基于并行混合網絡的生鮮水果短文本情感分類
2022-04-25 05:35:50潘夢強董微張青川
科學技術與工程 2022年10期
潘夢強,董微,張青川
(北京工商大學電商與物流學院,北京 100048)
民以食為天,食品安全一直是人們關注的焦點,同時它也是全面建成小康社會的重要標志。隨著互聯網的迅猛發展,直播帶貨等線上銷售手段如雨后春筍般涌現,由于其門檻低、數量多、質量雜等特點,難以通過常規抽查的方式來對其進行有效的質量監控。廣大消費者在購買產品之后,也傾向于在平臺發表一些自己對于購物的觀點,這些評論觀點飽含情感特征,通過對評論文本進行情感分析,于消費者而言可以緩解信息不對稱,了解商品的真實情況,減少決策成本;于商家而言,可以根據評論情感來改進自己的產品,提升銷量;于平臺而言,可以根據短文本的情感分析來掌握直播帶貨等銷售手段所售商品的質量,及時對不合格商品進行監管,尤其是保質期較短的生鮮水果;于國家而言,可以根據評論有的放矢,選取重點性的食品安全抽查對象進行重點抽查,這樣可以以較少的成本達到一個較好的效果,在一些較大的食品安全事故中甚至可以進行輿情的監測。
在線評論的情感分析是一項應用廣泛的技術,在商品推薦領域[1-2],銷售量的預測領域[3],消費者滿意度測算[4]等領域均有廣泛的應用。為了實現海量文本的情感分析,學者們通過情感詞典、機器學習和深度學習等方法分析文本情感傾向。
情感詞典方面,Taboada等[5]提出一種通過構建情感詞典來計算文本情感傾向的方法;Rao等[6]提出了一種改進的算法以及通過3種刪減的策略來自動的構建情感詞典。情感詞典的建立完全依賴于人工,對于日新月異的消費者表達方式,很難與時俱進。雖然情感詞典的方法也在不斷地改進,但是單純使用情感詞典無法突破‘詞典’的桎梏。
在傳統機器學習方法方面,Pang等[7]首次將機器學習用于情感分類,并且嘗試不同的機器學習方法,并且最終發現支持向量機(support vector machines,SVM)、樸素貝葉斯(naive Bayes,NB)等方法應用在文本情感分析上能取得較好的效果。然而,基于傳統的機器學習方法無法適用于當今時代,海量數據的存儲,新鮮詞匯的涌現,傳統的機器學習要隨時保持訓練,往往不能在第一時間發現新聞焦點。
