基于LSTM和新聞情感的股票價格預測方法
2022-05-27 06:56:22李桂城肖一凡陳麗綿
智能計算機與應用 2022年5期
許 麗,張 利,李桂城,肖一凡,陳麗綿,唐 艷
(貴州大學 大數據與信息工程學院,貴陽 550025)
0 引 言
股票市場是國家經濟市場的重要組成之一。隨著中國經濟的騰飛和大數據的發展,一方面,關心股市問題的不再只有上市公司,越來越多的普通民眾將目光轉向股票投資;另一方面,影響股票價格的因素有經濟、政治和公司自身的管理等,均使得股票價格走勢變得難以預測。因此,眾多研究者開始深入研究影響股票價格的因素,并提出了許多經典模型。
文獻[1]提出了一種ARIMA和SVM的組合預測模型,首先使用ARIMA模型對華泰證券一年的股票價格進行線性預測,接著使用SVM模型對其進行非線性預測,實驗表明,組合預測模型得到的綜合結果精度高于單一模型。文獻[2]改進了XGBoost模型,使用網格搜索算法對模型進行參數優化,基于原XGBoost、GBDT、SVM以及改進的XGBoost模型對5個短期數據集,如中國平安、中國建筑等進行預測,實驗結果表明,XGBoost表現出了最優的評價指標和最好的擬合性能。文獻[3]提出了一種粒子群和支持向量機的組合模型,傳統的支持向量機在股票預測中取得了較好的效果,但是根據人為經驗選取支持向量機的參數和核函數存在很大的弊端,而該模型利用粒子群算法可以自動更新速度和位置且各粒子之間共享信息的特性,對SVM的參數進行優化,實驗結果顯示,該算法在很大程度上提高了預測結果,對比原始的SVM,準確率有所提高。文獻[4]提出了Bagging-SVM模型,算法的思想是利用bagging將數據集劃分為若干的子訓練集去訓練傳統的SVM,最后通過對每一個子SVM模型的預測結果進行投票,票數最多的項即為最終的預測結果。文獻[5]在對輸入數據進行預處理后,將其送入層數不同的LSTM和層數相同、但神經元不同的網絡結構中,通過評價指標來選擇合適的結果,并對蘋果公司的股價進行預測分析,驗證了其精度可提高30%,證明了該方法的可行性。文獻[6]將LSTM網絡用于股票價格預測,通過對模型進行不斷調優,獲得最優預測模型后將其預測結果與BP神經網絡、RNN、CNN,人工神經網絡的預測結果進行對比,結果表明,LSTM評價指標最優且預測值和真實值的曲線擬合得最好。