基于SVM算法的藏文微博情感分析研究
2022-09-28 09:52:20朱亞軍
計算機仿真 2022年8期
朱亞軍,次 曲,擁 措
(西藏大學信息科學技術學院,西藏拉薩850000)
1 引言
微博作為一種輕量級的自媒體平臺,自由靈活。它是一種基于用戶關系,進行信息分享、傳播以及獲取的,通過關注機制分享簡短實時信息的社交媒體、網絡平臺。人們每天通過微博了解世界上每個角落發生的事情,還可以通過微博分享自己的經歷和感受,在瀏覽微博的時候,可以發表自己的評論,所以微博包含非常豐富的表達情感的內容。對微博進行情感分析能夠發現博主對社會事件、時事熱點的態度,從中挖掘商業價值,也可以幫助政府機關分析事件的社會影響。目前對中文微博的情感分類已經相對成熟,但是因為語法的差別,在對藏文微博進行情感分類時,直接遷移中文微博情感分類的方法,效果較差,所以需要針對藏文微博進行專門的研究。
對藏文文本情感分類已經有不少相關的研究。首先西藏大學擁措[1]教授對短文本情感分析的研究現狀進行了比較全面的總結和綜述。M. Srividya[2],Wan-qiu Cui[3]分別使用了復合分類器和基于語義的哈希圖對短文本進行了分類。H. M. Keerthi Kumar[4],曹魯慧[5]通過優化短文本的特征選擇方法提高了短文本的分類效果。范國風[6]基于語義依存關系通過圖網絡對文本進行了分類。余本功[7]基于改進SVM對網絡上的短文本分類,取得不錯的效果。楊朝強[8],施瑞朗[9]通過新的大量數據對原有的分類模型進行了驗證。西北民族大學李海剛[2],采用了信息增益的特征選擇方法,提高了特征對類別的代表性。Xiao Sun[11],HüseyinFidan[12]對小說文本的情感進行了分析,有效地抽取了文本中表達情感的句子。張俊[13],楊志[14],孫本旺[2]均基于藏文微博情感詞典對藏文微博情感分類進行了研究,其中孫本旺提出的基于SSTSD情感詞典的方法具有較優的分類效果,但是情感詞典的構造具有一定的困難,通常需要手工建立基礎的情感詞典,因此具有較大的建設成本和規模限制。江濤[16]在其多特征藏文微博情感分析的研究中,考慮了漢語,表情符號等,取得了較好的成果,但是對純藏文微博情感極性的識別仍有待改進。袁斌[17]的基于語義空間的藏文微博情感分析方法提出的語義空間+TF-IDF方法在特征空間的基礎上提供了語義的內容,通過語義進行聚類發現類別,形成特征空間,較大程度地挖掘了單條微博的信息量,所以分類效果較好。
本文針對從新浪微博上收集的藏文微博進行實驗,數據具有一般性和代表性,能夠有效地評價情感分析結果。引入核函數和容差值的SVM算法對小樣本數據的分類效果較好,因此使用SVM算法對藏文微博進行情感分析。SVM算法將分析微博文本所蘊含的情感,將微博劃分為積極、客觀和消極三類,細化了情感分析的類別。
