主觀博弈視角下虛擬學術社區(qū)用戶知識交互行為分析
2022-08-11 03:16:58王鵬民羅公利
現代情報 2022年8期
王鵬民 羅公利
(1.山東科技大學計算機科學與工程學院,山東 青島 266590; 2.山東科技大學經濟管理學院,山東 青島 266590)
隨著科研創(chuàng)新對知識融合與學科交叉需求的日益增長,以小木蟲、經管之家等為代表的虛擬學術社區(qū)正逐漸成為科研人員跨學科知識交互的有效渠道與跨組織合作創(chuàng)新的重要平臺[1],而虛擬社區(qū)或虛擬團隊的知識交流與合作創(chuàng)新也始終是學術研究與管理實踐的重點[2]。相較于百度、知乎等社會化問答社區(qū),虛擬學術社區(qū)的用戶結構相對穩(wěn)定,知識交互的學術性與專業(yè)性更強、信任度與連續(xù)性更高、創(chuàng)新性與價值性也更加明顯。Pangil F等指出,虛擬團隊的成功不僅有賴于團隊成員知識共享的頻率,更加重要的是其知識共享的強度[3]。所以,虛擬學術社區(qū)的運營管理,不僅要同其他一般虛擬社區(qū)一樣關注用戶注冊數與社區(qū)活躍度等指標數據,而且需要注重社區(qū)知識資源積累與知識價值創(chuàng)新等效用與產出,即不僅關注“數量與過程”,更要注重“效用與結果”[4]。由此,為真正解決虛擬學術社區(qū)的發(fā)展桎梏,徹底打破用戶知識行為的“黑箱”,本文嘗試突破傳統知識共享博弈研究中“有限理性”與二元策略集合等研究局限[5],基于經典博弈向主觀博弈的視角轉換與推演拓展,通過效用函數內生化、策略集合連續(xù)化、共有信念社會化等主觀博弈要素的推演,構建虛擬學術社區(qū)用戶知識交互的可變結構博弈模型,以明晰社區(qū)客觀規(guī)則與用戶主觀認知影響下社區(qū)用戶知識交互的博弈形式調整、均衡路徑演化與穩(wěn)定狀態(tài)影響機理等,為虛擬學術社區(qū)與科研人員突破知識互補均衡、達成知識協同創(chuàng)新的更優(yōu)穩(wěn)定狀態(tài)提出策略建議,從而進一步完善科研人員合作創(chuàng)新研究的理論體系,并對現實中虛擬學術社區(qū)的價值提升與長遠發(fā)展有所裨益。
1 虛擬學術社區(qū)用戶知識交互行為的博弈形式推演
1.1 博弈形式推演的理論基礎
傳統博弈可以探究博弈主體受其他主體與外部環(huán)境等因素的影響,但對于博弈主體內在心理因素等的考察卻相對欠缺。主觀博弈論則將主體認知等內生性影響因素納入研究視野[6],從而能夠綜合考察外在環(huán)境因素與內在心理因素對博弈主體行為策略與演化均衡的影響機理。
首先,在博弈主體理性假設方面,古典博弈“完全理性”與演化博弈“有限理性”假設在某種程度上是對博弈主體的同質性限定或對客觀制度規(guī)則的一種妥協,“有限理性”只是通過增加博弈次數與復制動態(tài)等接受了博弈主體的試錯與調整,進而形成演化穩(wěn)定。但主觀博弈更加注重博弈主體“有限理性”基礎上的主觀能動性,即基于個體認知能力的“認知理性”假設[7],類似于哈耶克式的演化理性[8],其既接受客觀環(huán)境的制度規(guī)則對博弈主體與均衡穩(wěn)定的外生性影響,也強調博弈主體主觀認知對博弈形式的改變以及對均衡穩(wěn)定的內生性影響。
