處理,進而利用線性加權法將式(16)中的多目標優化函數轉換成單目標優化函數f(n):
其中ω為OpenFlow 平均分組轉發時延所占的權重.該函數具有凸性質,如定理2 所證.
定理2.對于式(27)所示的目標函數,若其參數均為正,且ρ(s)<1,ρ(c)<1,則該函數具有凸性質,即f′′(n)>0.
證明.對f(n)二階求導有
其中g(q(n))和g′(q(n))分別如式(20)和式(21)所示.根據定理1 的證明過程可知
根據定理1 的證明 過程可 知1-a1q(n)>0,μ(c)-a0q(n)>0,g(q(n))>0,g'(q(n))<0.加之各項參數均為正,則式(29)等號右邊的每項均為正,進而可知D′′(q(n))>0.同時,根據定理1 的證明過程可知D′(q(n))>0.代入式(28)可得f′′(n)>0.
證畢.
由于目標函數f(n)具有凸性質,因此可利用二分法在整數范圍[nmin,nmax]內搜索TCAM 最優容量nopt,使f(n)取最小值.算法1 給出了OpenFlow 分組轉發能效聯合優化模型的求解算法.
算法1.OpenFlow 分組轉發能效聯合優化算法.
輸入:1)網絡拓撲信息G(V,E);2)OpenFlow 交換機的分組到達速率λ(p),每個步驟j的處理速率,控制器的Packet-in 處理速率μ(c);3)平均每條TCAM 流表項的查找能耗e1,分組轉發過程中其他處理步驟的能耗之和e0,分組轉發能耗上限Emax;4)QoS 允許的分組轉發時延上限Dmax.
輸出:交換機的TCAM 最優容量nopt.
算法1 分為3 個步驟:1)計算中間參數,包括交換機處理速率μ(s)(行①),交換機Sk發送的Packet-in消息觸發控制器下發Flow-mod 消息到交換機Si的概率δik(行②);2)確定TCAM 容量n的整數范圍[nmin,nmax](行⑥⑦);3)二分查找TCAM 容量的最優值nopt(行⑧~?).
4 實 驗
本節首先通過模擬實驗評估本文所提OpenFlow分組轉發時延模型的準確性,然后采用數值分析方法分析不同因素對分組轉發時延的影響,進而求解不同參數下的TCAM 最優容量.
4.1 時延模型對比
實驗采用Mininet 平臺模擬典型的Fat-tree 網絡拓撲結構[22],SDN 控制器共管理10 臺OpenFlow 交換機,包含2 臺核心交換機、4 臺匯聚交換機、4 臺邊緣交換機.其中,SDN 控制器采用OpenDaylight,Open-Flow 交換機采用Open vSwitch v2.13.在模擬實驗中,利用OFsuite 性能測試工具測得控制器的Packet-in 消息處理速率為21 kmsg/s,每臺交換機的分組處理速率為20 kpkt/s.同時,將交換機的流表容量設置為8 000條流表項,流超時間隔為10 s.實驗利用Iperf 工具為每臺交換機模擬產生不同速率的網絡流量,其中新流分組占比約為10%,進而測得平均分組轉發時延如圖5 所示.同時,將上述參數代入本文所提的Open-Flow 分組轉發時延模型和現有模型,其中控制器均采用M/M/1 模型,OpenFlow 交換機分別采用多優先級M/G/1 模型、M/G/1 模型[17]、Mk/M/1 模型[14],進而計算出平均分組轉發時延的估計值如圖5 所示.
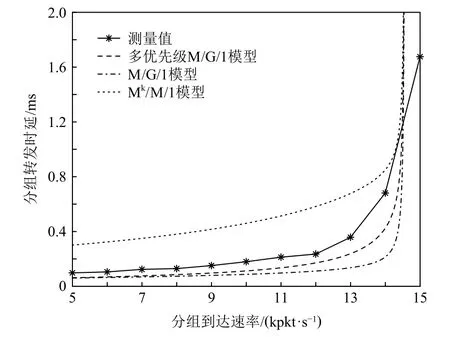
Fig.5 Comparison of delay models with different packet arrival rates圖5 不同分組到達速率下的時延模型對比
從圖5 中可以看出:與現有模型相比,本文所提基于多優先級M/G/1 的OpenFlow 分組轉發時延模型具有更接近于測量值的估計時延.OpenFlow 交換機的分組處理過程包含多個相互獨立的步驟,而Mk/M/1 模型將分組處理時間簡單地看作服從泊松分布,故其估計時延與測量值相差較大.M/G/1 模型可較為準確地估計OpenFlow 交換機的分組處理時間,但在分組到達速率較大時,其估計時延明顯較小.這是因為該模型只考慮到達OpenFlow 交換機的數據分組,而忽略了控制器下發的消息分組.多優先級M/G/1 模型則著重考慮了Flow-mod 消息的分組處理時延,因而其分組轉發時延估計值更接近于測量值.
