經典圖像快速匹配算法比較分析研究
2022-10-17 02:02:40王堅
攀枝花學院學報 2022年5期
王 堅
(遼寧對外經貿學院,遼寧 大連 116000)
圖像匹配即是應用某種特殊的邏輯運算和數學方法在兩幅圖片之間尋找共同點[1]。圖像匹配的研究工作很早就在國外開始了,70年代的美國為了軍事的需要開啟了關于圖像匹配的研究工作,主要是針對武器的飛行導航功能[2]。我國研究起步雖然比較晚,但是也有不少新的突破。其一,是圖像匹配過程中特征提取算法的改進,包括SIFT檢測算法、CNN算法、KNN算法和AKAZE算法等。其二,是聯合算法的設計與實現,例如多尺度PCA-HOG聯合技術提高算法的運行速度[3];KNN與RANSAC相結合改變抽樣規格與匹配模式,提高算法的魯棒性[4]。其三,是快速匹配算法的開發,例如基于改進SURF的快速匹配算法,與傳統算法相比提高30%的運行效率[5]。本文以灰度圖像為研究對象,分別比較常用的灰度圖像匹配的算法、改進的灰度圖像匹配的算法(序貫相似性算法)和局部灰度編碼算法在圖像快速匹配中的性能,為圖像匹配算法的開發提供理論基礎。
1 數字圖像匹配技術概述
1.1 基于模板法的圖像匹配方法
模板匹配是指通過尺寸更小的圖像模板與源圖像進行比較分析。想要確定模板是否與源圖像有相同或相似的區,則需要求出相似區域的位置和坐標,然后提取圖像。模板匹配的步驟如圖1所示。基于模板法的圖像匹配算法有許多,比較常見的主要包括誤差平方和算法(SSD)和基于誤差平方和的序貫相似性檢測算法(SSDA)。
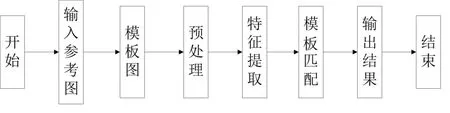
圖1 模板算法流程圖
1.1.1 誤差平方和算法(SSD)[6]
誤差平方和算法主要是通過求解模板圖像與源圖像相似區域的誤差平和進行圖像的匹配。假設f(x,y)為M×N的源圖像,t(j,k)為J×K(J≤M,K≤N)的模板圖像,則誤差平方和測度定義為:
(1)
由上式展開可得:
(2)
(3)
(4)
(5)
其中,DS(x,y)稱為源圖像中與模板對應區域的能量,其大小與像素的位置有關。DST(x,y)為模板與源圖像對應區域的互相關性。DT(x,y)為模板的能量。
1.1.2 基于誤差平方和的序貫相似性檢測算法(SSDA)
序貫相似性檢測算法是對傳統模板匹配算法的改進,增加了閾值參數。SSDA算法定義絕對誤差[7]:
(6)
其中,帶有上劃線的分別表示子圖、模板的均值:
(7)
(8)
實際上,絕對誤差就是子圖與模板圖各自去掉其均值后,對應位置差的絕對值,然后設定閾值Th;在模板圖中隨機選取不重復的像素點,計算與當前子圖的絕對誤差,將誤差累加,當誤差累加值超過了Th時,記下累加次數H,所有子圖的累加次數H用一個表R(i,j)來表示。SSDA檢測定義為:
(9)
1.2 基于改進的模板圖像匹配快速算法
整個圖像被劃分成k×k處的大小和非重疊正方形中,然后對圖像進行分塊,如果我們把圖像分割以后剩下的部分數量不是k的倍數,則底部和剩余行的最右邊、列切割。R-塊中,R,S(Ri)的R-塊表示像素Ri的灰度值和。塊R-附近的組成(圖2b),D-Block的定義和其周圍的八個塊相鄰的R(圖2a:R1,R2,R3,R4,R6,R7,R8,R9示出);將R-塊的鄰域分為4個部分,分別為D1,D2,D3,D4(如圖2b),稱為R-塊的D-鄰域;R-塊R5分別屬于4個D鄰域,即D1=R1∪R2∪R4∪R5;D2=R4∪R5∪R7∪R8;D3=R5∪R6∪R8∪R9;D4=R2∪R3∪R5∪R6。
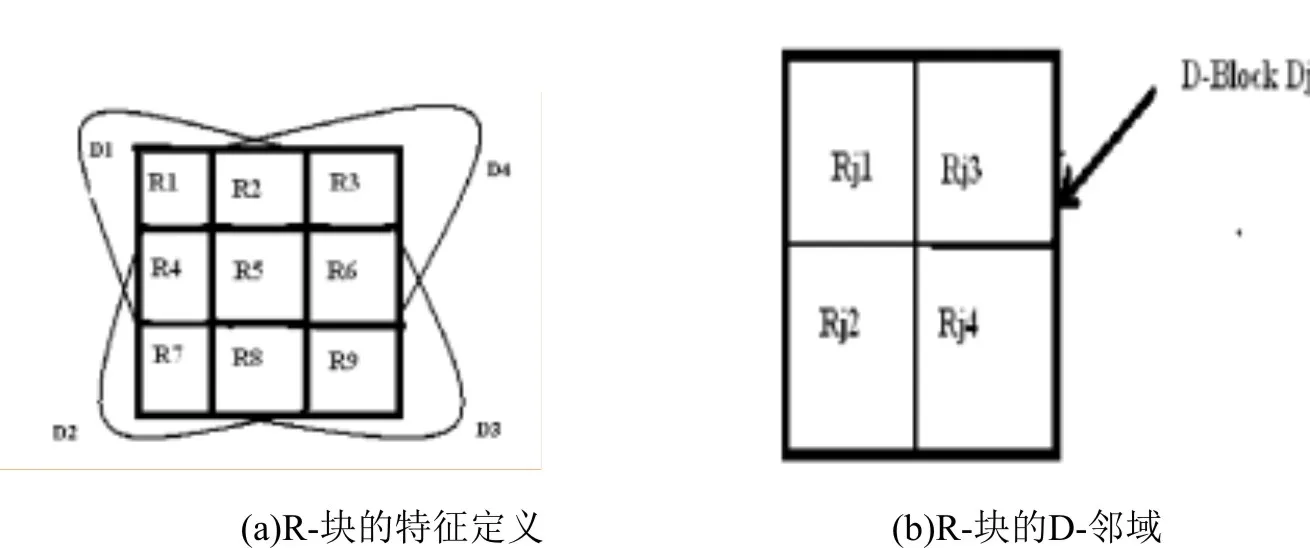
圖2 圖像劃分
對每一個D-R-附近的四大模塊,需要一個序列(圖2的逆時針順序)像素對Dj灰度總值進行表示。包括:S(Rj1)、S(Rj2)、S(Rj3)、S(Rj4)共有24(4!)種可能;可以用五位二進制代碼來表示。稱作P(Dj)∈{00000,00001,L10111}來表示。這樣的24種就是所謂的對應的位置關系,它們有24種,如果采取對D塊內扭轉(逆序)R-4塊。其中每個對應于灰度排序之間的位置關系,我們可以進行編碼再固定,當然,我們也可以使用序列。將R-塊Ri所在的4個D-塊的P(Dj)做位串并接得到:F(Ri)=P(D1)P(D2)P(D3)P(D4),接著對4個(Dj)具體操作是:F(Ri)=(P(D1)<<15)+(P(D2)<<10)+(P(D3)<<5)+P(D4)。其中P(Dj)是Rj鄰域Dj的二進制碼,后面的數字表示移位。2F(Ri)是塊20的二進制編碼的表示,稱為塊編碼。通過上述簡單的推論可以得知,Ri編碼塊的類型可有244種,但是F(Ri)表示位置的關系應該在相鄰的八領域塊的灰度和(R-塊Rj之間)排布。