基于梯度追蹤的結構化剪枝算法
2022-09-28 09:53:10季繁繁袁曉彤
計算機仿真 2022年8期
王 玨,季繁繁,袁曉彤
(南京信息工程大學江蘇省大數據分析技術重點實驗室,江蘇 南京 210044)
1 引言
現今,卷積神經網絡(CNN)[1-3]在計算機視覺、自然語言處理、語音識別等深度學習的各個領域中迅速發展,而且表現出其優越性能。通常情況下,神經網絡的層數越深、結構越寬,模型的性能也就越好。所以,CNN的大量可學習的參數使得網絡能夠擁有強大的表達能力。
盡管深度卷積神經網絡取得了巨大成功,但CNN卻存在過參數化的問題。當深度模型在硬件資源受限的環境(比如嵌入式傳感器、無人機、移動設備等)中實際工作時,會出現以下三個問題:運行時的內存過多;可訓練參數過多;計算代價過大。例如,在對分辨率為224×224的圖像進行分類任務時,ResNet-152[4]占用了不少于200MB的存儲空間,具有6020萬個參數,需要23千兆的浮點運算次數(FLOPs),這會導致CNN計算代價過大[5]。以上三個問題限制了深度CNN的實際部署。
為了有效緩解上述的問題,研究人員提出了一些新的技術來加速和壓縮深度CNN,包括低秩分解[6-7],量化[8-9],知識蒸餾[10]和網絡剪枝[5,11-12]等。他們在追求高精度的同時,能夠降低過參數化網絡的計算代價以及存儲需求。
濾波器剪枝能夠剪除原始網絡中的冗余卷積核,從而獲得小網絡,有效降低模型的運算量和存儲量。作為模型壓縮技術,濾波器剪枝有以下幾個優勢:首先,它可以應用于CNN的任何任務中,比如目標檢測,人臉識別和語義分割等。其次,濾波器剪枝可以在顯著減少FLOPs、加快推理速度的同時,不會損壞網絡結構。因此,可以利用其它模型壓縮技術(例如,知識蒸餾[10]、量化[8-9])進一步壓縮剪枝后的模型。此外,現有的深度學習庫可以支持濾波器剪枝,而不需要專用硬件和專用軟件。
一些代表性工作[5,12]可以通過計算網絡卷積層中的濾波器Lp范數的值,來衡量相應濾波器的重要性。這種情況下,上述方法對濾波器的參數范數值排序,刪除對應于小范數的不重要的濾波器,得到了較窄的卷積神經網絡。
然而,這些剪枝準則僅僅關注模型參數本身的信息(零階信息),卻忽略了其梯度信息(一階信息)對模型性能的影響,可能會剪去重要的濾波器。即使一些濾波器參數權值很小,但其參數變化對剪枝結果將產生很大的影響,這些梯度大的濾波器是不應該被剪去的。模型的梯度信息對卷積神經網絡來說是十分重要的。在神經網絡中,前向傳遞輸入信號,反向傳播根據誤差來調整各種參數的值,即運用鏈式求導的思想。而且,CNN參數優化的重要算法是根據梯度決定搜索方向的策略。因此,網絡的參數信息和梯度信息可以作為濾波器重要性的評判指標。