在深度學習方面,首先要解決的是詞的表征問題,即將字或詞轉換為計算機能夠識別的數值向量形式。Mikolov等[8]提出了Word2Vec模型來對文本中的單詞進行向量化表示,解決了傳統的獨熱編碼所帶來的維度災難問題。Pennington等[9]提出了Glove模型來對文本序列進行特征表示。但是以上方法都是對于文本序列特征的靜態表示,忽略了序列的位置信息,特別對于中文文本序列而言,一個詞只用一個固定的向量表示,無法解決廣泛存在的一詞多義現象。針對這一問題,GPT模型與ELMO模型[10]被提出,不同于之前模型,它們可以對同一個詞訓練出不同的詞向量,以應對同一個詞在不同語境下可以有不同的含義的情況。在此基礎上,Devlin等[11]提出了基于Transformer的BERT模型,進一步提升了對于文本序列的表征能力。張騰等[12]利用Glove模型進行詞嵌入,BiGRU模型克服雙向長短期記憶網絡(BiLSTM)計算量大的問題,并通過卷積神經網絡(CNN)與BiGRU模型分別對文本序列進行特征提取,然后融合特征進行情感分類。Du等[13]針對傳統CNN忽略文本語法結構而單獨對句子結構進行建模會帶來大量的計算負擔的缺點,改變了CNN的池化策略,用PCNN對句子中的語法結構進行分割,并提與相應文本序列中相應成分的特征,取得了較好的結果。Bahdanau等[14]將注意力機制引入自然語言處理中,其優點是可以動態的調整文本序列的權重分配,使得分類器可以有的放矢,專注于重點的特征信息,進而提升分類的準確率。楊長利等[15]在雙通道混合模型中加以注意力機制,提升了情感分類的準確率。已有較多的學者將BERT模型與Word2vec、Glove、ELMO等模型進行對比,最終發現使用BERT的模型在進行情感分類任務中得到最高的準確率[16-18]。然而以上研究都只是針對電商平臺的普通產品,沒有對產品進行詳細劃分,但是水果產品有著其特有的屬性,水果產品屬于生鮮產品,然而用戶針對其在形、味、包裝、運速等方面有著特別的關注。針對此類現象,現提出一種融合BERT和并行混合網絡的生鮮水果短文本情感分析算法,就電商平臺的生鮮水果產品的評論進行短文本情感分析。
1 相關理論
1.1 BERT模型
如圖1所示,BERT由若干個Transformer層[24]組成,得益于Transformer中的自注意力機制層模塊以及前向傳播神經網絡層模塊結構,使得BERT具有很強的詞向量表征能力。BERT通過“Masked Language Model”以及“Next Sentence Prediction”這兩個無監督的子任務進行訓練。使得輸出的詞的向量化表能夠詳盡地展現文本序列所包含的信息。BERT模型本質上也是作為詞向量的提供工具,相比于靜態的特征提取,BERT可以根據下游任務來動態的調整,對于一詞多義現象友好。