2 SVM分類算法
SVM主要是通過對訓練數據的學習,找到類別邊緣上的點,這些點被稱作“支持向量”,通過這些支持向量找到一個超平面,這個超平面可以較好地將樣本數據空間分離,并最大化類別邊緣上的點(支持向量)到超平面的距離,從而獲得最優的分類效果。
超平面(w,b)關于T中所有樣本點的幾何間隔最小值(也即是離得最近的點的距離)為
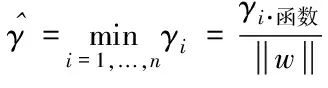
(1)
在盡可能地保證分類正確又使得類別之間的距離足夠大的情況下,可得

(2)
訓練過程就是最優化超平面的過程,并將最優化超平面問題轉化為凸優化問題。引入拉格朗日乘子αi> 0,i=1,2,…,n,定義拉格朗日函數
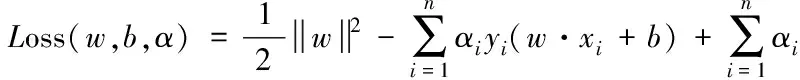
(3)
對上式中的w和b分別求一階偏導,并令它們等于0,即可求得w和b,并最終獲得最優分類超平面。
看上去支持向量機的超平面原理只能使用于二分類問題,但是經過改進的支持向量機分類算法同樣可用于多分類問題,而且在小樣本數據集上支持向量機擁有更加優秀的文本分類能力。
3 實驗數據
目前沒有公開的藏文微博語料本文使用的語料是人工從微博上收集的,選擇微博長度在10詞到100詞之間的,包含較少或不包含非藏文字符的微博,共計17000余條微博。數據預處理使用廈門大學在線分詞系統進行分詞,并對微博進行實義詞語的抽取。人工進行微博情感的標注,標注分為三類。標注規則和標注示例如表1和表2。

表1 標注規則

表2 標注示例
數據集被分為3部分,其中包括: 60%用于訓練,得到算法相應的分類模型;20%用于驗證,驗證模型的正確性;20%用于測試,測試模型在微博情感分類中的實際效果。
4 特征選擇
對文本分類來說,特征就是文本中表達了文本類別屬性的詞語,因此特征的選擇較大程度上決定了文本分類效果的好壞。隨著機器學習算法的深入研究,提出了很多特征提取方法,其中包括TF(Term Frequency),IDF(Inverse Document Frequency),TF-IDF等。這些特征選擇方法使得選擇的特征盡可能多地包含文本信息。
TF(Term Frequency):即詞頻,也叫絕對詞頻。指的是一個詞語在文本中出現的頻率。
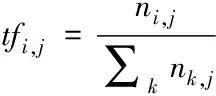
(4)
其中分子ni,j指的是該詞在文本中出現的次數,而分母∑knk,j指的是文本中所有字詞出現的次數總和。
