基于移動通信數據的商場綜合體選址高維度動態決策模型
2021-12-09 06:37:42蘭海翔李衛群張濤雷厚宇楊啟帆黃紀萍
微型電腦應用 2021年11期
關鍵詞:模型
蘭海翔, 李衛群, 張濤, 雷厚宇, 楊啟帆, 黃紀萍
(貴州力創科技發展有限公司, 貴州 貴陽 550003)
0 引言
20世紀90年代以來,全球經濟進入一體化的新時期,各國飛速發展的經濟,推動房地產市場的繁榮與發展,提升人們的生活水平。面對日益發展的社會經濟,居民的物質欲望與商品需求不斷增長,城市對于商場綜合體的需求越來越大,因此需要建立一個決策模型,實現對商場綜合體選址的決策[1]。
國外關于商場綜合體選址方面的研究,起源于20世紀初始階段,經過不同學派和學者的深入研究,將商場綜合體選址理論和城市空間結構相結合,其中美國學者格蒂斯,在1961年重點研究了地價與城市商業活動區位的關系,發現商場銷售額,隨著離城市商業中心和地價最高處越來越遠,且呈遞減狀態。而在1980年,道森將市場經濟與商業地理帶上了新的高度,從更寬廣的角度探討商場銷售與商業地理的空間關系,這些傳統的決策模型或方法,都對當時商場綜合體選址做出了巨大貢獻。
而國內在20世紀初期和中期,正處于內憂外患的戰爭階段,無暇顧及商業經濟帶來的社會變革,因此對于商場綜合體的選址也不甚關心。中華人民共和國成立以后隨著國家性質的轉變,楊吾揚利用克里斯塔勒理論,對中心城市進行了實證分析,將商業中心區域按照商業吸引力劃分等級,以此作為今后商場綜合體選址的參考依據[2]。
但隨著經濟體制不斷變化,城市一體化水平不斷提升,傳統的決策模型已經不適用于現階段的商場綜合體選址決策,因此,需要研究基于移動通信大數據的商場綜合體選址決策模型,根據移動通信大數據覆蓋范圍廣、獲取便利、數據相互關聯程度高等特點,構建一個可以進行高維度動態決策的模型,為城市中商場綜合體的建設與發展提供可靠的決策手段,為國家綜合國力的提升,提供更完善的技術支持[3]。
1 設計決策模型指標選取架構
構建性能更好的決策模型之前,需要設計一個選址指標體系選取框架,以此作為決策模型的構建思路。在現代城市的飛速發展下,商場綜合體選址不應離開人口密集區和城市中心經濟圈,因此設計的決策模型指標體系選取架構,要充分考慮4項影響指標[4-5],該架構如圖1所示。
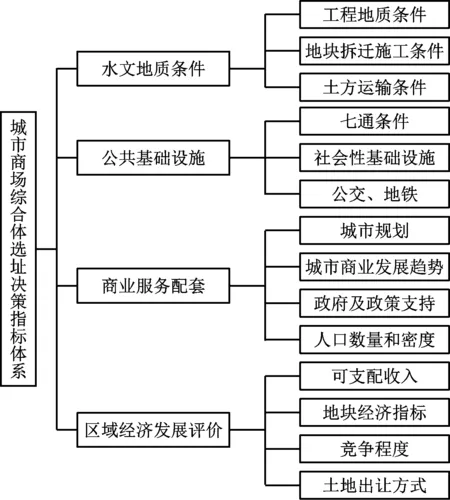
圖1 決策指標選取架構示意圖
按照上述決策模型架構,結合移動通信大數據的功能特點,以分析商圈附近及周圍關聯地區、客戶流動特征和行為特征為目的,構建商場綜合體選址決策模型。
2 基于移動通信大數據的商場綜合體選址高維度動態決策模型構建方法
2.1 基于移動通信大數據預測人口流動性
人口流動性作為商場綜合體選址的關鍵性指標,需要利用移動通信大數據對該指標進行預測。而人口流動性的預測,需要從兩方面入手,移動通信大數據預測人口流動性的兩個方向[6-7]如表1所示。