實驗采用4.1 節所述參數,將OpenFlow 交換機的分組到達速率設為10 kpkt/s,并不斷調整OpenFlow 交換機的流表容量值,可測得平均分組轉發時延如圖6所示.同時,將上述參數代入本文所提的OpenFlow 分組轉發時延模型和現有模型,計算出平均分組轉發時延的估計值如圖6 所示.
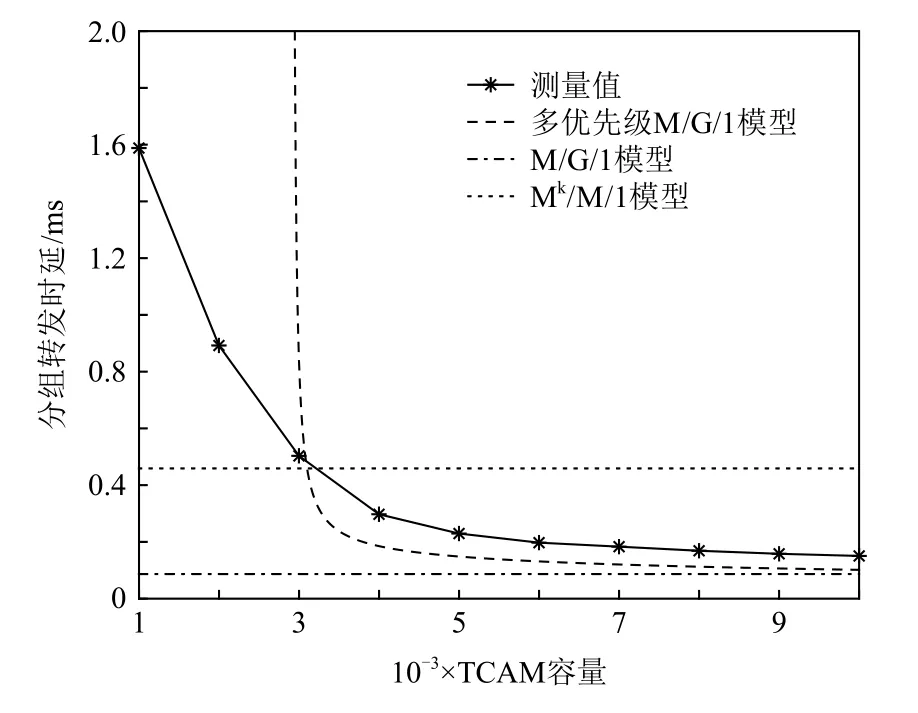
Fig.6 Comparison of delay models with different flow table capacities圖6 不同流表容量下的時延模型對比
從圖6 中可以看出:本文所提OpenFlow 分組轉發時延模型的估計時延比現有模型更接近于測量時延.現有模型由于忽略了流表容量對分組轉發時延的影響,其分組轉發時延始終保持不變,估計不準確.與此形成對照的是,隨著流表容量的不斷增大,本文所提模型的分組轉發時延估計值逐步降低,并趨于穩定,與測量值接近.這是因為交換機的流表命中率隨流表容量的增大而升高,進而導致發送給控制器的Packet-in 消息逐漸減少,其估計時延逐步接近于M/G/1 模型.特別地,當交換機的流表容量小于3 000條流表項時,模擬實驗中的控制器負載過大,將會丟棄部分Packet-in 消息,導致分組轉發時延測量值急劇升高.此時,對于OpenFlow 分組轉發時延模型,由于流表命中率過低,控制器的Packet-in 消息到達速率高于其處理速率,導致模型失效.
