基于深度學習的眼底視網膜圖像疾病分類研究
2022-08-19 01:29:02李果璟夏秋婷
傳感技術學報 2022年5期
李果璟,夏秋婷,李 宏
(杭州電子科技大學自動化(人工智能)學院,浙江 杭州310018)
眼底是人體唯一能直接看到血液循環狀況及微循環結構的部分[1]。 傳統眼底檢查的流程是患者前往醫院拍攝眼底照片,眼科醫生依據圖像進行診斷。 但日益上升的患者人數造成專業眼科醫生短缺,醫生工作愈發繁重等問題逐漸顯現。 并且,僅僅憑靠醫生肉眼觀察分析的傳統診斷方法所帶來的效率低下、誤診、漏診等問題也不容忽視。 因而,利用計算機技術輔助眼底診斷,進行眼底健康篩查十分必要。
糖尿病(Diabetes Mellitus,DM)和眼底病變的發生存在一定的關聯性,由胰島素分泌缺陷或者胰島素作用障礙造成的糖尿病會給患者帶來血糖升高,血管性改變等后果[2]。 在全球范圍內,糖尿病引發的眼底視網膜病變(Diabetic retinopathy,DR)是致盲的首要因素,是許多國家成年人失明的最主要病因之一[2-4]。
深度學習[5-10](Deep Learning) 是機器學習(Machine Learning)方法中的一種。 深度學習在眼科上的應用目前取得了很多成果。 Gulshan 等人[11]在2016年就利用Inception-v3 結構將深度學習技術應用在糖尿病眼底視網膜病變的診斷上,且實驗結果十分成功;Muhammad 等人[12]設計了一種基于Alexnet 網絡與隨機森林方法混合的深度學習方法(HDLM),基于OCT 眼底圖像對52 名青光眼患者眼底圖像進行是否為青光眼的診斷;Felix 等人[13]設計的神經網絡與隨機神經結合的模型,對年齡相關性黃斑病變進行12 個等級的分類。
