多模型加權融合的文本相似度計算
2021-11-20 03:23:30田紅鵬
計算機工程與設計 2021年11期
田紅鵬,馬 博,馮 健
(西安科技大學 計算機科學與技術學院,陜西 西安 710600)
0 引 言
在文本相似度計算領域中,其主要是扮演著自然語言處理的一種基礎性工具的角色。目前,這種計算方式在很多領域中都能夠看到其身影,比如在處理對話以及數據采集問題上均會使用[1]。Islam等[2]提出了一種基于語料庫的語義相似度測量和最長序列匹配算法來測量文本的語義相似度,可以在文本表示等領域專注于計算兩個句子或兩個短段落之間的相似度。李曉等基于Word2Vec模型的基礎上,把句子進行了簡化處理,并形成向量空間中的向量運算,然后根據矩陣之間的關聯度對句子語義中的相似度進行了檢驗和論證[3]。其所使用的設置方式,對于強化相似度結構的精準性起到了顯著作用。Magooda等[4]提出了一個基于TF-IDF和語言模型相結合的方式將計算出的相似度根據新的加權總和對檢索到的文檔進行重新排序。有效克服了模糊理解文章的語義和上下文的問題。Kusne等[5]提出文本距離算法,將文本距離分解為詞間的稀疏矩陣,基于文本向量空間距離進行求解。Tashu等[6]為了解決語義和上下文的問題,提出了使用詞移距離算法的成對語義相似性評估。該方法依靠神經詞嵌入來衡量詞之間的相似度。Pontes等[7]證明了局部上下文對于獲取句子中單詞的信息和改進句子分析效果顯著。其系統地分析、識別并保存了句子各部分和整個句子中的相關信息,通過局部上下文降低均方誤差并增加相關性分析來改進句子相似性的預測,同時也提出了語料庫的重要性。Yang等[8]基于淺層句法結構化特征的基礎之上進行求解,雖然依賴樹能有效解釋關聯關系,但無法適用于句子深層語義的解釋。Ozbal等[9]使用樹核函數根據輸入數據的結構化表示生成不同維度的特征信息,對多種富含語義特征的句法信息進行求解,實驗發現淺層語義特征與語義特征可以很好結合。
現存大多數研究僅考慮單一的文本特征或僅針對語義特征進行模型融合,本文不僅考慮文本語義、詞序、主題關聯性等相關語義問題,同時還結合了文本結構信息等表現形式展開分析。在此前提下,結合基于分層池化句向量的方法計算文本相似度,進而實現了不同形式在求解方面的融合,綜合考慮句子語義和文本結構信息并使計算結果更優且合理。
1 相關工作
1.1 TF-IDF權重(TIi)
此權重通過兩部分實現,其一是TF詞頻,特征詞在特定一段范圍之內出現的次數出現次數越多,詞頻量化值越大,出現次數越少值越小。通過這一數值的計算,能夠進一步得出與總長度的整體比值。特征詞總量共計為N,其中某詞條的浮現次數為n,詞頻TFik即
(1)
其二逆文檔頻率即包含特征詞條的文檔數,如式(2)所示。M為全量文本,包含詞條的文本置為m,包含特征詞的文檔越少IDF最終越大
(2)
其中,α為經驗系數,通常情況下,該數值等于0.01。TF-IDF權重表示為
TIik=TFik*IDFik
(3)
1.2 詞句位置權重(Pi)
美國P.E.Baxendale的調查結果顯示:在文本中的重點思想實際上大部分是出現在第一句當中,而這種現象占了整體的85%,另外7%是出現在段落末尾。因此在對其比例進行計算的時候,還需要對其位置因素多加考量,要根據其不同位置來對關鍵詞分析權重。當關鍵詞或者核心內容都聚集在第一句或者最后一句的時候,其關鍵詞會比其它位置的權重占比高很多。接下來對其加權函數進一步展示
(4)
其中,e1和e2為支持個性化設置,其中將e1值調整為0.2,e2值調整成0.1。x代表的時不同位置下的具體比例,且按照0-1的順序自然排序。其中一個i的詞句位置權重為Pi。
1.3 詞性權重(Si)
此處對我們當前使用的漢語言詞義與特征展開研究[10],需要根據關鍵詞的含義、句法關系等來對其權重展開針對性計算[11]。對所有詞語的詞性特征進行歸納[12],并總結為7種,每一種詞性分別所占的比例體現在表1中。

