基于卷積神經網絡的腦電情緒識別方法
2022-09-28 09:28:44廉小親羅志宏蔡沫豪
計算機仿真 2022年8期
廉小親,羅志宏,蔡沫豪,高 超*
(1. 北京工商大學人工智能學院,北京 100048;2. 北京工商大學中國輕工業工業互聯網與大數據重點實驗室,北京 100048)
1 引言
情緒是人當前精神狀態的直接反映,在人做理性決策、交流和學習的過程中都有至關重要的影響[1]。通過對情感狀態的識別,可以幫助人們管理自身的心理健康,提升工作效率,幫助更多需要心理治療的人認清自身需要調節的地方[2]。但是,平常人們對于自己情緒的判斷都是帶有主觀色彩的,難以客觀地評估自身的真實情感狀態。因此,基于多數研究者使用的腦電信號(Electroencephalogram,EEG)[3],建立一個客觀的情緒識別方法來進行情緒分類尤為重要。
基于目前學者的研究,情緒大多是在Lang二維情緒模型[4]的基礎上進行識別分類的。該模型是一個二維平面模型,通過定義效價(Valence)和喚醒度(Arousal)兩個評判基準作為平面上的橫縱軸,在該平面上表征了所有的情緒類別。目前的研究多是針對效價和喚醒度分別設置閾值進行情緒二分類,分類的方法主要有以下兩種。
一種方法是將腦電信號進行特征提取以減小數據量,之后借助提取的特征建立淺層神經網絡來進行情緒分類。比如王雪芹等人[5]提取了腦電信號在時域、頻域以及熵值三個方面的特征,從特征融合與決策融合兩個角度進行情緒識別,并在效價、喚醒度兩個層面上進行情緒二分類,平均準確率達到72.01%;劉珂等人[6]先采用MI互信息矩陣進行腦電信號的特征提取,后采用SVM、FLDA、KNN等方法在效價、喚醒度兩個層面上進行情緒二分類,平均準確率為68.85%;周豐豐、朱海洋[7]針對腦電信號分別提取時域、頻域以及空間域特征,采用三段式特征選擇策略進行特征篩選,最后使用SVM進行情緒二分類,平均準確率為71.00%。
另一種主要的分類方法是基于端到端的深度學習模型,將腦電信號進行預處理后直接輸入到深度神經網絡進行訓練,該方法無需復雜的特征提取方法。比如 Li X等人[8]基于小波變換將腦電信號轉換為網格狀幀后,將其輸入卷積神經網絡與遞歸神經網絡的融合模型進行情緒二分類,平均準確率達到73.12%;闞威、李云[9]利用預處理后的時序腦電信號訓練LSTM情緒二分類器,平均準確率為73.75%;Yang Y等人[10]對腦電信號進行了一維至二維的轉換,并將其輸入設計好的并行CNN與RNN的融合模型進行情緒二分類,平均準確率為91.01%;程程[11]基于分層卷積模型依次提取腦電信號的局部卷積特征,并分別在效價、喚醒度兩個層面上實現了情緒二分類,平均準確率為83.86%,之后通過優化腦電波波段和采集通道將準確率提高至91.55%。
但是,以上情緒二分類的方法都是基于復雜的腦電信號預處理方法以及復雜的深度學習模型實現的,在訓練和實際進行識別操作的時候時間成本較高。考慮到Lang二維情緒模型是建立在效價和喚醒度兩個維度上的,而前人做的二分類識別只是針對其中一個維度進行閾值二分類,無法對具體的情緒做到細粒度的識別。針對此問題,Zheng Weilong等人[12]在Lang情緒模型的基礎上,首先采用微分熵對腦電信號進行特征提取、線性動態系統(LDS)方法進行特征優化、最小冗余最大相關(MRMR)進行數據降維,隨后使用極限學習機(GELM)進行效價、喚醒度相結合的情緒四分類,平均準確率為69.67%。