本文利用全局信息對整個眼底圖像進行特征提取,隨后進行分類。 其創新點在于,提出了一種針對眼底視網膜圖像的多疾病多標簽分類的解決方案;針對視網膜圖像中多種疾病的多標簽分類,提出了構建多分支模型多任務學習的解決方法;為增強模型對病灶學習能力,引入了注意力機制來提高疾病分類的精度;采用多模型融合技術,對不同結構的神經網絡進行融合以提升模型效果。
1 材料與方法
1.1 數據和預處理
本文所用數據集來源于2019年北京大學“智慧之眼” 國際眼底圖像智能識別競賽(Peking University International Competition on Ocular Disease Intelligent Recognition,ODIR-2019),由北京上工醫信科技有限公司提供。 數據來源于在上工醫信合作醫院及醫療機構進行眼健康檢查的患者,數據提供了3500 組結構化脫敏信息作為訓練集。 以下簡稱數據集為ODIR。
從醫學角度上分析病灶特征,正常眼眼底圖像中血管清晰,包括小血管在內的多個血管走行方向明確,視盤呈正常淡紅色。 無絮狀物或結節狀物體出現。 而糖尿病視網膜病變的眼底圖像上可能會存在微動脈瘤(Microaneurysms,MA),軟性滲出(Soft Exudates,SE),硬性滲出(Hard exudates,EX)以及出血(Hemorrhages,HE)等癥狀。 微動脈瘤是由于毛細血管壁局部變薄而膨脹引起的,他們被認為是糖尿病視網膜病變發生時最早可見的體征。 滲出是由于毛細血管內血漿的滲漏,再根據顏色及邊界是否明顯區分為硬性或軟性滲出。 淺層的出血通常呈火焰狀,在視網膜深層的血管破裂將導致斑點狀圓形病灶[14]。
1.2 基于深度學習的眼底多疾病分類器方法實現
1.2.1 實驗環境
本文提出了新的眼底視網膜圖像病變檢測分類方法,并進行優化。 本實驗設計多組對比實驗,先確定了整體的分類器模型構建思路: 選擇以Resnet50[7]為主干網絡,在此基礎上對結構進行修改,結合特征融合技術并采用多任務學習得到基準模型。
