面向空間興趣區(qū)域的路線查詢
2022-11-12 11:28:06劉俊嶺劉柏何鄒鑫源孫煥良
計算機研究與發(fā)展 2022年11期
關鍵詞:區(qū)域
劉俊嶺 劉柏何 鄒鑫源 孫煥良
(沈陽建筑大學計算機科學與工程學院 沈陽 110168) (遼寧省城市建設大數據管理與分析重點實驗室(沈陽建筑大學) 沈陽 110168)
廣泛的位置感知應用產生了大量的空間文本數據,如用戶的簽到數據和評論、帶有地理標記的帖子以及商業(yè)平臺的基于位置的廣告等,擴展了路線規(guī)劃問題.結合空間文本數據,產生了符合用戶給定關鍵字相關約束的路線查詢問題[1-3].
現有的應用空間文本查詢路線的研究,通常返回1條由空間興趣點(point of interests, POI)組成的路線,每個POI是單獨的空間對象[4-7].由于實際應用中POI及相關的空間關鍵字是海量的,并且POI的分布通常嚴重偏斜,使得多條路線通過相同的聚集區(qū)域,導致查詢結果相似性較高,無法滿足用戶對于結果多樣性的需求.同時路線查詢需要遍歷每個POI及相關的空間關鍵字使得查詢算法的效率較低.
圖1(a)為空間關鍵字POI路線查詢示例圖,其中曲線代表軌跡、實心圓代表POI點.假設查詢起點為p1,給定路線長度約束及空間關鍵字集合,以最大化關鍵字收益和為目標可以得到2條路線,分別為A1(p1→p4→p5→p6)和A2(p1→p3→p5→p6).從示例中可以看出路線A1與A2存在多個重疊結點,導致路線間的相似性較大.當存在大量的POI及相關的空間關鍵字時,增加了搜索空間,影響了查詢算法的效率.
本文提出了面向空間興趣區(qū)域的路線查詢(region of interests oriented route query, ROIR)問題.給定一個反映用戶轉移關系的圖G、帶有關鍵字的POI集合P及查詢QU(v0,C,r,L),其中v0為查詢起點,C為關鍵字集合,r為一個興趣區(qū)域半徑,L為路線的長度限制.ROIR返回滿足長度L約束,關于關鍵字集C收益和最大的路線Ares,路線Ares的每個結點為一個興趣區(qū)域.如圖1(b)所示,在與圖1(a)相同的查詢條件下可以得到查詢結果Ares(D1→D2→D3→D4),該結果由半徑為r的興趣區(qū)域序列組成,包含了圖1(a)中A1和A2這2條路線.
與現有的POI路線查詢相比,ROIR返回路線的結點為興趣區(qū)域,包含了多個鄰近的POI,降低了路線的相似性,增加了用戶的選擇空間,使得查詢結果有更好的適用性.同時ROIR結果包含多條POI路線,提高了查詢效率.ROIR適用于海量分布的POI及空間關鍵字場景下的關鍵字偏好路線查詢,同時ROIR也適用于結伴出行情況,允許用戶在興趣區(qū)域內分別訪問各自偏好的地點.
本文將空間路線查詢對象由POI擴展為興趣區(qū)域,存在的主要挑戰(zhàn)包括:1)如何有效組織多種類型的海量POI及相關空間關鍵字是一個挑戰(zhàn).本查詢涉及用戶的空間轉移關系、空間對象及對象的文本描述等多種數據類型.2)如何設計支持ROIR的高效算法是另一個挑戰(zhàn).需要建立適用于所提出查詢的索引結構.ROIR是一個NP難問題,需要設計相應的高效近似算法.
為了應對以上2個挑戰(zhàn),本文提出一種2層數據組織模型.其中上層為反映用戶轉移關系的圖結構,結點概括抽象了POI的聚集區(qū)域;下層為細節(jié)的POI數據及相關空間關鍵字信息.針對提出的空間數據組織模型,提出了綜合空間對象、轉移關系以及空間關鍵字等信息的索引結構,同時預計算了空間關鍵字的局部收益的統(tǒng)計值,并以簽名方式存儲在轉移結點上.利用所提出的索引結構,設計了過濾—提煉2階段ROIR精確算法以及近似算法.
