神經機器翻譯譯文評測及譯后編輯研究
2021-12-17 04:40:12郭望皓胡富茂
北京第二外國語學院學報 2021年5期
郭望皓 胡富茂
引言
從2013 年開始,以神經網絡為主要特征的神經機器翻譯發展迅速,現已取代統計機器翻譯成為機器翻譯的主流范式。谷歌、微軟、百度、騰訊等國內外行業巨擘紛紛上線自己的神經機器翻譯系統,推動機器翻譯向實用化和商品化不斷邁進。2018 年3 月,微軟研究團隊甚至宣布其研發的機器翻譯系統在通用新聞報道的漢英翻譯上“達到了人類水平”。盡管如此,神經機器翻譯仍然面臨諸多挑戰,垂直領域專業題材的文本翻譯便是其中最大的一個挑戰。目前,市面上的主流神經機器翻譯系統都是面向通用領域的,對垂直領域文本的翻譯效果往往并不盡如人意。本文選取的英漢機器翻譯引擎分別來自谷歌、百度、騰訊、有道和搜狗5 家公司,均采用目前流行的神經機器翻譯技術作為英漢機器翻譯系統的基本架構。作為國內外知名企業研發的產品,這些翻譯引擎技術成熟、可靠性高、實驗數據可重復,而且都提供了英漢翻譯的API 接口,技術實現較為簡單。不過,通過實踐可以發現,在垂直領域僅依靠神經機器翻譯難以產出高質量的譯文,因而譯后編輯環節必不可少。本文以軍事領域英漢神經機器翻譯譯文評測作為切入點,通過整理歸納軍事題材英譯漢文本的錯誤類型,分析影響譯文質量的因素,并提出針對性的譯后編輯建議。
一、相關研究綜述
由于軍事領域翻譯任務量大,時效性要求高,各國都高度重視軍事用途機器翻譯的研發工作。Hutchins(2007)在講述機器翻譯發展史時指出,機器翻譯之所以在二十世紀五六十年代得以開端,正是源于美蘇兩國當時旺盛的軍事情報需求。Palmer et al.(1998)利用當時既有的技術模塊組合成了一個機器翻譯系統,專門用于從英語到法語的戰場信息翻譯。Holland et al.(2000)研發了一個能夠快速掃描紙質文本并將之翻譯成英文的原型系統,可以為獲取軍事情報提供便利。Jones et al.(2009)指出針對低資源語言和受限語言的機器翻譯研究具有重要的軍事意義和價值,并重點介紹了林肯實驗室在機器翻譯方面所做的探索性工作。在美國國防部高級研究計劃署(Defense Advanced Research Projects Agency,DARPA)的資助下,卡內基梅隆大學研發了可用于戰場交流的語音機器翻譯系統DIPLOMAT,其中包含塞爾維亞—克羅地亞語、海地克里奧爾語、韓語等美軍急需的語種翻譯(Frederking et al.,2000)。此外,DARPA 還先后啟動了多個與機器翻譯相關的研究項目,如“戰術用途的口語溝通與翻譯系統”(TRANSTAC)、“全球自主語言利用計劃”(GALE)、“多語言自動記錄分類分析和翻譯”(MADCAT)、“緊急事件低資源語言計劃”(LORELEI)等,部分研究成果已經被應用于駐阿富汗和伊拉克美軍的實戰之中。
國內有關軍事領域機器翻譯的公開資料不多,相關研究主要分為以下3 類:一是從理論上探討發展軍事領域機器翻譯技術與裝備的必要性與緊迫性,如解國棟等(2006)、劉明和彭天笑(2018a/b);二是比較不同機器翻譯系統在軍事文本翻譯中的表現,如張卉媛、楊士超(2019);三是探討機器翻譯技術在軍事領域的應用,如鮑廣宇等(2003)、黃金柱等(2016)。