其次,在博弈進程中,演化博弈強調通過不斷學習模仿達成某種策略的收斂穩(wěn)定,一定程度上容忍了博弈主體的短視(重視某一次博弈的得失而忽略長期的效果),并拒絕了其行為策略的突變(隨機改變已有策略或創(chuàng)造產生新的策略)。劉德海等指出,傳統的古典博弈或演化博弈是建立在博弈主體對策略分布與成本收益等博弈規(guī)則或客觀情境具有“共同知識”假設上的[9],忽略了博弈主體主觀認知的內生性影響,也難以解釋博弈結構的變化與創(chuàng)新性行為策略的產生與擴散。而主觀博弈論則逐步放松了博弈主體擁有全部客觀知識的假定,提出博弈主體以自身主觀認知構建的博弈形式進行博弈,且隨著博弈的進行會通過知識經驗的積累與主觀認知的修正等改變博弈形式,直至達到主觀認知上的博弈均衡。
最后,在博弈規(guī)則上,與古典和演化博弈中博弈規(guī)則大多來源于外生的客觀制度環(huán)境相比,主觀博弈由于對“共同知識”假設的放松,更側重于博弈主體基于自身認知對客觀博弈規(guī)則進行識別、學習和歸納所形成的主觀博弈規(guī)則,即源于內生的主觀認知影響。Greif A指出,重復博弈所積累的主觀認知能夠改變客觀博弈形式[10],黃凱南則指出,將客觀博弈形式的變化納入分析有助于主觀博弈論更加準確地描述均衡的內生演化[11]。由此,主觀博弈不僅是對博弈形式的客觀描述,而且更加側重博弈主體主觀認知對博弈客觀形式的改變,以及在主觀博弈規(guī)則基礎上存在的演化與形成的均衡[12]。
1.2 博弈形式推演的現實依據
現實中的虛擬學術社區(qū)更像是科研人員基于學術偏好或共同愿景形成的小眾社區(qū),其知識交互行為與學術報告、研討會等傳統知識共享模式相比更加開放化、隨機化與泛在化,相較于知乎等社會化問答社區(qū)又更具有專業(yè)性、目的性與創(chuàng)新性。而科研人員通過虛擬學術社區(qū)進行知識交互的主要目的是短期內獲取知識、解決科研難題與長期的尋求協作、提升科研產出,其既可以通過答疑解惑、交流經驗、分享資料進行短暫的或淺層次的知識共享,也可以就某一科學問題進行深入探討,甚至建立長期的科研合作關系,共同開展深層次的學術創(chuàng)新研究。因此,虛擬學術社區(qū)用戶在知識交互中除了可以決定是否共享知識外,還可以自由選擇知識交互的頻次、深度、范圍,以及是否建立合作關系、進行協同創(chuàng)新等,其知識交互的效果與產出幾乎完全依賴社區(qū)用戶自身的主觀能動性。對于虛擬學術社區(qū)而言,則不僅要推動用戶由“潛水者”向“貢獻者”轉化[13],更要促進其向“合作者”與“創(chuàng)新者”演化,進而真正提升社區(qū)的科研產出與應用價值。
過往研究中虛擬社區(qū)大多是博弈規(guī)則的制定者,也是影響用戶知識共享成本收益的關鍵[14],現實中虛擬社區(qū)大多在盈利思維影響下片面追求用戶的注冊量與活躍度,對于用戶的行為意愿與行為結果并無有效的約束辦法。在虛擬學術社區(qū)中,由于用戶時空分散、學科背景異質,大多數科研人員獲取所需知識的初始認知便是以較低成本獲取最大化的知識收益,而虛擬學術社區(qū)只能通過限制瀏覽下載、評論發(fā)帖、好友互動等使用權限,或通過打賞獎勵、突出標識、榮譽稱號等物質、精神獎懲,促進用戶注冊、登錄、簽到、回復并進行被動的知識分享。雖然獎懲機制能夠有效遏制“搭便車”行為[15],促進用戶知識共享,但這種外部性制度措施卻難以充分影響并有效提升用戶知識交互的持續(xù)性與創(chuàng)新性,這對于期望尋找合作伙伴進行知識協同創(chuàng)新并取得科研成果的用戶而言并無實質性作用。郭洋等指出,人際網絡、社會報酬、產出能力與合作氛圍等多要素共同作用才能促進科研人員合作創(chuàng)新[16]。所以,虛擬學術社區(qū)現有的外部性制度措施可能只是為用戶的知識交互行為提供了初始博弈框架,而隨著使用的深入與交互的頻繁,科研人員群體的社會化屬性將逐漸突顯,社區(qū)用戶也將基于自身主觀認知的積累與更新,形成并不一定與社區(qū)客觀博弈規(guī)則相一致,但卻更加符合現實情形的主觀博弈規(guī)則。