表1 人口流動性預測方向
利用移動通信大數據,獲取表1中人口流動性預測數據,采用信息增益法分析城市中,動態變化的人口流動狀態[8]。假設一個隨機變量為U,它的可能取值有n種,分別為u1,u2,…,un,變量U對應的概率分布為式(1)。
P(U=ui)=pi
(1)
其中,P表示概率;i=1,2,…,n,表示隨機變量n種取值中的任意一種。此時U的熵定義為式(2)。
(2)
式中,S(U)表示U的熵。而信息增益就是進行人口流動性預測前與預測后的熵的差值,即式(3)。
k(U,A)=S(U)-S(U|A)
(3)
式中,S(U|A)表示預測后的熵[9-10]。當k值減少的程度越大時,代表該預測產生的分類結果越好,信息增益值就越大。因此在人口流動性預測時,利用該方法獲取移動通信大數據中不同口徑的人口流動性,實現模型對商場綜合體選址的初步決策。
2.2 高維度分析客戶行為特征設置決策變量
根據預測的人口流動性,設計該模型的高維度分析方式,通過該分析獲取客戶行為特征。統計預測的人口流動性結果,某一城市中,人口流動性最豐富的一組預測結果[11-12],如圖2所示。
圖中,A、B兩點為最大人口流動線路的起始點和終止點;C、D是這條線路上的兩處商業建筑區。圖2是高維度分析法,將地圖軟件與分析軟件關聯后的分析結果。根據圖中的線路可知,人口流動具有一定的規律性,因此按照圖2中的數據來源,利用高緯度數據倉庫,設計決策模型的預處理流程,實現對客戶行為特征的分析,可視化的形式如圖3所示[13]。

圖2 人口流動性線路圖

圖3 客戶行為特征高維度分析結果
圖3是一天中,從早上8點至晚間10點的人口熱力分析圖,從圖中可以看出,受C、D商業建筑區的影響,此條線路中的客戶一直按照該線路活動,可見設計的高維度動態決策模型,需要通過高維度分析,獲取客戶行為特征,實現移動通信大數據下,商場綜合體選址的決策參數的設置[14]。假設圖3中的所有商業集群用Ai表示,每一商業區為a1,a2,…,an,其中i∈n,表示商業集群中所有商業區域的數量。則該線路對客戶的吸引力計算式為式(4)。
(4)
式中,x表示吸引力;α表示商業場所的權重因子;d表示距離;γ表示偏離距離權重因子;Δa表示在城市發展中,增加或減少的商業區。該吸引力指標,即為客戶行為特征分析下動態決策模型的決策變量,根據該變量,構建商場綜合體選址動態決策模型[15]。
2.3 構建商場綜合體選址高維度動態決策模型
依據設置的決策變量,構建商場綜合體選址高維度動態決策模型,該模型的構建流程[16]如圖4所示。