眾所周知,信息技術的發展和應用給翻譯帶來了深刻的影響與變革(孔令然、崔啟亮,2018;司顯柱、郭小潔,2018)。“機器翻譯 + 譯前 / 譯后編輯”便是近年來出現的一個重要變革,已經成為翻譯工作的一種重要模式,有關譯后編輯的研究也呈井噴態勢,其中既包括對理論的探討,如譯后編輯的概念、發展現狀、人才培養、能力建設及未來趨勢等(魏長宏、張春柏,2007;崔啟亮,2014;馮全功、崔啟亮,2016;馮全功、劉明,2018),也包括各種實證研究,研究者往往從某個譯后編譯實踐出發,探討譯后編輯的方法(陳齊祖,2014)、作用(王萍,2016;郭高攀、王宗英,2017)、策略(張瑞雪,2018;褚閩閩,2018)、適用性(劉艷麗,2020)以及機器翻譯與人工翻譯的認知差異(周博,2017)等。對這些文獻進行梳理后可以發現,以機器翻譯的譯后編輯作為選題的MTI碩士論文呈逐年增多的趨勢,這也在另一個側面反映出學界對該問題的關注。此外,許杰(2018)、程露藍(2018)以The Defense Industrial Base: Strategies for a Changing World一書的翻譯實踐為例,歸納總結了國防科技文本的特征,提出了譯后編輯的策略。但是總體來看,有關軍事文本譯后編輯的論文數量仍然較少。
從上述研究分析可以看出,目前學界對于軍事文本譯后編輯的關注程度尚不夠高,且許多研究對機器翻譯背后的機制仍不夠了解,因此未能提出具有針對性的譯后編輯策略。本文將在對相關翻譯錯誤進行統計分析的基礎上,指出哪些類型的錯誤是目前的機器翻譯難以克服的,哪些類型的錯誤是可以通過技術手段迅速加以解決的,以期切實提高軍事題材文本譯后編輯的效率與質量。
二、軍事領域英漢神經機器翻譯譯文評測實驗設計
本研究有針對性地選取了谷歌等國內外知名公司研發的5 個主流神經機器翻譯系統作為實驗對象,選取1 000 句軍事文本作為實驗材料和1 000 句通用領域文本作為對照材料,采用國際通用的BLEU(Bilingual Evaluation Understudy)算法來對譯文的質量進行評測,力求客觀地反映目前神經機器翻譯系統在軍事領域英譯漢翻譯方面的表現。在測定BLEU 值的基礎上,本研究將再通過人工手段對機器翻譯的錯誤進行分類統計。
1. 研究問題
本研究要探究的兩個問題是:(a)主流機器翻譯系統在翻譯英語軍事題材文本和通用文本時,漢語譯文質量方面有無顯著差異?(b)軍事題材文本英譯漢譯文的錯誤類型有哪些?呈現何種特點?
2.研究路徑
本研究采用的技術路線為:(a)構建實驗數據集和對照數據集;(b)運用國內外主流的神經機器翻譯系統分別對實驗數據和對照數據進行英譯漢機器翻譯;(c)計算BLEU 值;(d)對機器產出的翻譯錯誤進行分類統計。
3.研究數據集
為研究目前國內外主流神經機器翻譯系統對軍事文本和通用文本英譯漢譯文的質量是否存在顯著差異,研究者構建了兩個數據集。實驗數據集由軍事領域英漢雙語文本構成,對照數據集則以新聞領域英漢雙語文本為主。兩個數據集的原始語料均來自于互聯網,都屬于開放型的數據,目的是為了最大限度地確保實驗結果的可比性。
(1)中英雙語語料的選擇