本文工作的主要貢獻有3個方面:
1) 定義了面向空間興趣區(qū)域的路線查詢問題,解決了現有關鍵字路線查詢中多樣性不足問題,提高了路線查詢的適用性.
2) 設計了結合上層轉移圖與下層POI對象及相關空間關鍵字的2層數據組織模型.針對2層模型提出一種新的索引結構,并設計了面向空間興趣區(qū)域的路線查詢優(yōu)化算法.
3) 利用真實數據集進行了詳細的實驗分析,評估了所提出算法的有效性.
1 問題定義
給定一個空間D、興趣點集合P,任何一個點p∈P表示為p(p.id,p.loc,p.C),其中p.id是p的唯一身份標識,p.loc是點p的空間坐標,p.C是點p含有的關鍵字及其流行度的集合.對于一個興趣點的某個關鍵字p.c∈p.C,收益分值p.Sc代表點p中關鍵字c的流行度,可用用戶的訪問次數表示.
轉移圖G(V,E)是用戶在空間上軌跡轉移的概括表示,反映了結點間用戶流行的轉移關系,其中V為結點的集合,E為邊集.任意結點v∈V代表興趣點聚集的中心點,定義為(v.id,v.loc),其中v.id是v的唯一身份標識,v.loc是結點v的空間坐標;任意邊e∈E代表V中2個結點vi與vj間的轉移關系.轉移圖的生成方法將在2.1節(jié)中介紹.


(1)

(2)

查詢實例如圖2所示,假設查詢關鍵字集合為C={a,b,d,e,f}.長度約束L=17,區(qū)域半徑r=2,查詢起點為v1.

Fig. 2 The example of ROIR圖2 ROIR實例
對于傳統(tǒng)POI路線查詢,例中針對查詢關鍵字集合C的最優(yōu)結果為序列A2(p1→p4→p5→p6),序列收益分數為29.然而,對于ROIR最優(yōu)路線為A1(v1(D1)→v3(D2)→v5(D3)→v7(D4)),其收益為33,高于POI路線的收益.由定義1可知,ROIR屬于空間關鍵字偏好的路線查詢,將關鍵字的收益和作為優(yōu)化目標.
由實例可以看出,所提出的ROIR可以提高路線的收益值.由區(qū)域組成的路線,提高了原有單個POI結點的多樣性,起到對多個相似路線聚集的作用.另外,在轉移圖上按興趣區(qū)域查詢也可以提高查詢效率.
實現ROIR是一個具有挑戰(zhàn)性的工作.由實例可知,本查詢涉及POI點、圖結構以及文本信息等多種類型的數據,并且實際應用中數據具有海量性,需要對數據進行有效的組織與設計相應索引以支持查詢.同時所定義的查詢在轉移圖上進行搜索是NP難問題.假設每個結點的出度為λ,即經過結點后有λ條路可選擇,在長度約束L下可以經過的結點個數為n,則代價為λn,若結點上含有關鍵字個數為m,則最終代價為(m·λ)n.因此,ROIR問題是NP難問題.表1簡要概述了本文所使用的符號.

Table 1 Symbol Summary表1 符號總結
2 查詢處理算法
本節(jié)介紹數據組織與索引結構,以及精確查詢算法和近似查詢算法.
2.1 數據組織與索引結構
為了有效地處理多類型的海量數據,考慮將POI及相關空間關鍵字密集且流行度高的區(qū)域聚集,并從具體的細節(jié)數據中分離出來,以提高查詢路線的多樣性和算法查詢效率.因此,提出一種2層數據組織結構,如圖2所示.圖2中,上層為轉移圖,由軌跡的交叉區(qū)域提取或是密集POI點聚集生成;下層為具體的POI及其關鍵字信息,路線的關鍵字收益得分由下層數據提供.
本文首先利用用戶軌跡數據,采用文獻[4]的方法提取了轉移圖.同時,添加一些流行度高且遠離現有結點的POI聚集點,采用了基于網格密度聚類的方法產生增加的聚集點[8].首先將空間網格化,統(tǒng)計單元格內點的數量并對稠密的單元格進行聚類;然后計算轉移結點所在單元格與聚類后的單元格的轉移數量,數量超過一定閾值即可生成一條轉移邊;最后提取聚集網格的中心點加入轉移圖.
