基于密度劃分的云數據分塊存儲方法仿真
2022-09-28 09:54:14潘文標元文浩
計算機仿真 2022年8期
潘文標,元文浩
(溫州醫科大學信息技術中心,浙江 溫州 325035)
1 引言
互聯網技術與移動互聯網業務迅速普及,使得在日常應用過程中產生了大量數據[1],給后續的數據存儲、分析等均帶來了極大的難度,因此,謝鵬等研究人員[2]在數據存儲的探究課題中,結合HBase分布式存儲系統,創建空間矢量數據存儲模型,期望打破存儲技術的探索瓶頸。
進入云計算時代后,云存儲技術[3]迅猛發展,云端服務器應運而生,作為新型的存儲方式,該存儲形式在大數據時代得以廣泛應用,不僅讓用戶體驗到了極佳的數據存儲服務,也為大規模數據存儲減輕了不小的壓力。隨著云端服務器越來越普及,應用頻率越來越高,其爆炸式的增長趨勢使云數據的存儲問題受到高度關注,相關存儲方法應運出現,比如,劉福鑫設計的Kubernetes云原生海量數據存儲系統[4],取得了較好的研究成果。
我國云數據存儲技術的研究剛剛起步,仍存在很大的優化空間。本文基于密度劃分算法,設計一種分塊存儲方法,緩解存儲壓力。根據細粒度云數據的密度不均勻屬性,設計出低敏感度的密度劃分算法,獲取高集中性的數據類別,去除無效的冗余數據,縮減存儲空間;根據密度分割點建立階躍函數,避免密度閾值過高導致聚類不精確;基于伽羅華域完成云數據分塊編碼與解碼的全部運算,利用范德蒙矩陣編碼、解碼,簡化編解碼復雜性,降低運算難度與復雜度,加快運算速度。
2 基于密度劃分算法的細粒度云數據聚類
針對細粒度云數據,按照下列密度劃分算法流程,聚類所有云數據:
1)輸入細粒度云數據集合P,構建距離矩陣D;
2)明確自然特征值λ,以距離矩陣DN*N為依據,以r為搜索范圍,遍歷各云數據的近鄰與逆近鄰[5]數據,待反向鄰域數據個數穩定時停止,獲得的矩陣nb為全部云數據的逆近鄰數量,此時有r=λ;
3)利用云數據及其近鄰數據,建立局部鄰域集LN;
4)通過式(1)求解云數據p的局部密度
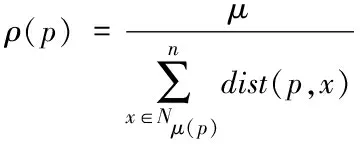
(1)
式中,Nμ(p)指代數據p的μ近鄰數據集;dist(p,x)指代云數據p及其第μ個近鄰數據x之間的歐幾里得距離[6]。其中,μ=max{nb};
5)按局部密度值,降序排列云數據,密度值最大的云數據就是局部鄰域集LN的局部核,劃分剩下云數據至局部核的所屬類別中;
6)取得比平均密度低的最大二階導數,將該最大值對應的云數據密度作為密度閾值ρt,去除每個類別內比該閾值小的數據;
7)利用各云數據及其λ近鄰點,建立全局鄰域圖;
8)假設類別Ci與Cj間的跨類別邊緣數據是vi、vj,兩數據間的邊權重值為w(vi,vj),(vi,vj)表示數據vi、vj的偏導數,CE(Ci,Cj)表示兩類別的聯合密度,則采用下列計算公式求解類別Ci、Cj之間的關聯度

