一種結合用戶適合度和課程搭配度的在線課程推薦方法
2022-11-12 11:28:48胡園園姜文君任德盛
計算機研究與發展 2022年11期
胡園園 姜文君 任德盛 張 吉
1(湖南大學信息科學與工程學院 長沙 410082) 2(之江實驗室 杭州 310012)
隨著互聯網技術的快速發展,社會對教育重視程度的提高以及經濟水平的不斷增長,在線教育行業得到了前所未有的發展[1].與傳統教育相比,在線教育突破了時間和空間的限制,降低了學生的時間成本和經濟成本.根據iiMedia Research(艾媒咨詢)數據顯示,2020年第1季度中國在線教育用戶規模已達3.09億人,市場規模達4 538億元[2].“互聯網+教育”[3]的形式使得在線教育用戶規模擴大,同時用戶對在線教育的認同度和接受度也在不斷提升.但與此同時,各種各樣的在線課程大量涌現,可供選擇的課程種類越來越多.面對如此眾多的選擇,用戶想要從中挑選優質并且適合自己的課程非常困難.因此,個性化課程推薦[4]應運而生.課程推薦算法通過研究用戶的選課興趣、歷史選課行為、課程的屬性等,向用戶推薦其可能感興趣的課程,從而有效緩解信息過載問題,提升用戶的選課效率和在線體驗.
課程推薦是在線教育平臺中一個關鍵環節.有效的課程推薦不僅可以提高用戶聽課率和滿意度,而且能夠促進在線課程銷售,提高平臺收入.課程推薦的關鍵在于精準定位每個用戶的學習目標和學習需求,找到最適合用戶的課程.已有的課程推薦方法大多基于相似用戶或者相似課程,通過構造用戶評分矩陣進行推薦.一些研究[5]提出將課程前提關系嵌入神經注意力網絡的算法來實現課程推薦,還有一些工作[6]通過研究用戶的個性化潛在學習偏好來提高課程推薦的性能.但是,已有課程推薦方法很少關注用戶能力與課程的適合度,可能會推薦用戶感興趣但學不會、不合適的課程;也較少考慮候選課程與用戶已學課程的搭配程度,可能產生相似課程重復推薦或不當推薦.因此,有效的在線課程推薦需要同時關注不同用戶的個性化學習特征(用戶適合度)和不同課程之間的關聯(課程搭配度).
本文通過研究用戶的各種在線學習行為和習慣,如注冊課程、觀看課程等,探究用戶的學習特征和學習適合度;同時,深入挖掘不同課程之間的關聯關系,探索不同課程之間的可搭配度;最后,融合用戶適合度和課程搭配度,提出改進的協同過濾模型來給用戶推薦課程,提高推薦性能.本文試圖采用簡單易行的方法實現更合適的課程推薦,同時保證較強的可解釋性.總體來說,本文主要貢獻有3個方面:
1) 深入研究用戶的學習特征,分析用戶學習成績特征分布和課程之間的關系,探究用戶對不同課程的適合度.
2) 挖掘不同課程之間的關聯,并基于關聯來評估課程之間的搭配度.
3) 提出了一種結合用戶適合度和課程搭配度的課程推薦模型(user-suitability and course-matching aware course recommendation model, SMCR).該模型根據用戶適合度和課程搭配度得到最終推薦列表,實現更合適的top-k課程推薦.
1 相關工作
本文主要與學習成績預測和課程推薦相關.
1.1 學習成績預測相關技術
Su等人[7]提出了一種新的回歸神經網絡框架,通過雙向長短期記憶(long short-term memory, LSTM)模型學習做題序列和題目信息,并加入自注意力機制來預測得分.Sweeney等人[8]根據學生歷史成績和相關課程資料,提出了一種混合矩陣分解(matrix factorization)和隨機森林(random forest)的方法預測學生成績.Wang等人[9]分析了不同學習行為和學習效果之間的關聯,提出了因果關系關聯分析算法.He等人[10]提出了基于正則邏輯回歸的2種轉移學習算法LR-SEQ(sequentially smoothed logistic regression)和LR-SIM(simultaneously smoothed logistic regression)來預測用戶學習情況.Dhanalakshmi等人[11]使用基于機器學習技術的有效意見挖掘和排名方法分析學生成績.
目前課程推薦和學習成績預測的相關工作通常都是分開獨立進行的.而本文通過考慮用戶可能的課程成績或完成度來得到其對某一課程的學習適合度,并基于此幫助用戶選擇更適合其能力或需求的課程.
1.2 課程推薦相關技術
Jing等人[12]提出了一種基于內容的算法框架,將用戶興趣和課程前提條件關系結合起來,并通過協同過濾進行課程推薦.Apaza等人[13]提出了一種基于大學生歷史成績的課程推薦系統,并使用LDA(latent Dirichlet allocation)主題模型從課程內容中提取相關主題.Ibrahim等人[14]提出了一種基于本體的混合過濾系統框架,結合協同過濾和基于內容的過濾為用戶提供個性化課程建議.Farzan等人[15]研究了學生未來職業目標并為學生提供與其職業目標相關的課程建議.Jiang等人[16]提出了一種基于目標的課程推薦算法,根據用戶已經學會的知識模型為其推薦合適的一系列相關的課程.Zhang等人[17]提出一種分層強化學習算法,用以修改用戶個人資料,并且能夠根據修訂后的個人資料調整課程推薦模型.Parameswaran等人[18]為學生推薦既滿足其課程修讀要求又符合其學習興趣的課程.Aher等人[19]結合聚類技術和關聯規則算法來為剛學習某些課程的新學生推薦課程.
整體來說,已有的學習預測和課程推薦方法主要基于用戶和課程之間的交互信息進行模型設計,但是通常忽略了用戶的學習適合度和課程之間的搭配度,可能導致課程推薦準確性低或者學習效果不佳.基于上述調研和分析,本文結合用戶適合度和課程搭配度來綜合得到課程的推薦度.
2 問題定義及整體方案和數據描述
本節首先給出關鍵概念,然后給出形式化的問題描述,最后簡要介紹本文的解決方案.本文用到的符號如表1所示:

Table 1 Symbol Table表1 符號表
2.1 相關概念
定義1.用戶適合度.用戶適合度表示某用戶對于某課程的學習適合程度.
定義2.課程搭配度.課程搭配度表示2個課程可以進行搭配的程度.
定義3.課程推薦度.課程推薦度表示該課程值得推薦的程度.根據定義1和定義2中的學生適合度和課程搭配度,將二者結合起來,按照一定的方式進行綜合計算.
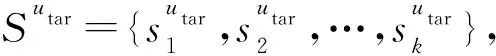
2.2 方案概述
本文解決方案主要包括3個模塊,如圖1所示.
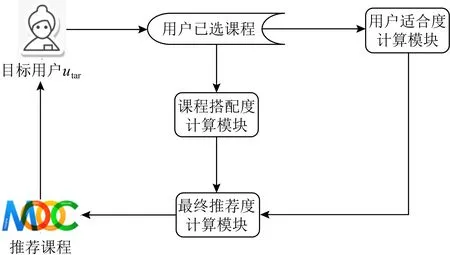
Fig. 1 The overall framework of the SMCR model圖1 SMCR模型整體框架
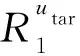
模塊2.課程搭配度計算模塊.通過挖掘課程之間的關聯關系,計算出課程之間的搭配度.4.2節將介紹該模塊的詳細內容.
模塊3.最終推薦度計算模塊.將上述2個步驟中得到的用戶適合度和課程搭配度按照一定比例進行結合得到最終推薦度,并根據該推薦度實現課程top-k推薦.4.3節將介紹該模塊的詳細內容.