文獻[7]提出了一種基于粒子群算法改進的LSTM模型,傳統LSTM網絡常常根據自身經驗確定其中的重要參數,由于主觀性極強無法確定最優值,粒子群算法的提出解決了這一問題,通過算法尋優構建了完善的預測模型,使得準確率大大提高且獲得了普遍的適用性。文獻[8]將不同的輸入特征送入LSTM模型來預測股票的收入,驗證了特征不同的輸入對股票價格的影響。文獻[9]提出了Adv-ALSTM模型,通過添加擾動來模擬價格的隨機性,以此來訓練模型在干擾數據下的泛化能力,實驗表明,在訓練模型階段,采取對抗性網絡的方式大大提高了網絡性能和擬合能力。為了同時滿足捕獲長時間依賴關系和選擇相關驅動進行預測的要求,文獻[10]提出了DA-RNN網絡,該網絡是一個2層LSTM結構,包含解碼和編碼環節,將該模型應用在SML2010數據上,結果表明該網絡不僅可以進行有效預測,而且具有很強的可解釋性。文獻[11]提出了基于TCN和文本情感分析方法的股票價格預測方法,通過爬蟲的方式獲取相關數據集,使用LSTM對新聞文本進行情感極性分析,并將其結果與股票數據一同輸入TCN網絡,改進后模型的評價指標表現良好,驗證了其可行性。
本文的結構大致如下:第一節綜述了股票價格預測的經典模型和算法;第二節介紹了本文使用的一些相關算法機理;第三節概述了本文算法的原理;第四節給出了本文網絡在相關數據集上的評價指標和擬合曲線的實驗結果;第五節總結概括了該文章,并提出該領域未來可能的發展方向。
1 相關算法
1.1 交叉驗證
泛化能力是評價一個模型好壞的指標之一。因此,常常使用交叉驗證來提高模型的泛化能力。常見的交叉驗證有簡單交叉驗證、留一交叉驗證以及k折交叉驗證。其中,簡單交叉驗證僅僅需要將數據集劃分為2份,選取數據量小的一份作為驗證集來評價模型的好壞,該算法雖然可以用來評價模型,但是劃分的比率不同會產生較大的差異。留一法,顧名思義,將個樣本劃分為份,進行次訓練,每次只留一份為驗證集,該方法在數據量小的時候可以最大限度地利用每一個樣本,其弊端在于如果數據量很大時會造成欠擬合。k折交叉驗證把數據集劃分為份,每一份逐一作為驗證集去評價模型,基于此再取平均值作為最后的評價指標。一般情況下,值越大則模型性能越好,但是有研究表明,其范圍在5~10之間或能取得最佳效能,本文使用10折交叉驗證對LSTM模型進行訓練。