TF無法避免停用詞帶來的影響,比如:“我”、“的”、“但是”等。與情感詞相比,這些詞在各類情感文本中的使用頻率都比較高,但是對微博文本情感的分類貢獻不大。
IDF(Inverse Document Frequency):逆文本頻率。逆文本頻率的計算為:文本總數除以包含詞條的文本數再取對數。
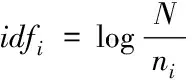
(5)
其中分子N表示總文本數,ni表示包含詞語i的文本數。
IDF降低了各類文本中都會出現的常用詞的影響,使得那些在各類情感文本中均會使用的常用詞的權重減小,而提高了在某一情感分類文本中出現頻率較高的詞的權重。
TF-IDF:指詞頻和逆文本頻率的乘積:
tf-idf=tfi,j·idfi
(6)
通常情況下,在文本中會大量存在這樣的詞,不管文本的主題是什么,總會用到這些詞,比如:“我”、“我們”、“的”、“個”。這些詞和文本的情感表達關系不是很密切,對于文本的情感分類沒有幫助,并且這些頻繁出現的詞,還會掩蓋那些詞頻很低但是卻有力地表達了作者的想法和態度的詞或短語,比如網絡流行詞。
如果一個詞或短語在一篇或一類文章中出現的頻率很高(TF較大),并且在其他類別的文章中出現的頻率又較低(IDF較大),則認為這個詞或短語具有很好的類別區分能力,而其在文本分類中做出的貢獻也越大,使得文本的類別識別率較高。TF-IDF的優點是能夠很好地避免各類文本中都會出現的常用詞帶來的影響。
5 實驗結果
本文主要針對SVM分類算法進行實驗分析。考察實驗結果的三個指標:準確率P(Precision)、召回率R(Recall)和F1(F1_Score)。
通常情況下,精確率和召回率是相互矛盾的,精確率較高時,相應地,召回率就較低,所以引入F1作為參考,在精確率較高,而F1值也相對較高時,訓練出來的模型在分類的時候才具有比較優秀的表現。
由通過實驗找到SVM算法最優的懲罰系數C和gamma值對。
圖1和圖2可得,模型在gamma=1.667和C=1.320時達到最優分類效果。分類精確率為58.3%,召回率為48.3%,F1值為48.1%。
最后,實驗設置SVM分類算法與貝葉斯分類算法(MB)的對比實驗,并分別在對微博文本進行簡單分詞(segment)和在分詞后對實義詞語進行抽取(keywords)的兩種數據樣本上進行實驗,分別采用TF,TF-IDF兩種特征選擇方法進行特征空間的建設,考察其精確率、召回率、F1值及模型訓練的用時,實驗結果如表3所示。
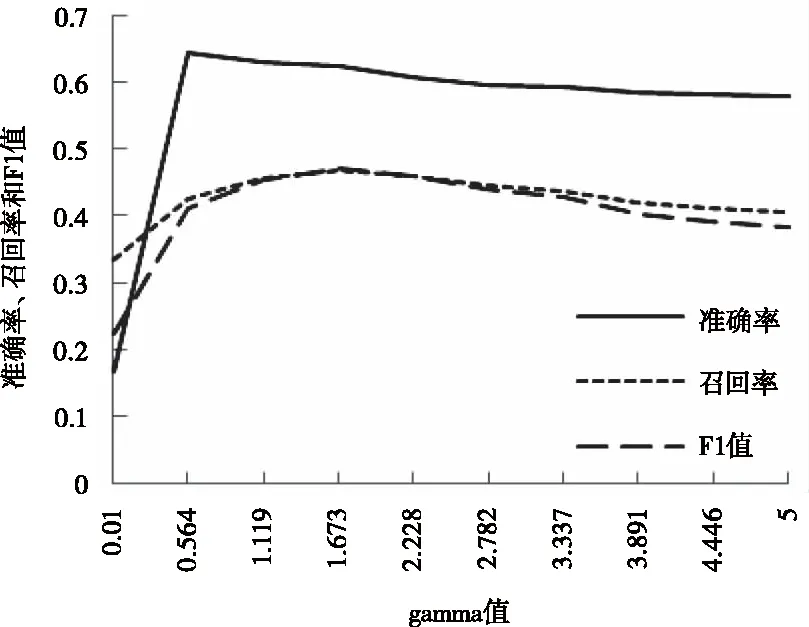
圖1 參數gamma對分類性能的影響