2.3 數據集及預處理
本文使用2個在線學習平臺的數據集來探索用戶適合度和課程搭配度.一個是CN(canvas network)數據集[20],包含了Canvas Network開放課程平臺2014年1月至2015年9月的學習記錄,包含每個用戶的選課記錄及相關課程屬性.另一個是學堂在線平臺公開的中國大學MOOC(massive open online courses)學習數據[21],其中包括學生id、第1次注冊課程的時間、課程id等屬性.具體統計信息如表2所示:
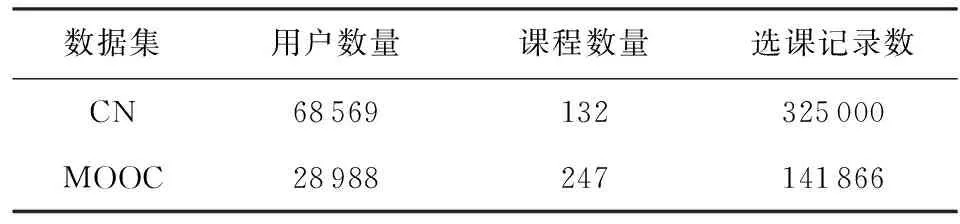
Table 2 Introduction of Dataset表2 數據集介紹
CN數據集還包含了課程類別信息,如表3所示:
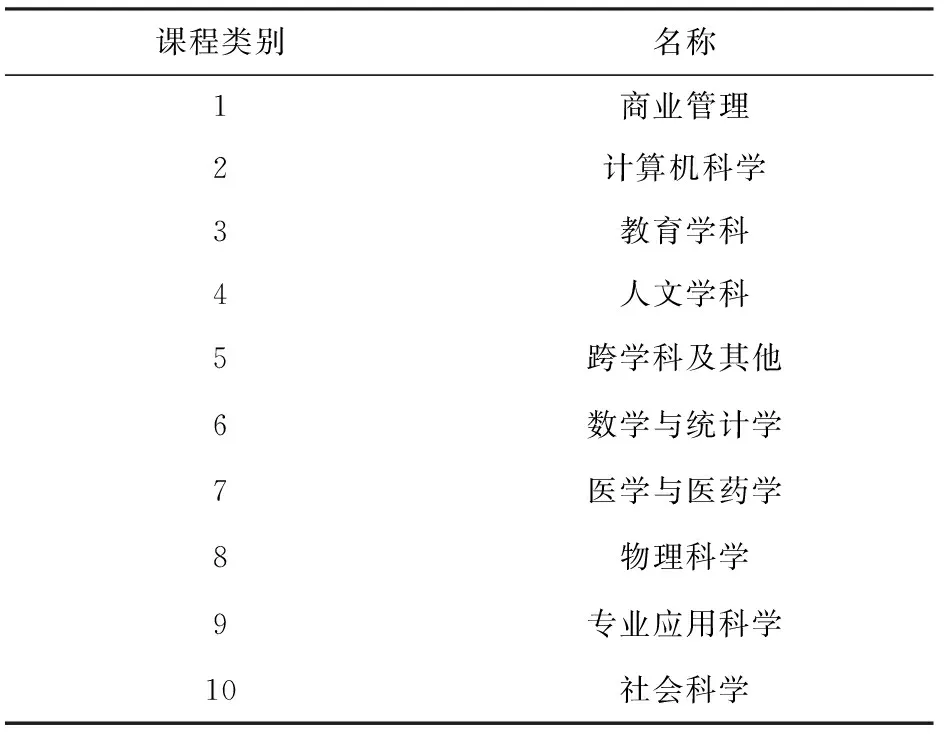
Table 3 Different Category Names of Courses on CN Dataset表3 CN數據集上不同課程類別名稱
在進行分析和實驗之前,需要對數據集進行預處理,包括清除數據集中成績為空值的記錄,并去除重復值.同時,需要過濾掉僅選1門課程的用戶.另外,數據集中的成績進行了歸一化處理,即成績分布在[0,1]范圍內.
3 數據分析
本節主要分析用戶的不同學習行為和學習類型,探究用戶的學習需求;研究用戶適合度和課程成績之間的關系,分析了課程成績對課程推薦的影響.這些分析可以幫助了解用戶的學習意圖,同時能夠提高課程推薦的準確性.
3.1 用戶學習類型分析
首先統計在線學習平臺中用戶歷史所學課程的類別分布,來判斷其學習類型.圖2展示了CN數據集上2個典型用戶的課程類別分布.
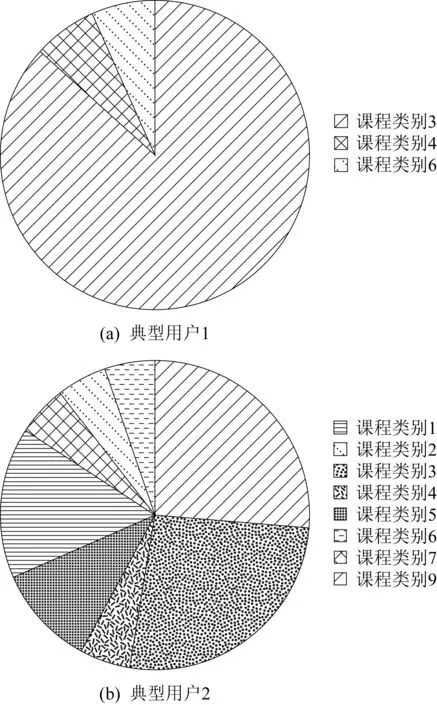
Fig. 2 Course selection for two typical users on CN dataset圖2 CN數據集上2個典型用戶的課程選擇情況
圖2(a)中用戶選擇的主要課程所屬類別為教育學科,課程類別為人文學科和數學與統計學所占比較少,說明該用戶更重視專業課的學習,更專注于教育學科類別的課程學習.圖2(b)中用戶所選課程的類別比較豐富,說明該學生的課程興趣分布較為廣泛,課外興趣比較濃厚.
接著,統計數據集中用戶的學習狀態,如圖3所示.圖3(a)展示了用戶學習狀態的分布情況.可以看到,學習類型為積極型的用戶數量最多,其次是學習類型為被動型的用戶數量,說明大多數用戶有著明顯的學習者類型區分,有積極型的,也有消極型的.
圖3(b)表示的是用戶1周中希望學習的時間分布.從圖3(b)中可以看到,每周學習2~4 h是大多數用戶希望的學習時長,其次是每周1~2 h和每周4~6 h.這說明大多數用戶都有比較積極的學習行為,希望學習時長分布也符合實際情況.
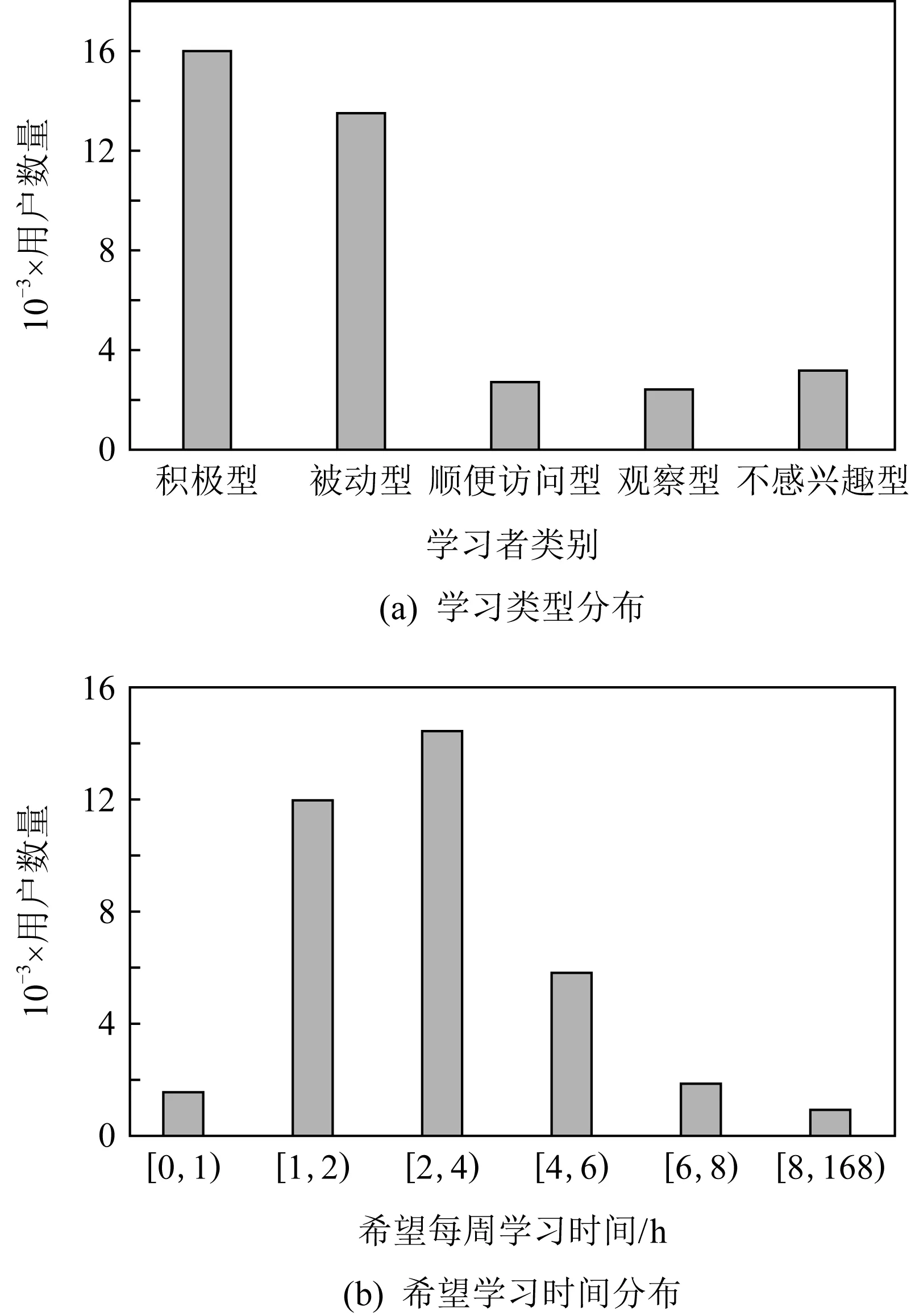
Fig. 3 Course selection for different types of users on CN dataset圖3 CN數據集上不同類型用戶的課程選擇
圖4表示的是CN數據集中每個類別的選課人數分布.從圖4可以看到,不同類別的課程選課人數是不同的,其中選擇“專業應用科學”類別的選課人數是最多的,其次是選擇“人文學科”和“教育學科”類的人數.圖5表示的是MOOC數據集中所有課程的選課人數分布.大多數課程的選課人數都在500~1 000之間.圖4和圖5表明不同類別或者不同課程的選課人數是有差別的.