針對目前情緒識別方法大多只關注相對簡單的二分類問題,在更為精細、復雜的四分類問題上存在準確率不高、模型較為復雜的問題,本文通過調研,結合腦電電極的空間分布特征進行腦電信號重構,并設計輕量化的卷積神經網絡模型進行情緒四分類,最終實現對情緒的細粒度識別.
2 腦電信號數據集處理
2.1 DEAP數據集
為了便于與前人的研究成果進行對比分析,本文采用DEAP(database for emotion analysis using physiological signals)公開數據集作為實驗數據。該數據集是由Sanders Koelstra等[13]建立的公開情感數據集,包括了16名男性和16名女性被試者的腦電數據。被試者佩戴符合10-20國際標準的32導聯電極帽,以512Hz的頻率進行EEG信號采樣。被試者在觀看完40段時長為1分鐘的刺激視頻后,被要求以浮點數的形式(數值范圍1-9),在效價(Valence)、喚醒度(Arousal)、優勢度(Dominance)以及喜好度(Liking)四個方面對視頻觀后感做一個相對客觀的評價,實驗人員將該評價結果作為對應視頻的樣本標簽進行記錄。本文采用的實驗數據為官方降采樣至128Hz后進行4-45Hz帶通濾波且去除眼電及其它肌電信號后的數據,本文依據Lang二維模型,采用官方記錄四個標簽值中的效價、喚醒度作為本文的評價標準。
2.2 數據集預處理
文獻[14]的研究結果表明相同情緒的腦電信號在個體之間存在差異性,因此情緒分類模型的建立需要以個人為單位,即一個人對應一個模型。由于DEAP數據集的被試者僅僅觀看了40段視頻后作出評價,因此針對每個被試者只得到了40組數據和標簽作為樣本,該原始數據集較小且難以滿足深度學習模型的訓練要求。同時,DEAP數據集中每一采樣時刻所對應的一維數據向量無法體現腦電電極在大腦上的空間分布特征。本文針對以上問題,對DEAP數據樣本進行了特征重構。
2.2.1 腦電信號背景扣除及時域分割
根據文獻[15],采集的腦電信號中往往包含大量的背景信號,而背景信號會影響后續情緒識別的準確率。因此,為了提高情緒識別的準確性,本文對原始腦電信號進行處理,將受刺激時記錄的信號與背景信號的差值作為待使用的數據。DEAP數據集每個標簽對應的數據中提供了32通道的3s背景信號,鑒于此本文以1s為時間窗將每個標簽對應的背景信號分割成三段,將這三段信號取平均值后作為每個標簽對應數據的背景信號,接著將后60s的受刺激信號也以1s為時間窗進行分割,再把每一段受刺激信號減去背景信號,進而得到受刺激信號與背景信號的差。具體的背景信號處理的流程圖如圖1所示[15]。
將這些去除背景信號后的數據作為新的腦電信號,并且按照1s的時間長度進行分段保存并延續使用原來的標簽。這樣,每個標簽對應的樣本就由1組變成了60組,擴充了后續模型訓練時所需要的樣本數。同時每個標簽對應的實驗數據由原來的32×7680(通道數×采樣點)矩陣切割為60個擁有同樣標簽值的32×128矩陣,后續每個矩陣作為輸入進行模型的訓練,變相的縮小了每次訓練時的樣本數據大小,提高了后續神經網絡的訓練效率。

