大規模結構網格數據的相關性統計建模輕量化方法
2023-03-27 13:39:38汪云海
計算機研究與發展 2023年3期
楊 陽 武 昱 汪云海 曹 軼,3
1(北京應用物理與計算數學研究所 北京 100094)
2(山東大學計算機科學與技術學院 山東青島 266237)
3(中物院高性能數值模擬軟件中心 北京 100088)
大規模數值模擬是科學發現與工程設計不可或缺的關鍵手段,高置信度的數據可視分析對大規模數值模擬至關重要[1].隨著高性能計算機的峰值性能的快速提升,為了精細模擬所研究問題的復雜特征,以盡可能高的計算效率將計算能力集中在問題的最關鍵部分,科學家常采用如圖1 所示的非均勻分解的自適應網格,導致大規模多塊數據的生成.然而,硬件存儲瓶頸導致可視分析應用獲取原始高分辨率數據越來越困難[2],大規模數值模擬應用先保存原始計算結果再進行事后可視分析的可行性不斷降低.因此,數據約減勢在必行.
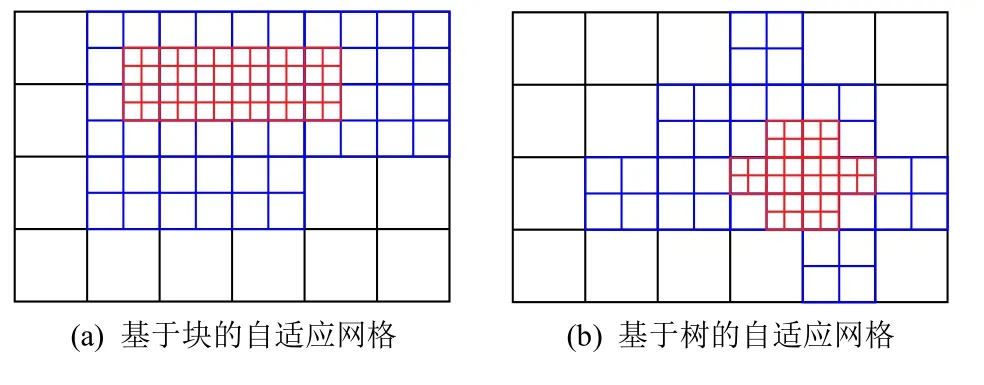
Fig.1 Adaptive mesh refinement圖1 自適應網格
基于統計建模的數據輕量化方法[3-8]是一種主流的數據約減方法,它采用緊湊型的分布數據表達,替代傳統的3 維網格數據表達,可以實現數值模擬數據規模的大幅約減,便于高效的事后可視分析[9-14].常用的分布數據表達有直方圖(histogram)和高斯混合模型(Gaussian mixture model,GMM)[15-17].
然而,基于統計建模的數據輕量化方法的重建精度低,可視化不確定性高.主要原因是此類方法與數值并行區域分解策略產生的多塊拼接網格數據的不適配性.因此,此類方法通常需要首先對原有的多塊拼接網格數據進行合并;然后根據可視化的同質性需求,采用更適合可視分析方法的區域分解策略對合并數據進行重分,保證單塊網格數據具有較小的數值梯度;最后,采用統計分布模型對每個數據塊進行特征建模和可視分析.在大規模數值模擬場景下,這種建模方法會引起性能瓶頸和建模不確定2方面的問題[18].首先,數據合并與數據重分,將引起全局數據通信和高性能計算機節點間的大量數據遷移,導致顯著的性能瓶頸問題.其次,不恰當的區域分解策略或統計分布模型,均會導致數據統計特征的丟失,進而增加可視分析的不確定性.能夠適配數值并行區域分解策略的高精度統計建模與可視分析方法,仍有待開展研究.
為此,本文提出了一種大規模結構網格數據的相關性統計建模輕量化方法,其創新點有2 個方面:
1)提出了一種數據塊間的相關性統計建模方法.在計算各單塊網格數據的數值分布和空間分布后,利用信息熵與互信息表征數據塊間的相關性,指導鄰接數據塊的統計建模.該方法通過耦合數據塊的數值分布信息、空間分布信息和相關性信息,能夠顯著提升重建精度,降低可視化的不確定性.
2)本文方法保持初始數據分塊不變,不需要對原始數據進行全局合并與重分,從而顯著減少不同并行計算節點間的通信開銷,降低計算成本.
實驗結果表明,與現有方法相比,本文方法節省了數據合并與重分的計算成本,在獲得更高重建精度的同時,將數據存儲成本降低了約1 個數量級.
1 相關工作
1.1 網格數據壓縮編碼方法
壓縮編碼是傳統常用的網格數據約減方法,分為無損和有損2 種壓縮策略,但它很難適用于具有浮點數特征的數值模擬數據.例如,采用行程編碼[19-20]、bZIP[21]等無損壓縮算法,很難將數據壓縮比提升到一個數量級.有損壓縮則是相對有效的科學數據壓縮途徑.例如,幾何驅動的靜態有損壓縮方法,它涉及網格頂點位置量化、預測、熵編碼3 個主要處理階段[22].面向不斷增大的數據規模,漸近網格壓縮方法逐漸成為研究熱點,衍生出基于八叉樹的漸近編碼[23]、小波編碼[24]、幾何圖像編碼[25]等相關研究.但是,有損壓縮算法無法在較大數據壓縮比的前提下,同時高精度地保留原始高分辨數據的物理特征.
1.2 特征提取方法
特征提取方法使用特征數據替代原始數據場,從而實現數據輕量化.物理特征的定義形式包括等值面、流線、條紋線、矢量場拓撲、渦管、裂縫、斷層線等.針對3 維數據場,目前通常采用“基于iso-value指定的等值數據范圍”和“基于體繪制傳遞函數指定的不透明度到數值范圍的映射”等方法進行空間特征提取.Tzeng 等人[26]使用標量值、梯度值和空間位置坐標訓練傳遞函數,用于數據特征識別.Kindlmann等人[27]利用曲面曲率對數據樣本進行特征分類.Tenginakai 等人[28]通過鄰域統計信息定義數據等值面特征.Hladuvka 等人[29-30]借助等值面實現數據特征分離.但是,上述特征提取方法均依賴個性化特征定義,其普適性弱.
1.3 基于統計建模的數據輕量化方法
基于統計建模的數據輕量化方法,是目前有望解決大規模數據存儲瓶頸的一種最新數據約減途徑.它采用緊湊的分布數據表達,可以極大降低高分辨數據存儲量,同時還能較好地保持數據蘊含的物理特征.Thompson 等人[15]使用直方圖近似表示網格數據等值面.Wei 等人[13]提出了一種基于直方圖的有效算法來搜索數據局部區域的相似分布.Liu 等人[16]和Dutta 等人[17]則使用GMM 對數據信息進行緊湊表達.然而這類方法的一個關鍵缺點是,其忽略了數據的空間分布信息,并最終導致基于統計建模方法的重建數據精度低,不確定性高.針對這一問題,Wang等人[31]提出了一種基于空間分布的數據輕量化方法,它使用直方圖建模數值信息,GMM 建模空間分布信息,利用貝葉斯準則結合這2 類分布模型,最終顯著提升重建數據精度.然而,受限于大規模數值模擬復雜的并行特征,文獻[13,15-17,31]所述的輕量化方法無法直接適配多塊拼接網格數據.因此,在大規模數值模擬場景下,這些方法勢必會引起性能和建模不確定2 方面的問題.