當D1中塊之間的位置關系被確定,以及灰度值總值被確后,D2和D4塊之間的關系(總值灰度)就不可能24種,是12種。R4和R5再加上R2和R5倆對關系已經很明顯的,所以D3只有六個可能的種類,雖然我們做了這么多的簡化推論,看起來少了不少種類,但是仍然要計算至少24*12*12*6=20736種,導致了計算量仍然不小,因此在計算整幅圖像的時候出現的重碼的概率應該是非常低的,這也是種方法的準確性的體現。此外,該編碼方法反映了灰度圖像的灰度相對值。所以,相對穩定的灰度值也使得計算少了許多干擾,抗噪聲能力很強。用k的選擇粒度的大小可以改變圖像處理的大小,方便在不同的噪聲情況下對象圖像進行處理。
用搜索圖S搜索以模板T的長度、寬度水平、垂直步長為標準。從左上方以T的大小分割至S稱為限制塊C(i,j))。由它開始,其中(i,j)為限制塊左上角頂點在搜索圖S上的坐標。這種劃分之后,如果我們還可以在右側或底部搜索到S的沒有被覆蓋的部分,那么我們就可以從相應起始位置的最右側向S的左側搜索,或從底部開始重新劃分成塊或限制線,使得全部限制塊可以完全覆蓋搜索圖S。限制塊C(i,j))和T是N×N模板圖像的尺寸,其中,每個組可用塊R-矩陣A(C(i,j))與A(T)表示已知特征編碼矩陣,其中K是一個側R-塊的邊長。比較A(C(i,j))和A(T)的每個元素相同的行號列號,記錄行列號。和分形編碼檢索中遇到的問題一樣,也是在兩圖中很顯然的問題,就是說怎么對準R-塊。我們來看(圖3a)是模板圖的陰影部分和搜索圖和圖S的模板T匹配。然而,在對模板T和搜索圖S進行塊R分割后,就沒有兩者之間的相同的R-塊了,這是R-塊就不能很好的表示兩幅圖像的局部相似度了,匹配率將受到不同程度的影響。因此,有必要對模板T做合適的剪切,在圖中移除陰影部分。如(圖3b),剩余的子區域可被配置為如圖3c中,然后圖3b中的右下側4個R塊對齊。
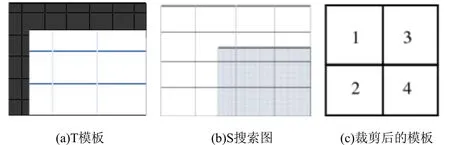
圖3 S搜索示意圖
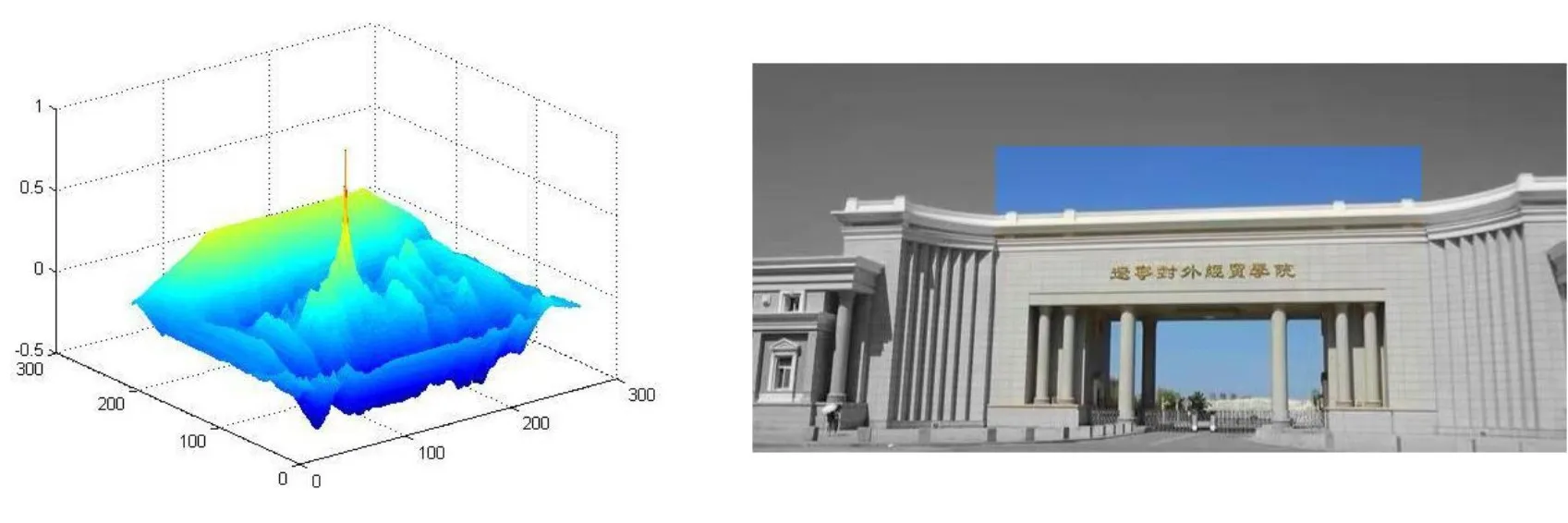
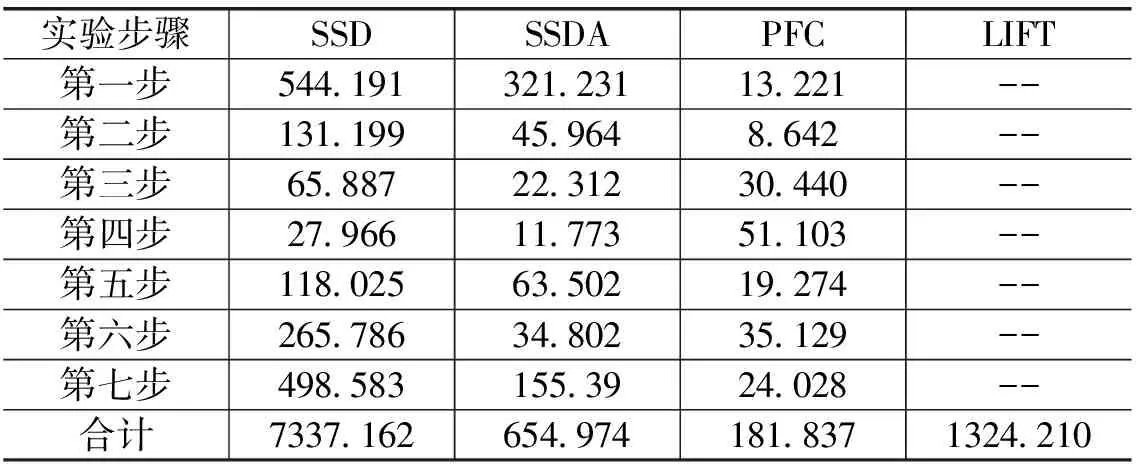
