基于多重指數移動平均評估的DDPG算法
2021-11-20 03:22:02范晶晶陳建平傅啟明1悠1吳宏杰1
計算機工程與設計 2021年11期
范晶晶,陳建平,傅啟明1,,4+,陸 悠1,,4,吳宏杰1,,4
(1.蘇州科技大學 電子與信息工程學院,江蘇 蘇州 215009;2.蘇州科技大學 江蘇省建筑智慧節能重點實驗室,江蘇 蘇州 215009;3.蘇州科技大學 蘇州市移動網絡技術與應用重點實驗室,江蘇 蘇州 215009;4.蘇州科技大學 蘇州市虛擬現實智能交互及應用技術重點實驗室,江蘇 蘇州 215009;5.珠海米棗智能科技有限公司 科研部,廣東 珠海 519000)
0 引 言
近年來,強化學習(reinforcement learning,RL)在很多科學領域取得的成就較為顯著。通常的講,強化學習是一個智能體(Agent)與未知環境相交互,進而學習得出一種最優策略的方法[1]。強化學習可以分為3種方法,行動者方法、評論家方法、行動者-評論家方法。行動者方法通常利用策略梯度優化。評論家方法的核心為值函數逼近。而行動者-評論家方法則結合了兩個方法的優點,評論家結構是值函數的近視函數,以最大化累積獎賞為目標指導行動者選取最優動作[2]。
深度強化學習(deep reinforcement learning,DRL)采用大型神經網絡策略,通過值函數取代了經典的線性函數逼近器。并且深度強化學習在各類具有挑戰性的問題上都有了成功的結果,例如Atari游戲、圍棋問題和機器人控制任務等[3,4]。Minh等[5]提出深度Q網絡(deep Q-network,DON)算法,該算法主要是結合了卷積神經網絡以及強化學習,并引入經驗回放技術解決了神經網絡去擬合值函數導致訓練結果不收斂的問題。然而DQN等算法僅在離散低維動作空間比較適用,而對于連續動作空間的問題很難適應。策略梯度是用來解決連續狀態空間問題的基礎,經過反復計算跟策略參數的梯度相關的策略期望的總回報,進而更新策略參數,達到策略的收斂。Silver等提出確定性策略梯度(deterministic policy gradient,DPG)算法,隨機選擇動作的依據為概率分布,而DPG算法則是直接學習輸出動作,輸出動作增加了確定性。然而DPG的適用范圍不廣,策略優化也有待提高,依據策略梯度的深度強化學習方法所優化的效果更佳。Lillicrap等[6]提出DDPG(deep deterministic policy gradient,DDPG)算法,更好解決了連續動作空間的問題,取得最優解的時間步也遠少于DQN。陳建平等[7]針對DDPG算法需要大量數據樣本的問題,提出了一種增強型深度確定策略梯度算法,提高了DDPG算法的收斂性。何豐愷等[8]優化DDPG算法并成功應用于選擇順應性裝配機器臂。此外,張浩昱等[9]改進DDPG算法并應用在車輛控制上,體現了DDPG算法很好的控制前景。