1.4 相關性建模方法
現有的統計可視分析方法難以適應多塊拼接數值模擬數據,無法在數據塊的鄰域邊界保持重建精度.為此,近幾年出現了相關性建模方法,它引入數據相關性來提升統計分布建模的精度.Dutta 等人[18]提出了一種基于數據固有空間相關性對數據進行聚類劃分的方法,但該方法并不適用于數值并行計算階段產生的多塊拼接網格數據.Wang 等人[32]通過創建先驗知識,捕捉低分辨率與高分辨率數據之間的相關性來提高重建精度,但先驗知識的計算是十分耗時的.Hazarika 等人[33-34]從統計分析的角度出發,對多變量數據的相關性進行統計建模,從而降低重建數據的不確定性.目前,適用于數值并行應用區域分解策略的統計可視分析方法仍未開展研究.
2 基本概念
2.1 信息熵與互信息
在信息論中,信息熵(information entropy)是關于離散隨機事件的出現概率.對于任意的概率分布,均可以定義信息熵以度量單個隨機變量的不確定性.針對科學模擬數據,信息熵還可以作為一個數據復雜程度的度量[35].如果一個數據場越復雜,蘊含異質的物理特征越多,它的信息熵會越大;反之,數據場越簡單,蘊含異質的物理特征越少,則它的信息熵將越小.聯合熵(joint entropy)可用于度量一個聯合分布隨機系統的不確定性,它可以推廣到互信息(mutual information),互信息可用于度量2 個隨機變量之間的依賴關系.
將信息熵應用于數據輕量化問題的關鍵在于如何正確指定隨機變量X,并定義其概率密度函數p(x)=Pr(X=x).在大多數情況下,可以啟發式地定義這些概念函數以滿足應用需求.本文將科學模擬數據集建模為離散隨機變量,其區域內的每個數據點都對應物理場的一個數據值.因此,我們可以使用直方圖對隨機變量X的概率密度函數p(x)進行估計,即使用每個直方圖Bin 區間的歸一化頻率作為相應的概率p(x).
本文使用信息熵、聯合熵、互信息概念對數據相關性進行了建模.為便于理解,圖2 為多塊拼接結構網格數據中3 個相鄰數據塊X,Y,Z的信息熵與互信息示意圖,其中,數據點的不同圖案填充代表不同的物理 場變量 值.H(X),H(Y),H(Z)為數據 塊直方 圖的信息 熵;H(X,Y),H(X,Z),H(Y,Z)為直方 圖之間 的聯合熵;I(X,Y),I(X,Z),I(Y,Z)為直方 圖之間 的互信息.由于聯合熵與互信息具有對稱性,為簡化示意圖,圖2 在右上方加粗黑色框內展示聯合熵與信息熵之間的關系,左下方加粗黑色框內展示互信息與信息熵之間的關系.
2.2 空間高斯混合模型
為了提升大規模數值模擬數據的重建精度,本文在數據建模過程還同時考慮空間位置信息,這構成了空間高斯混合模型(spatial GMM,SGMM)[31,36].SGMM可用于捕獲相似數據值的空間分布特征.與將數值映射到概率的塊高斯混合模型(block GMM)[14,16]不同,SGMM 將空間位置映射到概率.給定一個3 維空間位置p,則SGMM 定義為其中K是高斯函數分量的個數,ωk,μk,Σk分 別為第k個高斯函數分量的混合權重、均值向量和協方差矩陣.SGMM 的求解相當于一個包含缺失數據的參數估計問題,采用最大期望算法(expectation maximization algorithm)[36]可實現對其求解.
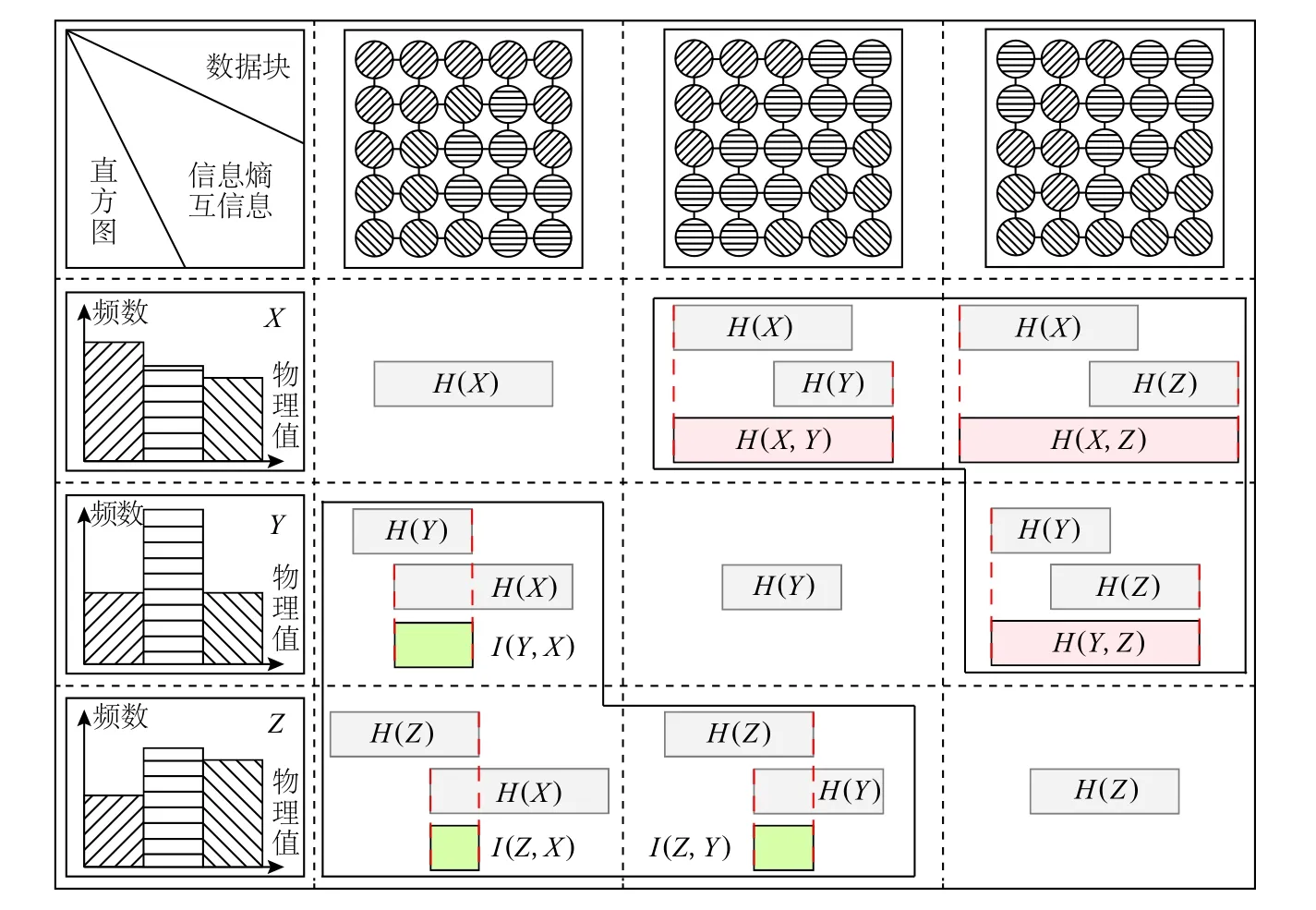
Fig.2 Information entropy and mutual information圖2 信息熵與互信息
為了提高SGMM 的重建精度,目前的解決方案是根據可視化的需求對原始數據進行合并和重新分塊.大規模多塊數據的合并與重分會涉及并行計算節點之間的全局數據通信,導致顯著的性能瓶頸問題.因此,隨著并行通信模擬規模的逐漸擴大,減少全局通信對提高并行性能至關重要.本文方法利用相關性統計建模極大地降低了全局數據通信量.
