基于計算機智能的英語譯文語境化自動校準系統
2021-12-09 06:37:48王小遷
微型電腦應用 2021年11期
王小遷
(陜西藝術職業學院 基礎教學部, 陜西 西安 710054)
0 引言
現有的英語翻譯軟件通過一定的算法對單詞的詞義進行廣義的搜索,而大多計算機譯文校準系統僅注重單詞和短句語法是否翻譯正確,欠缺對具體語境的考慮[1]。為此,本文提出了一種基于計算機智能的英語譯文語境化自動校準系統,通過各功能模塊進行詞義搜索、用戶行為分析并結合局部語境進行單詞調整。該系統的研發大幅提高了英語譯文的整體準確性和通暢度,適于在英語翻譯領域推廣應用。
1 總體架構
英語譯文語境化自動校準系統共由6個部分組成,即工作模塊、翻譯模塊、譯文校準模塊、用戶模塊、搜索模塊和行為日志,其總體架構如圖1所示。
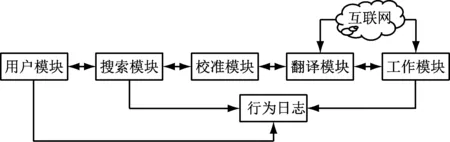
圖1 系統總體架構示意圖
系統的自動校準功能是通過對英語原文的再翻譯實現的,再翻譯的內容由系統從互聯網中獲取并儲存于工作模塊中,將得到的新譯文與待校準譯文進行對比,結合文章的語境信息找出錯誤的詞匯并以正確的詞匯將其替代,從而完成文章的自動校準[2]。行為日志用以記錄各功能模塊在工作時所產生的各種數據,用以控制譯文校準過程中出現的錯誤,保證校準結果的準確性。工作模塊負責系統與用戶的交互,接收來自用戶的操作指令并向下傳遞,翻譯模塊根據上下文語境對待校準譯文中的詞匯進行檢驗,基于詞義的相似度對得到的選項進行排序,從而決定是否需要替換,用戶模塊中存儲了待選詞匯及其排序結果供用戶進行查詢。
2 系統設計及算法實現
2.1 系統設計
搜索模塊用于詞匯特征的提取與分析,系統工作過程中該模塊對詞匯在各個領域和各種環境下的基本含義進行搜索,模擬人類大腦記憶存儲的方式不斷地更新和優化詞匯特征,為后續的譯文校準建立足夠豐富的知識庫。用戶發出操作指令后,為了得到詞匯在特定語境下的不同含義,搜索模塊構建出一種映射線程以完成搜索任務。該線程采取了多映射點的模式,所有的映射點均為不同特定環境下待校準詞匯的具體含義。搜索模塊的工作保證了所有含義相近的詞匯全部出現在待選范圍之內,很大程度上避免了用戶的部分錯誤表達所造成的搜索到無關結果的現象。
