基于OAVU四元組的數值型知識元表示方法與實踐
2022-08-11 03:16:54王山
現代情報 2022年8期
王 山
(中國社會科學院經濟研究所,北京 100836)
在當前數據化與智能化的社會背景下,數據量呈指數趨勢發展,面對海量增加的數據信息,傳統的以卷/冊或篇為單元的文獻服務已遠不能滿足用戶的需求。多數情況下,用戶感興趣的可能只是專利文獻或科技論文全文中的某一數值信息。中國科學院文獻情報中心劉細文[1]指出,未來情報工作的戰略選擇應該重視發展基于數值的情報研究,建立以智能情報為核心的決策支持系統,進而充分發揮情報研究的決策咨詢作用。國防科技大學羅威等[2]認為,數據驅動的技術預測需要綜合利用科技文獻的元數據、全文數據等,因數據涉及的內容紛繁復雜,層次不一,文章從數據、流程和系統3種視角對數據驅動的技術預測進行了梳理,提出了開展數據驅動的技術預測需要重點關注的六大關鍵技術問題。Mckeown K等認為,在進行技術預測時,引入基于全文的指標,抽取出全文中所蘊含的有價值的數值信息將顯著提升技術預測的結果[3]。鑒于數值信息所具有的研究價值和實際應用價值,基于數值信息的知識服務相關研究越來越受到眾多科研人員的關注與重視。但文獻中的數值信息一般以非結構化形式存在,如何對這些數值信息進行結構化表示并逐漸提高信息抽取的準確率,成為了知識服務中重要的研究內容。
數值信息的結構化表示是簡化數值信息描述與實現信息準確抽取的基礎,因為信息抽取的目標是從海量無規則數值信息中通過自動化的技術提取出計算機能夠理解、計算的結構化信息。由于科技文獻中數值信息所蘊含的價值巨大,增值應用前景廣闊,近年來國內外學者依據各自研究領域的特點,從不同的視角對數值信息的知識表示方法進行了積極有效的探索。數值型知識元作為數值信息的一種,因詞匯表達、句法特征與表達方式的復雜性和多樣性,知識表示方式更加靈活多樣。然而,數值型知識元在知識表示方面的實踐遠落后于理論方面的研究,迄今為止還未見有學者對電化學領域科技文獻中表征技術發展水平的性能指標數值信息進行知識表示與抽取,且已有數值型知識元表示較多局限于數字表達,在抽取結果中難以呈現出與命名實體之間的邏輯關系。因此,本文創新性地提出一種“研究對象(Object)—屬性(Attribute)—數值(Value)—單位(Unit)”(以下簡稱OAVU)四元組的數值型知識元知識表示結構,根據數值型知識元的詞匯表達、句法特征構建領域數值型知識元四元組結構,然后編寫相對應的正則表達式實現領域數值型知識元的抽取,最大化利用隱藏在無序信息載體中大量有價值的數值信息,滿足科研工作者數據驅動型研究的信息需求,實現數據統計分析、學術論文評價、知識挖掘與技術發展趨勢預測等高層次的數值信息增值服務,為科學知識傳承、科研方向選擇、技術路徑確定與科研創新等提供高效支撐。