為了解決上述剪枝方法的缺陷,根據梯度追蹤算法(GraSP)[13]的思路,本文提出了一種新的濾波器級的剪枝方法。本文將在優化器步驟中實現所提方法,并且在所有卷積層中同時進行剪枝操作。具體地來說,本文方法首先計算濾波器梯度的L1范數值,并對它們進行排序,然后,選擇對應最大梯度值的濾波器索引。隨后,本文算法將該索引和上一次迭代中得到的對應最大權值的濾波器索引聯合,生成了一個包含參數信息和梯度信息的并集。除了參數信息,梯度信息也是衡量濾波器重要性的依據。然后,在該并集上利用隨機梯度下降的動量法(SGDM)[14]更新參數。在每次迭代結束時,計算濾波器權重的L1范數,對它們排序,選擇保留最大范數的濾波器,然后設置小濾波器為零。該剪枝方法允許已經歸零的濾波器在往后的迭代中繼續訓練。本文方法將繼續迭代直到模型收斂。最后,重建網絡,從而獲得了剪枝后的小網絡。
本文的主要貢獻如下所述:
1)提出了一種改進的結構化剪枝方法來壓縮模型。與傳統的剪枝方法相比,采用梯度追蹤算法,創新地使用模型的梯度信息和參數信息來評判濾波器的重要性;
2)與硬剪枝方法[12,15-16]相比,本文方法從頭開始訓練,不需要使用預訓練的模型。因此,不需要剪枝后的微調步驟,省略微調時間;
3)將結構化剪枝算法運用到ResNet模型上,并在基準數據集上進行實驗。結果證明,本文方法能夠在不影響的模型性能情況下,減少網絡參數量和運算量,使得深度卷積神經網絡能在硬件資源受限的環境下部署。
2 網絡剪枝算法
網絡剪枝是模型壓縮的重要技術之一。它可以在神經網絡模型的精度損失忽略不計的情況下,剪去網絡的冗余參數,達到減少過參數化模型的大小和運算量(例如FLOPs)的目的。一般來說,剪枝算法可以分為兩類,即非結構化剪枝和結構化剪枝。
2.1 非結構化剪枝
LeCun等[17]最先開創性地提出了OBD的方法,利用參數的二階導數,來衡量且去除不重要的神經元。但是,以上的剪枝方法并不能應用在深度神經網絡(DNN)上。Han等[11,18]提出一種剪枝方法,在預訓練網絡中剪去那些參數權重低于預定義閾值的連接,然后重新訓練以恢復稀疏模型的準確性。該方法可以在深度神經網絡中縮小模型尺寸。然而,如果剪枝失誤,則無法恢復連接。為了解決以上問題,Guo等[19]提出了一種動態網絡剪枝技術,該方法可以利用剪枝和接合這兩個操作以動態地恢復剪枝后的重要連接,顯著地減少了訓練迭代的次數。Jin等[20]在目標函數上添加L0范數的約束,使得模型更加稀疏。它保留了最大權值的參數,然后重新激活所有的連接。該方法是利用剪枝策略來提升模型精度。
非結構化剪枝主要對模型參數剪枝,但是不能充分利用現有的BLAS庫。在實際應用中,剪枝后的連接是不規則的,所以非結構化剪枝在推理時的加速并不明顯,而且需要專用庫(如cuSPARSE)和專用的硬件平臺。
2.2 結構化剪枝
結構化剪枝能夠剪除整個冗余濾波器,以顯著減少卷積神經網絡的FLOPs,內存空間和運算功耗。
下面是引入可控超參數的剪枝方法:Wen等[21]提出了一個結構化稀疏學習(SSL)的剪枝方法。該方法在損失函數中引入了分組LASSO正則化,來將一些濾波器逐漸歸零。Liu等[22]利用了批量歸一化(BN)層的信息,在目標函數中加入BN層中的縮放因子γ,將γ的L1范數作為懲罰項,然后剪去與較小縮放因子相對應的通道。Ye等[23]針對BN運算中的縮放因子γ,采用了迭代收縮閾值算法(ISTA)來稀疏參數。
