制造業(yè)上市公司財務困境預測-Logit模型
2023-02-21 07:38:26樸蓮花
智庫時代 2023年4期
樸蓮花
(上海大學悉尼工商學院)
一、引言
破產(chǎn)是企業(yè)經(jīng)營的一種結(jié)果,達到這一結(jié)果的過程是一系列可識別的環(huán)節(jié):穩(wěn)健經(jīng)營—不穩(wěn)健經(jīng)營—財務困境—破產(chǎn)。財務困境又稱財務危機(Financial crisis):指現(xiàn)金流量不足以補償現(xiàn)有債務。
在當前激烈的市場競爭下,構(gòu)建科學、合理的財務風險預警模型,正確地預測企業(yè)財務困境,不僅可以保護投資者和債權(quán)人的利益,而且還有利于經(jīng)營者防范財務危機、政府管理部門監(jiān)控上市公司質(zhì)量和證券市場風險。
Logit模型因具有不嚴格要求指標服從多元正態(tài)分布的優(yōu)勢,選取合適的財務指標作為解釋變量,即可做到預測公司陷入財務困境的概率的用途,目前已經(jīng)得到廣泛運用。
國外研究方面,Ali Mansouri等(2016)采用了三層人工神經(jīng)網(wǎng)絡(luò)模型和logistic回歸模型,來比較兩種模型在基于提前3、2、1年的指標預測破產(chǎn)的效果。研究結(jié)果顯示,兩種模型都由較強的預測能力;Sami Ben Jabeur(2017)基于彌補傳統(tǒng)預測模型缺點的角度,用偏最小二乘邏輯回歸(PLS-LR)模型整合大量比率,同時考慮了矩陣中的缺失數(shù)據(jù)。這種方法優(yōu)于傳統(tǒng)方法,可以考慮預測財務困境的所有指標、環(huán)境不確定性的減少、控制變量的改進以及不同公司利益相關(guān)者之間的協(xié)調(diào)。