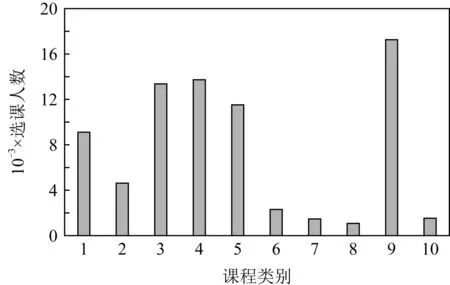
Fig. 4 Number of users for different categories of courses on CN dataset圖4 CN數據集上不同類別課程的選課人數
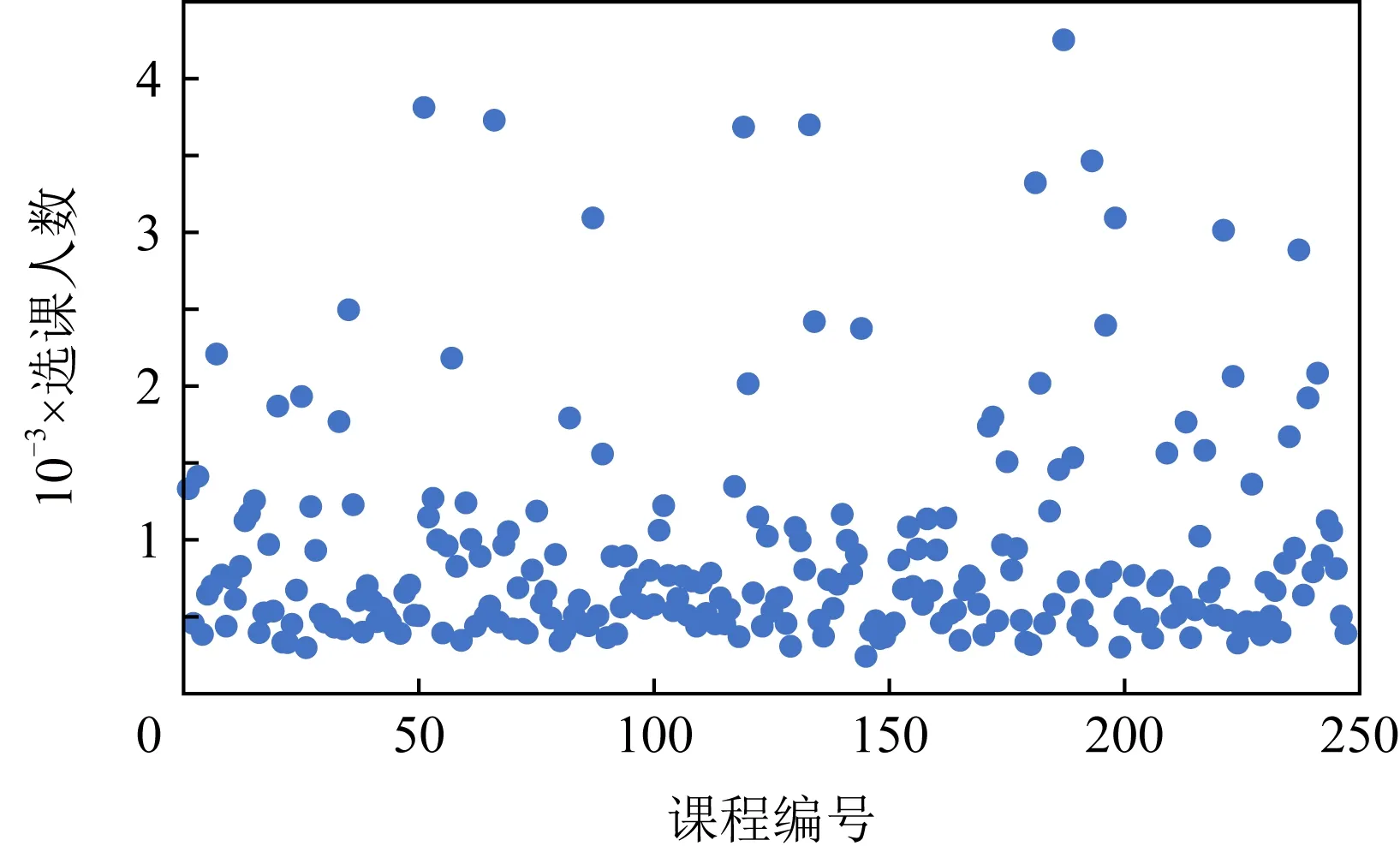
Fig. 5 Number of users for different courses on MOOC dataset圖5 MOOC數據集上不同課程的選課人數
3.2 用戶適合度分析
一般來說,用戶學習適合自己的課程通常應該得到較高的成績.因此,本文主要根據成績來分析用戶對不同課程的適合度.分別從課程類別、單個用戶的平均課程成績等方面對用戶的所選課程成績進行分布統計,挖掘用戶適合度的相關因素和影響.
圖6展示了CN數據集中不同類別課程的成績分布情況.圖6(a)展示了每個課程類別的平均成績分布.不同類別的課程平均成績各不相同,說明課程成績與課程所屬類別有關.其中,類別為“人文學科”的課程平均成績是最高的.
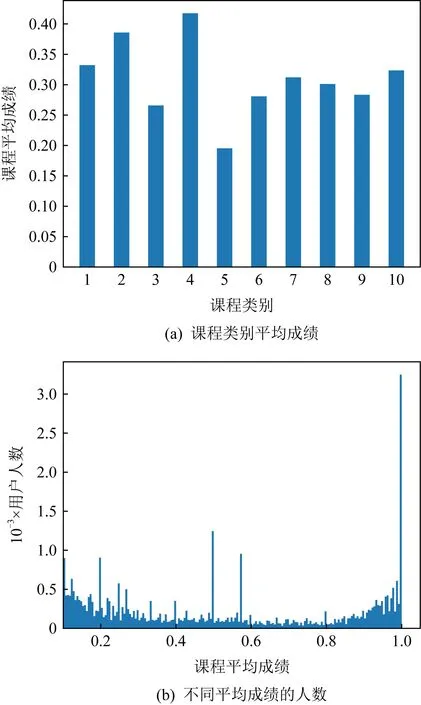
Fig. 6 Average grades by course category and user number distribution of average grades on CN dataset圖6 CN數據集上各類課程平均成績及用戶平均 成績人數分布
圖6(b)表示的是關于不同課程平均成績的人數分布.這表明每個平均成績分布段的人數頻率.每個平均成績段的人數主要集中于500人以下,這說明用戶的平均學習成績分布范圍較為廣泛,不同學生因適合程度、努力程度等的不同,所得到的學習成績也相應不同.
圖7展示了CN數據集中不同成績段的用戶“觀看”和“交互”所有不同課程的人數分布情況.圖7(a)是不同課程成績段分布的用戶觀看該課程的人數.其中,“觀看”行為的值為1表示用戶與課程的互動,即觀看課程視頻;而“觀看”行為的值為0表示用戶與該課程并未有互動.從圖7(a)中可以看到,隨著課程成績的提高,觀看課程視頻和未觀看課程視頻的人數比值在不斷上升,這表明觀看課程視頻對于取得較高成績有一定的促進作用.另外,成績在0~0.2的用戶數量最多,表明在線課程的完成率整體偏低.這也從側面反映了考慮用戶適合度對在線課程推薦具有非常重要的意義.
