物聯網中節點捕獲攻擊早期檢測方法研究
2022-09-28 09:28:52曾凡鋒田雨絲王景中
計算機仿真 2022年8期
曾凡鋒,田雨絲,王景中
(北方工業大學信息學院,北京 100144)
1 引言
作為第三次信息時代發展浪潮,物聯網[1]將互聯網的客戶端延伸到了任何物品和物品之間,滿足信息交換和通信。由于物聯網感知層存在節點設備基數龐大、微處理器計算受限、感知環境不確定和網絡拓撲結構動態變化等特點,實現物聯網網絡安全存在巨大挑戰[2]。攻擊者通常采用控制節點設備的方法來入侵物聯網網絡,經過物理捕獲感染節點、將節點重新部署回到網絡和通過被感染節點發起攻擊這三個階段來完成入侵[3]。針對防御的研究重點大多數放在了第二和第三階段,例如基于節點位置的檢測[4]等。但由于攻擊進行到第二、三階段時,已經對節點設備或者整個網絡造成了一定的損失,因此,盡早檢測出被捕獲節點對維護物聯網網絡安全具有重要意義。
目前,物聯網安全技術研究方面,許多安全技術已經被提議,但是由于物聯網網絡協議設計階段,沒有考慮安全問題,因此也沒有形成完善的安全體系。針對通信協議的安全問題,大多數研究都是基于修改協議源碼展開,面向的問題也常為數據安全問題[5],并且針對特定問題修改協議內容在一定程度上影響了安全策略的實施難度和適用性。
本文不更改協議源碼,從MQTT協議應用角度出發,借助其心跳機制設計了包括心跳消息、問候消息在內的檢測流程,并充分考慮到其發布訂閱模式[6]下的服務器客戶端網絡結構,設計了包括服務器、鄰居節點在內的多方協同決策方案。由仿真結果表明,該方法在檢測率和誤報率方面均優于傳統方法,特別是在降低誤報率方面具有較好的效果。
2 相關研究
2.1 典型的傳統方法
節點捕獲攻擊主要是利用傳感器的編程和測試接口對傳感器進行妥協從而達到控制的目的[7]。研究表明,節點捕獲攻擊需要將節點從正常網絡通信中“移除”一段不可忽略的時間,從幾分鐘到幾小時不等[8]。對節點捕獲攻擊檢測的現有方法正是利用這一特征,通過節點間廣播信標消息、問候消息或心跳消息相互監控對方的存活性,以盡早發現被捕獲節點。
Lin Xiaodong等人的CAT方法[3]采用H-W兩兩配對的方式,通過發送接受BEACON信標消息相互監控對方的存活性,如果未收到的信標消息超過一定閾值則將判斷對方被入侵。如果區域節點為奇數時,將有一組H-W-C節點進行相互監控,用以消除網絡中的孤立節點。由于CAT方法中節點的檢測效果由其配對的一方所決定,節點被同時捕獲時,檢測方法無效,且對可疑狀態的節點沒有進行審查判斷,會增加誤報率。Ding Wei等人的FSD方法[9]是通過節點定期廣播hello消息來證明自己的存在,監控節點未收到來自被監控節點的連續hello消息超過一定數量,將多次發送長間隔的詢問ask消息確認被監控節點狀態,若節點沒有回復則認為其被捕獲。在FSD方法中,節點還具有自檢功能,如果節點沒有收到所有鄰居的hello消息,則考慮自己被捕獲,節點開啟自毀模式并向鄰居廣播消息。相較于CAT方法,FSD方法對被監控節點增加了一個監控方,一定程度上降低了誤報率。Al-Riyami等人針對耗能問題,對不同簇下的hello消息采用不同的廣播頻率[10]。Zhang Zhihua等人針對節點休眠問題,提出了節點聲明消息統一調度廣播機制[11]。