本文針對DDPG算法網絡結構的不穩定性以及單評論家評估不準確的問題,提出基于多重指數移動平均評估的DDPG算法,介紹一種EMA-Q網絡和目標Q網絡合作得出目標更新值,并針對DDPG訓練過程中行動者的學習過于依賴評論家,對多個評論家給出的Q值求平均,這樣多個獨立的評論家網絡可以充分在環境中進行學習,降低單個評論家的不準確性。實驗結果表明,比傳統的DDPG算法相比,基于多重指數移動平均評估的DDPG算法準確性更好,穩定性更高。樣本池部分引入雙重經驗回放方法,采用兩個樣本池分別存儲不同的經驗,實驗結果表明,改進后的算法求得最優解需要的時間步更少,收斂速度也有明顯提升。
1 相關理論
1.1 強化學習
在強化學習中,一個智能體(Agent)在不同時間步與環境交互盡可能得到累積最大獎賞。強化學習問題可以以一個五元組的形式
(1)
其中,t為時間步,T為終止時間步,r(st,at) 為在狀態st采取動作at所得到的回報。
尋找出最優策略是強化學習的關鍵,并在該策略基礎上進行決策。在強化學習中,策略為π,π(s,a) 是指在狀態s下選擇動作a的概率。如果策略π是一個確定的策略,在任意狀態s∈S,π(s) 表示在狀態s下所選擇的動作a。
強化學習中用來評估策略π的好壞的是值函數,由狀態值函數Vπ、 動作值函數Qπ組成,Vπ(s) 表示在狀態s下,根據策略π得到的期望回報,Qπ(s) 表示在狀態s下,選擇動作a并根據策略π得到的期望回報。通常用Qπ(s) 來評估策略π的好壞
(2)
式(2)為Bellman方程。
強化學習中π*表示最優策略,該策略能最大化獎賞函數,對應的Q*(s,a) 可以表示為
(3)
式(3)為最優Bellman方程。
1.2 DDPG算法
無模型強化學習方法可以不需要一個完整、準確的環境模型而直接學習得到最優策略。DDPG算法屬于行動者-評論家方法的一種,是屬于無模型、離策略的強化學習方法。
Deepmind提出DDPG,聯合深度學習神經網絡以及DPG,由此得到的更優的策略學習方法。在DPG的基礎上,它的優點在于策略函數μ和Q函數分別用卷積神經網絡去模擬,也就是策略網絡和Q網絡,后續用深度學習對上述神經網絡進行訓練,Q函數用的是Alpha Go同樣的Q函數方法。
DDPG方法包含AC算法,經驗回放,目標網絡和確定性策略梯度理論,其主要貢獻是證明了確定性策略μw的存在:S→A, 通過給agent一個狀態得到一個確切的動作,而不是得到所有動作的概率分布。在DDPG中,性能目標定義為
(4)
ρπ(s) 代表狀態分布,確定性策略的目標是
(5)
θ和w分別是評論家網絡Q(st,at,θ) 和行動者網絡μ(st,w) 的參數,在DDPG方法中分別用于逼近動作值函數和參與者函數,用于訓練的經驗取自于經驗回放。經驗回放通常是一個用來存儲四元組 (st,at,rt,st+1) 的緩沖器,其中的一部分用于行動者和評論家網絡的更新。當緩沖器容量滿時,較新的經驗會代替舊的經驗,因此只有一小部分舊經驗得到保留。另外,通過給訓練過程一個目標,利用目標網絡來更新評論家網絡,目標網絡的參數通常與評論家網絡的參數一樣。目標網絡定義為Qtar, 損失函數定義為
