一種面向業務過程的剩余時間預測算法
2021-12-09 07:00:56劉云峰高俊濤
微型電腦應用 2021年11期
劉云峰, 高俊濤
(東北石油大學 計算機與信息技術學院, 黑龍江 大慶 163318)
0 引言
業務過程管理是管理、分析、控制和改進企業產生經營過程的系統化與結構化方法,幫助企業提升管理體系的關鍵。越來越多的企業開始建立自己的業務過程模型、運行和部署過程模型,并通過對運行流程的檢測以及歷史數據的分析來逐步優化企業流程。業務過程評價的重要指標是時間,剩余時間預測是業務過程的一項核心任務。研究及時準確的剩余時間預測方法不僅可以幫助企業調整生產計劃和服務流程,還有助于緩解用戶因長時間的等待而產生的焦慮。
1 研究現狀
流程監控的對象主要包括流程的周轉時間、資源占用情況、成本開銷等流程性能指標。預測方法可以歸結為分析型方法和比較型方法兩類。
典型的分析型預測方法包括Rogge-Solti于2015年提出基于隨機Petri網的預測方法[1]和Dumas于2017年提出的基于流分析(Flow Analysis)技術的預測方法[2]。
比較型預測方法包括SVM[3]、決策樹[4]和聚類[5]在內的多種數據挖掘模型和算法分析影響監控指標的企業流程因素和外部環境因素。2011年,Wil van der Aalst等[6]提出了基于變遷系統的剩余時間預測方法,該方法用變遷系統描述事件日志中流程實例的所有可能狀態,并在狀態上標記時間信息,以便根據當前流程實例所處的狀態預測其剩余執行時間。