通過設計多組對比實驗,實驗環境配置表如表1 所示,所設計的深度學習方法實現是基于Pytorch1.1.0 以及torchvision0.3.0 框架。
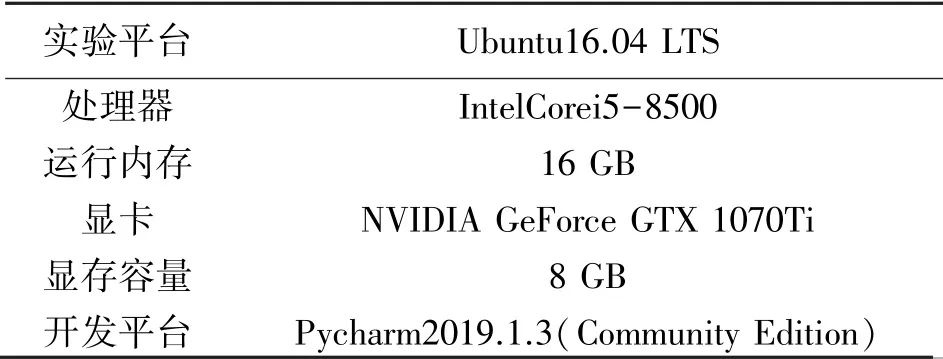
表1 實驗環境配置
1.2.2 評價指標
本實驗利用留出法進行模型選擇和評估,選擇所有數據中的90%左右為訓練數據,10%為測試數據。 本實驗為多標簽分類問題,輸入示例可以由多個標簽進行標記且不互斥。 采用的評價策略分為兩個部分,首先是對于所有類別評估模型整體的準確率(accuracy,acc)、基于標簽的評價指標(f1-score)、受試者工作特征曲線下面積(Area of receiver operating characteristic curve,AUC)以及杰卡德指數(Jaccard Index);其次,針對每個類別,進行acc、f1-score、AUC、查準率、敏感性(Sensitivity)以及特異性(specificity)的評估。 通過綜合指標的考量,更為全面地判斷模型性能好壞。 上述指標大多借助混淆矩陣得分統計,如表2 所示。
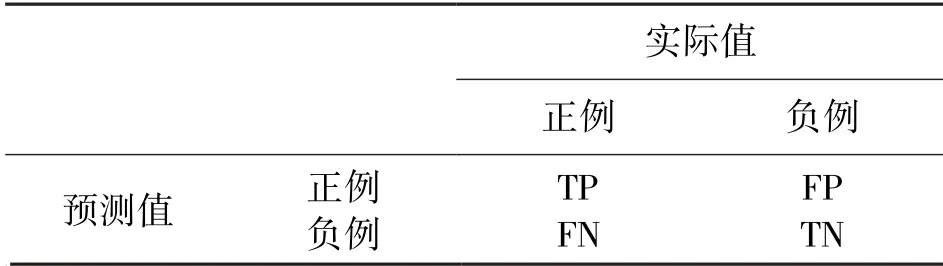
表2 混淆矩陣分析
準確率表示所有被預測正確的數據比例,計算公式為:
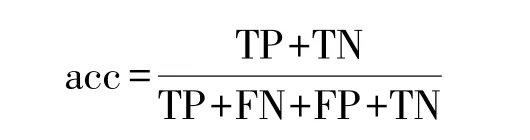
查準率(precision)表示預測值為正例時預測正確的比例,計算公式為:

敏感性表示真實值為正例的情況下,預測正確的比例,計算公式為:

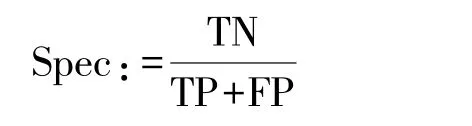