表1 中文文本詞性分布占比
通過梳理表1數據我們不難發現,在這些不同性質的代表詞性當中,在解釋詞匯內容方面,最具解釋能力的詞性就是動詞、名詞、形容詞和副詞。剩余3種詞性的詞語幾乎不具備完整的詞匯信息,因此會被看作數據噪音被處理掉。通過前4類詞語的運用,一方面,能讓其解釋能力更佳,另一方面,還能進一步簡化不必要的計算流程,進而使計算結果更為精準與快速。同理,得出了表2中不同詞性下所對應的占比。

表2 詞性權重系數
在表2所示的數據當中,Si代表的是不同詞性i下的不同占比,可以發現,除了一類與二類詞性之外,其它詞性權重都置為零。
2 多模型加權融合算法設計
在此研究的過程中,首先充分考慮了詞語出現頻率的問題,構建多特征權重的量化信息,兼容TF-IDF、語句、詞性。在多特征融合的前提下,對不同特征詞進行了再次計算,基于其自然降序排序原則下,對特征詞進行排序,其中選取前n個作為文本關鍵特征詞。最終,在Word2Vec詞向量模型中,通過計算特征詞數值,得出了最終的向量形式,進而計算出比較精確的相似度數值。
通過結合實現的池化操作使用SIF模型,將不同詞序和結構信息的表達類型分層分組,去除向量之間的空間距離后,可以計算出單位向量模型與分層求和的相似度結果。
為了更好強化算法的特征,并保證最終數值的準確性,將上述兩種單模型線性加權計算,得到融合的計算算法(algorithm for calculating the similarity of multi-model fusion,MuMoSim)。計算如下
MuMoSim=x×MuSim+y×IIGSim
(5)
其中,MuSim為前者多特征融合度量計算結果,IIGSim為后者分層池化度量計算結果。該計算方法的流程如圖1所示。

圖1 多模型融合文本相似度計算算法
2.1 基于多特征融合的詞移距離算法
大多數基于關鍵詞的相似度計算方法單一統計句子的關鍵詞,為綜合考慮關鍵特征對文本相似度結果的影響,本文采取將詞頻TF-IDF權重(TIi)、詞性(Si)、詞句位置(Pi)3個特征相結合,共同計算句子相似度。詞語i在文本D中的多特征融合權重計算公式如式(6)所示
MFWi=α×TIi+β×Si+γ×Pi
(6)
式中:α、β、γ分別代表的是詞頻、詞性和詞句位置3個不同要素的相似度權重系數,0≤α≤1,0≤β≤1,0≤γ≤1,同時要滿足α+β+γ=1。
本文采用層次分析法計算各特征項α、β、γ的權重,針對不同數據集設計不同權重系數取值。層次分析法針對本文特征元素進行定性和定量分析。具體步驟如下:
(1)建立層次結構模型
特征融合后的結果作為目標層,詞頻、詞性、詞句位置相似度作為準則層。
(2)構造判斷(成對比較)矩陣
根據重要程度對比,得出準則層各個準則的比重。標度量化值1-9代表重要程度由低到高,兩兩比較減少干擾因素,最終生成判斷矩陣。
判斷矩陣元素標度方法
(7)
(3)層次排序及其一致性檢驗
計算一致性指標CI
(8)
式中:λmax為從判斷矩陣得出最大特征值,n為特征向量的維度。
平均隨機一致性指標RI標準值見表3,本文為三階矩陣,RI對應表格中為0.52。計算一致性比例CR