針對提出的2層數據組織模型,本文借鑒文獻[9]對交通網絡的索引結構,并引入關鍵字簽名,提出了結合空間文本索引與轉移圖結構的索引結構,命名為BIR(balance information tree).如圖3所示,索引結構由3部分組成,第1部分為擴展的B+樹結構,存儲了轉移圖上的結點、鄰接表以及關鍵字的概要簽名信息,對應于圖2中上層數據結構;第2部分為IR樹結構,用于存儲POI點空間位置及其文本信息,對應于圖2中下層數據結構;第3部分為圖結點與空間最小邊界矩形MBR的關系表,用于連接IR樹與B+樹這2個索引,實現圖結點到其所在MBR的聯系.

Fig. 3 BIR index structure圖3 BIR索引結構
IR樹結構中使用簽名存儲2層結構中底層的POI點信息,底層結點存儲POI點包含的關鍵字及分值,非底層結點{E1,E2,…,En}稱為中間結點,代表IR樹中由結點組成的矩形區(qū)域MBR.中間結點的簽名由多個葉子結點的簽名計算得到,為該區(qū)域內葉子結點的關鍵字與其最大分值.
擴展的B+樹結構中每個結點存儲2部分內容,分別為結點鄰接表和關鍵字范圍簽名(命名為r簽名).鄰接表存儲一個結點所有鄰接結點的信息,圖3中v1結點的鄰接表由鄰接結點v2,v3,v4組成,v1鄰接表的第1行v2,5,ptr2表示v1鄰接到v2,5為2點間的距離,ptr2指向v2在B+樹中葉子結點的位置.
關鍵字范圍簽名存儲了以結點為中心多個同心圓周范圍內的關鍵字收益的最大值信息.圖3中簽名的每一列對應不同的半徑r.例如,以v2結點為中心的r簽名中,當r1=400 m時,(p8,p9,p10)包含在范圍400 m內,取這些POI點的關鍵字的最大收益值,可以得到{0,2,1,2,0,0}作為簽名表的1列.


(3)
文獻[10]給出適宜步行距離的結論,即在787 m的步行距離以內,用戶選擇步行出行的可能性超過10%.本文選取1 000 m作為r的最大值,在該范圍內用戶選擇步行分散訪問所偏好的空間對象.通過預計算的r簽名可以初步估算路線收益值,從而過濾大量的結點,減少候選路線的數量.
轉移圖結點與空間MBR關系表存儲轉移結點與其所在空間的MBR位置關系,分別記錄了指向B+樹中轉移結點的指針,以及結點位置在IR樹中所屬MBR的指針.
由于提出的索引結構為離線構建并存儲在磁盤中,索引建立的時間不會影響查詢效率,因此只需分析索引的空間代價.空間代價由3部分組成:第1部分為轉移圖結點的B+樹存儲,代價為|C|×nr×h,其中|C|為關鍵字類別數,nr為r簽名的列數,h為B+樹高度;第2部分為POI點的IR樹存儲,代價為|C|×(|P|-1)/(mR-1),其中mR為IR樹最大扇出,|P|為POI集合的大小;第3部分為圖結點與空間最小邊界矩形MBR的關系表,代價為NG×(|P|-1)/(mR-1),其中NG為轉移圖結點數.由于轉移圖結點數NG遠小于POI數|P|,則總的空間代價為O(|P|).
2.2 ROIR精確算法
基于所提出的索引結構,本文設計了一種過濾—提煉2階段精確查詢算法,如算法1所示.算法1在過濾階段利用上下界剪枝,過濾掉不可行解,減少對IR樹的訪問;在提煉階段采用best-first方式,優(yōu)先選擇高收益的解,從而提高算法查詢效率.
算法1.ROIR路線查詢精確算法Region.
輸入:QU(v0,C,r,L),由G和P建立的索引BIR;
輸出:收益最高的一條路線Ares.