4.2 分組轉發時延
進一步,實驗采用數值分析方法研究平均分組轉發時延的主要影響因素.實驗參數設定為:假定分組在網絡流中的分布傾斜程度α=0.95,每臺OpenFlow 交換機的分組到達速率λ(p)=10 kpkt/s,分組處理過程分為10 個步驟,且每個步驟的處理速率相同,分組處理速率μ(s)=20 kpkt/s.同時,SDN 控制器的Packet-in 消息處理速率μ(c)=21 kmsg/s,每臺控制器管理10 臺OpenFlow 交換機.
實驗設置不同的TCAM 容量,可得到平均分組轉發時延與分組到達速率之間的關系如圖7 所示.從圖7 可看出:當TCAM 容量一定時,分組到達速率越高,交換機和控制器的負載越大,平均分組轉發時延越高.同時,當分組到達速率一定時,交換機的TCAM容量越大,流表命中率越高,Packet-in 消息的發送速率越低,其在控制器中的逗留時間越短,平均分組轉發時延越低.此外,TCAM 容量越大,允許的分組到達速率越高.具體而言,當交換機的TCAM 容量n分別為4 000,6 000,8 000,10 000 條流表項時,平均分組轉發時延在分組到達速率λ(p)分別超過10 kpkt/s,11.6 kpkt/s,12.8 kpkt/s,13.8 kpkt/s 時急劇上升,且允許的最大分組到達速率分別為10.7 kpkt/s,12.6 kpkt/s,14.3 kpkt/s,15.3 kpkt/s.
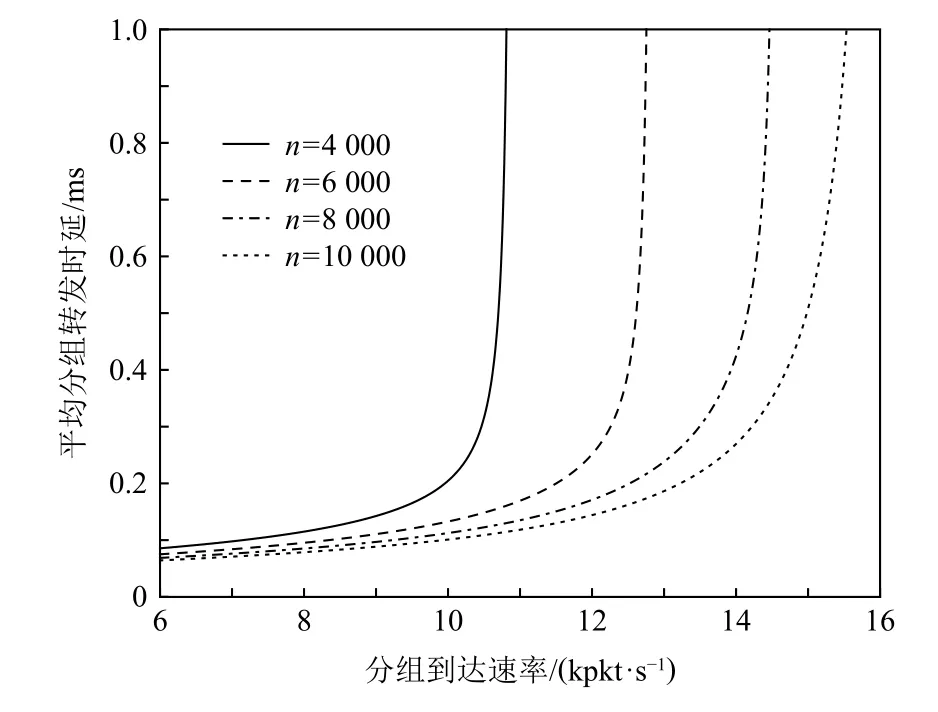
Fig.7 Relationship between average packet forwarding delay and packet arrival rate圖7 平均分組轉發時延與分組到達速率的關系
實驗設置不同的TCAM 容量,可得到平均分組轉發時延與分組處理速率之間的關系,如圖8 所示.從圖8 可看出:當TCAM 容量一定時,分組處理速率越高,分組在交換機中的逗留時間越短,平均分組轉發時延越低;同時,當分組處理速率一定時,交換機的TCAM 容量越大,流表命中率越高,發送給控制器的Packet-in 消息越少,相應收到的Flow-mod 消息也越少,平均分組轉發時延越低.此外,TCAM 容量越大,交換機的分組處理速率需求越低.具體而言,當交換機的TCAM 容量n分別為4 000,6 000,8 000,10 000條流表項時,平均分組轉發時延在分組處理速率μ(s)分別小于16 kpkt/s,14.5 kpkt/s,13.7 kpkt/s,13.2 kpkt/s時急劇上升,且交換機允許的最小分組處理速率分別為14.3 kpkt/s,13.4 kpkt/s,12.7 kpkt/s,12.1 kpkt/s.
