基于數據挖掘算法的漢英機器翻譯二元語義模式規則
2021-12-09 06:37:44呂洋張靜華芳
微型電腦應用 2021年11期
呂洋, 張靜, 華芳
(西北大學 現代學院基礎部, 陜西 西安 710000)
0 引言
語言是人類進行溝通的基礎,尤其是隨著國際化發展程度越來越高,不同國家之間的往來越來越頻繁,不同語言之間的翻譯也變得愈加重要。在國際化發展迅速的今日,單純依靠人工翻譯已經不能滿足人們日常溝通、閱讀的需求,因此機器翻譯應運而生[1-5]。近年來,隨著國內外研究學者對機器翻譯系統的開發和改進,機器翻譯已經在各個領域中都出現了廣泛的應用。
然而,機器翻譯的質量還不能夠滿足特殊領域的需求。例如對于某些學術論文、文學作品中的專有詞匯的翻譯準確度還較低,因此機器翻譯系統的語言分析和處理技術還有待進一步發展。若要提升機器翻譯的質量,消除詞語的歧義是首要任務[6-10]。通常一個詞語具有多種詞義,這種歧義稱為詞匯歧義。而詞語在與其他詞匯構成短語時,受到固定搭配,通過短語構造的句法語義規律可以消除這一歧義;除了詞匯歧義外,自然語言中還存在著結構歧義,是同形短語產生的歧義,通常需要從語義關系和句法結構方面進行消除。