3 相關性統計建模輕量化方法
為了適配數值并行應用區域分解策略,提升針對多塊拼接結構網格數據的重建精度,實現大規模數值模擬數據的高效、高置信度可視分析,本文提出了一個大規模結構網格數據的相關性統計建模輕量化方法,它包括數據塊內的統計分布建模、面向多塊拼接網格數據的相關性統計建模、基于統計模型的數據重建與可視分析3 個階段過程.特別地,本文的統計分布建模均采用了耦合了3 維空間位置信息的SGMM,SGMM 方法的總流程如圖3 所示.
3.1 總體流程
給定一個多塊均勻拼接網格數據,首先基于SGMM 進行逐塊數據建模.每個數據塊的統計模型,包含數值分布和空間分布2 類信息.本文針對數值分布,使用直方圖進行數據表征;而針對落在直方圖中同一個Bin 區間內的數據點,如它們具有相同或相似的數值,則要同時耦合該數值區間所對應網格數據點的空間分布,采用SGMM 進行數據表征.
其次,是逐塊計算塊內統計分布模型的信息熵.其中,一個數據塊的統計模型對應的信息熵越大,則代表該塊數據分布的不確定性越高,塊內包含的信息量越大,并且將越逼近于均勻分布.針對均勻多塊拼接的網格數據,每個數據塊的1-鄰域構成關系,可以分為圖4 所示的4 種情況,深色立方體部分標記為中心數據塊.針對中心數據塊,計算其與1-鄰域上每個數據塊的統計分布模型的聯合熵.特別地,聯合熵越大,表明該鄰接塊的分布對中心塊的分布所帶來的影響越小.基于聯合熵,可以獲得中心數據塊與其1-鄰域數據塊的統計分布模型的互信息.其中,互信息越大,表明2 個數據塊之間的相關性越強.
然后,基于數據塊之間的相關性感知采樣,進行塊間的統計分布相關性統計建模.其中,基于信息熵和互信息的理論,本文的相關性感知采樣包含了3 項基本建模準則:1)信息熵越大的數據分布,越需要根據該塊的鄰接塊的分布信息,對其進行相關性修正;2)與中心數據塊分布具有較大互信息的鄰接數據塊,則其相關性系數越大;3)與中心數據塊分布具有較大聯合熵的鄰接數據塊,則其所需的相關性感知采樣系數較小.如圖3 所示,具有加粗黑色邊框的子塊區域代表一個中心數據塊,其他8 個子塊區域代表中心數據塊的1-鄰域數據塊.圖3 中數據點的不同圖案填充,代表不同的物理場變量值.通過針對中心數據塊及其鄰域數據塊的數值分布直方圖進行相關性統計建模,本文方法可以提升中心數據塊在邊界附近的統計分布重建精度.隨后,結合空間分布模型,即可得到關于中心數據塊的相關性統計模型.
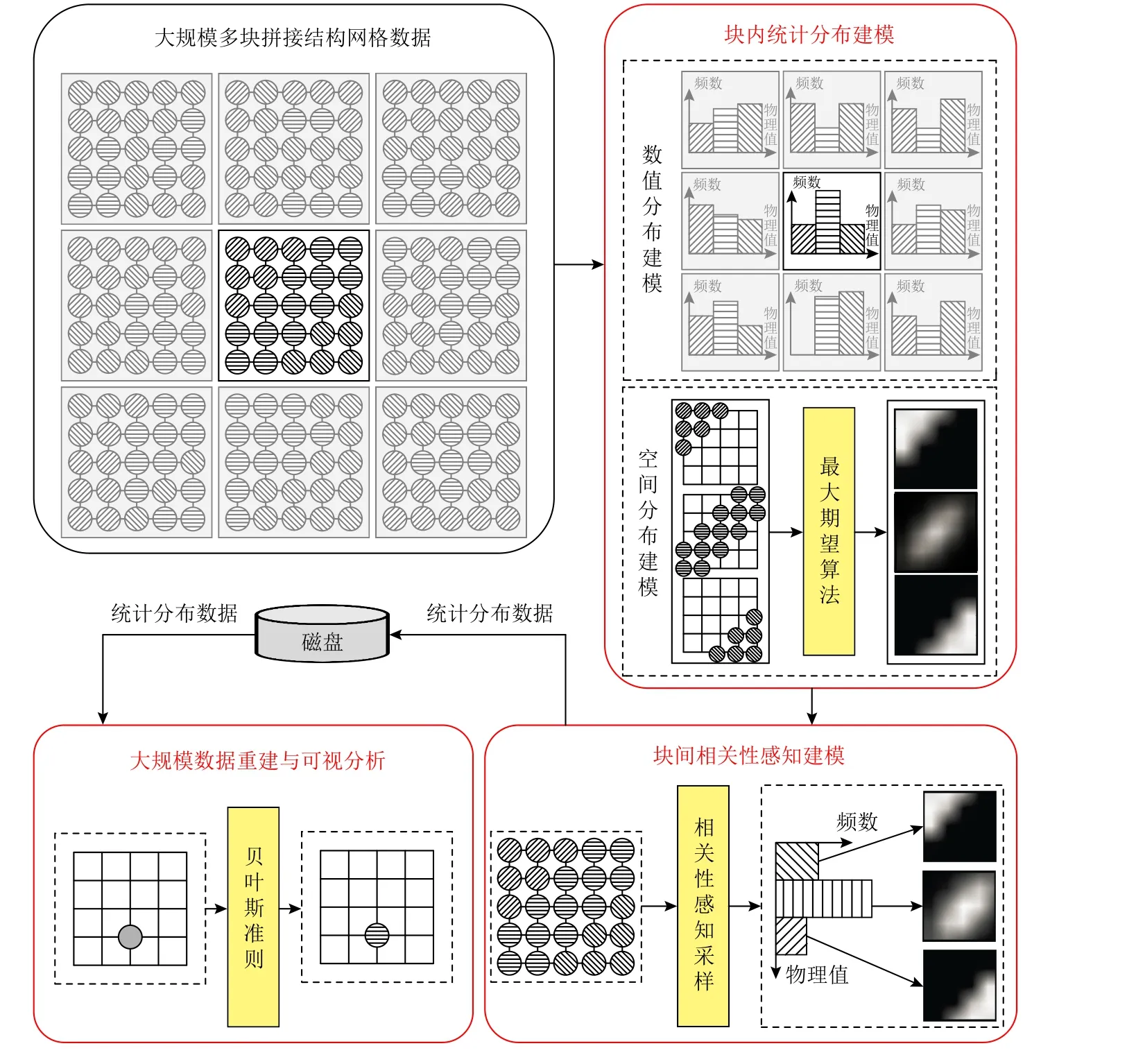
Fig.3 Method workflow of SGMM圖3 SGMM 方法流程圖
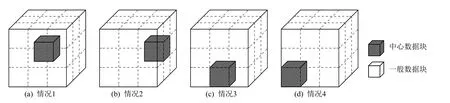
Fig.4 Four cases for 1-ring composition of a data block圖4 數據塊1-鄰域的4 種分布情況
本文的統計建模過程,可以通過原位可視分析的緊耦合模式,直接對接大規模數值模擬應用,作用于數值模擬的計算結果輸出過程,產生用于事后分析的統計分布數據.本文統計模型的數據表征方法,可以大幅降低大規模數值模擬應用的數據存儲量,同時還能夠高質量保持數據蘊含的物理特征,因此可以支撐事后的高效、高置信度可視分析.
最后,還需要統計分布模型的數據重建與可視分析.現有的可視分析算法均面向網格數據表征進行設計.因此,可視分析應用在讀入統計分布模型表征的緊湊型數據后,還必須進行數據重建.數據重建包括網格拓撲構建和網格頂點上的變量數據重建2部分.對于結構網格應用,網格拓撲的構建無需依賴統計分布模型信息,重點在于網格頂點的變量數據重建.變量重建的過程,可以描述為:對于任意給定的一個空間位置坐標,在確定其所在數據塊后,利用貝葉斯準則將數值分布、空間分布和相關性分布進行耦合,估計該空間位置坐標所對應的物理場數值,得到數據重建結果.