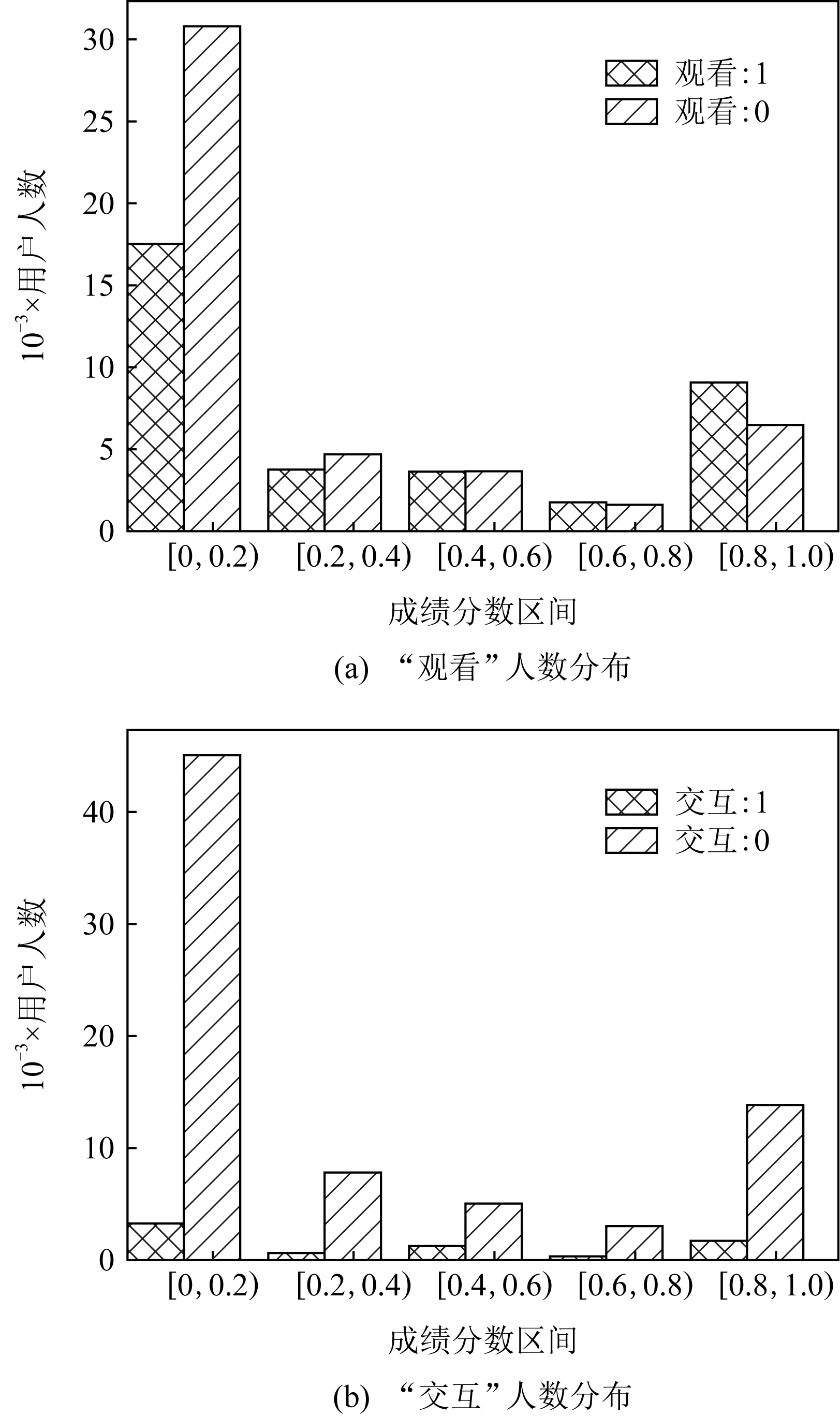
Fig. 7 Number of “viewed” and “explored” users in different grades on CN dataset圖7 CN數據集上不同成績段“觀看”和“交互”人數
圖7(b)展示了“交互”屬性與用戶課程成績之間的關系,“1”表示用戶與該門課程有交互行為,而“0”表示用戶與該課程沒有交互.從圖7(b)中可以看到,在每個成績段,沒有進行課程交互的人數要大于進行了課程交互活動的總人數.該現象再次反映了很多用戶對在線課程的學習投入不夠,整體參與度較低.因此需要改進課程推薦,考慮用戶適合度,從而有望提升用戶參與度.
圖8(a)和圖8(b)分別表示MOOC數據集中不同課程的輟學率分布情況以及用戶的輟學率整體分布統計.在該數據集中,是否輟學統一由0和1來表示.可以看到,大多數課程的輟學率集中分布于0.7~0.9之間.而對于用戶來說,輟學率在0.8~1區間的人數最多.該數據分析結果表明,現有在線學習平臺的整體學習情況亟待改善,而本文考慮通過用戶適合度來改進課程推薦就是為此目的.
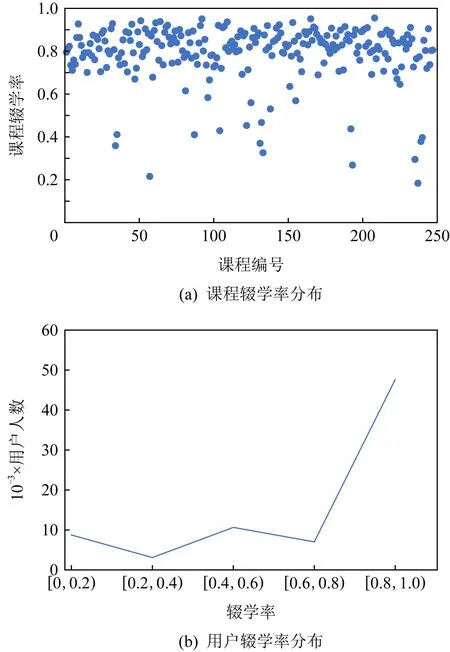
Fig. 8 Distribution of dropout rate for courses and users on MOOC dataset圖8 MOOC數據集上課程輟學率和用戶輟學率分布
3.3 課程搭配度分析
一般來說,不同課程之間是有關聯關系的,不同課程之間的搭配關系也是不同的.因此,需要根據課程之間的關聯關系來分析不同課程之間的搭配度.
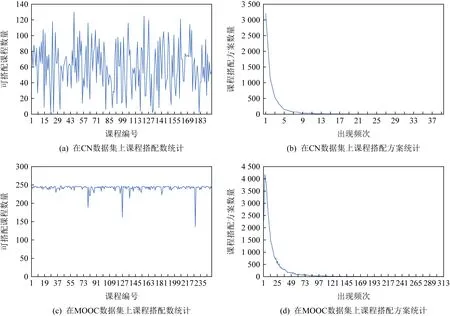
Fig. 9 Number of courses and collocation statistics圖9 課程搭配統計
圖9(a)展示了CN數據集每門課程可搭配的課程數量.從圖9(a)中可以看到,每門課程可以實現搭配的課程數量在0~120之間,這說明不是所有課程之間都可以進行搭配.同時,圖9(a)中也顯示有少數課程可以實現的搭配課程數量較多,可能該課程為基礎課程或者科普類課程,說明學習該課程的人數比較多,課程比較受歡迎.
圖9(b)展示了CN數據集課程搭配方案的頻率分布情況.將2個可以進行搭配的課程看作是一個課程搭配方案,圖9(b)統計了每個課程搭配方案出現的次數.根據統計結果,大多數課程搭配方案出現的次數較少,基本都在10次以下.這表明相當多的課程搭配方案出現頻率都不太高,說明在線用戶選課具有較強的自主性和一定的隨意性.正因為如此,合適的課程推薦需要考慮候選課程與用戶已學課程之間的搭配性,因為并不是任意2個課程之間都可以實現搭配.
圖9(c)展示了MOOC數據集中每門課程可搭配的課程數量.從圖9(c)中可以看到,每個課程可搭配的課程數量主要分布在200~250之間,比圖9(a)中每門課程可搭配的課程數量要多.
圖9(d)展示了MOOC數據集中課程搭配方案的頻率統計分布.可以看到,大多數課程搭配方案出現的次數都在50以下.該數據集較CN數據集的可搭配課程數量更多.