1.2 XGBoost
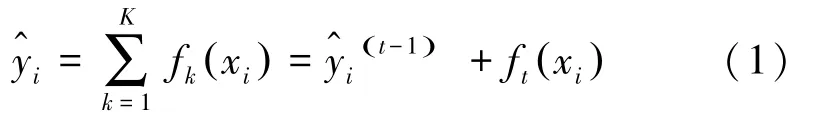
XGBoost是梯度提升決策樹算法(DBDT)的改進版本。由葉節點為分類變量的決策樹和葉節點為連續變量的回歸樹兩種增強樹組成。DBDT梯度提升樹的表達式如(1)所示: 為了避免正則化,通過在原網絡的基礎上增加正則項來簡化模型,XGBoost包括回歸樹和決策樹,并且采用了blocks的存儲結構,使得算法可并行,提高了運算速度。該算法的最終目標是優化函數Obj ,其中包含損失函數和表示復雜度的正則項。 網絡在每一次迭代之后增加一棵樹,來優化Obj 。 函數的數學定義可寫為如下形式:
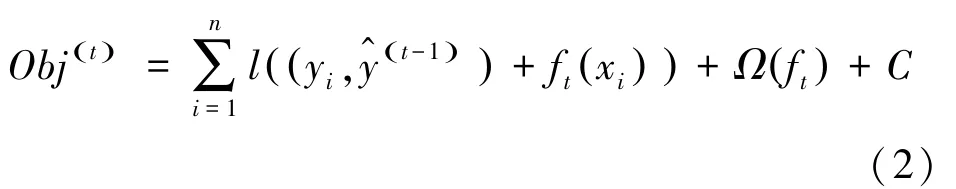
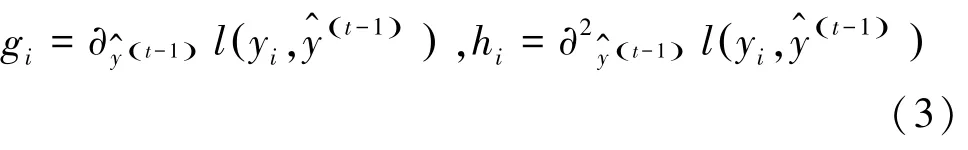
損失函數在第1次迭代時獲得的預測值的一次偏導g和二次偏導h,如式(3)所示:將目標函數按泰勒二階公式展開,消除常數項帶來的影響。二階導數使得損失函數更加精確,并將式(3)帶入,得到新的目標函數如式(4)所示:
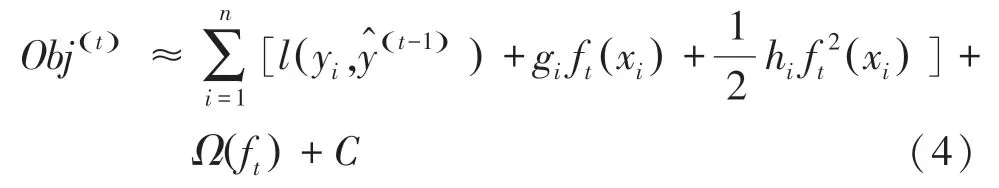
進一步地,研究中可推得:
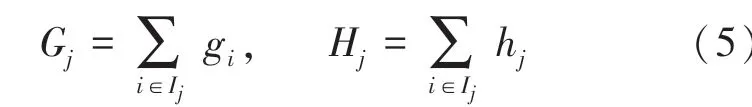
在訓練目標函數時,f()=w,即把函數(樹)拆分為葉子的權重向量部分和樹的結構部分,目標函數可以表示為:
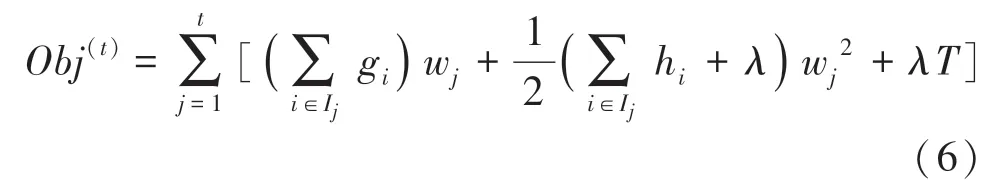
將式(5)帶入式(6)合并一次項系數和二次項系數,得到最終的目標函數如式(7)所示:
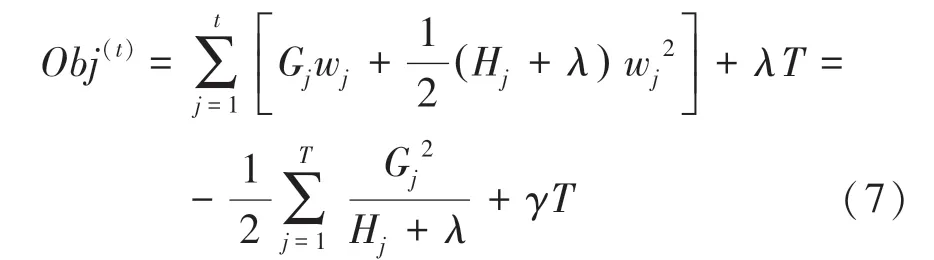
目標函數又可稱作打分函數,在一定范圍和條件下,目標函數的值最小,表明此時得到了最優解。總而言之,XGBoost具有很多優點。不僅可以減少過擬合并且處理正則項,也可提升運算速度、可自定義目標函數以及模型評價指標,具有高度靈敏性。除此之外,XGBoost具有自動處理數據集缺失值的功能,允許在boosting迭代中使用交叉驗證。
2 算法機理及流程