圖1 背景信號處理流程圖
2.2.2 腦電信號維度重構


圖2 10-20系統平面圖
其中顏色標注的就是DEAP數據集中使用的腦電測試點。從圖中可以看出,每一個電極都與多個電極相鄰。根據文獻[16]可知大腦可以功能區的方式進行劃分,因此電極的空間排布特征也是一種有助于情緒識別的特征信息,應當與數據集本身提供的腦電時序信號一同作為輸入數據進行訓練。基于以上分析,本文將分割完的數據集進行一維向量形式向二維幀矩陣形式的轉換,具體如下:

(1)


(2)
其中,x表示數據幀從某個位置開始時的非零元素,μ表示所有非零元素的平均值,σ表示這些元素的標準差。因此,每個被試者的樣本數都從原來的40個擴充到了2400個(40次實驗×60個片段),并包含了電極的空間分布特征。
2.3 數據集篩選及標簽閾值處理
根據常用的連續情緒模型——Lang二維情緒模型對于情緒的定義,每一個情緒都可以由效價(Valence)和喚醒度(Arousal)兩個維度來共同表征。依此可以繪制出一個情緒平面分布圖,如圖3所示。
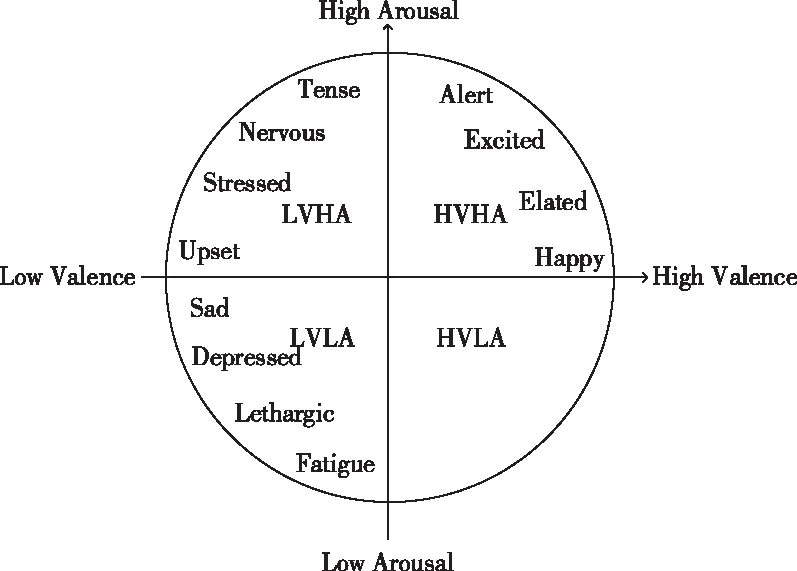
圖3 Lang二維情緒模型
圖中橫坐標是效價,縱坐標是喚醒度。假設以回歸問題來解決情緒識別問題,讓每個情緒都定位于平面上具體的某一個點,這無疑是一個很難解決的問題。如果以分類問題對情緒進行效價或喚醒度層面的二分類,每一類的區域范圍又過大,對于被試者當前的情緒很難精確描述。所以,本文將情緒平面如圖3所示劃分為四個象限區域,這樣能夠進一步實現最終識別的情緒與實際情緒相匹配。本文以5為閾值進行高低效價和喚醒度的劃分,將所有的標簽依照原浮點型標簽統一改寫為高效價高喚醒度(HVHA)、低效價高喚醒度(LVHA)、低效價低喚醒度(LVLA)以及高效價低喚醒度(HVLA)四類,并分別以0-3的整數進行編碼。根據文獻[17],被試個體差異會導致樣本在閾值附近形成模糊樣本,所以應該舍棄效價和喚醒度標簽值在4.8-5.2之間的樣本,從而更好地實現情緒分類。
3 基于腦電信號的情感分類模型
隨著計算機視覺識別技術的更新迭代,卷積神經網絡的識別分類效果也不斷提高[18]。本文參照成熟的計算機視覺識別圖像技術,從其原理的角度出發尋找合理的方法與模型來解決情緒分類問題。
3.1 模型輸入設計
在計算機圖形學的領域中,一張圖片可以用紅、綠、藍三原色來表示(即RGB)。在RGB三個通道中用0-255的值來表示圖像上某一像素點的某一原色強度,彩色圖片是最終呈現給人的三個通道融合后的結果。
計算機視覺圖像可以看成一個三維矩陣,RGB三種原色在視覺光譜中屬于不同的頻段范圍,每個原色通道都是一張單獨的圖片。如果一張圖片的三原色通道排布均勻,那么每個通道的圖片都會帶有圖片中待識別物體的特征。以此為啟發,考慮到腦電信號的標簽是一段連續時間的標簽,那么一段時間內的某一個時刻的腦電信號也可以帶有待識別標簽的特征,所以將預處理好的每個標簽對應的1s的腦電數據幀段以采樣時刻為單位進行堆疊。因為數據的采樣頻率為128Hz,所以仿照圖像構成的原理將腦電數據幀段看做是9×9的128通道的圖像,每一通道都是1s樣本中某一采樣時刻對應的幀矩陣。這樣仿照圖像識別的方式,將9×9×128的一組樣本輸入卷積神經網絡中進行加權訓練,即可達到與圖像識別一樣的分類效果。圖像與腦電信號類比的關系如表1所示。