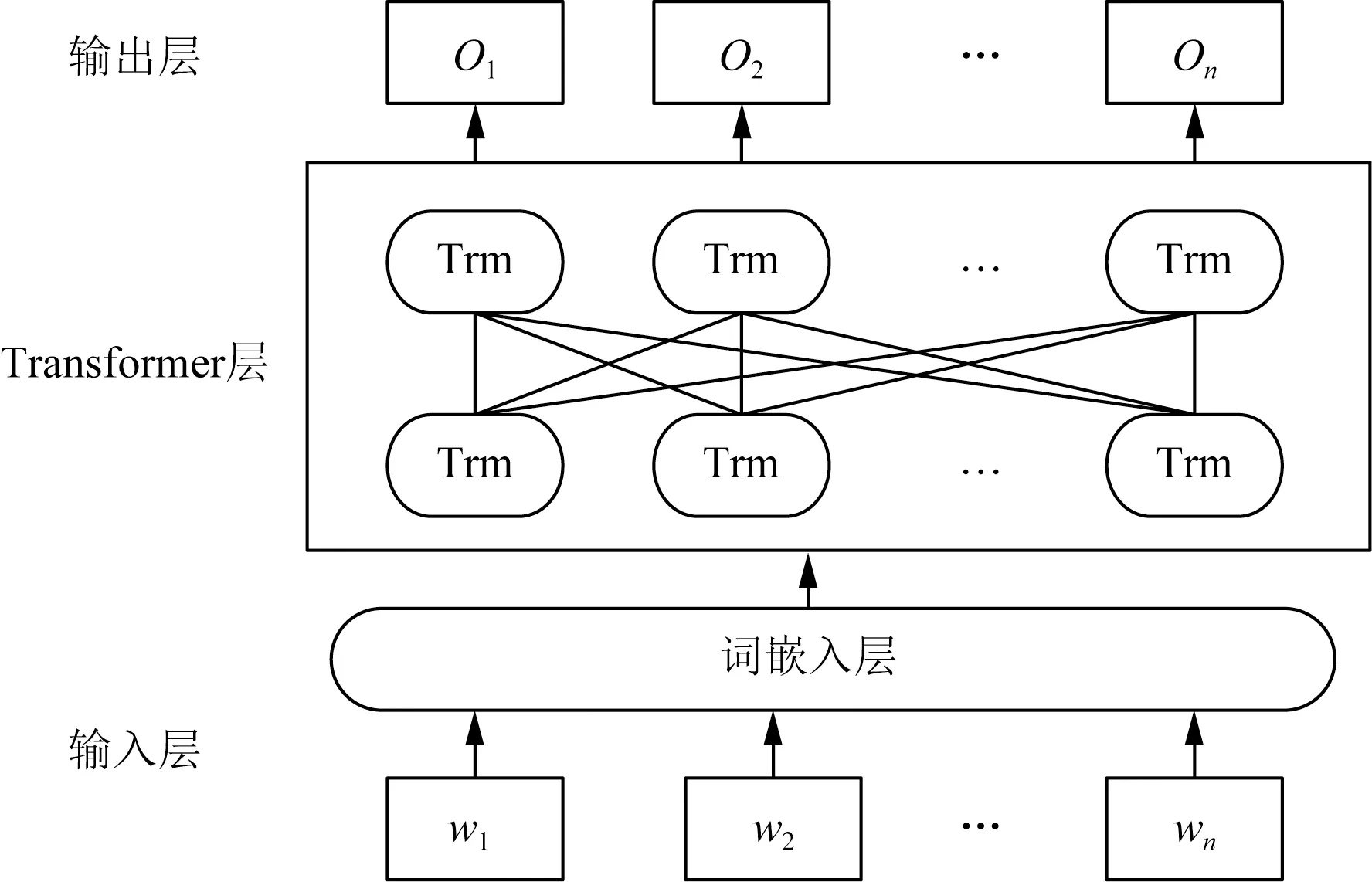
wn為輸入的單詞;Trm為Transformer結構;On為輸出的結果
1.2 CNN與PCNN模型
CNN模型與PCNN模型主要由卷積層和池化層組成。
1.2.1 卷積層
卷積層是在得到詞的向量化表示之后,使用若干的卷積核對所得向量進行卷積操作,得到特征的初步提取。由此可得新的特征矩陣。對于一次卷積操作而言,在第i個卷積核進行卷積操作之后,可以得到特征值ci,j:
ci,j=f(ωixj:j+h-1+b)
(1)
式(1)中:h為卷積核的窗口大小;f為非線性函數;b為偏置項。對于一條文本序列,卷積核i在沿著序列的方向滑動,最終可以得到特征序列ci:
ci={ci,1,ci,2,…,ci,n-h+1}
(2)
1.2.2 池化層
卷積操作可以得到文本序列特征,由于得到的特征向量較大,如果直接傳分類器會導致模型參數增加,訓練難度增大,且容易出現模型過擬合的情況。為了解決模型復雜度較大的問題,往往會在卷積操作之后加入全局最大池化層,這樣可以減少參數并且進一步的提取主要特征,圖2為全局最大池化的卷積神經網絡的結構圖。

圖2 CNN模型結構
在得到一個卷積核提取的特征序列ci之后,選取其中最大的值,全局最大池化的操作如式(3)所示,di為最大池化操作提取的特征。
di=max({ci,1,ci,2,…,ci,n-h+1})
(3)
全局最大池化是將卷積操作所得的特征進行一個篩選,得出與任務最相關的特征,達到一個‘降維’的目的。但是在應用于文本語言中,最大池化的操作難以捕捉句子的語法結構。分段池化不僅僅是在卷積核ci中提取最大的數,而是先將ci分成若干段,再對分成的各段進行一個最大池化操,然后將所得的特征進行一個拼接,在一定程度上彌補單一的最大池化操作忽略語法結構的缺點。圖3為分段池化卷積神經網絡的結構圖。
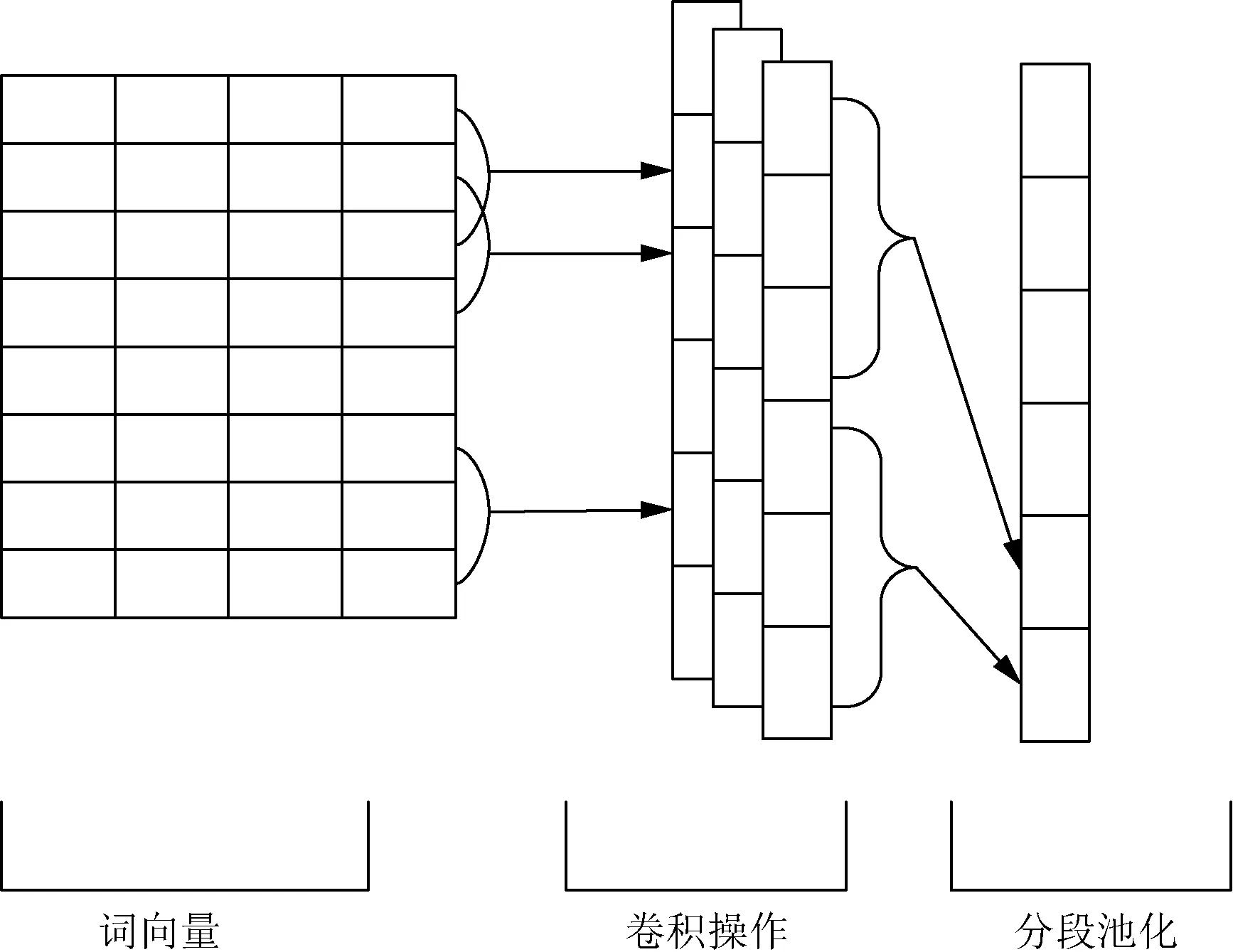
圖3 PCNN模型結構
在得到一個卷積核提取的特征序列ci之后,將特征序列分為k段,即
ci={ci,1,ci,2,…,ci,k}
(4)
式(4)中:1≤k≤n-h+1。在分為k段之后,分段池化是對于其中的每一段進行一個最大池化的操作,如式(5)所示,對第i個卷積核所得的特征ci進行分段池化可得di,即
di={max(ci,1),max(ci,2),…,max(ci,k)}
(5)
1.3 BiGRU模型