1.3 博弈形式關鍵要素的推演
根據上述分析可以大致勾勒出虛擬社區(qū)知識共享的傳統博弈形式,即基于社區(qū)運營管理的現實情形構建用戶知識共享的二元策略演化博弈模型[17],其策略收益可以簡單界定為共享即有知識收益與社區(qū)獎勵收益,而不共享則沒有收益或受到懲罰,如表1所示。

表1 虛擬社區(qū)用戶知識共享的傳統博弈模型支付矩陣
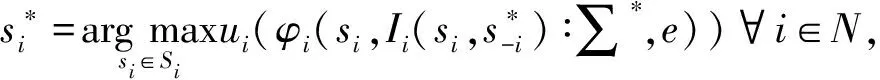
1)預期效用函數
由表1可知,傳統博弈形式下用戶知識共享的預期收益可以分為兩部分,一是由虛擬社區(qū)根據用戶客觀行為給予的確定性獎懲收益;二是取決于另一博弈主體策略選擇的不確定性知識收益[20]。社區(qū)用戶需根據他人策略與客觀環(huán)境的變化來確定并優(yōu)化自身策略,最終實現優(yōu)勢策略的均衡穩(wěn)定。這種情形下用戶的主觀認知幾乎被忽略,用戶只能根據絕對化的收益或損失在兩個極端策略中進行選擇,而現實中用戶可能存在突變、試錯或擴展策略的可能,比如用戶在一次共享中獲得高價值的稀缺性知識,即使在接下來一次共享中受到損失也會再次進行知識共享,原因在于其知識收益來源于異質性的用戶主觀認知判斷,而非同質性的客觀規(guī)則決定。主觀博弈視角下,知識交互收益應當是取決于社區(qū)用戶主觀感知的內生性影響因素,用戶私人剩余信息Ii(s)包含自身對不同策略收益差距的敏感性以及在知識交互博弈中積累的經驗等,可以衡量用戶對知識交互預期效用ui(·)的主觀判斷,并可能與客觀博弈規(guī)則存在一定偏差。同時,傳統博弈形式下客觀規(guī)則的不合理(如社區(qū)激勵收益遠大于知識共享收益)會導致絕對占優(yōu)策略的出現,而失去現實指導意義。因此,主觀博弈形式下社區(qū)用戶的預期效用函數應當更加依賴其主觀認知等內生性因素,而不僅僅是由博弈對手與制度環(huán)境等外生因素決定。
2)博弈策略集合
知識“共享”與“不共享”的二元策略集合仍是博弈研究的主流范式[21],但卻難以有效衡量知識共享的程度與效果。如Nielsen J指出,虛擬學術社區(qū)用戶不共享、偶爾共享與經常共享知識的占比為90∶9∶1[22],但二元策略集合難以體現偶爾與經常的差別。而科研人員大多將虛擬學術社區(qū)作為獲取知識資源的一種渠道,對于協同合作并不十分關心[23]的問題同樣不是“知識共享”策略能夠準確描述的。主觀博弈是博弈主體基于主觀認知更新而嘗試新的行動策略,并構建新的博弈形式,其對個體行為的假定更加接近于經驗事實,而博弈策略集合的調整將是虛擬學術社區(qū)用戶學習并重構博弈規(guī)則的重點。青木昌彥指出,主觀博弈形式下每個參與人i的“技術可行”策略集合(si∈Si)可由一個無限維度的空間代表,但任何博弈時點上只能有一個有限維度的子集被啟用并維持一定時間不變[24]。因此,主觀博弈形式下社區(qū)用戶的知識交互策略應當是受其主觀認知積累影響的連續(xù)型策略集合,即用戶可以通過主觀判斷并決定自身參與知識交互的程度與范圍等。考慮到一個博弈節(jié)點只有一種策略選擇以及后續(xù)研究的開展,本文將知識共享二元策略拓展為知識協同、知識互補與知識攫取的三元策略,如表2所示[25-26],以體現社區(qū)用戶主觀認知對知識交互程度與效果的影響,并期望對當前虛擬學術社區(qū)用戶知識交互中攫取常態(tài)、互補偶發(fā)、協同則嚴重匱乏的現狀有所改進。