表3 隨機一致性指標
(9)
通常情況下,若CR<0.1,假設判斷矩陣已通過最一致性測試,否則不符合一致性。對函數向量進行歸一化后,將生成權重向量為α、β、γ的取值。
根據組建的多特征融合權重,可以得出富含信息的特征,其中包含大量的文本信息。在多特征融合的詞移距離算法中,使用內置多特征權重之間轉移詞的代價計算來代替算法中對兩個文本中兩個詞轉移代價的計算。假定ki和kj分別為兩篇數據文本囊括的關鍵詞。計算轉移代價
(10)
構建轉移矩陣Tki,kj以保證文本D中所有關鍵詞ki完全轉移到文本D′中,結合原始算法的矩陣定義,需要添加以下約束
∑kjTki,kj=MFWki|D
(11)
∑kiTki,kj=MFWkj|D′
(12)
式(11)定義的約束指定從關鍵項ki轉移的總成本必須等于關鍵特征的權重系數,式(12)定義的約束規定轉移到關鍵項kj的總成本必須等于此特征項的組合權重因子。因此計算文本轉移的總代價公式如下
(13)
本小節提出的距離優化目標,就是使上述總代價Ic最小。因此文檔D與文本D′之間的歐氏距離如式(14)所示
(14)
為了確保最終相似度計算結果加權過程不受其它因素干擾,此處本文將計算出來的相似度進行處理,使結果位于0~1范圍內。經過運算,我們可以得到文檔之間的相似度如式(15)所示
(15)
2.2 分層池化IIG-SIF句向量的相似度計算
(1)改進信息增益計算方法
對于平滑逆頻句向量模型只考慮通用數據集上的詞頻信息來計算詞權重,為了使特征詞能夠在更大程度上影響計算任務,必須要綜合性的考慮增強各種因素,其中包括考慮特征詞對不同文本的影響。所以此處添加了類內詞頻因子β和類內、類間判別因子δ。將兩個影響因子看作新的元素進行數據篩選,計算公式如下所示
IIG(T)=IG(T)×β×δ
(16)
此處假設語料中各類型文本集合為Ci,i∈[2,n]。β表示語料集合中某特征詞在集合中出現次數與語料當中詞總量的比值,這樣能夠更大程度客觀表述特征詞和類別之間的相關性。類別Ci中單詞w的類內詞頻公式如下
(17)
其中,m表示集合中詞總量,Nij表示某特征詞匯在集合中出現次數。類內詞頻因子越大,說明特征詞匯與本類的相關程度越高,此詞語對于這個集合的語料更具有代表性。
δ刻畫的是對于不同的語料集合進行篩選。如果一個詞只在一個類別中頻繁出現,而在其它類別中不太可能出現,則說明該詞在類別之間具有較高的區分度和較高的屬性對比度。此處區分度計算如下
(18)

(19)
簡言之,類別之間的分離程度越大,類別內部的劃分程度越小,文本的區分程度就越大,特征詞w對類別Ci的貢獻就越大,并且能夠更好地表示類別中包含的信息。特征詞區分度定義如下
(20)
(2)基于特征貢獻度因子的選詞方法
原SIF模型具有領域自適應的優勢,在不同語料庫中使用仍然能保證優秀的性能,但當具體到各語料庫中的集合時,不同詞對任務的貢獻不同及其權重的問題不考慮修正。此處在第一小節的基礎上,增加針對文本任務的特征貢獻度因子,其表示如式(21)所示
TCF(w)=IIG(T)Weight(w)
(21)
其中,Weight(w) 表示原模型中對特征詞的設定。
生成句向量需要根據數據集中不同類別特征詞的分布,采用改進的信息增益特征選擇方法提取出任務貢獻因子。需要將任務貢獻度低的數據項剔除,需要將任務貢獻度低的數據項剔除后再展開計算,這是實現運算結果準確性的基礎。模型算法過程如下算法1。首先對各個特征詞的出現頻率進行了求解,其次對增益算法進一步升級增強后,對任務貢獻因子求解,隨后根據任務貢獻度因子值大小進行降序排序,修正特征詞表,最終將詞向量加權平均得到句向量。
算法1: 分層池化的IIG-SIF句向量模型
輸入: 詞向量集合vw; 句子集合S; 語料庫p(w); 分類訓練集Ci
輸出: 句向量集合vs
(1)forallsentencesinSdo