除了采用傳統數據挖掘方法進行類比預測外,將深度學習技術應用于業務流程預測也是近年來流程管理領域一個新涌現的研究熱點[7]。
本文在前人研究的基礎上,以數據純度作為重點,提出一種基于模型數據純度高低選擇合適預測模型的剩余時間預測方法。該方法采用搜尋歷史相似數據的方式,適用于現在主流的XES和CSV格式事件日志。
2 基本概念
2.1 算法基礎概念
業務過程實例的剩余時間預測需要先從歷史事件日志中獲取時間戳及相關信息。為了敘述方便,首先對業務過程的相關概念進行定義。
定義1(軌跡) 軌跡是一種有限非空線性集合,即σ∈ε*。在任意一個軌跡中,每個事件只發生一次并且時間是非遞減的。
定義2(事件日志) 一個事件日志L={σ1,σ2,…}是多條日志軌跡的集合,每個事件在整個日志中最多只出現一次。
定義3(變遷系統) 變遷系統是一個三元組TS=(S,E,T),其中S為狀態集合;E為活動集合;T∈S×E×S為轉移集合。
傳統TS預測方法采用帶時間標注的變遷系統預測業務過程的剩余時間。其方法采用序列、集合、多重集中某一種抽象機制構建預測模型,并根據模型預測剩余時間。如果構建預測模型的抽象機制發生了變化,剩余時間的預測結果可能不一樣。事件日志片段案例如表1所示。

表1 事件日志片段
對表1所示的事件日志片段,采用序列和集合抽象分別得到2個模型,如圖1所示。
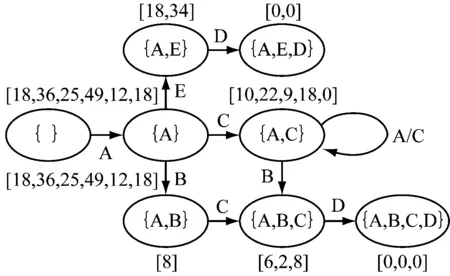