(2)
若跨類別邊緣數據是vi、vj的歐幾里得距離是dist(vi,vj),則云數據邊權重值w(vi,vj)的計算公式如下所示

(3)
通過下列公式計算類別Ci與Cj間的緊密度

(4)
求解類別間關聯度與緊密度的乘積,即得到類別Ci與Cj的相似度,數學表達式如下所示
sim(Ci,Cj)=connect(Ci,Cj)*close(Ci,Cj)2
(5)
9)根據距離閾值η,判定跨類別數據的同類性與異類性,獲取數量比例;
10)降序排列類別相似度,以類別相似度與跨類別數據的類別屬性為依據,聚類所有云數據。當跨類別數據的同類數多于異類數時,符合聚類條件,將兩類別整合在一起[7];獲取新的相似度與聚類條件,待不符合聚類條件時,終止聚類操作,將未完成聚類的類別云數據整合成一類[8];
11)劃分密度閾值較低的云數據至其局部核的所屬類別。至此,實現所有云數據聚類。
密度劃分算法的兩個重要參數為聚合條件的判定矩陣ψ與距離閾值η[9,10]。假設集合P中含有M個云數據,其中,數據i及其第k個近鄰點的間距是dik,則距離閾值η的計算公式如下所示

(6)
若類別Ci、Cj的跨類別數據共有ni,j對,則將下列表達式界定為聚合條件的判定矩陣ψ

(7)

(8)
針對比平均密度小的密度曲線,取得離散的最大二階導數,獲得聚合條件判定矩陣ψ與距離閾值η的最優值。
3 基于里所碼的細粒度云數據分塊存儲
將完成聚類的細粒度云數據劃分為規格相同的數據塊,任意類別中的數據塊集合為B={b0,b1,…,bm-1},各數據塊經里所碼分塊后,得到K個規格相同的云數據分塊集F={f0,f1,…,fK-1},其中,m-1與K-1各指代里所碼分塊前后的云數據塊數量。為簡化編碼復雜性,利用范德蒙矩陣A編碼,獲得校驗塊集G={g0,g1,…,gM-K-1},該集合中含有M-K個校驗塊。編碼處理通過下列矩陣方程實現

(9)
式中,范德蒙矩陣A的界定式如下所示

(10)
經范德蒙矩陣編碼處理,儲存編碼后的細粒度云數據。為避免主節點產生大量冗余云數據,選取的節點只存儲一個云數據塊,根據兩者間的相關性,獲取分塊存儲的元數據。每完成一個節點的云數據塊存儲,元數據都將直接更新至各節點。綜上所述,設計出下列細粒度云數據分塊存儲算法流程:
1)假設待輸入的細粒度云數據是data,其文件名是src,通過用戶端把云數據data輸入流中;
2)數據分塊,得到B={b0,b1,…,bm-1};
3)在主節點選取的節點上存儲云數據塊;
4)利用范德蒙矩陣進行編碼,二次分塊細粒度云數據;
5)在所選節點上儲存編碼后的云數據;
6)基于各云數據塊,獲取新的元數據。迭代循環整個流程,直到沒有新的元數據生成,此時,即可實現所有云數據的分塊存儲。
迭代分塊存儲過程中,需要調度節點來執行云數據塊的處理任務,這就涉及到一個重要的步驟,即細粒度云數據的解碼處理。
假設待處理云數據塊為bα,任務執行的節點為nodeα,搜尋所有儲存數據塊bα的節點,形成列表listα,針對其前φ個有效節點,取得云數據塊及其元數據,將范德蒙矩陣A與有效節點上儲存的云數據塊集F″={f″0,f″1,…,f″K-1,f″K}相結合,得到矩陣L及其逆矩陣L-1,建立L-1與新分塊集F′={f′0,f′1,…,f′K-1,f′K}的乘積形式,即完成云數據塊解碼處理。該解碼處理通過下列矩陣方程實現

