基于數據增強的領域知識圖譜構建方法研究
2022-03-11 06:55:21錢玲飛崔曉蕾
現代情報 2022年3期
錢玲飛 崔曉蕾

摘要:[目的/意義]探究使用大數據技術解決傳統制造業知識管理問題的方法,實現對專利知識的自動抽取和結構化構建,提高信息檢索效率和利用率。[方法/過程]結合深度學習技術,提出了一種面向非結構化專利信息的知識圖譜自動構建方法,在BiLSTM-CRF的基礎上引入預訓練模型實現對實體和開放式關系的自動抽取,并基于遷移學習進行數據增強提升抽取效果;改進實體關系抽取模型提升三元組結構識別的準確率;最后將其存儲到Neo4j圖數據庫中進行領域知識圖譜的構建。[結果/結論]本文提出的方法解決了信息抽取在專業領域樣本量少的問題,對專利三元組識別的準確率達到了94.71%,構建的知識圖譜能夠滿足企業創新知識管理和競爭情報獲取的需求,提升企業知識的可重用性。
關鍵詞:專利;數據增強;信息抽取;三元組識別;新能源汽車電池技術領域
近來,企業知識產權保護意識和創新意識不斷提升,專利文獻的數量也隨之不斷增長,在信息化建設仍然未全面普及的傳統制造業,難以對海量的文獻數據進行科學的管理和利用。隨著“中國制造2025”[1]“兩化融合”[2]的提出,制造業向智能制造的轉型升級是未來發展的必然趨勢。然而,目前國內中小制造業企業正面臨著信息化建設成本高,人才少,缺乏信息化建設具體實施方案等諸多問題[3]。專利文本作為制造業創新型文獻,主要以非結構化或半結構化形式存儲,對其挖掘領域知識并建立領域知識圖譜能夠提升知識的可重用性,幫助企業進行流程化的知識管理和存儲。本研究將深度學習技術運用到領域知識圖譜的自動構建,旨在融合大數據技術幫助傳統制造業進行內部知識管理,整合技術資源,解決在無可用知識庫情況下高質量領域知識抽取的問題,降低中小企業信息化建設成本。
1相關研究
1.1知識圖譜發展研究現狀
知識圖譜的概念最早在2012年由谷歌公司提出[4],其本質上是一個語義網絡知識庫,主要分為知識抽取和圖譜數據存儲兩個部分。知識抽取主要是從結構化、半結構化甚至非結構化的文本中挖掘有價值的信息[5],數據存儲則是將抽取出的信息進行集成。知識圖譜的存儲表現形式由節點和邊組成,節點即實體,邊即實體間的關系,知識通過這種方式集成后可以表現為結構化形式,便于知識的結構化管理和檢索。
國外知識圖譜技術進展較為迅速,目前發展較為成熟的知識圖譜有DBpedia[6]、YAGO[7]等。DB?pedia通過從維基百科抽取結構化結果,強化維基百科的檢索功能,包含95億事實三元組;YOGA包含1.2億條三元組數據,相比DBpedia引入了時間、空間知識。國內知識圖譜技術起步較晚,同樣集中在百科知識圖譜領域,百度知識圖譜基于百度百科構建而成,不僅能夠提升搜索效率,還可以為企業多領域業務提供知識基礎。