3.2 數據塊內的統計分布建模算法
數據塊內的統計分布建模算法,實現了每個結構網格數據塊的高精度統計建模,是實現多塊拼接結構網格數據高精度統計建模的基礎.該算法包含了數值分布建模和空間分布建模2 部分.
首先,計算數據塊內的數值分布模型.針對數據塊尺寸為b的均勻拼接結構網格數據,分別計算其每個數據塊的物理場變量的數值直方圖.其中數值直方圖Bin 區間的個數為M.以第i個 數據塊Blocki為 例,其物理場變量記為Xi.使用直方圖Histi對Xi的概率密度函數進行估計,Histi的每個Bin 區間對應一個數值區間.以第j個統計區間Binj為例,其相應的數值區間記為 [Lj,Uj],物理場數值屬于該區間的網格采樣點數目記為C,數據塊Blocki內的網格采樣點總數目記為Nb,則統計區間Binj的頻率記為C/Nb.
其次,計算數據塊內的空間分布模型.針對第i個數據 塊Blocki的數值直方圖Histi的 第j個統計區間Binj,使用2.2 節中介紹的方法,計算物理場變量值能夠落在統計區間Binj內的網格采樣點,然后根據這些網格采樣點的空間位置坐標求解分布模型SGj.
需要注意的是,由于SGMM 為定義在無限空間內的近似分布,而非針對單一數據塊,這勢必會給數據塊內物理場變量的概率密度函數帶來一定的偏差,因此需要對其進行歸一化處理:
其 中 Ωi為數據 塊Blocki的空間 域,為SGj在Ωi上的累積概率.
3.3 面向多塊拼接數據的相關性統計建模算法
面向多塊拼接數據的相關性統計建模算法,考慮相鄰數據塊之間的統計分布特征,實現數據塊邊界的高精度統計建模,是多塊拼接結構網格數據高精度統計建模的關鍵部分.基于3.2 節的塊內統計建模結果,本節算法采用信息熵與互信息來表征數據塊之間的相關性,指導鄰接數據塊的統計分布相關性感知采樣,實現面向多塊拼接結構網格數據的高精度統計建模.
首先,計算每個塊內統計分布的信息熵和1-鄰域內數據塊間的聯合熵與互信息.以第i個數據塊Blocki為例,以Blocki為中心數據塊,其1-鄰域內數據塊集合記為BSi,分別計 算信息熵H(Hi),聯合熵H(Hi,),和互信息I(Hi,),其中為歸一化處理后的數值分布直方圖,且∈BSi.
其次,利用信息熵與互信息進行相關性感知采樣計算.采樣過程中需要用戶預先設定信息熵閾值ε和互信息閾值δ .以Blocki為例,若H(Hi)>ε,則以Blocki為中心數據塊,對其進行相關性感知采樣.遍歷其1-鄰域內數據塊集合BSi,若I(Hi,)>δ,則對中的網格點進行隨機采樣,采樣比例Radd計算為
其中Hmax為聯合熵的最大值.根據Radd對的空間域進行隨機采樣后得到的空間子域記為 Ωadd,Ωi更新為 Ωi∪Ωadd.利用更新后的 Ωi,將Hi更 新為.
特別地,相關性統計建模算法所涉及的信息熵閾值 ε和互信息閾值 δ,對模型重建精度和模型并行計算時間均具有顯著影響.不同閾值參數的評估見本文實驗部分(4.1 節).
3.4 基于統計模型的數據重建算法
采用統計模型表征,可以大幅降低大規模數值模擬在磁盤上的數據存儲量.但是,為了適應現有可視分析方法,將分布數據表達恢復成可視分析可以處理的網格數據表達,還需要進行基于統計分布模型的網格數據內存重建.本節算法在塊內統計建模算法和塊間相關性統計建模算法的基礎上,根據貝葉斯準則進行高質量的數據重建.本文算法中,重建數據采用了與原始數據一致的網格分辨率.
給定的3 維網格上的一個空間位置坐標p,首先要定位其所在的數據塊Blocki,并且遍歷的每個Bin 區間.其次,根據貝葉斯法則,計算位置p的物理場 數值落在第j個統計 區間Binj的概率:
4 實驗結果與分析

Table 1 Test Data表1 測試數據
實驗分別從重建精度和建模計算效能2 個方面進行測試與評估.首先,針對不同數據塊尺寸參數b、信息熵閾值ε、互信息閾值 δ和多種統計分布模型,以及時變和大規模模擬數據應用,來評估本文方法的重建精度.其次,本文分別從模型并行計算時間和數據壓縮比這2 個角度,評估本文方法對數值模擬實際應用的適用性和高效性.此外,本文在量化評估中使用歸一化均方根誤差(normalized root mean squared error,RMSE)和歸一化最大誤差(normalized maximum error,NME)來評估數據重建質量,它們的計算方法為:
其中X為原始數據,Y為重建數據,Xr為原始數據物理場變量的值域.此外,我們使用結構相似性(structural similarity,SSIM)[37]來度量2 組數據之間的相似性.
4.1 重建精度評估
4.1.1 不同數據塊尺寸b的影響
數據塊的尺寸代表了大規模數值模擬應用的區域分解特征.針對不同數據塊尺寸的對比測試,用以評估本文方法對該類數值應用特征的典型適用性.
圖5 展示了針對具有不同數據塊尺寸的氣候模擬颶風數據,給出基于SGMM 和本文提出的相關性統計模型的數據重建結果對比.其中,重建數據的可視分析采用了等值面繪制方法.分析結果顯示,當數據塊的尺寸相同時,SGMM 的重建結果顯示出鄰接數據塊之間存在明顯的數值不連續性,而本文方法卻可以提升鄰接塊邊界區域的數據重建精度,因此重建數據的數值不連續性得到了顯著改善.這主要是由于SGMM 僅對單塊網格數據進行獨立統計建模,缺少了鄰接數據塊的統計分布信息.另一方面,通常建模采用的數據塊尺寸越大,建模形成的統計分布數據的內存占用量越小,數據壓縮比越大,并行計算時間越短,但是重建精度卻越低.而本文方法通過相關性統計建模降低了數據塊尺寸對重建精度的影響.因此,基于本文方法可以采用大尺寸數據塊,獲得與必須采用小尺寸數據塊的SGMM 才能獲得的同等甚至更高的重建精度.因此,本文方法實現了對大規模數值模擬應用并行特征更好的適應性,如圖5(d)(e)所示.
4.1.2 不同信息熵閾值 ε的影響
本節主要討論相關性統計建模中的關鍵參數之一,即信息熵閾值 ε選取對建模質量的影響與評估.