(11)
式中,逆矩陣L-1的界定公式如下所示

(12)
綜上所述,構建出下列細粒度云數據塊的解碼操作流程:
1)假設云數據的路由信息與緩沖大小各是path與size;
2)創建系統文件,根據文件名搜索元數據;
3)基于存儲待處理云數據塊的節點列表,完成解碼處理;
4)更新云數據塊,利用用戶端取得經過解碼處理的云數據塊;
5)迭代循環上列步驟,直到分塊存儲完所有云數據。
本文基于伽羅華域完成云數據分塊編碼與解碼的全部運算,且在不改變范德蒙矩陣形式的前提下,執行編碼與解碼處理,二者均能夠在一定程度上降低運算難度與復雜度,加快運算速度。
4 細粒度云數據分塊存儲仿真研究
為增加實驗可靠性,設定仿真環節為三個階段:明確里所碼編碼比例的最優參數;分析密度劃分算法的可用性;探究分塊存儲方法的完整性、壓縮性。
4.1 基于分塊存儲的里所碼編碼比例設置
令里所碼編碼比例按等差數列取值,分析不同編碼比例下分塊存儲細粒度云數據時的開銷與帶寬,根據實驗結果,擇優設置里所碼編碼比例參數。

圖1 編碼比例參數相關性
從不同編碼比例參數值下分塊存儲的開銷與帶寬情況可知(見圖1),當里所碼編碼比例參數取值為0.5時,存儲開銷最小,且隨著運行時間的增加呈持續大幅下降趨勢;同時帶寬一直保持最高數值,且隨著運行時間的增加呈平緩上升趨勢。因此,設定里所碼編碼比例參數為0.5,能夠以最佳狀態展開方法驗證試驗,減小該參數對存儲效果的影響。
4.2 密度劃分算法可用性分析
選取細粒度云數據量不同的三個集合,分別采用正相關的純度、互相關信息熵、F1綜合指標,評估密度劃分算法的聚類效果。各評估指標的取值范圍均為0到1,計算方式如下所示

(13)