當前發展較完善的知識圖譜大多針對通用領域,但學術界已有部分學者開始進行關注專業領域知識圖譜的構建,XuR等[8]基于半監督學習從生物醫學文獻中抽取疾病風險關系,建立生物醫療知識庫;XuJ等[9]利用BioBERT模型從PubMed摘要中提取生物實體、作者、基金關系等數據,構建了PubMed知識圖譜用于后續知識分析;廖開際等[10]針對在線醫療問答社區數據量大、規范性差、數據稀疏等問題,構建在線醫療社區問答知識圖譜助力個性化醫療;楊波等[11]基于企業風險知識構建知識圖譜,引入時間維度動態觀測企業面臨的風險因素。領域知識對于企業來說既是重要的競爭情報,又是企業創新的堅實基礎,因此對領域知識進行有效的管理和存儲是十分必要的。本文選取包含領域專業知識豐富的專利文本作為領域知識圖譜構建的數據來源,專利文本作為工業界的重要技術資源,包含了最新的工藝技術信息及領域詞匯,便于獲知更多的領域技術信息。當前少有研究針對新能源汽車電池技術領域構建知識圖譜,本文將選取新能源汽車電池技術領域為研究對象,進行領域知識圖譜構建。
1.2實體關系抽取國內外研究現狀
實體關系抽取作為知識圖譜構建的基礎,主要由實體識別和關系識別兩部分構成。目前實體識別的研究已經取得了一定的進展,傳統的機器學習模型有隱馬爾可夫模型(HMM)[12]、條件隨機場(CRF)[13]等。隨著研究者對深度學習研究的不斷深入,HammertonJ[14]首先將LSTM模型應用于實體抽取領域;此后,HuangZ等[15]提出在條件隨機場模型的基礎上加入雙向長短時記憶神經網絡(BiLSTM)來挖掘上下文信息,提高模型效果。ZhaiZ等[16]在BiLSTM-CRF模型的基礎上引入EMLo預訓練模型,增強數據的語義表示。目前在命名實體識別基礎研究領域已有大量的高質量開源數據,但在特定領域,樣本數據缺乏是信息自動抽取的難點之一。馬建霞等[17]依托于文物資源數據庫對訓練樣本進行規則映射,解決了文物領域數據標注的問題;彭博[18]基于規則庫和知識庫對生態治理技術領域文獻進行實體標注。在沒有可應用的領域本體及術語詞典的情況下,人工標注的工作量繁重,需要耗費巨大的時間成本。因此,本文將在小樣本標注的基礎上,基于遷移學習思想進行數據增強,旨在獲取精確度更高的領域知識用于領域知識圖譜的構建。
關系識別可分為限定關系識別和開放關系識別。傳統實體關系抽取研究大多基于限定關系,GiorgiJ等[19]基于BERT預訓練模型提出了端對端的實體關系識別;ChenL等[20]對英文專利文本中的實體關系進行注釋,提出了基于SAO法的實體關系抽取框架。限定關系抽取作為一個多分類問題,通常分類粒度較粗,包含的語義信息有限,為此,BankoM等[21]提出開放關系抽取的概念,即無需預先定義關系類型,從文本中提取所有能找到的語義關系。開放關系識別可以看作關系抽取和實體關系識別兩部分,StanovskyG等[22]將開放信息抽取問題轉化成序列標記問題,基于BiLSTM算法擴展了深層語義角色標記模型并取得了突破性的進展;羅耀東[23]利用基于語義角色標注的BiLSTM深度模型運用于濕地文獻數據關系抽取,并對實體關系進行識別和匹配。現階段開放關系識別的研究較少,本文將在實體識別階段加入開放關系識別,并利用關系識別分類算法對抽取出的實體關系三元組進行識別,最終作為知識圖譜構建的基礎數據。