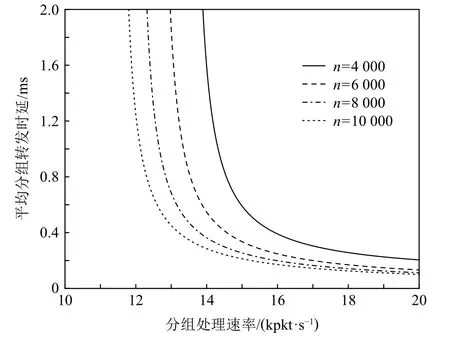
Fig.8 Relationship between average packet forwarding delay and packet processing rate圖8 平均分組轉發時延與分組處理速率的關系
實驗設置不同的TCAM 容量,可得到平均分組轉發時延與Packet-in 消息處理速率之間的關系如圖9 所示.從圖9 中可看出:當TCAM 容量一定時,Packet-in 消息處理速率越高,其在控制器中的逗留時間越短,平均分組轉發時延越低.同時,當Packet-in消息處理速率一定時,交換機的TCAM 容量越大,流表容量越高,Packet-in 消息的發送速率越小,其在控制器中的逗留時間越短,平均分組轉發時延越低.此外,交換機的TCAM 容量越大,控制器允許的Packet-in消息處理速率越低.具體而言,當交換機的TCAM 容量n分別為4 000,6 000,8 000,10 000 條流表項時,平均分組轉發時延在Packet-in 消息處理速率μ(c)分別低于18 kmsg/s,15 kmsg/s,12 kmsg/s,8 kmsg/s 時急劇上升,且控制器允許的最低Packet-in 消息處理速率分別為18.9 kmsg/s,14.1 kmsg/s,10.6 kmsg/s,7.9 kmsg/s.
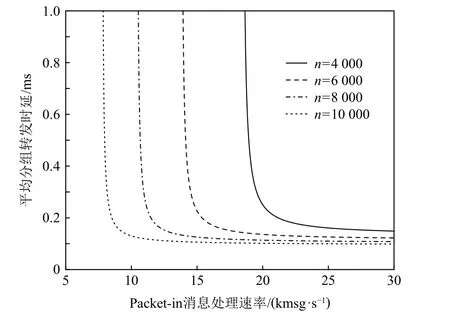
Fig.9 Relationship between average packet forwarding delay and Packet-in message processing rate圖9 平均分組轉發時延與Packet-in 消息處理速率的關系
4.3 TCAM 最優容量
對于OpenFlow 分組轉發能效聯合優化模型,不妨假設每條TCAM 流表項的平均查找能耗e1為1 個單位,其他處理步驟的能耗e0為3 000 個單位,分組轉發能耗上限為Emax為15 000 個單位,即最大TCAM容量為12 000 條流表項.同時,QoS 要求的最大分組轉發時延Dmax=1.5 ms.基于上述參數配置,將單目標優化函數f(n)中的權重ω設置不同值,進而實現OpenFlow 分組轉發能效聯合優化算法,求解不同分組到達速率下的TCAM 最優容量如圖10 所示.