在為了實現圖R-塊對齊的模板T和S中的特征匹配,模板T可正確切割,在模板圖T的行x、列y被切割(0 ph,j.right=Dright+k (10) ph,j.left=Dleft-Tx,y-D.width-k (11) 其中左,右,寬度,分別是矩形的左和右邊緣坐標和寬度。由以上可以得出我們在進行局部灰度編碼算法匹配時候的步驟為:對樣本模板T與做K2次剪切,并計算T(x,y)的特性;計算出基于搜索圖S所有的R-塊的特征;以C(i,j))確定搜索圖S大小(圖S的最右面或最低部有很大的可能被限制快重影);對于每塊限制C(i,j))的模塊,包含在R塊排序的特征編碼矩陣A(C(i,j)),再對模板T的K2剪切后的有序特征集做有序比較。發現限制塊C(i,j))與裁剪模板T(x,y)的最相似的特性;重新有序比較對C(i,j))與模板T(x,y)的特征值。用兩個一維數組linecolL來表示累計矩陣A(C(i,j))各行、列的特征比較結果;求得限制塊C(i,j))內匹配子區域D的邊界,需要對linecolL數組做邊緣檢測濾波;求出模板T在搜索圖S中匹配的參考點。由D與限制塊C(i,j))的相對位置關系與裁剪情況T(x,y)得出。 以網絡上下載的遼寧對外經貿學院的正門圖像(簡稱“ZM”)做為實驗對象。第一步,輸入源圖像讀出兩個圖像ZM1和ZM0,如圖4。以這兩個圖像為匹配的模板。 圖4 從Matlab中提取目標文件 第二步:選取ZM0/ZM1中的各一個區域,定義新的名稱。(選取的圖像區域要事先選定好,不能太過偏離圖像特征區域,以免實驗的匹配效果不佳)顯示選中的區域圖像。第三步,在兩幅圖像中進行歸一化互相關計算。就是比較匹配圖像和待匹配圖像之間的互相關點,然后確定互相關點的峰值;最后確定待匹配圖像在匹配圖像的位置,但該計算能更直接的顯示圖像特征點。通過Matlab軟件顯示一個三維的峰值圖像,找到圖像最佳匹配點,特征點結果如圖5所示。 圖5 相似度比較峰值-特征點 圖6 圖像匹配結果 第四步,確定圖像最大匹配點,繼續進行圖像的線性預算,為后續的圖像匹配做準備。第五步,繼續為最后的圖像匹配做準備。在圖像內提取區域,找出區域屬于源圖像的哪部分,提取出區域和原圖像進行比較。第六步,為防止圖像匹配中可能出現圖像的不規則,圖像傾斜或者畸變,導致進行圖像匹配時間延遲。先定義一個零矩陣,把圖像定義在一個黑色的背景下,方便圖像的匹配,使圖像在匹配中可以以點的形式一點點匹配,防止圖像在匹配后出現的畸變,省去匹配后的校正過程。第七步,先是圖像的灰度處理,然后設計結果顯示。