2基于深度學習的領域知識圖譜構建模型
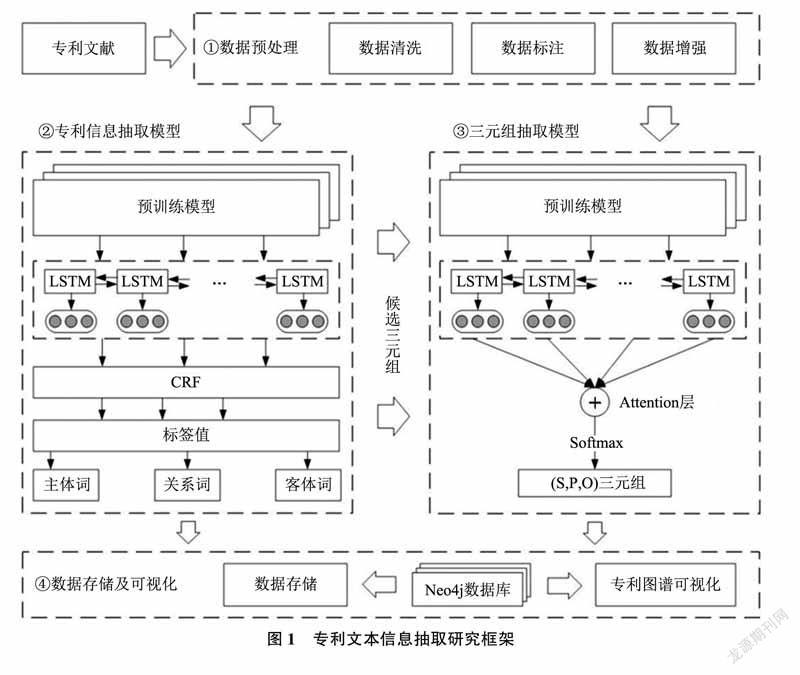
本文提出一種基于深度學習的領域知識圖譜自動構建方法,實驗流程主要分為數據預處理、領域知識抽取、三元組識別及知識圖譜可視化4個部分。
2.1領域信息抽取模型構建
為解決領域內語料數據不足的問題,本文將對已標注的訓練數據進行數據增強來提升信息抽取的效果。傳統的數據增強方法包括同義詞替換、隨機插入、隨機交換和隨機刪除[24],但領域知識往往包含大量專業詞匯,結構固定,傳統數據增強方法并不適用,因此,本文引入遷移學習思想進行數據增強的研究。
遷移學習[25]是指將從之前訓練任務中學到的知識應用到新的訓練任務中,主要分為樣本遷移、特征遷移、模型遷移和關系遷移。其中,特征遷移[26]可以在文本特征分布相似的情況下,借助歷史標記數據以解決目標項目訓練實例過少的問題。本文選取的數據為新能源汽車電池技術領域的專利文本,具有領域分支少、文法結構相似等特點,通過特征遷移的方法對人工標注的少量樣本數據進行數據增強,提升信息抽取模型訓練效果。
信息抽取模型主要分為文本的多維向量映射和語義特征提取兩個方面。文本的多維向量映射即文本的語義表示,傳統的語義表示方法,例如Onehot、Word2vec、Glove等,使用一個詞向量對應一個詞語,包含的語義信息有限;現階段使用較多的是預訓練模型,例如EMLo預訓練模型和BERT預訓練模型,能夠表達出詞語在不同語境下的語義信息。預訓練模型通過對大量語料進行無監督學習來獲取豐富的語義特征,相比于EMLo模型,BERT將模型結構由LSTM更改為Transformer,解決了長依賴的問題,并通過遮蔽語言模型(MaskedLan?guageModel,MLM)和下一句預測(NextSentencePrediction,NSP)兩種預訓練任務,分別從預測遮蓋詞和預測下一句兩個方面學習文本的語法、語義及句間關系[27]。
文本的語義特征主要通過神經網絡來進行提取,本文選取的基準模型為雙向長短記憶神經網絡模型[28](Bi-directionalLongShort-TermMemory,BiLSTM)和條件隨機場模型[13](ConditionalRandomField,CRF)。在雙向長短記憶神經網絡中,前向的LSTM模型可以存儲上文信息,后向的LSTM模型可以存儲下文信息,因此,BiLSTM模型能利用上下文信息對文本數據進行特征提取,由于上下文的語義信息對實體詞、關系詞的序列標注具有重要意義,BiLSTM能夠使得模型對當前位置的信息預測更加準確。傳統的序列標注算法通常在BiLSTM層后直接接入Softmax函數進行文本標簽值的輸出,但BiLSTM模型無法處理相鄰序列值之間關系,為了減小這一影響,本文在BiLSTM后接入CRF層來優化序列標注結果,輸出字序列對應的概率值最大的標簽值提高序列標注的準確率。
