云端大數據流序列異常挖掘數學建模仿真
2022-09-28 09:28:56徐成桂徐廣順
計算機仿真 2022年8期
徐成桂,徐廣順
(成都理工大學工程技術學院,四川 樂山 614000)
1 引言
近年來,計算機技術飛速發展,計算機網絡[1]規模愈加龐大,隨著網絡使用范圍的增加,計算機網絡安全問題逐漸成為各個國家的重點關注對象。數據流異常數據挖掘因其高強度網絡防御特性,受到廣泛應用。云端數據流作為計算機網絡的重要組成部分,對其有效的異常數據檢測[2]是計算機領域亟待解決的問題之一。
早于20世紀90年代,哥倫比亞大學就有學者就數據流異常數據挖掘的檢測給出了具體方法,從而為云端數據流的異常序列挖掘奠定了堅實的基礎。在此背景下,當前也出現了較多的研究成果。文獻[3]提出基于BiGRU-SVDD的ADS-B異常數據檢測模型。該方法基于神經網絡方法計算數據差值;再將獲取的計算結果放入支持向量機中進行訓練,完成數據分類;最后依據分類結果確定數據滑動窗口,縮減神經網絡訓練時間,從而建立數據的異常檢測模型,實現數據異常檢測。該方法由于未能在模型建立前,提取數據融合特征,所以該方法建立的模型數據挖掘時間長。文獻[4]提出基于三次指數平滑模型與DBSCAN聚類的電量數據異常檢測。該方法首先依據歷史數據預測當前時刻數據量,計算與實際值的殘差;使用DBSCAN聚類算法對數據殘差進行聚類處理,最后依據三次指數平滑模型建立數據的異常檢測模型,實現異常數據的檢測。該方法在對數據聚類處理時存在問題,導致該方法建立模型的挖掘效果差。文獻[5]提出基于逆向習得推理的網絡異常行為檢測模型。該方法依據提取的數據特征項對數據進行離散化處理,并對離散結果進行歸一化處理;再利用改進的ALI算法對數據進行訓練處理,生成數據檢測集;最后使用異常數據檢測函數判斷數據距離是否異常,將深層結構能量模型與高斯編碼混合模型進行結合,完成異常數據檢測模型的建立,從而實現異常數據的檢測。該方法在判斷數據距離時,存在較大誤差,所以該方法建立的模型數據的挖掘性能差。
為了解決上述傳統方法的應用弊端,本研究提出云端大數據流序列異常挖掘數學建模方法。實驗結果證明了所構建的模型應用效率果高,相關系數和召回率指標也均高于文獻方法,說明所提方法具有可行性。
2 提取云端大數據流特征
在對云端大數據流的異常序列挖掘前,需要結合神經網絡與布谷鳥算法[6]提取云端大數據流的數據特征。數據流在進行特征提取時需要檢測數據流信息,獲取數據流多項信息特征并進行特征重構,利用布谷鳥搜索算法對重構特征尋優處理,從而提取云端數據流的特征。
2.1 建立數據流神經網絡模型
設定云端數據流的神經網絡模型[7]共分為三層架構,分別為輸入層a、輸出層c以及隱含層b,由若干節點q組合而成。將神經網絡輸入層節點數量設定成x,隱含層節點數量標記z形式,輸出層節點數量標記y,網路訓練權值為ω,建立云端數據流神經網絡模型,具體模型結構如圖1所示。
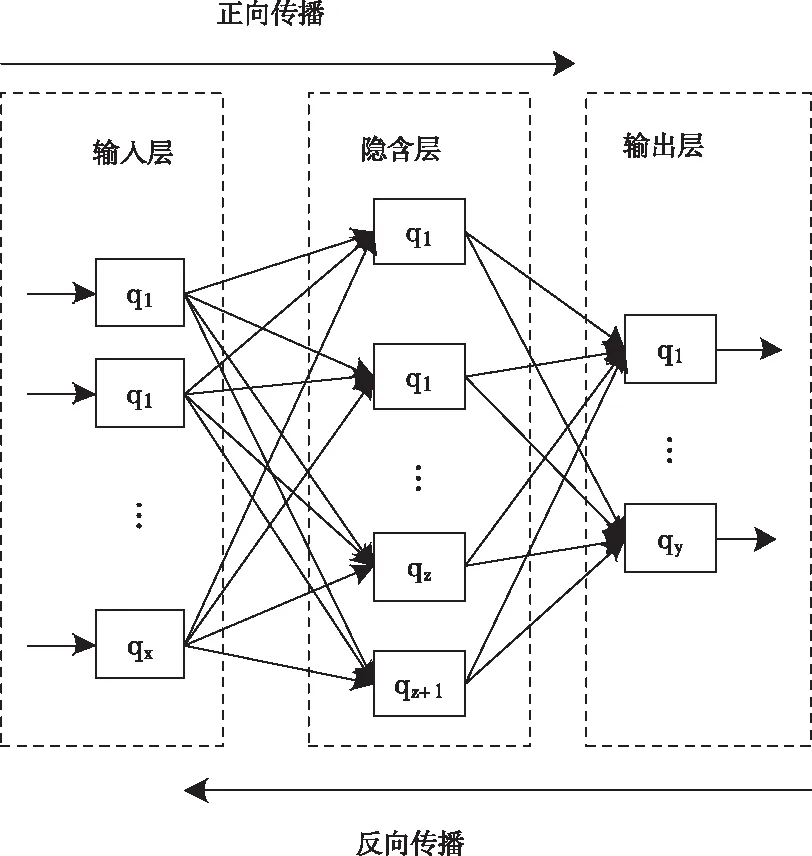
圖1 大數據流神經網絡具體結構
神經網絡模型建立后,基于大數據流參數確定神經網絡各個層級權重ω,其中輸出層至隱含層單元權重標記ωij形式,隱含層至輸出層權重標記ωjk,通過確定的單元權重對大數據流數據進行訓練,過程中需要建立相關激活函數,過程如下式所示
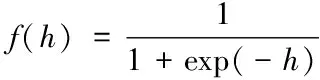
(1)
式中,激活函數標記f(h)形式,指數函數標記exp(-h)形式,數據流訓練樣本數量標記h。通過對網絡閾值的調節,獲取數據流[8]信息的均方誤差值?,結果如下式所示
?=1/2(Jn-Ln)
(2)
式中,云端數據流樣本信息的均方誤差標記?形式,樣本信息的訓練結果標記Jn,誤差函數標記Ln,神經網路訓練樣本數量標記n。
2.2 檢測數據流信息
首先依據上述獲取的均方誤差函數對數據流進行分割處理,將云端數據流D分成若干數據段,并將其作為數據流滑動窗口Dm。依據滑動窗口建立數據流的調度集函數,結果如下式所示