1 文獻綜述
1.1 數值型知識元與數值信息
當今大數據環境下,情報信息的采集往往交由計算機自動完成,如關鍵核心技術的指標數據監測、軍事武器裝備的監測等,這些工作的其中一個焦點就是對數值信息進行采集監測。科技文獻中的數值是一種有價值的信息,它存在于一定的上下文中。從表達形式上看,數值信息多以“數字”表達為構成主體,基數類數值信息是未與量詞結合的相對“單純”的數字,如序數詞、分數、小數等,構成比較簡單,所含信息量較少,且數據本身沒有較大的實際意義;數量類數值信息是在基數類數值信息的基礎上加上量詞或者特定符號組成,以數詞開頭、量詞結束,結構比較穩定,雖較易抽取識別,但數量類數值信息一般沒有具體的對象,難以表達出事物本身的客觀事實;數值型知識元是在數量類數值信息的基礎上加上句子其他組分組成的,含有的信息更加完整,能夠獨立描述事物本身數值信息的知識單元。另外,在ACE(Automatic Content Extraction)測評會議中,特定情景下的事件名稱也作為數值信息研究的主要內容,如“北京奧運會的贊助單位為聯想公司”“小明在阿里巴巴擔任總經理”,其中的單位信息、職位信息也被視為數值信息的一種[4-6]。數值信息主要分類如表1所示。因基數類、數量類數值信息難以展現出與研究主體或研究對象之間的邏輯關系,文章主要圍繞數值型知識元展開知識表達與實踐方面的研究。
1.2 數值型知識元多元組表示
肖洪等認為,數值型知識元是代表客觀事物或事件本身數值方面的屬性,如長度、銷售額、利潤等,依據經濟學領域特點,將數值型知識元劃分為宏觀數值知識元與微觀數值知識元,并用六元組表示經濟學領域數值型知識元結構,即{時間、主題、指標、謂詞、數值、單位}[7],例:{2005年、盤龍區、工業總產值、完成、62.93、億元}。溫有奎等認為,數值型知識元是以數值形式存在,能夠表達一個獨立的事實,并用{時間、地域、領域、對象、對象數值、單位、上屬對象、相關對象、數據來源}來表達數值型知識,并提出數值型知識元的抽取是建立知識元庫的先導和基石。他研究了數值知識元的特征和抽取規則,開發出一套數值知識元抽取軟件,用于從年鑒、網頁文本中自動抽取數值知識元并將抽取結果自動存入庫中[8-10]。Roy S等認為,數值信息包含數字、單位、變化性3個語義槽,并提出數量—值二元模型嘗試對數值信息的內部結構進行語義分析,但這種模型粒度較粗,難以向下游應用提供更多豐富信息[11]。Lamm M等提出了適用于金融領域的數值語義角色標注模型(Quantitative Semantic Role Labels),根據金融領域的需求設計了包括7個顯式語義角色和5個上下文相關的語義角色[12]。