互聯網上有關軍事領域的文本汗牛充棟,但高質量的英漢對照文本并不容易獲取。經過仔細甄別篩選,研究者選取Air Sea Battle: A Point-of-Departure Operational Concept(《作戰概念起點》)、The United States Army’s Cyberspace Operations Concept Capability Plan 2016–2028(《美國陸軍網絡作戰概念能力構想2016—2028》)和2014 Quadrennial Defense Review(《四年防務評估報告(2014 版)》)集中作為實驗數據中原始數據的來源。這3 篇報告的原始漢譯文均來自于知遠戰略與防務研究所網站①知遠戰略與防務研究所網址:http://www.knowfar.org.cn/。。
在構建對照數據集時,研究者選取了VOA 雙語新聞、《中國日報》雙語新聞和《經濟學人》雙語對照文本中的部分內容。這些語料都是經過人工校對后才發布到互聯網上供人們閱讀使用的,因此翻譯質量是能夠得到保證的。
(2)語料預處理
互聯網上下載的語料格式不統一,存在多余的空格、與研究內容無關的圖表等,因此需要首先對數據進行清洗。研究者通過以下3 個步驟對語料進行了預處理:(a)將所有文本轉化為TXT 格式;(b)去除文本中多余的空格、空行,以及與研究任務無關的圖表、符號等;(c)刪除原始文檔中的目錄及各種類型的注釋。
(3)雙語語料句對齊
在完成原始語料預處理之后,研究者對英漢雙語文本進行了句對齊處理。本次研究選用的句對齊工具是成都優譯信息技術股份有限公司研發的工具Transmate 單機版。這款工具對中文的支持度較好,對齊準確率較高,個人用戶可免費下載使用。
(4)構建研究數據集
由于原始數據較多,譯文質量參差不齊,為了在有限的時間內盡可能地保證實驗的效度與信度,研究者對實驗數據集和對照數據集作了進一步的處理。一方面,使用隨機采樣的方法,利用計算機在軍事文本實驗數據集中抽取了1 000 個句長大于10 個單詞的英文句子,并由2 名專業軍事翻譯人員對這1 000句英文的漢譯文本進行了校對,以保證譯文的準確性與專業性。隨后,研究者采用同樣的方法從通用文本對照數據集中也提取了1 000 個句子,但并未對譯文再作校對與修改。最后,對已選取的雙語對齊數據的對齊質量和文本格式進行了人工核對,最終完成了研究數據集的構建工作。兩個數據集的基本情況如表1 所示。

表1 實驗數據集和對照數據集的基本情況
4.神經機器翻譯系統進行翻譯
研究者將建好的數據集導入Microsoft Excel 中,通過自編的Python 小程序調用谷歌、百度、騰訊、有道和搜狗5 家公司的在線機器翻譯引擎,對數據集收納的英語原文進行了英漢翻譯,并將翻譯結果返回顯示在Microsoft Excel 中,以便后期進行數據分析。實驗日期為2019 年5 月22 日,翻譯結果如圖1 所示。

圖1 谷歌等5 個機器翻譯系統的翻譯結果
5. BLEU 值計算
較之于人工打分,對譯文質量進行自動評測具有速度高、成本低、不依賴于人的主觀判斷等優勢。Bilingual Evaluation Understudy(BLEU)算法是美國IBM 公司提出的一種文本評估算法,一般用于評測機器翻譯與專業人工翻譯之間的對應關系,是目前普遍采用的一種機器翻譯自動評測指標。其核心思想是利用N-gram 和懲罰因子對機翻譯文和人工譯文進行相似度計算,二者越相似,說明機翻譯文的質量越高,這時BLEU 值越接近于1;反之,BLEU 值接近于0。在實際操作中,可以在Python 中直接調用NLTK(Natural Language Toolkit)的nltk.translate.bleu_score 工具包進行計算。在本實驗中,各項參數均選用默認值,數據平滑算法采用Chen & Cherry(2014)推薦的method 4,通過計算最終得到BLEU 值數據。