在國內(nèi),吳世農(nóng)、盧賢義(2001) 對 比 了LPM模 型、Fisher二類線性判定模型、Logistics模型的預測效果,結(jié)果表明Logistic模型的判定準確性最高;黃子罡(2020)、方圓(2021)將研究進一步延伸至采用KMV-Logit模型來研究違約模型的實際應用。
近幾年,國內(nèi)外學者采用Logit模型預測財務困境或違約的研究越來越多,且多集中于模型上的拓展。基于其他學者的研究,本文將研究視角轉(zhuǎn)移至選取對公司財務狀況最具有解釋能力的財務指標,以提高預測模型的準確性和可靠性。
二、Logit模型介紹
Logit函數(shù)的曲線,是一個單調(diào)上升的函數(shù),不存在斷點,但具有良好的連續(xù)性。而后衍生出的Logit回歸函數(shù),更常使用二分類的因變量,利用變量與變量的之間關(guān)系,對預測結(jié)果做出分類判斷。因為函數(shù)更常解決一個問題會發(fā)生或不會發(fā)生,所以隨后模型在完善應用中,常常解決各個領(lǐng)域中的概率問題。
本文將Logit模型與財務數(shù)據(jù)相結(jié)合,使用財務困境Logit預測模型對公司未來是否會發(fā)生財務問題進行預測。
假設(shè)公司i用于財務困境預測的k個財務指標集合為xi=(x1i,x2i,…,xki) ,則事件發(fā)生的條件概率記為pi=p(yi=1|xi)為客戶不違約的概率,稱為事件的發(fā)生比。在Logit分布下,Logit回歸模型的表達式為:
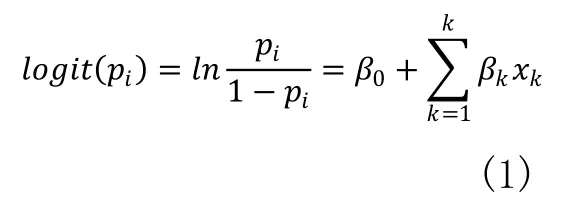
事件發(fā)生的概率可寫作:
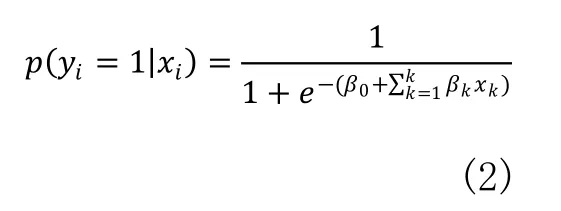
估計模型的參數(shù)后,根據(jù)式(2)計算企業(yè)陷入財務困境概率pi。
在企業(yè)財務危機判定和預測中,更多會關(guān)心危機的發(fā)生與否,Logit模型把預測一個公司是否發(fā)生財務危機的概率問題轉(zhuǎn)化為預測一個公司是否發(fā)生財務危機的機會比問題。根據(jù)Logit回歸模型計算結(jié)果,通過P的分割值0.5為界限,衡量企業(yè)發(fā)生財務風險的概率有多大,是否接近臨界值而造成后續(xù)財務危機。