(b) 基于set抽象的變遷系統
以軌跡前綴〈A,C,B〉為例,采用序列抽象的剩余時間預測值為7,采用集合抽象的預測值為5.3。因此序列抽象預測結果的MAE為1,集合抽象預測結果的MAE為1.7。
定義4(預測模型) 本文在TS預測方法的基礎上,將原來只包含單一抽象機制的變遷系統擴展為包含3種抽象機制的復合變遷系統。預測模型M是一個集合,其元素為三元組(C,E,V)。其中,C為預測狀態編碼;E為剩余時間觀察值的均值;V為觀察值的標準差。
3 基于數據純度的預測算法
本節在預測模型M的基礎上,介紹在實際企業業務過程的部分軌跡已知的情況下,對其剩余時間進行預測的算法。算法1描述了在輸入部分已知軌跡θ和模型M的情況下,根據觀察值的標準差V進行選擇,返回預測值的過程。

算法1 基于數據純度的剩余時間預測算法輸入:預測模型M,前綴軌跡θ輸出:剩余時間預測值^tFunction Predict(M,θ)1. l=len(θ)2. maxpur f=0 //最大純度3. while (l>0)4. Foreach abs in {hdl(θ),bag(hdl(θ)),set(hdl(θ))}5. Foreach m in {m∈M|mcode=abs}6. If pur f(m)>maxpur f7. ^t←mE-(e|θ|-el)8. return ^tEndFunction
3.1 狀態選擇