本研究用于數據統計分析的工具是IBM SPSS Statistics 22。
三、實驗結果及討論
1. 總體情況
在基于BLEU 值的自動評測中,BLEU 值越高,說明機器翻譯的結果越接近人工譯文。Doddington(2002)實驗表明,BLEU 評測結果與人工評測結果具有高度相關性,因此能夠在一定程度上反映機器翻譯系統翻譯質量的優劣。本實驗對兩組數據的描述性統計結果顯示,谷歌、百度、騰訊、有道、搜狗5 個神經機器翻譯系統軍事領域文本英譯漢譯文的BLEU 均值分別為20.59、22.03、21.50、18.65、21.50,各系統平均值為20.85(詳見表2);通用領域文本譯文的BLEU 均值分別為27.90、27.52、27.70、26.47、27.75,各系統平均值為27.47(詳見表3)。實驗結果證實,以目前市場上主流的機器翻譯系統為代表的神經機器翻譯,在通用領域文本英漢翻譯方面顯著優于軍事文本翻譯,前者的BLEU 值平均比后者高出6.62。
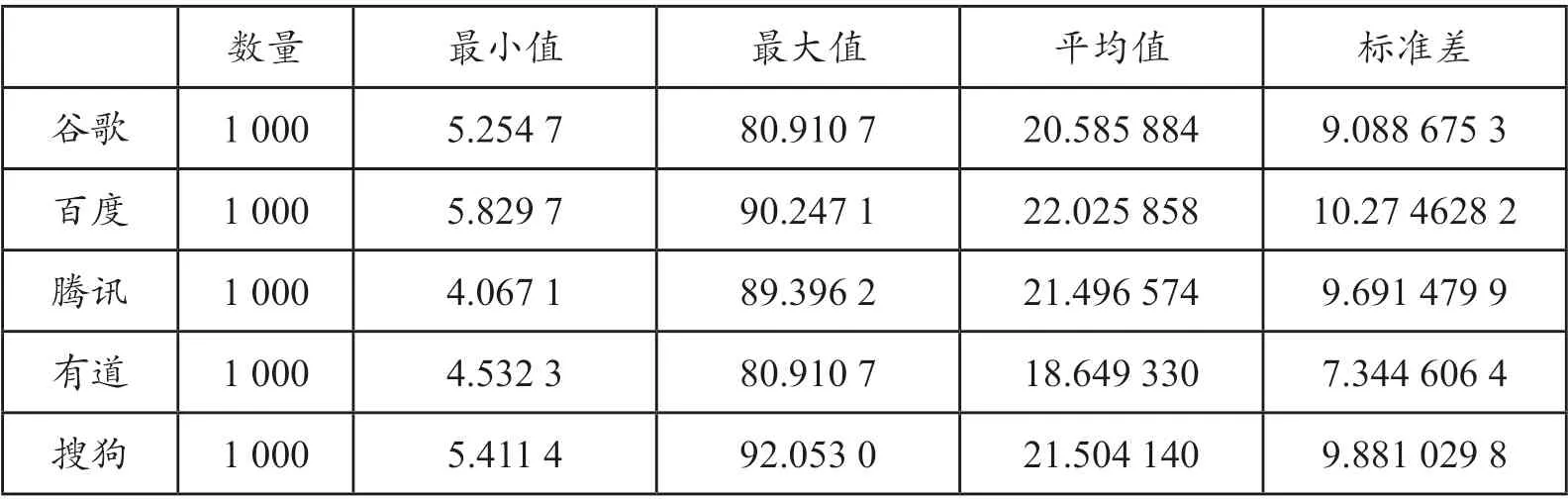
表2 谷歌等5 個神經機器翻譯系統在軍事領域文本翻譯上的表現(BLEU 值)
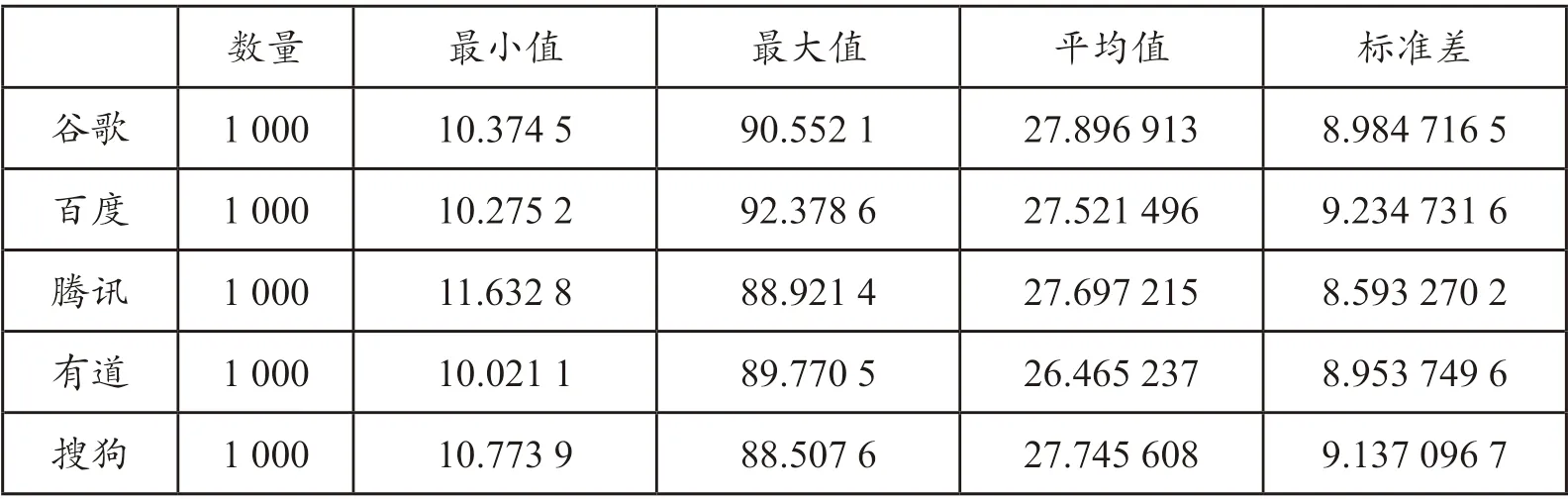
表3 谷歌等5 個神經機器翻譯系統在通用領域文本翻譯上的表現(BLEU 值)
2.錯誤類型分析
盡管BLEU 值對評估譯文質量的優劣具有一定的參考價值,但是僅依靠BLEU 值無法給譯后編輯帶來更多的幫助,因此研究者需要對錯誤類型進行更加深入細致的分析。李梅、朱錫明(2013)等研究表明,深入研究分析機器翻譯的錯誤類型,能夠有效地提升譯后編輯的效率。
研究者對所有機器翻譯的結果進行了統計分析。首先,在借鑒相關研究(Vilar et al.,2006;Farrús et al.,2010;Kirchhof f et al.,2012;Stymne & Ahrenberg,
2012;Comelles et al.,2017;羅季美、李梅,2012;李梅、朱錫明,2013;羅季美,2014;劉艷麗,2020)的基礎上,研究者從語言學角度出發,將翻譯錯誤類型分為拼寫錯誤、詞匯短語錯誤、句子句法錯誤和語義錯誤4 個大類,每個大類下又分成若干個小類,最終確定了15 個小類的錯誤類型,如表4 所示。
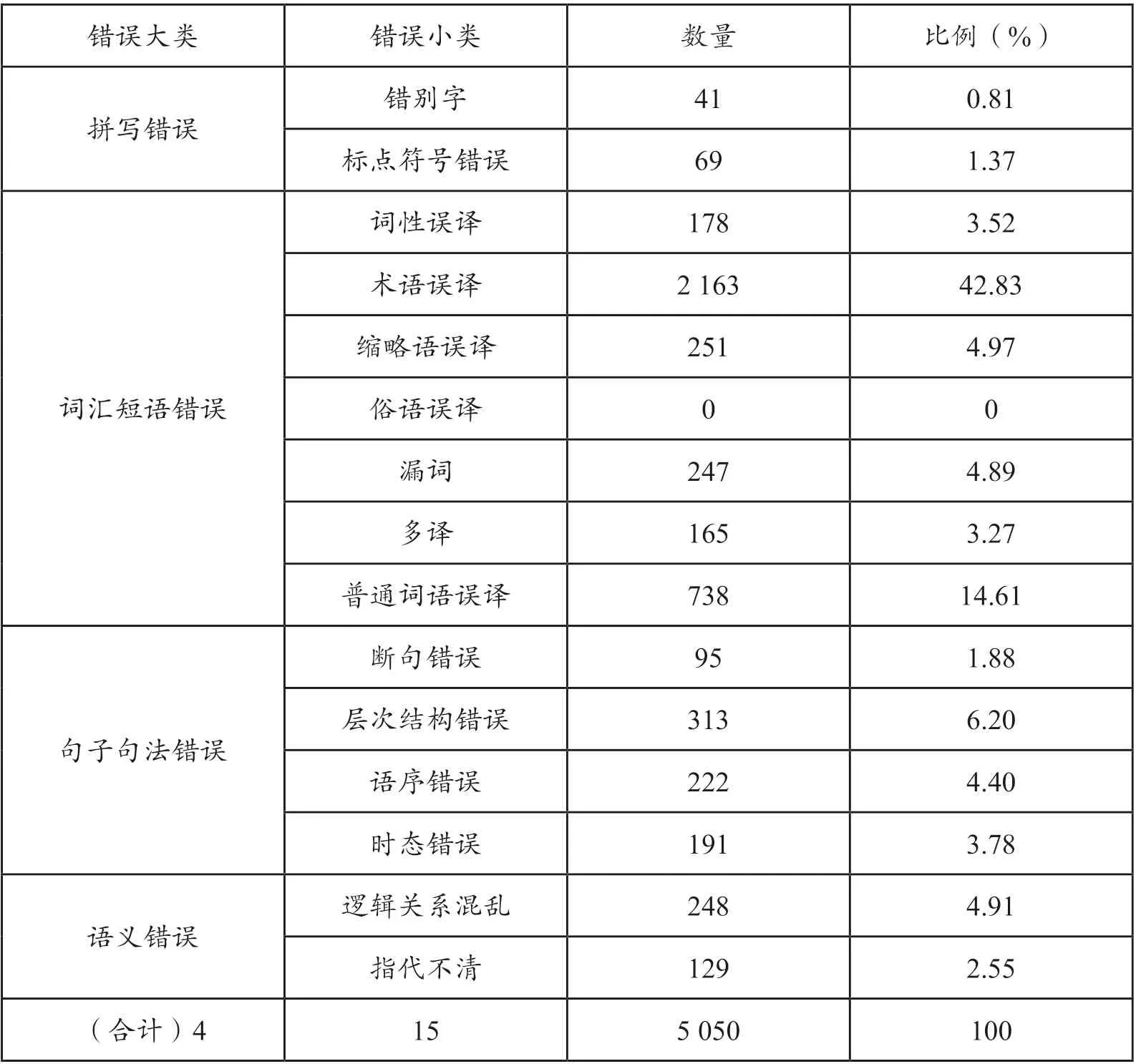
表4 機器翻譯錯誤類型統計分析
(1)拼寫錯誤
① 錯別字
神經機器翻譯模型的構建往往以大規模語料為基礎,這使得其譯文的流利度較之于以前的統計機器翻譯系統有了較大的提高,加之成熟的系統往往在譯文生成后會利用語言模型等技術對譯文進行糾錯處理,所以,一般來說,單純的錯別字還是比較少的,主要是在該用“地”的時候用了“的”之類的誤用。究其原因很可能是原始語料中就存在大量此類錯誤,而在模型訓練的過程中,這類錯誤也被學習到并保留了下來。例如,“correspondingly reduced on-station time”被譯為“相應的減少在空間站時間”(有道),應為“相應地減少在空間站時間”。