(3)endfor
(4) Create matrix X whose columns arevs
(5) Create first singular vectoruby X
(6) Create word order vectordby X
(7)forallsentencesinSdo
(8)vs←vs-uuTvs
(9)vs.append(d)
(10)endfor
分層池化的IIG-SIF計算相似度過程如下:
(1)數據預處理。將標準化、去停篩選后的文本數據集合定義為S′1、S′2。
(2)句向量生成。采用改進的特征貢獻度因子生成模型句向量Sv1和Sv2。
(3)相似度計算。利用向量Sv1和Sv2之間的余弦距離計算文本之間的相似度,即
(22)
3 實驗設計與分析
3.1 實驗環境及數據
具體實驗環境見表4。

表4 實驗環境
為了凸顯本文方法的有效性,實驗在數據集選取時引入中文和英文的句子對、短文本集合等4種數據集,以驗證在不同語言、不同粒度下的實際表現情況。具體的數據體現見表5。
表5 Quora數據集示例
數據集Ⅰ如表5所示,其源自Quora數據集。其中囊括了39萬余英文句子,由Question1、Question2及Is_duplicate 這3部分組成,在此數據集中語義標注為人工標注,若語境結果表述的含義相同或相似則Is_duplicate置為1,反之為0。
數據集Ⅱ選擇了20余類英文的熱點話題,其中包括財經、歷史、體育、科技等。將話題文本總量較少的文本類型剔除后,剩余6組共計3000條數據以供使用,其中3組文本類別相似,其余3組不相似以供對比。
數據集Ⅲ選擇STS中文文本語義相似度語料庫,見表6。數據集的評分區間為[0,5],即0為語義相反或毫不相關,5為相似度極高。該數據集分為兩組數據,其中包含27 490個句子對,其各個相似度評分的數據量分布不均,大部分為相似度極高數據集,因此,需要篩選數據,最終本文剩余8000個句子對展開實驗分析,盡量保證各個相似度評分下的數據量大小一致。

表6 ChineseSTS數據集示例
數據集Ⅳ選取自復旦大學的中文文本分類數據集。下載的原始數據編碼格式是gb18030,因此需要將數據格式轉為utf-8編碼格式后使用。train.zip訓練集共9804篇文檔,test.zip測試集共9832篇文檔,都分為20個類別。其中無用數據需篩選,部分類別的文檔數量較少,無法使用。本文選擇計算機、環境等7類數據量充足的數據以供使用。
3.2 實驗設計
在實驗過程中首先做預處理,對數據進行刪除和過濾等處理。與此同時,本文使用了相同的區間值,即[0,1],在對相關數據進行觀察和研究之后,對評分較低的語句進行了二次標注,即統一標上1,而評分結果為2或0時置為0。
接下來,本文使用jieba工具包對采集到的數據進行分詞,并對特征詞的TF-IDF系數予以求解,然后對所有詞匯按照其不同特征值進行細分,最終歸結為4類,并分別進行標注。而在此之前,要先對短文本數據進行篩選,并對其中不同詞語的位置予以定位,進而得出不同詞性的權重。另外,對于句子對比而言,應將初始權重均勻設置為1。這種做法,一方面能夠降低文本長度對結算結果造成的影響,另一方面也能夠最大限度提升計算過程的便利性。至此將數據代入式(6)計算出融合后的權重系數大小。
第三步結合現有資料,利用已有流行庫來對Word2Vec詞向量進行數據集訓練。其中選用模型Skip-gram模型(sg=1)。設定其基本參數,結合實際情況將窗口大小設為5,向量維度300,初始默認學習率設置為0.001。并且使用一些初始化后隨機的向量來表示不在語料庫中的詞語。
最后進行分層池化相關操作。先對各個特征詞的出現頻率進行了求解,再將增益算法增強后對任務貢獻因子求解。模型依然按照原始模型當中參數進行設置。模型系數a設置為0.0001。
3.3 實驗結果與分析
(1)實驗1:選取特征詞最佳占比
在實驗過程中,選擇使用多特征融合模式下適用的詞移距離算法時,在選取詞語這一過程中,不同選取比例會影響文本相似度計算的結果。選取的比例過小,就會導致模型可能會忽視一些文本信息,影響算法的計算結果;但如果選取的比例過大,而這些信息中包含了一些與模型不兼容的信息,模型涉及的冗余信息過多,這導致算法效果不佳、精準度無法得到保證。
聚類被廣泛應用在信息挖掘模型中,因為這種模式不僅不需要事先訓練,同時還能夠免去標注、分類等復雜環節。所以在從此實驗過程中,本文重點采用了當下聚類效果出眾的K-means、DBSCAN算法中來確定特征詞占比。鑒于數據集Ⅱ在聚類算法中也經常使用,也得到了大部分研究者的認可。基于此,本文將在這一數據集的前提下,選擇歸一化互信息指標(normalized mutual information,NMI)來評測聚類結果好壞。當NMI值越大,說明聚類的效果越好,即說明該算法包含的文本信息越多。在圖2中,不同比例特征項對聚類結果的差異十分明顯。