傳統TS方法每次預測只能使用一種抽象機制,而且在實際業務過程中需要根據人工經驗來判斷選擇哪種抽象機制,這與智能制造的宗旨不符。因此,本文將實際業務過程中的部分已知軌跡θ在預測模型M中根據歷史相似數據進行匹配,記錄下每個匹配成功的結果作為備選預測值。然后我們假設樣本數據純度越高,樣本預測值可能越接近真實值,在這種假設情況下通過式(1)純度函數purf:State→Pre評價每一個預測值的純度,基于純度高低智能選擇純度最高的預測值作為最終預測值,如式(1)。
purf(s)=-sV
(1)
為了計算方便,式(1)采用樣本的標準差作為數據純度的反向指標。
4 實驗設計與分析
回歸任務的主要誤差評估標準是平均絕對誤差(MAE)和均方根誤差(RMSE)。由于事件之間的時間差值往往變化很大,大多在不同的數量級上,并且由于RMSE對異常數據點的錯誤非常敏感,所以我們使用MAE對誤差進行評估。
本文實驗采用真實業務過程的公開事件日志數據集,它們均可以在4TU Center for Research Data下載。日志的具體統計信息如表2所示。
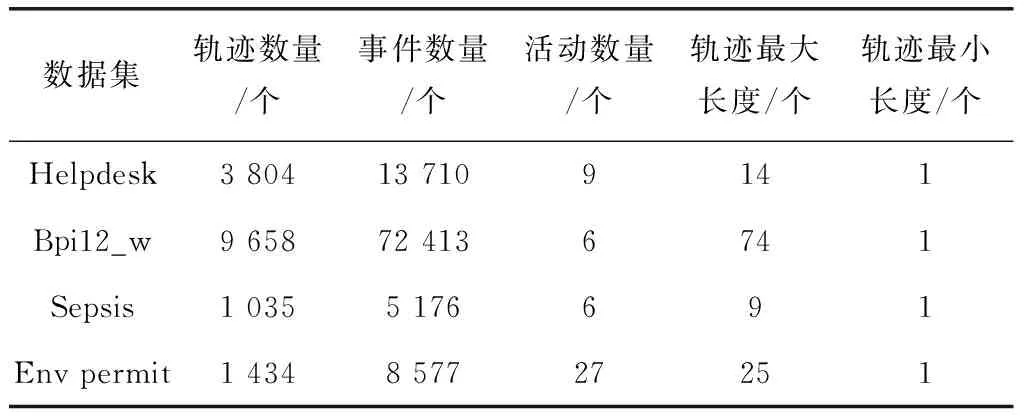
表2 事件日志的統計信息
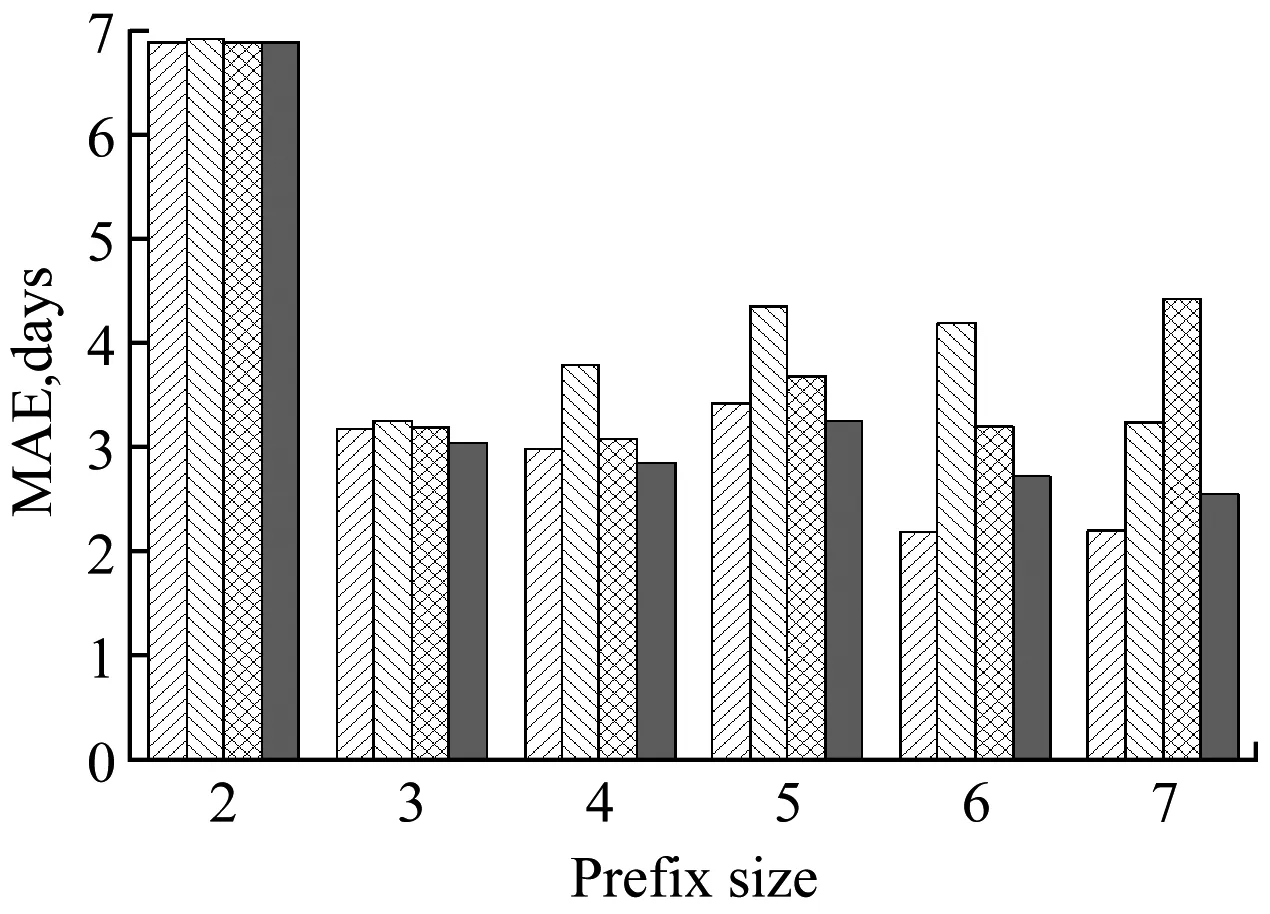
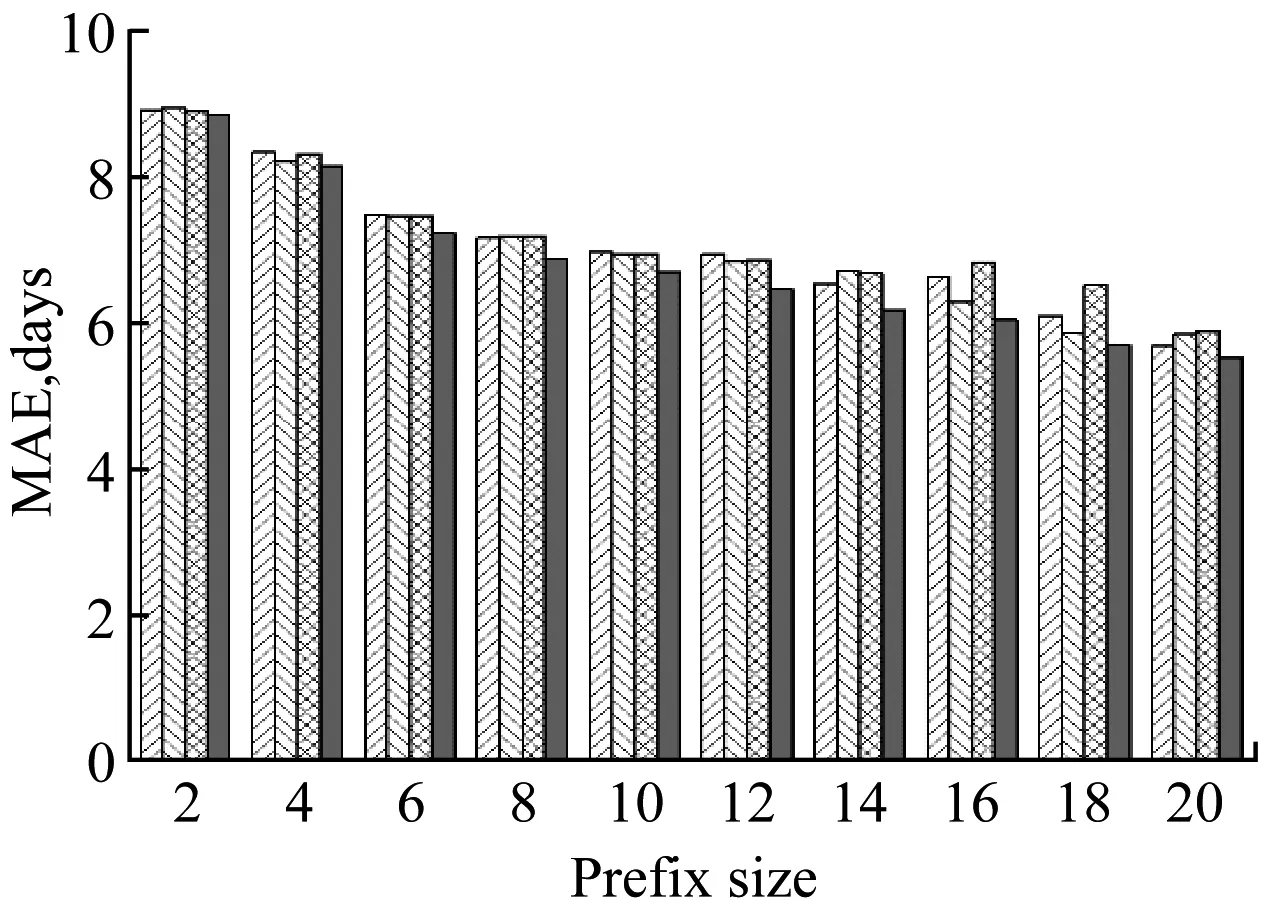
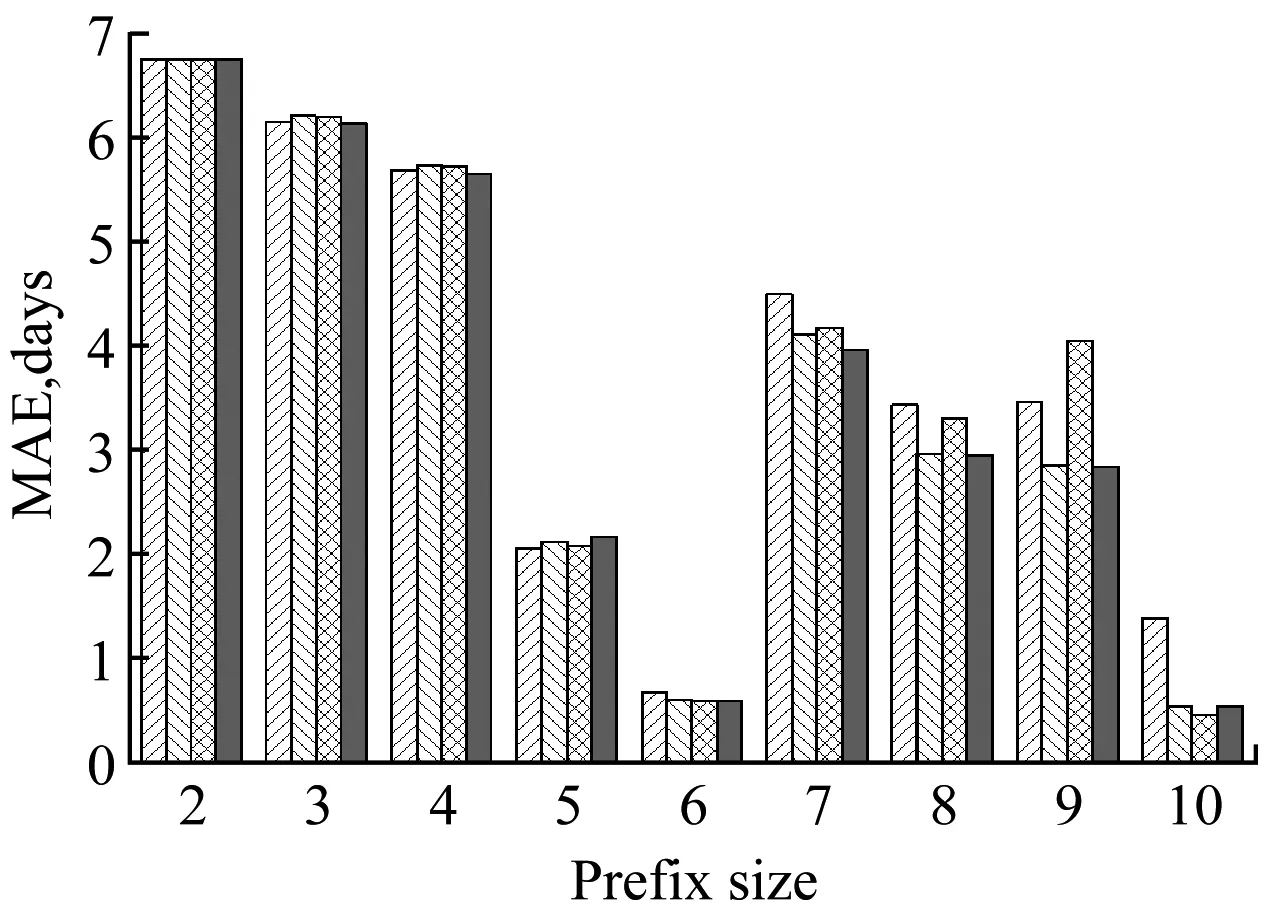
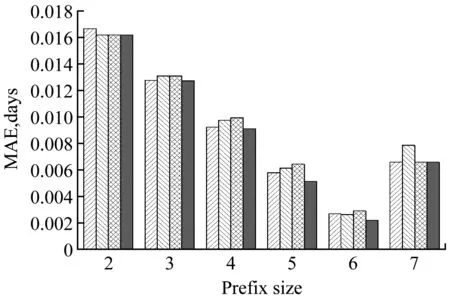