①A={v0},A.last=v0,LIST={};
② for (A.last未訪問的鄰接點v)
③ if (dist(A.last,v)+A.L>L)
④ if (Mupper(A)>Mmaxlower(LIST))
⑤LIST=LIST∪A,更新
Mmaxlower(LIST);
⑥ 刪除上界分值小于Mlower(A)的路線;
⑦ end if
⑧ else
⑨A=A∪{v},A.last=v;
⑩DFS(Q,BIR,A);
算法1的過濾過程在擴展的B+樹上執(zhí)行如行①~所示.算法1遞歸調用算法2執(zhí)行深度優(yōu)先搜索,不斷擴展路徑長度,直到其滿足長度約束,返回一條候選路線并計算其上下界收益值.如果生成的候選路線A的上界得分高于候選列表中路線的下界得分,需要用路線A更新候選列表,實現對候選路線的剪枝(行③~⑦),更新方法的正確性由定理1及推論1,2保證.提煉階段在IR樹上執(zhí)行,如行~所示.初始計算LIST中的一條候選路線的精確收益值(行),然后用此路線精確收益對候選進行剪枝.若候選路線的精確得分高于當前最優(yōu)路線的得分,則用此路線更新最優(yōu)路線(行~).
算法2.DFS(Q,BIR,A).
① for (A.last未訪問的鄰接點v′)
② if (A.L ③A=A∪{v′},A.last=v′; ④DFS(Q,BIR,A); ⑤ else returnA; ⑥ end if ⑦ end for 定理1.已知2條路線A和A′,當A的下界收益值Mlower(A)大于A′上界收益值Mupper(A′)時,即Mupper(A′)≤Mlower(A),則可用A剪枝A′. 定理1說明了給定2條路線A和A′,當Mupper(A′)≤Mlower(A)時路線A的實際收益值一定大于路線A′的實際收益值,則可用A剪枝A′. 算法1定義了一個存儲候選路線集LIST,LIST中各候選路線應滿足性質1. 性質1.LIST中的任意候選路線的上界收益都大于所有其它候選路線的下界,其下界都小于所有其它候選路線的上界. 性質1說明當LIST用于返回一個具有最高收益的結果時,LIST中候選路線收益范圍是交疊的.為了便于算法剪枝,將LIST中的路線按下界收益值降序排列,將最大下界與最小下界收益值分別表示為Mmaxlower(LIST)與Mminlower(LIST).由性質1可以得出推論1與推論2,用于對候選路線的剪枝. 推論1.已知候選路線集LIST,對于任意一條新的候選路線A,若Mupper(A)≤Mmaxlower(LIST),則可以將A放棄. Fig. 4 The figure of routes in candidate set圖4 候選集路線示意圖 圖4(a)為推論1的情況示例,A1~A4是LIST中的候選路線,縱軸為收益值,分別含有上下界收益,Mlower(A1)即為Mmaxlower(LIST).A是新的候選路線,Mupper(A) 推論2.已知候選路線集LIST,對于任意一條新的候選路線A,滿足Mupper(A)>Mmaxlower(LIST),需要將A插入到LIST中.路線集LIST中任意路線A′,如果Mupper(A′)≤Mlower(A),則可將路線A′剪枝. 如圖4(b)所示,路線A的上界收益值大于A1的下界收益值,可插入到LIST中.然而,在候選路線集LIST中存在路線A2和A4,Mupper(A2)≤Mlower(A)及Mupper(A4)≤Mlower(A)時,A2和A4被剪枝.利用推論2實現對LIST剪枝見算法1行⑥. 在提煉階段,優(yōu)先選擇可能有較高精確收益值的候選路線,獲得的精確值有利于對剩余候選路線的剪枝,從而減少IR樹的訪問次數.因此,本文分別采用最大上界收益值優(yōu)先、最大下界收益值優(yōu)先、最大平均收益值優(yōu)先3種策略選取路線.實現時只需更改算法1的行即可.算法1中輸入C為空間關鍵字集合,當實際應用中需要考慮關鍵字訪問順序時,可以在算法的提煉階段中增加訪問順序作為過濾條件來實現. 