特異性(Specifity)表示預測值為負例的情況下,預測正確的比例,計算公式為:
F1-score 事實上是查準率和敏感性的調和平均數Fβ的一種特殊情況,來評估樣本不平衡情況下的模型總體表現。 其計算公式為:
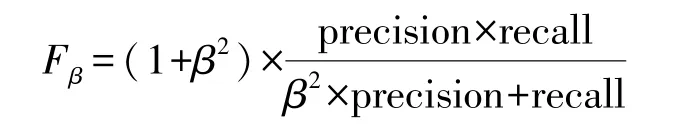
分類過程中按照不同閾值設定,可得到一系列的橫坐標為假陽性率(false positive rate,FPR)和縱坐標為真陽性率(true positive rate)即敏感性數值對,并按照假正例率進行排序。 然后將閾值設為最大值,那么所有的樣本均為負例,再按照排列順序將閾值設為每個預測值,可繪制得到曲線。 該曲線為受試者工作特征(Receiver Operating Characteristic,ROC)曲線。 該曲線右下方面積為AUC,AUC 越大表示性能越佳。
Jaccard 指標是預測值和真實值都為正例占預測為正例或者真實值為正例的比例,其所代表的含義是比較兩個樣本之間的差異程度,Jaccard 指數越大,說明差異性越小。 假設標簽集合為T,預測結果為P,計算公式可以表示為:
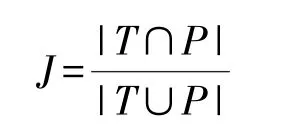
1.2.3 特征融合與多任務學習
本實驗中包含兩組對比實驗,分別為:
①用于選擇輸入模式,驗證本實驗中對輸入進行特征融合是必要的。 ②不同的輸出策略對結果的影響,設計適用于本實驗的多任務學習方案。
同一位患者的左右眼存在一定相關性,從而進行猜想:訓練模型同時參考左眼和右眼圖像信息將提高實驗結果。 為驗證該猜想設計如下實驗:
對ODIR 信息標簽表中“Left-Diagnostic Keywords”和“Right-Diagnostic Keywords”采用正則匹配手段,依照關鍵詞信息,提取并生成相應的左眼和右眼各個疾病的單眼級別的標簽(image label)。 在預測的時候,根據同一患者的ID 選擇出左右眼,然后利用訓練好的模型分別針對其左眼和右眼進行預測,然后對雙眼結果進行融合得到最終診斷結果。在預測診斷階段,綜合左眼和右眼結果進行融合,并整合成診斷意見,指出患者是否存在相應眼底疾病。
采用信息標簽表中已有數據(雙眼各疾病類別標簽)。 相應采取的訓練策略是先將左眼和右眼分別讀入,然后將雙眼圖像做拼接處理后輸入卷積神經網絡進行訓練。 輸出結果即為患者診斷信息。
最終訓練集和驗證集中各類別數據分布如表3所示,其中訓練集為9417 張,驗證集為290 張。 其中,N 表示正常眼,D 表示糖尿病視網膜病變,G 表示青光眼,C 表示白內障,A 表示年齡相關性黃斑病變,H 表示高血壓,M 表示近視。 在訓練策略上,設置初始學習率為3×10-4,每8 次迭代完成后學習率衰減為原來的0.6;批量大小表示網絡每一次輸入的樣例個數,本實驗中設置為10。 實驗所采用的優化器是SGD,動量設置為0.9,網絡損失函數采用二元交叉熵。
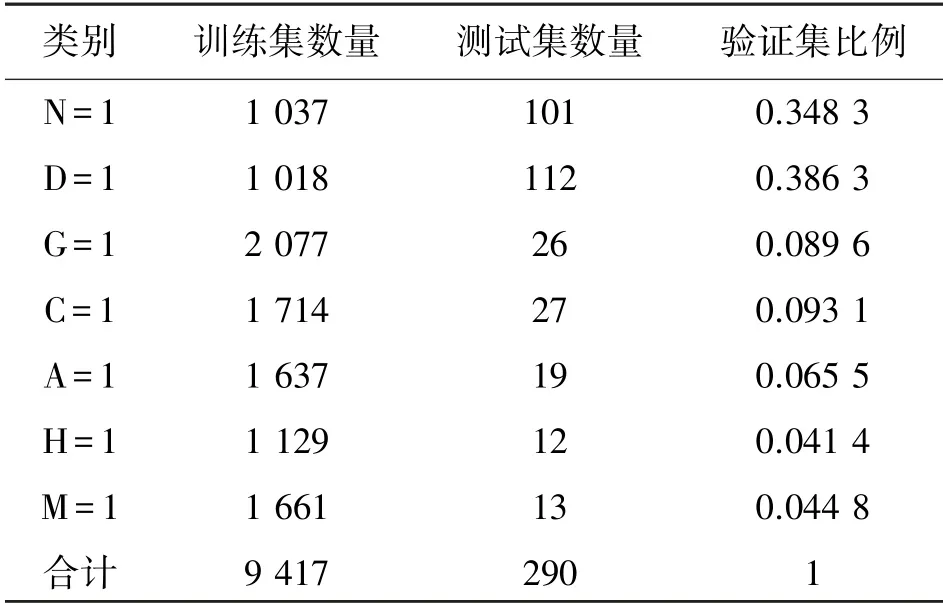
表3 訓練集與驗證集各類別數量及比例統計
2 結果
如表4 所示,雙眼級別多任務學習除AUC 指標外,在其他指標上均比單眼突出,驗證了雙眼級別預測模型效果比單眼級別效果更好。 在特異性、敏感性、查準率和F1-score 上,雙眼級別模型結果比單眼級別更優。
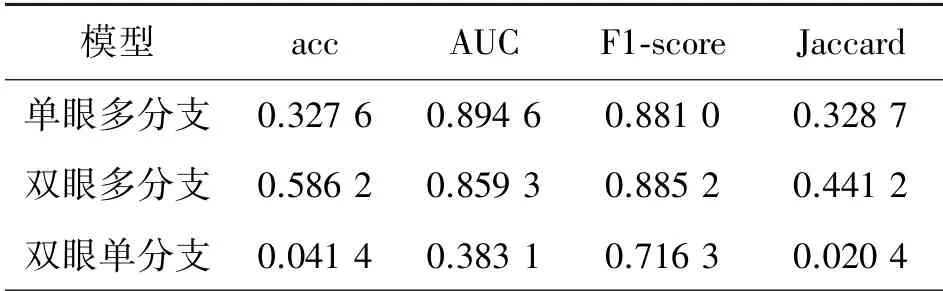
表4 基于單/雙眼級別不同輸出分支模型結果統計
單眼與雙眼級別多分支情況下每個類別的分類情況評價指標對比如圖1 所示。 從準確度來講對于正常眼(N)以及糖尿病視網膜病變(D)的分類效果最差。