我們將實驗日志切分為2部分,第1部分包括前2/3的軌跡,作為訓練集;剩余1/3軌跡作為第2部分測試集。我們從大小為1的軌跡前綴開始,預測并評估每個通過事件的剩余時間。本文將傳統TS方法作為基準方法進行對比,對比結果如圖2所示。
Helpdesk
(a)
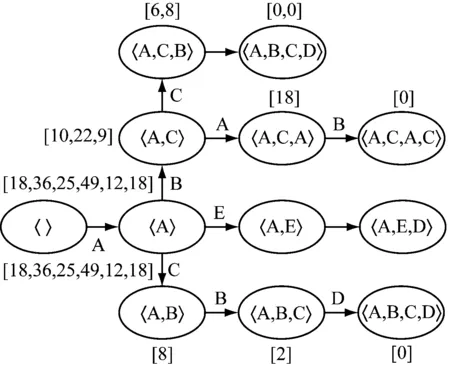
(a) 基于sequence抽象的變遷系統
Bpi12_w
Environment permit
Sepsis
圖2顯示了本文的純度方法與傳統TS方法在不同前綴長度上的平均絕對誤差(MAE)。從圖中可以看出,本文的純度方法在絕大多數情況下要優于傳統TS方法。在實際業務過程中,本文方法可以代替人工選擇,自動的選擇數據純度最高的抽象機制進行剩余時間預測。并且在業務過程運行的中后期,基于數據純度的預測方法候選空間變大,預測精度明顯提高。
5 總結
本文提出了一種基于復合變遷系統的業務過程剩余時間預測方法,改變了傳統預測方法每次預測只能使用單一抽象機制的預測方式。融合了多種抽象機制,基于觀測值的數據純度智能選擇最優抽象機制進行剩余時間預測。在4個公開事件日志上進行了實驗,結果顯示該方法在可解釋性、預測準確率方面具有一定優勢。目前,該方法只基于觀測值的純度進行抽象選擇,結合觀測值的樣本規模或增加感受野抽象機制,有望進一步提高預測的準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