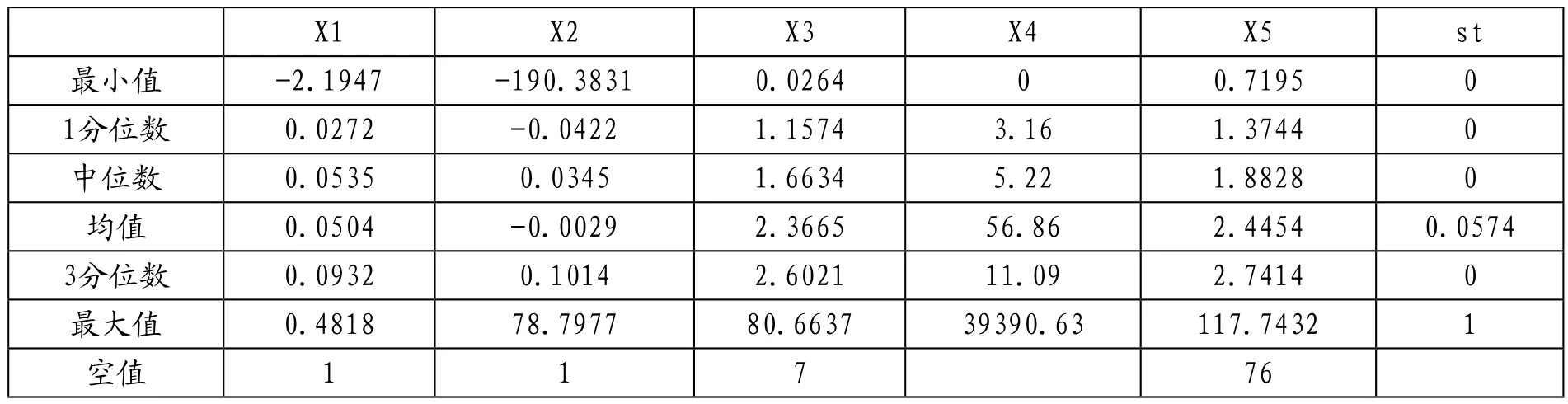
表1 原始參數(shù)值描述性統(tǒng)計
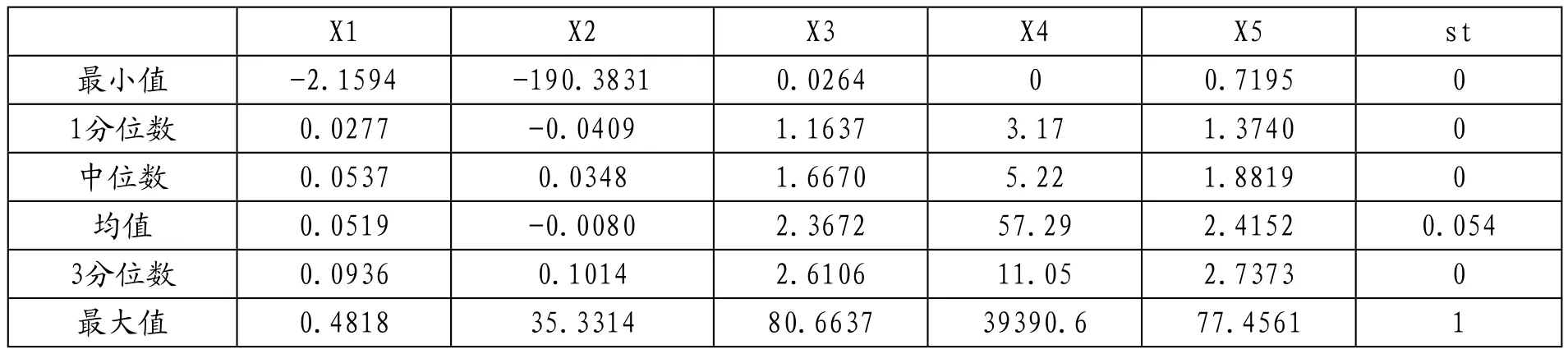
表2 處理后參數(shù)值描述性統(tǒng)計
三、數(shù)據(jù)來源及財務指標的選擇
本文選取的財務困境預測樣本是2017年-2019年的滬深兩市A股中正常經(jīng)營的公司和被ST或ST的1739家制造業(yè)公司,其中正常公司為1608家、ST或*ST公司為131家。對于樣本公司,預測其財務困境的財務指標數(shù)據(jù)均來自于公司被ST或ST年度前一年度的財務指標,也即利用t-1年的財務指標來預測其在第t年是否會處于財務困境或違約。樣本數(shù)據(jù)來源于CSMAR和Wind數(shù)據(jù)庫。
在借鑒數(shù)據(jù)可獲得性的基礎(chǔ)上,選擇反映公司財務狀況的5個財務指標。各項指標的名稱分別為:X1:資產(chǎn)收益率;X2:每股凈資產(chǎn)增長率;X3:流動比率;X4:應收賬款周轉(zhuǎn)率;X5:托賓Q比率。這些指標涵蓋了公司的盈利能力、發(fā)展?jié)摿Α攤芰ΑI運能力、投資價值等五個方面,具有一定的全面性。為分析簡便,將t年被st的值表示為1,未被st的值表示為0。另外,本文使用R(3.5.1)對數(shù)據(jù)進行實證分析。
四、實證分析
(一)數(shù)據(jù)清洗
將初試數(shù)據(jù)導入R后進行描述性統(tǒng)計分析,可見部分數(shù)據(jù)存在空值,因此使用na.omit()進行空值刪除處理,從原有的4900條數(shù)據(jù)縮減至4816條數(shù)據(jù)。
(二)多元Logit回歸模型的選擇