但以上方法在節點狀態的檢測判斷中,只運用了傳感器網絡下角色相同的節點進行相互監控,沒有考慮運用物聯網中服務器客戶端網絡結構下的服務器節點。而引入不同角色的節點,增加不同消息類型的監控,使節點的檢測更全面、更可靠。筆者所提方法在傳統方法鄰居監控的基礎上,借助了MQTT協議中服務器與客戶端的心跳監控,增加了服務器節點的決策環節,在不額外增加網絡負擔的情況下,優化了傳統方法的檢測結果。
2.2 網絡結構模型與入侵假設
傳統方法的實驗環境通常為包含了一個sink和多個終端節點的傳感器網絡,而應用了MQTT協議的物聯網網絡通常由一個云端服務器、M個服務器節點和N個終端節點組成。網絡結構模型如圖1所示。假設服務器節點在網絡中是安全的,終端節點隨機均勻分布在服務器節點下。所有節點都在同一時間啟動,每一個節點部署好之后都是靜止的,且具備一個全網唯一的ID標識。每一個服務器節點和其終端節點都維護一個存有ID號的鄰居表,用來確認節點鄰居。服務器節點周期性匯總終端節點的采集數據發送給云端服務器,終端節點周期性向服務器節點發布采集數據。服務器節點與終端節點間雙向發包,終端節點之間也可以互通消息。
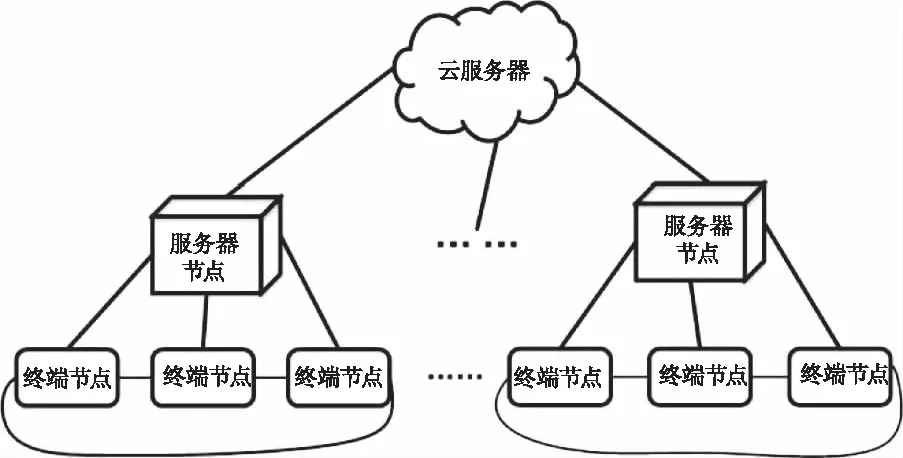
圖1 網絡結構模型
由于節點被捕獲的第一階段狀態表現為無法通信,可以假設在網絡初始化后,將每個終端節點在一定概率下隨機定義為被捕獲節點,被捕獲節點在一段時間內不再發送任何消息。若被捕獲的節點過多,檢測是沒有意義的,本文假設被捕獲節點總數K的上限是節點總數N的25%。如果已被捕獲的節點未被檢測出來,該節點的通信將時斷時續來模擬入侵者通過該節點分析網絡的行為;如果已被捕獲節點被成功檢測,則將主動使其脫離網絡。
3 節點捕獲攻擊早期檢測方法
3.1 節點消息結構
服務器客戶端網絡結構中設備角色有:
1)云端服務器Cloud:云端服務器連接服務器節點來接收工作數據。
2)服務器節點Server:服務器節點連接云端服務器和終端節點,與終端節點雙向發包。
3)終端節點Node:終端節點連接服務器節點,同一個服務器節點下的終端節點也可以相互發包。
主要消息類型有:
1)Conn負責Node和Server之間的連接。
2)SUBSCRIBLE負責推送Node的左右鄰居id給Server。
3)HEART負責Node和Server之間的心跳。
4)HELLO負責Node之間的問候。
5)CLOUD負責云數據推送。
6)DECISION負責發送檢測信號。
7)UPDATE負責通知Node更新鄰居列表。消息類型還包括交互過程的應答消息。
3.2 檢測方法