2.1 SVM_LSTM模型的搭建
隨著人們生活水平的提高,在滿足日常衣食住行之余,已有很多人開始利用手中的閑錢來做投資,由于股票的低投資以及高回報性,使其成為大眾的重要選擇,基于此,如何選擇最優股即已成為備受關注的熱點話題。以往的研究者要么針對股票歷史數據進行時序預測,要么采取分類網絡進行文本情感分析,忽略了二者直接的內在聯系。在此背景下,本文提出了SVM_LSTM網絡。
在時序預測通道上,本文首先采用歸一化的手段處理股票數據,對股票數據進行歸一化處理可以削弱量綱帶來的影響,將數據統一到一個相差不大的范圍,以此來減少較大數據和較小數據的影響,本文采取的歸一化公式具體如下:

其中,x表示第個變量,x表示均值。
其次,本文使用10折交叉驗證劃分經過預處理的股票數據,來訓練LSTM模型;最后,調用訓練良好的模型預測中國銀行、中國聯通、浦發銀行的股票數據。LSTM機理詳見2.2節。
在文本預測通道上,對于中國銀行股票新聞的文本數據集,本文首先在百度智能云網站注冊一個AipNlp賬號,這是自然語言處理的Python SDK客戶端,通過調用該網站可以對本文爬取的文本數據集做一個初步的處理,由于使用該接口對新聞文本標題預測得到的結果為每一條新聞詞條對應的積極的可能性和消極的可能性,本文在Python中指定當積極的可能性大于消極的可能性時,就將該新聞文本標注為1,代表利好,反之,將文本標注為0,表示利空;隨后采用處理好的文本數據集訓練SVM模型;最后,調用SVM預測文本新聞情感極性。SVM原理詳見2.3節。
至此,研究中采用了加權的方式將SVM的預測結果與LSTM的預測結果進行融合。其算法流程如圖1所示。圖1中,第天的股票最終預測價格_pred的計算方法如式(9)所示:
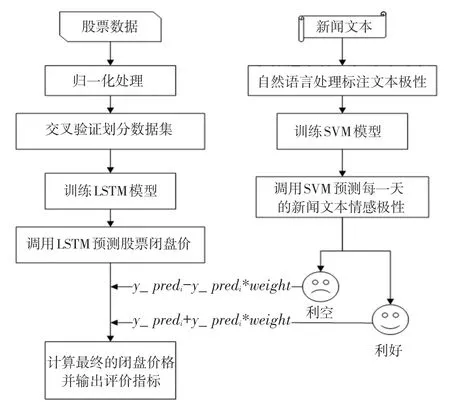
圖1 算法流程圖Fig.1 Algorithm flow chart
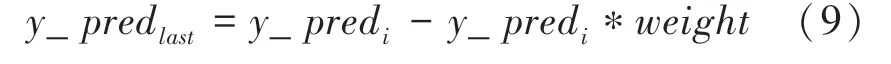
其中,_pred 表示時序預測第天的結果。在本文中,由于在時序預測階段,真實值與預測值在整體走勢上擬合得很好,只需要微小的調整就可以使得預測值更接近于真實值,故而本文將設置為001。
2.2 LSTM