Fig.5 Reconstruction results of HD with different block sizes圖5 氣候模擬颶風數據在不同數據塊尺寸的重建結果
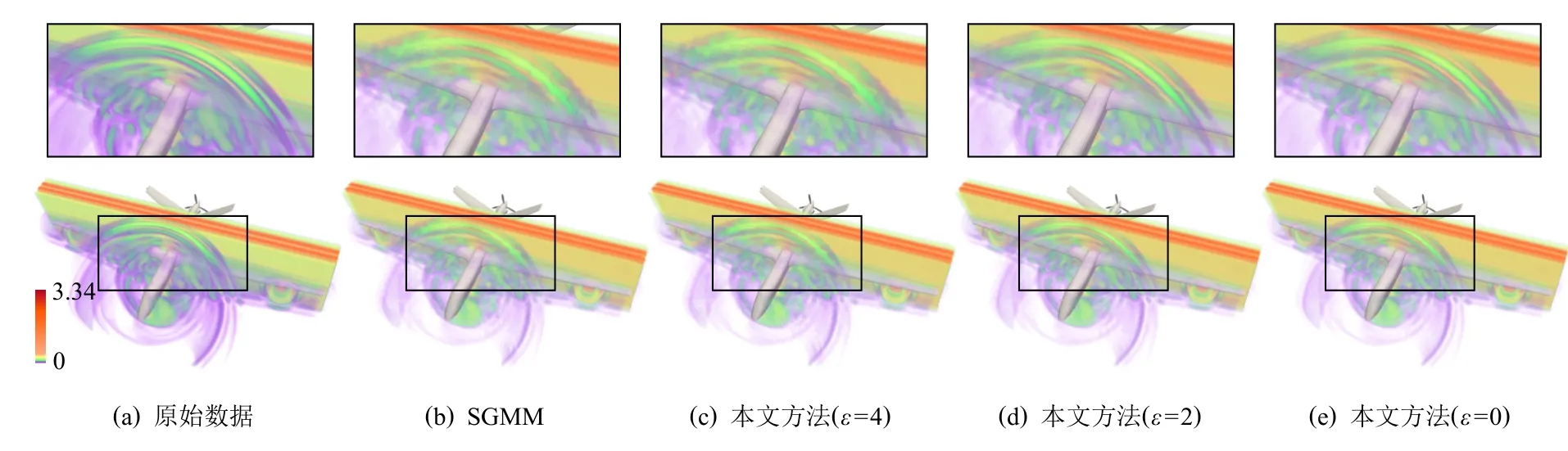
Fig.6 Reconstruction results of AED with different ε圖6 飛行器電磁模擬數據在不同ε 的重建結果
圖6 展示了不同信息熵閾值 ε參數設置下,使用SGMM 和本文所介紹的相關性統計模型對飛行器電磁模擬數據進行統計重建的體繪制結果.通過權衡數據壓縮比、計算時間與重建精度三者,本實驗設置數據塊尺寸b=8 進行建模.由于該模擬數據的物理特征尺度小,在數據塊尺寸b=8 時,數據重建會帶來一定程度的局部精度損失,導致體繪制光線在數據空間上針對紫色屬性數據的采樣數量降低,故這些像素區域的體繪制累積不透明度低,導致顏色更淡、面積更小的現象.但是,相比圖6(b),當設置 ε=2 和 ε=0時(圖6(d)(e)),本文方法獲得的重建數據及其體繪制結果具有更高的物質界面連續性.當原始數據場的網格分辨率進一步增大時,采用相同的數據塊尺寸將可以獲得重建精度更高的結果.圖7 展示了信息熵閾值 ε的不同設置下,計算時間T、數據壓縮比Rpre和重建精度RMSE,NME,SSIM的變化情況.結果表明,ε越小,進行相關性統計建模時需要耦合的數據塊越多,重建結果的精度越高、不確定性越低;但數據壓縮比越小,并行計算時間越長.通過權衡數據壓縮比、計算時間與重建精度三者,本文默認設置ε=2(由于直方圖Bin 區間個數的默認值為M=256,故 ε的最大值為8).如果用戶對數據重建精度有更高的要求,并且可以處理更大的數據內存占用和更長的并行計算時間,則可以使用更小的信息熵閾值.圖6(e)展示了ε=0 時相關性統計模型的重建結果,即在面向多塊拼接數據的相關性統計建模算法中對所有數據塊均進行了相關性統計建模.
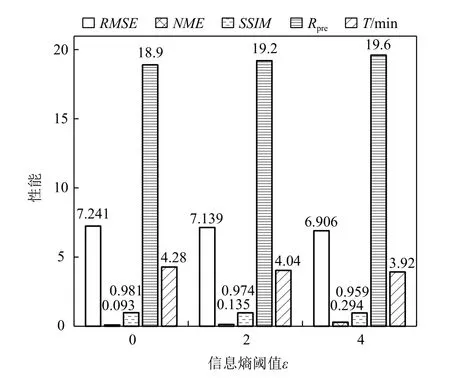
Fig.7 Quantitative analysis of AED with different ε圖7 飛行器電磁模擬數據在不同ε 的定量分析
4.1.3 不同互信息閾值 δ的影響
一年365天,吳躦輝有一半時間都奔波在路上,家人的支持和理解給他全身心投入到工作中提供了巨大的支持。談到接下來的規劃,吳躦輝希望從眼前的事情做起,一步一步把服務做實做細,讓農戶有個好收成。
本節主要討論相關性統計建模中的另一個關鍵參數,即互信息閾值 δ對建模質量的影響與評估.
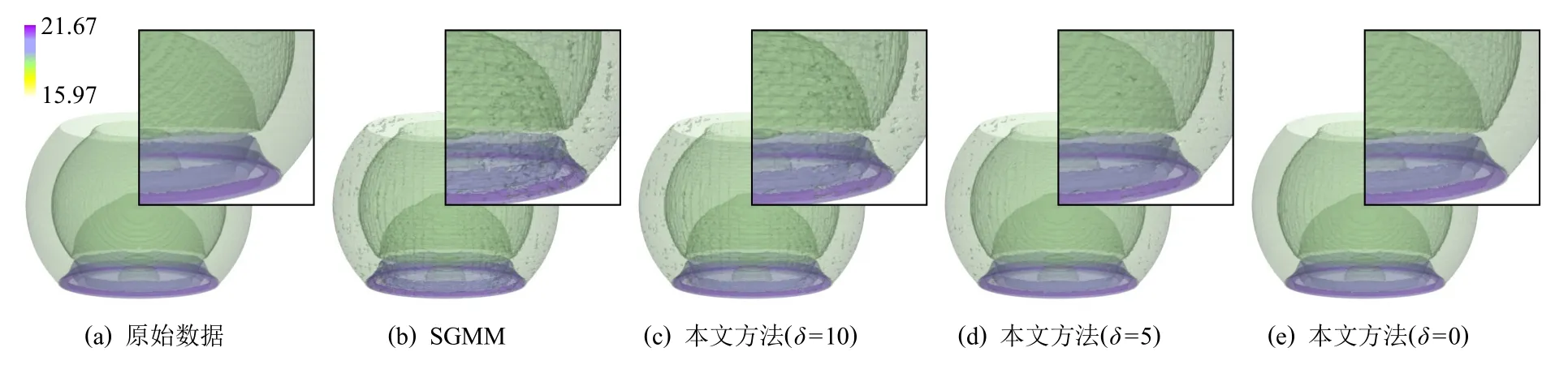
Fig.8 Reconstruction results of SWD with different δ圖8 沖擊波效應模擬數據在不同δ 的重建結果
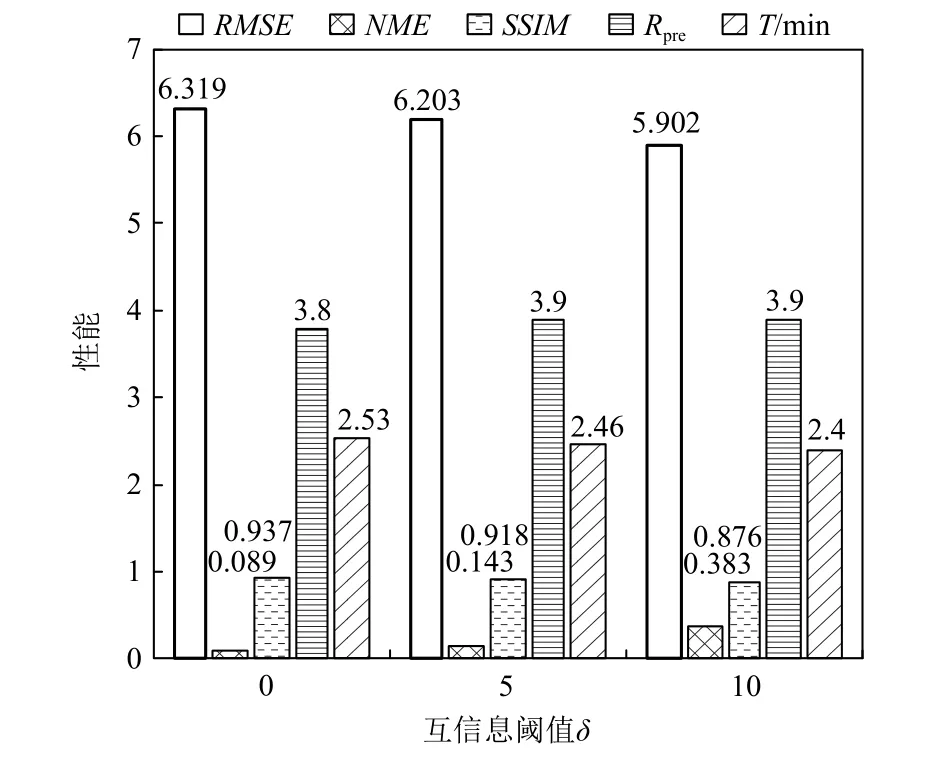
Fig.9 Quantitative analysis of SWD with different δ圖9 沖擊波效應模擬數據不同δ 的定量分析