語義規則是一種常用于剔除歧義的規則,對于外顯型歧義除了可以運用上下文的句法關系進行歧義剔除,還可以直接利用語義知識進行語法分析來排除歧義;對于內含型歧義,無法通過句法關系進行歧義剔除,只能依靠語義知識進行歧義剔除[11-12]。本文設計了一種基于數據挖掘的二元語義算法,發掘詞語組合的語義規律并轉換成二元語義規則集。將二元語義規則模式與句法分析規則進行結合后,應用于機器翻譯的歧義消除中,并對其應用效果進行了評價。
1 優化系統的整體架構
本系統是基于XMMT英漢機譯系統進行優化,對其排歧方面的不足進行了改進。原系統所采用的排歧方法是“優化”和“約束”相結合的方法,但“約束”方法的研究深度不夠。由于語義知識不足和算法誤差,導致了“約束”排歧的效果不理想,而且對“優化”排歧的效果也造成誤導。
原系統排歧效果不理想的根本原因是語義知識不全面,因此本系統外掛了一個語義模式規則獲取模塊。優化后系統漢英機器翻譯工作流程如圖1所示。
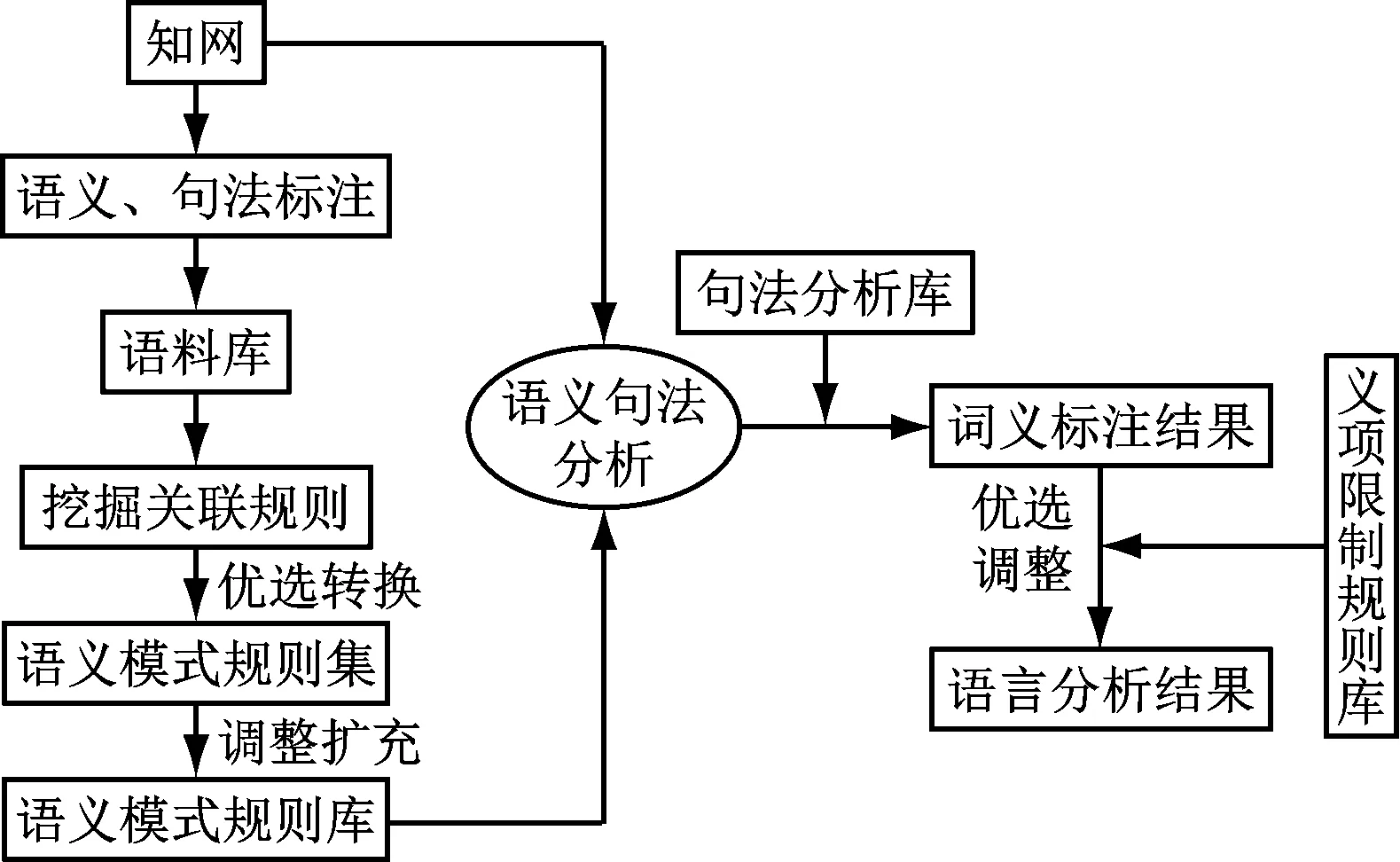
圖1 優化后系統漢英機器翻譯工作流程