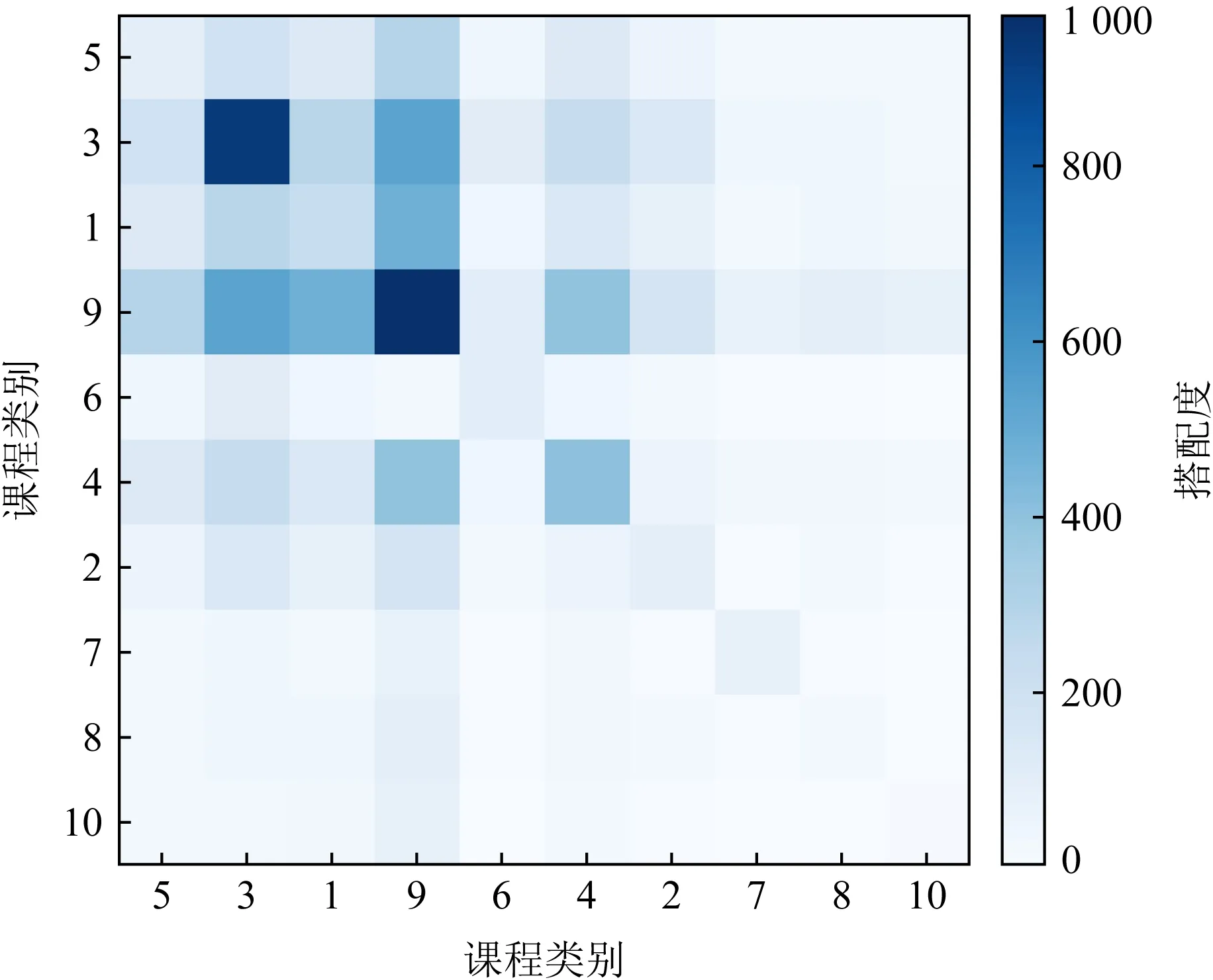
Fig. 10 Statistics of collocation courses between two categories on CN dataset圖10 CN數據集上2個類別之間的可搭配課程統計
圖10展示了CN數據集中2個類別之間的可搭配課程統計.顏色越深,表示這2個類別之間可以搭配的課程數比較多,類別的課程搭配度較高;顏色越淺,則表示這2個類別之間的可搭配課程較少,類別的課程搭配度較低.可以看到,一般情況下,屬于同一類別的2個課程之間可搭配度較高,不同類別的2個課程之間可搭配度相對較低.但也有一些類別與其他多個類別課程的搭配度都較高,比如類別9.
3.4 總 結
從3.1~3.3節的數據分析發現:
1) 不同用戶的學習類型不同;學習成績能夠反映用戶對課程的學習適合度.一般來說,用戶某門課程的成績越高,表明用戶對該課程的適合度就越高.很多用戶對在線課程的學習投入較少,課程完成度較低.因此需要改進課程推薦,考慮用戶適合度,從而有望提升用戶參與度,改進在線學習效果.
2) 課程之間是有一定關聯關系的.每門課程的可搭配課程數是不同的;并不是任何2門課程都可以進行搭配;相同類別的2門課程之間可以進行搭配的可能性較高.另外,在線用戶選課具有較強的自主性和一定的隨意性.因此,合適的課程推薦需要考慮候選課程與用戶已學課程之間的搭配性,從而提升課程推薦的效果.
4 基于用戶適合度和課程搭配度的推薦方法
本文提出了一種結合用戶適合度和課程搭配度的課程推薦模型SMCR,該模型主要由2個部分組成:一是通過用戶-課程相似度矩陣和已學課程成績,計算用戶對候選課程的適合度;二是挖掘課程搭配頻繁項集,計算課程之間的搭配度.將這2部分融合起來,形成最后的課程推薦.
4.1 計算用戶適合度
本文使用基于物品的協同過濾思想來計算用戶對課程的適合,這是一種基于最近鄰的推薦算法,主要基于如下現象:用戶傾向于喜歡與其歷史行為記錄相似的物品.在推薦系統中,該算法通過計算物品之間的相似性,從而給用戶推薦與其歷史最接近的物品.但該算法未考慮候選產品是否真正適合用戶,本文對此進行了改進.本文首先計算課程之間的相似度,然后基于相似度和已學課程成績計算目標用戶對候選課程的適合度.
1) 根據目標用戶utar的學習行為,構建用戶-課程學習成績矩陣.利用基于物品的協同過濾推薦算法,計算目標用戶utar的已選課程ci與未選課程cj之間的相似度W(ci,cj).計算公式為
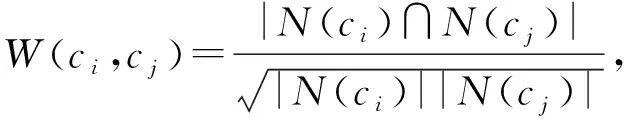
(1)
其中,N(ci)和N(cj)分別表示選擇了課程ci和課程cj的用戶集合.
2) 根據相似度選出與目標用戶utar已選課程集合中每一門課程相似的前l個課程,作為候選課程.計算目標用戶utar對于候選課程列表中每一個候選課程cj的適合度P(utar,cj).找出與候選課程cj相似的已選課程,根據目標用戶在這些課程中的成績來衡量其對候選課程cj的課程適合度.P(utar,cj)計算為
(2)
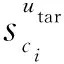
4.2 計算課程搭配度
本文使用關聯規則來計算任意2個課程之間的搭配度.基本思想是:頻繁被用戶共同選擇的課程通常是有較高的搭配度[22].例如,同時選擇學習《C語言》和《數據結構》的用戶比同時選擇學習《C語言》和《西方經濟學》的用戶要多,即已學習《C語言》的用戶更傾向于選擇《數據結構》,而不是《西方經濟學》,因此《C語言》與《數據結構》的搭配度更高.本文首先計算2個課程同時出現的概率(即支持度),篩選出支持度高于設定閾值的所有候選課程對;然后,計算其置信度作為課程之間的搭配度.具體如下.
關聯規則是描述數據集中數據項之間存在的內在關系的規則.一般來說,關聯規則的挖掘主要分為2個步驟:1)找出目標數據集中所有的頻繁項集;2)利用這些頻繁模式產生符合條件的關聯規則.本文主要通過FP-growth算法來挖掘課程之間的關聯規則,該算法通過構建一個“FP樹”來存儲數據集中的所有數據,并且從中挖掘出數據集中存在的頻繁項集或者頻繁項對.
首先,通過FP-growth算法挖掘所有課程中頻繁共同被選的課程對,構造課程與課程之間的搭配.搭配度大小可以通過支持度和置信度衡量.將用戶同時選擇課程ci和課程cj的情況看成一個搭配課程對,該課程對出現的頻率即支持度support(ci,cj),篩選出支持度高于一定閾值的所有候選課程對.支持度計算為
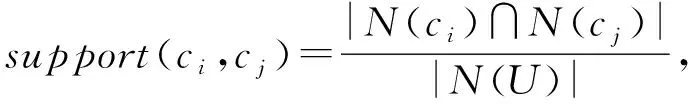
(3)
其中,|N(ci)∩N(cj)|表示同時選擇課程ci和課程cj的用戶數量,|N(U)|表示數據集中進行了選課行為的所有用戶數量.
