基于本福特定律的財政大數據審計驗證方法
2021-10-12 17:27:43吳冬惠
審計與理財 2021年7期
吳冬惠

一、大數據審計背景和意義
隨著信息技術的發展,大數據時代的到來為審計工作帶來了機遇和挑戰。目前國內高度關注大數據技術及其在審計中的應用。2015年8月國務院印發《促進大數據發展行動綱要》。2015年12月中共中央辦公廳、國務院辦公廳印發《關于實行審計全覆蓋的實施意見》指出:創新審計技術方法是實現審計全覆蓋的一個重要手段,要求構建大數據審計工作模式,提高審計能力、質量和效率,擴大審計監督的廣度和深度。因此研究大數據環境下的審計理論與方法具有重要的理論意義和應用價值。本文結合目前大數據的研究與應用現狀,研究基于本福特定律的財務大數據審計驗證方法。
二、本福特定律簡介
1938年,Frank Benford在研究中通過對20 229個隨機數據統計分析發現了本福特定律:以1為首位數字的數的出現概率約為總數的三成,是接近直覺得出之期望值1/9的3倍。推廣來說,越大的數,以它為首幾位的數出現的概率就越低。它可用于檢查各種數據是否有造假。
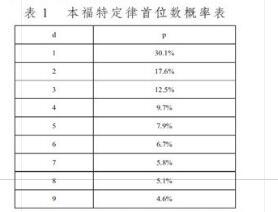
本福特定律的數學定義為:在b進位制中,以數n起頭的數出現的概率為:P=logb(n+1)-logb(n)。在十進制首位數字(1~9)的出現概率(%,小數點后一個位)如表1所示:
需要注意使用條件:(1)數據至少3 000筆以上。(2)數據是自然生成的,不能有人為操控(如設置最大值、最小值等)。
三、基于本福特定律的財務大數據審計驗證方法
大數據環境下,本福特定律有助于審計人員探索、分析和解釋復雜的海量數據,審計人員通過本福特定律,能夠高效辨別被審計數據信息中的異常數據,快速發現問題。
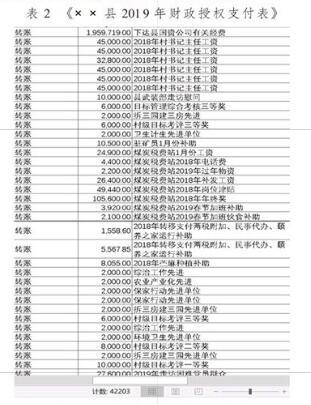
本文以某縣財政局提供的《××縣2019年財政授權支付表》作為實驗測試數據集,該數據集包含42 203行支付記錄(部分數據如表2所示),以表中的支付金額作為測試指標,利用IT審計網(https://www.itshenji.com/)提供的本福特定律測試平臺,來驗證該縣財政支付數據是否有偽造嫌疑。
測試結果如圖1、圖2所示:
實驗結果顯示,測試數據指標中以1~9為首位數的支付金額數出現概率分別為30.7%、18.6%,12.2%、8.7%、8.7%、6.4%、4.9%、4.9%、4.9%,高度符合本福特定律(如圖1所示),偏離度僅為3%(如圖2所示)。
四、總結
大數據時代的到來使得審計工作不得不面臨被審計單位的大數據環境,如何便于審計人員從整體上把握審計大數據情況,快速發現可疑數據,提高審計效率,實現集中分析,分散核查的方式成為大數據環境下開展審計工作的一項重要任務。
本文通過對××縣2019年度財政支付數據進行本福特定律驗證實驗,實驗結果驗證了該數據是自然產生,并未有任何偽造嫌疑。基于本福特定律的大數據審計方法將會成為今后大數據審計的一個重要手段。此外本福特定律還可以結合信息熵等技術應用于醫保和社保大數據審計。
(作者單位:上高縣審計局)
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中國生殖健康(2020年6期)2020-02-01 06:28:50
新世紀智能(英語備考)(2019年12期)2020-01-13 06:07:18
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國生殖健康(2019年11期)2019-01-07 01:28:02
中國生殖健康(2018年6期)2018-11-06 07:09:28
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