吳超等認為,數值型知識元是一個含有數值信息并能夠完整表達事實的信息單元,并將數值型知識元分為基礎數據知識元、過程數據知識元與結果數據知識元,并對計算機科學、情報學、計算語言學、醫學與管理科學與工程學科領域數值信息抽取相關內容進行了分析[13]。周和玉討論了一種適用于知識工程領域的“研究對象—屬性—數值”三元組知識標引法,該方法不僅可以表達文獻主題內容,還能表達其所含知識。每一組“研究對象—屬性—數值”三元組構成一個知識單元,多組“研究對象—屬性—數值”可以充分表達一篇文獻的研究特點及所含數據和知識[14]。

表1 數值信息主要分類表
通過學者們對數值型知識元的定義可知,數值型知識元是從數值角度描述客觀事物或事件本身數值方面的知識單元,包括數據類知識和科學數據,具有數值分析與知識推理的功能。在知識表示層面,因研究領域的差異性與詞匯、句法特征表達的多樣性,數值型知識元具有不同粒度的知識表示結構,一般以多元組形式呈現,且結構元素具有明確的描述對象、具體的主題、確切的數值和單位量詞等。但數值型知識元涉及到的學科領域不夠豐富,表達結構比較復雜,移植性較差,迄今為止還未見有學者針對自然科學領域科技文獻中的數值型知識元進行知識表達與抽取。已有知識工程“研究對象—屬性—數值”三元組法雖可用于評價文獻的知識量及創新程度,利于提高文獻庫的使用效率與情報分析精度,但該種方法使用的前提是需要先建立一個由“研究對象—屬性—數值”三元組法標引的文獻知識庫,因研究領域的差異性特定領域大規模已標注的數據事實語料庫較少,因此篩選出用戶所需要的數據與事實,定位用戶感興趣的片段實屬困難,且該方法在技術發展水平評價和趨勢預測方面缺乏真正的實踐應用。
1.3 數值型知識元抽取
信息抽取領域,數值型信息的抽取始于2000年12月美國組織的ACE評測會議,而中文數值信息的識別和抽取則始于2005年。數值信息抽取的目標是從海量的數據中,通過自動化的技術提取出計算機能夠理解、計算的結構化信息,并以此幫助下游應用[6]。通過研讀已有文獻可了解到數值信息抽取所采用的數據源較多集中在報紙、新聞語料與Web網頁上[5],且抽取的對象以基數類與數量類數值信息為主,對于數值型知識元抽取的研究工作主要有:Roy S等學者針對數值信息的內部結構提出了數量—值二元表示模型,并通過Semi-CRF序列標注模型定位到原始文本中表達數值的連續字串,然后運用基于規則的方法對字串中的語義成分進行了抽取和標準化[11]。Collobert R等利用前向神經網絡,使用固定大小的窗口獲取每個單詞的上下文信息,提出了基于窗口和句子方法兩種網絡結構進行實體識別[15]。Lample G等首次使用一種小規模監督數據集并結合大量無標注語料進行訓練,通過反向傳播算法調整訓練模型的參數與使用Dropout提高模型泛化能力后取得了不錯的識別效果[16]。綜上,關于數值型知識元抽取的方法主要有兩種:一是規則與指標構建相結合的方法。