門控循環單元(gate recurrent unit, GRU)模型本質上與長短期記憶網絡(long short term memory, LSTM)一脈相承,都是對循環神經網絡(recurrent neural network, RNN)的改進,都能在一定程度上克服長期依賴問題以及梯度彌散的問題。GRU與LSTM的區別在于GRU的內部結構相較于LSTM來說要簡單,主要由更新門(zt)和重置門(rt)組成,參數較少,易于訓練。GRU的信息傳播方式為
rt=σ(Wr[ht-1,xt])
(6)
zt=σ(Wz[ht-1,xt])
(7)
(8)
(9)

雖然GRU相較于傳統的循環神經網絡,已經有了較大的進步,但是單向的GRU模型應用于文本情感分析時會出現文本后面出現的字詞要比前面的重要的情況,這一問題在長文本時尤為突出。所以本文利用雙向的GRU模型來緩解這一情況,同時得益于GRU參數較LSTM少的特點,使用雙向GRU模型不會對模型訓練產生太大的壓力。圖4為雙向GRU(BiGRU)模型的結構圖。

圖4 BiGRU模型結構
2 模型設計
提出一種融合BERT的并行混合網絡模型來進行水果方面的短文本情感分析。如圖5所示,該模型由4個信息處理層組成:輸入、特征提取、特征融合和輸出。由于單一的卷積層無法提取文本的上下文信息特征,所以在卷積神經網絡的基礎的并聯一個雙向門控循環單元來提取文本的上下文信息特征,二者優勢互補,這樣可以提取到較多的特征以提升最終模型的準確率。雖然BERT模型可以很好地進行文本序列的特征表示,但是由于其缺乏領域知識,所以在后面使用PCNN來提取靜態特征以及結構特征,使用BiGRU提取上下文信息,再將二者組成雙通道之后進行特征融合,進而彌補BERT所缺乏的領域知識。采用并行連接的方式,使得PCNN提取到的結構特征得以完整保留,并且相比于CNN與RNN堆疊的方式,可以避免模型過深帶來的問題。

Wn為輸入的字;BiGRU和PCNN分別為BiGRU模塊和PCNN模塊
2.1 輸入層
對于一條文本句子序列,經預處理后的詞語序列{W1,W2,…,Wn}作為模型的輸入,然后由預訓練模型BERT來提供詞的向量化表示,并依據上下文語境來對詞向量進行一個動態的調整,以便讓模型得到真實的文本語義。
2.2 特征提取層
在經由BERT預訓練模型處理之后,便得到了文本的向量化表示。一方面利用BiGRU來提取上下文信息,得到文本的深層次特征信息。另一方面利用分段池化卷積神經網絡來提取局部語義特征信息以及結構特征。
2.3 特征融合層