還有是按照某個度量標準來衡量某些濾波器是否重要的剪枝方法:Li等[12]在預訓練模型上,對每個濾波器計算卷積核權重的絕對值之和,對其排序,然后剪去其中不重要的濾波器。此方法是基于L1范數來判斷濾波器的重要性。然而,被剪去的濾波器無法在訓練過程中繼續更新參數,從而限制了網絡模型的表達能力。針對這一問題,He等[5]提出了一種軟剪枝(SFP)的方法。該方法剪去L2范數值較小的濾波器,并且從頭開始一邊剪枝一邊訓練。已經剪去的濾波器能夠繼續參與訓練,從而節省了微調步驟的時間。但是,當使用基于范數的剪枝準則時,應該滿足以下兩個條件:范數標準差要大;最小范數接近于零。然而,這兩個條件并不總是成立。因此,He等[24]提出了一個基于濾波器幾何中位數(FPGM)的剪枝準則。該方法選擇與同一層中其它濾波器的歐氏距離之和最小的濾波器,然后將其剪去,從而可以剪去冗余的濾波器。Lin等[25]提出了基于高秩特征圖的濾波器剪枝方法(HRank)。該方法計算每個濾波器的輸出特征圖的平均秩,將其排序,然后對平均秩比較小的相應濾波器進行剪枝。
還有通過重建誤差來確定哪些濾波器需要剪除的方法:Luo等[16]提出了一個ThiNet框架。該框架將通道選擇問題轉化為優化問題的形式,并且在預訓練模型上計算相應的下一層統計信息。它將最小化剪枝前模型和剪枝后模型之間的輸出特征圖上的重建誤差。He等[15]將通道選擇問題轉化為最小二乘法的LASSO回歸問題。
2.3 探討
上述剪枝算法僅僅使用參數信息,所以容易忽略權值很小、梯度卻很大的濾波器。而本文方法既使用模型的參數信息,又使用其梯度信息,能有效減少神經網絡中的冗余參數。本文方法先在當前優化器中選取梯度值較大的濾波器,聯合幅值較大的濾波器,從而得到一個濾波器索引的并集。然后,在該并集上使用隨機梯度下降法更新參數,最后,剪去權值較小的濾波器。本文還使用不同的CNN架構進行大量剪枝實驗,證明了所提方法的有效性與優越性。
3 梯度追蹤的網絡剪枝方法
本節介紹了利用梯度追蹤算法進行結構化剪枝的方法。首先,簡單介紹用于解決稀疏約束優化問題的梯度追蹤算法(GraSP)。然后,針對壓縮深度卷積神經網絡的問題,本文提出了采用GraSP的結構化剪枝方法。
3.1 機器學習的梯度追蹤算法
本文所提出的算法受到梯度追蹤算法(GraSP)[13]的啟發,利用GraSP的思想對CNN進行結構化剪枝。GraSP算法是一種用于近似求解壓縮感知[26]的稀疏約束優化問題的方案。
在3.1節中,x∈d表示一個向量。表示x的稀疏估計值。表示向量x的L0范數(即向量x的非零項個數)。supp(x)表示向量x的支撐集(即x的非零項索引)。A∪B表示集合A和集合B的并集。T表示集合T的補集。bk表示向量b的最大k項(按幅值大小)。
為了最小化目標函數f(x),GraSP算法考慮以下稀疏約束的優化問題

(1)

算法1.梯度追蹤算法。
輸入:f(·)與k。
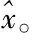
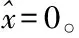
repeat

選擇z中2k個最大值:Z=supp(z2k);
在該并集上最小化:b=arg minf(x) s.t.x|T=0;
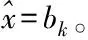