表2 虛擬學術社區(qū)用戶知識交互行為策略分析
3)共有信念系統
主觀博弈中的共有信念系統是一種組織模式或制度安排,是博弈主體除了私人剩余信息外所共享的一種博弈制度規(guī)則,博弈主體會根據私人剩余信息Ii(s)與對∑*、e等的主觀推斷,在策略集合中啟用合適的策略以獲取最大的預期效用。當博弈主體在各個時期采取的行為策略與預期效用相一致時,其主觀認知得以積累強化并成為未來行為策略選擇的依據,從而形成均衡路徑直至達到穩(wěn)定。反之,博弈主體的主觀認知受到沖擊,引發(fā)其對現有制度規(guī)則的不滿,達到臨界狀態(tài)后便會主動尋求并構建新的制度規(guī)則,即在基于自身主觀認知的重復博弈中形成更加穩(wěn)定的共有信念系統。虛擬學術社區(qū)是相對穩(wěn)定的社群結構,且學術問題需要反復深入討論的過程,但盛小平等指出,虛擬學術社區(qū)中普遍存在核心用戶協同性強而普通用戶積極性低的問題,而發(fā)帖數量越多、聲譽等級越高的用戶越能夠主動與他人交流[27]。因此,聲譽機制不僅能夠有效強化社區(qū)用戶共享或不共享知識的策略選擇[28],而且能夠促使社區(qū)用戶尋求積極的社會認同,以獲得長期的協作機會[29]。所以,隨著知識交互的深入進行,社區(qū)用戶主觀上會輕視社區(qū)規(guī)則的約束,而側重于構建社會化的聲譽機制對其他用戶的知識交互行為進行主觀推斷。此時,主觀博弈形式下博弈環(huán)境e開始由社區(qū)制定的客觀規(guī)則環(huán)境轉變?yōu)橛脩糁鲗У纳鐣粨Q環(huán)境[30],共有信念系統∑*也將在社區(qū)獎懲機制基礎上,引入用戶群體的聲譽機制,以充分考量用戶主觀認知對知識交互的影響機理。
綜上,主觀博弈形式下虛擬學術社區(qū)用戶知識交互的博弈要素推演可以簡單概括為效用函數內生化、策略集合連續(xù)化、共有信念社會化。其中,預期效用函數更加依賴用戶私人剩余信息與主觀認知積累,策略集合隨傳統博弈規(guī)則的打破而得以擴展,共有信念系統也在用戶長期的學習與調整中發(fā)生演變并逐漸趨同。利用科斯盒子反映主觀博弈形式的要素推演,如表3所示。由此,形成共同認知的虛擬學術社區(qū)用戶將在主觀博弈模型下進行重復博弈,直至達成新的、內生性的、更具穩(wěn)定性的主觀博弈均衡,并推動社區(qū)用戶知識交互行為模式的變遷與虛擬學術社區(qū)生態(tài)系統的演化。

表3 主觀博弈形式關鍵要素的推演
2 虛擬學術社區(qū)用戶知識交互的主觀博弈模型分析
2.1 主觀博弈形式下的參數假設與支付矩陣
由于虛擬學術社區(qū)的知識交互是一個反復進行的長期過程,主觀博弈形式下博弈主體會根據主觀認知的積累與更新,在連續(xù)的策略集合中選擇最佳的反應策略,使預期效用最大化,并達成主觀博弈均衡。為便于模型求解與分析,提出假設如下:
假設1:博弈主體設定為各自具有主觀博弈模型,并形成共有信念的虛擬學術社區(qū)用戶a與b,其在每一個博弈節(jié)點能夠從連續(xù)型策略集合中選擇的知識交互策略為{知識協同,知識互補,知識攫取}。