節點捕獲早期檢測在全網執行檢測任務,根據監控、詢問和決策判斷結果來對被監控節點的狀態進行判斷。終端節點入網后將分別向服務器節點、鄰居節點發送周期性的心跳消息和問候消息;當服務器未收到某節點超過一定數量的心跳消息時,該節點進入被審查狀態;經過對該節點問候消息以及后續心跳消息發送情況的綜合決策,得出該節點狀態;當決策結果為異常時,通過更新鄰居列表來將該節點排除在外,不再使其接入網絡。
網絡初始化后,云端服務器Cloud將與服務器節點Server[0,1,…M]、終端節點Node[0,1,…N]形成一個樹形結構。每個服務器節點Server[i]下有n=N/M個終端節點,分別是Node[i*n]、Node[i*n+1]…Node[i*n+n-1]。每個終端節點Node[myId]的左右鄰居的ID分別是left.id=myId-1、right.id=myId+1,其中首節點的左鄰居left.id=myId+n-1,尾節點的右鄰居right.id=myId-n-1。網絡運行過程中,節點之間狀態轉換如圖2所示。
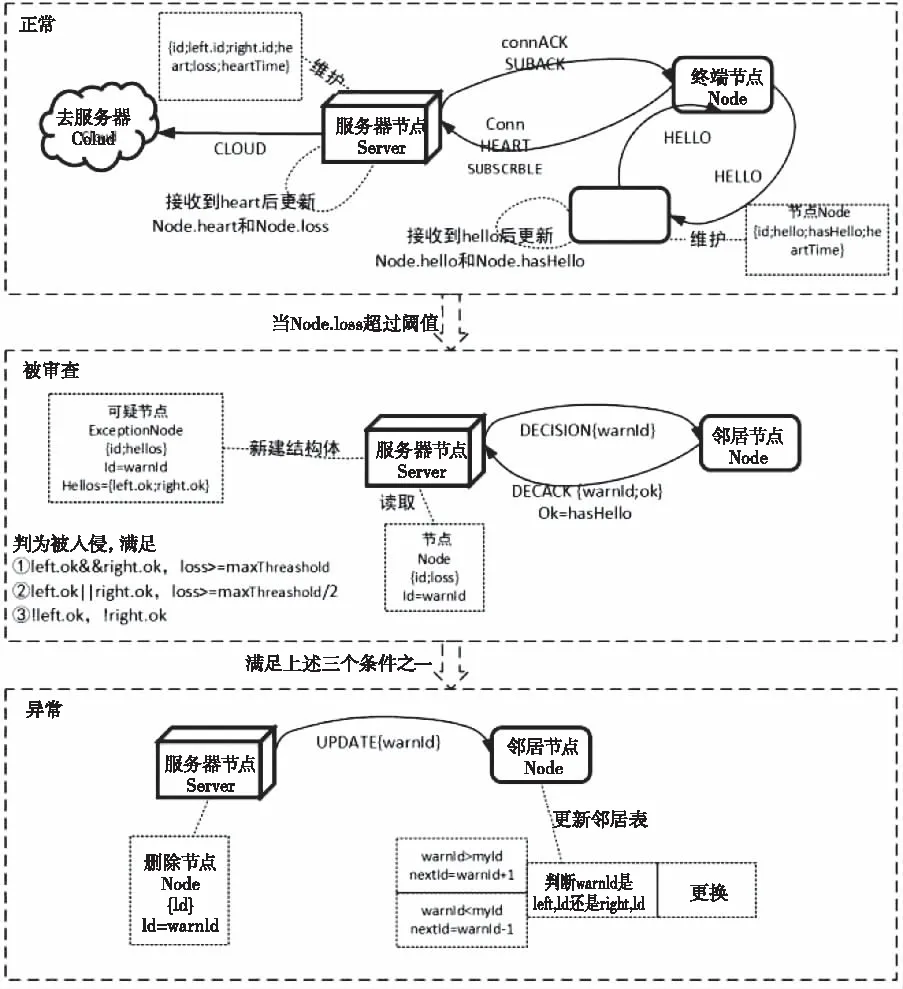
圖2 節點狀態轉換
正常狀態下:Server周期性向Cloud推送工作數據。Node周期性向Server發送heart消息和工作數據。Server每次接收heart消息都會對節點心跳信息進行維護,內容包括heart數量、loss遺失數量、heartTime。Node也向自己的左右鄰居left、right發送周期性的hello消息,每個節點也將維護自己左右鄰居節點的hello消息信息,使用hasHello來表示是否收到問候消息,helloTime來監控問候消息的發送間隔。
被審查狀態:當Server維護的某Node.loss超過所設定閾值時,該節點進入檢測判斷環節。Server將生成一個新的結構體ExceptionNode,讀取該可疑節點的id和收集其鄰居的hello情況放入hellos中。Server向可疑節點的左右鄰居發送DECISION消息,收到DECISION消息的節點,將檢查被審查節點是否發送了問候消息,并通過DECACK消息發送給Server,內容包含ok(表示hasHello),服務器將warnId節點的左右鄰居ok情況存入hellos。之后服務器將根據hellos和loss的情況對該id的節點狀態進行分情況判定。
在Node.loss達到閾值從而進入被審查狀態后,節點判斷為入侵的三種情況:
1)左右鄰居均收到了hello,且Node.loss達到maxThreashold。
2)左右鄰居只有一個收到了hello,且Node.loss達到了maxThreashold的一半。
3)左右鄰居均未收到hello。
異常狀態:若節點判定為被捕獲狀態,則服務器Server向warnId的鄰居節點發送UPDATE消息來提醒節點更新鄰居列表,接收到此消息的節點根據消息中的warnId值選擇新的鄰居nextId。服務器Server還將在結構體Node中刪除id為warnId的節點。