通過分析可知,本文算法在過濾階段的復雜度級別與POI點序列路線查詢算法同為(mλ)n,在提煉階段,假設剪枝后的路線為x條,每條路線的結點數依舊為n,結點范圍內POI點的個數為n′,代價為n′xn,因此算法總代價為(mλ)n+n′xn,可表示為O((mλ)n).然而,由于算法過濾階段是在轉移圖上進行,圖中結點概要了底層POI點相關信息,因此顯著降低了n的大小,從而降低整個算法代價. 由于ROIR是一個NP難問題,為了有效地實現該查詢,提出了近似路線查詢算法.ROIR的近似查詢利用近似收益代替精確收益.路線Ares的近似收益值由式(4)計算: (4) 為了減少提煉過程的查詢代價,僅保留上層空間轉移圖用于查詢,由于轉移結點上不存儲精確的關鍵字收益值,僅在r簽名存儲固定區(qū)域內的關鍵字分值信息,查詢結果返回區(qū)間收益而不能得到精確收益值.本文采用近似的方法估計轉移結點在某關鍵字上的收益值,基本思想假定收益與圓周面積成正比,關鍵字近似收益如定義2. 定義2.r簽名關鍵字近似收益.已知轉移結點vj中某一關鍵字的下界與上界收益值分別為Si和Si+1,且ri (5) 數據組織模型只保留了上層轉移圖,對應的索引結構也只保留了擴展的B+樹,同時設計了新的簽名存儲于樹上的每個結點之中,索引結構命名為簽名B樹(balance tree with signature, BTS).以B+樹為基礎擴展了結點的信息,每個結點存儲3部分內容,包括鄰接表、r簽名和長度約束簽名(稱為L簽名).長度約束簽名存儲在轉移圖上,存儲以當前結點為起始點、長度為L約束下經過的所有結點關鍵字的最大收益值,且半徑L等間隔遞增.由于轉移圖上結點間的距離大于r簽名的半徑,因此被圓周包含的結點的關鍵字收益值由r簽名半徑最大一列的收益值表示. 定義3.L簽名關鍵字近似收益.已知轉移結點v在L簽名上某一關鍵字的下界與上界收益值分別為Si和Si+1,且Li (6) 定義4.路線預期收益.已知當前查詢路線A,在剩余長度約束L下路線訪問結點v時,路線預期收益為各個關鍵字已獲與可獲收益值之間的最大收益值之和,由查詢路線A得到各關鍵字已獲取的收益值,由結點v得到剩余長度下各關鍵字可獲取的收益值,如式(7)所示: Mexp_Q(A,v)= (7) 算法3是查詢一條近似路線的算法,當起始點的鄰接點未全部訪問時,每次優(yōu)先訪問收益最大的鄰接點v(行②③).若路線滿足長度約束,需要計算該路線的近似收益MQ(A′),并與候選路線A的近似收益MQ(A)進行比較,若當前路線的近似收益大于候選路線的近似收益,則當前路線是更優(yōu)的結果,需要對候選路線進行更新(行④~⑦);若不存在候選路線,當前路線是通過best-first方法搜索出的最優(yōu)路線,因此直接加入候選解中.每次比較候選路線后,需要將當前路線最后一個結點彈出并標記(行⑧⑨).當搜索長度小于約束條件時,將結點加入路線中并通過深度優(yōu)先搜索(DFS)過程獲取可行路線(行⑩~),與算法2類似.若路線當前結點的所有鄰接點都已經被訪問,將該結點從路線中刪除,直到起始點的鄰接點都被標記(行). 算法3.ROIR近似查詢算法r-RegionApprox. 輸入:QU(v0,C,r,L)、基于圖G建立的索引BTSG; 輸出:一條近似收益最高的路線A. ①A′={v0},A′.last=v0,A={}; ② while (A′不為空) ③ for (A′.last中未訪問的鄰接點v) ④ if (dist(A′.last,v)+A′.L≥L) ⑤ if (MQ(A′)>MQ(A)) ⑥A=A′; ⑦ end if ⑧vtag=A′.pop(),標記vtag; ⑨A′.last=A′.top(); ⑩ else 定理2.當一條路線A′訪問到結點v時,其預期收益值小于路線A的近似收益值時,即Mexp(A′,v) 證明.當Mexp(A′,v) 證畢. 