該系統首先基于知網語料庫進行語義和句法的標注,然后獲得熟語料庫。運用數據挖掘方法來發掘語料庫中詞語組合的規律,并基于“統計”方法將語義規律轉換為二元語義模式規則集;進一步通過人工調整和擴充,得到最終排歧所需的二元語義模式規則庫。本系統在基于所建立的二元語義模式規則庫和知網語料庫的基礎上對語義和句法進行分析,通過外掛句法分析庫進行詞義標注,通過一個外掛的二元語義模式規則庫對語言進行優化和調整,最終得到語言分析結果。
2 二元語義模式規則的獲取
本系統二元語義模式規則獲取分為2個步驟,分別為發現子目標模式和由子目標模式獲取二元語義模式規則集。
子目標模式發現算法如圖2所示。
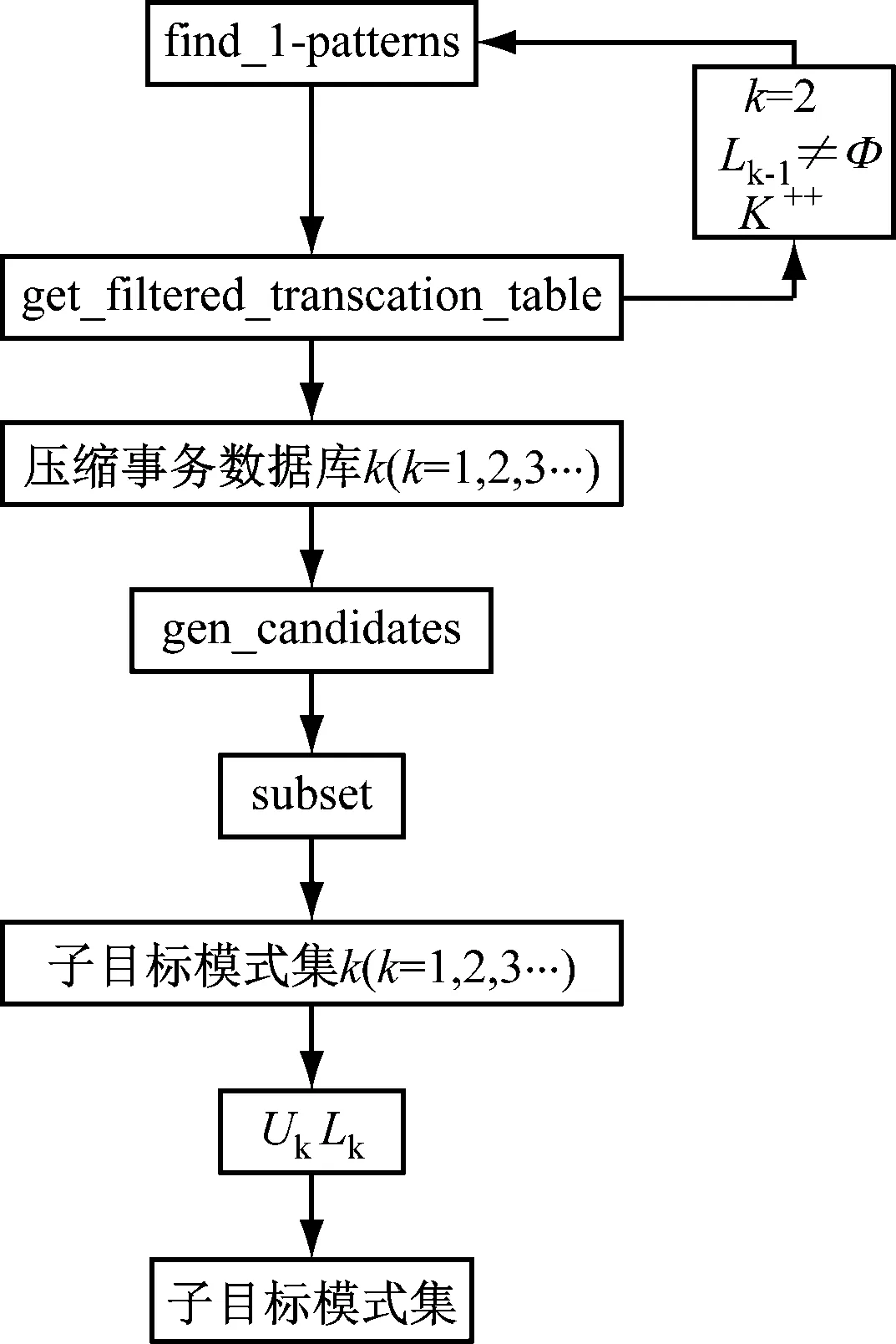
圖2 子目標模式發現算法
首先,利用Find算法逐層對各個層次上的子目標進行尋找。然后利用get_filtered方法刪除不包含子目標模式的項和事務,得到壓縮事務數據庫并循環進行下一個子目標的尋找。接著利用gen_candidates算法產生候選模式集,利用候選模式集掃描壓縮事務數據庫,利用Subset方法找到壓縮事務數據庫中所有的候選并計數和刪除壓縮事務數據庫中不被候選模式集包含的項和事務,然后得到該子目標的子目標模式集。最后,將所有子目標模式集匯總,便得到最終的子目標模式集。