until 參數收斂。

3.2 梯度追蹤的結構化剪枝算法
結構化剪枝可以有效地壓縮加速網絡,而且不會破壞網絡模型結構。
如3.1節所述,GraSP[13]將梯度最大的信號與幅值最大的信號聯合,從而解決壓縮感知的稀疏約束優化問題。而本文算法將GraSP的思路創新地應用到CNN結構化剪枝中。與基于參數信息的剪枝算法[5,12]相比,本文算法使用CNN的梯度信息和參數信息來評判濾波器的重要性,剪去被判為不重要的濾波器。這有助于提升結構化剪枝的效果。
在CNN模型中,令i作為卷積層索引。網絡參數則表示為{Wi∈Ni+1×Ni×K×K,1≤i≤L},其中,Wi表示第i個卷積層中的參數權重矩陣。Ni表示第i層的輸入通道數,Ni+1表示第i層的輸出通道數。K×K表示卷積核的大小。L表示網絡中卷積層個數。剪枝率Pi表示第i個卷積層中剪去的濾波器的比例。Wi,j∈Ni×K×K表示第i個卷積層的第j個濾波器。nonzero(x)表示x中非零元素的位置(索引)。topk(x)表示x中k個最大項索引。
本文定義Lp范數如下所示

(2)
其中,Ni是第i個卷積層中的輸入通道數。梯度追蹤的結構化剪枝方法根據計算濾波器的L1范數,以此評估濾波器的重要性。本文通過Ni+1(1-Pi)來計算k,本文方法在所有卷積層中使用相同的剪枝率Pi。

圖1 梯度追蹤的結構化剪枝方法的框架圖
圖1清晰地概述了如何將GraSP的原理推廣到結構化剪枝的流程框架。在圖1中,k表示某個卷積層中剪枝后剩余的濾波器數目。大的方框表示某卷積層中的濾波器空間。在濾波器空間中,黃色框表示k個最大L1范數的濾波器,綠色框表示k個最大梯度的濾波器,白色框表示其余的濾波器,虛線框表示濾波器設置為零。在某個卷積層中,W表示參數權重矩陣,g表示梯度矩陣。本文方法選擇k個梯度最大的濾波器,再將其索引與在上一次迭代中得到的濾波器支撐集聯合成一個并集。然后,本文算法在該并集上更新參數。在每次迭代結束時,該算法選擇權值最大的濾波器,最后剪去小濾波器。
算法2詳細地描述了梯度追蹤的結構化剪枝算法。本文所提的方法將從頭開始訓練CNN,在所有卷積層中同時進行剪枝操作。
算法2.梯度追蹤的結構化剪枝算法。
輸入:訓練數據X,剪枝率Pi,學習率η,CNN模型參數W={Wi,1≤i≤L},卷積層的層數L。
輸出:剪枝后模型,和它的參數W*。
隨機初始化網絡參數。
for each step=0 to stepmaxdo
計算當前梯度:g=?f(Wstep);
for each i=0 to L do
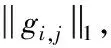



end for
end for
重建剪枝后的模型,最終得到一個小網絡W*。
首先,隨機初始化模型參數,本文方法在優化器步驟中迭代地進行剪枝過程。
在第step次迭代中,f(Wstep)是當前的損失函數。該算法通過反向傳播計算當前梯度g
g=?f(Wstep)
(3)
然后,計算gi,j的L1范數,對其進行排序,在向量gi中選擇k個梯度最大范數值的濾波器索引,如下式(4)所示。其中,gi,j表示在第i層中第j個濾波器對應的梯度。