表1 圖像與腦電信號的對應術語
3.2 模型結構設計

圖4 連續卷積神經網絡結構
3.3 模型訓練
模型的訓練是通過前向傳播進行卷積操作輸出結果,接著將誤差反向傳播進行卷積核的值的調整。通過這樣的迭代,在保證模型具有較大泛化能力的同時提高模型的情緒分類準確率。具體的訓練方法為Adam(Adaptive Moment Estimation)梯度下降法,它利用梯度的一階矩估計和二階矩估計動態調整每個參數的學習率。它的優點主要在于經過偏置校正后,每一次迭代學習率都有個確定的范圍,使參數比較平穩。其公式如下
mt=μ*mt-1+(1-μ)*gt
(3)

(4)

(5)

(6)

(7)
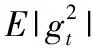
全連接層的輸出使用Softmax函數。Softmax函數的作用就是將每個類別對應的輸出分量歸一化,使各個分量的和為1,即可以理解為將任意的輸入值轉化為概率,而概率最大的即認為是最終的分類結果。Softmax計算公式為:

(8)
損失函數使用交叉熵的方法,它是用來描述兩個分布的距離函數,對于神經網絡來說就是檢測g(x)逼近p(x)的程度。在多分類的情況下,由Softmax計算出每個類別的概率,代入以下公式進行計算:
(9)
其中K是類別的數量,N是樣本的數量,y是標簽,i是觀測樣本,c是真實類別。在此公式中如果i=c則yic=1,否則等于0,pic是神經網絡對觀測樣本i是否屬于c的預測概率,這個輸出值由Softmax函數計算得來。
在干燥處理之前,莖瘤芥分別在功率為0,200,400,600 W的超聲波條件下進行30,60 min預處理(見表1)。在超聲波預處理過程中,將莖瘤芥樣品放入500 mL蒸餾水中。超聲波處理后,用吸水紙吸去表面多余水分,隨后放入干燥箱中進行熱風干燥[5]。
同時網絡訓練的結束標志是參考準確率以及損失函數的值的,當模型訓練的準確率提升不到1%,或者損失函數值下降時沒有做到準確率的提高的時候網絡的訓練終止。
4 實驗結果對比分析
依照前面幾節的內容,對DEAP數據集進行數據重構并建立模型進行訓練,同時對每個人的樣本進行十折交叉驗證(10-fold cross-validation)來對模型的分類效果進行評估。十折交叉驗證就是將數據集分成十份,輪流將其中的九份作為訓練數據,一份作為測試數據進行試驗,每次試驗都會得到相應的準確率,十次結果的準確率的平均值作為對算法精度的估計。在DEAP數據集中一共有32個被試者,在進行標簽篩選后每個人的樣本數也不一樣,通過十折交叉驗證將數據集分為訓練集和測試集后對應的數量如表2所示。
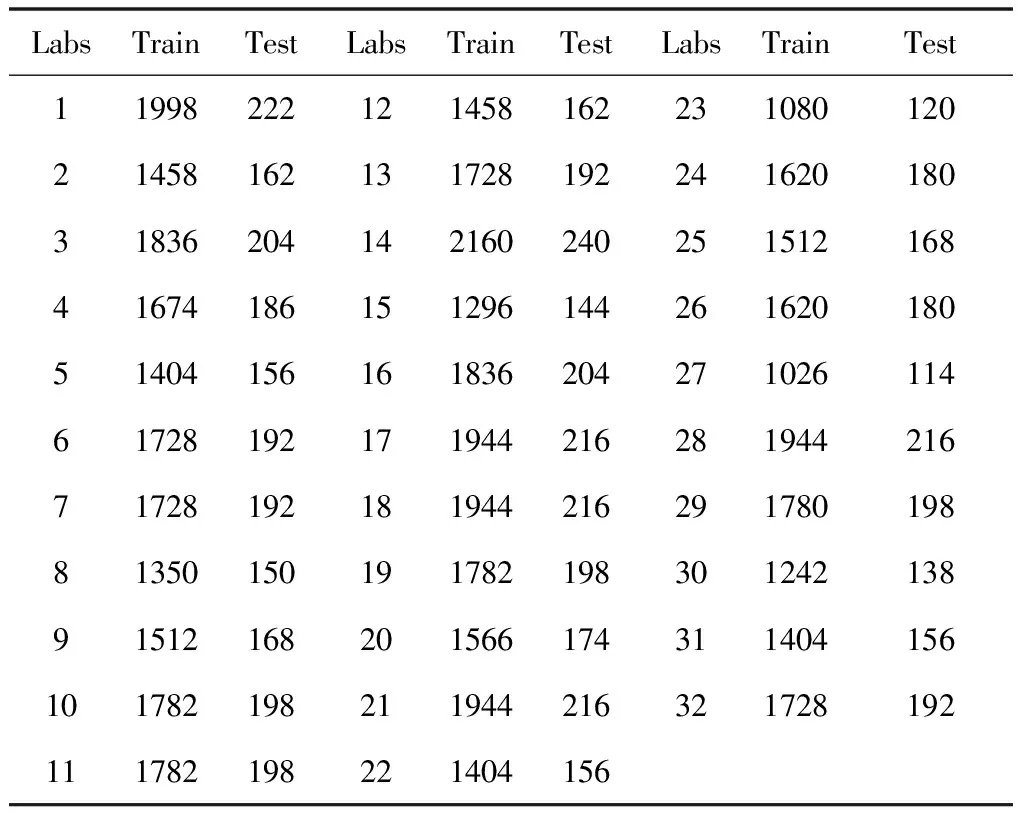
表2 標簽篩選后被試者訓練樣本與測試樣本的個數
從表中可以看出,每個被試者通過標簽篩選后的樣本數量基本都不相同,這從另一方面驗證了對于同一段視頻刺激,不同被試者的腦電數據及其對應的情緒標簽也是不盡相同的。因此在建立情緒分類模型的時候,以個人為單位建立的模型要比以所有被試者的數據集合建立的模型更合理準確。因此,本文依次對每個被試者建立輕量化卷積模型,分別按照十折交叉驗證的規則進行實驗。模型建立主要借助TensorFlow框架實現,在Inter(R) Core(TM) i7-10870H CPU上進行訓練,模型batch設置為32時,訓練的迭代次數最多為7即可滿足模型準確率要求,每次迭代用時1s。實驗的分類結果如表3所示。