② 標點符號錯誤
在機器譯文中,有些標點符號的用法不符合中文表達習慣,其中大部分是格式錯誤,如使用了半角標點或單破折號等。這類錯誤盡管數量不少,但并不影響對譯文的理解,而且在后期編輯過程中極易統一處理,故并未納入錯誤統計之中。納入統計的標點符號錯誤有:頓號和逗號之間的誤用、引用他人說法時未使用冒號和引號、連詞“和”前使用逗號的情況。總的來說,這類錯誤也不算太多,屬于行文不規范,對語義理解并不會造成太大障礙。
(2)詞匯短語錯誤
詞匯短語誤譯是翻譯中最為常見的錯誤,該類錯誤在數量上占絕對多數,共包含7 個小類的錯誤類型。
① 詞性誤譯
詞性誤譯是指將原本應譯為A 詞類的詞譯成了B 詞類,如將動詞譯為名詞等。例如,有道將“ability to project”(<兵力的>投送能力)譯為“項目能力”。這類錯誤時常出現,并且沒有任何規律可循,即使同一神經機器翻譯系統在翻譯不同句子中的同一短語結構時,也可能會出現不同的譯法。
② 術語誤譯
軍事文本與其他專業文本一樣,都存在大量的專業術語。與普通詞語相比,術語最大的特點就是無歧義性,能夠準確表義,符合軍事文體的要求。美國翻譯協會(American Translators Association,ATA)秘書長Alan K. Melby 將“術語”視為翻譯“三腳架”(Tripod)中的一個支架(轉引自Jiang & Wang,2018:64)。由此可見,術語在翻譯(尤其是專業領域翻譯)中極其重要。在本實驗中,術語誤譯在15 種錯誤類型中數量最多、占比最高。具體而言,術語誤譯可分為以下兩類:
一是把軍事術語誤譯為普通詞語。例如,把“theater”(戰區)誤譯為“劇院”(谷歌、百度、搜狗),把“logistics”(后勤)誤譯為“物流”(谷歌、百度、騰訊、有道、搜狗)等。這樣的誤譯例子不勝枚舉。
二是有的軍事術語未采用通用譯法。例如,“Western Pacif ic Theater of Operations”的通用譯法為“西太平洋戰區”,有的系統卻將之譯為“太平洋戰場西部”(搜狗);又如,“AirSea Battle”的通用譯法為“空海一體戰”,有的系統卻將之譯為“空海戰役”(百度、騰訊)。這種情況不僅存在于軍事術語的翻譯中,也存在于包括組織機構名稱在內的其他領域術語的翻譯中,例如,將“Bonin Islands”(即日本的小笠原群島)直接音譯為“博寧群島”(谷歌、百度、騰訊)。
③ 縮略 語誤譯
一些軍事文本往往默認讀者了解常用縮略語的涵義而省去全稱,這對機器翻譯造成了很大的挑戰。如果機器在模型訓練過程中根本沒有接觸過這種縮略形式,那么它就不可能給出正確的翻譯,因為目前的神經機器翻譯系統的推斷能力非常弱,甚至可以說根本就不具備這種能力。例如,有關美軍的文本中經常出現的“C4ISR”是“Command Control Communication Computer Intelligence Surveillance Reconnaissance”的縮寫,即“指揮、控制、通信、計算機、情報及監視與偵察”,是美軍開發的一個自動化指揮控制系統。機器翻譯系統通常的做法是保留原縮略語形式不變,不作進一步翻譯,但有時也會出現丟失或者誤譯的情況。例如,將“A2/AD”(anti-access/area-denial)(反介入/區域拒止)中的“AD”誤譯為“廣告”(有道),令人啼笑皆非,這就需要在譯后編輯過程中多加注意。