Logit回歸是研究因變量為二分類或多分類變量與影響因素之間關(guān)系的一種多變量分析方法,是一種概率性非線性回歸。一個隨機事件是否發(fā)生常常受到多個因素的影響,Logit回歸分析可以在多種多樣的影響事件的潛在因素中選出其中對事件發(fā)生概率影響較大的因素,并根據(jù)這些因素建立該事件在特定時間內(nèi)發(fā)生的概率預估模型。
本文初步篩選5個變量后,將結(jié)果顯示為不顯著的變量刪除,來確保所得自變量子集中每一個變量都是顯著的。
1.首先將st和5個參數(shù)值進行多元回歸后發(fā)現(xiàn),X1和X5的回歸系數(shù)顯著性最明顯,其他項的顯著性并不明顯。
隨后為檢驗所有因素是否確實有用,計算自由度為7的卡方統(tǒng)計量和p值,結(jié)果p值<0.001,說明拒絕H0,也即βi都為0的概率非常小,至少有一項對st的預測有貢獻。
表3 Logit回歸結(jié)果(X1X5)
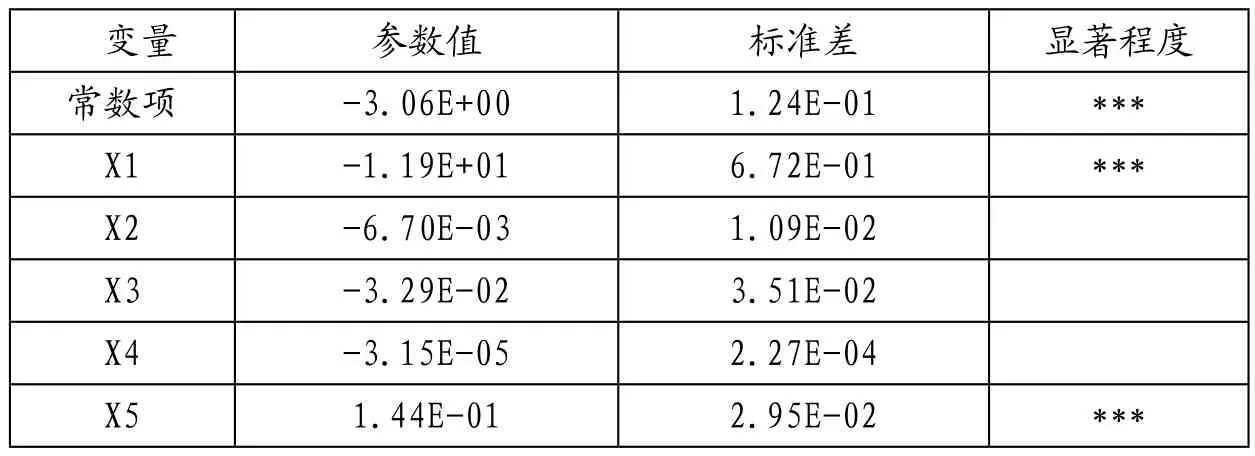
表3 Logit回歸結(jié)果(X1X5)
變量 參數(shù)值 標準差 顯著程度常數(shù)項 -3.06E+00 1.24E-01 ***X1 -1.19E+01 6.72E-01 ***X2 -6.70E-03 1.09E-02 X3 -3.29E-02 3.51E-02 X4 -3.15E-05 2.27E-04 X5 1.44E-01 2.95E-02 ***
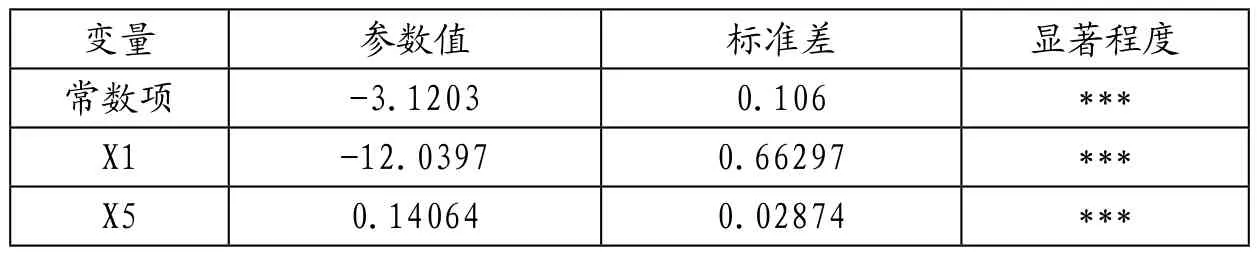
表4 Logit回歸結(jié)果(X1、X5)
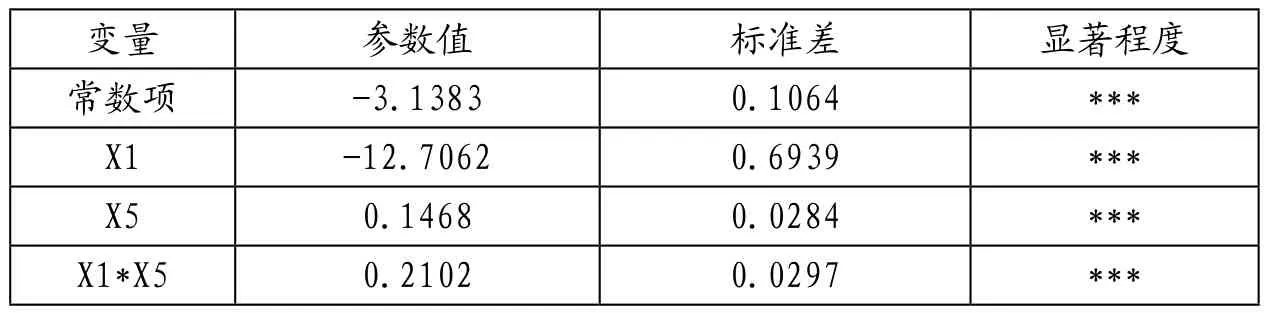
表5 Logit回歸結(jié)果(X1、X5、X1*X5)
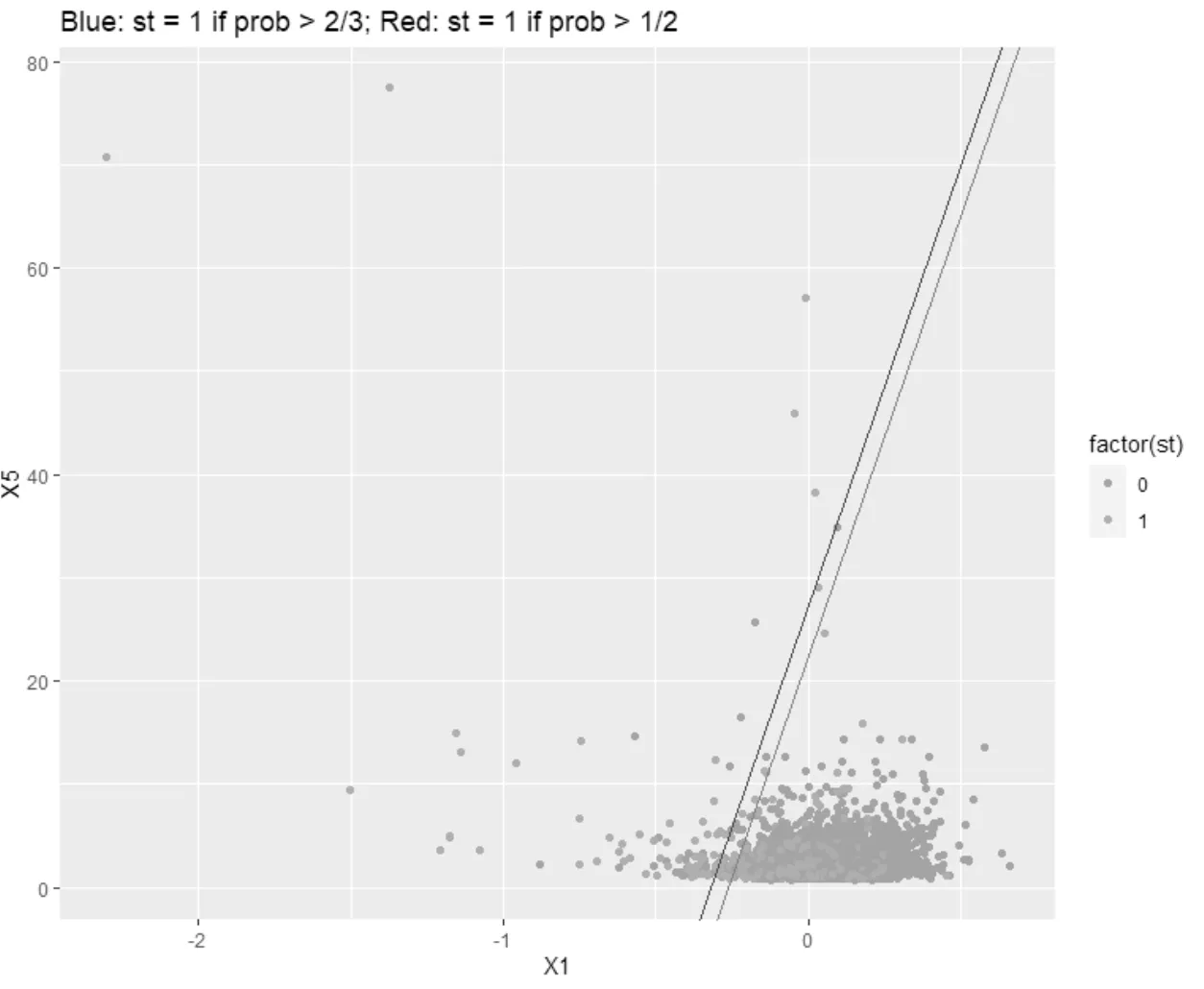
圖1 Logit回歸分類作圖