圖8 展示了不同互信息閾值 δ參數設置下,使用SGMM 和本文所介紹的相關性統計模型對沖擊波效應模擬數據進行統計重建的結果,選取了沖擊波效應模擬數據的4 個等值面進行渲染.圖9 展示了互信息閾值 δ的不同設置下,計算時間、數據壓縮比和重建精度的變化情況.結果表明,δ越小,執行隨機采樣的相鄰數據塊的數目越多,重建結果的精度越高、不確定性越低;但數據壓縮比越小,并行計算時間越長.通過權衡數據壓縮比、計算時間與重建精度三者,本文默認設置δ=5(由于直方圖Bin 區間個數的默認值為M=256,故 δ的最大值為64).如果用戶對數據重建精度有更高的要求,并且可以處理更大的數據內存占用和更長的并行計算時間,則可以使用更小的互信息閾值.圖8(e)展示了δ=0 時相關性統計模型的重建結果.在多塊拼接數據的相關性統計建模算法中,針對每個中心數據塊的1-鄰域范圍,需要逐數據塊進行相關性感知的分布數據采樣計算.
4.1.4 不同統計分布模型的比較
不同的統計分布模型,可以描述不同的數據統計特征,其針對大規模多塊數值模擬數據的特征表征效果存在差異.對比不同統計分布模型的重建結果,可以評估本文提出方法對于大規模多塊數值模擬數據的適用性.
圖10 顯示了對慣性約束聚變激光成絲數據進行統計重建的結果,實驗采用了直方圖分布模型、SGMM和本文提出的相關性統計模型.在數據可視分析環節,本文選取了慣性約束聚變激光成絲數據的一個等值面進行可視分析結果評估.針對直方圖模型,其主要缺陷是在統計建模過程中僅處理原始數據的數值分布信息,而丟失其空間分布信息;SGMM 則添加了對數據空間分布信息的統計建模,但仍然無法達到高質量的數據建模要求,尤其在數據塊邊界.由于以上這2 種統計分析方法僅針對每個數據塊進行獨立統計建模,缺省了鄰域數據信息,因此其重建結果中數據塊間的數值不連續性相對明顯.相比之下,本文方法通過對數據塊間的統計相關性進行建模,顯著改善了塊間不連續性,與直方圖模型和SGMM 相比,它可以產生更為平滑的重建結果.定性定量分析的結果顯示,上述3 種統計模型的重建結果與原始數據間的歸一化最大誤差,分別為0.011,0.894,0.992.3 種統計模型的數據壓縮比均為43.5∶1,數據輕量化的效果顯著,但其中本文方法的模型重建精度最高.
4.1.5 超大規模數值模擬數據集
為了驗證本文方法處理超大規模數值模擬數據集的有效性,實驗使用了模擬小行星撞擊海底的2組大規模數值模擬數據集,采用體繪制方法進行可視分析.圖11 與圖12 分別給出采用SGMM 和本文相關性統計模型的統計可視分析結果.對比可知,本文方法可以顯著提升分塊數據邊界區域的重建數據的數值連續性,從而獲得與真實數據非常相似的重建結果.另外,本文方法還能夠實現針對原始大規模數據的高效數據壓縮.例如,模擬小行星撞擊海底數據的Tev 變量數據場和V02 變量數據場的數據壓縮比,可以分別達到22.2∶1 和11.4∶1,實現2 個數量級的大規模數據輕量化.
4.1.6 時變數據集
為了驗證本文方法處理時變數據集的有效性,實驗使用了包含48 個時間步的氣候模擬颶風數據集,根據不同的數據塊尺寸和不同的統計建模方法,組合為4 組實驗:1)b=16,使 用SGMM;2)b=8,使 用SGMM;3)b=16,使用本文的相關性統計建模方法;4)b=8,使用本文的相關性統計建模方法.圖13 與圖14分別展示了上述4 組實驗的時間步數據重建結果的歸一化最大誤差以及數據壓縮比的堆積柱形圖.分析可見,采用相同數據塊尺寸(實驗1 與實驗3),實驗2 與實驗4),本文方法具有更小的歸一化最大誤差,即重建結果精度更高;采用不同數據塊尺寸(實驗2 與實驗3),本文方法同時具有更小的歸一化最大誤差和更大的數據壓縮比.