Ltar(θ)=(r(st,at)+γQtar(st+1,at+1,θ-)-Q(st,at,θ))2
(6)
其中,θ-是先前迭代的參數,經驗回放和目標網絡對于穩定DDPG方法的訓練過程具有重要意義,并且有利于深度神經網絡的建立。
2 基于多重指數移動平均評估的DDPG算法
基于多重指數移動平均評估的DDPG算法針對DDPG算法雙網絡結構的不穩定性以及單評論家評估不準確的問題,介紹一種EMA-Q網絡和目標Q網絡合作得出目標更新值,并針對DDPG訓練過程中行動者的學習過于依賴評論家,對多個評論家給出的Q值求平均,多個獨立的評論家網絡可以充分的在環境中進行學習,降低單個評論家的不準確性,提高算法穩定性。樣本池部分引入雙重經驗回放方法,提高算法的收斂性能。
2.1 指數移動平均DQN
在DQN算法的基礎上,平均DQN算法又做了進一步的改進。在平均DQN的訓練過程中,目標Q網絡對以前學習的K個Q網絡求平均得到,而不是直接在一個固定長度的時間步后,直接從目標Q網絡復制值。平均DQN通過降低目標近似誤差(target approximation error,TAE)的方差來提高整個訓練過程的穩定性。
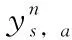
(7)
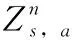
(8)
在平均DQN中
(9)
(10)
顯而易見,平均DQN的性能隨著值K的上升而提高,換句話說,要得到一個更好的策略需要更多的神經網絡來存儲參數,也意味著需要大量的內存。
為了處理需要過多的神經網絡的需求,采取了式(11)中的遞歸形式,而不像平均DQN那樣降低TAE的方差
(11)
并且與平均DQN的方差估計相比減小了一半[10]。
2.2 關于樣本池的改進
優先經驗回放的核心是頻繁選取TD誤差大的經驗,以加快訓練進程。然而,這要求必須在整個訓練過程中掌握采樣TD誤差的概率,本文提出一種雙重經驗回放,使用兩個經驗池B1和B2來存儲Agent的經驗,其中B1和B2的工作方式相同,B2的大小為50,B1的大小為200,在雙重經驗回放中,非常好或者非常差的經驗被視為具有高TD誤差的經驗,其中TD誤差的公式為
φi=r(si,ai)+γQ′(si+1,μ′(si+1|θμ′)|θQ′)-Q(si,ai|θQ)
(12)
TD誤差的閾值設置為0.4,當TD誤差的值大于0.4時視為具有高TD誤差,存儲在B1和B2中,其它經驗則存儲在B1中。當進行采樣時,從B1中采樣40個樣本,B2中10個樣本,約占20%。隨著訓練過程的進行,Agent的學習的表現效果會更好,甚至取得最好的分數,因此B2中的經驗不再具有高TD誤差,對雙重經驗回放的需求隨著訓練過程的進行應該降低。