通過關聯規則挖掘,可以由子目標模式獲取二元語義模式規則集。根據所有子目標的支持度和近似度,基于最小值置信度規則和元規則,剔除冗余規則,得到二元語義模式規則的優選算法,將子目標模式轉換為二元語義模式規則集。本文所利用的二元語義模式規則的優選算法如圖3所示。
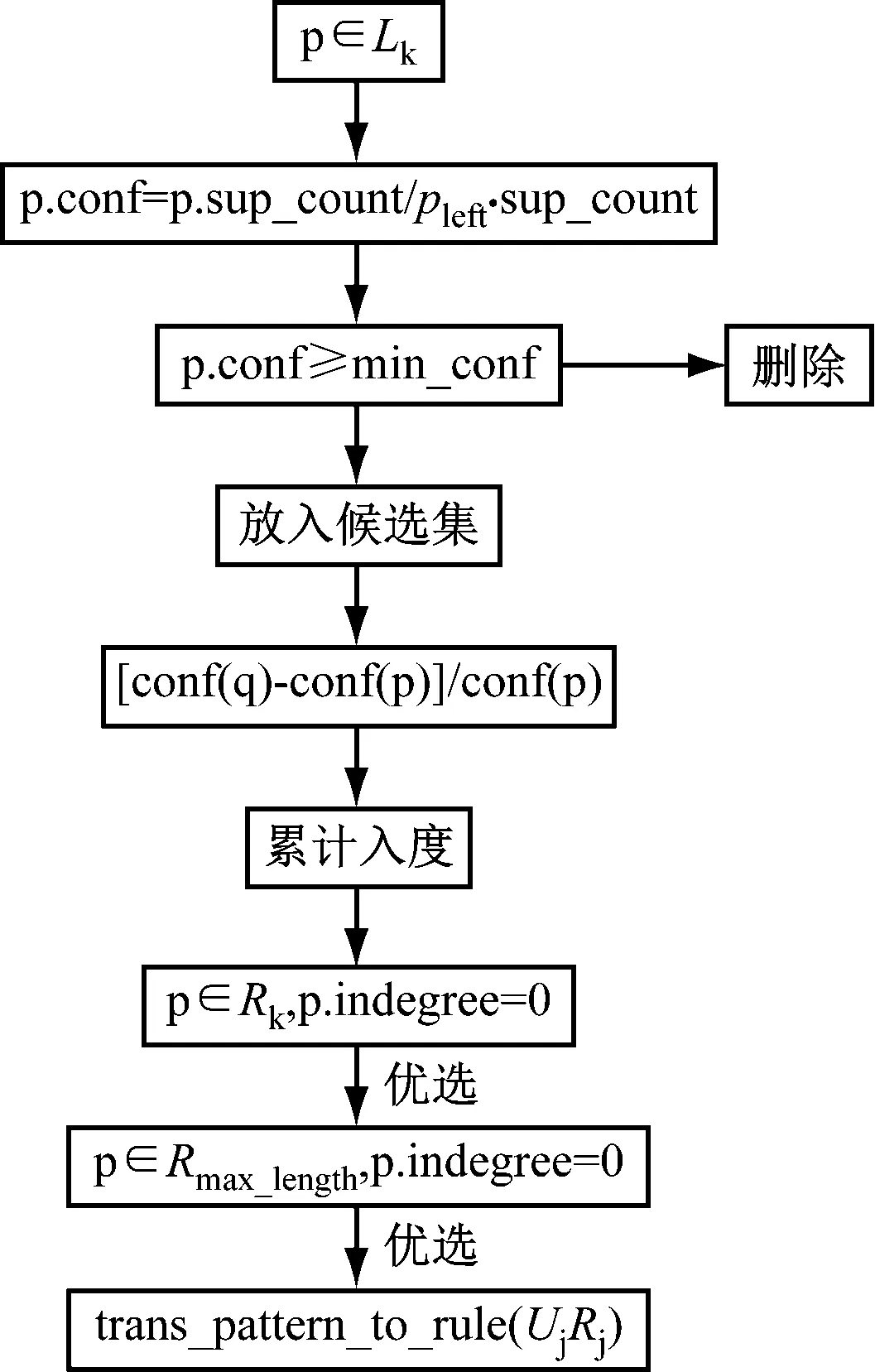
圖3 二元語義模式規則的優選算法
首先,基于元規則從子目標模式集中篩選出目標模式,計算目標模式的置信度,將不滿足最小置信度的模式從中剔除,得到了候選二元語義模式規則集;接著掃描候選二元語義模式規則集,機選其覆蓋關系的入度,將所有入度為0的候選二元語義模式規則集篩選出來,得到最終的二元語義模式規則集。
3 基于二元語義規則的語義排歧
前文介紹本系統是基于XMMT系統進行優化后的二元語義模式規則排歧,其排歧規則與XMMT系統類似。傳統XMMT系統排歧是由兩部分組成,CFG產生式和偽等式,分別是描述短語、句子的組成模式和約束條件、分析結果的構造過程。只要是合理的LISP表達式,均可以出現在偽等式中,所以可以將語義評價函數加入到原有的句法分子規則中。