假設2:結合現實情形將主要由私人剩余信息Ii(s)決定的預期效用u(·)界定為:知識協同收益KS、協作成本TS,知識互補收益KC、共享成本TC,且KS>KC、TS>TC,知識攫取收益GS或GC,且GS>GC、KS>GS、KC>GC,搭便車成本忽略為0。
假設3:主觀博弈形式下∑*、e是在社區(qū)獎懲機制等客觀博弈規(guī)則基礎上,基于用戶主觀認知重新構建的基于聲譽機制的博弈規(guī)則。客觀博弈規(guī)則下知識共享(協同與互補)均獲得激勵收益M,知識不共享(攫取)則承擔懲罰損失P;而主觀博弈規(guī)則下知識協同可獲得聲譽收益R,知識互補獲得聲譽收益為0,知識攫取在對方進行知識協同時會遭受聲譽損失L。
由此,在考慮博弈主體私人剩余信息、共有信念與博弈環(huán)境可變的情況下,虛擬學術社區(qū)用戶知識交互的主觀博弈模型支付矩陣如表4所示。

表4 主觀博弈形式下虛擬學術社區(qū)用戶知識交互支付矩陣
2.2 均衡穩(wěn)定分析
假設虛擬學術社區(qū)用戶a選擇知識協同、互補與攫取策略的概率分別為x1、x2與1-x1-x2;用戶b選擇知識協同、互補與攫取策略的概率分別為y1、y2與1-y1-y2。
則用戶a選擇知識協同、互補與攫取策略的期望收益Ua1、Ua2、Ua3分別為:
Ua1=y1(KS-TS+R+M)+y2(KC-TS+R+M)+(1-y1-y2)(R+M-TS)=y1KS+y2KC-TS+R+M
(1)
Ua2=y1(KC-TC+M)+y2(KC-TC+M)+(1-y1-y2)(M-TC)=y1KC+y2KC+M-TC
(2)
Ua3=y1(GS-P-L)+y2(GC-P)
(3)
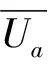
(4)
同理,用戶b選擇知識協同、互補與攫取策略的期望收益Ub1、Ub2、Ub3為:
Ub1=x1(KS-TS+R+M)+x2(KC-TS+R+M)+(1-x1-x2)(R+M-TS)=x1KS+x2KC+R+M-TS
(5)
Ub2=x1(KC-TC+M)+x2(KC-TC+M)+(1-x1-x2)(M-TC)=x1KC+x2KC+M-TC
(6)
Ub3=x1(GS-P-L)+x2(GC-P)
(7)
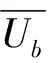
(8)
由此,用戶a和b選擇知識協同策略與知識互補策略的復制動態(tài)方程為:
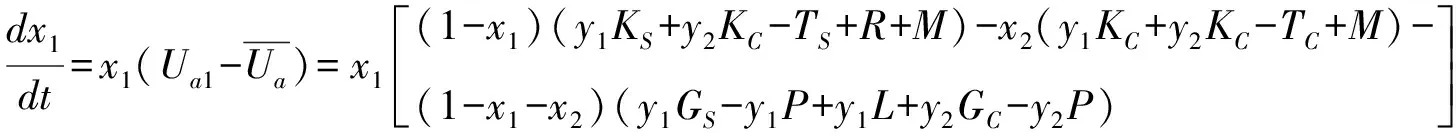
(9)
(10)
(11)
(12)
(13)
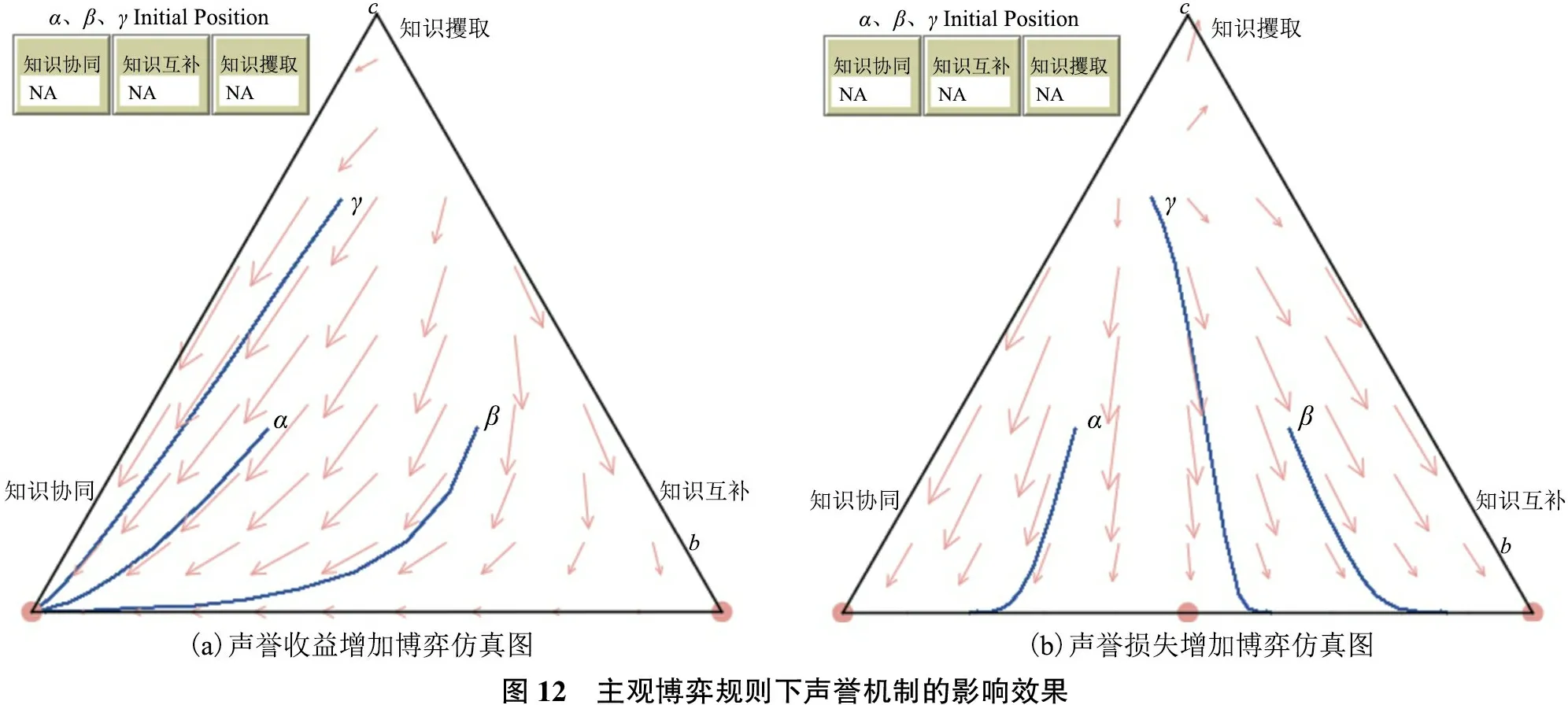
根據表5均衡點穩(wěn)定性分析,D10、D11、D12、D13所需參數條件中知識收益普遍較低,用戶過于注重聲譽收益與獎懲收益,并不符合主觀博弈形式下的現實情形。而D1(0,0,0,0)、D4(0,1,0,1)、D7(1,0,1,0)在滿足一定參數條件時可成為博弈模型的漸近穩(wěn)定點,分別對應知識攫取、知識互補與知識協同3種不同的均衡穩(wěn)定策略。

表5 均衡點穩(wěn)定性分析
3 虛擬學術社區(qū)用戶知識交互的博弈仿真分析
由于三策略博弈模型相對復雜,本文將借助Netlogo軟件與Matlab軟件通過數值模擬對虛擬學術社區(qū)用戶知識交互的均衡穩(wěn)定狀態(tài)進行驗證,并進一步分析博弈參數的調整對虛擬學術社區(qū)用戶主觀博弈均衡的影響機理。其中,Netlogo軟件適合宏觀層面上隨時間推進的多主體復雜系統建模,并具備一定的隨機性與不確定性,符合主觀博弈對有限理性假設的放松要求,而Matlab軟件則能夠有效將微觀個體的復制動態(tài)過程予以準確呈現,兩者相輔相成,能夠更好地反映三策略主觀博弈系統的演化過程與均衡狀態(tài)。