(3)
式中,云端大數據的數據平均熵sn(u),信息樣本集中心點標記n形式,數據流信息譜特征量標記kn(u)形式,神經網絡迭代次數標記u,大數據流中的數據總量標記E形式。依據上述計算結果獲取數據流信息譜α,通過信息融合提取數據的多維時間序列。
2.3 建立大數據流特征提取模型
結合上述建立的神經網絡與提取的數據流多維時間序列,建立數據流的空間融合模型[9],結果如下式所示
pm(u)=(aj+δj(u))+(bj+εj(u))
(4)
式中,融合模型參數標記aj和bj,誤差擾動標記δj(u),數據均值噪聲標記εj(u)。提取數據流融合特征時,設定數據段Yj初始分割點為Yj(1),并以此獲取模型參數向量β。通過上述計算,獲取數據流的融合特征集R=(supk1(r),…supkf(r)),并使用聚類算法[10]計算數據段聚類迭代方程,結果如下式所示

(5)

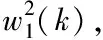

(6)

2.4 搜索最佳特征值
使用布谷鳥算法計算數據流融合特征值,從而搜索數據流的最佳特征。過程如下:
1)初始化數據流
2)更新循環鳥窩位置

(7)
3)替換位置較差的鳥窩
對獲取的鳥窩位置進行高斯擾動,獲取新的鳥窩位置P″,通過對比測試將鳥群中位置較差的鳥窩進行替換處理。
4)尋找最佳鳥窩位置
替換后,搜索鳥群中最佳的鳥窩位置,獲取數據流的最佳融合特征,結束搜索。
最后通過上述搜索流程輸出結果,獲取云端數據流的最佳融合特征信息。
3 建立云端大數據流異常序列挖掘模型
3.1 確定模型閾值自適應調整策略
云端大數據流由若干n數據序列組合而成,并會隨著時間的變化而發生改變,表現形式標記{z1,z1,…,zn},數據流[12]的最大近似序列用zn表述。

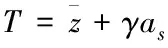
(8)

(9)
式中,數據流序列的閾值調整條件標記G形式,調整因子標記μ形式,當序列閾值比重為0時,t可作為常數處理。
3.2 計算相關系數
設定云端大數據流序列之間的相關系數[13]為F(0),長度用l表示,若序列長度小于l,則默認序列長度為0,說明該序列為滯后序列。一般來說,計算云端大數據流序列相關系數時,可使用皮埃爾系數ρ完成相關系數的計算,結果如下式所示

(10)
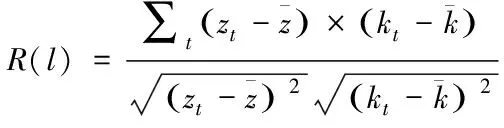
(11)
式中,序列滯后相關系數標記R(l)形式。
3.3 建立相關約束條件
基于上述數據流序列相關系數的計算,引入遺忘機制建立模型相關約束條件。
在建立數據流異常序列挖掘模型時,設定序列的決策變量為A,遺忘因子為Y,序列衰減因子用σi(N)表示,并以此建立數據流異常序列挖掘模型的約束條件,過程如下式所示

(12)
式中,序列的最大相關系數標記Rmax(l),最小相關標記Rmin(l)。
3.4 建立模型
基于上述確定的閾值、序列相關系數以及約束條件,建立云端大數據流序列的異常挖掘模型[15],過程如下式所示