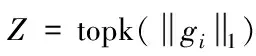
(4)

之后,將式(4)中的索引Z與當前參數的權值Wstep的支撐集聯合,從而獲得一個并集T,如下所示

(5)



(6)


本文算法將一直迭代,直到模型參數收斂。最后,該算法重建剪枝后的網絡,生成小模型。
綜上所述,本文方法使用梯度學習,考慮了模型的參數信息和梯度信息的聯合影響,從而能在剪枝后有效保留模型的重要信息。
4 實驗結果與分析
為了驗證本文所提算法的有效性,本文在三個標準數據集(即MNIST[27],CIFAR-10[28]和CIFAR-100[28])上,使用梯度追蹤的結構化剪枝方法,對幾種常見的CNNs進行剪枝實驗,并將該算法與一些當前已經提出的剪枝技術進行比較。本文使用所提出的剪枝方法在MNIST上對LeNet-5[27]模型、在CIFAR-10和CIFAR-100對ResNet[4]進行剪枝實驗,從而壓縮神經網絡。本文的實驗使用Pytorch[29]深度學習框架,在型號為NVIDIA GeForce GTX 1080Ti的GPU上運行程序。本文算法在優化器步驟中迭代地執行剪枝操作,在所有卷積層中同時進行濾波器剪枝。為了進行比較,實驗關注剪枝率、精度變化以及FLOPs。使用Top-1準確率來衡量基線模型和剪枝后模型的性能。剪枝率是剪枝后的網絡與原始網絡在參數量上相比減少的百分比。FLOPs是每秒浮點運算次數,FLOPs減少表示網絡運算速度得到了加速。同樣地,本文將所有剪枝算法的最好的實驗結果用粗體表示。
在4.1節和4.2節中,本文介紹了三個圖像分類的標準數據集和實驗設置。然后在4.3節、4.4節和4.5節中,本文在三個標準數據集上進行結構化剪枝實驗,將本文算法的結果與其它剪枝算法進行比較,驗證了本文算法的性能。在4.6節中的消融實驗研究了不同的剪枝策略以及不同Lp標準對剪枝實驗的影響。4.7節證明了本文方法也可以應用于非結構化剪枝。
4.1 數據集
MNIST[27]是一個手寫數字的通用數據集,其中包含了60,000個訓練集樣本和10,000個測試集樣本。
CIFAR-10[28]是一個用于識別目標的小型數據集,包含了60,000張分辨率為32×32的彩色圖像。它分為10個類別,包含了50,000訓練圖像和10,000測試圖像。CIFAR-100[28]與CIFAR-10數據集類似。它有100個類別,每個類有600張圖片。
4.2 實驗設置
首先,本文在數據集MNIST上對LeNet-5模型進行實驗。LeNet-5[27]是一種典型的CNN模型,它由兩個卷積層和兩個全連接層組成,具有431,000個可學習參數。對于MNIST實驗,本文使用SGDM[14]算法,其動量系數β設置為0.9,權重衰減為0.0005。本文算法從頭開始訓練200個epoch,批量數據樣本數為64。實驗初始學習率為0.01。在epoch為60、120和160的時候,學習率η乘以0.2。
在CIFAR-10和CIFAR-100的實驗中,本文對ResNet-20、32、56和110模型進行剪枝。SGDM[14]所使用的動量系數β為0.9,權重衰減為0.0005。本文使用梯度追蹤的結構化剪枝方法從頭開始訓練所有模型,一共訓練250個epoch,批量數據樣本數為128。在第1、40、120、160和200個epoch時,學習率η將分別設為0.1、0.02、0.004、0.0008、0.0002。
