通用數據交換耦合技術“三源”關系探究
2022-05-30 06:08:14趙毓峰叢磊
出版廣角 2022年13期
趙毓峰?叢磊
【摘 要】作為國家新聞出版署出版產業通用數據交換技術重點實驗室研究性課題之一,出版業通用數據交換平臺的構建是實驗室建設的重要組成部分。文章系統論證了出版業通用數據交換平臺中三個核心部分(“三源”)的定義和作用,并著重探討“三源”在平臺架構中的關系,最后通過實驗平臺的實例,展示出版業通用數據交換平臺的優勢。
【關? 鍵? 詞】出版業;通用;數據交換
【作者單位】趙毓峰,出版產業通用數據交換技術重點實驗室,北京理工大學出版社有限責任公司;叢磊,出版產業通用數據交換技術重點實驗室,北京理工大學出版社有限責任公司。
【基金項目】本文系國家新聞出版署“出版產業通用數據交換技術重點實驗室”研究性課題。
【中圖分類號】G230.7 【文獻標識碼】A 【DOI】10.16491/j.cnki.cn45-1216/g2.2022.13.007
在數字化、信息化大潮的引領下,國內大多數出版企業根據自身的實際情況開展了數字化、信息化建設,圖書的選題策劃、編輯加工、印制發行等各個環節,都能產生相應的數字化、信息化產品和海量數據。在出版業各個環節中,利用以物聯網、大數據、云計算、人工智能、5G網絡、區塊鏈為代表的現代信息技術使這些海量數據互聯互通,能夠有效消除信息孤島,構建全行業的通用數據交換生態,為有力推進出版業信息化進程作出貢獻。
一、出版業通用數據交換平臺的設計背景
目前,出版企業存在數據交換、數據分析方面的迫切需求,不僅有企業內部數據交換需求,還有企業對外數據交換需求。國內外出版企業普遍采用“FTP+XML”接口模式進行數據交換[1],基于此模式開發的接口采用的是“軟件代碼與業務代碼交織在一起”的模式,任意節點業務規則的變化,都會導致所有接口需要重新開發。此種數據交換模式,無論是研發費用還是后續的維護或接口模式修改費用,都大大超出了出版企業的承受能力。
1.出版業數據交換面臨的主要挑戰
出版業大數據包括七類數據,分別是機構數據、人員數據、產品數據、政務數據、商務數據、用戶數據和內容數據。出版業的數據分散在不同的主體中,這七類數據散落在政府部門、出版企業、發行商、圖書館、科研院所、廣電商、電商平臺等。主體接收的數據分散,導致主管部門與出版業主體之間、產業鏈上中下游主體之間信息不暢,信息系統無法實現互聯互通,產業鏈數據不能真正融合[2]。
以北京理工大學出版社為例。作為出版企業,北京理工大學出版社在開展出版業務的過程中,需要完成如下工作:與發行商(如各級新華書店)、圖書館、電商平臺(如京東、當當等)之間的圖書信息推送、批銷單生成、物流配送、財務結算等數據交換工作;與排版廠、設計公司、印刷廠等單位傳遞排版、封面設計文件,完成財務結算等數據交換工作。需要與北京理工大學出版社完成數據交換工作的單位粗略估計有幾百家,幾乎每家單位的信息化應用系統都是孤立存在、互不兼容的。甚至在使用相同應用系統(如目前出版業較常用的 “云因系統”)的不同企業之間,由于管理理念的差異,也無法進行有效的數據交換,導致出版企業需要通過電話、傳真、電子郵件等方式傳遞信息,然后通過人工處理完成所有業務,費時費力,效率低下。為此,北京理工大學出版社數字出版中心基于“FTP+XML”接口模式開發了XMLEDI電子數據交換平臺。利用XMLEDI電子數據交換平臺,北京理工大學出版社可接收需求方的訂單信息,并根據約定的數據結構將信息轉換成出版企業應用系統所需的數據格式,生成采購單。在采購單生成后,系統會將批銷單直接送達庫房,使庫房能夠及時按照批銷單發貨,有效提升數據交換速率。利用XMLEDI電子數據交換平臺,北京理工大學出版社能夠高效完成出版社新書信息發送、庫存信息推送,采購單確認、發退貨確認、財務結算等業務。可見,XMLEDI電子數據交換平臺解決了大量業務首先通過電話、傳真、電子郵件等方式進行信息傳遞,再進行人工處理的問題,大量的手工錄入工作由計算機系統自動完成,業務員只需要核對數據的準確性。