概率函數Pder用來表示從B2中采樣的概率,隨著時間的后移該概率隨之降低,具體公式見下式
(13)
該步驟對訓練過程的收斂至關重要,一個好的訓練模型總是根據以前的成功經驗進行更新,這可能會導致Agent在大部分狀態具有較差的魯棒性和靈活性。總之,使用概率函數能在訓練前期加快訓練過程,并且在模型趨于收斂時降低自身的作用,進一步加快收斂。
2.3 基于多重指數移動平均評估的DDPG算法
雖然DDPG在連續控制領域表現出了其優異的性能,但是穩定性方面仍然可以得到提高,在訓練過程中,行動者的學習依賴于評論家,使得DDPG方法的訓練對評論家學習的有效性過于敏感,為了進一步提高評論家網絡的準確性,提出采取K個評論家求平均得
(14)
其中,θi表示第i個評論家的參數,該方法包含K個獨立的評價網絡,因此,當一個評論家為行動者提供指導時表現較差時(例如該評論家的估計值突然下降),多個評論家求平均會在一定程度上降低不良影響。并且,多個獨立的評論家網絡可以充分的在環境中進行學習。
有兩種方法訓練評論家網絡,一種是利用評論家的平均值與目標評論家的平均值之間的誤差(TD errors)
(15)
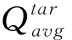
LMC(θi)=αLavg(θ)+βLtar(θi)+η(Qi(s,a,θi)-
Qavg(s,a,θ))2
(16)
其中,LMC(θi) 為平均評論家的損失函數平均值,α,β和η為權重,α,β和η都是0到1之間的浮點數,α和β加起來等于1,Lavg(θ) 為評論家網絡的損失函數平均值,Ltar(θi) 為目標評論家網絡的損失函數值。因為當K為1時,LMC應該等于Ltar, 即損失函數可以看作是3個兩兩相關部分的總和:兩組評論家之間的全局平均誤差、單個評論家和其對應的目標評論家之間的獨立TD誤差、用來減小評論家方差的單個評論家與K個評論家平均值的差值。
針對DDPG中的雙網絡結構的不穩定的問題,介紹一種EMA-Q網絡和目標Q網絡合作得到目標更新值,目標網絡具體更新公式
θEMA←αθQavg+(1-α)θEMA
(17)
(18)
θμ′←βθμ+(1-β)θμ′
(19)
行動者網絡的參數更新
(20)
根據上述具體優化過程,下面給出基于多重指數移動平均評估的DDPG算法的流程,如算法1所示。
算法1:基于多重指數移動平均評估的DDPG算法
(1)隨機初始化K個評論家網絡Qi(s,a|θQi), 行動者網絡μ(s|θμ) 及它們相對應的權重分別為θQi和θμ,i=0,1…k-1, 初始化EMA網絡QEMA, 權重為θEMA←θQavg,K個目標評論家網絡Q′i, 目標行動者網絡μ′, 權重為θQ′i和θμ′,θQ′i←θQi,θμ′←θμ, 原始樣本池B1, 高誤差樣本池B2初始為空,B2內存較小,時間步T
(2)while episode do
(3) 初始化一個隨機過程Nt用于探索動作
