基于AWDE算法的整周模糊度解算算法
2022-09-28 09:53:04鄧洪高紀元法孫希延
計算機仿真 2022年8期
鄧洪高,程 歸,紀元法,孫希延
(桂林電子科技大學,廣西 桂林 541004)
1 引言
隨著北斗全球組網的成功,中國的衛星導航定位技術進一步提升。然而,在利用衛星通過載波相位實現高精度定位時,載波相位的整數部分是一個未知的隨機整數,稱為整周模糊度,需要在計算載波相位之前進行固定[1]。根據國際大地測量協會的統計,早在20世紀80年代初,整周模糊度的解算方法就已經被提出[2]。在1981年,Counselman提出了模糊度函數法(Ambiguity Function Method,AFM),該方法具有對周跳不敏感的優點,但是計算效率有待提升[3];靜態模糊度快速解法(Fast Ambiguity Resolution Approach,FARA)是E.Frei和G.Beutler提出的,采用數理統計代進行數據預處理,在靜態處理上有著顯著效果,但是該方法在動態處理中并不適用[4]。LAMBDA(Least-Square Ambiguity Decorrelation Adjustment)算法是由Teunissen提出的經典算法[5,6],LAMBDA算法具有良好的解算能力,但是算法中的搜索部分屬于遍歷搜索,搜索效率可以進一步提高;在Teunissen的基礎上,后人針對搜索效率問題提出MLAMBDA-LAMBDA算法[7],有效提高了整周模糊度的解算效率。由于整數模糊度的解決方案是從實數區域到整數區域的非線性映射,所以可以圍繞浮點解設置一個整數解決方案集合,使用全局搜索來固定整周模糊度。本文基于標準差分進化算法(Differential Evolution Algorithm,DE)的強大全局搜索能力和快速收斂能力,對差分算子進行了自適應調整,避免了早熟,中斷等問題,并通過ratio值對搜索完成的固定解進行質量檢驗。
2 載波相位雙差模型
2.1 構建載波相位雙差模型
在GNSS精密定位中,假設有衛星信號接收機r,b,在某時刻同時觀測到i,j兩顆衛星,則雙差觀測方程如下

(1)
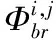

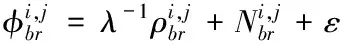
(2)
通過雙差觀測模型可知,一個雙差載波相位觀測方程有3個未知數,而每多一個共視衛星將會多一個雙差整周模糊度,所以,在可用共視衛星較多的情況下,會導致多維整周模糊度,而多維整周模糊度的解算也是一個難點。
2.2 浮點解求解與處理

同時,對于短基線的實時定位來說,事先利用精密測量取得基線向量的精確值,可以有效地縮小搜索空間范圍[10]。在基線長度為l對應的雙差整周模糊度的取值范圍如下

(3)


(4)

(5)

圖1 定位流程簡圖
3 自適應加權的DE算法
3.1 標準DE算法
DE算法是由Kenneth Price和Rainer Storn最先提出的,其本身是一種隨機模型,通過反復迭代以保存適應環境的個體。同時,DE特殊的記憶能力使其可以動態跟蹤當前的搜索情況調整其搜索策略,具有較強的全局收斂能力和魯棒性[11]。標準DE算法的主要流程如下:
1) 初始化
首先確定差分算法的控制參數,包括種群大小Popsize,最大迭代數Max_generation,加權因子F和交叉概率CR。
2) 編碼
實數編碼是DE算法的特點所在,相較于二進制編碼,兩者均能夠有效的搜索的雙差整周模糊度固定值,但二進制編碼無法反映問題本身的固有結構特點,個體長度較大,穩定性低于實數編碼,也無法避免hamming懸崖問題。
3) 適應度函數
適應度函數是利用最小二乘準則,用模糊度浮點解去擬合固定解,使得浮點解達到在最小二乘準則下整數最優。在最小二乘準則下,代價函數為