然后,對每一個候選課程對計算其課程搭配度.具體來說,確定課程cj在包含課程ci的課程對中出現的頻繁程度,也就是在已經選擇課程ci的條件下選擇cj的概率;反之亦然.搭配度計算為
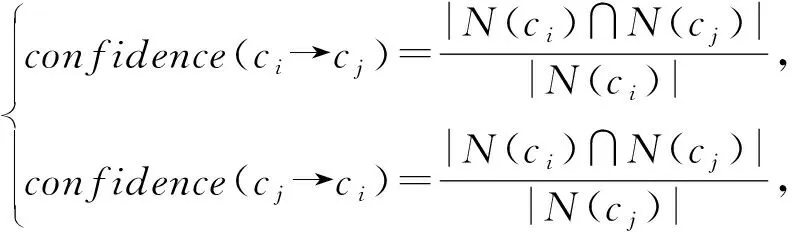
(4)
(5)
根據2個搭配的課程支持度及其置信度構建課程搭配庫,將Q(ci,cj)看作2個課程之間的搭配度.
4.3 計算最終推薦度
本文結合4.1節中的用戶適合度和4.2節中的課程搭配度,最終得到課程推薦度.通過課程推薦度最終決定給目標用戶推薦的課程.
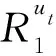
Rec(cj)=w1×P+w2×Q,
(6)
其中,w1和w2分別為用戶適合度和課程搭配度的權重系數,取值在[0,1]范圍內,且二者之和為1.本文根據總課程推薦度Rec(cj)對候選課程進行排序,選取前k個課程,實現top-k推薦.
本文SMCR模型通過用戶適合度和課程搭配度改進了已有方法僅考慮相似度可能導致不當推薦的問題,并且具有較強的可解釋性.比如,可以把推薦課程cj的用戶適合度和課程搭配度作為推薦的解釋.
5 實驗與結果分析
本節將在2個數據集CN和MOOC中,通過對比實驗來驗證本文SMCR課程推薦模型的效果,并對模型參數敏感度進行測試.
本實驗的評價指標主要有3個:準確率Precision、召回率Recall和綜合指標F1_score.
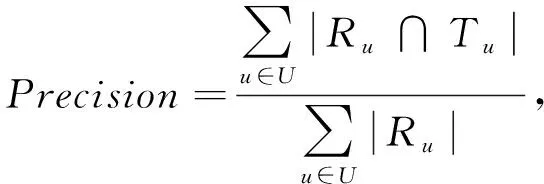
(7)
(8)
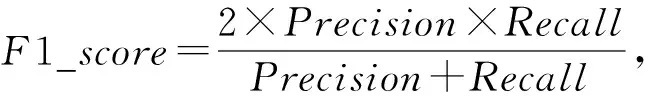
(9)
其中Ru表示課程推薦列表中所推薦的課程樣本的個數,Tu表示不同的用戶所選擇的學習課程樣本的個數.
5.1 對比方法
為了驗證所提出的方法效果,本文選定了其他5種推薦方法作為基線,即UserCF,ItemCF,LFM,BPR,MPR,簡介如下:
1) UserCF[23](user based collaborative filtering).基于用戶的協同過濾算法.該算法給目標用戶推薦相似用戶所選的課程.
2) ItemCF[24](item based collaborative filtering).基于物品的協同過濾算法.該算法給目標用戶推薦與其所選課程相似的課程.
3) LFM[25](latent factor model).隱語義模型算法.該算法先對所有的課程進行分類,再根據用戶的興趣分類給用戶推薦該分類中的課程.
4) BPR[26](Bayesian personalized ranking).貝葉斯個性化排序算法.根據隱式反饋將給用戶推薦的商品按照個性化偏好進行排序.
5) MPR[27](multiple pairwise ranking).多重成對排名算法.該算法通過進一步挖掘具有多個成對排名標準的項目之間的聯系,從而放寬了BPR算法中的簡單成對偏好假設.
6) SMCR.本文所提結合用戶適合度和課程搭配度的課程推薦模型.同時考慮用戶對課程的適合度和課程之間的搭配度,并將課程按照推薦度進行排序推薦.
5.2 對比實驗結果及分析
本文SMCR及5種基線方法在CN數據集和MOOC數據集上的top-k推薦性能分別如表4和表5所示.其中,k=2.本文也進一步測試了不同k值時的對比結果,如圖11和圖12所示.
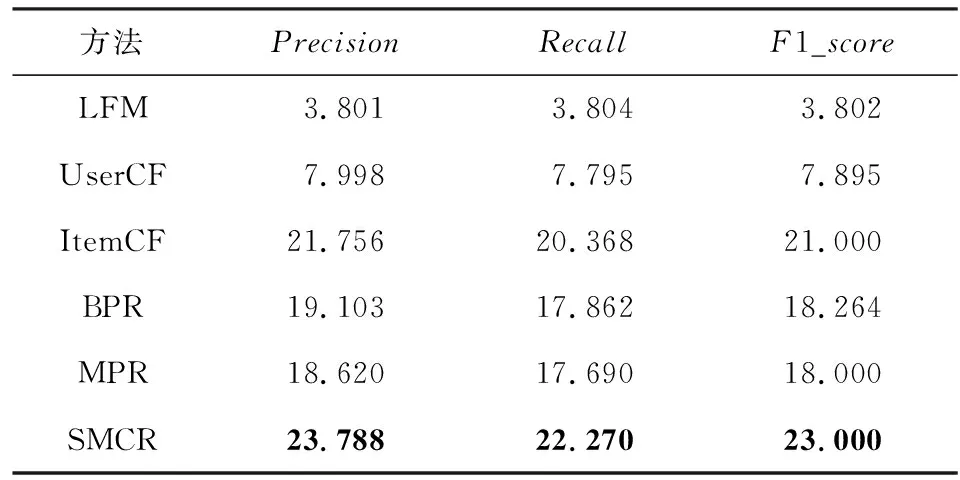
Table 4 Comparison of Experimental Results on CN Dataset表4 CN數據集上的對比實驗結果 %
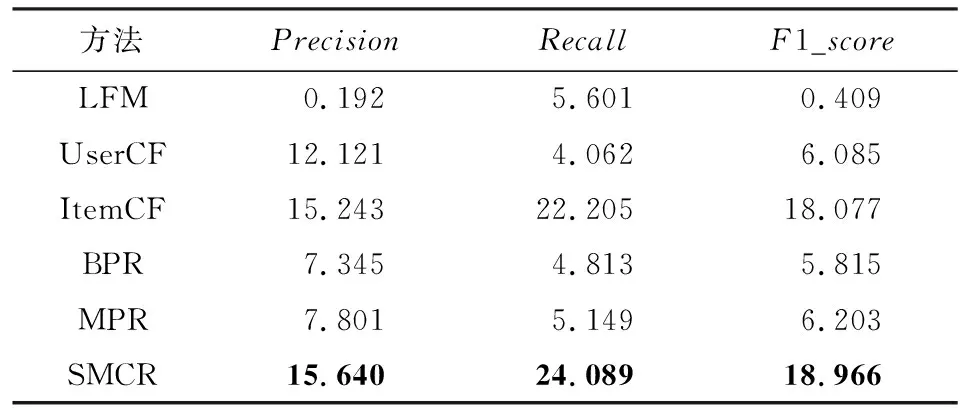
Table 5 Comparison of Experimental Results on MOOC Dataset表5 MOOC數據集上的對比實驗結果 %
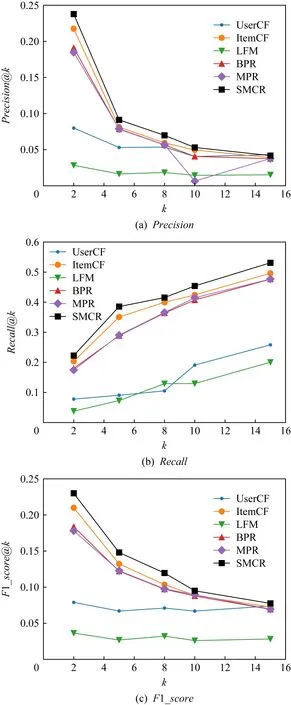
Fig. 11 Comparison of experimental results under different k on CN dataset圖11 CN數據集上不同k值時的對比實驗結果