3.1 均衡穩(wěn)定狀態(tài)仿真分析
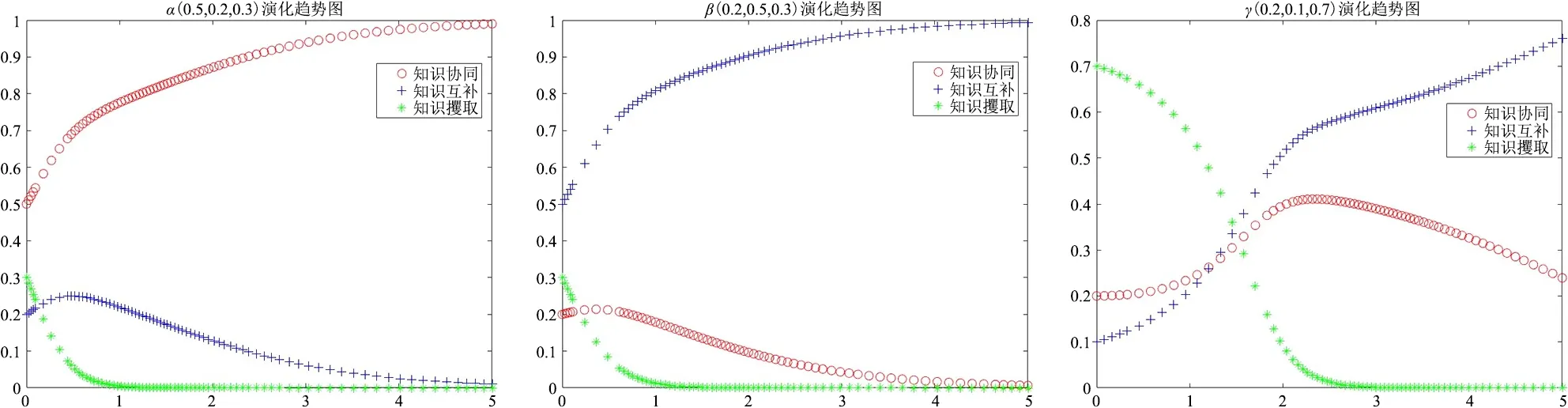
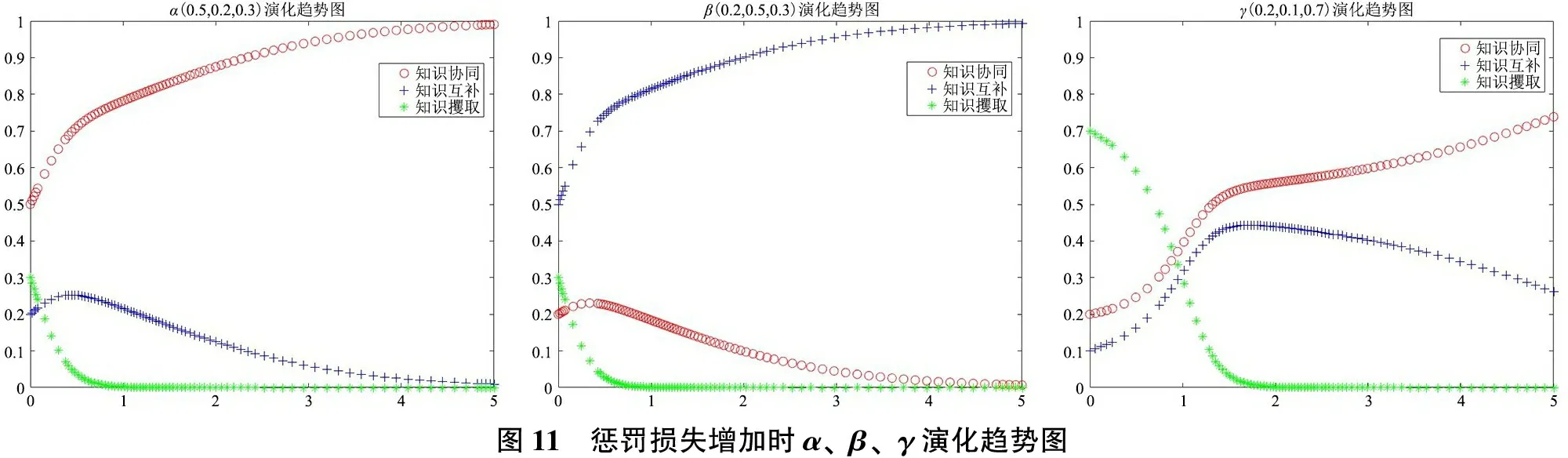
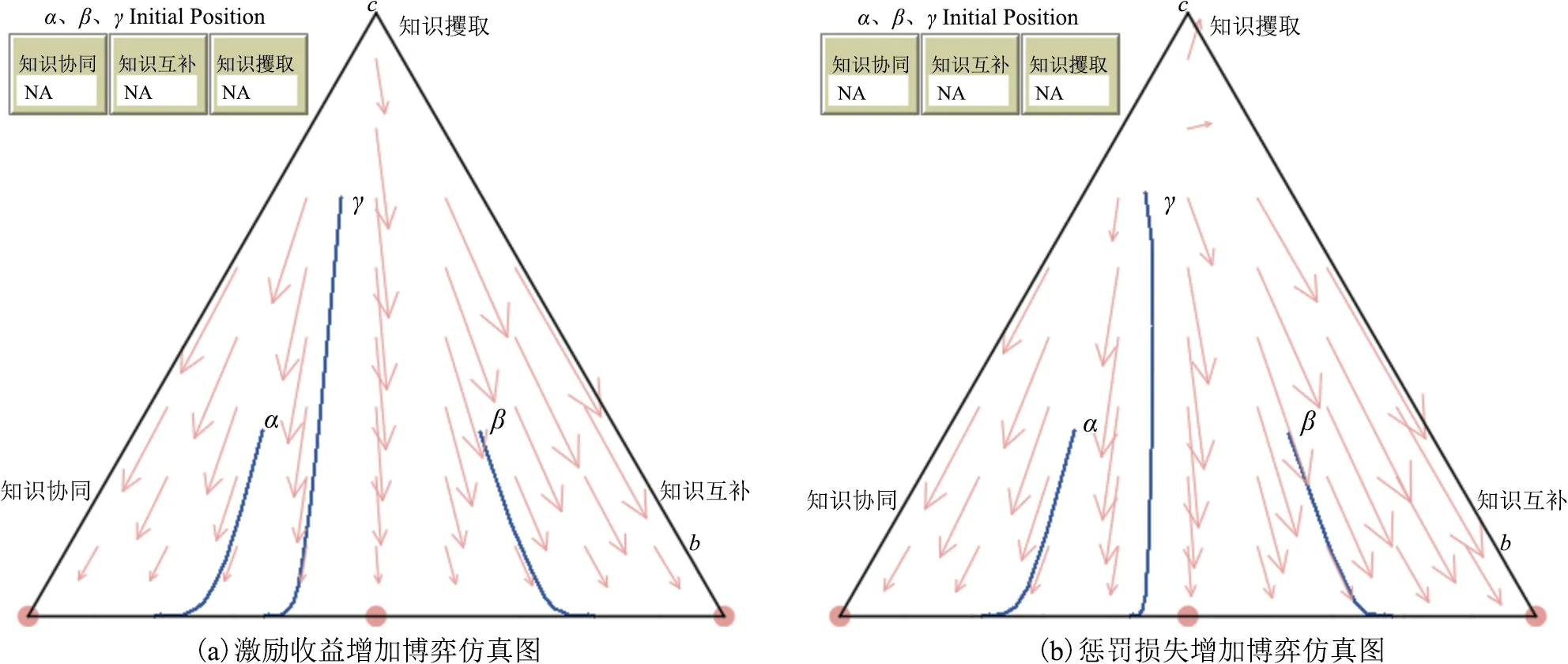
依據參數假設條件,令KS=10、KC=9、R=2、M=2、TS=9、TC=7、GS=8、GC=7、P=1、L=1以符合知識攫取策略為均衡穩(wěn)定狀態(tài)的參數條件R+M 3.2 參數影響機理仿真分析 虛擬學術社區(qū)用戶知識協同、互補與攫取3種均衡穩(wěn)定狀態(tài)均得到有效驗證,但現實中3種知識交互策略往往是同時存在且動態(tài)變化的。同樣依據參數限制條件,令KS=10、KC=8、R=1、M=3、TS=6、TC=4、GS=7、GC=4、P=1、L=1構建知識協同、知識互補、知識攫取3種均衡穩(wěn)定狀態(tài)并存的情形,此時Netlogo仿真結果如圖4所示。同時,分別選取α(0.5,0.2,0.3)、β(0.2,0.5,0.3)與γ(0.2,0.1,0.7)代表社區(qū)用戶基于私人信息與主觀認知而分別偏向選擇知識協同、知識互補與知識攫取策略的初始博弈狀態(tài),并運用Matlab軟件進一步分析用戶在主觀博弈形式下3種知識交互策略的演化趨勢,如圖5所示。 在當前參數條件下,α、β、γ3個點分別趨向于知識協同、知識互補、知識攫取3種不同的均衡穩(wěn)定狀態(tài),即用戶初始狀態(tài)下選擇的知識交互策略大概率會成為最終的演化穩(wěn)定策略。而通過觀察參數調整時α、β、γ3個點的演化趨勢與均衡穩(wěn)定狀態(tài),便可以明晰主觀認知判斷的知識收益與交互成本、社會化的聲譽機制與社區(qū)客觀規(guī)則的獎懲機制等因素對虛擬學術社區(qū)用戶知識交互行為策略選擇與均衡穩(wěn)定狀態(tài)的影響機理。 1)知識收益與交互成本影響分析 基于初始狀態(tài)參數設置,將社區(qū)用戶主觀認知判斷的知識協同收益KS=10調整為KS=13,α、β、γ3點的演化趨勢如圖6所示。隨著知識協同收益增加,3點均最終趨向于知識協同策略,知識互補與知識攫取收益的增加同樣可以得到驗證。表明當用戶主觀認知判斷知識交互的收益增加時,便會延續(xù)之前的博弈策略,直至達到主觀均衡。 圖4 初始狀態(tài)博弈仿真圖 基于初始狀態(tài)參數設置,將知識交互成本TS=6、TC=4分別調整為TS=4、TC=2,α、β、γ3點的演化趨勢如圖7所示。隨著知識交互成本的降低,社區(qū)用戶普遍放棄了消極的知識攫取策略,轉而選擇積極的知識協同策略或知識互補策略,表明用戶主觀感知交互成本的降低,能夠有效減少“搭便車”的知識攫取行為,提升虛擬學術社區(qū)知識交互的積極性。 圖5 初始狀態(tài)下α、β、γ演化趨勢圖 圖6 知識收益增加時α、β、γ演化趨勢圖 圖7 交互成本降低時α、β、γ演化趨勢圖 2)聲譽機制影響分析 基于初始狀態(tài)參數設置,將聲譽收益R=1調整為R=4,α、β、γ3點的演化趨勢如圖8所示。隨著聲譽收益的增加,社區(qū)用戶普遍放棄知識互補策略與知識攫取策略,轉而選擇知識協同策略,表明聲譽收益的增加能夠有效促使用戶進行知識協同,從而提升虛擬學術社區(qū)的科研協作水平與知識創(chuàng)新產出。 