循環神經網絡RNN能夠處理時序數據,時序數據、即數據之間具有時間先后性,數據整體呈現某種趨勢。循環神經網絡具有跨越時間節點的自連接層,能夠建立當前時刻與序列上一時刻的關系。但是隨著網絡層的加深,由于循環神經網絡只會獲取上一節點的信息,無法儲存距離當前時刻較遠的網絡的輸出,會造成梯度消失。為了解決梯度消失和梯度爆炸,最早由Zhao等人提出了LSTM網絡,在此后的一段時間里,該網絡被廣泛地應用在時序預測鄰域中。
LSTM是對RNN模型的改進,以達到解決梯度消失的效果。這一改進主要表現為:在RNN隱藏層中添加了長短期記憶單元;通過添加門控結構、引入激活函數結合RNN原有的tanh激活函數,來控制網絡對歷史信息的輸入保存和輸出;輸入信息由添加的細胞狀態記憶。綜上所述可知,LSTM解決了短期依賴和長距離依賴問題。
LSTM的3個門控單元分別為輸入層、隱藏層、輸出層,共同構成了模型的輸入部分。LSTM網絡結構如圖2所示。由圖2可知,該結構中各主體組成部分的設計原理及數學表述詳見如下。
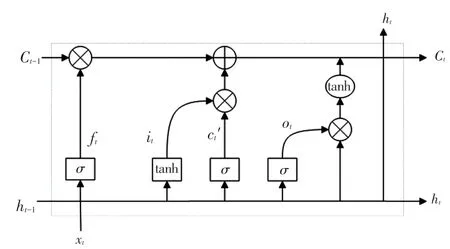
圖2 LSTM網絡結構Fig.2 LSTM network structure
(1)輸入層。為全連接層,該網絡首先對數據進行預處理,以達到輸入數據格式要求。輸入門的值i和輸入細胞的候選狀態值Ct可由如下方式計算得到:
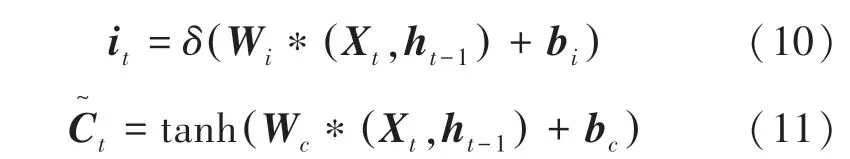
其中,和表示計算時的權重矩陣;表示偏置向量;表示激活函數。
(2)隱藏層。是包含多個LSTM神經元的循環神經網絡。在該網絡結構中,激活函數選取和tanh,時刻遺忘門的和當前時刻細胞的狀態的更新值的數學表達式可寫為:
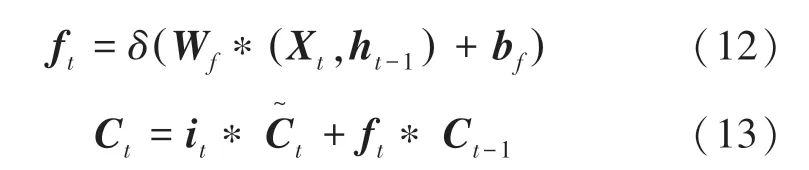
(3)輸出層。將隱含層的多個輸出結果映射到全連接層來獲得模型的最終輸出。在該層網絡結構中,計算得到的最終輸出結果如下:
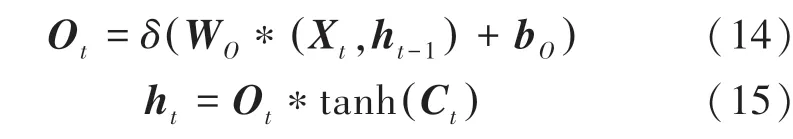
2.3 SVM
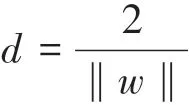
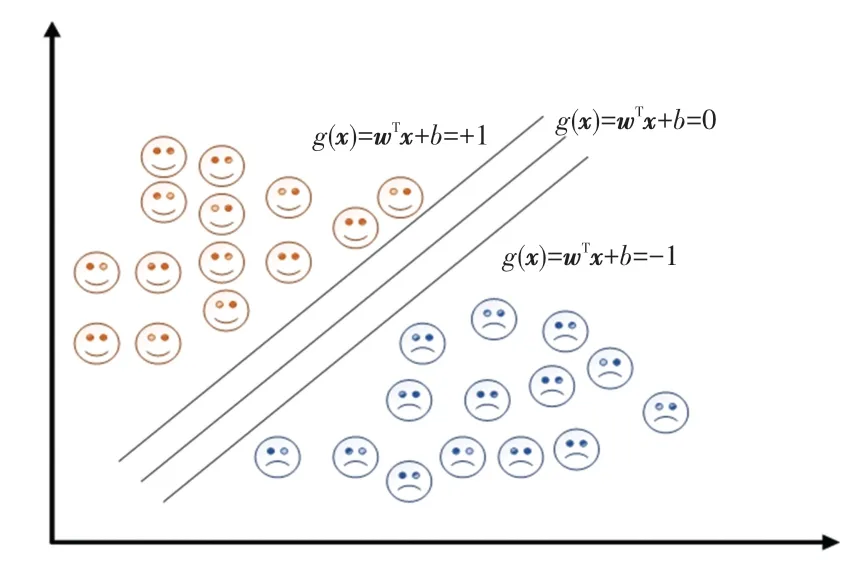