(14)
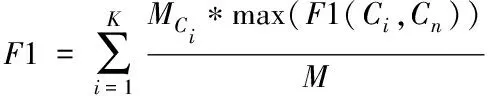
(15)
其中,Cn為類別n的真實聚類;θ(Cn,Ci)指代聚類結果是Ci,但實際類別是Cn的幾率,θ(Cn)與θ(Ci)各指代真實聚類為Cn的幾率與聚類結果是Ci的幾率,MCn與MCi各指代兩類別數量;F1(Ci,Cn)指代兩類別的F1綜合指標值,計算公式如下
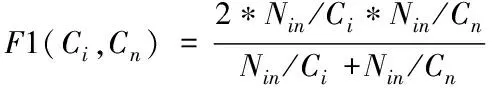
(16)
根據圖2所示的各集合評價指標結果可以看出,對于不同大小數據量的實驗樣本,密度劃分算法始終具有較好的聚類效果,即便面對海量細粒度云數據,該算法通過深入探討判定矩陣與距離閾值兩個關鍵參數,憑借近鄰與逆近鄰數據構成的局部鄰域集與全局鄰域圖優勢,精準完成聚類,具備良好的可用性,對分塊存儲的干擾幾乎可以忽略不計。
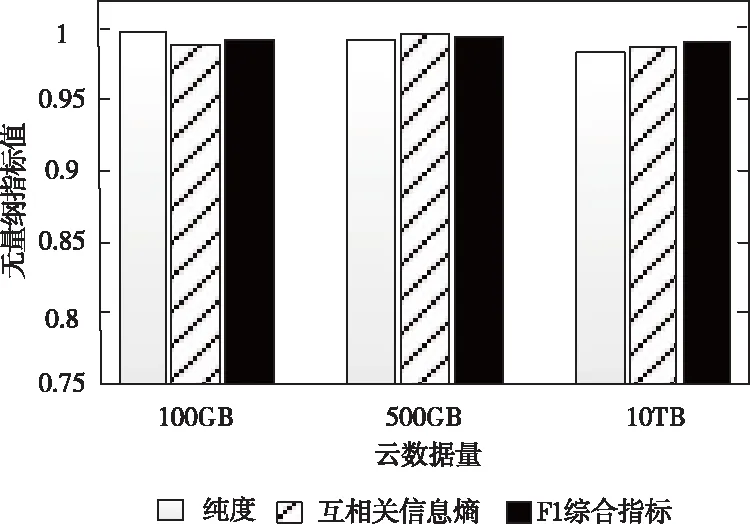
圖2 不同數據量的聚類效果示意圖
4.3 細粒度云數據分塊存儲效果分析
利用本文方法分塊存儲某細粒度云數據集,將得到的實驗結果分別與HBase模型及Kubernetes系統的存儲效果作比較,驗證本文方法的優越性與實踐性。
4.3.1 分塊存儲完整性
以500GB的云數據量集為檢驗對象,設定主節點所選節點的存儲量為50個數據塊,待完成所有云數據塊存儲后,根據各節點上存儲的數據塊數量,分析不同方法在存儲數據過程中發生的數據丟失情況。任意選取其中十個節點,其數據塊存儲結果如圖3所示。
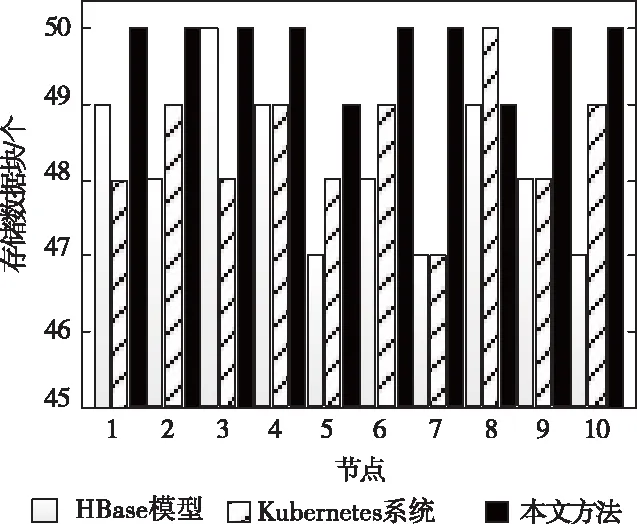
圖3 數據塊存儲數量示意圖
由十個節點的數據塊存儲量可以看出,本文方法結合密度劃分算法與里所碼技術,大幅提升細粒度云數據塊的聚類與劃分精度,確保各云數據都得到分類處理,盡可能不遺漏數據塊,因此,僅有節點5、8各丟失一個數據塊,相較于文獻方法的多次、多塊丟失情況,具有更理想的存儲完整性。
4.3.2 分塊存儲壓縮性
就分塊存儲壓縮性能,利用輸入、輸出數據的大小比值(即壓縮因子指標)客觀評估,該指標值與壓縮效果呈正相關性。三種存儲方法的壓縮因子指標數值如表1所示。

表1 不同存儲方法的壓縮因子數值
根據表1中的壓縮因子參數值可以看出,本文方法的壓縮因子值幾乎是文獻方法的二倍,壓縮優勢顯著,實現了分塊存儲目標。這是因為該方法根據類別相似度,準確聚類所有云數據,為數據分塊奠定基礎,利用多個適配度較高的節點,分塊存儲云數據,極大程度減緩存儲壓力,令壓縮性能得到更好發揮。
5 結論
大數據與云時代的來臨,在為用戶提供便利的同時,導致云數據規模暴增,這一發展趨勢對存儲技術提出了巨大挑戰,其中,以細粒度數據的存儲難度最大。為此,針對細粒度云數據,提出分塊存儲方法,通過實驗證明,方法取得較好效果。所以,在接下來研究中,為拓展方法應用領域,進一步提升存儲效果,將以下幾點作為重點研究方向:數據類型多種多樣,應就多元化的數據種類,不斷檢驗本文方法的存儲效果;針對編碼語義的可擴展性,驗證復雜情況下能否實現數據的統一編碼;需利用經典的加密算法,提升分析存儲安全性;改進密度劃分算法的離線處理局限性,令其對實時的數據流也具備較好的處理能力;應在真實場景中開展實驗活動,令方法更契合實際應用。