該方法抽取準確率高,但需要投入較多的人力和時間;二是基于機器學習自動抽取的方法。雖然近年來機器學習抽取方法不斷完善,效率較高,但目前尚未開發出大規模已標注的數值型知識元語料庫,采用機器學習的方法對數值型知識元進行自動抽取有一定的困難,且抽取的準確率不盡人意。因此,為了提高數值型知識元抽取的準確率,本研究擬采用人工構建規則與指標構建相結合的方式實現數值型知識元的抽取,抽取流程示意圖如圖1所示。

圖1 數值型知識元四元組抽取流程
首先在確定研究對象的基礎上建立目標研究領域數值型知識元特征詞集,對所下載的文獻摘要進行文本預處理,提取含有技術性能特征數值型知識元(屬性、數值、單位)的語句;選擇對文獻摘要中的數值型知識元進行處理主要考慮以下3個方面:一是數據層面,與摘要相比,科技文獻全文數值型知識元的獲取難度較大;二是技術層面,科技論文一般是PDF格式,將PDF格式轉化為計算機可讀的文本形式Bug較多,分析處理起來耗時耗力;三是內容層面,為了展現科技論文實驗結果的優越性,自然科學領域表征技術性能指標發展水平的數值型知識元較多出現在文獻摘要中。因此,本研究選擇文獻摘要進行文本預處理。文本預處理后運用Python編寫代碼對該語句進行切分,然后通過對所切分的句子集進行總結歸納,記錄技術性能指標“屬性—數值—單位”的規律性描述,繼而構建候選規則集;最后運用Python構建數值型知識元“屬性—數值—單位”三元組結構的正則表達式,實現“屬性—數值—單位”的抽取。其中,正則表達式是對字符串操作的一種邏輯公式,是運用事先定義好的一些特定字符、或特定字符的組合組成一個“規則字符串”,來檢索、替換那些符合某個模式(規則)的文本。
2 數值型知識元知識表示方法設計
2.1 數值型知識元四元組知識表示
考慮到上文所述數值型知識元在知識表示方面的研究局限,本研究設計了一種適用于自然科學領域的,用于技術發展水平評價和趨勢預測的四元組表示結構,即“研究對象—屬性—數值—單位”。在這種知識表達方法中,O代表對象(Object),既可以指物理實體,也可以指概念上的實體,如鋰離子電池正極材料磷酸鐵鋰、船舶的運輸業務等;A代表屬性(Attribute),指與對象有關的一般特征或性質,如磷酸鐵鋰正極材料振實密度、放電容量、鋰離子擴散系數、電導率與能量密度等;V代表值(Value),是指屬性在一定條件下的數值,如磷酸鐵鋰正極材料振實密度、放電容量、鋰離子擴散系數、電導率與能量密度的具體數值等,其中,值并不一定是具體的數值,也可以是描述語,如顏色屬性的值可以是紅、黃、藍;U代表單位(Unit),指計量屬性的名稱,如航空發動機運轉時內部溫度能夠達到2000℃,其中單位指的是℃。例如:某篇文獻的一段文字:在鋰離子電池正極材料中,磷酸鐵鋰(LiFePO4)因較低的電子導電率(10-7~10-10S·cm-1)和鋰離子擴散系數(10-12~10-16cm2·S-1)導致其倍率性能不佳,難以滿足迅猛發展的電動汽車鋰離子電池對功率密度的需求。