在特征融合層中,將BiGRU與PCNN得到的特征信息進行融入拼接,進而組成整段的情感特征向量,以便在輸出層使用。
2.4 輸出層
將特征融合層的輸出(即得到的情感特征向量)輸入到Sigmoid分類器中,從而得出最終的情感分類結果。
3 結果分析
3.1 實驗數據
實驗數據為開源數據集online_shopping_10_cats和waimai_10k。online_shopping_10_cats是一個包含多類商品的電商評論情感分析數據集。本文主要選取其中的水果類進行情感極性預測。其情感標簽分為兩類,即積極與消極分別用1和0表示,標簽列表為[0,1]。隨機抽取7 000條水果類的數據作為訓練集,1 000為測試集組成數據集一。waimai_10k包含大量外賣訂單評論數據,分別取出2 000條正向情感與2 000條負向情感評論數據組成數據集二,在實驗中隨機抽取3 200條數據為訓練集,其余為測試集。
3.2 評價指標
采用準確率(Accuracy)、F1、召回率(Recall)作為模型的評價指標,具體公式為
(10)
(11)
(12)
(13)
式中:TP為標簽為1且預測為1的樣本數;FP為標簽為0且預測為1的樣本數;TN為標簽為0且預測為0的樣本數;FN為標簽為1且預測為0的樣本數。
3.3 數據預處理
在實驗進行前,首先要對實驗數據進行預處理,大量的評論文本由不同的用戶書寫而來,形式自由,口語化嚴重,還存在大量的噪聲數據。此外,由于水果類的特殊性,同一種水果在不同的地方可能有不同的叫法,存在的一義多詞的現象,所以需要對評論文本進行預處理,預處理過程如圖6所示,具體操作如下。

圖6 數據預處理
(1)過濾掉所有的標點符號和特殊字符,只保留具有語義價值信息的中文文本。
(2)使用jieba分詞工具進行詞語分割。
(3)使用哈工大停用詞表、百度停用詞表和四川大學機器智能實驗室停用詞表去除噪聲數據。
(4)針對同一類水果可能擁有不同的叫法,選取一些常見的水果別名,以及水果品種名,將水果名統一化。
表1為部分名稱統一化的樣例;表2為部分文本預處理的樣例。

表1 名稱統一化樣例

表2 文本預處理樣例
3.3.1 實驗一
Du等[13]的研究發現句子有一般都包含主謂賓等語法結構,而分段是對語法結構的模擬,所以分段數是一個重要的參數,它決定了信息提取的有效性,在酒店數據集中,分段數在2~5時能取得較好的效果[13]。然而電商平臺水果評論有著不同的表達方式,需要對合理的分段數進行探究。為了探究采用分段池化的卷積神經網絡在生鮮食品領域的短文本情感分類中的合適的分段數,先設計不同分段數的卷積神經網絡來進行對比,參考Du等[13]在酒店數據集的分段數,在本研究中分段數分別為1、2、3、4。