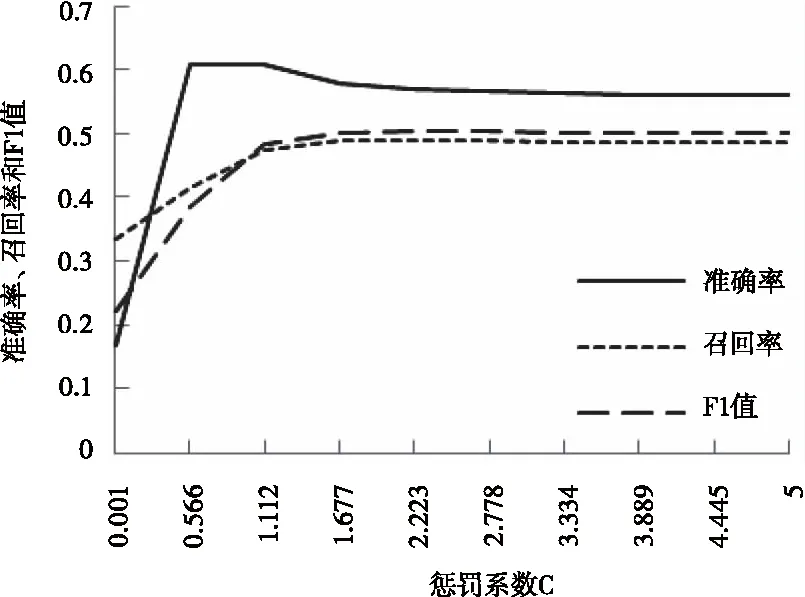
圖2 懲罰系數C對分類性能的影響
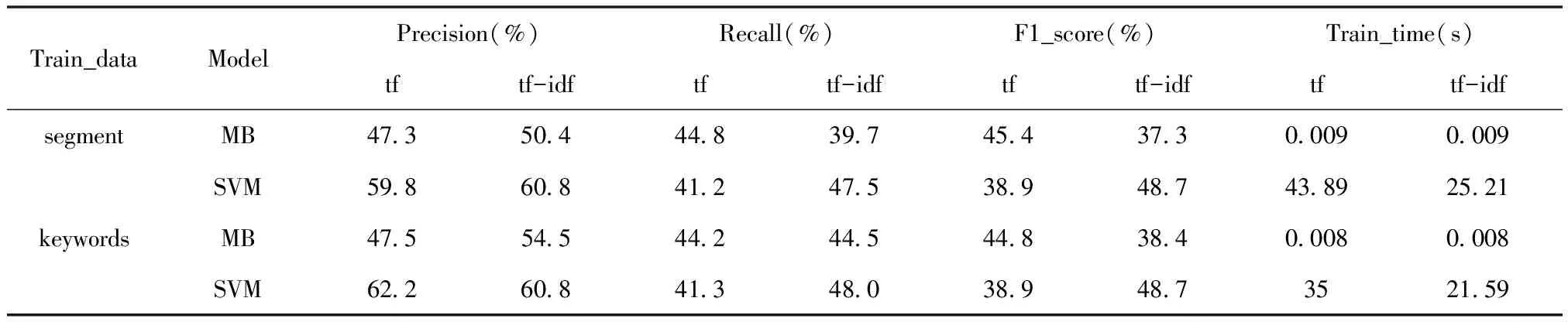
表3 不同數據集和不同特征選取方法下MB和SVM的實驗結果對比
首先,從模型的訓練時間上看,SVM的復雜度比MB的復雜度大。非線性可分樣本集的復雜度為O(dn2),其中n為訓練樣本集的大小,d為特征向量的維度,而MB復雜度為O(dn),因為訓練數據量較大,所以SVM的訓練時間比MB的訓練時間大得多;其次,在SVM進行訓練時可以看到,TF的訓練用時比TF-IDF訓練用時多。因為TF選擇的特征空間大,特征向量維度更大,所以在模型訓練時需要更多的訓練時間;再次,在分類模型為MB時,相比TF,TF-IDF對召回率(Recall)影響不是很大,但是卻能夠在一定程度上提高準確率(Precision),這樣就降低了F1的得分。在分類模型為SVM時,相比TF,TF-IDF雖然對準確率的影響不是很大,但是卻能夠明顯提高召回率的值,從而提高F1的得分;最后,在對微博進行實義詞語的抽取之后,可以發現在保證準確率和F1值的情況下,可以提高模型的訓練效率,其中TF下大概提高20%,TF-IDF下仍能提高大概15%。
SVM分類算法的優秀表現應該歸因于兩個方面,第一,SVM使用了核函數技術。通過引入核函數,將訓練數據映射到更高維的空間中去,這樣就能更容易地找到決策面,也即是SVM的超平面。第二,松弛變量和懲罰項的引入。通過引入松弛變量和懲罰項,再加上前面的核函數使得SVM具有了對非線性問題處理的能力。另外與貝葉斯分類算法依賴于全樣本數據不同,SVM通過尋找樣本中的支持向量,并通過支持向量來建立超平面。所以SVM分類算法的實驗結果優于貝葉斯分類算法。
6 結論
相比TF,TF-IDF的特征空間小,文本向量維度小,可以加快模型的訓練速度。并且TF-IDF構建的特征空間具有更加突出的類別表征能力,有利于提高藏文微博情感分類的效果;SVM相比MB具有更加優秀的分類效果。相比單一的特征顯現概率來講,SVM求解一個超平面,這個超平面能夠將樣本集較好地分離開;對實義詞語進行抽取能夠在保留足夠多的文本信息的基礎上提高模型的訓練效率。
目前深度學習在人工智能領域成為研究熱點,但是仍然不能忽視對傳統機器學習算法的研究,因為在深度學習算法中仍然可以看到那些經典的傳統機器學習算法的存在,對傳統機器學習算法的研究的意義在于它可以為深度學習的方法提供較好的實驗對比基線,從而為深度學習方法的選擇提供有價值的參考。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