OAVU四元組結構可以表達為(磷酸鐵鋰、理論比容量,170,mAh/g)、(磷酸鐵鋰、電子導電率,10-7~10-10,S·cm-1)與(磷酸鐵鋰、鋰離子擴散系數,10-12~10-16,cm2·S-1)。本文所設計的數值型知識元四元組表達結構在確定研究對象Object基礎上,不僅可以建立起屬性A與單位U之間的對應關系,還可以呈現出與研究對象之間的邏輯關系,拓展了科技文獻大數據內容挖掘的粒度和深度,彌補了數值型知識元在自然科學領域科技文獻中數值型知識元表示方法的不足。
2.2 抽取結果評價
查全率與查準率是信息檢索領域檢驗信息抽取結果的重要指標,在對數值型知識元抽取結果檢驗方面,僅僅通過效仿信息檢索領域的查全率與查準率,引入正確率、召回率與綜合指標F值。雖然信息抽取結果評價指標比較單一,不能全面反映抽取結果的好壞,但正確率、召回率與綜合指標F值仍為目前結果評價中比較有效的指標。因此,本研究擬采用精確率、召回率與F值對抽取出的實驗結果進行評價,計算公式如下:
正確率(P)=正確抽取的信息數/需要抽取的信息數×100%
(1)
召回率(R)=正確抽取的信息數/所有的信息數×100%
(2)
F={P×R×(β2+1)}/(R+β2×P)×100%
(3)
β是正確率(P)與召回率(R)重要性的加權系數,本研究取均衡權重,將正確率與召回率視為同等重要,取β=1。
3 實證分析——以磷酸鐵鋰正極材料研究領域為例
正極材料作為鋰離子電池最關鍵的功能材料,是鋰離子電池鋰離子之源,也是鋰離子電池能量密度的基礎,決定著鋰離子電池整體的電化學性能及其成本。鋰離子電池正極材料(表達式為LiFePO4)因鐵資源豐富、價格低、無污染等優點成為一種大型能源所需的具有良好發展前景的材料[17-18]。本文以鋰離子電池正極材料LiFePO4為研究對象,探討數值型知識元四元組表達方法在該領域的應用。
3.1 數據來源與檢索
論文及專利文獻數據來源分別選擇收錄自然科學、工程技術領域最具影響力的SCI Expanded數據庫及覆蓋全球專利信息比較全面、權威的Derwent World Patents Index數據庫。通過調研大量文獻及結合專家建議制定鋰離子電池正極材料磷酸鐵鋰研究領域的檢索式為:TS=((“Lithium iron phosphate” OR “LiFePO4” OR “LFP” OR “LiFePO4/C” OR “LiFePO4@C”) AND (“batter*” OR “cell*” OR “polymer battery” OR “dop*”)),檢索時間段為PY=2016,數據采集樣本量如表2所示。

表2 數據采集信息表