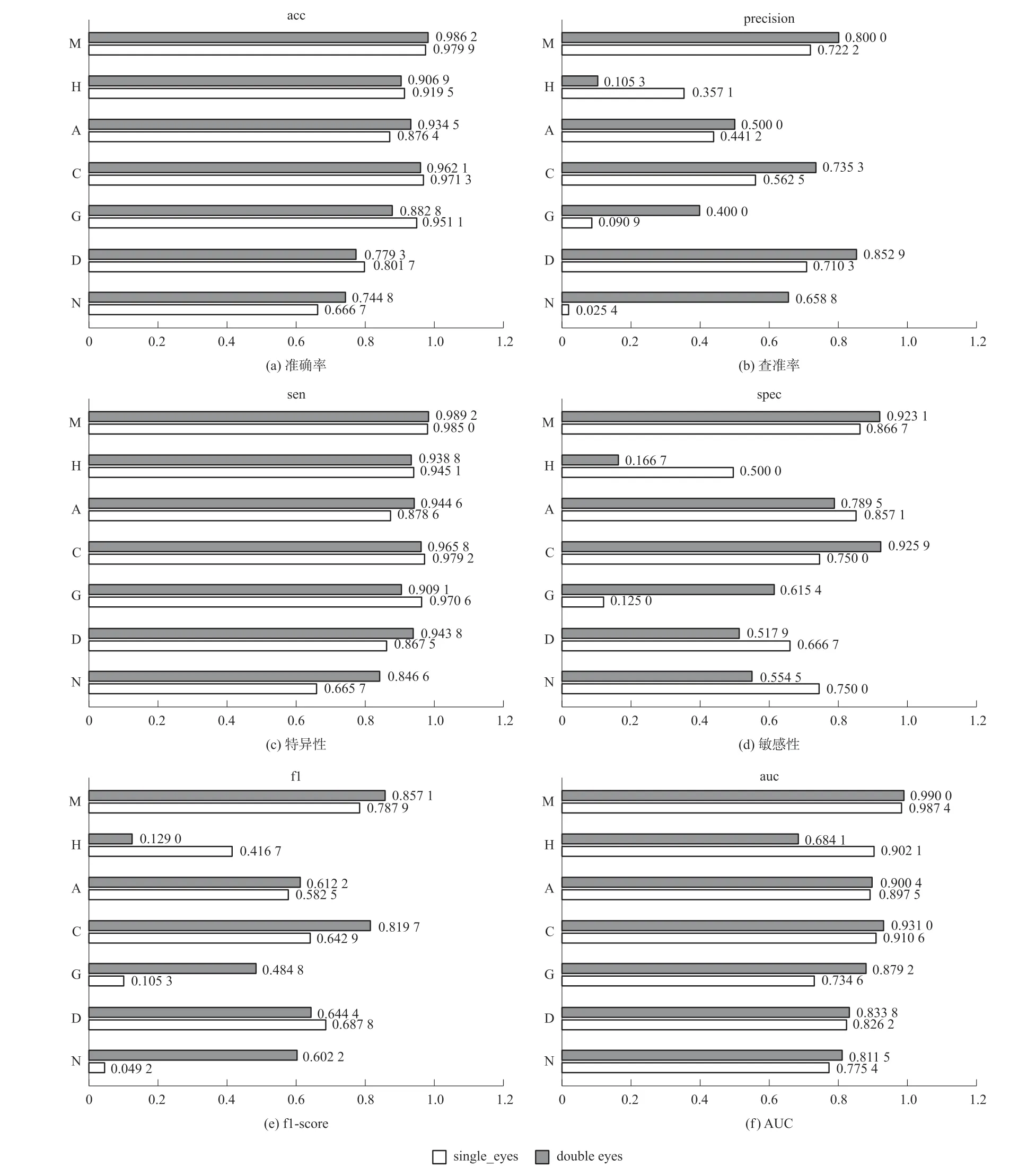
圖1 單眼或雙眼級別多任務學習模型每個類別評價指標對比
實驗2 中,同樣參數條件下,對比雙眼級別多任務學習模型及其分類效果。 分析loss 曲線及ROC曲線,如圖2,雙眼級別單分支模型未能成功收斂,效果十分不理想。 由此,模型訓練結構為多眼級別多分支結構。
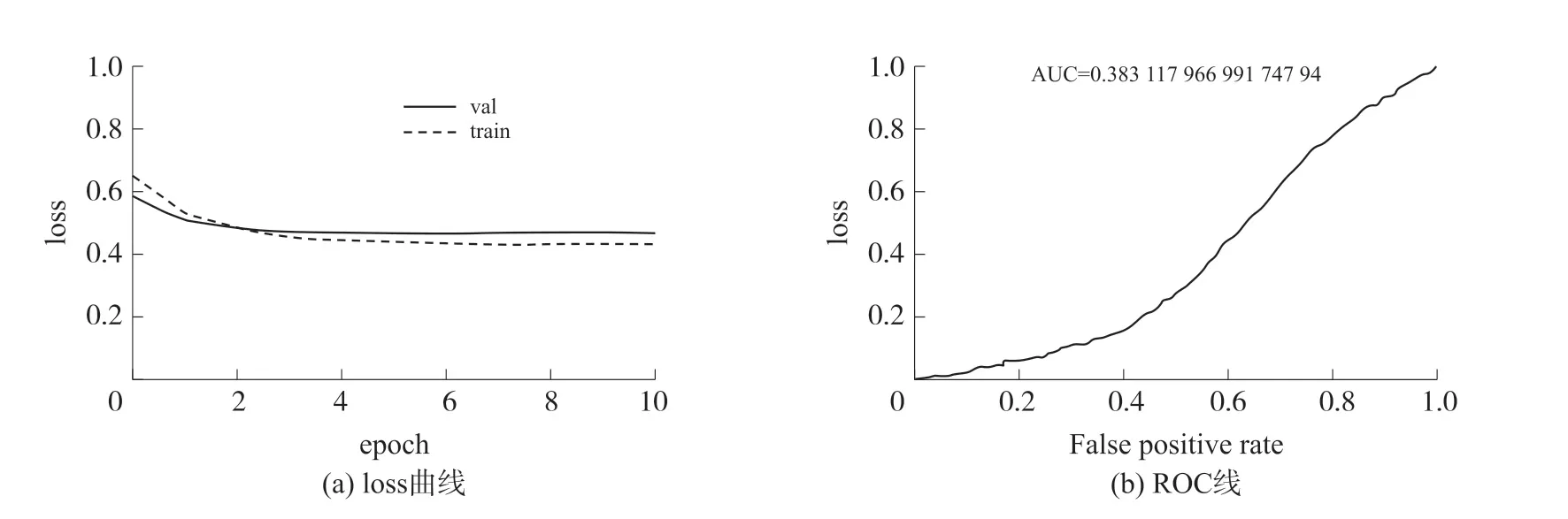
圖2 雙眼級別單分支模型訓練
最終在迭代了總共32 次后,模型最佳結果各項指標如表5,將其定義為基準模型Resnet50_M。

表5 Resnet50_M 模型整體評估指標
2.1 超參數優化
針對當前所獲得的基準模型Resnet50_M,進一步調整參數來優化,設計了以下方案:
①更改學習率衰減策略,將訓練得到模型記為new_lr 觀察Resnet50_M 模型loss 下降曲線。 僅調整學習率衰減策略,即始終保持3×10-4不變,Resnet50_M模型訓練時其他超參數設置均不改變,重新訓練模型。
②更改loss 函數為Focal Loss,將訓練得到模型命名為focal_loss。 與方案(1)中其余超參數保持一致,進行訓練,并且設置Focal Loss 中γ=1,α=1。
如表6,重新訓練后,new_lr 模型的準確率、AUC、F1-score、Jaccard 有所提升。 但是再進一步采用Focal_Loss 方案后,部分指標略微有些下降。
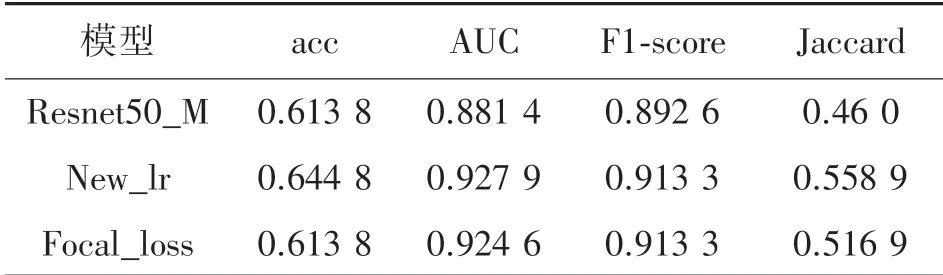
表6 Resnet50_M/new_lr/focal_loss 模型評估指標