2.2三元組識別模型構建
本文選取新能源汽車電池技術領域為研究對象,基于專利文本構建領域知識圖譜。本文在信息抽取階段的數據標注中引入語義角色信息,對實體詞進行主體詞和客體詞的區分,一方面可以提高信息抽取效率,另一方面可以減少候選三元組的噪聲數據,提升三元組抽取的準確率和圖譜構建效率。
信息抽取模型抽取出信息主要分為主體詞集合、關系詞集合以及客體詞集合3類,分別映射到知識圖譜(S,P,O)三元組的表示形式中,候選三元組由主體詞、關系詞及客體詞的隨機組合形成,三元組數據是圖譜構建的基礎。因此,圖譜構建模型的關鍵在于去除候選三元組的噪聲數據,識別語義正確的三元組,也可以看作對三元組和專利文本的語義匹配。本文將候選三元組和對應的專利文本語句組合成一個長句子,利用預訓練模型和雙向長短記憶神經網絡模型進行語義解析,為減少長序列文本在解碼過程中上下文信息、位置信息丟失問題的影響,本文加入注意力機制[27](Attention)來增強重要字詞的權重,優化模型,提升模型的準確率。
2.3領域知識圖譜構建及可視化
本文基于前兩小節的工作,將抽取出的三元組結構導入到Neo4j圖數據庫中進行結構化的存儲和展示。Neo4j數據庫作為圖數據庫的一種,主要由節點、屬性和關系3種模塊構成,可以將知識進行結構化的可視化存儲,同時,它支持遍歷式的查詢,通過查詢語句獲知專利實體之間的關系及專利間關系,對企業競爭情報便捷獲取有極大幫助,提升大數據下的信息檢索效率[29]。
3實驗
3.1實驗數據來源
本文利用關鍵詞匹配的檢索方式從CNKI中國專利數據庫中獲取新能源汽車電池技術領域專利文獻,作為構建知識圖譜的基礎數據。由于專利摘要的高度概括性,本文將專利摘要作為領域知識抽取的來源,進行人工標注及數據預處理后獲得8238句,共63228個字符的標注實驗語料。
3.2基于數據增強的信息抽取實驗
3.2.1數據預處理
本文采用BIO標注法分別對每個字符人工標注,B表示詞的開始,I表示詞的中間或結束,O表示不屬于任何一個標簽的部分。基于該體系標注后共得到9個標簽類型,分別為“B-SUBJ”“ISUBJ”“B-OBJ”“I-OBJ”“B-PRE”“I-PRE”“B-CHAR”“I-CHAR”“O”。
3.2.2數據增強
本文把實驗語料按8∶2劃分為訓練集和測試集,利用信息抽取領域的傳統模型BiLSTM-CRF作為基準模型進行數據增強,具體方法為:將標注后的訓練集數據作為基準模型訓練的樣本,對未標注的文本數據進行標簽預測,獲得數據1199句,共10503個字符,最后對人工標注的訓練集數據和基于模型遷移標注的數據進行融合,作為最終模型的訓練樣本。
最終用于領域信息抽取模型的實驗語料9437句,共73731個字符。
3.2.3實驗設置
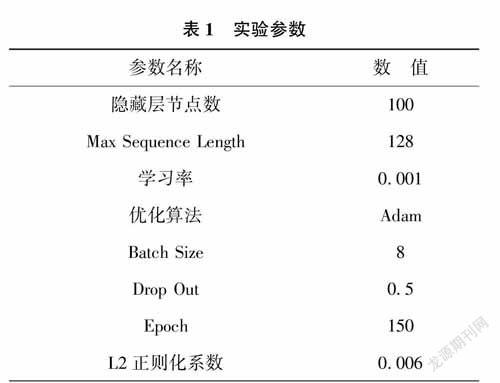