3.2 磷酸鐵鋰數值型知識元四元組知識表示
通過大量研讀鋰離子電池磷酸鐵鋰正極材料相關文獻可知,表征磷酸鐵鋰電化學性能的屬性主要有倍率放電容量、鋰離子擴散系數、電導率、振實密度與比表面積等。基于指標的代表性、動態性、科學性及可量化性,本研究選取了7個技術屬性,分別為正極材料振實密度、0.1C放電倍率下放電量、5C放電倍率下放電量、10C放電倍率下放電量、離子電導率、鋰離子擴散系數與電池質量能量密度[19-20]。其中,材料振實密度是表征正極材料顆粒間相互作用常用的指標;0.1C放電倍率下放電量、5C放電倍率下放電量與10C放電倍率下放電量可在一定程度上反映出低、中、高倍率下電池正極材料放電狀況;離子電導率可以體現正極材料電荷流動難易程度;鋰離子擴散系數可以考察出鋰離子在電解液中的擴散能力;質量能量密度在一定程度上可以反映出電池儲存能量的能力。
結合科技文獻中磷酸鐵鋰正極材料屬性、數值與單位表達方式,磷酸鐵鋰研究領域數值型知識元四元組結構表達式如下,以離子電導率為例,因數值型知識元四元組英文結構表達式較多,現僅展示部分,如(lithium iron phosphate,ionic conductivity,value,S/m)、(lithium iron phosphate,ion conductivities,value,S cm(-1))、(lithium iron phosphate,ion conductivities,value,mS cm(-1))、(lithium iron phosphate,ion conductivities,value,S CM(-1))、(lithium iron phosphate,electric conductivity,value,S CM(-1))、(lithium iron phosphate,electronic conductivity,value,S/m)、(lithium iron phosphate,electronic conductivity,value,S CM(-1))。表3展示了磷酸鐵鋰正極材料“研究對象—屬性—數值—單位”四元組在科技文獻中的主要出現形式。
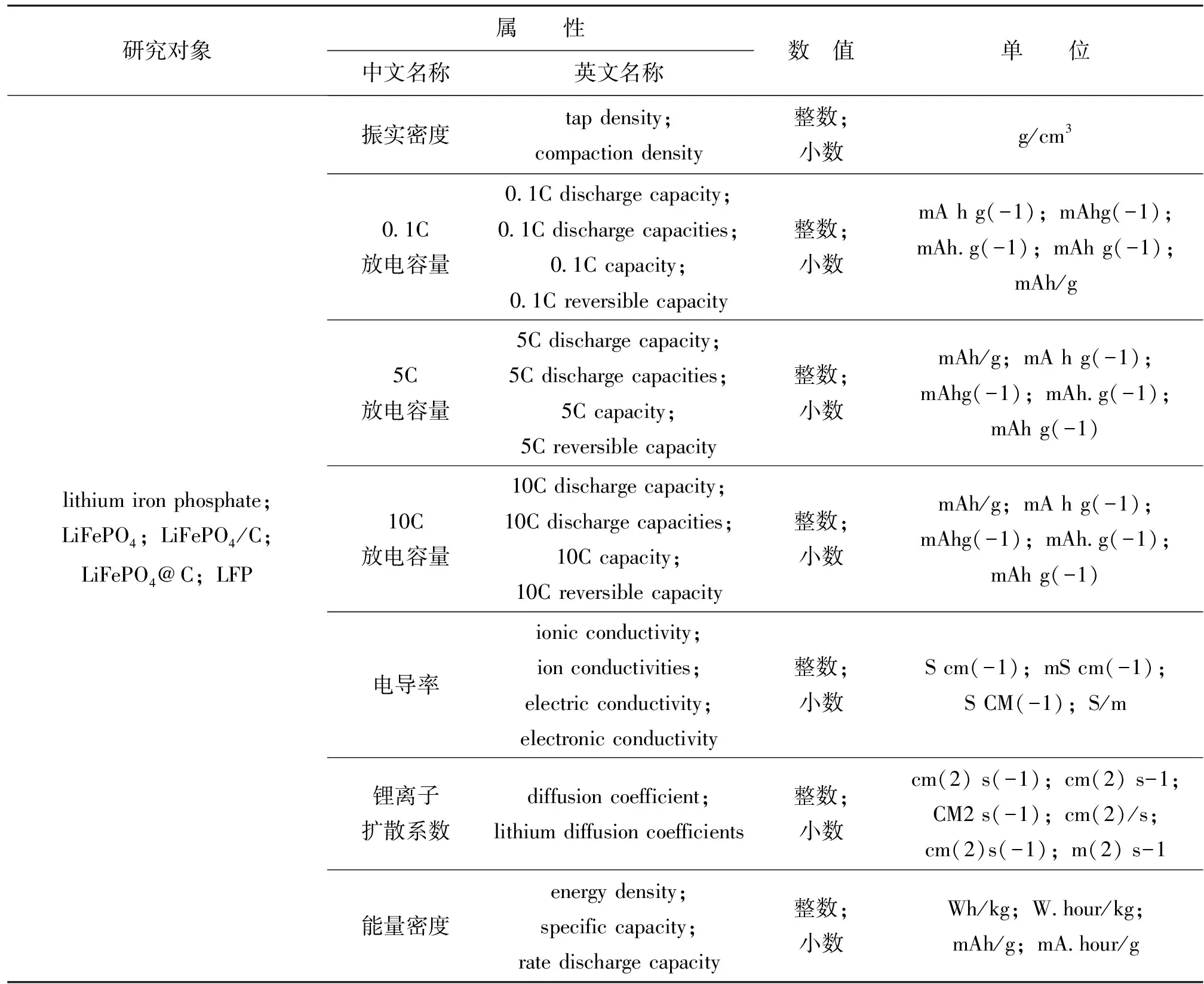
表3 磷酸鐵鋰數值型知識元四元組每組主要的出現形式
3.3 有效性驗證
為了驗證本研究所設計的“研究對象—屬性—數值—單位”四元組知識表達結構在數值型知識元抽取方面的優越性,本研究選擇能夠充分表達文獻主題內容的知識工程“研究對象—屬性—數值”三元組標引法,因為知識工程“研究對象—屬性—數值”三元組知識表達法自提出以來,主要應用于特定領域的知識標引與科技項目的查新咨詢,以解決科研主題、成果評審中的創新性評價問題,在篩選用戶感興趣的數據或事實方面可以起到有效的作用。