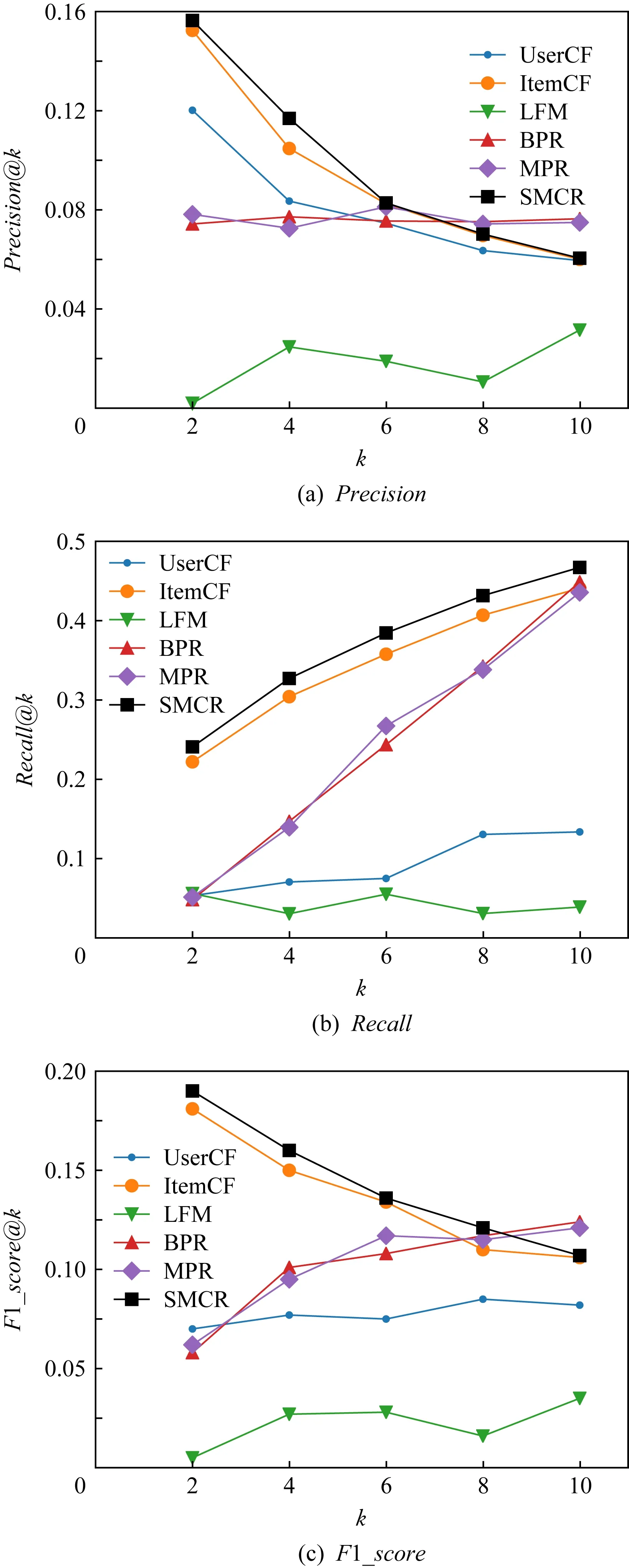
Fig. 12 Comparison of experimental results under different k on MOOC dataset圖12 MOOC數據集上不同k值時的對比實驗結果
5.2.1 準確性對比
如表4和表5所示,相對5種基線方法,本文SMCR表現最好,ItemCF次之.
表4展示了在CN數據集上進行的對比實驗結果.在Precision指標上,SMCR比ItemCF提升了大約2.03%,比BPR提升了大約4.69%,比MPR提升了大約5.17%.在Recall指標上,SMCR比ItemCF提升了大約1.9%,比BPR提升了大約4.41%,比MPR提升了大約4.58%.對表4的分析表明,同時考慮適合度和搭配度能夠有效提高推薦準確性.
表5展示了在MOOC數據集上的對比結果.與其他5種基線方法相比,SMCR在指標Precision,Recall,F1_score上的表現效果均最大.例如在指標Precision上,SMCR比ItemCF提升了大約0.4%,在指標Recall上,SMCR比ItemCF提升了大約1.88%.
SMCR的性能相對其他方法更優的原因是其同時考慮了用戶和課程之間的適合度以及課程之間的搭配度,而其他方法僅從整體上考慮用戶和課程之間的關聯關系,如相似歷史課程.此外,SMCR在CN數據集上的表現比在MOOC數據集上的表現更好,可能的原因是CN數據集上用戶的歷史行為記錄更多,從而能夠幫助更好地挖掘課程之間的搭配關系.
除性能提升之外,本文SMCR相對其他方法更能產生適合用戶學習特征的課程推薦.
5.2.2 不同k值的對比
本文課程推薦使用了top-k推薦.在實際的在線學習平臺中,每個用戶所選課程的數量各不相同.因此實際的top-k推薦列表大小,即k值,與用戶所選課程數量有關.
5種基線方法及本文SMCR在CN數據集和MOOC數據集上的推薦性能Precision@k,Recall@k,F1_score@k隨k值的變化情況如圖11和圖12所示,圖11中k∈{2,5,8,10,15},圖12中k∈{2,4,6,8,10}.從圖11(a)和圖12(a)中可以看到,本文中所提出的SMCR的Precision@k值隨著k值的增加逐漸降低,當k=10時,該方法Precision趨于穩定.當k<10時,SMCR的推薦準確率相比其他基線方法具有不同程度的提升.當k=2時,圖11(a)顯示SMCR比ItemCF提升了大約2.03%,圖12(a)顯示SMCR比ItemCF提升了大約0.40%.
從圖11(b)和圖12(b)中可以看到,方法推薦結果的召回率Recall@k值會隨著推薦個數的增加而增加.這是因為當給用戶的課程推薦個數增大時,方法推薦結果會包含更多符合用戶偏好的課程.當k=2時,圖11(b)顯示SMCR在CN數據集上的推薦結果的召回率較對比方法有明顯的提升,提升了大約1.90%,圖12(b)顯示SMCR在MOOC數據集上的召回率比ItemCF提升了大約1.88%.
圖11(c)和圖12(c)展示了F1_score@k值的變化情況.當k=2時,從圖11(c)中可以看到,SMCR較ItemCF提升了大約2.00%;從圖12(c)可以看到,SMCR較ItemCF提升了大約0.89%.
綜上,當k=2時,SMCR方法的整體推薦效果是最佳的.這說明本文所提出的方法較傳統協同過濾方法考慮到了課程之間的關聯搭配關系,向目標用戶推薦更符合其偏好的課程.從圖11來看,當k<4時,SMCR在CN數據集上的準確率小于BPR和MPR,但是召回率大于BPR和MPR,從整體性能來看,其F1_score要大于BPR和MPR,說明與這2個方法相比,SMCR在整體上獲得了更好的推薦性能.
5.3 參數敏感度測試
5.3.1k的敏感度測試
本節測試參數k對推薦性能的影響.由于數據集本身具有稀疏性,部分用戶只有1個選課記錄,會對top-k推薦結果產生影響.因此,需要從原有數據集中選取那些選課記錄超過2個的用戶并構建新數據集.