4 實驗及結果分析
下面對所提方法和傳統方法的有效性和通信開銷情況進行評價。實驗在OMNET++平臺上進行,并在相同的網絡拓撲、相同的參數下與CAT方法、FSD方法進行比較,其中丟包率和節點入侵概率均為0.01。實驗中隨機均勻部署10個服務器節點,190個終端節點和一個云節點。網絡拓撲如圖3所示。
圖3 實驗網絡拓撲
采用三種方法進行實驗的結果如下。被捕獲節點檢測率如圖4所示,可以看出在被捕獲節點較少時,三種方法的檢測率都比較高,基于節點存活性進行檢測的方法都具有很高的靈敏性,在發現節點的異常行為方面非常高效。本次實驗設置190個終端節點作為可攻擊節點,當被捕獲節點超過190*25%時,三種方法的檢測率都有所下降,其中,由于CAT方法中節點的監控只依靠一個節點對象,在被捕獲節點增加的情況下,檢測率下降較快。FSD方法和本文所提方法在存活性監控基礎上增加多個對象的監控,使檢測率下降較慢,且均采用了鄰居節點監控方式,檢測率差異性不大。

圖4 三種方法的檢測率
被捕獲節點誤檢率如圖5所示。CAT方法和FSD方法的誤檢率在整體趨勢上隨著被捕獲節點的增加而上升,CAT方法對異常節點未加判斷,導致了最高的誤報率;FSD方法在對異常節點的判斷時,只依靠鄰居間的問候消息,當此消息產生較高丟包現象時容易造成誤判。本文所提方法不僅有鄰居節點的問候消息監控,還增加了服務器節點的心跳消息參與監控和判斷,使其在最大程度上避免了誤檢。
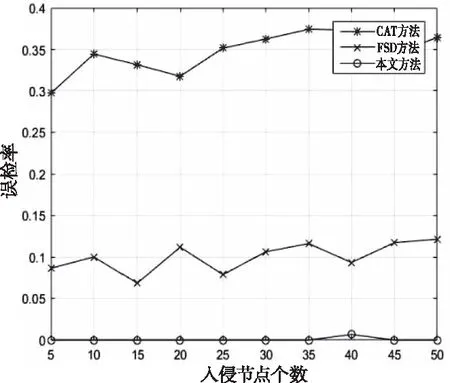
圖5 三種方法的誤檢率
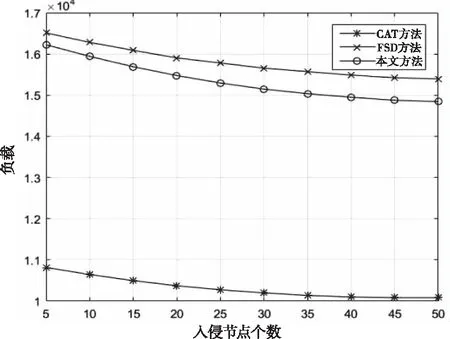
圖6 三種方法的負載
被捕獲節點通信負載如圖6所示。三種方法的實驗環境和參數均相同的情況下,由于本文采用的心跳消息是MQTT協議自帶的環節,在檢測開銷上只增加了鄰居間的問候消息和發現異常后的詢問消息,并未給網絡造成額外負擔。隨著被捕獲節點的增加,被踢出網絡的節點數量變多,使得整個網絡的負載呈下降趨勢。CAT方法只包含對一個節點的問候消息,且沒有進行詢問,所以誤報較高使而負載最少;本文所提方法與FSD方法既有對兩個鄰居的問候也有詢問,但是FSD方法包含多次問候和詢問環節,而本文方法只進行一次詢問來收集hasHello的情況,在檢測判斷環節上比FSD方法更加便捷,負載更少。
5 結束語
針對具有服務器客戶端的物聯網網絡結構,結合MQTT協議特點,提出了一種心跳消息和問候消息結合的節點捕獲早期檢測方法,以實現對捕獲攻擊的早期發現。該方法基于節點存活性監控,通過逐步審查、多方協同的方式對節點狀態進行判斷。實驗結果表明,所提方法有效避免了因為丟包等情況對捕獲攻擊檢測效果的影響,在不影響網絡負載和檢測率的情況下,顯著降低了誤報率。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