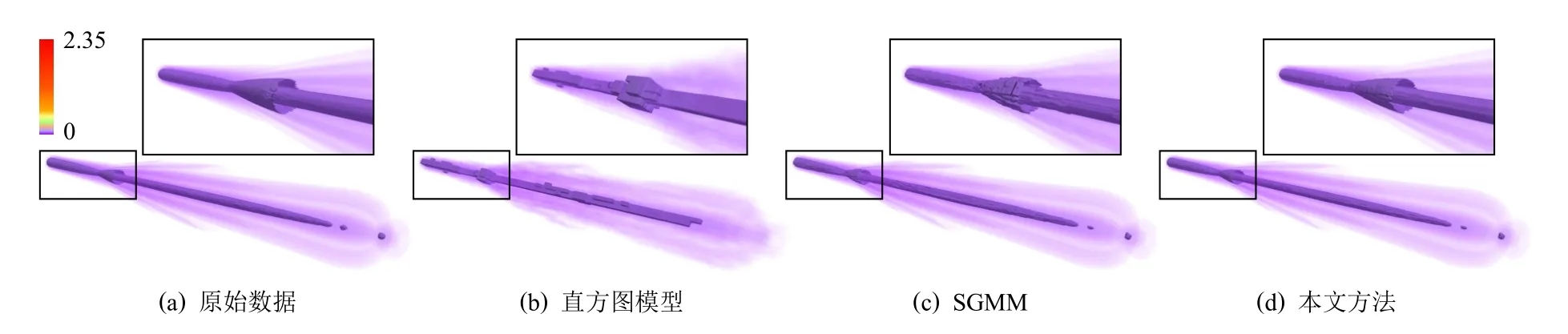
Fig.10 Reconstruction results of LD of different statistical distribution models圖10 慣性約束聚變激光成絲數據在不同統計分布模型的重建結果
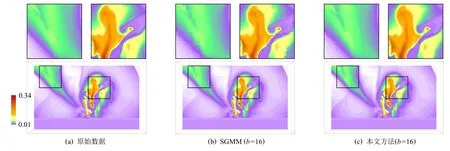
Fig.11 Reconstruction results of Tev field of AID圖11 小行星撞擊海底數據Tev 數據場的重建結果
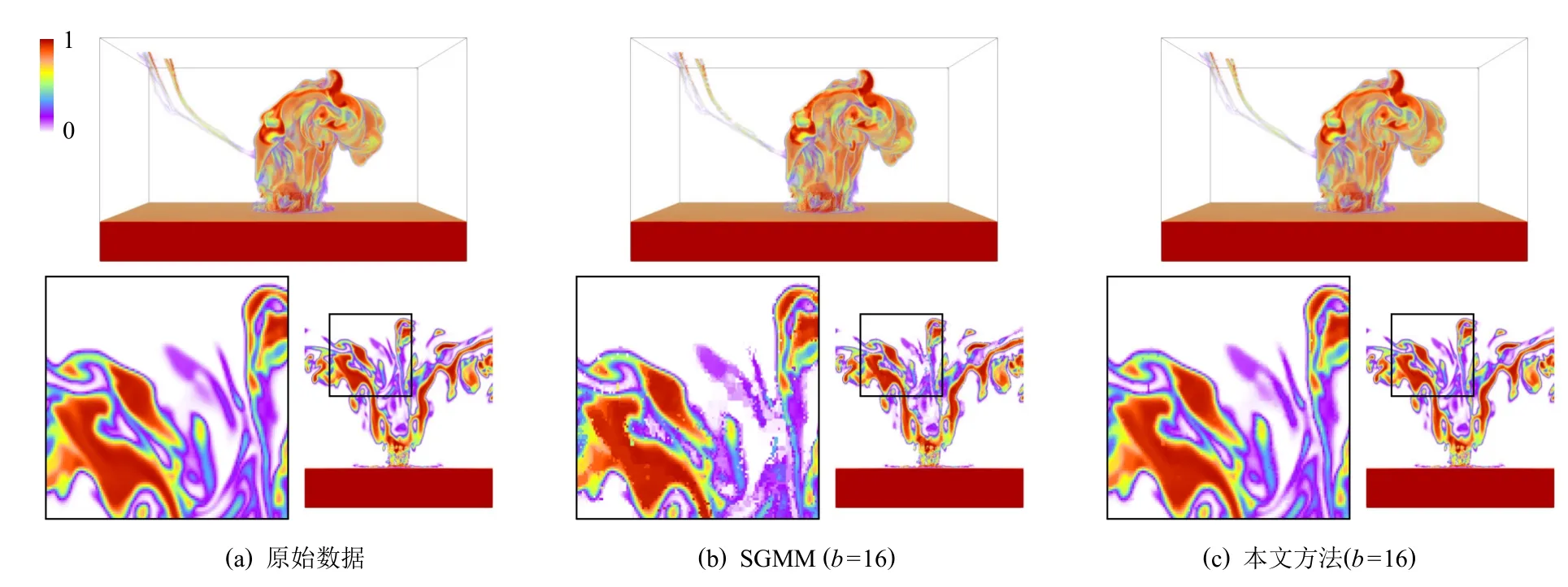
Fig.12 Reconstruction results of V02 field of AID圖12 小行星撞擊海底數據V02 數據場的重建結果
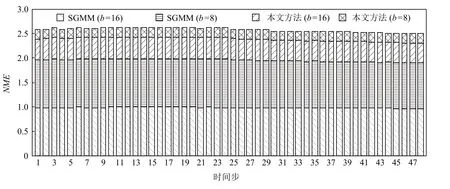
Fig.13 NME of HD varying with time step圖13 氣候模擬颶風數據在不同時間步的歸一化最大誤差
4.2 建模計算效能評估
4.2.1 并行計算時間
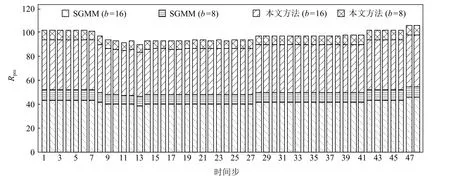
Fig.14 Rpre of HD varying with time step圖14 氣候模擬颶風數據在不同時間步的數據壓縮比
本節通過模型并行計算時間評估本文方法針對大規模模擬數據的處理效能.針對小行星撞擊海底數據(圖11),浪潮服務器節點的每個核分配的數據塊個數為9 300,采用24 核,塊內統計分布模型和相關性統計模型的并行計算時間分別為199.52 s 和29.88 s,數據重建的并行計算時間為79.06 s,數據壓縮比達到了22.2∶1.針對飛行器電磁模擬數據(圖6),浪潮服務器節點的每個核分配的數據塊個數為10 752,塊內統計分布模型和相關性統計模型的并行計算時間分別為155.25 s 和32.93 s,數據重建的并行計算時間為53.07 s,數據壓縮比達到19.2∶1.由于建模計算相對于數據可視分析是一個預處理過程,不強調處理的實時性,因此上述模型并行計算時間仍屬于用戶可接受范圍,并可通過并行核數的增加繼續縮短并行計算時間.而2 個數量級的壓縮比,則確實可以顯著解決應用數據的存儲瓶頸.此外,由于本文方法不需要對多塊數據進行合并與重分,可以顯著減少多核間的數據通信.本文方法對小行星撞擊海底數據(圖11)和飛行器電磁模擬數據(圖6)的通信時間分別為2.13 s 和1.09 s.
一般統計分布模型的精度,是與數據分塊的大小成反比趨勢變化的.而本文的統計分布模型則能夠采用尺寸更大的數據塊,獲得與SGMM 相似甚至更高的重建精度,因而建模速度更快.如圖5(c)和圖5(d)所示,SGMM 需要使用數據塊尺寸為b=8 時,才能獲得相對高質量重建結果,其模型并行計算時間為39.49 s.而采用本文模型,僅需采用數據塊尺寸b=16,即可獲得與b=8 時SGMM 的重建質量,并且模型并行計算時間相比更短,下降為僅需32.48 s(塊內統計分布模型和相關性統計模型的并行計算時間分別為31.22 s 和1.26 s).需要注意的是,原始數據的統計特征分布情況對本文算法的并行計算時間長短具有決定性影響,數據統計特征分布越集中,并行計算時間越短,反之亦然.
4.2.2 不同統計建模的效能比較
本文通過記錄通信時間Tc、模型并行計算時間Tm、重建并行計算時間Tr和 總時間Tt來說明本文方法在計算效能方面的優勢.由于本文方法可以直接處理原始的多塊數據,無需進行合并和重分,因此多核間的數據通信時間相對較短.直方圖分布模型和SGMM 則需要對合并后的數據進行重新分塊,需要更長的通信時間.圖15 和圖16 分別為適用直方圖分布模型、SGMM 和本文方法對飛行器電磁模擬數據和小行星撞擊海底數據進行計算的Tc,Tm,Tr,Tt.可以發現,對于直方圖分布模型和SGMM,數據通信占據了主要的時間,本文方法則使用最短的總計算時間獲得了最精確的重建結果.