在系統運行的過程中,行為日志負責監聽用戶的行為并將其全部以數據的形式進行保存。用戶執行譯文校準時,行為日志會記錄整個校準過程中發生的事件。若用戶多次對同一篇文章進行校準,則系統將自動擴大詞匯的搜素范圍,從而獲取更多的待選詞匯以實現更為精準的表達,實現校準結果準確性的進一步提高。
英語原文的翻譯和譯文的校準本質上都是兩種不同形式文本之間的轉換,譯文校準實際上就是一個再翻譯的過程,將校準結果與翻譯結果進行比較和詞匯替換以獲得表達更為準確的英語譯文。
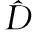
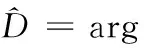
(1)
其中,M(D)代表已完成初步校準的詞匯。由于初始翻譯結果僅注重單個詞匯的翻譯準確性,所以必須通過自動校準的方式對式(1)進行優化,以獲得符合文章意境的譯文,具體的優化方法[4]為式(2)。
(2)
其中,ε、γ分別為M(H|D)和M(D)各自權重的數值。
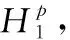
(3)
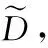
2.2 算法實現
在系統軟件部分的設計中,利用改進后的短語翻譯模型進行譯文自動校準的實現代碼如下。
Start
Terms Form=NEW semanticsblurry;
//初始化待校準譯文
ashy relevance=NEW semantics theme
//初始化待校準詞匯權重
Vocabulary=Englishtranslation(Vocabulary Form)
//匯總詞匯在各種環境下的含義
Simultaneously(phrasal language envimoment Is Not Empty.){
IF(Vocabularysemanticsblurry best){
Vocabulary=folds cooperate(phrasal message);