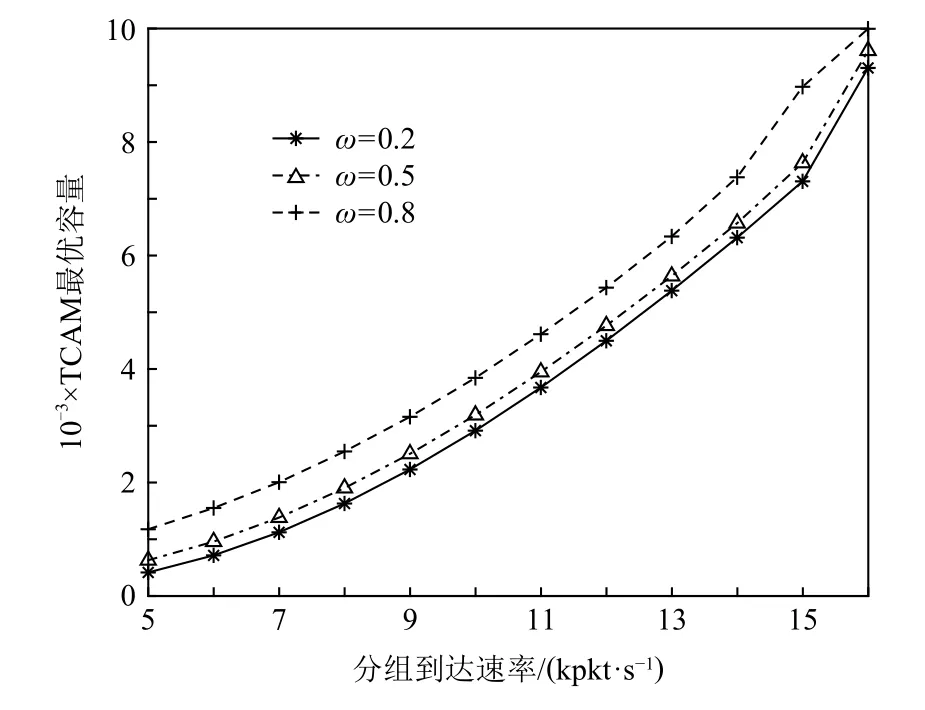
Fig.10 Optimal TCAM capacity with different packet arrival rates圖10 不同分組到達速率下的TCAM 最優容量
從圖10 中可看出:當每個交換機的分組到達速率增加時,TCAM 最優容量將隨之增大,以提高TCAM命中率,保證Packet-in 消息發送速率不會過高,從而防止控制器過載,Packet-in 消息逗留時間過大.具體而言,當交換機的分組到達速率λ(p)分別為5 kpkt/s,10 kpkt/s,15 kpkt/s,且權重ω=0.8 時,TCAM 最優容量nopt分別為1 400,4 600,10 800 條流表項.當分組到達速率超過16 kpkt/s 時,交換機需要繼續增大TCAM容量,以保證分組轉發時延,但分組轉發能耗將會超出上限,因而無解.此外,當分組到達速率一定時,分組轉發時延的權重越高,TCAM 最優容量越大,以使TCAM 命中率越高,平均分組轉發時延越小.
采用上述同樣的參數配置,并將交換機的分組到達速率λ(p)設為10 kpkt/s,進而求解不同分組處理速率下的TCAM 最優容量,如圖11 所示.從圖11 中可看出:當交換機的分組處理速率升高時,TCAM 最優容量將隨之減小,并趨于穩定.這是因為在保證分組轉發時延的情況下,交換機的分組處理速率越高,需要的TCAM 容量越小.具體而言,當交換機的分組處理速率μ(s)分別為14 kpkt/s,16 kpkt/s,18 kpkt/s,且權重ω=0.8 時,TCAM 最優容 量nopt分別為8 900,5 800,4 900 條流表項.此外,當交換機的分組處理速率低于12 kpkt/s 時,由于逐步接近于分組到達速率,平均分組轉發時延將超出QoS 規定的上限,因而無解.