特別地,對于CIFAR-10實驗,本文方法將與以下方法進行定量比較:濾波器剪枝(L1-pruning-A,L1-pruning-B)[12]、Channel-pruning[15]、More is Less(LCCL)[30]、軟剪枝(SFP)[5]、HRank[25]、FPGM[24]。其中,Li等[12]認為,ResNet模型的一些特定的卷積層對剪枝十分敏感,比如ResNet-56的第20、38和54層,或者ResNet-110的第36、38和74層。因此,它們跳過上述的卷積層,修剪其它層的10%的濾波器,這就是L1-pruning-A[12]。而Li等提出的L1-pruning-B[12]在不同階段使用不同的剪枝率。在ResNet-56中,L1-pruning-B跳過更多的卷積層(16,18,20,34,38,54),同時第一階段每個卷積層的剪枝率為60%,第二階段的剪枝率為30%,第三階段剪枝率為10%。在ResNet-110中,L1-pruning-B跳過第36、38和74層,第一階段剪枝率為50%,第二階段剪枝率為40%,第三階段剪枝率為30%。FPGM-only[24]表示只使用基于濾波器幾何中位數(FPGM)的剪枝準則,那么,FPGM-mix[24]就將FPGM同基于范數的剪枝準則相結合。
4.3 數據集MNIST的剪枝實驗結果

表1 在MNIST數據集上本文方法對LeNet-5剪枝的實驗結果
本文算法在MNIST數據集上對LeNet-5模型中的兩個卷積層進行結構化剪枝。實驗中使用的剪枝率為10%、20%、30%、40%、50%、60%、70%和80%。表1表示了在MNIST數據集上LeNet-5模型的結構化剪枝結果。實驗結果表明,在剪去兩個卷積層的50%的濾波器的情況下,本文方法Top-1準確率僅僅降低了0.12%。此外,本文方法可以在保持分類準確率的情況下,甚至可以剪去80%的濾波器。
因此,本文通過在MNIST上的實驗初步證明了該算法的實用性和有效性,驗證了GraSP的原理可以應用在CNNs上,同時使用梯度信息和參數信息的方法能夠有效地進行結構化剪枝。在以下的4.4節中,將在更深的卷積神經網絡模型上(例如ResNet)上進一步實現本文方法,并將該剪枝算法與其它剪枝方法進行比較。
4.4 數據集CIFAR-10的剪枝實驗結果
對于在CIFAR-10上的實驗,本文算法對ResNet-20、32、56和110模型按照五個不同的剪枝率進行剪枝操作。
表2中表示了在CIFAR-10上的實驗結果。該實驗將本文算法與4.2節列出的對比方法進行比較。對比算法的結果都在相應論文中有所體現。
例如,ResNet-56模型的剪枝實驗中,當具有微調步驟的HRank[25]剪去50%的FLOPs時,剪枝后結果比基準精度減少了0.09%;在剪枝后的FLOPs減少了52.63%的情況下,具有微調步驟的FPGM-mix[24]方法的準確率下降了0.33%;而本文方法沒有微調步驟,在FLOPs減少量為52.63%的情況下,其準確率僅僅下降了0.04%。從實驗結果來看,本文的方法能有效地對殘差網絡進行剪枝,而且不需要微調步驟,能夠節省訓練時間。