但是,在開發XMLEDI電子數據交換平臺的過程中,北京理工大學出版社數字出版中心發現了其難以克服的弊端——這種數據交換模式若想大規模應用,就需要設計人員針對每個應用系統開發單獨的XMLEDI電子數據交換接口。目前,平臺只能與京東、當當、浙江省新華書店集團等十幾個業務平臺進行一對一的數據交換。在與不同業務平臺進行數據交換時,業務員需要在計算機上手工切換。在對接平臺數量較少時,這種模式尚能應付,但如果面對幾十個、幾百個甚至成千上萬個平臺,以此種模式進行數據交換,無論是對業務員還是對開發人員來說都是難以完成的。這還是單個平臺對多個平臺進行數據交換的情況,如果是多個平臺對多個平臺進行準確數據交換,設計人員需要開發的接口數以及業務員需要處理的業務會呈數量級增長。這一問題是由出版企業普遍采用的“FTP+XML”接口模式進行數據交換造成“軟件代碼與業務代碼交織在一起”所帶來的。
2.項目研發目標
為了解決以上問題,以北京理工大學出版社有限責任公司為主體承建的出版產業通用數據交換技術重點實驗室提出了“出版業通用數據交換平臺”的概念。出版業通用數據交換平臺定義了中間標準庫、端交換方案以及通用數據交換耦合器這“三源”。“三源”之間的有機結合,密切協作,能夠為不同系統間的數據交換搭建通道,支持不同廠家、不同版本的出版業應用系統接入,實現軟件代碼與業務代碼分離,達到建立一個獨立于應用系統之外且開放、通用的信息交換平臺,減少出版企業對特定系統開發廠商的依賴。運用出版業通用數據交換平臺,出版企業可自主拓展更多創新服務。
二、出版業通用數據交換平臺的“三源”結構
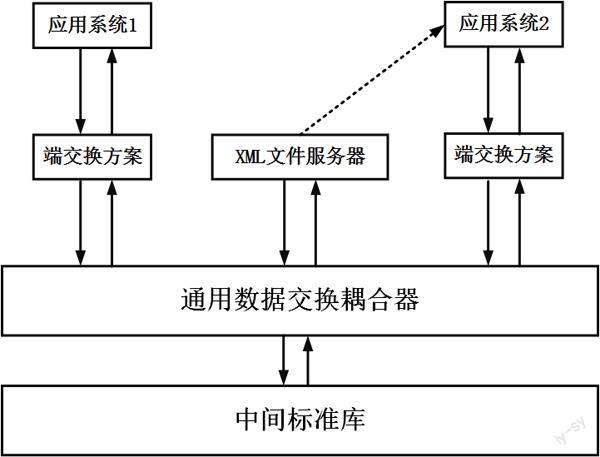
如圖1所示,在出版業通用數據交換平臺的數據交換過程中,業界分別將中間標準庫定義為標準源,將端交換方案定義為數據源,將通用數據交換耦合器定義為執行源。
中間標準庫之所以被定義為標準源,是因為其能夠整合與出版產業相關的60余種出版、發行、信息類標準,如2006年頒布的《圖書流通信息交換規則》、2013年頒布的《中國出版物在線信息交換(CNONIX)圖書產品信息格式》等標準。出版業通用數據交換生態依據標準中規定的信息交換的內容、類型、格式規范、技術規范等形成中間標準庫,所有的數據交換工作都以中間標準庫中的定義為藍本來完成,中間標準庫由出版業通用數據交換平臺管理者進行管理和更新。
端交換方案之所以被定義為數據源,是因為其是應用系統數據的提供者,能夠根據數據需求方應用系統的數據結構,將系統運作行為抽象為connect、select、insert等類型,然后抽取數據提供方的對應數據,并且標注這些數據,以適應需求方的數據結構。系統的開發廠商、系統用戶甚至是與應用系統無關的第三方,只要愿意,都可以根據自己對應用系統的理解和使用習慣開發端交換方案,并提交出版業通用數據交換平臺供用戶選用。
通用數據交換耦合器之所以被定義為執行源,是因為其是出版業通用數據交換平臺的數據交換單元及數據管理單元。一方面,通用數據交換耦合器能夠校驗端交換方案提交的數據結構與中間標準庫,以解決出版業“有標準不用、有標準難用”的問題。另一方面,通用數據交換耦合器能夠分析處理端交換方案提交的運行請求,將數據轉換為滿足對應系統數據格式的XML文件,并推送到相關的XML文件服務器,供需求方讀取。