(4) 獲得初始觀察狀態s0
(5) while t=0,T do
(6) 根據當前策略和高斯噪聲at=μ(st|θμ)+Nt選擇動作
(7) 執行動作at, 得到rt,st+1
(8) 將 (st,at,rt,st+1) 存儲在兩個樣本池B1,B2中
(9) 從樣本池B1中隨機采樣一部分,B2隨機采樣一小部分,約占10%
(10) 通過最小化損失函數來更新每個評論家網絡:LMC(θi)=αLavg(θ)+βLtar(θi)+η(Qi(s,a,θi)-Qavg(s,a,θ))2,Lavg(θ) 為評論家網絡的損失函數平均值,Ltar(θi) 為目標評論家網絡的損失函數值,LMC(θi) 為平均評論家的損失函數平均值。
(12) 更新目標網絡的參數:
θEMA←mθQavg+(1-m)θEMAθQ′avg←nθQavg+(1-n)θQ′avg,θμ′←qθμ+(1-q)θμ′, 其中,θEMA,θQavg,θμ分別為EMA網絡、評論家網絡、策略網絡的權重,m,n,q都是(0,1)之間的浮點數。
(13) end
(14)end
3 實驗部分
為了驗證基于多重指數移動平均評估的DDPG算法的有效性,本文將原始DDPG算法和基于多重指數移動平均評估的DDPG算法分別實驗于經典的Pendulum問題和MountainCar問題,實驗環境為OpenAI gym,為一個開源的仿真平臺。OpenAI Gym是開發和比較強化學習算法的工具包。OpenAI Gym由兩部分組成:①gym開源庫:gym開源庫為用于強化學習算法開發環境,環境有共享接口,用于設計通用的算法;②OpenAI Gym服務:用于對訓練的算法進行性能比較。
3.1 實驗描述
3.1.1 MountainCar 問題
在MountainCar問題中,一輛小車沿著一維軌道行駛,停在了兩座小山之間,小車企圖到達較高的一座山上,然而由于其動力不足不能直接到達山頂,而是需要來回行駛獲取更多的動能,才能到達山頂。如果消耗的能量越少,則回報值越大。圖1給出了Mountain Car問題。
圖1 Mountain Car
狀態為2維狀態,分別通過位置、速度來表示,可以表示為:s=(p,v), 其中p∈[-1.2,0.6],v∈[-0.07,0.07], 動作為1維動作,有3個能夠選擇的動作:向左加速,向右加速,不加速,分別用+1,-1,0表示,即動作a={-1,0,+1}。 一開始,會隨機地給小車一個位置以及速度,小車來回行使的過程中不斷學習。當小車到山頂之后(“星”形標記處),或者是當時間步超1500時,情節會立即結束,重新開始另一個情節。
3.1.2 Pendulum問題
倒立擺是控制方面中的經典問題,鐘擺從一個隨機的位置開始,通過施加一個力(作用力的范圍是[-2,2]),Agent的主要任務為學習到一個最優的策略,使它先擺動起來,最終保持鐘擺直立。圖2給出了Pendulum問題。

圖2 Pendulum