圖3 SVM分類示意圖Fig.3 SVM classification diagram
利用拉格朗日優化最大間隔,最終得到決策函數具體如下:
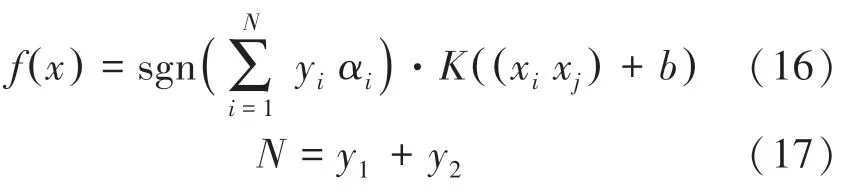
其中,表示分類總數。
二次規劃問題,求解約束最優化的問題變成公式(18):
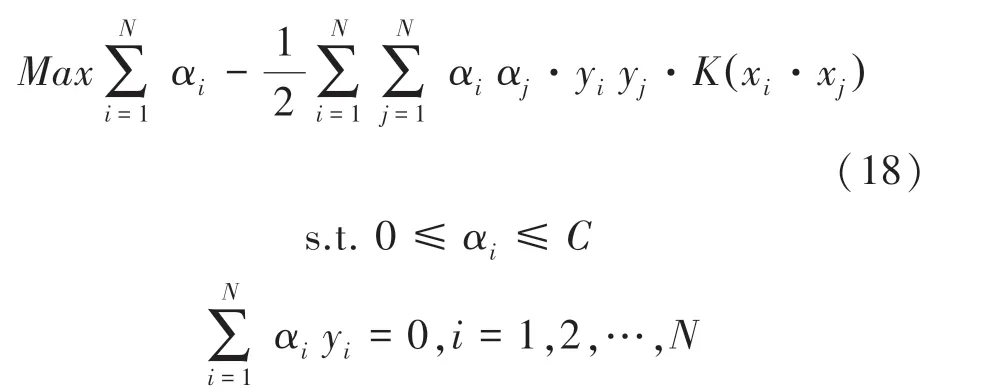
其中,為懲罰函數,該值與模型對噪聲的容忍度成正比,與模型的泛化能力成反比。
常見的SVM核函數有線性核函數、多項式核函數、徑向基核函數,對應的數學公式可順次表示為:
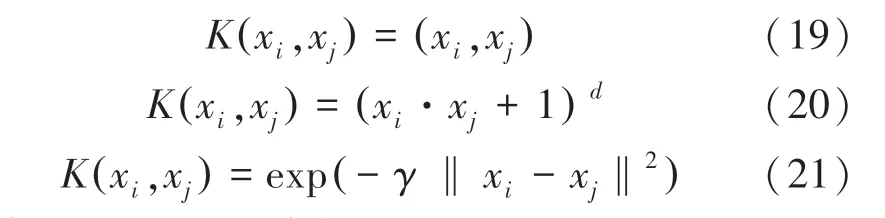
其中,和是常數項。
核函數的選擇決定了模型的預測效果,通過核函數網絡,SVM將輸入的向量映射到高維特征的空間,將原本的非線性問題變換為高維度特征空間的線性可分問題。
3 實驗
3.1 數據集介紹
本文通過baostock庫爬取了中國銀行、中國聯通、浦發銀行三只股票從2020年8月30號到2021年10月27號的相關數據,包括開盤價,收盤價,最高價以及最低價。 收盤價表示股票當天的最后成交價,一般將其作為股票價格預測中唯一的因變量。圖4是中國銀行的收盤價隨時間的變化曲線,橫坐標表示不同的日期,縱坐標表示相應日期對應的股票價格。從圖4中可以看到該時序數據整體價格分布在2~4之間,某一天的閉盤價周圍一段時間內不會發生太大的突變;但是,圖4中黃色方框處股票急劇上升,在綠色方框處股票又突然下降。
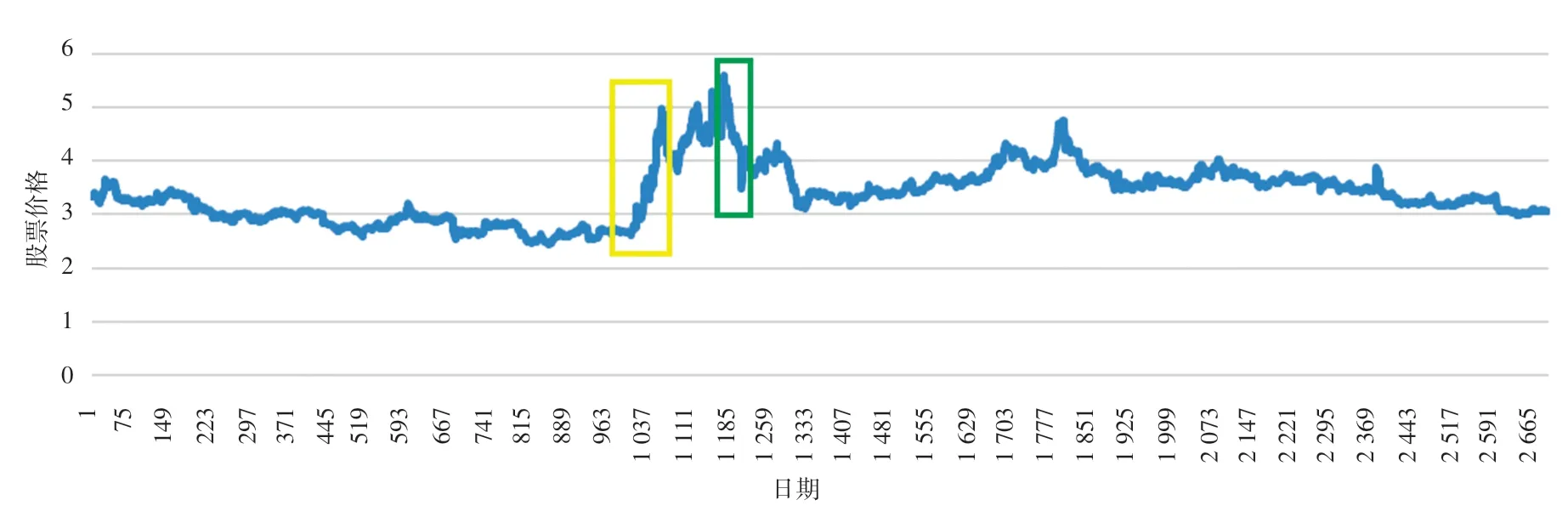
圖4 中國銀行股票跌漲曲線Fig.4 Stock decline and rise curve of Bank of China
對于新聞文本數據集,本文利用lxml庫爬取了“新浪財經網”和“金融界”網站中有關中國銀行的新聞文本。lxml是XML和HTML文件的解析器,還可以用于Web爬取。
3.2 評價指標
本文采取均方根誤差()、平均絕對誤差()以及均方誤差()來衡量模型的性能。各指標值的數學公式可表示如下:
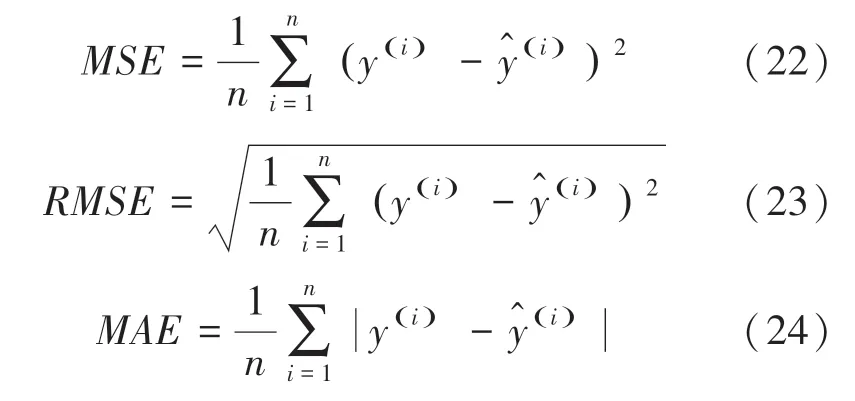
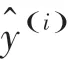