2.由于前一步驟發(fā)現(xiàn)X1和X5的顯著性最明顯,因此對st和X1、X5進行多元回歸,結(jié)果發(fā)現(xiàn)兩個變量的顯著度未出現(xiàn)大變動,且所有變量的顯著度都非常明顯。
為檢驗所有因素是否確實有用,計算自由度為2的卡方統(tǒng)計量和p值,結(jié)果p值=0.67非常大,無法拒絕H0,也即無法認為βi不都為0。
3.X1和X5的顯著性最明顯,但僅用這兩項進行回歸后進行卡方分布的結(jié)果不理想,因此這一步引入X1和X5的乘積,即對st和X1、X5和X1*X5進行回歸,結(jié)果三個變量都非常明顯。
再計算自由度為3的卡方統(tǒng)計量和p值,結(jié)果p值=0.0138<0.05,在5%的置信度拒絕原假設(shè)。
(三)多元Logit回歸模型的分類器
分類器是為了從數(shù)據(jù)特征中學習出一個0/1分類模型,這個模型以樣本特征的線性組合作為自變量,應用Logit函數(shù)將自變量映射到(0,1)上。因此分類器的解是求解一組權(quán)值θ0,θ1,…,θn,并代入 Logit 函數(shù)構(gòu)造出預測函數(shù):
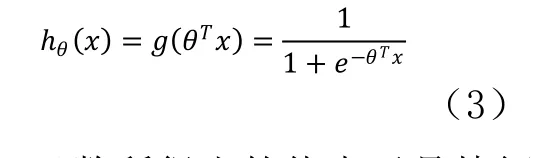
函數(shù)所得出的值表示是特征屬于y=1的概率。也即,對于輸入x分類結(jié)果為y=1和y=0的概率分別為:
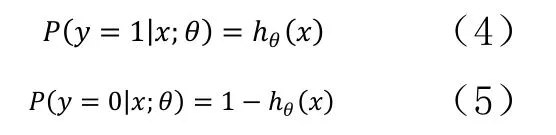
當我們要判別一個新來的特征屬于哪個類時,按照下式求出一個z值:

x1,x2,...,xn是樣本的各個特征,維度為n。然后求出hθ(x),若大于0.5則y=1,反之屬于y=0。分類器的這一組權(quán)值需要涉及到極大似然估計MLE。
根據(jù)前文分析,以下使用X1和X5選擇分類器,將估計概率作為預測器的函數(shù)進行閾值化。

當估計概率為2/3時,X5>85.606513X1+ 27.114954 則st=1
當估計概率為1/2時,X5>85.606513X1+ 22.186433 則st=1