(6)
適應度函數為
f(N)=b-lg(J(N))
(7)
4) 變異
一個變異個體的產生是根據變異公式vi,g=xr1,g+Fi,g*(xr2,g-xr3g),其中i≠r1≠r2≠r3,F是控制差異變化的整數常量,通常取值為[0,2];
5) 交叉
6) 選擇

7) 更新
將更新之后的個體作為新的種群,重新迭代,重復4-7,直到滿足終止條件或者最大迭代數。
3.2 標準DE算法中存在的問題
DE算法是根據父代個體間的差分矢量進行變異、交叉和選擇操作,盡管在非線性優化問題上有強穩健性,但是同樣容易由于本身的最優聚集性質而陷入早熟。當算法控制參數F,CR等設置不當的時候,一旦將其應用于整周模糊度解算中,即便是單頻單模情況下,即模糊度維數較低的情況下,也會陷入早熟或者停滯問題。而在實際情況中,衛星數目的更迭導致模糊度維數的變化對于標準DE算法而言,更是無法適用。針對以上問題,提出了一種新的AWDE算法。
3.3 AWDE算法
新的AWDE算法,在進行固定模糊度之前,先對浮點解與協方差矩陣進行降相關處理,以增加算法的搜索效率;在DE算法之中,對迭代情況進行實時的評估,變異算子,交叉算子,種群大小均是隨著種群適應度進行自適應調整。在搜索開始,變異和交叉算子較大,較大交叉算子和種群能夠使得全局搜索的范圍更大,較大的變異算子能夠豐富種群多樣性;而在迭代后期,種群所有個體的適應度都較高,此時,較小的交叉算子變異算子能夠使迭代更快收斂,較小種群數量能夠使得種群迭代的速度更快。在算法搜索完成之時,對此時的搜索值進行ratio值檢驗,用于判斷算法是否陷入局部最優解。具體改進如下:
1)降相關
采用DE算法的實質是從搜索近似全局最優解來代替最優解,所以浮點解之間的強相關性將使搜索過程變得復雜。本文采用逆整數Cholesky變換對協方差矩陣進行降相關處理,在進行降相關處理后,適應度函數分布由原本的非單調函數變成了只有一個極值的單調函數[12],從而降低了算法陷入局部最優的可能性。
2)變異
變異式vi,g=xr1,g+Fi,g*(xr2,g-xr3g),更一般的可以寫成如下形式
vi,g=Ai,g*xr1,g+Fi,g*(xr2,g-xr3g)
(8)
式中,i和r代表種群中的個體,g是迭代次數;Ai,g是對個體xr1,g的加權因子;于是針對于加權因子Ai,g和Fi,g提出的自適應改進為

(9)
Fi,g=0.5*(1.5-pi,g)
(10)
其中,i=[1,2,…,Popsize],Popsize是種群大小,g是迭代數,ni是第i個個體未更新的次數,max是個體允許的最大未更新次數。其中pi,g的值為