本文將實驗文本以字符為單位作為模型的輸入層,對比基準模型BiLSTM-CRF和加入BERT預訓練的模型實驗效果,驗證預訓練模型對于文本語料特征表示是否有增強。此外,本文通過設置數據增強對比實驗來驗證數據增強對于小樣本量信息抽取模型的效果,數據增強用DATA(str)表示。本次實驗基于TensorFlow框架,訓練過程中的參數設置如表1所示。
3.2.4實驗結果及分析
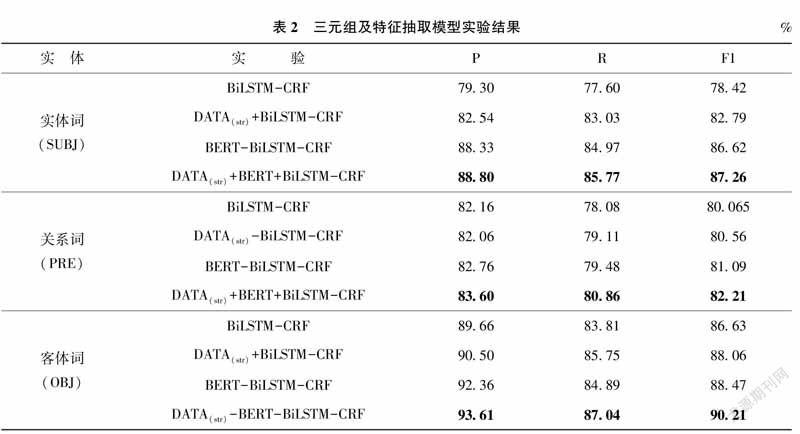
本次實驗以精準率、召回率和F1值為評價指標,取5次結果的均值作為最終結果,實驗結果如表2所示。
從實驗結果上看,雖然進行數據增強后的訓練語料中包含部分噪聲數據,但對于模型訓練效果影響不大,由于新能源汽車電池技術領域可復用的領域知識少,樣本規模小,借助遷移學習思想對訓練樣本進行數據增強不僅能夠極大地減少人工標注的壓力,且對于模型效果的提升也十分顯著。此外,預訓練模型本質上也是遷移學習的應用,通過對大量開放性語料進行無監督學習,獲取到更深層次的語義信息,對下游模型的訓練起到輔助作用。對于小樣本量的模型來說,借助預訓練模型可以更進一步提升模型效果。
從信息抽取的角度看,模型對于客體詞的抽取效果最好,主要原因是主體信息大多由名詞和方向性名詞組合構成,結構多變,而客體詞相比于主體詞及關系詞更加標準,特征更明顯。而開放式關系抽取使得關系詞更加多樣化。例如:連接關系包含連接、轉動連接、固定連接、滑動連接等。這種非標準化的構成導致抽取模型效果降低,但開放式的信息抽取方式使得抽取出的信息語義更加多樣,包含大量的專有名詞、專業術語等,能夠滿足企業對于領域知識的需求。抽取出的部分主體詞、關系詞、客體詞如圖2所示。
3.3知識圖譜構建
3.3.1三元組識別實驗
知識圖譜構建的基礎是形如“實體—關系—實體”的三元組結構,本文對抽取出的實體詞、關系詞及客體詞進行隨機組合后,共獲取到4512個候選三元組,三元組結構需要與專利摘要保持語義一致,將其看作語義匹配的過程,輸入格式為三元組和專利句的結合,形成一個長句子作為模型的輸入,本文在對比實驗中引入預訓練模型和注意力機制,通過預訓練模型加強文本的語義特征,同時利用注意力機制可以對長文本中的重要信息進行加權,在進行三元組和文本句的語義匹配時,使得模型有更好的學習效果。
3.3.2實驗結果分析
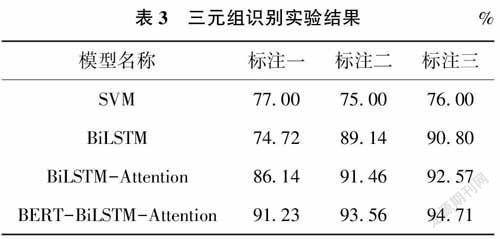
本文將候選三元組按8∶2的比例劃分為訓練集和測試集,由于正負樣本較為均衡,本實驗采用準確率(acc)作為評估標準,代表預測正確的樣本數占總樣本數的比例,實驗結果如表3所示。
從模型的角度看,深度學習模型實驗效果要明顯優于傳統機器學習模型(支持向量機,SVM),且加入注意力機制和預訓練模型后,模型性能有顯著提升。
同時,針對本文使用的數據集特征,在數據輸入格式上進行創新,傳統的語義匹配模型通常是在實體詞、關系詞及專利文本之間加入特殊分隔符,并在專利文本對應位置處用其他特殊符號分別替換實體詞和關系詞,標注位置信息。筆者認為,三元組實質上可看作包含語義信息的短文本,為增強三元組的語義表示,本文不對三元組進行分隔,“標注一”直接利用特殊分隔符將三元組與專利文本隔開,判斷三元組與文本數據之間的語義匹配是否正確。“標注三”是“標注一”和“標注二”的結合,即加入三元組的位置信息。實驗結果從數據標注方式的角度來看,本文所提出的數據輸入格式有效,結合本文所用的模型后,模型準確率能夠達到94.53%的最優值。