將兩種概率閾值的圖像畫出,無法從圖中獲得明顯的結(jié)論,因此我們以0.5的概率作為預測閾值。
(四)最終模型
為確定最終模型,引入ROC曲線和AUC來判斷最優(yōu)模型。
ROC曲線又稱接收者操作特征,ROC曲線上每個點反映著對同一信號刺激的感受性。橫軸為FPR特異度,劃分實例中所有負例占所有負例的比例,也即1-Specificity。縱軸則是TPR靈敏度,也即Sensitivity。
AUC是ROC曲線下的面積,介于0.1和1之間。AUC作為數(shù)值可以直觀的評價分類器的好壞,值越大越好。AUC值是一個概率值,當隨機挑選一個正樣本以及負樣本,當前的分類算法根據(jù)計算得到的值將這個正樣本排在負樣本前面的概率就是AUC值,AUC值越大,當前分類算法越有可能將正樣本排在負樣本前面,從而能夠更好地分類。
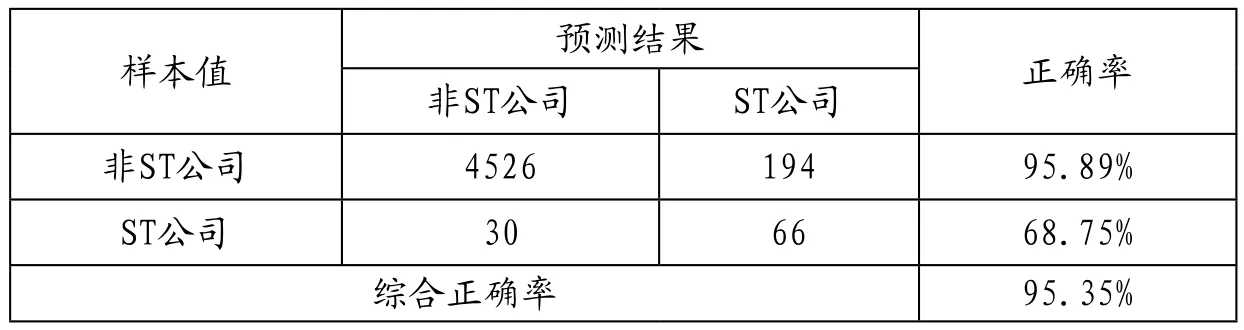
表6 模型預測效果

圖2 Logit回歸ROC曲線作圖
對于前文分析的3種Logit模型畫圖,可以看出第3個模型的AUC值最高,達到0.853,因此最終選用第三個模型作為最終財務風險預測模型。
(五)模型檢驗
使用第三個模型對樣本值進行預測檢驗,在概率P值設(shè)置為0.5的情況下,結(jié)果綜合正確率可以達到95.35%。其中對非ST公司的預測準確率可以達到95.89%,對ST公司的預測準確率達到68.75%。綜合正確率雖然比較高,但對于ST公司的預測正確率提高還有較大的發(fā)展空間,總體上該模型的預測結(jié)果是可信賴的。
(六)小結(jié)
根據(jù)實證分析,最終確定的制造業(yè)企業(yè)財務風險預測模型的表達式為:

發(fā)生財務風險的概率可寫成:

根據(jù)上式計算公司發(fā)生財務風險概率,若p≥0.5,則認為公司預計下一年發(fā)生財務風險,股票被ST;若p<0.5,則認為公司下一年財務狀況將處于正常狀態(tài)。
五、結(jié)論