(11)
其中,maxF(xg)代表在第g代中,最優個體的適應度函數值。通過pi,g來對種群適應度情況進行判斷。對加權因子Fi,g的變化可以使得算法在種群整體適應度較差時,將變異個體迅速重新迭代得到更好的變異個體;而在種群適應度好的時候,可以使得變異個體與原個體差別減小,從而使得算法快速收斂。
3)交叉
標準DE算法采用的是貪婪策略。貪婪策略雖然有利于加快算法的收斂速度,但是其本質是逐漸向某最優值靠攏,導致了種群多樣性的減小,即導致了早熟收斂的風險。好的搜索策略應該是在搜索初期保持著搜索空間的完整性,以確保包含最優解,而在搜索階段的后期,應當加快搜索能力,增加搜索效率。新的交叉策略如下:
CR=CRmin+time(CRmax-CRmin)/Max_generation
(12)
式子中CRmin為最大交叉率,CRmax為最小交叉率,time為當前迭代次數,Max_generation為最大迭代次數。
4)種群大小變化
由于在解算整周模糊度固定解時,每個歷元所觀測到的衛星數是變化的,而可用共視衛星數目越多,所形成的雙差載波相位方程也就越多,浮點解的維數也就越多。在模糊度搜索過程中,高維問題一直是難點。在DE算法中,不確定的浮點解意味著不確定的個體維數,當種群數量較小,浮點解維數較高時,極易陷入局部最優解;雖然可以通過增大種群數量解決這一問題,但是種群數量過大時,又會導致搜索效率降低。在本文中,初始種群數量的大小由個體維數確定,即popsize = 4*Dim,同時初始種群的分布采用均勻設計,后續種群數量將隨著種群適應度的提高而縮小。
5)質量控制
由于智能優化算法本身是通過交叉,變異等方法去用全局近似最優解去擬合全局最優解,這就導致了算法本身具有一定的不確定性。而在實際情況下,由于可用共視衛星變動導致雙差整周模糊度維數的頻繁變化在一定程度上增大了這種不確定性。所以,解算之后的質量檢測尤為重要。Ratio值檢驗法是以固定解中次優解和最優解的殘差平方和的比值作為檢驗值,將其與設定的閾值比較,閾值通常取2或3,當ratio值大于閾值時,判定模糊度固定解正確[13]。

圖2 AWDE算法流程圖
4 算例與分析
4.1 算例1(3維情況下六種算法對比試驗)
本例將對上述六種模糊度固定方法進行仿真,比較相互的解算性能。選取3維的雙差載波相位方程的模糊度浮點解和協方差矩陣為
通過高斯整數變換進行降相關之后,浮點解和協方差矩陣為:
初始種群大小為Popsize=4*3=12,DE算法終止迭代數為50,基線長度為1米,遺傳算法終止迭代數為100,利用簡單遺傳算法GA,自適應遺傳算法AGA,LAMBDA算法MLAMBDA-LAMBDA算法,標準DE算法和AWDE算法對整周模糊度進行搜索和比較。仿真結果如下圖所示。

圖3 簡單GA算法 圖4 AGA算法注:圖中紅色表示最大適應度,綠色表示平均適應度,藍色表示最小適應度,下圖一致
簡單遺傳算法的參數需要在解算整周模糊度之前需要根據模糊度浮點解和協方差矩陣進行適應性調整,當參數不合適時,算法效果十分差。而且由于其遺傳算子的值是固定值,沒有辦法隨著迭代而更新,導致算法容易陷入停滯與早熟;在算法迭代至最優值解時,又無法及時降低交叉變異概率,增加了解算時間。經過對遺傳算子進行自適應調整之后,算法能夠準確的迭代出全局最優解,但是搜索效率和成功率還有提升空間。

圖5 DE算法(未降相關) 圖6 DE算法(降相關)
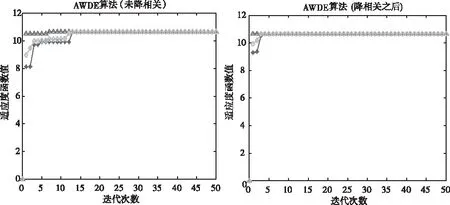
圖7 AWDE(未降相關) 圖8 AWDE(降相關)
通過對標準DE算法和AWDE算法分別進行了降相關和未降相關的比較,如圖5,6,7,8所示。在經過降相關之后,標準DE算法的收斂代數由23代左右升級到了17代左右,AWDE算法由12代升級到了7代左右。從圖中可以明顯看出,在經過降相關之后,AWDE算法的最小適應度并未陷入局部最優,減少了解算時間,提高了搜索效率。
在采用自適應加權的DE算法之后,對于3維雙差整周模糊度,在10次迭代以內就能準確解算出全局最優解,算法具有良好的全局搜索能力和較快的收斂速度。即使在未降相關的情況下,也不會陷入局部最優解。
為了準確統計算法的準確性和可靠性,對3維雙差整周模糊度用以上六種算法進行100次的重復試驗,最大迭代次數為50代。對比各算法的解算時間與解算成功率,統計結果如表1所示。