在ResNet-110的實驗中,當具有微調步驟的L1-pruning-B[12]剪去38.60%的FLOPs時,其Top-1準確率為93.30%;而LCCL[30]在剪去34.21%的FLOPs時,獲得了93.44%的精度;當沒有微調步驟的本文方法剪去40.78%的FLOPs時,其準確率為94.18%,比起原始模型提高了0.01%。因此,上述結果表明,本文算法使用了基于梯度和參數聯合的剪枝準則,從而提供了比其它剪枝算法更為出色的性能,能夠在追求高精度和模型壓縮之間取得了更好的平衡。

表2 在CIFAR-10數據集上對ResNet剪枝的比較結果
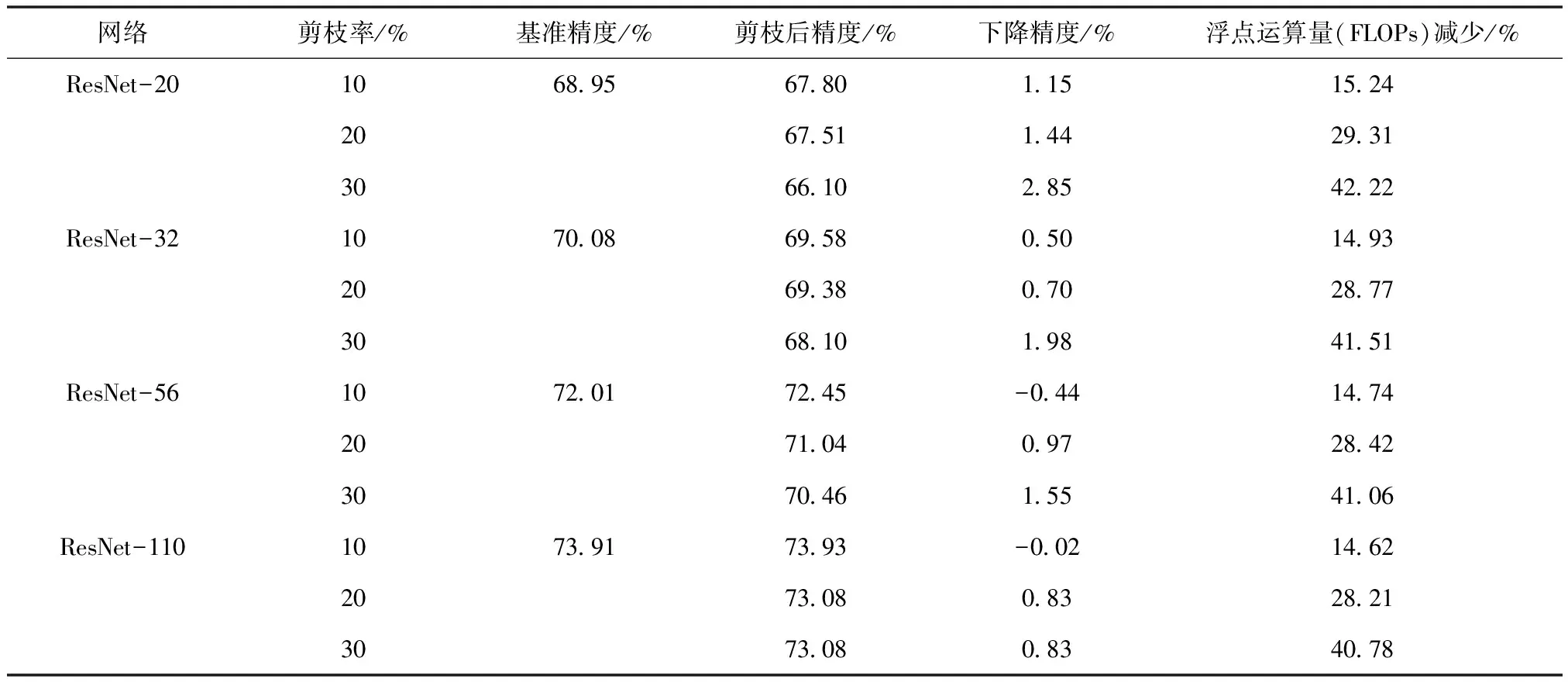
表3 在CIFAR-100數據集上利用本文方法對ResNet模型用不同剪枝率進行濾波器剪枝
4.5 數據集CIFAR-100的剪枝實驗結果
本節在CIFAR-100數據集上對ResNet-20、32、56和110模型使用本文算法進行結構化剪枝實驗。如表3所述,在CIFAR-100對ResNet-56剪枝的實驗中,本文算法在剪去14.74%的FLOPs時,獲得了72.45%的準確率,甚至比剪枝前提高了0.44%。實驗結果說明了本文算法能夠有效緩解模型過擬合,提高模型精度。
在ResNet-110剪枝的實驗中,當剪去40.78%的FLOPs時,本文算法可以獲得73.08%的Top-1準確率,比剪枝前的基準精度僅僅降低了0.83%。
綜上所述,本節通過在CIFAR-100數據集的剪枝實驗,證明了本文方法有助于確定在某一卷積層中保留哪些濾波器。
4.6 消融實驗
為了研究本文方法中不同要素對剪枝結果的影響,本文對ResNet-56在CIFAR-10數據集上的結構化剪枝實驗進行消融研究。
4.6.1 剪枝方法的選擇
首先,本文研究基于參數信息和梯度信息的策略對剪枝結果的影響。本文在CIFAR-10數據集上對ResNet-56模型進行消融實驗。該實驗增加了兩個剪枝策略與本文方法比較:①保留梯度的范數值大的濾波器,即只使用梯度信息的剪枝準則;②保留參數的范數值大的濾波器,即只使用參數信息的剪枝準則。
表4總結了不同剪枝方法的選擇對實驗結果的影響。原始模型的基準精度為93.43%。表4中剪枝率的設置與表2的ResNet-56部分相同。在使用CIFAR-10數據集進行剪枝的實驗中,當剪去40%的參數時,FLOPs減少了52.63%,只使用梯度信息的剪枝方法的準確率為92.59%,證明了梯度信息可以作為評判濾波器重要性的標準。只使用參數信息的剪枝方法的準確率為93.09%,而把兩個信息結合的本文方法的Top-1準確率為93.39%。與只利用參數信息的方法和只利用梯度信息的剪枝方法相比,本文算法的性能更為優越。因此可以從該實驗看出,把參數信息和梯度信息結合起來,能更好地剪去冗余的濾波器。
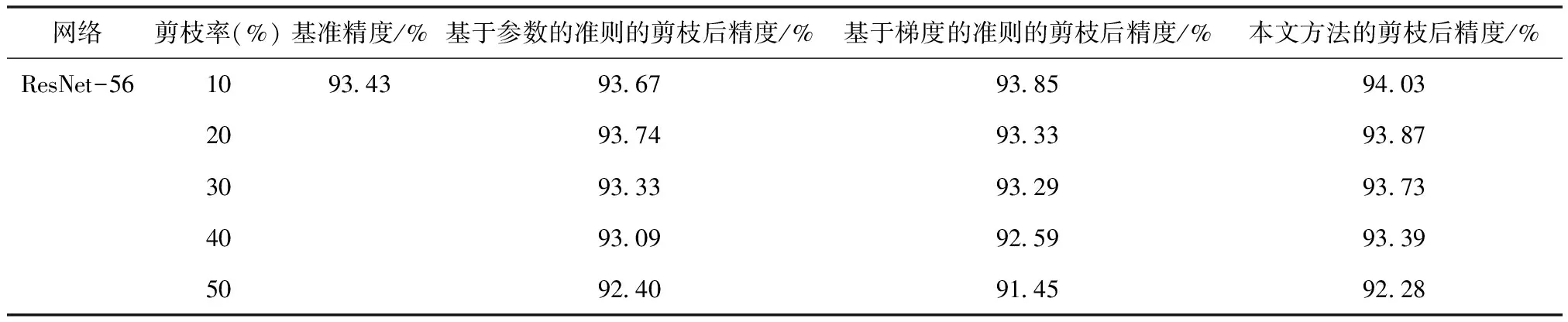