實驗一僅對數據集一進行了實驗,對比實驗設置如下:①PCNN-1,池化層分段數為1,即普通的卷積神經網絡;②PCNN-2,池化層分段數為2;③PCNN-3,池化層分段數為3;④PCNN-4,池化層分段數為4。其他參數如表3所示。

表3 實驗一參數設置
由表4可以看出,采用分段池化的卷積神經網絡在應用于生鮮類電商評論時,相較于普通的卷積神經網絡(PCNN-1)在準確率上有提升,以分成3段的PCNN-3最高,達到了93.25%,提升了1%。PCNN-3無論是在準確率,召回率還是F1均領先于PCNN-1,

表4 實驗一結果
說明了分段池化的操作可以在卷積神經網絡提取到文本局部特征的基礎上把握文本的結構特征。而通過PCNN-2與PCNN-4的實驗可以發現,在3個指標上與PCNN-1相近,且部分指標甚至不如PCNN-1。由圖7可以看出,PCNN-3的曲線一直在PCNN-1的上面,且能較快的收斂,隨著epoch的增加Accuracy的波動較為穩定,PCNN-1在本實驗中效果較差,Accuracy并不高且隨著epoch的增加難以趨于穩定。印證了Du等[13]得出的不合適的分段數會破壞文本序列本身的結構,只有合理的分段數才能較好地提取特征的結論。綜上可以得出結論,采用分段池化的操作并非是通過單純地增加提取的特征來提升模型性能,在本數據集中,選擇段數為3的分段數能取得較好的效果。

圖7 不同分段數的ACC曲線
3.3.2 實驗二
為了驗證本文提出的融合BERT的并行混合模型在生鮮食品短文本情感分類任務中的優勢,利用數據集一與數據集二來進行實驗。
實驗二對比實驗設置:①PCNN+BiGRU模型,即本文提出的模型;②CNN+BiGRU模型,將PCNN替換為CNN的模型;③BiGRU模型,只有BiGRU的模型,參數同上;④PCNN模型,只有PCNN的模型,參數同上,池化方式為分段池化;⑤CNN模型,只有CNN的模型,且池化方式為全局最大池化;⑥BiLSTM模型,只有BiLSTM的模型。
參考其他文獻中參數設置以及對各參數選擇進行實驗對比后,各模型最佳參數設置如表5所示。

表5 實驗二參數設置