從單個類別的多項評估指標來看,如圖3 所示,new_lr 以及focal_loss 效果均比Resnet50_M 優良。new_lr 以及focal_loss 模型查準率較優,表明模型正樣本預測的準確率較高,也代表對正樣本的“過濾能力”較佳。 對于不同類別在敏感性評估前三種模型各有所長。 使用Focal Loss 時,效果略微下降。
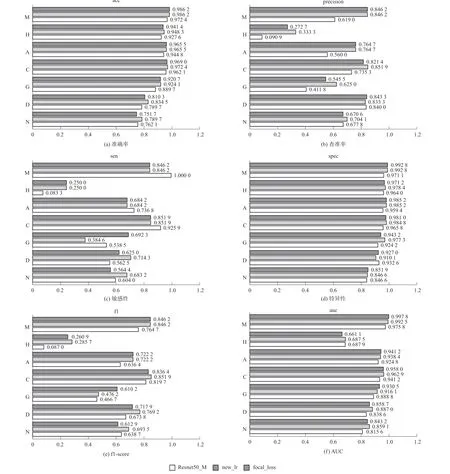
圖3 Resnet50_M/new_lr/focal_loss 在單類別中評估指標
2.2 注意力機制
本實驗中,將SE 模塊添加至Resnet50 結構中,記為SE_Resnet50_M,并嘗試更換zuiho 新的主干網絡為Xception 及孿生網絡。 訓練數據集預處理方式都與其他設置與new_lr 模型基本相同,但由于內存有限,batch size 只能設為8。 將學習率初始化為3×10-4,每迭代32 次后衰減為原來的0.2,即在loss下降較為平穩時候,主動調整學習率繼續訓練。
由表7 可以發現,SE-Resnet50_M 使模型整體效果提升較大。 acc 和Jaccard 指數大幅度提升。 但Xception_M 模型中,acc 下降較大,更換孿生網絡后模型未能擬合。

表7 Resnet50_M/SE-Resnet50_M/Xception_M評估指標
從圖4 看,SE_Resnet50_M 在高血壓(H)上的查準率、敏感性和f1-score 中出現了0 值,這說明高血壓類別較難正確分類。
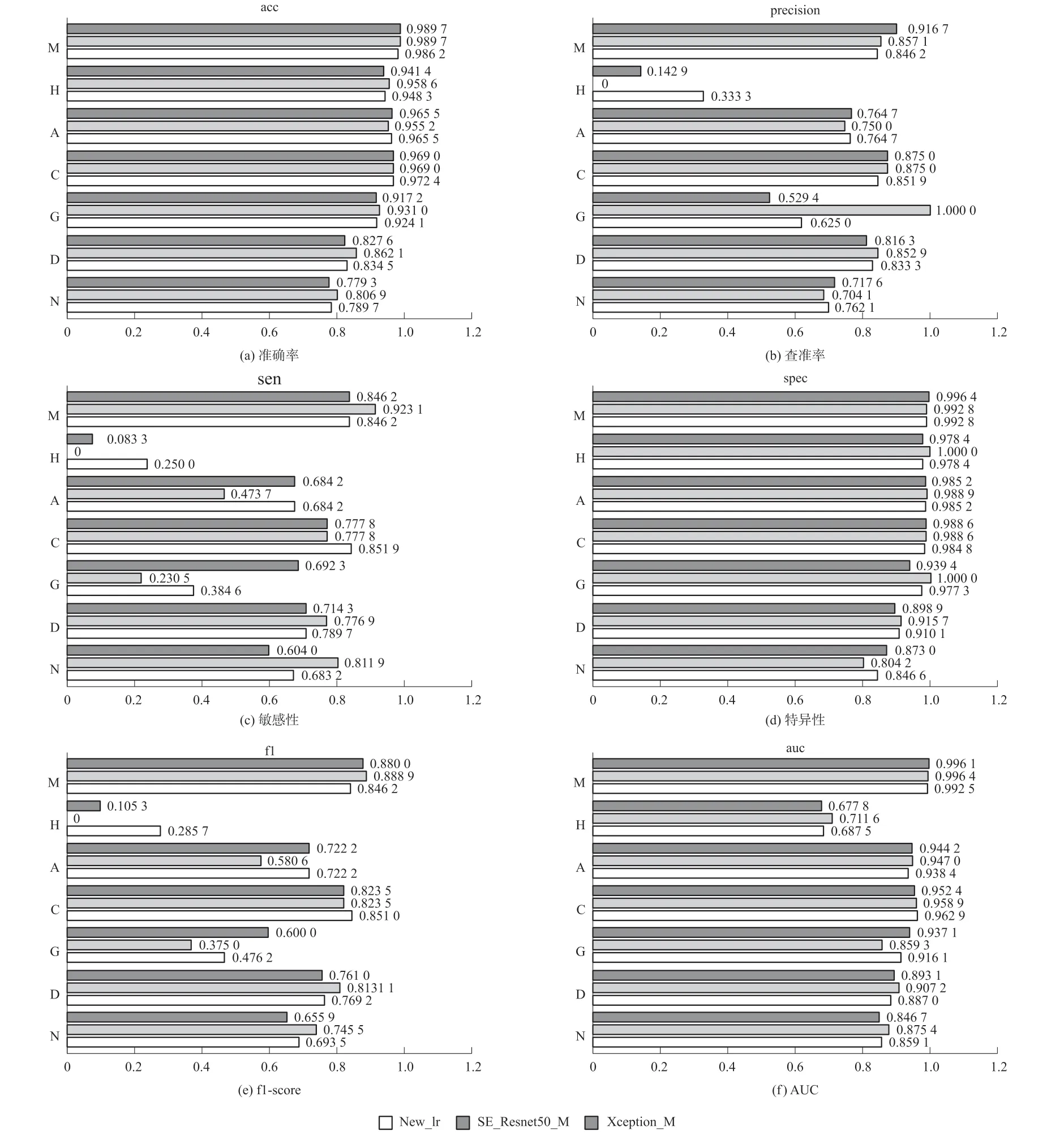
圖4 Resnet50_M/SE-Resnet50_M/Xception_M 在單類別中評估指標
2.3 模型融合
將Resnet50_M 與SE_Resnet50_M 使用加權平均法實現模型融合,如表8 所示,其中,α表示Resnet50_M的權重,γ表示SE_Resnet50_M 的權重,兩個模型在不同的權重比例下,得到結果為表8。