狀態為3維狀態,鐘擺的位置代表其中的2維,速度代表另一維。具體可以表示為:s=(cosθ,sinθ,v), 其中θ∈[-1,1],v∈[-8,8], 動作為1維動作,代表了對鐘擺所施加的力,具體可以表示為:a∈[-2,+2]
3.2 實驗設置
實驗運行硬件環境為Inter(R) Xeon(R) CPU E5-2660處理器、NVIDIA Geforce GTX 1060顯卡、16 GB內存;軟件環境為Windows 10操作系統、python 3.5、TensorFlow_GPU-1.4.0。
對于每個實驗,一些實驗參數是固定的。使用Adam 優化器對神經網絡的參數進行優化,行動者網絡和評論家網絡的學習率分別為2×10-5、 2×10-4, 折扣率為0.99。目標網絡的更新參數為0.01,在探索過程中,方差為0.2的零均值高斯噪聲被加進行動中。對于每個訓練過程包含300個情節,每個情節有15次循環,每個循環中有100個時間步。批處理固定值為64,經驗回放緩沖器是長度為105的循環隊列。在DDPG中,行動者及評論家網絡均含有兩個隱藏層(128個單元),在基于多重指數移動平均評估的DDPG算法中,參數α,β,η分別設置為0.6、0.4、0.05,評論家的個數設置為5。
3.3 實驗結果分析
DDPG算法和指數移動平均的DDPG算法以及基于多重指數移動平均評估的DDPG算法在Mountain Car和Pendulum環境中實驗,實驗結果在本部分詳細說明,并進一步客觀地分析實驗結果。
為了評估評論家的可靠性和穩定性,采用平均回報值進行評估。在DDPG方法、指數移動平均的DDPG方法及基于多重指數移動平均評估的DDPG方法中,agent與獨立環境交互,得到每7個周期的10條路徑的平均獎賞作為性能的評估,損失函數的值顯示了整個訓練過程的收斂性。
DDPG算法、指數移動平均的DDPG算法以及基于多重指數移動平均評估的DDPG算法分別在Pendulum、Mountain Car環境中進行實驗,對于圖中的實驗結果,在兩個實驗中,平均回報值增加然后收斂,損失函數隨著訓練進程的加快直至結束逐漸趨向于0,如圖3(a)、圖3(b)所示,由指數移動平均的DDPG算法獲得的平均回報值在大部分情節遠大于原始DDPG算法所獲得的平均回報值,而加入多評論家的指數移動平均的DDPG算法獲得的平均回報值比指數移動平均的DDPG方法更大,此外,從圖3(a)、圖3(b)中兩幅圖可以很明顯看出,與原始DDPG算法和指數移動平均的DDPG算法相比,基于多重指數移動平均評估的DDPG算法的平均回報值變化范圍最小,因此,基于多重指數移動平均評估的DDPG算法的穩定性和有效性得到了有效的驗證。此外,基于多重指數移動平均評估的DDPG算法中平均回報值突然下降較少且很快回歸正常。在Mountain Car環境中,盡管3種方法的獎賞很相似,但是可以看出在整個路徑中基于多重指數移動平均評估的DDPG算法大部分情節不存在獎賞的突然下降。圖4(a)、圖4(b)所示的平均損失函數也相當不同,從實驗結果可以明顯看出,基于多重指數移動平均評估的DDPG算法的損失函數值相比指數移動平均的DDPG算法更小,且隨著訓練進程的加快更快的趨向于0,驗證了基于多重指數移動平均評估的DDPG算法的收斂性能更好。