圖2 文本特征詞對聚類的影響
由圖2可知,如果選取60%的文本特征詞,聚類的效果是最好的。若是選取的比例小于60%,就會出現模型包含的文本信息量不足,造成算法的效果不理想,若是選取的比例大于60%,就會造成文本的冗余,削弱文本與文本之間的獨立性,造成算法的效果不準確。
(2)實驗2:針對加權因子進行取值。
該實驗的數據集選自數據集Ⅳ中的部分內容,結果見表7。

表7 不同x和y取值下的實驗結果
由表7可知,通過增加多特征融合和詞移距離算法的權重,就能夠進一步提升召回率,因此這種做法能夠最大限度保證數據運算的準確性和文本特征的多元性。通過實驗結果可知,當x選取0.6,y選取0.4的時候,召回率最高,最終本文確定x和y的取值分別為0.6和0.4。
(3)實驗3:融合方法的對照實驗
為了驗證本文算法的有效性,選擇了準確率、召回率和F1值作為評價指標,通過將本文算法(MuMoSim)與未融合多特征的詞移距離算法(MuSim)、基于分層池化IIG-SIF句向量算法(IIGSim)、傳統的詞移距離算法(WMDSim)和基于SIF句向量算法(SIFSim)進行對比來進行驗證。實驗結果見表8。
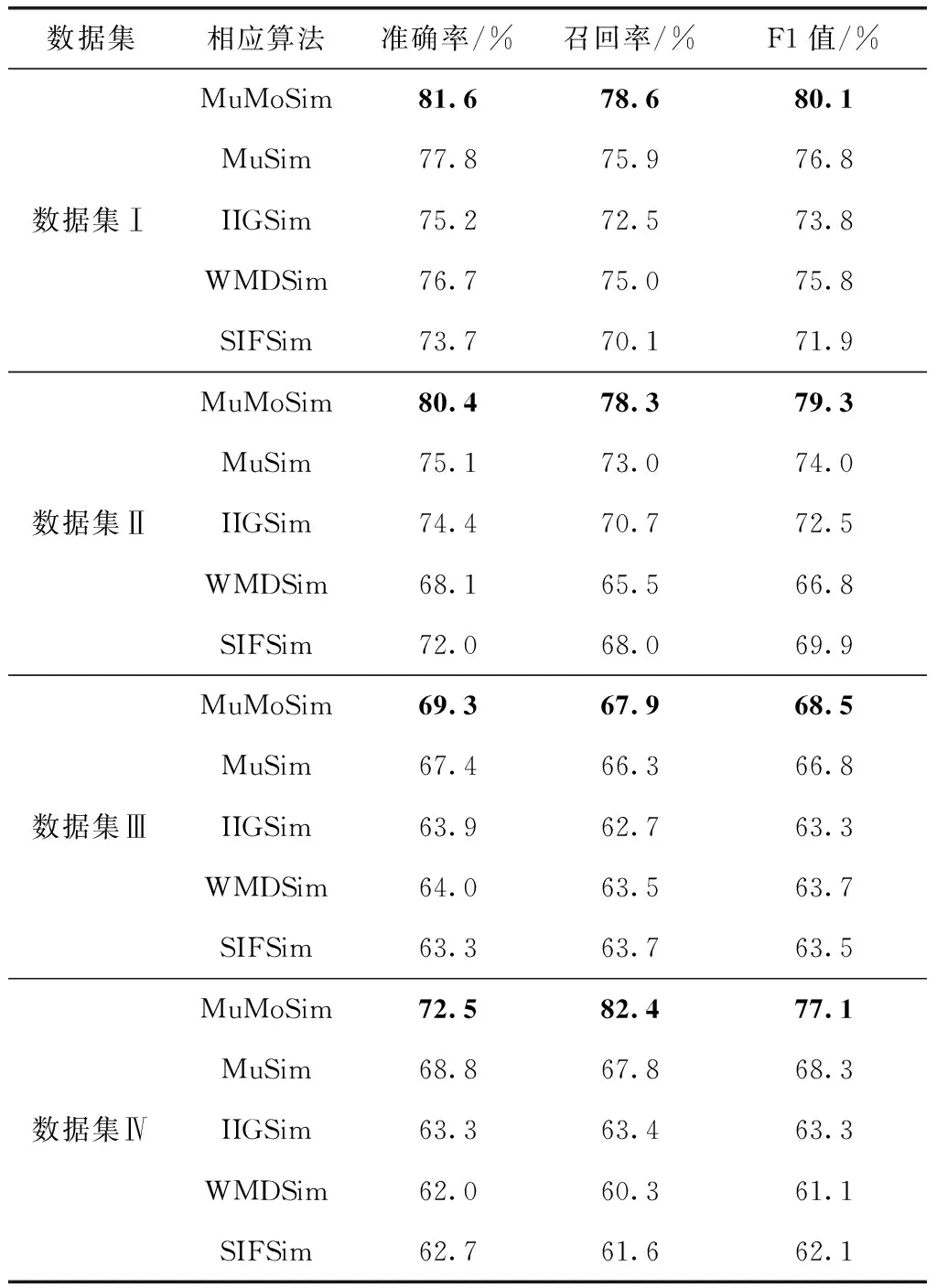
表8 融合方法對照實驗結果數據
由表8可以看出,在這4種數據集下,本文算法(MuMoSim)在3個評價指標上都獲得了比較高的數值,評價指標取得的值越高,說明算法的效果越好。這是因為本文算法能夠實現詞義、語義等多種信息的有效采集和處理。而在這一前提下提出的多特征融合權重,結合數據特征能夠更為精準解釋詞語轉移距離。結合分層池化相關內容,根據數據集中不同類別特征詞的分布,采用改進的信息增益特征選擇方法提出任務貢獻因子,計算出句向量大小。由于本文算法還提前設置了最佳的文本特征詞的占比,這從一定程度上提高了算法運行的效率。
(4)實驗4:不同文本相似度算法的對比實驗。
將本文算法與文獻[13,14]相關融合算法做對照實驗,以F1值為評價標準,實驗結果見表9。