表3 輕量化CNN四分類結果
但以上都是樣本標簽在閾值范圍內的理想情況,還需要測試以理想情況訓練出來的模型是否適用于閾值邊緣的情況。因此將先前篩選出來的閾值邊緣樣本作為測試集,以所有閾值內的樣本作為訓練集,以此進行實驗。這樣每個DEAP數據集中的對象都會得到一個相關的準確率,具體結果如表4所示。
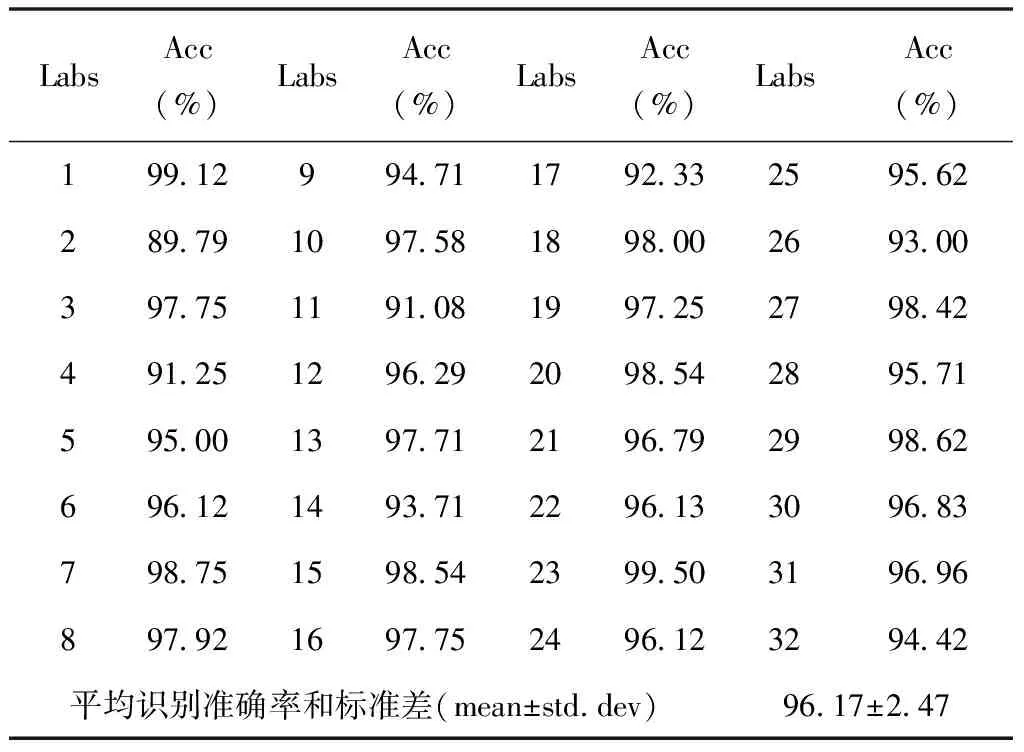
表4 邊緣樣本測試準確率
樣本標簽在閾值范圍的數據屬于常規數據,而從表4可以看出使用常規數據訓練出來的模型同樣適用于識別邊緣樣本。
本文的數據預處理與類比計算機圖像識別的思想參考了文獻[10][15]的方法。Yang Y等人[10]將腦電信號預處理為二維矩陣后使用CNN與RNN的融合模型進行情緒二分類,平均準確率為91.01%,低于本文的四分類準確率,且該文獻的模型包含了并行的兩個基礎模型,本文的模型為輕量化卷積神經網絡,相對簡單、高效。楊一龍[15]將腦電信號的不同頻段計算出差分熵矩陣進行堆疊,并輸入四層卷積層的卷積神經網絡進行情緒二分類,平均準確率為89.88%,低于本文的四分類準確率,而本文的腦電信號除了去除背景信號的操作外沒有進行任何的計算步驟,直接進行二維轉換,在數據預處理的計算量上小很多,同時模型的復雜度更低。由此可見,本文在情緒識別的類別數量、數據預處理計算量、模型復雜度這三個方面均優于以上兩篇文獻。
本文在保證數據完整性的前提下充分利用了深度學習網絡自主提取特征的特性,對原始數據進行維度重構并加入了腦電采集的電極空間分布特征,提高了情緒分類的準確率。前人研究多是先人工進行腦電特征提取,這一操作大多會造成特征缺失的問題,后續網絡訓練就很難做到在有限的特征中高準確率的進行情緒識別分類;并且少有人進行背景信號去除的操作,這樣會讓提取的特征中夾雜有大量的噪聲信號,對識別會形成很大的干擾;同時本文針對待處理的腦電信號特征設計了輕量化卷積神經網絡,對最終的高準確率情緒分類起到了關鍵作用。所以本文的最終情緒識別準確率和識別種類數均優于前人研究結果。具體的對比結果如表5所示。