對于分類模型SVM,本文采取預測準確率()來衡量效果的好壞,研究后可推得的數學公式如下:
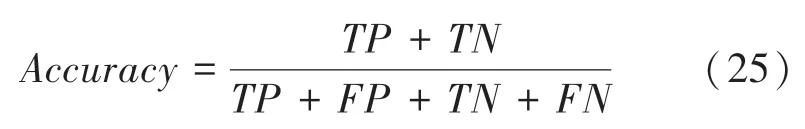
其中,具體參數含義見表1。

表1 預測與實際情況類型表Tab.1 Forecast vs.actual type table
3.3 XGBoost和LSTM模型的預測結果
圖5(a)~圖5(c)中,左側為XGBoost模型的預測值與真實值的擬合曲線,右側為LSTM網絡的預測值與真實值擬合曲線。本文中,如果不做特殊說明,統一使用紅色曲線表示預測曲線,藍色曲線表示真實值曲線。可以看到:
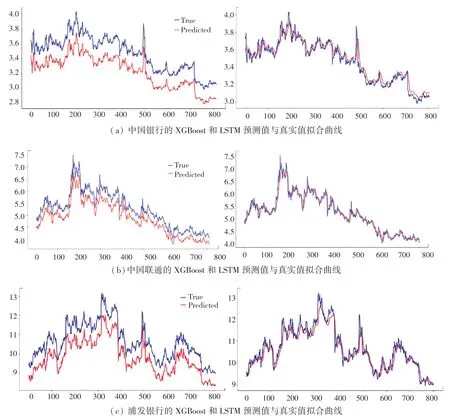
圖5 XGBoost和LSTM模型的預測結果Fig.5 Prediction results of XGBoost and LSTM models
(1)XGBoost模型擬合得到的預測值與真實值相比,其漲幅趨勢大致相同,并且在第天出現峰值時也能夠進行較好的預測,然而預測值曲線整體處于真實值下方,說明對于數值的預測存在偏差,因此該模型性能仍存有提升空間。
(2)LSTM在保留了XGBoost優點的同時,預測值無限逼近真實值,并且與絕大部分的低谷值和峰值完全吻合,針對中國銀行數據集,表2顯示了LSTM的評價指標、和較XGBoost分別減少了0.234、0.173和0.011,說明了本文搭建的模型預測精度更高。
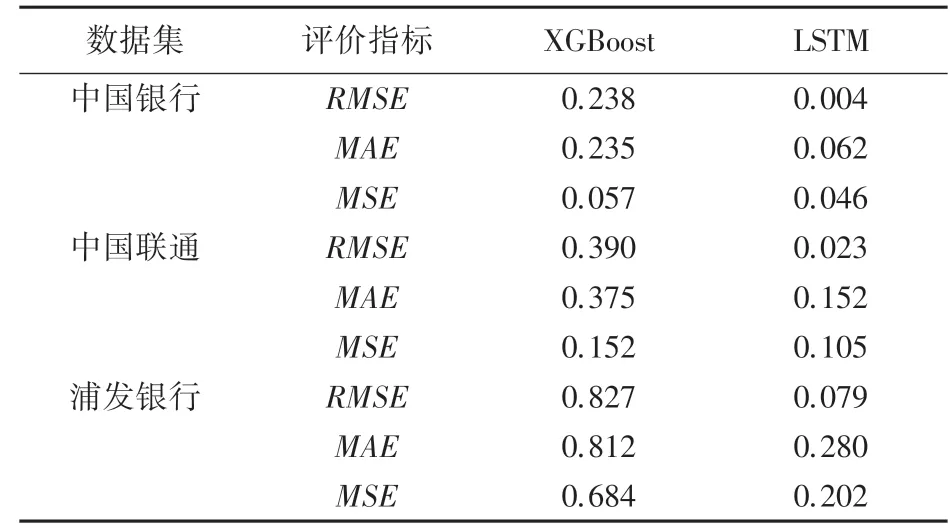
表2 XGBoost和LSTM在各數據集上的評價指標Tab.2 Evaluation indicators of XGBoost and LSTM in each dataset
(3)中國銀行無論在曲線擬合程度、還是在評價指標上,均優于中國聯通和浦發銀行,對于LSTM網絡,各評價指標之間整體沒有大致的差別,表明了本文模型具有較好的泛化能力。
3.4 SVM實驗結果
使用中國銀行股票新聞數據集對SVM模型進行訓練,該模型的準確率()達到了81%,高于文獻[3]中SVM模型所達到的79.11%,說明本文模型的可行性。表3展示了自2021年9月1號到2021年10月25號的預測結果,其中1代表利好,0代表利空,分別對應了股票的上漲和下跌。表3中的新聞文本標題均為中國銀行的個股資訊,由于不是每天都有相關新聞消息,表中的日期并不連續。沒有日期則對應的時序預測股票價格保持不變。