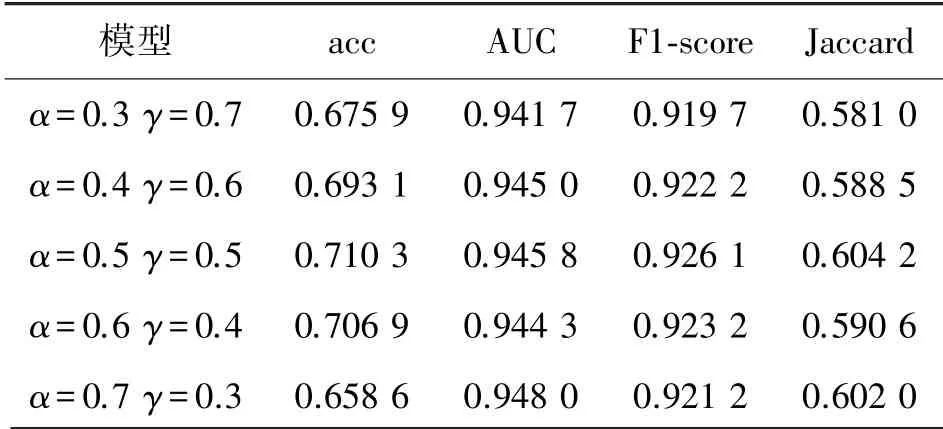
表8 不同權重比例下模型評估指標
因此,在α=0.5,γ=0.5 時候,模型融合效果為最佳。 對比基準網絡Resnet50_M,最終結果在其基礎上有所提升。
從單個類別的結果來看,最終得到結果如表9所示。 從準確度acc 來看,正常眼(N)和糖尿病(D)預測結果最差。 在本實驗中,AUC 考慮了閾值變動情況,為二分類中最常用,評估價值最高的指標。Gulshan 等利用Inception-v3 結構在兩個數據集上分別進行驗證得到的AUC 分別為0.991 和0.990。
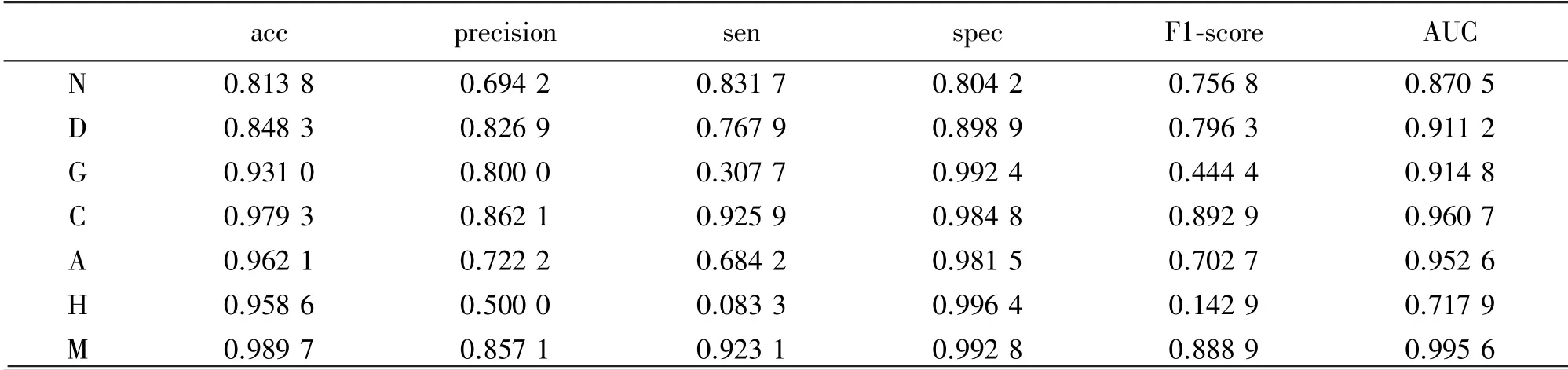
表9 多模型融合后單個類別下模型評估指標
3 結論
本實驗針對左右眼之間的相關性,提出了一種左右眼拼接的特征融合方法;針對視網膜圖像中的多種疾病多標簽分類,提出了利用多任務學習構建多分支模型的解決方法;為增強模型對病灶學習能力,引入了注意力機制來提高對疾病分類的精度;采用多模型融合技術,對不同結構的神經網絡進行融合提升模型效果。
在確定模型架構為“雙眼級別輸入-網絡-多分支輸出”的情況下,進行參數優化,得到基準模型Resnet50_M。 在對比實驗中,發現注意力機制有利于特征的學習,并且準確率大幅度提升。 利用多模型融合技術,綜合考量Resnet50_M 與SE_Resnet50_M 模型預測結果,準確率提升了21.17%達到0.7103,AUC 提升了10.07%達到0.9458,F1-score 提高了4.620%達到0.9261,Jaccard 指數提高了36.94%達到0.6042。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