本節(jié)提出的近似ROIR,利用面積近似的方法計算路線收益值,返回結果較優(yōu)的路線.采用近似的方法代替提煉過程,減少了訪問IR樹的I/O操作,加快了查詢效率. 定理3.近似路線查詢算法的收益近似率為1/ε. 證明.假設查詢結果Ares,滿足長度約束L,查詢半徑為r,查詢的關鍵字集合為C,Ares包含n個轉移結點,近似率為 (8) (9) (10) (11) 則存在 (12) 證畢. 本節(jié)對所提出的ROIR精確算法及近似算法進行實驗評估. 實驗采用北京市75 963條POI數據和北京市2012年10月、11月這2個月的出租車上下車數據.本文選擇了賓館、餐飲、大廈、商場、休閑娛樂等10個類別作為實驗數據的關鍵字. 實驗中類別的偏好值利用高斯函數賦值.以北京市天安門為中心,采用高斯分布為不同區(qū)域范圍內的POI點賦值,從二環(huán)以內到五環(huán)以外期望值分別為8.0~2.0,標準差為1.0~3.0.將用戶軌跡與近鄰POI進行匹配,利用軌跡的轉移關系生成轉移圖,通過設置區(qū)域間距大小及POI點的密度補充轉移圖中結點的數量.通過設置連通數的數量篩選軌跡,剪去流行度低的路線,利用長度限制剪枝結點間距離較遠的路線. 本文結合現有算法設計實現了2個基準算法的ROIR,利用3種優(yōu)化策略實現了相應的優(yōu)化算法,比較了這些算法的收益值及查詢效率,其中查詢效率用I/O次數度量.各算法如下. 1) BaseDFS.文獻[3]處理top-k空間多樣性問題,本文采用DFS實現了top-1路線查詢,作為比較算法,命名為BaseDFS.該算法在獲得轉移圖上候選路線后,以路線各轉移結點為中心,查詢范圍r內POI序列是否符合查詢結果. 2) BaseRegion.利用文獻[1]中過濾—提煉查詢2階段方式實現,實現無r簽名優(yōu)化的空間興趣區(qū)域路線查詢算法,在過濾階段返回所有候選路線集,在提煉階段求得路線精確收益值并選取收益值高的路線返回. 3) Region.本文提出的ROIR算法,該算法利用r簽名在過濾階段采用上下界收益值剪枝方法獲取候選路線集,在提煉階段遍歷IR樹比較求得最優(yōu)路線,見算法1. 4) RegionLow,RegionUp,RegionAvg.這3個算法是在Region算法基礎上采用下界收益值優(yōu)先策略所實現的算法.算法在提煉階段分別按候選路線的下界收益值、上界收益值、上下界收益值的均值從大到小次序訪問IR樹,對收益值進行精確計算并剪枝求得最終結果. 3.2.1 路線收益比較 本節(jié)比較了在長度和關鍵字數量變化的情況下,BaseDFS算法和Region算法的收益值. 圖5(a)比較了長度約束對路線收益的影響,給定關鍵字約束{賓館,餐館,商場,商務中心,娛樂},各算法隨著長度的增長,收益均呈上升趨勢.其中,BaseDFS算法的收益值最低,Region算法的收益值最高.在r從200~800 m變化時,r越小,收益值越趨向于BaseDFS算法收益值;r越大,收益值趨向于800-Region算法收益值.隨著長度增長,查詢返回一條路線所包含的轉移結點增多,算法收益值也會增大.BaseDFS算法返回的是POI點組成的序列路線,Region算法返回的是區(qū)域組成的路線,增大了解空間,收益值高于BaseDFS算法的收益值.另外,隨著區(qū)域半徑r的增大,區(qū)內包含的POI數量不斷增多,算法整體收益值的差距較小. Fig. 5 Profit comparisons of the exact algorithms圖5 精確算法收益比較 圖5(b)比較了關鍵字數量對路線收益的影響,給定起始點,路線長度約束L=10 km,各算法的收益值均隨著關鍵字數量的增多而增大.對于BaseDFS算法,每個POI點僅包含一個關鍵字,路線收益值來源局限于單個POI點;而Region算法利用區(qū)域對象代替點對象,區(qū)域中包含不同關鍵字的數量增多,使得一個區(qū)域可以提供多個關鍵字的收益值.