表1 六種算法對比情況
為了更加直觀的展示每一次試驗的解算時間,將DE,AWDE,AGA算法的運算時間用柱狀圖顯示如圖9所示。
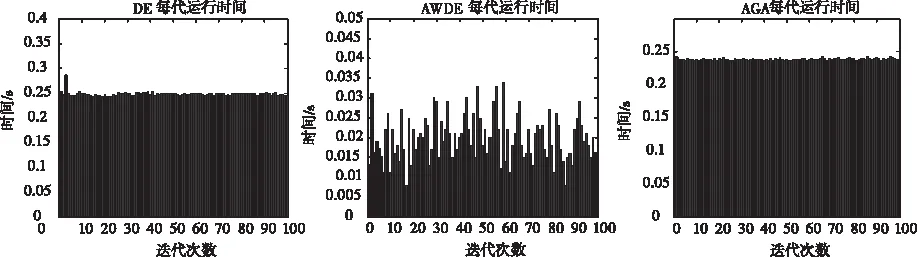
圖9 各算法運行時間比較圖
從上面的圖表可知,在六種算法中,AWDE算法有著99%的解算成功率和0.0142秒的解算時間。而GA算法由于本身的不穩定,統計結果無效,DE算法的成功率只有86%,AGA算法的成功率達到了96%,但是平均解算時間到了0.2459秒。AWDE相對于LAMBDA算法和MLABDA-LAMBDA算法,解算成功率相差無幾,但是解算時間比LAMBDA和MLABDA-LAMBDA算法分別快了0.0479秒和0.0083秒。
同時,在AWDE算法中加入了ratio值檢驗,檢驗閾值為2,當每次檢驗的ratio值大于或等于閾值時,代表固定解可用。在本次的100次重復實驗中,檢驗結果如圖所示,在100次的迭代試驗中,只有剛開始的第一次ratio值小于檢驗閾值,解算成功率達到了99%。

圖10 3維下的AWDE算法100代ratio檢驗
4.2 算例2(多維解算實驗)
對于目前最常用的單頻接收機ublox接收機來說,為保證低成本與高精度,通常采用單頻雙模工作模式,理論上最大衛星數為59顆(北斗35顆,GPS24顆),而在實際觀測中,單頻雙模接收機能夠獲得20顆左右的可用共視衛星。

圖7 一天內觀測到的衛星數
而隨著可用共視衛星的增多,意味著浮點解維數的增加,對固定模糊度的難度增加。所以在此算例中選取了3維,6維,12維的雙差模糊度進行解算速度和可靠性的比較,其中3維浮點解與算例1一致。6維浮點解和12維浮點解分別為:
9.9955 -43.0015]T
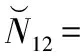
-297.6589 -22201 51236 30258 3899.4
-22749 -159.2788]T
解算結果如下所示:

圖12 6維AWDE 圖13 12維AWDE

表2 AWED算法在不同維數下的比較
通過上述圖表可以看出,隨著維數的增長,雙差整周模糊度的解算難度增加。6維,12維的平均收斂代數變成了11代和20代,解算時間也由3維的0.0142秒增長到0.0352秒和0.1659秒,解算成功率有稍微下降,但是解算速度和精度依舊能夠滿足解算的實時性。
5 結語
DE算法具有很強的全局搜索能力和極快收斂速度,但是由于本身的貪婪算法和差分加權本質上屬于尋優迭代,且本身的變異,交叉因子,種群數量均是定值,無法滿足實際解算中的變化情況,更無法適應雙模甚至三模情況下的多維模糊度情況。本文針對整周模糊度解算問題對迭代算子進行自適應優化,并通過ratio值進行解算質量控制。實驗結果表明,改進后的AWDE算法在有效性和穩定性方面均有不錯的表現。