④ 俗語誤譯
軍事文本中時常會出現對名人名言、兵書著作的引用,如果不借助于已經建好的雙語對齊的俗語庫,單純依靠“不求甚解”的直接翻譯,面對諸如諺 語、名言、歇后語等具有強烈歷史文化內涵的語句,機器自動翻譯系統可以說是“束手無策”。不過,由于在本次實驗的語料中并未出現此類語句,故而對這類錯誤的統計結果為0。
⑤ 漏詞
由于神經機器翻譯模型中缺乏“硬對齊”模塊,導致譯文中經常會出現漏譯,即“該翻譯的沒有翻譯”,最后造成意義的不完整。例如,“a global power with global interests”本應譯為“擁有全球利益的全球大國”,但是有系統卻將之翻譯為“全球大國全球利益”(有道),漏掉了表示修飾關系的引導詞“with”,從而產生了錯誤。值得注意的是,有時系統在單獨翻譯某一子句或者某一短語時,并不會發生漏譯的現象,但當將這一子句或者短語放到句子之中再進行翻譯時,就會有漏譯現象出現。
⑥ 多譯
這里的多譯包括兩種情況。第一種情況是指把“不該翻譯的給翻譯了”,例如“the Chinese PLA”翻譯成“中國人民解放軍”就可以了,有的系統卻會誤譯為“中國中國人民解放軍”(搜狗),將“中國”翻譯了兩次。第二種情況是指將句子中的某個詞語或者短語翻譯了至少兩次,例如,“…will almost certainly create downward pressure on both countries’ defense budgets”的意思為“幾乎肯定會對兩國的國防預算造成下行壓力”,有系統將“下行”翻譯了兩次,譯為“幾乎肯定會對兩國的國防預算造成下行下行壓力”(百度)。
⑦ 普通詞語誤譯
普通詞語誤譯也是經常出現的一類錯誤,這里的普通詞語是指軍事術語以外的詞語。例如,“play important enabling roles”中的“enabling”可以翻譯為“推動”或者“扶持”,而譯為“授權”(騰訊)顯然是不合適的。
(3)句子句 法錯誤
句子句法類錯誤主要表現在以下5 個方面。
① 斷句錯誤
對于超過一定長度的句子,神經機器翻譯系統可能會從中將其截斷,從而造成斷句錯誤。例如:
原文:The PLA’s ef forts are made all the more ef fective as the US defense program f inds the bulk of the most stealthy US strike aircraft will be relatively short-ranged lategeneration strike fighters carrying very small payloads of guided munitions, while US bombers, with their much greater payloads, are unlikely to be able to penetrate the PLA’s robust IADS systems without considerable risk of loss.