//無法在初始譯文中找到,更改權值在所有詞義中搜索
Otherwise Crunode=phrasal message(Scientific);
//對初始譯文進行對比分析
Analog=assort compute(Vocabulary, Crunode);
//計算詞匯語義相似度
Analog_Form. Place(Lauygdbgf Of (Sfgr));
//根據排序結果搜索與待校準詞匯相似度最高且符合語境的詞匯
Vocabulary, freesurface (If (simregrfist). Nbtjuke);
//歸納分詞
END}}
3 實驗驗證
3.1 系統功能驗證
為了對所提出的譯文自動校準系統功能的可實現性和有效性進行驗證,針對本系統開展英語引文校準實驗,從某短文數據庫中隨機選取篇幅為400個詞匯的英語短文及其首次翻譯譯文500篇[6],通過本系統對初始譯文進行校準,系統單個詞匯的平均校準速度為25 KB/s,短文平均校準速度為15 KB/s,將經過本系統校準的譯文準確度與首次翻譯譯文的準確度進行對比(譯文標準答案,即準確度,由專家評判獲得),具體結果如圖2所示。
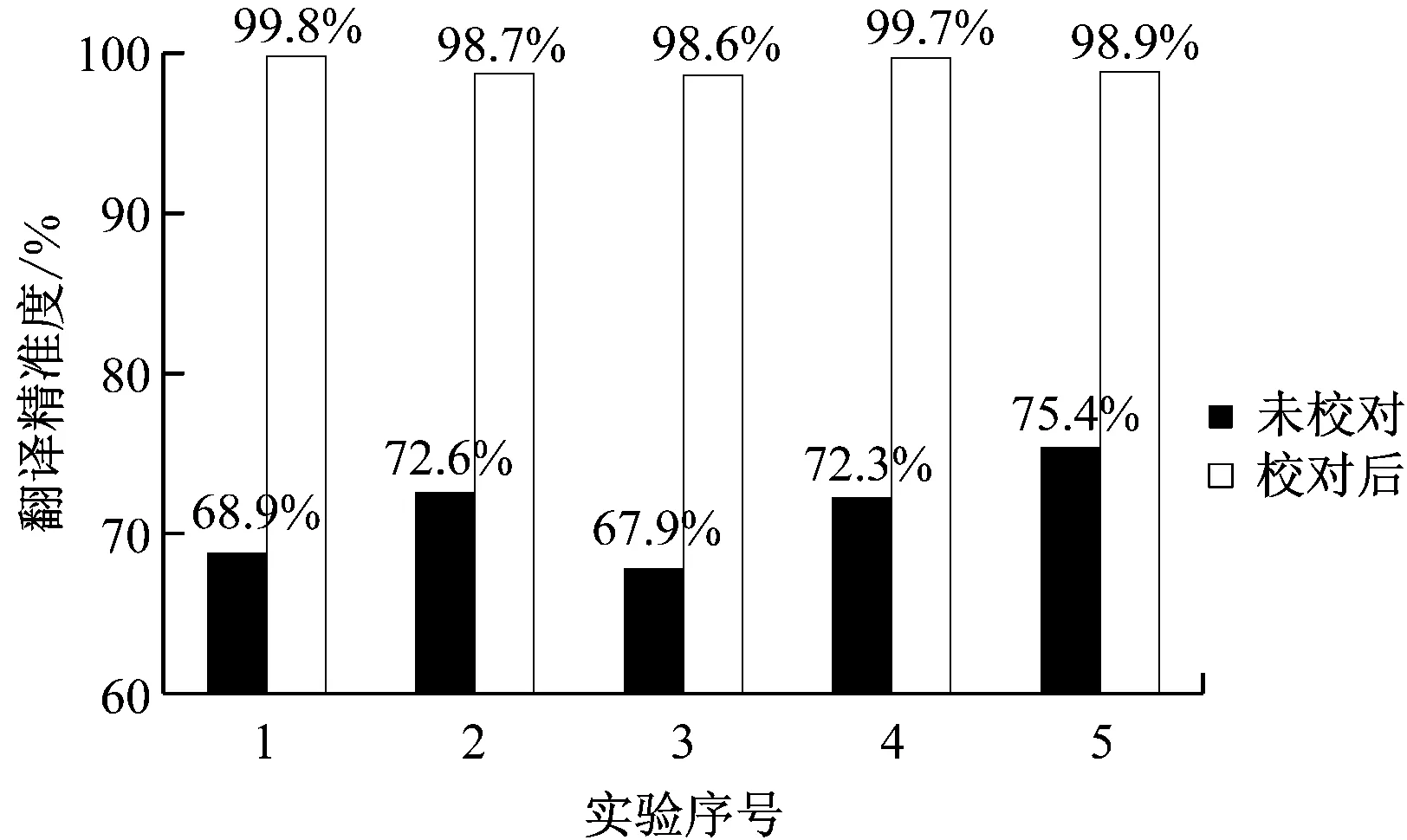
圖2 經本系統校準前后譯文的準確度對比
由圖2中的數據可見,經本文所提出的自動校準系統校準后,譯文的平均精確度明顯提升。經過統計可知,本文系統翻譯精準度均值為99.1%,相較于首次翻譯譯文的平均精確度71.4%提高了27.7%,極大地改善了譯文描述的準確性,從而證明了本文所提出系統的功能有效性。
3.2 校準節點密集度對比
英語譯文節控點位的分布情況能夠表征翻譯后的詞匯語義與文章語境的關聯程度,節控點密集度越高,譯文的詞義表達越準確,與語境的貼合程度越高且文章越為通順。為了進一步驗證本文所提出的語境化自動校準系統所具有的性能優勢,選擇一種傳統的、注重詞匯和語法的校準系統進行性能對比。在譯文校準實驗過程中分別記錄兩種系統的節控點數量并分析其各自的節控點分布情況,具體結果分別如圖3、圖4所示。