表5 使用DEAP數據集評估方法對比
綜上所述,本文所使用的方法在保證數據預處理和模型復雜度低的同時也保證了較高的準確率。
5 結論
本文使用公共DEAP數據集進行情緒識別模型的評估,考慮了腦電背景信號的影響,采用了一種簡單且計算量小的數據預處理方法獲取了腦電信號的時域特征信息,同時結合腦電電極的空間分布獲取了腦電信號的空間特征信息,兩者融合后的腦電信號時空二維矩陣作為卷積神經網絡的輸入,參考計算機視覺圖像識別的成熟技術設計了輕量化連續卷積模型,通過該模型自提取對應標簽的情緒特征,進行基于Lang二維情緒模型的四分類,對情緒的情況判斷更為精細。結果表明在該方法下,情緒識別在四分類上準確率明顯提高。
本文的方法適用于個人情緒模型的快速訓練及識別的問題,該方法在實際的應用中,可以基于個人腦電信號建立情緒識別模型,從而較好的監測個人的情緒狀態。考慮到每個人的同一種情緒在腦電信號中都存在一定的共性特征,基于這些共性特征是否可以建立一個適用于多人的情緒識別模型,這也是目前基于腦電信號的情緒分類方法的研究熱點與難點。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
風流一代·青春(2018年2期)2018-02-26 15:27:06
風流一代·青春(2017年6期)2018-02-14 19:28:55
風流一代·青春(2017年5期)2018-02-14 09:32:37
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