表9 4種數據集下3類相似度算法F1值/%
由表9可知,文獻[13]的算法雖結合反義與否定兩種信息,但其語義詞典不完善,明顯在不同的數據集有不同的影響,在英文新聞數據處理方面效果起伏較大。文獻[14]的相似度計算算法雖然獲取了句子的詞形特征、詞序特征、句長特征,但在語義相似度處理方面存在不足,影響相似度結果。而本文在此次研究中,提出MuMoSim的算法,既考慮了最佳的文本特征占比,還設置了最佳權重,讓最終結論更為精準。由實驗結果可知,本文算法在4種數據集中在F1值下的表現都要優于其它兩種方法,更具有競爭性。
4 結束語
首先,本文在傳統詞移距離算法的基礎上加入了特征融合機制,融合多特征來解決權重單一對詞移距離算法的影響。其次,引入分層池化IIG-SIF句向量模型,在一定程度上增強文本結構信息和詞匯排序問題。最后,通過對前兩種方法進行加權融合,得到最終算方法。實驗結果表明,本文的算法與之前基線模型進行相比,在評價指標F1值上有了明顯的提升,得到了較好的文本相似度計算結果。
在后續的研究過程中將繼續對本文的方法加以改進,例如引入外部知識來彌補中文數據庫效果差的弊端,增強中文的語義信息,提高文本相似度的計算結果。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