因此,本研究通過數值型知識元四元組法與知識工程三元組法的對比分析來驗證本文所設計的數值型知識元四元組知識表達結構的有效性。兩種知識表達結構抽取結果如表4所示。實驗結果表明,數值型知識元四元組中單位這一增量對科技文獻數值型知識元的抽取產生較大的影響,主要體現在數值抽取更加全面,通過屬性與單位所建立的對應關系使得數值型知識元抽取的準確率、召回率與F值均高于知識工程三元組法。在研究對象、屬性一致的情況下,采用知識工程三元組法所抽取出來的數值不一定是特定屬性下所對應的準確數值,而通過本研究所設計的知識表達方法所建立的屬性與單位共存的正則表達式能夠迅速定位到用戶感興趣的數值型知識元,不僅提高了數值型知識元抽取的準確率,也使得抽取出的數值型知識元更加接近于需要抽取的數值型知識元。
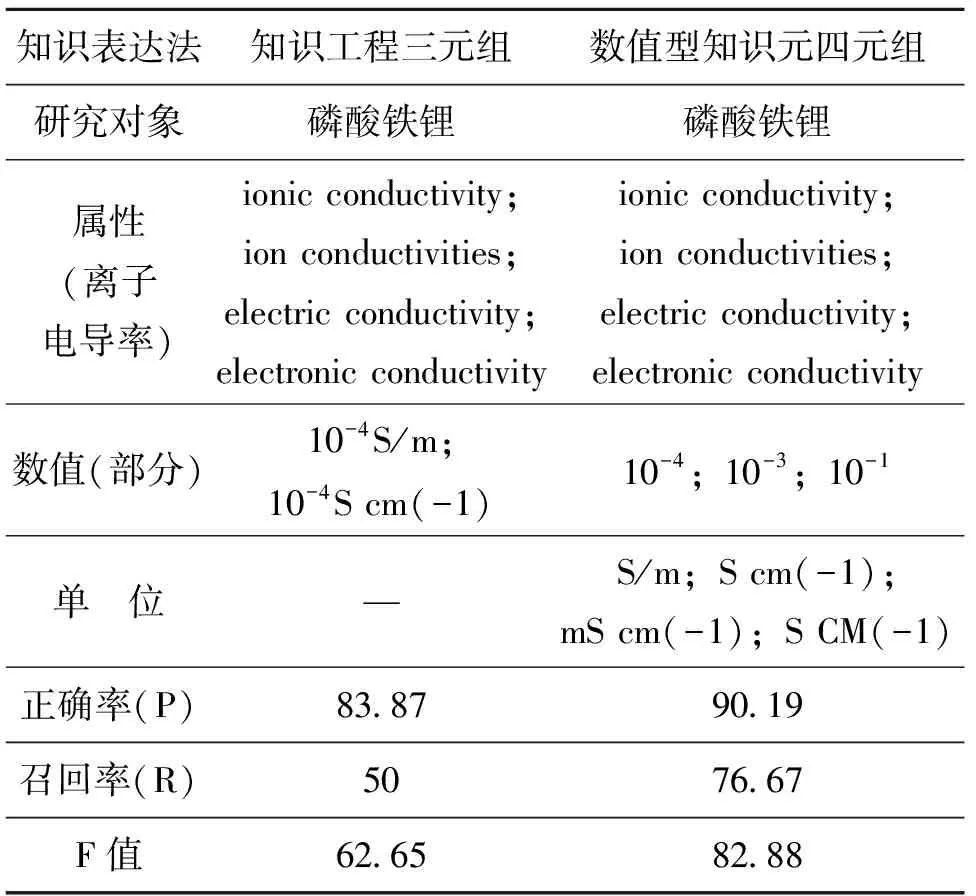
表4 不同知識表示方法抽取結果比較 %
4 總結與展望
自然科學領域數值型知識元知識表達與抽取方面的研究對技術發展規律掌握與發展趨勢預測等具有重要的現實意義與實用價值。本研究系統梳理了已有學者對數值型知識元知識表示與數值型知識元抽取方面的研究成果,發現數值型知識元表達結構比較復雜,移植性較差,涉及的學科領域不夠豐富,難以迅速篩選出用戶感興趣的數據或事實,在技術發展水平評價和趨勢預測方面缺乏真正的實踐應用。針對以上研究局限,本文創新性地設計了“研究對象—屬性—數值—單位”數值型知識元四元組結構,在一定程度上提高了數值型知識元抽取結果的準確率與召回率,彌補了電化學學科領域表征技術發展水平指標的數值型知識元知識表達方法的不足。本研究的主要貢獻在于:①本研究所提出的“研究對象—屬性—數值—單位”四元組結構可以較為準確地抽取出電化學研究領域表征技術發展水平的數值型知識元知識,拓展了科技文獻內容挖掘的粒度和深度,有助于科研人員密切跟蹤技術發展態勢,識別、掌握和突破關鍵核心技術中處于“卡脖子”短板位置的技術性能指標;②本研究所提出的知識表達結構可建立研究對象、屬性與單位之間的索引,豐富了自然科學領域數值型知識元的知識表示方法體系,不僅可以深度解析科技文獻內容,為文本內容挖掘的成果輸出提供了新形態,也為科技文獻大數據的開發利用奠定了數據基礎。
本研究所提出的數值型知識元四元組結構也存在一定的研究局限。首先是技術屬性層面,數值型知識元四元組結構更適應于研究對象屬性易量化的技術領域,對于較難量化的安全性、可靠性等技術屬性知識表達則有待進一步考察;其次是通用性層面,文章考察了數值型知識元四元組結構在電化學領域的知識表達與實踐應用,對于自然科學領域中其他研究領域適用性如何,有待進行更深入的研究。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