圖8 聲譽收益增加時α、β、γ演化趨勢圖 基于初始狀態(tài)參數設置,將聲譽損失L=1調整為L=4,α、β、γ3點的演化趨勢如圖9所示。隨著聲譽損失的增加,社區(qū)用戶普遍放棄知識攫取策略,轉而采取知識協同或互補策略,表明聲譽損失的增加能夠有效促使用戶放棄消極的知識攫取策略,但由于聲譽機制難以調節(jié)知識互補行為,所以用戶只有在知識協同時遭到知識攫取才能給對方造成聲譽損失,因此β和γ點最終趨向于知識互補的均衡穩(wěn)定策略。 圖9 聲譽損失增加時α、β、γ演化趨勢圖 3)獎懲機制影響分析 基于初始狀態(tài)參數設置,將激勵收益M=3調整為M=6,α、β、γ3點的演化趨勢如圖10所示。隨著激勵收益的增加,社區(qū)用戶普遍放棄消極的知識攫取策略,轉而采取積極的知識協同或互補策略,表明激勵收益增加能夠有效減少不勞而獲的知識攫取行為。 圖10 激勵收益增加時α、β、γ演化趨勢圖 基于初始狀態(tài)參數設置,將懲罰損失P=1調整為P=4,α、β、γ3點的演化趨勢如圖11所示。隨著懲罰損失的增加,社區(qū)用戶同樣普遍放棄了知識攫取策略,轉而采取積極的知識交互策略,表明懲罰措施同樣能夠有效減少用戶的知識攫取行為。 主觀博弈規(guī)則并非是對客觀博弈規(guī)則的替代,而是博弈主體在客觀博弈形式基礎上,基于主觀認知的調整與積累形成新的博弈形式,并達成主觀意義上的博弈均衡。具體到虛擬學術社區(qū),聲譽機制是由社區(qū)用戶在連續(xù)知識交互中自發(fā)形成并逐漸穩(wěn)定的主觀博弈規(guī)則,而獎懲機制則是由虛擬學術社區(qū)預先設定的客觀博弈規(guī)則,兩者對于社區(qū)用戶主觀博弈中的連續(xù)型知識交互策略可能存在不同影響。聲譽機制與獎懲機制的博弈仿真如圖12、圖13所示,聲譽機制與獎懲機制均能促進社區(qū)用戶放棄知識攫取策略,但聲譽機制更加能夠促進用戶突破知識互補的均衡狀態(tài),達成知識交互水平與創(chuàng)新價值產出更高的知識協同狀態(tài),如圖12(a)所示。 值得注意的是,在當前參數設置下,聲譽機制中正向收益的增加能夠有效促進知識協同均衡狀態(tài)的達成,但負向損失增加的影響效果相對一般。其原因可能在于兩個方面:①只有在個人聲譽積累或提升的過程中,虛擬學術社區(qū)用戶才會更加注重自身聲譽的維護,個人聲譽的提升也會促使其更加積極地參與共享與協作。但在匿名的虛擬網絡環(huán)境中,若個別用戶不在意個人聲譽,則即使聲譽受損也不會做出積極的改變。即在當前共有信念的主觀博弈形式中,社區(qū)用戶的私人剩余信息更加重視聲譽機制正向反饋所帶來的收益;②知識協同與知識互補具有本質區(qū)別,知識協同是以合作關系為基礎、以知識創(chuàng)新為導向、以科研產出為目標而形成的用戶間知識交互行為,而包含聲望、信譽甚至知識位勢在內的聲譽優(yōu)勢能夠快速促成知識協同關系的達成,降低交互成本,但負向的聲譽損失對于知識協同的達成并無實質性影響。即在連續(xù)型策略集合的主觀博弈形式中,聲譽收益增加更能動態(tài)促進用戶提升知識交互水平。這符合虛擬學術社區(qū)用戶知識交互的現實情形,也從側面證明主觀博弈形式下可變結構博弈模型構建的合理性,同時能夠為虛擬學術社區(qū)突破知識互補限制、達成知識協同狀態(tài)提供管理建議。 