3.3.3專利圖譜構建及可視化
本文將抽取出的實體關系三元組存儲到Neo4j圖數據庫中,結合專利文本的公開號、申請方、作者等信息,構建的新能源汽車電池技術領域知識圖譜共包含36635個實體節點和29488個關系邊。
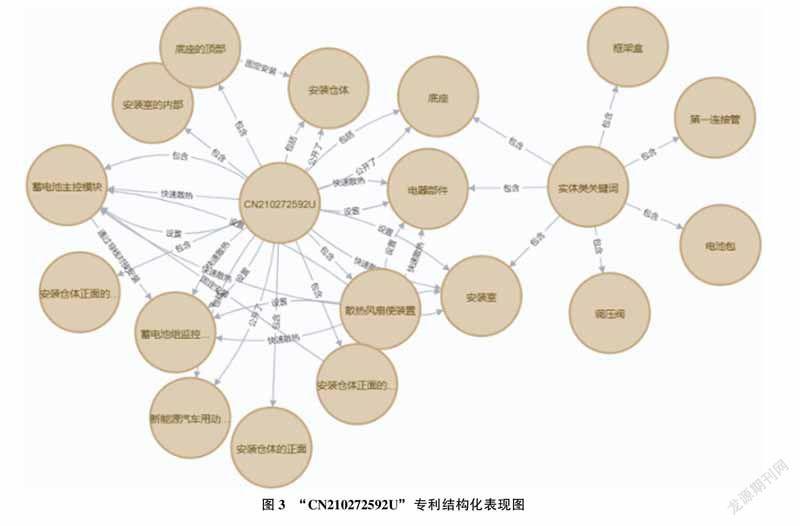
新能源汽車電池技術領域知識圖譜由專利信息和領域關鍵詞兩部分構成,專利信息以專利公開號為唯一識別號,圖譜所存儲數據包括專利作者、申請方、專利名稱及結構化專利領域知識,結果如圖3和圖4所示。由此可見,由專利信息建立的領域知識圖譜,一方面可以較為明確地反映出專利之間以及專利作者、申請方之間的關系,幫助企業更為便利地獲取行業內專利創新競爭情報;另一方面,將非結構化的專利信息以結構化的圖譜形式進行展示,便于企業后續的創新知識管理,在企業進行技術革新、工藝創新時,可以重用領域知識,且在進行內部管理培訓時,知識圖譜能夠較為快速地進行領域知識檢索,發現知識間的關聯關系。
領域關鍵詞主要分為實體類關鍵詞和關系類關鍵詞,本文利用哈工大分詞工具分別對抽取出的實體詞和關系詞進行分詞處理,經過詞頻統計、數據去重、無效詞清洗后,最終抽取出實體類關鍵詞1379個,關系類關鍵詞262個,部分領域關鍵詞抽取結果如圖5所示。
4結論和不足
為解決非結構化專利信息抽取和領域知識圖譜構建問題,本文選取新能源汽車電池技術領域的專利文本為研究對象,綜合深度學習算法BiLSTM、CRF、BERT預訓練模型及注意力機制,提出了一種基于非結構化信息自動抽取的知識圖譜構建方法,并驗證了該方法的可行性和有效性。結果顯示,通過本文提出方法能夠極大程度減少數據量對于實體關系抽取模型的影響,取得較高的精準度和召回率,為構建高質量領域知識圖譜提供數據和技術支撐,提升知識的可重用性。
本文的創新點主要體現在以下幾個方面:第一,在沒有可用領域知識詞典和知識庫的情況下,通過數據增強和增加預訓練模型降低樣本量小對領域知識抽取效果的影響,減少了人工標注成本,實現了領域知識的自動抽取,為小樣本數據的實體抽取提供了一種方法;第二,本文旨在利用序列標注算法解決開放式關系的識別,最終提取出的關系相比于人工劃分的限定關系具有更強的專業性,為新能源汽車電池技術領域的知識發現提供更豐富的數據支持;第三,在三元組識別實驗模型BERT-BiL?STM的基礎上加入注意力機制,結合文本匹配的特點,增強了長文本的重點信息的權重,提升了三元組識別實驗的精確率。
未來研究中,本文將進一步探究擴大數據集規模的方法,驗證方法的普適性,并引入領域術語、上下位關系等信息構建更全面的領域知識圖譜,進行更廣泛的應用研究。
3078500338287