把彩色圖像匹配到灰色圖像中,結果如圖6所示。 誤差平方和算法的優點,計算簡單,易學易用;缺點是計算量比較大,需要的時間比較久。不滿足匹配快速的要求,而且匹配原理簡單,容易受到外界噪聲的干擾。序貫相似性算法的優點,各步驟的計算量要比誤差平方和快2-3倍;缺點是時間復雜度高,對搜索圖尺寸要求比較高。總的來說這兩種算法僅是基于灰度信息的相似性來比較差值,需要比較大量的像素點,所以計算量還是比較大的,達不到快速匹配的目的。而局部灰度編碼算法把要匹配的圖像劃分割成若干塊,然后計算每塊的灰度值,接著把整個圖像的局部灰度值按照順序劃分排序,進行編碼。最后和模板圖像進行比較,實現圖像的匹配。由于把圖像從空間上的層次轉換到編碼的層次,所以它的計算量有了很大的縮減,速度有極大的提高(見表1)。所以說局部灰度編碼算法還是可以達快速匹配(計算量小、匹配時間短、匹配精確)的要求。為了比較經典的圖像匹配算法與深度學習算法的耗時性能,選取了魯棒性較好的基于學習的不變特征變換算法(LIFT)[8]進行圖像匹配分析。LIFT算法采用了一種改進的SIFT圖像特征點提取技術,通過Kd-Tree特征結構、BBF搜索策略和HOUGH聚類進行圖像匹配,完成圖像匹配耗時為1324.210ms。 表1 各個算法運行時間記錄(ms) 圖像匹配將計算機視覺、多維信號處理和數值計算緊密聯合形成了密切相關的近領域交叉技術。本文所使用的灰度圖像匹配方法的基礎是圖像的相似度,即灰度信息所代表的灰度值的大小之間的關系。尋找塊匹配灰色信息區域的相似度的大小,可以用波形的峰值確定最大相似度區域以提高搜索的效率和準確性。通過測試發現,傳統的模板匹配算法和序貫相似性算法具有較好的魯棒性,而序貫相似性所要的時間要比傳統的模板匹配算法少得多。傳統的模板匹配算法的主要時間都用在匹配圖像和模板圖像之間的平滑過程,序貫相似性算法則首先設定了閾值,閾值越是接近相似度最高點,匹配的時間越短,精確度也越高。而基于學習的不變特征變換算法(LIFT)盡管具有較好的魯棒性[11],但復雜的運算過程增加了圖像匹配的耗時。所以,相對于一般傳統的模板匹配算法而言,序貫相似性已經可以實現圖像的快速匹配的要求。2 結果分析
2.1 圖像匹配結果

2.2 耗時性比較分析結果
3 結論
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