圖13 客觀博弈規(guī)則下獎懲機制的影響效果 基于理論推演與現實考量,本文將過往知識共享研究中普遍采用的傳統博弈視角轉化為主觀博弈視角,通過預期效用函數的內生化、策略集合的連續(xù)化與共有信念的社會化,將過往知識共享博弈研究中取決于外部客觀環(huán)境與對手策略的預期策略收益轉變?yōu)槿Q于自身主觀認知判斷的預期效用函數,以更為核心的知識收益考察社區(qū)用戶主觀認知的內生性影響;將“共享”與“不共享”的傳統二元策略集合拓展到“知識協同”“知識互補”“知識攫取”的三元策略集合,以嘗試符合主觀博弈中連續(xù)型策略集合的研究范式;在社區(qū)預設獎懲機制等客觀博弈規(guī)則基礎上,結合虛擬學術社區(qū)用戶群體結構與知識交互特征,引入社會化的聲譽機制作為用戶群體自發(fā)構建并趨于穩(wěn)定的主觀博弈共有信念,以體現用戶主觀認知的積累與更新,并更加貼近現實情形。通過對主觀博弈視角下可變結構博弈模型的均衡穩(wěn)定分析與仿真模擬發(fā)現,用戶主觀認知決定的知識收益與交互成本、群體自發(fā)形成的聲譽機制與社區(qū)預設的獎懲機制均能促使社區(qū)用戶放棄消極的知識攫取策略,轉而采取積極的知識互補或知識協同策略(取決于社區(qū)用戶知識交互的初始狀態(tài))。但值得注意的是,社區(qū)獎懲機制的客觀博弈規(guī)則只能杜絕知識攫取策略,但聲譽機制的主觀博弈規(guī)則(聲譽收益增加)則能夠突破知識互補均衡狀態(tài),達成知識協同的均衡穩(wěn)定狀態(tài)。 由此,除了取決于社區(qū)用戶主觀認知判斷的知識收益與交互成本外,虛擬學術社區(qū)可以從聲譽機制強化與獎懲機制優(yōu)化入手,改善運營管理模式,促進社區(qū)用戶進行知識協同與合作創(chuàng)新,逐步形成具有廣泛信任與協作關系的利益共同體,提升虛擬學術社區(qū)的創(chuàng)新產出與應用價值。在聲譽機制強化中,虛擬學術社區(qū)一方面可以通過實名認證等方式關聯用戶個人信息,了解其知識背景與學術成果,并通過社區(qū)官方認證、特殊身份標識等方式確立其意見領袖或科研合作帶頭人等社區(qū)地位;另一方面,對于積極參與知識協同與創(chuàng)新合作的用戶可以通過好友推薦、首頁推送等方式提高其知名度與關注度,以社區(qū)背書增加其個人聲譽,從而擴大其知識協同與科研合作的范圍,充分發(fā)揮聲譽機制對用戶知識交互的正向引導作用。而在獎懲機制優(yōu)化中,虛擬學術社區(qū)可以利用數據挖掘與用戶畫像等方法,構建更具針對性與差異化的激勵機制與更為開放全面的科研創(chuàng)新評價體系;同時可以通過對社區(qū)用戶的實名認證、等級劃分、信用評價等方式,有效識別“搭便車”與不勞而獲的個別用戶,并通過設置發(fā)帖限制、瀏覽與下載權限、好友互動權限等方式避免其知識攫取行為,合理保護其他用戶的知識產權與創(chuàng)新成果。 本文不足之處在于對主觀博弈模型的策略集合擴展與均衡穩(wěn)定分析仍然受到傳統演化博弈模型研究范式的限制。未來將嘗試在計算社會科學的指導下,利用仿真實驗等方法,構建更加貼近用戶主觀認知、更加符合現實情形、更能考察主體認知等內生性影響因素的主觀博弈模型,探究個體認知與群體行為對系統均衡的影響機理。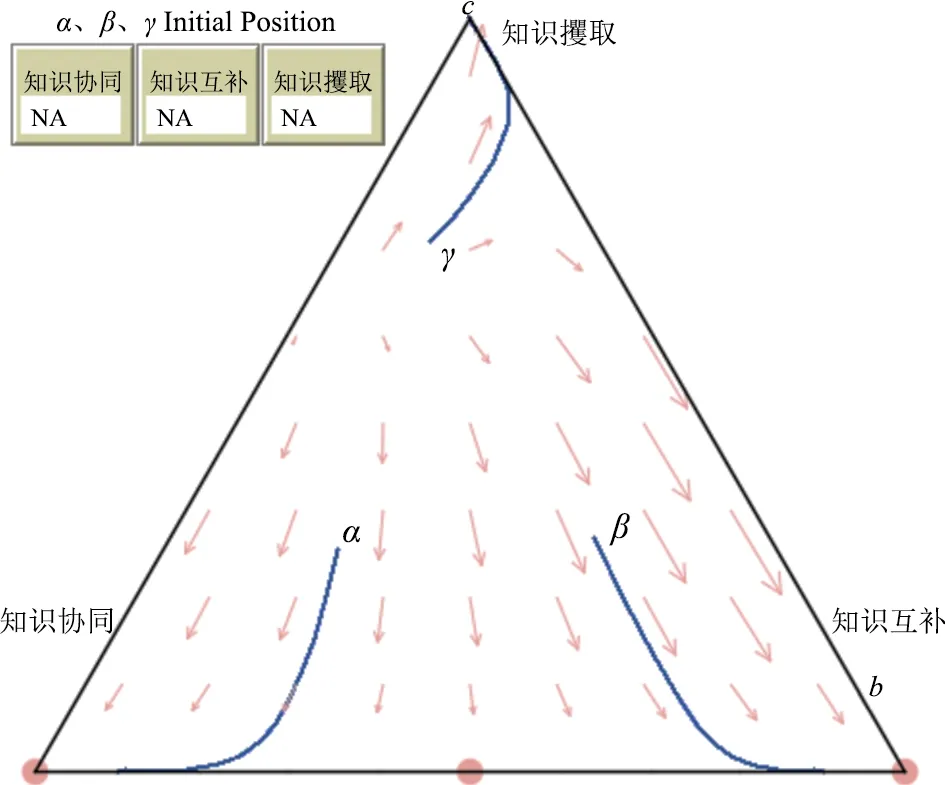





3.3 主觀與客觀博弈規(guī)則對比分析
4 結論與啟示
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