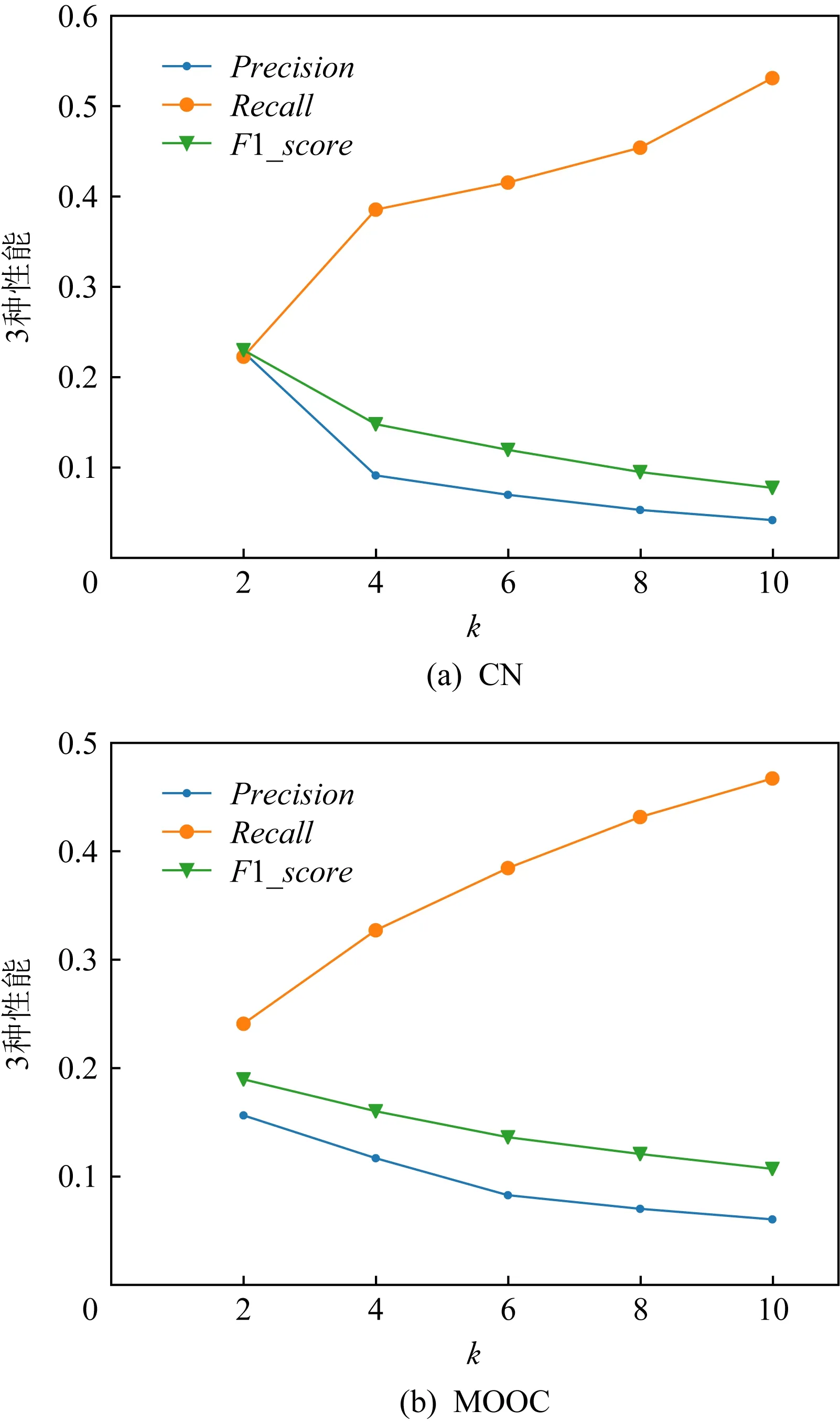
Fig. 13 Performance under different k on two datasets圖13 2種數據集上不同k值時的性能
如圖13所示,準確率隨著k值的增大而減小.這是因為在本文所使用的數據集中,每個用戶選擇學習的平均課程數為2.5,學習的課程序列較小.但是召回率隨著k值的增大而增大,這是因為算法推薦的課程數量越多,就越容易命中真實選課情況.
5.3.2w1和w2的敏感度測試
本文的課程總推薦度是由用戶適合度P和課程搭配度Q加權而成的.為了判斷這2個量的不同組合對推薦結果的影響,本文在2個數據集CN和MOOC上,對用戶適合度和課程搭配度的權重,即w1和w2的不同組合效果進行了實驗,結果如圖14所示:
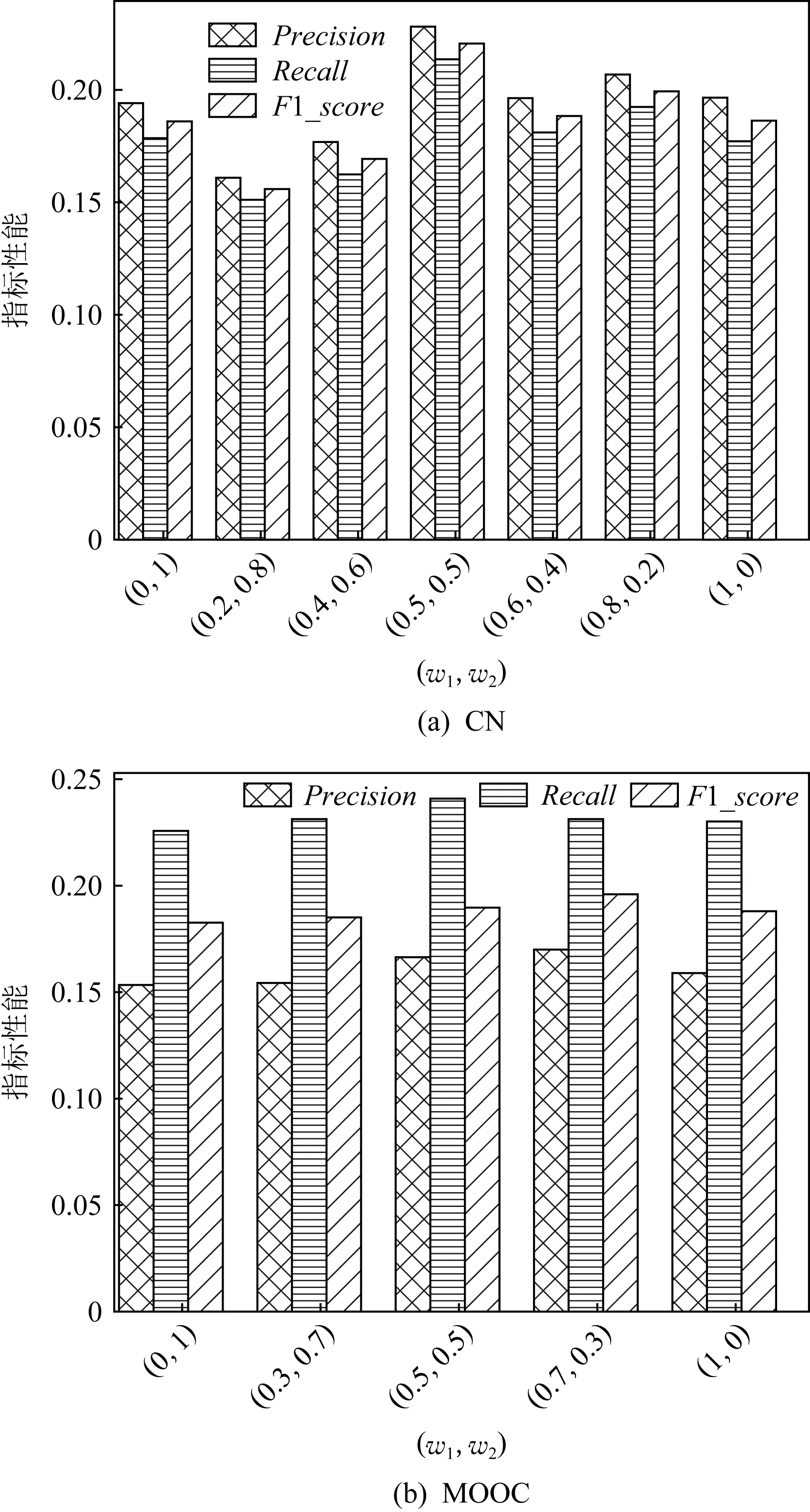
Fig. 14 Performance under different weights of w1 and w2圖14 不同權重w1和w2時的性能
從圖14(a)中可以看到,在CN數據集上,當w1=0.5,w2=0.5時,SMCR的Precision,Recall,F1_score值均達到最大.說明該數據集中用戶適合度和課程搭配度具有基本相同的重要性.
從圖14(b)中可以看到,在MOOC數據集上,當w1=0.7,w2=0.3時綜合實驗效果即F1_score最好.說明該數據集中用戶適合度具有更大的重要性.
在最佳權重參數之外,用戶適合度和課程推薦度的任意一個權重增大,都會導致準確率或召回率的降低.這說明,針對不同數據集需要深入分析用戶適合度和課程推薦度的不同作用,準確地把握二者權重,以便做出更加準確的推薦.
6 總 結
本文通過結合用戶適合度和課程搭配度為用戶推薦合適的課程.本文提出的SMCR模型能夠向用戶推薦既適合其學習又與其已學課程可以進行搭配的課程.與其他方法相比,本文全面考慮了用戶適合度和課程搭配度2個方面,能夠避免僅依賴相似度的傳統推薦方法產生的相似課程重復推薦或不當推薦(比如推薦的課程太難)問題.本文使用簡單易行的方法達到較好的效果,并具有較強的可解釋性.在未來的工作中,我們希望能夠更多地挖掘課程之間的內在關聯,從上下文信息中提取出關鍵信息來實現更準確的課程推薦.同時,我們還考慮將知識圖譜[28]引入課程推薦中,以達到更好的課程推薦效果.
作者貢獻聲明:胡園園負責論文撰寫與修改、數據分析、方法設計和實驗;姜文君負責確定創新點、改進數據、設計實驗和全文寫作;任德盛負責論文整體思想的討論與改進;張吉負責論文數據分析和實驗的改進.
猜你喜歡
內蒙古教育(2021年20期)2021-03-08 01:09:14
計算機教育(2020年5期)2020-07-24 08:53:38
家庭影院技術(2019年11期)2019-12-09 09:14:30
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
創業家(2015年5期)2015-02-27 07:53:25