通過對財務數(shù)據(jù)的Logit回歸分析,可以得出我國制造業(yè)上市公司股票戴上ST,也即公司出現(xiàn)財務問題,與公司前期的資產(chǎn)收益率和托賓Q比率有較大的關(guān)系,也即公司的盈利能力和投資價值對公司財務預警的影響較大。當然,其他指標雖然在該模型中沒有顯著性關(guān)聯(lián),但這并不意味著這些指標對公司未來價值沒有影響,優(yōu)秀上市公司的財務指標應當?shù)玫饺姘l(fā)展,使得我國證券市場得到良好的發(fā)展。
本文聚焦制造行業(yè)數(shù)據(jù)構(gòu)建模型,樣本數(shù)據(jù)越多,提取的財務指標種類越復雜,Logit模型的精確度會越高。但制造業(yè)整體數(shù)目雖然龐大,內(nèi)部個體企業(yè)間差異較大,業(yè)務細分企業(yè)的數(shù)目又太少,總體結(jié)果雖達到研究目的,但由于作者學術(shù)能力的不足以及數(shù)據(jù)的不完善,因此得出的Logit模型準確性依舊有所局限。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
現(xiàn)代企業(yè)(2021年2期)2021-07-20 07:57:18
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
現(xiàn)代經(jīng)濟信息(2020年34期)2020-06-08 06:02:40
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年12期)2020-04-13 00:54:08
意林·全彩Color(2019年9期)2019-10-17 02:25:48
河南水利年鑒(2017年0期)2017-05-19 02:29:27
環(huán)境保護與循環(huán)經(jīng)濟(2017年8期)2017-03-22 01:28:58
環(huán)境科技(2016年3期)2016-11-08 12:14:20