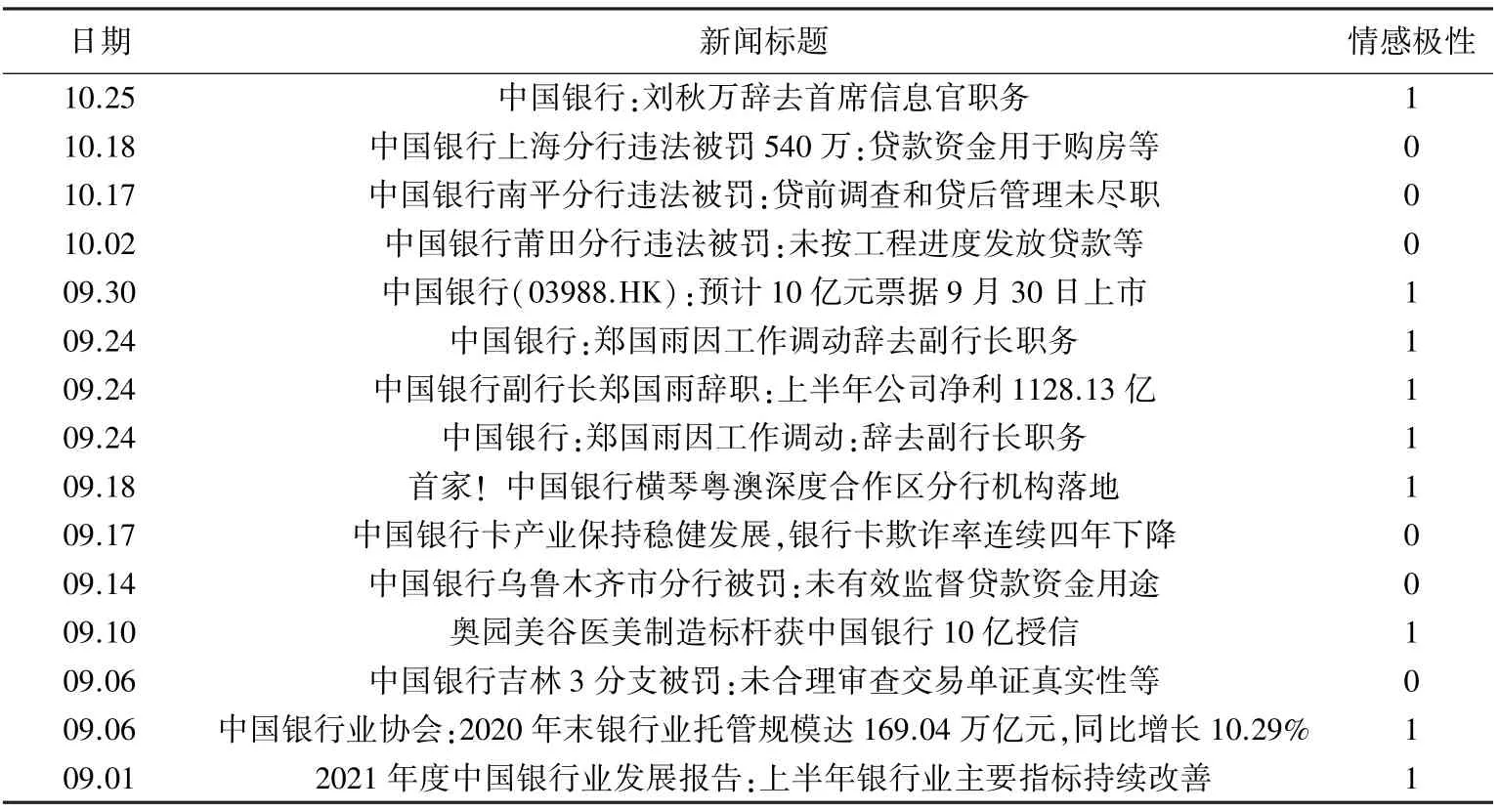
表3 SVM預測結果Tab.3 SVM prediction results
3.5 SVM_LSTM模型實驗結果
本文將中國銀行的預測結果按照對應日期加權(2.1節附有詳細說明)到LSTM的預測結果上。經過計算,本文網絡SVM_LSTM的最終結果見表4,顯然,各評價指標較原LSTM均明顯減少,、、分別減少了7.5%、6.4%、10.8%。

表4 SVM_LSTM評價指標Tab.4 SVM_LSTM evaluation index
4 結束語
本文綜合考慮了影響股票價格的雙重因素,分別是新聞文本和股票歷史數據,通過SVM和LSTM對2個通道的數據進行預測,再對其預測結果進行加權融合,使得2種不同的數據類型相互補充,讓最終預測股價更接近于真實價格。將本文模型應用于中國移動股票的預測上,結果表明:
(1)利用交叉驗證優化的LSTM雖然比XGBoost模型具有更高的預測精度,曲線擬合程度也更優,但是模型預測值和真實值之間仍然存在一定的差距。
(2)SVM模型預測準確率雖然達到了81%,能夠給投資者提供大致的股票跌漲訊息,可是卻不能夠獲取實際閉盤價格。
(3)本文采取加權融合的方式將SVM以及LSTM的預測結果融合,使得評價指標、、在原LSTM的基礎上分別減少了7.5%、6.4%、10.8%,證明了SVM_LSTM網絡的實用性,能夠給投資者帶來一定的參考價值。
下一步工作將考慮使用爬蟲獲取更多與股票相關的數據和文本訊息,進行多維度、深層次的分析,同時考慮分別優化時序和文本預測網絡,采取更科學的舉措歸并兩者的預測結果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
石油瀝青(2021年4期)2021-10-14 08:50:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
語文知識(2014年1期)2014-02-28 21:59:13