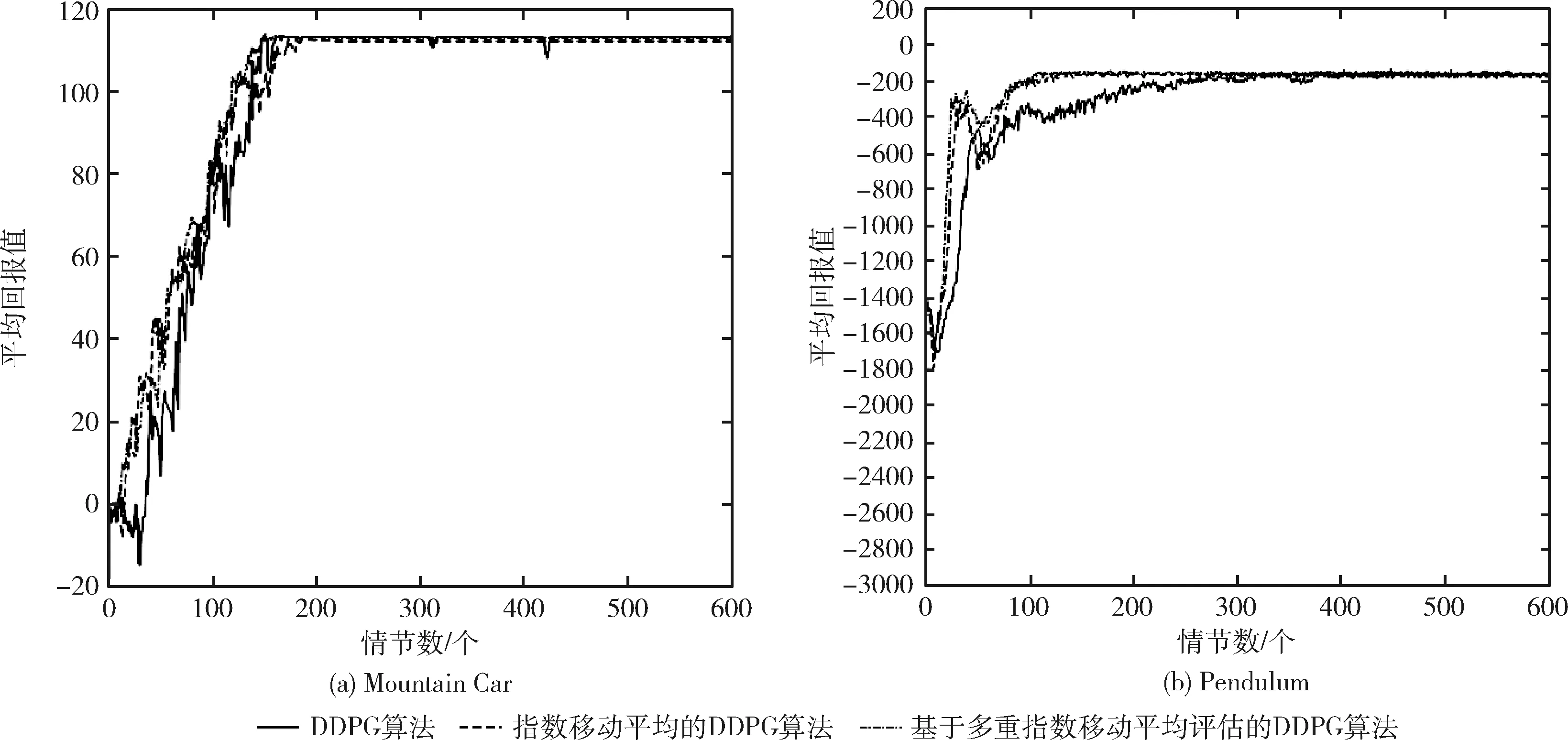
圖3 3種算法的平均回報值實驗對比
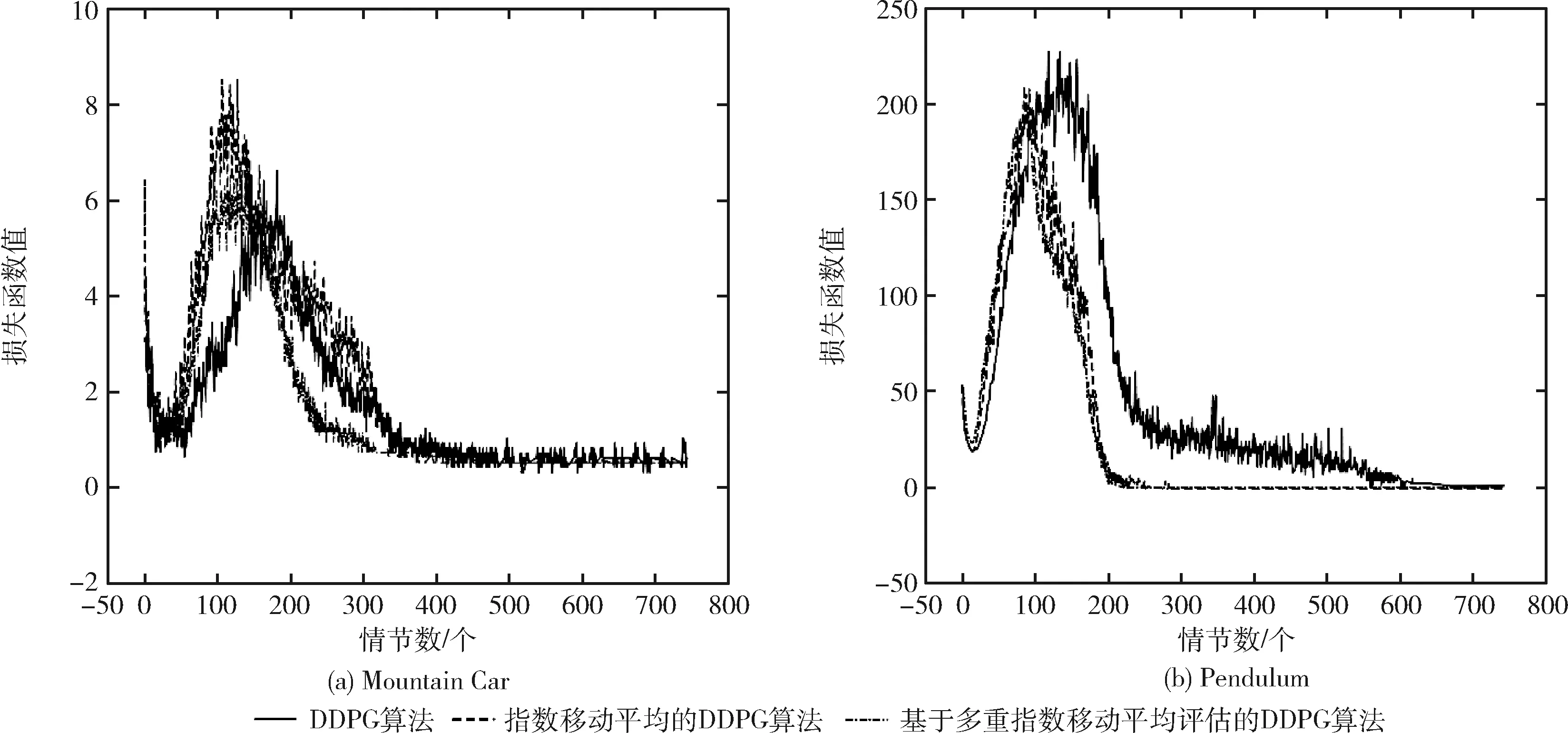
圖4 3種算法的損失函數值實驗對比
對于雙重經驗回放部分,我們將DDPG算法與加入雙重經驗回放的DDPG算法在Pendulum實驗中測試了這部分改進內容。如圖5所示,黑色的虛線部分代表了收斂的近
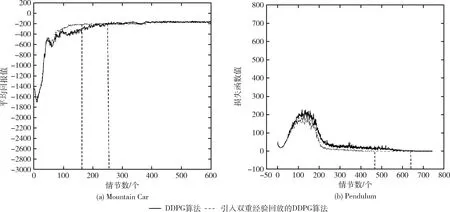
圖5 Pendulum問題中DDPG算法是否引入雙重經驗回放的實驗對比
似時間,由圖5(a)中,可以看出引入雙重經驗回放的DDPG算法在160個情節處逐漸收斂,而原始DDPG算法的收斂時間大致在250個情節,圖5(b)中可以看出引入雙重經驗回放的DDPG算法大致在470個情節收斂,而未引入雙重經驗回放的DDPG算法在630個情節收斂,因此由實驗結果可以明顯可見雙重經驗回放確實加快了訓練的過程。
4 結束語
本文針對DDPG算法雙網絡結構的不穩定性以及單評論家評估不準確的問題,提出基于多重指數移動平均評估的DDPG算法,介紹一種EMA-Q網絡和目標Q網絡合作得出目標更新值,并針對DDPG訓練過程中行動者的學習過于依賴評論家,對多個評論家給出的Q值求平均,多個獨立的評論家網絡可以充分的在環境中進行學習,降低單個評論家的不準確性。樣本池部分引入雙重經驗回放方法,提高算法的收斂性能,實驗結果表明,比傳統的DDPG算法相比,基于多重指數移動平均評估的DDPG算法的收斂性能更好,穩定性更高。
本文主要針對Pendulum和Mountain Car兩個實驗驗證基于多重指數移動平均評估的DDPG算法的性能,從實驗結果可以看出,基于多重指數移動平均評估的DDPG算法的收斂性更好,穩定性更高。但是算法中的超參數的設置均為人工設置,因此在未來的工作中將重在調整損失函數的參數為可訓練的變量,使得算法收斂性更好,穩定性也有所提升。
猜你喜歡
黨課參考(2021年20期)2021-11-04 09:39:46
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小哥白尼(軍事科學)(2019年6期)2019-03-14 05:49:56
黨課參考(2018年20期)2018-11-09 08:52:36
中國蜂業(2018年6期)2018-08-01 08:51:14
數學大世界(2018年1期)2018-04-12 05:39:14
都市麗人(2015年4期)2015-03-20 13:33:22