由實驗結果表6可以看出,PCNN+BiGRU模型相比于CNN+BiGRU、BiGRU、PCNN、CNN和BiLSTM模型,在F1值上分別提高了1%、2.12%、0.83%、1.75%和1.26%。Accuracy值上分別提升了1.10%、1.5%、1%、2%和1.4%,Recall也比其他的要高。通過實驗可以發現CNN+BiGRU模型的準確率、F1等指標與傳統的CNN相近,但是模型訓練時間卻高出很多,說明單純的堆砌參數并不能有效地提升模型的準確率以及模型的性能,并非模型越復雜就越好,當與PCNN相比時,準確率反而降低了0.1%,然后在每個epoch的訓練時間上,PCNN有著較大的優勢。PCNN模型與CNN模型、BiGRU模型、LSTM模型相比,可以發現,當改變池化策略時,在不過多增加參數的情況下就能達到一個較高的準確率。通過表6也可以發現PCNN模型在準確率,F1與Recall均高于CNN、BiGRU和BiLSTM模型,且訓練時間較短,說明PCNN模型在一定程度上可以把握文本的結構特征。PCNN+BiGRU模型與同等復雜度的CNN+BiGRU模型相比在3個指標上均有提升,且自身的準確率也在數據集一和數據集二上分別達到了94.25%和85.88%,綜合起來可以發現,PCNN+BiGRU性能的提升并非單純因為模型參數的增加,而是因為該模型確實把握住了文本結構,對文本局部特征與全局特征的提取較為充分,也印證了本文提出的模型的有效性。
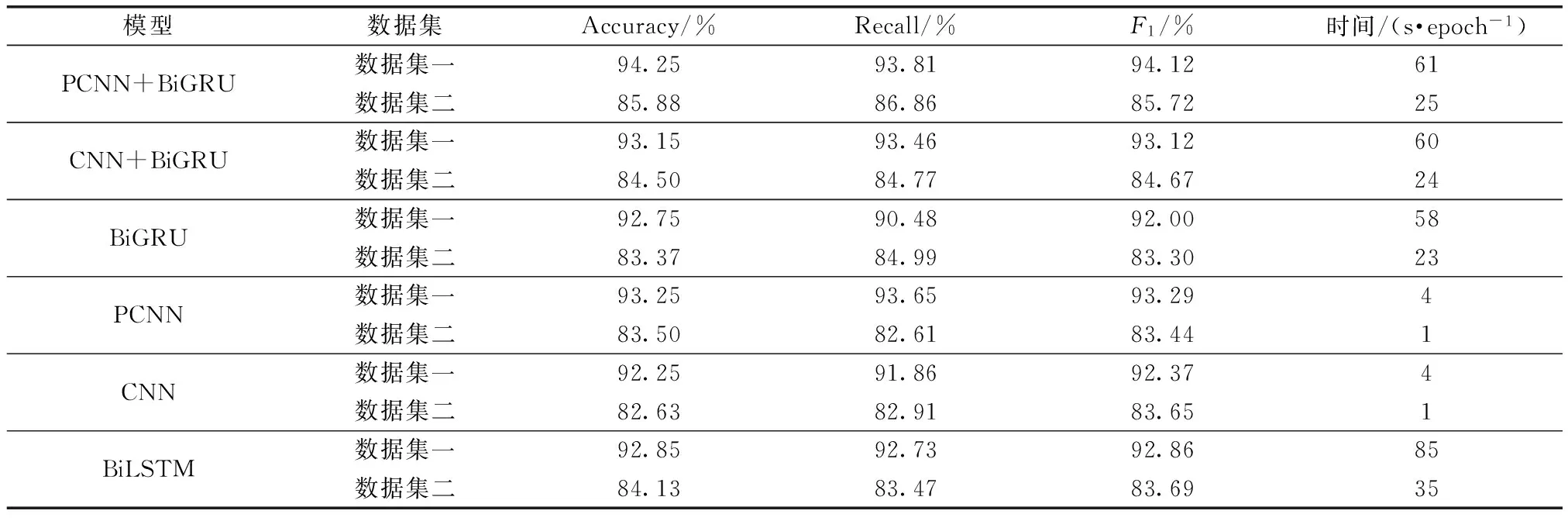
表6 數據集一和數據集二的實驗結果
4 結論
隨著移動互聯與物流的迅猛發展,網上購物已經成為民眾主要的購物方式之一。然而平臺監管難成為一個大問題,在全球新冠肺炎疫情沖擊下,進口生鮮產品攜帶新冠病毒的事情屢屢發生,國家層面的食品安全檢查難以面面俱到。從在線評論的情感角度去輔助監管與重點抽查是一項頗具實際應用意義的研究。
提出了一種融合BERT的情感分類模型,在同一公開數據集上通過不同算法之間的對比,初步印證了本文提出模型的有效性。得益于BERT強大的詞向量表征能力,本文模型得到了一個較好的準確率。同時發現了非模型越復雜準確率越高,并且發現分段池化卷積神經網絡在選定合適的分段數時,可以提升卷積神經網絡對文本序列信息的提取能力,并且在訓練耗時上與傳統卷積神經網絡幾乎相同。同時PCNN的性能可以和BiGRU模型、BiLSTM模型相媲美,但是訓練時間卻大大降低了。本文模型可以分別提取文本序列的結構信息與上下文信息,能較好地完成情感分類任務,為情感分類下游任務提供基礎。同時相對較短的訓練時間也能夠支持商品監管等效性較高的任務。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