譯文:隨著美國國防計劃的實施,中國人民解放軍的努力變得更加有效,因為美國最隱秘的攻擊機大部分將是相對短程、攜帶非常小有效載荷制導彈藥的新一代攻擊機,而美國轟炸機的有效載荷更大,不太可能穿透中國人民解放軍。強大的IADS 系統,不會有相當大的損失風險。(騰訊)
原句共63 個英文單詞,譯文在“PLA’s”和“robust”之間進行了切分,把一個完整的子句分成了兩個句子,出現了斷句錯誤。造成這種錯誤的原因在于,當進行翻譯模型訓練時,出于加快訓練速度、減少資源消耗等因素的考慮,通常會將訓練語料的句長限制在一定范圍內,這就使得訓練出來的模型在面對過長句子的時候不具備相應的推斷能力,從而導致此類錯誤的產生。
② 層次結構錯誤
在未嵌入句法分析模塊的神經機器翻譯系統翻譯的譯文中,層級結構錯誤是一類常見的錯誤。例如:
原文:Their main operating bases, ports and facilities have been largely invulnerable to serious conventional attack since World War II.
其中的“since World War II”用于修飾全句,通常譯作“自二戰以來”并放在句首。有系統誤將其作為“attack”的修飾語,譯作“……嚴重的自二戰以來傳統的攻擊”(有道),顯得十分混亂,令人感覺不知所云。此外,該句中的“conventional attack”應譯為“常規攻擊”而非“傳統攻擊”。
③ 語序錯誤
盡管英漢兩種語言都是“SVO”結構,語序大體相同,但是二者在某些方面也存在差異。比如,漢語傾向于將修飾和補充成分前置,而英語中這些成分后置的情況則更為常見。如果在將英語翻譯成漢語時不調整語序,譯文讀起來就可能會顯得非常別扭。例如,“high-value Navy surface units, including carriers”通常譯作“包括航母在內的高價值水面部隊(或目標)”,但有系統卻將其譯作“高價值水面部隊,包括航母”(搜狗)。
④ 時態錯誤
英漢兩種語言采用不同的時態表現形式,純粹的神經機器翻譯系統并不含有時態分析生成模塊,這就給時態錯誤的產生帶來了可能。例如:
原文:This state of af fairs is almost certainly ending, with signif icant consequences for US security.
譯文:這種狀況幾乎肯定是結局,對于美國的安全產生了重要影響。(有道)
機器翻譯把原本的將來時誤譯成了過去時,出現了明顯的時態錯誤。
(4)語義錯誤
語義錯誤多集中在以下兩個方面:邏輯關系混亂和指代不清。
① 邏輯關系混亂
原文:This is the key to maintaining the stable military balance that has preserved the peace in the Western Pacif ic.
這句話的意思是:“這是保持軍事態勢平衡的關鍵,正是這一態勢維持了西太平洋地區的和平。”有些系統把“maintaining the stable military balance”(保持軍事態勢平衡)與“preserved the peace in the Western Pacif ic”(維持西太平洋地區和平)相并列,從而造成整句邏輯關系錯誤,如有道就將其譯為“這是維護穩定的軍事平衡的關鍵,保存在西太平洋地區的和平”。
②指代不清
指代不清是指譯文中的指示代詞所指對象不明,導致意義含混。例如:
原文:Consequently, the United States confronts a strategic choice: either accept this ongoing negative shift in the military balance, or explore options for of fsetting it.
譯文:因此,美國面臨一個戰略選擇:要么接受這種軍事平衡持續地向負面轉變,要么探索抵消它的方法。(谷歌)
這句話原文的最后一個單詞“it”本應指代“ongoing negative shift”,如果將其簡單地翻譯為“它”,就會造成指代不清。谷歌的譯文中就存在這種錯誤,最后一個短句中的“它”讀起來甚至更像是在指代“軍事平衡”。
四、提升軍事文本英譯 漢譯后編輯效率的建議
基于以上研究統計結果與分析,針對當前神經機器翻譯系統對軍事文本英譯漢翻譯質量與效果不佳的情況,筆者提出如下4 項建議,以期提升該領域英譯漢譯后編輯的效率。
1. 通過構建術語庫增加術語翻譯的準確性和一致性
上文統計顯示,術語誤譯占全部神經機器翻譯錯 誤的四成以上。經過分析不難看出,大部分出現誤譯的詞語都是一詞多義,在通用文本中大多使用的是普通義,而在軍事文本中則多作為術語出現。由于本研究選用的神經機器翻譯模型都是采用大規模通用語料進行的訓練,自然就難以譯出術語義,這也在一定程度上造成了神經機器翻譯系統可移植性差的問題。軍事文本專業性強、術語眾多,如能較好地解決術語翻譯問題,軍事文本譯文質量必將得到大幅提升。