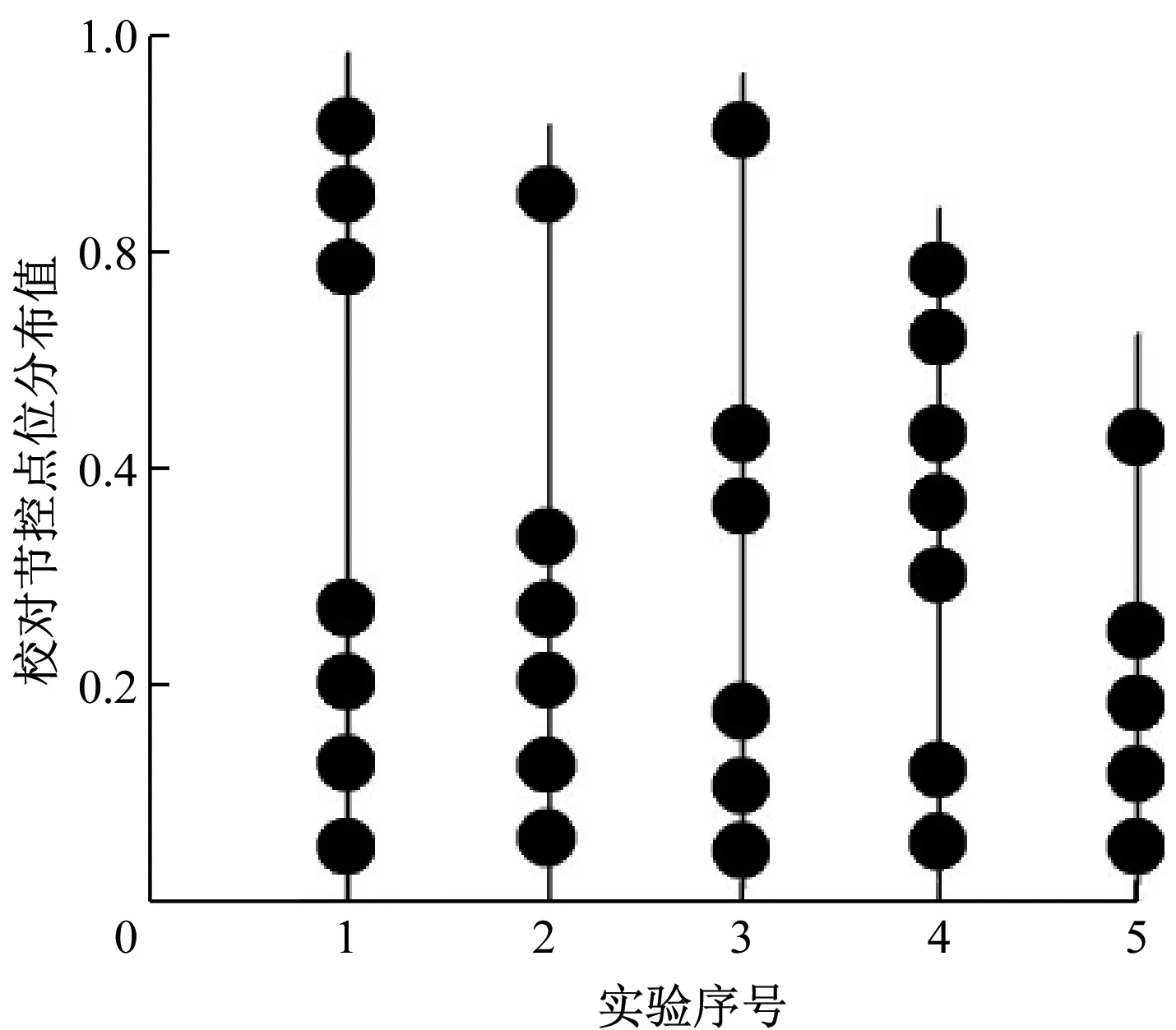
圖3 語境化自動校準系統節控點分布
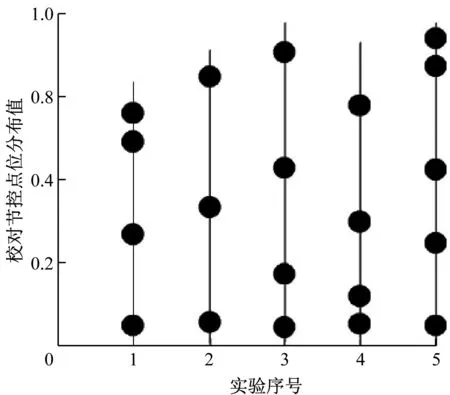
圖4 傳統自動校準系統節控點分布
由圖3可見,本文提出的語境化自動校準系統節控點分布密集而有序,一方面說明系統輸出的校準譯文準確性較高,另一方面則說明譯文中的詞匯與語境相符且文章整體較為通順;反觀圖4中傳統校準系統的節控點情況,雖然在部分實驗中節控點分布較為緊湊,一定程度上保證了詞匯表達的準確度,但在詞匯與語境的貼合度方面存在較大缺陷,從而影響了譯文整體的通順性和準確性。
4 總結
由于過于注重詞匯與語法的表達準確性,忽略了詞匯在不同語境中詞義的差異,傳統英語譯文自動校準系統的校準效果并不理想。為此,提出并設計了一種基于計算機智能的英語譯文語境化自動校準系統,利用行為日志分析用戶行為,基于改進后的短語翻譯模型進行英語原文的再翻譯,獲取符合文章語境的新譯文,將其與初始譯文進行對比并替換其中不符合語境的詞匯,從而獲得準確性更高的譯文。本系統在開發過程中得到了陜西藝術職業學院計算機系教師的幫助,尤其是系統結構、模塊程序編程、系統調試等方面,計算機系教師給予了莫大支持,在此鳴謝。目前,該系統在陜西藝術職業學院得到了應用,效果顯著。特別聲明,該系統產權歸陜西藝術職業學院所有。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
北京測繪(2020年12期)2020-12-29 01:33:58
山東醫藥(2020年34期)2020-12-09 01:22:24
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
家庭影院技術(2017年9期)2017-09-26 03:41:45
小學生導刊(低年級)(2016年2期)2016-02-24 23:02:11
小天使·五年級語數英綜合(2014年5期)2014-06-25 05:22:42
中華胰腺病雜志(2012年3期)2012-11-07 05:18:45