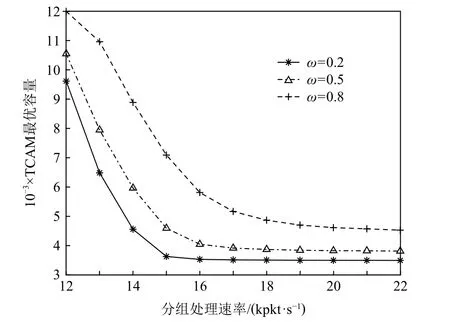
Fig.11 Optimal TCAM capacity with different packet processing rates圖11 不同分組處理速率下的TCAM 最優容量
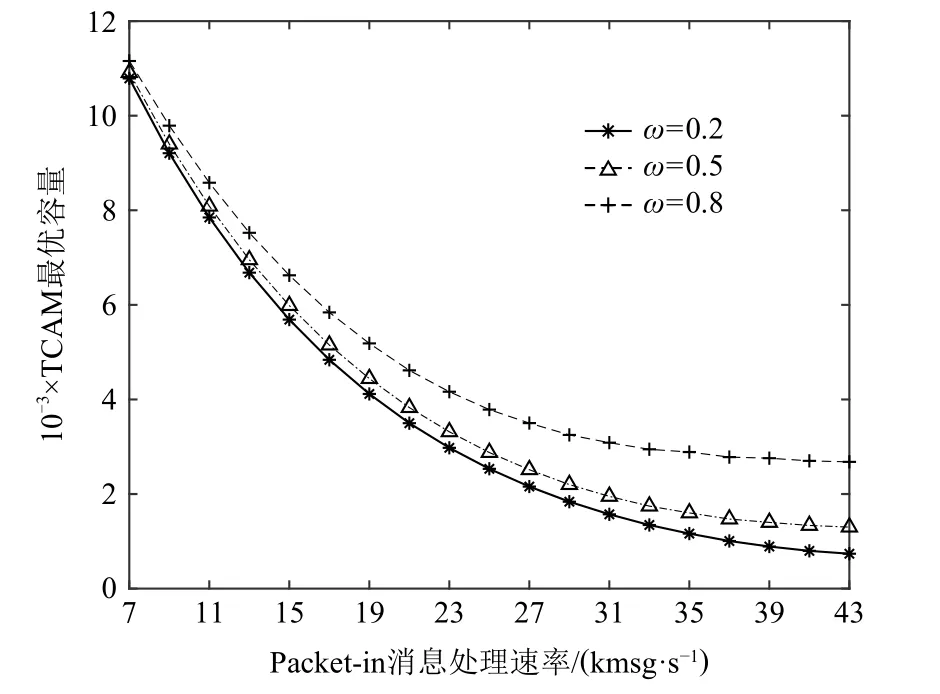
Fig.12 Optimal TCAM capacity with different Packet-in message processing rates圖12 不同Packet-in 消息處理速率下的TCAM 最優容量
采用上述同樣的參數配置,并將交換機的分組處理速率μ(s)設為20 kpkt/s,進而求解不同Packet-in消息處理速率下的TCAM 最優容量,如圖12 所示.從圖12 中可看出:當控制器的Packet-in 消息處理速率升高時,TCAM 最優容量將隨之降低,并趨于穩定.這是因為控制器的Packet-in 消息處理速率越高,其允許的Packet-in 消息到達速率越高,進而交換機所需的TCAM 容量越少.具體而言,當Packet-in 消息處理速率μ(c)分別為15 kmsg/s,25 kmsg/s,35 kmsg/s,且權重ω=0.8 時,TCAM 最優容量nopt分別為6 600,3 800,2 900 條流表項.此外,當Packet-in 消息處理速率小于7 kmsg/s 時,交換機需要繼續增加TCAM 容量,以提高TCAM 命中率,保證平均分組轉發時延,但分組轉發能耗將會超出上限,因而無解.
5 結論
本文針對SD-DCN 網絡場景,利用多優先級M/G/1 排隊模型刻畫OpenFlow 交換機的分組處理過程,進而構建OpenFlow 分組轉發時延模型.進一步,基于網絡流分布特性建立TCAM 命中率模型,求解OpenFlow 分組轉發時延與TCAM 容量的關系式.在此基礎上,結合TCAM 查找能耗,建立OpenFlow 分組轉發能效聯合優化模型,以求解TCAM 最優容量.實驗結果表明:與已有排隊模型相比,本文所提時延模型更能準確估計SD-DCN 網絡場景下的OpenFlow分組轉發性能.同時,數值分析結果表明:交換機的TCAM 容量和控制器的Packet-in 消息處理速率對OpenFlow 分組轉發時延有著關鍵性的影響,而交換機的分組到達速率和分組處理速率影響較弱.最后,通過OpenFlow 分組轉發能效聯合優化算法,求解出不同參數配置下的TCAM 最優容量,為SD-DCN 網絡的實際部署提供參考依據.
作者貢獻聲明:羅可提出研究思路,并設計研究方案,以及修訂論文最終版本;曾鵬完善論文創新點,并完成模型的建立和推導,以及撰寫論文初稿主要部分;熊兵設計了實驗思路,以及審查和修改潤色論文;趙錦元協助創新點推導和論文修改;所有作者都參與了實驗分析和手稿撰寫.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