因此當區(qū)域半徑越小,涵蓋的POI點越少,則收益越小,區(qū)域半徑越大,則收益越大. Fig. 6 Effects of different constraints on algorithms efficiency圖6 不同約束條件對算法效率的影響 Region算法在各類約束條件下,由于利用區(qū)域的方式擴展了POI點的數量,因此較BaseDFS算法能夠獲取更高的收益值.圖5也驗證了Region算法在路線收益值方面的優(yōu)越性. 3.2.2 算法效率比較 圖6是不同約束條件對算法效率的影響比較,算法效率由I/O次數度量,I/O次數越少,算法效率越高.圖6(a)~(c)分別為長度約束、區(qū)域半徑、關鍵字數量對算法效率的影響.圖6(b)中當區(qū)域半徑大于300 m時,BaseDFS算法由于其代價過高無法完成路線搜索.結果顯示本文設計的優(yōu)化算法效率均高于基本算法的效率,對比BaseDFS算法,優(yōu)化算法利用興趣區(qū)域減少了訪問結點的數量;對比BaseRegion算法,本文算法設計了簽名信息用于剪枝路線,減少了候選路線的數量.結果顯示,RegionUp算法效率高于RegionAvg,RegionLow算法效率. 對于近似路線查詢算法,本節(jié)將BaseDFS算法、BaseRegion算法、Region算法和RegionUp算法作為比較算法,比較算法的收益值及效率.RegionApprox是本文提出的算法,見算法3. 1) 近似路線收益比較 本節(jié)比較了長度及關鍵字數量變化情況下BaseDFS,Region,RegionApprox算法的收益,如圖7所示,關鍵字為{賓館,餐館,商場,商務中心,娛樂},長度約束L=10 km,半徑r=200 m. Fig. 7 Profit comparisons of approximate algorithms圖7 近似算法收益比較 圖7(a)是長度約束下的路線收益比較,結果顯示長度越長,路線收益越大.Region算法的收益值最高,RegionApprox算法的收益值接近Region算法的收益,BaseDFS算法的收益值最低.圖7(b)是不同關鍵字數量下的路線收益比較,結果顯示關鍵字數量的增多會使得收益值增大,收益值由大到小排序分別是Region,RegionApprox,BaseDFS算法. Fig. 8 Efficiency comparisons of approximate algorithm圖8 近似算法效率比較 2) 近似算法效率比較 本節(jié)比較了長度約束L、區(qū)域半徑r及關鍵字數量|C|的變化下,BaseDFS,BaseRegion,RegionUp,RegionApprox算法的總I/O讀取次數,如圖8所示.默認設置長度約束L=10 km,半徑r=200 m,關鍵字為{賓館,餐館,商場,商務中心,娛樂}.由圖8(a)~(c)表明算法的總I/O讀取次數均隨約束條件的變化呈上升趨勢,且RegionApprox算法的效率最高. RegionApprox算法利用B+樹中簽名的近似收益值作為解,只保留了過濾階段的操作而不再執(zhí)行提煉階段的操作,減少了轉移圖上結點在IR樹中的I/O次數. 本節(jié)介紹空間關鍵字查詢、偏好路線查詢等相關工作. 空間關鍵字查詢返回滿足文本約束與空間位置要求的結果,文本約束以關鍵字集合表示[11-12].空間關鍵字查詢可分為POI對象查詢[13-14]、組對象查詢[15-16]、區(qū)域查詢等[17-21].其中,POI對象查詢返回單個POI對象滿足查詢關鍵字需求,包括滿足關鍵字集且距離最近的k個對象的布爾kNN查詢、返回前k個最佳對象的top-k查詢、返回布爾關鍵字表達式且位于指定空間區(qū)域的布爾范圍查詢.空間關鍵字組對象查詢指一組對象符合共同查詢關鍵的需求.