表4 在CIFAR-10數據集上對ResNet-56模型使用不同剪枝準則的實驗結果
4.6.2 Lp范數的選擇
為了研究不同Lp范數計算對估計濾波器重要性的影響,本文在CIFAR-10數據集上對ResNet-56模型進行剪枝實驗。在此,本文使用L1范數的剪枝方法和使用L2范數的剪枝方法進行對比。
表5將L1范數與L2范數這種評估濾波器重要性的剪枝標準進行比較。對于在CIFAR-10數據集上修剪ResNet-56的實驗,當剪枝率為40%時,FLOPs減少了52.63%,L2范數標準的準確率為93.04%,L1范數的準確率為93.39%。可以看出,使用L1范數比使用L2范數更為優越。所以,本文方法是使用L1范數來評估濾波器的重要性,然后剪去L1范數小的濾波器。

表5 在CIFAR-10數據集上對ResNet-56模型使用不同范數約束的實驗結果
4.7 本文算法在非結構化剪枝的應用
最后,本文所提出的算法也能夠應用于非結構化剪枝。
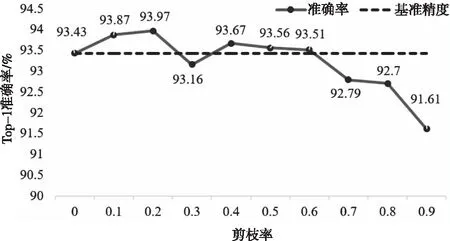
圖2 在CIFAR-10數據集上的ResNet-56不同剪枝率的非結構化剪枝結果
圖2表示了在CIFAR-10數據集上不同剪枝率對ResNet-56模型進行的非結構化剪枝實驗結果。圖中的基準精度為稠密網絡的基準精度。x軸剪枝率為0.1時,網絡的剪枝率為10%。對于該剪枝實驗,當剪枝率為20%,本文方法能夠得到93.97%的準確率,甚至比基準精度提升了0.54%。而且,當剪枝率為10%、20%、40%、50%以及60%時,剪枝后網絡的精度超過了基準精度,本文方法能使CNN的性能有所提升。當卷積層上的非結構化剪枝率為80%,本文方法能夠得到92.70%的Top-1準確率,與基準精度相比僅僅下降了0.73%。
因此,可以從實驗結果看出,本文方法能夠應用在非結構化剪枝中。當剪枝率非常高時,所提方法可以保持網絡性能。
5 結語
1)本文提出了一種新的剪枝算法,它利用梯度追蹤算法對CNN進行濾波器剪枝。該剪枝算法使用了CNN的一階信息和零階信息。其主要思路是:在每次迭代開始時,計算參數梯度的范數值,將梯度最大的濾波器索引與上一次迭代時保留的權值最大的濾波器索引結合,形成并集;然后在該并集上使用梯度下降法更新參數;在每次迭代結束時,通過計算每個濾波器的范數值,選擇且保留權值最大的濾波器;以上步驟將一直迭代至收斂;最后,獲得壓縮后的模型。
2)在基準數據集上的幾個剪枝實驗表明,該算法能夠在模型精度幾乎不變的情況下,使用比較高的剪枝率對卷積神經網絡進行壓縮,從而有助于CNN的實際部署工作。例如,在CIFAR-10數據集上修剪ResNet-56的實驗中,所提算法在不進行微調的情況下,減少52.63%的FLOPs,而準確率僅僅降低0.04%。所提方法的性能明顯高于當前方法。
3)實驗表明,本文也可以將梯度追蹤算法應用在神經網絡的非結構化剪枝中。
在往后的工作中,將考慮使用其它的復雜數據集進行進一步研究。同時,將嘗試與其它網絡壓縮方法結合,完善該算法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