三、出版業通用數據交換平臺“三源”之間的關系
出版業通用數據交換平臺雖然仍是通過“FTP+
XML”方式傳輸數據,但是由于出版業通用數據交換平臺獨立于各應用系統之外,因此其并不參與各應用系統的運轉,只能根據應用系統之間數據交換的需求處理及轉發相應數據。因此,任何應用系統之間運用出版業通過數據交換平臺進行的數據交換工作,都不需要對自己的應用系統進行二次開發及修改,也無須專門針對數據交換修改應用系統節點業務規則。由此,軟件代碼與業務代碼成功分離。
出版業通用數據交換平臺遵循通用性、標準化和開放性原則,不僅可以使出版業的應用系統之間進行數據交換,還可以使出版業與不同行業的應用系統進行數據交換,從而簡化開發環節,節省研發費用。而且平臺的所有標準、工具及應用方法都向全社會公開,無論是系統的開發廠商、系統用戶,還是與應用系統無關的第三方,都可以根據自己對應用系統的理解和使用習慣開發平臺并獲取收益。
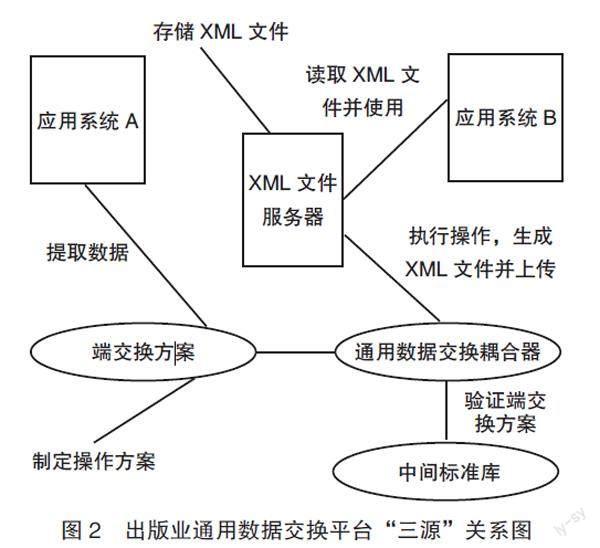
綜上,出版業通用數據交換平臺“三源”關系如圖2所示。
1.標準源
標準源——中間標準庫是出版業通用數據交換平臺的基準。平臺在運行初期,首先需要導入可供各應用平臺查詢并參照使用的60余種出版、發行、信息類標準。隨著平臺的日益成熟,平臺將不斷更新新出臺的國家標準,應用系統可以向平臺管理者提出一些尚未成熟的標準應用申請,并按照中間標準庫的設計規范,自行創作交換規范,形成“準中間標準”供各應用系統和開發者使用。
2.數據源
數據源——端交換方案是出版業通用數據交換平臺中數據交換的發起者和操作的制定者,由系統開發廠商、系統用戶等針對需要進行數據交換的應用平臺中間標準庫的定義開發而成。各應用系統由各自開發團隊開發,互不統屬,不可能有統一的數據格式,導致不同系統難以共享數據,形成“信息孤島”。端交換方案可以按照數據需求方的數據結構,從數據提供方獲取數據并提供轉換模式,根據通用數據交換耦合器的標準發出各項操作指令。端交換方案開發者必須充分了解應用系統的數據結構,將不同應用系統數據各字段的命名、數據類型、數據格式、排序規則等通過端交換方案進行統一。端交換方案還需要將數據傳輸過程中需要執行的操作,如接收、存儲、發送、加載、寫入、修改、刪除等寫入其中。但是,端交換方案并不能真正執行這些操作,相關操作由數據交換耦合器來完成。
3.執行源
執行源——通用數據交換耦合器起到承上啟下的作用,是真正體現出版業通用數據交換平臺價值的關鍵環節。它能夠協同標準源進行標準校驗、執行數據交換的各項指令、生成契合數據需求方格式的XML文件,并上傳到XML文件服務器,供需求方讀取。建立出版業通用數據交換平臺的核心目的是解決出版業普遍采用的“FTP+XML”接口模式在數據交換過程中“軟件代碼與業務代碼交織在一起”的弊端。
一方面,端交換方案按照數據需求方的數據結構,從數據提供方獲取數據并提供轉換模式,根據通用數據交換耦合器的標準發出各項操作指令。但是,端交換方案自身不參與數據轉換和操作,相關操作由數據交換耦合器來完成,并生成適應數據需求方要求的XML文件,數據需求方只需要讀取使用。另一方面,通用數據交換耦合器完成端交換方案與中間標準的校驗。上述過程中,無論是數據需求方還是數據提供方的應用系統都不參與數據交換。數據通過端交換方案—通用數據交換耦合器—中間標準庫完成提取—驗證—轉換—傳輸的全過程,實現軟件代碼與業務代碼分離的目的。業務代碼只在業務系統中運行,而軟件代碼依賴中間標準庫、端交換方案以及數據交換耦合器的密切協同獨立運行于出版業通用數據交換平臺上。任何應用系統業務規則的改變,都無須設計人員開發專門的數據接口,設計人員只需要將對應的數據結構寫到端交換方案,這樣大大節省了開發成本。