空間關鍵字區(qū)域查詢返回一個矩形或圓形區(qū)域,其中包含最多的給定查詢關鍵字[17-18]、區(qū)域中的關鍵字集合與查詢關鍵字集合具有最高的文本相似度[20]. 本文所提出ROIR與現有的空間關鍵字區(qū)域查詢均查找與輸入查詢關鍵字集相關的空間區(qū)域.然而,本文提出的查詢返回多個區(qū)域組成的路線,具有路線規(guī)劃功能. 偏好路線查詢提供用戶個性化的路線搜索服務,可以分為AOP(arc orienteering problem)問題[22-23]、POI及關鍵字覆蓋路線問題[5-6,24-25]、關鍵字優(yōu)化路線問題[2,7]. 在AOP問題中,結點上存儲收益值,邊表示代價(如距離成本),查詢的目標是獲取給定代價約束下最大化結點收益和的路線.ROIR與AOP均為在一定代價約束下最大化路線收益.區(qū)別在于,AOP路線由POI序列組成,ROIR路線由興趣區(qū)域序列組成. POI及關鍵字覆蓋路線查詢的目的是獲取由POI組成的路線,返回路線上的POI所包含的關鍵字覆蓋了指定關鍵字,或者關鍵字滿足一定的關系約束下同時最小化時間或距離代價.其中,文獻[25]研究了關鍵字覆蓋情況下top-k路線多樣性問題.文獻[5]搜索與用戶提供的線索最匹配的路徑,線索由用戶提供的關鍵字間的關系表示.文獻[6]提出了關鍵字訪問序列約束的路線查詢. 關鍵字優(yōu)化路線問題將路線長度作為約束條件,最大化關鍵字收益或關鍵字相似度.其中,文獻[1]提出了關鍵字敏感的路線查詢,查詢的目標是找到一條覆蓋一組用戶指定的查詢關鍵字并最大化給定成本預算內的目標得分.文獻[4]考慮查詢對象不同關鍵字的權重,提出了一個基于關鍵字得分的路線優(yōu)化問題.文獻[2]提出一個距離成本約束下的路線查詢,用于檢索與用戶指定關鍵字集最相關的路徑.文獻[7]提出興趣路徑查詢問題,尋找收集最多查詢關鍵字數量的最優(yōu)路線. 與文獻[2,7]相似,本文提出的ROIR屬于空間關鍵字的偏好路線查詢.現有的空間關鍵字偏好路線查詢返回的路線由POI點組成,而ROIR搜索由興趣區(qū)域組成的路線. 本文提出了一種面向空間興趣區(qū)域的路線查詢,將傳統(tǒng)空間關鍵字路線查詢的POI對象擴展為空間興趣區(qū)域,提高了路線查詢的適用性.設計了2層數據模型及相應的索引結構,設計了過濾與提煉2階段算法的精確算法,以及高效的近似查詢算法.通過詳細的分析,驗證了所提出方法的有效性.提出的ROIR可以廣泛應用于興趣路線規(guī)劃,特別適用于結伴出行情況,允許用戶在區(qū)域內分散訪問各自偏好的地點. 作者貢獻聲明:劉俊嶺負責問題定義、算法的提出及全文的撰寫;劉柏何負責算法的實現與實驗對比;鄒鑫源負責算法設計與實驗對比分析;孫煥良參與實驗數據的收集與論文的修改.
2.3 ROIR近似算法
















3 實驗分析
3.1 數據集
3.2 精確查詢算法比較

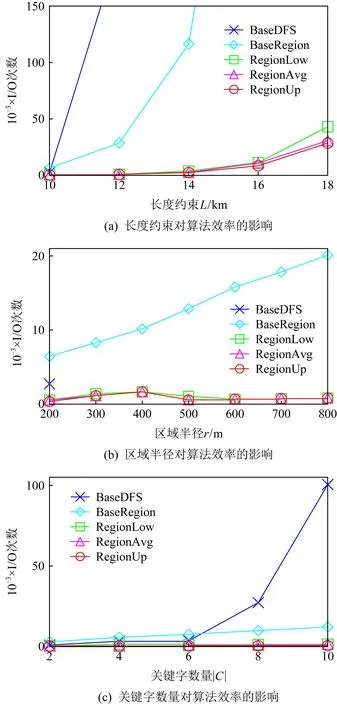
3.3 近似路線查詢算法比較


4 相關工作
4.1 空間關鍵字查詢
4.2 偏好路線查詢
5 結 論
猜你喜歡
發(fā)明與創(chuàng)新·小學生(2021年3期)2021-03-25 11:48:49科學(2020年5期)2020-11-26 08:19:22軟件(2020年3期)2020-04-20 01:45:18商周刊(2018年15期)2018-07-27 01:41:20敦煌學輯刊(2018年1期)2018-07-09 05:46:42北京教育·普教版(2017年1期)2017-02-05 13:26:23新疆農墾科技(2016年2期)2016-08-21 13:50:16中國科技博覽(2016年2期)2016-04-25 20:32:39小學生導刊(2016年34期)2016-04-11 00:49:44新疆財經大學學報(2015年3期)2015-12-10 03:49:15