目前,“機器翻譯+譯前/譯后編輯”的基本工作流程大致可分為以下幾個階段:原文預處理、構建術語庫、機器翻譯、譯后編輯和定稿校對。其中,構建術語庫通常采用術語自動提取和人工提取相結合、提取后再進行人工翻譯的方式進行。一個高質量的術語庫既可以用于機器翻譯,也可以用于譯后編輯。這樣看來,構建和維護一個較大規模的軍事術語庫就顯得十分必要了。尤其在譯后編輯階段,利用軍事術語庫能夠對譯文進行批量修改,不僅提升了編輯效率,而且還能保證譯文的統一性。
2. 充分利用語法檢查工具快速定位漏譯、多譯及斷句錯誤問題
斷句錯誤在各種類型的神經機器翻譯系統中都會或多或少地存在,此類錯誤產生的主要原因是,目前神經機器翻譯系統在對長句的處理方面還存在很多困難,一旦句子長度超過50 個單詞,系統性能便會開始急劇下降。因此,在訓練神經機器翻譯模型時,通常會將訓練語料文本的句長限定在一定范圍之內。面對過長的、超出處理范圍的語句,神經機器翻譯系統會依據一定的條件進行斷句處理,這時就有可能引發斷句錯誤。此外,由于神經機器翻譯架構自身缺少“硬對齊”,漏譯、多譯問題也時有發生。這3 類錯誤一旦出現,往往會導致整句譯文不符合語法規則。但是,這3 類錯誤的出現一般缺乏規律性,因而難以預測。在這種情況下,若能有效地利用語法檢查工具,如Microsoft Word中的“拼寫與語法”模塊就可以快速地定位此類錯誤,再通過譯后人工編輯對其進行修訂。
不過,神經機器翻譯系統譯文的流利度較好,有時即使多一個詞或者少一個詞都不會影響整句的可讀性,漏譯更是如此。因此,對于語法檢查工具未能發現的錯誤,就需 要與原文進行仔細比對,切不可遺失關鍵信息。
3. 開發符合實際需求的譯后編輯工具
工具能夠給人類帶來效率的提升,翻譯工作也是如此。一個優質的譯后編輯工具應該可以快速實現句對齊、術語智能提示、語法錯誤自動標記等功能,還能夠方便地進行保存和導出,并且具備可擴展性。在此基礎上還可開發具備自主學習功能的模塊,當用戶將某一規則以特定的形式輸入編輯工具后,學習模塊在遇到類似的問題時能夠實現自動處理。目前,軍事翻譯需求量巨大,如果專業譯員能夠同技術人員一起合作開發符合軍事翻譯特點和需求的譯后編輯工具,必然能夠助力軍事翻譯工作效率與質量的提升。
4. 設計研發軍事領域英漢智能神經機器翻譯系統
神經機器翻譯模型的優劣直接決定譯后編輯的難易程度,高質量的神經機器翻譯系統能夠減少譯后編輯中重復性的簡單勞動,提高譯后編輯的效率。盡管神經機器翻譯已經給人類帶來了許多驚喜,然而從上文的研究結果不難看出,目前市面上主流的神經機器翻譯系統在處理軍事文本時還不能令人滿意,亟需設計開發專門用于軍事領域的神經機器翻譯系統。從神經機器翻譯發展的現實情況來看,人機結合的翻譯策略是目前的主流翻譯方式,單純地依靠機器并不可行,機器完全取代人類也不能一蹴而就。因而,在設計開發軍事領域英漢神經機器翻譯系統時要突出“智能化”,構想中的這一智能翻譯系統應是“機器翻譯(machine translation,MT)+計算機輔助翻譯(computer aided translation,CAT)”的綜合平臺。其中,MT 部分是專為軍事領域研發的機器翻譯引擎,甚至可以是多引擎融合式的,能夠輸出若干翻譯結果供使用者選擇;而CAT 部分則涵蓋專門的軍語辭典、軍事術語庫、雙語實例庫、翻譯記憶庫等模塊,具備增、刪、查、改等常用功能,滿足用戶的通用型及個性化需求。
結語
從本文的研究結果來看,與通用語料的翻譯質量相比,目前國內外主流神經機器翻譯系統在軍事文本的英漢翻譯方面表現仍不盡如人意。與通用語料翻譯相比,神經機器翻譯系統對軍事文本譯文的BLEU 值平均低了6.62;從錯誤類型占比來看,軍事術語誤譯、普通詞語誤譯和層級結構錯誤位居前三位,超過錯誤總數的63.64%。據此,筆者認為目前現有的神經機器翻譯系統還不能實現高質量的軍事文本翻譯,無法滿足現實需求,“機器翻譯+譯后編輯”的人機協同應該成為軍事翻譯的主要工作模式。在此基礎上,筆者建議應當重視術語庫在譯后編輯中的作用,充分利用語法檢查、雙語對齊、術語提示等工具提高譯后編輯的效率,開發出真正能夠滿足實際需求的譯后編輯工具,并積極設計研發軍事領域英漢智能神經機器翻譯系統等,以不斷提高軍事翻譯工作的效率與質量,滿足日益增長的軍事翻譯需求。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
甘肅教育(2020年8期)2020-06-11 06:10:02
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:48:08
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
電子制作(2018年18期)2018-11-14 01:48:06
家庭影院技術(2017年9期)2017-09-26 03:41:45
小學教學參考(2015年20期)2016-01-15 08:44:38