圖4 決策模型構建流程示意圖
上述流程中的前4步流程已經實現,因此構建判斷矩陣,確定決策系數。假設判斷矩陣用W表示,則有W=(Wij)m×n,其中Wij表示影響因素i和影響因素j相對于決策目標而言的重要值;m、n表示維度[17-19]。則該判斷矩陣描述如表2所示。
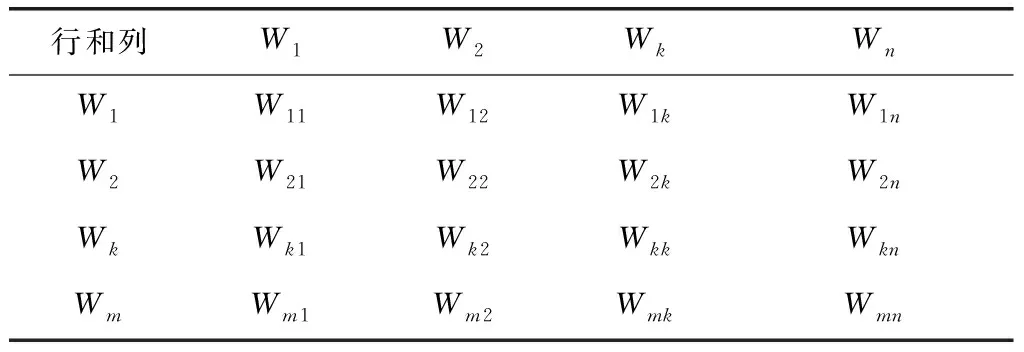
表2 決策模型判斷矩陣
表中,k∈m,n,是(Wij)m×n中的任一數據。而決策系數是判斷矩陣的相對一致性指標,計算式為式(5)。
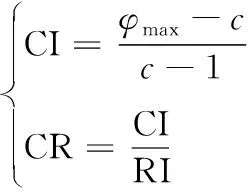
(5)
式中,φ表示矩陣判斷結果;c表示數量;CI表示一致性指標;RI表示平均隨機一致性指標[20]。根據式(5)計算結果確定決策模型的決策系數,通過模糊變換得到最終的選址結果,至此在移動通信大數據作用下,商場綜合體選址的高維度動態決策模型構建完畢。
3 案例實證分析
提出仿真實驗,分析本次構建的決策模型,在工程化實際應用中的使用效果,為了確保測試結果真實可信,將3種傳統商場綜合體選址決策模型作為比較對象,分析不同決策模型對商場綜合體選址的影響效果。
3.1 構建驗證案例
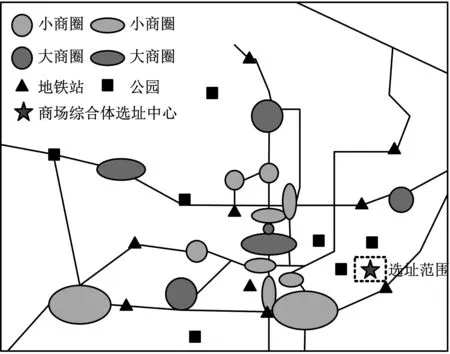
搭建仿真實驗環境,使用Spark集群,并在用戶端安裝Spark-Client,令所有實驗測試模型都可以正常運行自己的決策算法。隨機選擇一個城市作為工程化應用測試對象,該城市的商圈如圖5所示。
圖5 實驗測試商圈示意圖
統計該城市中,所有標志性建筑區域的信息,同時調查這些區域周圍的城市概況,如表3所示。
以上述參數為依據,利用仿真實驗環境構建的4組決策模型,對該地區的商場綜合體選址進行決策,并根據決策結果進行實地分析。
3.2 工程化應用結果與分析
實驗將本次研究的決策模型作為實驗組,將3種傳統商場綜合體選址決策模型分別作為對照組1、對照組2以及對照組3。結合表3中的數據進行實驗,4組選址結果如圖6所示。

表3 實驗測試對象基本概況
根據上述4組測試結果可知,在同樣的城市背景下,4個決策模型得出了全然不同的測試結果,比較商場綜合體的選址結果。實驗組的選址位置,充分考慮了商圈位置、交通位置和人口密集區,將新的商場綜合體選址位置,設置在符合上述要求的區域內。而其他3個對照組,其決策模型忽視了人口流動性和行為特征等因素,對照組1的選址位置雖然有可取之處,但相較于實驗組而言,不夠接近商圈密集區,能夠吸引的客流量少于實驗組;對照組2和對照組3,則極度單一,沒有考慮商圈內,客流量的流動性和商場的吸引力,致使2個決策模型沒有建立起一個高維度的動態決策思維,導致最終的選址位置不是最優。為了令實驗結果更加詳細,在該實驗測試商圈中,隨機選擇100名群眾進行調查,比較商業圈中的流動群眾,對4個選址結果的喜愛程度,調查結果如表4所示。

(a) 實驗組選址結果
(c) 對照組2的選址結果

表4 實地調查對比結果/人 單位:人
從上述調查結果中可以明顯看到,100名調查對象會經常去的商場,是實驗組決策模型決策下的選址結果,而其他3個對照組決定的商場綜合體選址,大多數調查對象都選擇極少去或不會去這一選項。綜合上述實驗測試結果,可知本次研究的決策模型,得到的決策方案最優,為投資商進行商場綜合體選址提供了案例借鑒。
4 總結
研究提出的商場綜合體選址高維度動態決策模型,以移動通信大數據多樣性、實時性等特點為依托,充分考慮了城市中人口流動的特點,以此鑒別客戶行為,增強決策模型的感知與思考能力。在多次試驗論證下,證明了此次研究的決策模型得到的商場綜合體選址最優,滿足商場建設目的的同時,符合真實情況。但該模型只是針對商場綜合體選址進行決策的,今后的研究與發展,可以將該模型改進,應用于不同功能或用途的商業建筑選址決策中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