優化后的排歧規則是將二元語義模式庫中的規則與語義組合進行匹配,將不合語義項、組合、句法排除,然后將所有可能的組合保存為中間結果并評分,經進一步分析得到最終排歧結果。本系統所嵌入的語義評價函數為Semantic Value函數,進行語義評價的算法如圖4所示。
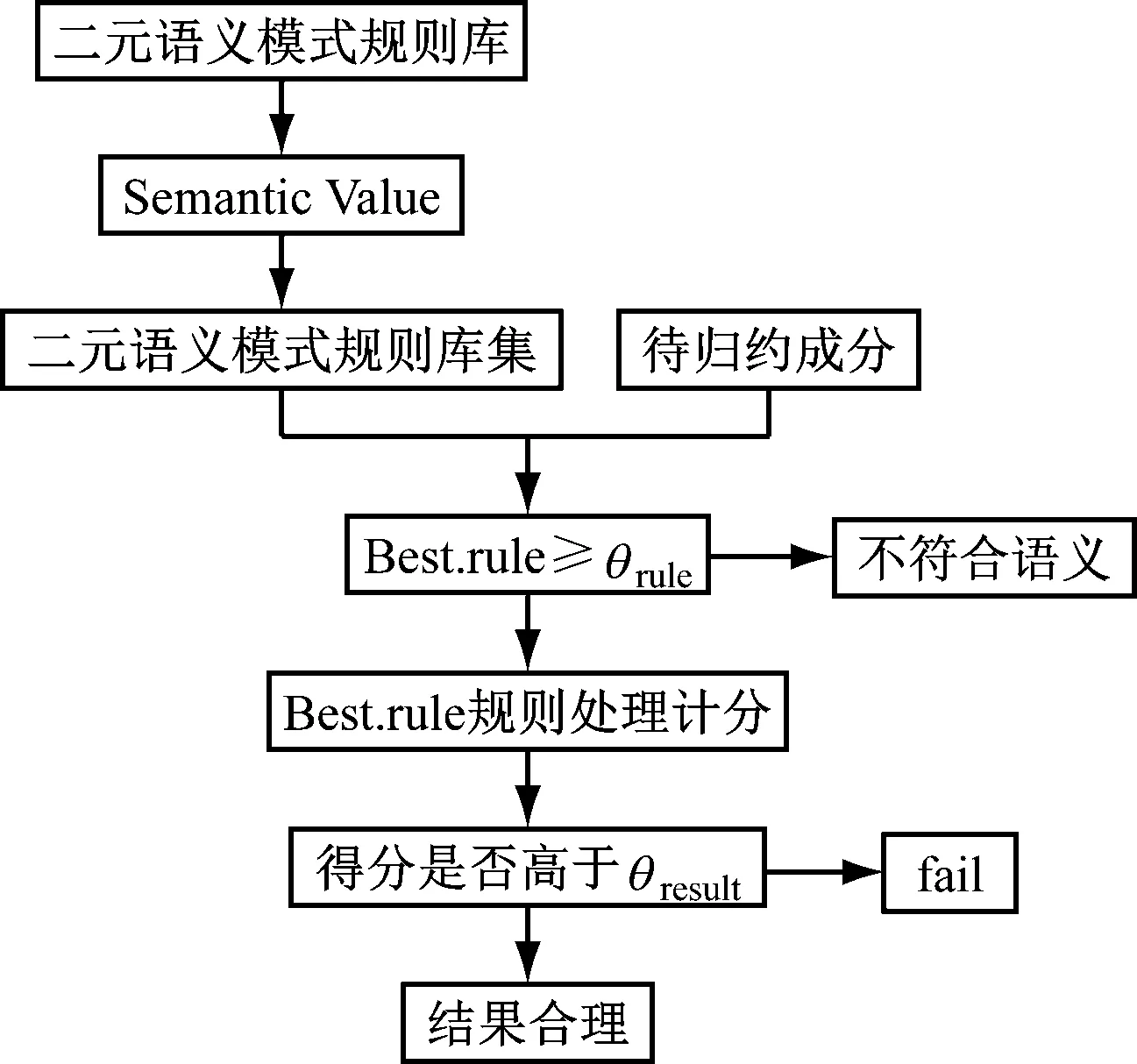
圖4 二元語義模式規則的語義評價的算法
首先,調用Semantic Value算法進行句法和語義分析,在二元語義模式規則庫中找出相應的二元語義模式規則集,計算待歸約成分中每一項組合與二元語義模式規則集的語義匹配度,如果二者之間的最高匹配度規則Best.rule高于閾值θrule,那么則認為結果合理;否則,則認為該項不符合語義。將合理的結果利用Best.rule規則進行處理并進行計分,若結果最終得分高于最小語義評價得分閾值θresult,則結果合理;否則返回fail。
另外,本文利用該二元語義模式規則進行了排歧實驗,以短語“黃 皮膚 男孩”為例進行了排歧分析。首先將由語料庫獲取了短語中各詞語的詞義和詞性,將其轉換為待歸約成分,如表1所示。