(13)
式中,云端大數據流序列異常挖掘模型標記P(x)形式。
最后將云端大數據流中相關待檢測序列放入模型中,通過模型輸出,獲取數據流異常序列值。
4 實驗設計與指標測試結果
為了驗證上述云端數據流序列異常挖掘模型建立方法整體有效性,需要對此方法進行測試。
4.1 實驗結果及分析
分別采用云端大數據流序列異常挖掘數學建模仿真(本文所提方法)、基于BiGRU-SVDD的ADS-B異常數據檢測模型(文獻[3]方法)、基于三次指數平滑模型與DBSCAN聚類的電量數據異常檢測(文獻[4]方法)進行測試;
在建立異常挖掘模型時,數據流序列挖掘時間的長短、相關系數的大小以及檢測效果的優劣都會給模型的檢測性能帶來影響,采用本文所提方法、文獻[3]方法以及文獻[4]方法建立異常數據挖掘模型時,利用上述測試指標檢測三種模型的模型檢測性能。
1)模型挖掘時間測試
在建立異常數據挖掘模型時,模型檢測時間的長短能夠直接反映模型的檢測性能,采用本文所提方法、文獻[3]方法以及文獻[4]方法建立異常數據挖掘模型時,對三種模型的異常數據挖掘時間進行測試,測試結果如圖2所示。

圖2 不同模型異常數據檢測時間測試結果
分析圖2可知,檢測次數的增加會提高模型對異常數據的檢測時間。在測試初期,文獻[3]方法測試結果與本文所提方法測試結果相一致,隨著檢測次數不斷增加,二者之間差距拉開,本文所提方法測試結果低于文獻[3]方法檢測結果。本文所提方法的測試結果同樣會隨著檢測次數的增加而提升,但是當檢測次數達到一定范圍時,本文所提方法能夠將異常數據挖掘時間穩定在固定時間內。由此可知,本文所提方法的異常數據檢測時間低于其它兩種方法,文獻[3]方法測試結果略高于本文所提方法,文獻[4]方法測試結果較差。
2)模型相關系數測試
在建立異常數據挖掘模型時,模型相關系數的大小會對模型的挖掘效果帶來影響。設定皮埃爾系數ρ為模型相關系數指標,最佳區間為[0,1],模型的相關系數越高,模型的挖掘效果越好,反之則越差。采用本文所提方法、文獻[3]方法以及文獻[4]方法建立異常數據挖掘模型時,測試三種方法的模型相關系數,測試結果如圖3所示。
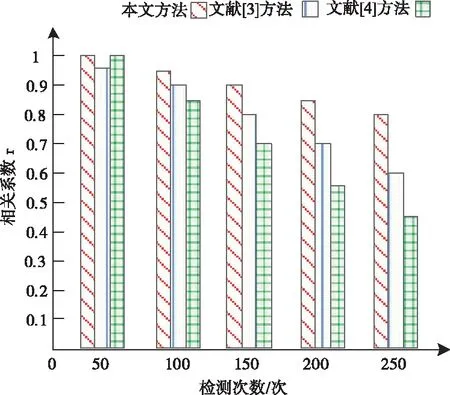
圖3 不同模型的相關系數測試結果
分析圖3可知,模型相關系數的大小會隨著檢測次數的增加而有所下降。在測試初期,文獻[4]方法檢測出的模型相關系數與本文所提方法測試結果相一致,隨著測試的進行,文獻[4]方法測試結果急速下降,直至低于文獻[5]方法測試結果。本文所提方法雖然也會隨著檢測次數的增加有所降低,但是測試出的模型相關系數依然高于其它模型。這主要是因為本文所提方法在建立異常數據挖掘模型前,提取了數據流融合特征,所以本文所提方法建立的異常序列挖掘模型具備較高的相關系數。由此可證明本文所提方法的挖掘效果好。
3)檢測效果測試
基于上述測試結果,選定5000個待挖掘數據,采用本文所提方法、文獻[3]方法以及文獻[4]方法建立異常數據挖掘模型時,對三種方法的模型挖掘效果進行測試,測試結果如表1所示。

表1 不同方法的模型挖掘效果測試結果
分析表1可知,本文所提方法在挖掘數據流異常序列時,檢測出的挖掘效率、召回率高,檢測出的數據誤報個數低。
綜上所述,本文所提建立的數據挖掘模型在進行異常數據挖掘時的挖掘時間短、挖掘效果好、挖掘性能高。
5 結束語
隨著網絡應用范圍的增加,云端數據流的異常序列檢測就變得尤為重要。針對傳統數據流異常數據挖掘方法中存在的問題,提出云端大數據流序列異常挖掘數學建模方法。該方法依據提取的云端數據流融合特征,獲取模型的自適應閾值;再通過相關系數以及約束條件的建立,完成異常挖掘模型的建立,實現數據流序列的異常挖掘。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
信息通信技術(2015年6期)2015-12-26 01:16:46
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