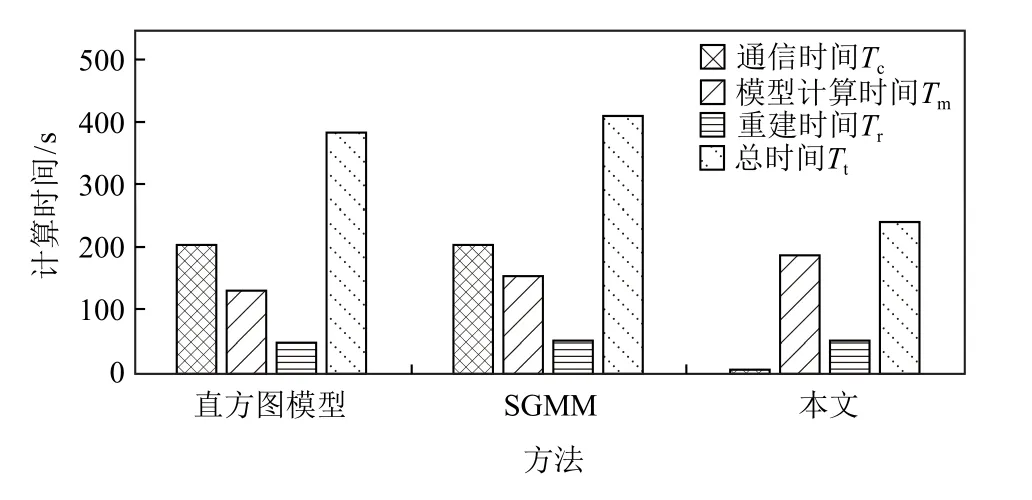
Fig.15 Efficiency comparison of different statistical modeling of AED圖15 飛行器電磁模擬數據在不同統計建模的效能比較

Fig.16 Efficiency comparison of different statistical modeling of Tev field of AID圖16 小行星撞擊海底數據在不同統計建模的效能比較
4.3 對比分析
實驗使用的小行星撞擊海底模擬、颶風氣候模擬、飛行器電磁模擬、沖擊波效應模擬和聚變激光成絲模擬數據,分別屬于流體力學、氣候變化、電磁環境、爆炸沖擊、慣性約束聚變等5 個不同應用領域,代表了當前結構網格科學模擬的典型應用.這些典型應用的高分辨率模擬結果均呈現復雜的空間分布特征,并且在單塊網格數據內表現出高度的數值異質性,如圖5,6,8,10~12 所示.現有統計建模方法忽視了上述單塊數據內的數值異質性,導致重建結果在數據塊邊界具有強數值不連續性,無法保持高精度.而本文方法則考慮了鄰域數據的統計分布特征,從而可以獲得數值連續性更優的重建結果,如表2第6~8 列所示.
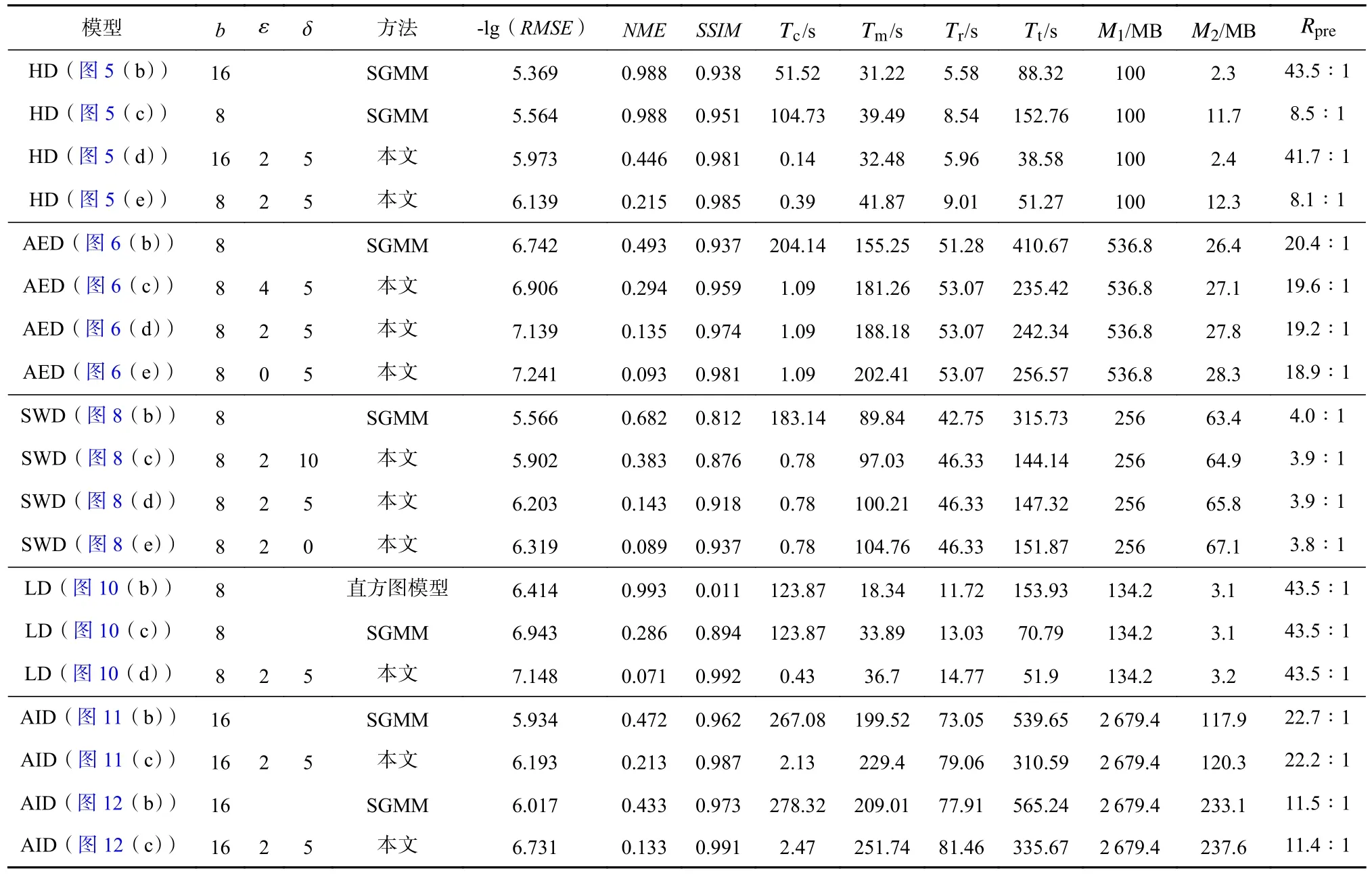
Table 2 Statistical Analysis and Computational Time of Test Data表2 測試數據的統計分析結果和計算時間
此外,本文方法不需要對原始多塊數據進行合并與重分,避免了隨并行計算規模顯著增長的數據通信開銷,因此,在實現跨量級的數據輕量化的同時,還能使得大規模數據的建模計算更加高效,如表2第10,11 列所示,其中M1為 原始數據所占內存,M2為統計模型所占內存,Rpre為數據壓縮比.綜上所述,本文方法能夠在顯著降低計算成本的同時,得到具有更高重建精度的數據輕量化結果,對于結構網格模擬應用具有較好的方法普適性.
5 結束語
本文提出了一種大規模結構網格數據的相關性統計建模輕量化方法,它通過使用數據塊間的相關性統計表征,指導鄰接數據塊的統計建模,從而有效地保留數據統計特征.通過耦合數據塊的數值分布信息、空間分布信息和相關性信息,可以更精確地重建原始數據,降低可視化的不確定性.且本文方法不需要在統計建模前對不同并行計算節點中的數據塊進行合并與重分,從而顯著減少數據通信開銷.通過采用最大包含10 億網格點的5 組科學數據進行實驗比較,定量分析結果顯示,本文方法相比現有方法可將數據存儲成本降低約1 個數量級,同時具有更高的重建精度.然而,雖然本文方法對結構網格數據具有普適性,但由于非結構網格數據和集成數據沒有規則的拓撲結構,使得本文方法難以適用.在未來的工作中,我們將考慮對網格的拓撲結構進行輕量化處理,實現本文方法的推廣.
作者貢獻聲明:楊陽進行了該論文相關實驗設計、編碼及測試、論文撰寫等工作;武昱進行了實驗設計和結果分析;汪云海進行了論文結構討論和修改;曹軼進行了實驗設計和論文修改.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