四、出版業通用數據交換平臺的展望
在圖書銷售的實踐中,通用數據交換耦合器通過端交換方案關聯數據交換雙方的業務系統,通過調用中間標準庫中的CY/T 39-2006(圖書流通信息交換規則)標準進行校驗后,生成XML文件并通過FTP協議進行轉發。在這里,雙方進行的是圖書銷售信息相關數據的交換。例如,通過出版業通用數據交換平臺,浙江省新華書店集團浙江新華營銷平臺能夠獲取北京理工大學出版社ERP(云因)系統里的圖書銷售信息,并生成需求清單;北京理工大學出版社ERP(云因)系統根據需求清單生成批銷單,提交庫房發貨。雖然雙方應用系統定義的圖書銷售信息的各字段完全不同,但是通過端交換方案的提取和通用數據交換耦合器與中間標準庫的驗證及數據轉換,各項數據能夠無縫對接。
需要注意的是,在數據交換過程中,數據交換雙方應用系統的使用者并不需要在出版業通用數據交換平臺上進行過于復雜的操作。出版業通用數據交換平臺完全獨立于具體應用系統之外,只需要數據交換雙方的系統管理人員根據數據交換的實際需求,在進行第一次數據交換之前,在出版業通用數據交換平臺上設置通用數據交換耦合器,設置完成以后,所有的數據交換工作都是自動進行的,無須系統管理人員完成后續操作。這樣的數據交換模式對數據交換雙方應用系統的使用者來說是完全透明的,出版業通用數據交換平臺“軟件代碼和應用代碼分離”的優勢盡數體現。
出版產業通用數據交換技術重點實驗室是國家新聞出版署的研究性課題之一,實驗室自2021年成立以來已經完成了出版業通用數據交換平臺的實驗平臺建設,并且正在通過實驗平臺,與北京市百萬莊圖書大廈、浙江省新華書店集團等多家單位的多個應用系統進行數據交換。通用數據交換耦合器在北京理工大學出版社與合作伙伴進行出版發行數據交換過程中發揮了巨大作用,取得了良好的效果,大大降低了參試單位的工作強度和開發成本。雖然運行時間較短,平臺還存在許多需要改進的問題,但是隨著項目的不斷推進與完善,出版業通用數據交換平臺正式投入運營后,將會大幅降低產業鏈數據共享投入,解決產業鏈數據共享難題,推動標準的落地應用,為產業信息交換的規范性、科學性提供應用保障,實現企業對內、對外無差別的數據交換,并通過大數據技術推進行業智慧決策、智慧生產、智慧服務,助力出版業數字化、信息化的不斷進步與發展。
|參考文獻|
[1]葉枝平,李振坤,劉竹松,等. 基于XML的數據交換平臺的研究與設計[J]. 微計算機信息,2008(9):243-244+229.
[2]劉成勇. 樹立數據思維,建設新聞出版大數據體系[J]. 出版參考,2016(7):5-8.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
城市道橋與防洪(2022年4期)2022-07-01 06:04:12
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
當代陜西(2019年8期)2019-05-09 02:22:48
動漫星空(興趣百科)(2019年3期)2019-03-07 07:23:10
家庭影院技術(2018年4期)2018-05-09 07:07:52
家庭影院技術(2017年9期)2017-09-26 03:41:45