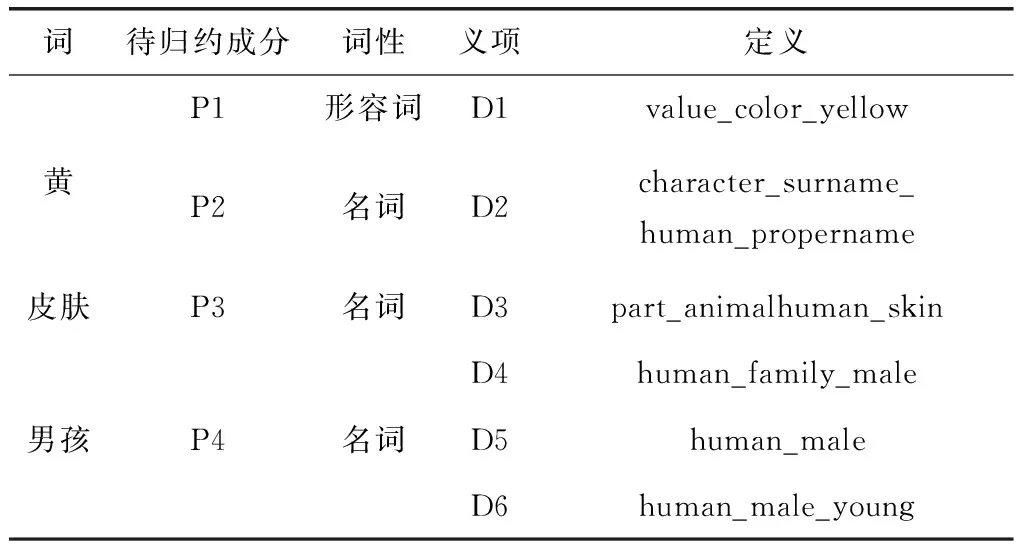
表1 示例詞語的詞性和義項
在對待歸約成分進行歸約前,先利用Semantic Value函數對各義項的組合進行語義評價,當歸約結果得分高于閾值θresult時,則生成新的歸約成分。所有義項組合的歸約結果得分如表2所示。
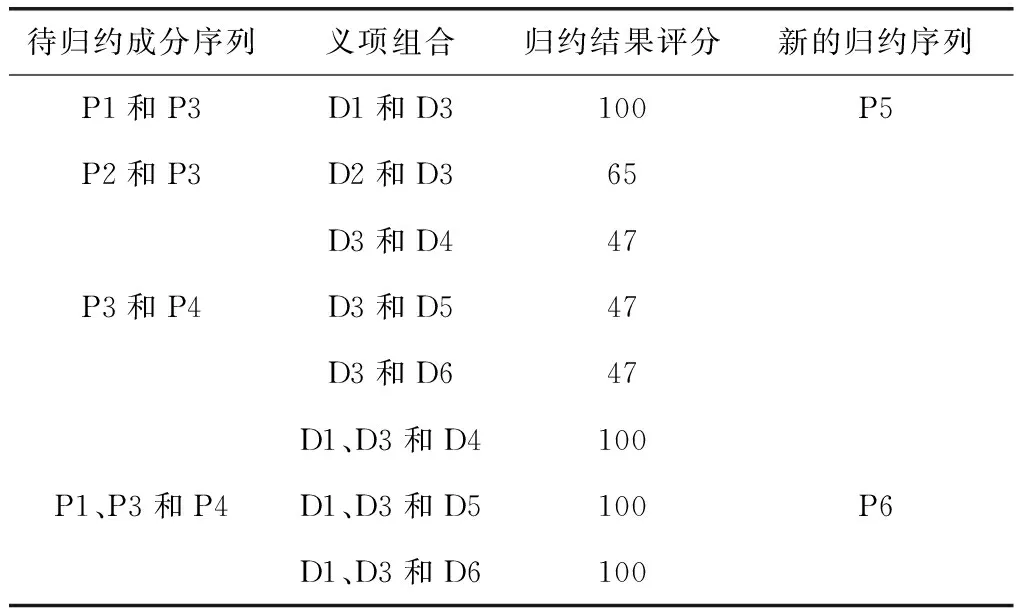
表2 第一次歸約結果
其中D1和D3組合,D1、D3和D4,D1、D3和D5以及D1、D3和D6組合的歸約結果得分均為100分,產生新的歸約序列P5和P6。以上結果表明P2和P3以及P3和P4無法歸約,P1和P3可以歸約得到合理結果“黃皮膚”;P1、P3和P4歸約得到合理結果“黃皮膚男孩”。所得到的新的帶歸約序列P5可以與P4進行第二輪歸約,但是無法得到新的歸約結果,因此歸約結束,最終只得到唯一的排歧分析結果,即“黃皮膚男孩”。另外,通過2 000組隨機短語排歧實驗結果表明,對比原XMMT系統,基于二元語義模式規則進行排歧時,詞義排歧正確率為79.9%,結構排歧正確率為85.7%,比原系統分別提高了8.6%和3.9%。
4 總結
本文基于XMMT系統進行優化,設計了一種基于數據挖掘的二元語義算法,發掘詞語組合的語義規律并轉換成二元語義規則集,在漢英翻譯中展現了較好的排歧效果,主要結論如下。
(1) 獲取二元語義模式規則包括子目標發現和二元語義模式規則集2個步驟,通過關聯規則挖掘,可以由子目標模式獲取二元語義模式規則集。
(2) 嵌入的語義評價函數Semantic Value,進行句法和語義分析,進行匹配度計算,完成排歧過程。
(3) 優化后的系統排歧效果得到改善,詞義排歧正確率為79.9%,結構排歧正確率為85.7%,比原系統分別提高了8.6%和3.9%。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
開放教育研究(2020年2期)2020-03-31 01:54:14
Coco薇(2017年11期)2018-01-03 20:59:57
家庭影院技術(2017年9期)2017-09-26 03:41:45
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
現代語文(2016年21期)2016-05-25 13:13:44
