基于灰度共生矩陣和支持向量機的茶葉病害診斷研究*
2021-09-03 10:12:16周文玉
貴州科學 2021年4期
關鍵詞:分類
陳 榮,李 旺,周文玉
(1銅仁學院 大數據學院,貴州 銅仁 554300;2銅仁市為拓網絡技術有限公司,貴州 銅仁 554300)
0 引言
茶葉作為茶農的重要經濟支柱,在當前精準扶貧形勢下是茶農脫貧的重要產業[1]。 消費者更加注重茶葉的品質,“綠色、生態、有機”茶葉成為茶葉市場的新寵兒[2]。然而,因為不能有效地診斷茶葉病害而濫用農藥、化肥,嚴重地影響了茶葉的品質,損失了茶葉市場。因此,對茶葉病害進行正確的診斷對提高茶葉的競爭力極具重要意義。目前,茶葉的診斷主要靠茶農的經驗和植物保護專家的病理知識進行主觀、模糊的判斷[3],缺乏客觀的評估,即便有經驗的專家在診斷茶葉病害時也常常出現錯誤。不同的茶葉病害由于致病的機理不同而使得茶葉病斑具有不同的紋理,因此可以利用提取茶葉病害的紋理特征和支持向量機技術來識別茶葉病害,提高茶葉病害診斷的科學性,促進數字農業的發展。
1 茶葉病害識別模型
1.1 基于灰度共生矩陣的紋理特征構造與提取
特征提取是茶葉病害圖像識別的前提,只有正確地提取出病害的特征才能進行正確的識別。不同的茶葉病害有不同的紋理,灰度共生矩陣是分析紋理特征常用的二階統計方法,描述了灰度空間的相關性,能夠反映出紋理結構的變換[4],是一種區分能力較強的特征。
灰度共生矩陣Pd表示灰度為i和j的兩個像素具有某種空間關系d的情況出現的次數[5]。常用的位置關系有0°、45°、90°、135°,也就是說不同的位置關系可以確定不同的灰度共生矩陣[6],進而不同的病害有不同的紋理特征。因此,本研究采用灰度共生矩陣提取了以下5種紋理特征。
1.1.1 對比度(Contrast)
對比度描述了紋理溝紋的深淺程度;值越大,紋理的溝紋越深,圖像越清晰。計算公式:
(1)
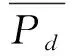
1.1.2 相關性(Correlation)
相關性描述了相鄰像素間灰度的線性關系,即像素間的相似度;當灰度共生矩陣中各元素的值相差越大,則相關性就越小。計算公式:
(2)
1.1.3 能量(Energy)
能量描述了圖像灰度分布的均勻程度;當灰度共生矩陣中各元素的值相差越大,則能量就越大。計算公式:
(3)
1.1.4 熵(Entropy)
熵是紋理圖像的信息度量,描述了圖像紋理的非均勻程度和復雜度;值越大,紋理越復雜。計算公式:
(4)
1.1.5 同質性(Homogeneity)
同質性描述了圖像的局部平滑性。計算公式:
(5)
1.2 支持向量機算法
支持向量機(Support Vector Machine,SVM)是一種分類性能好的分類識別技術,能夠兼顧訓練誤差和測試誤差,能夠有效地解決小樣本、高維、非線性等方面的識別問題[7]。
對于線性可分的問題,可以被一個分類線(二維空間)或分類面(多維空間)無差錯的分開,使分類間隔最大的分類線(面)為最優分類線(面)。如圖1(a)所示。設線性可分的樣本集{(xi,yi),i=1,2,…,N;j=1,2},求出最優分類判決函數為[8]:
(6)
式中,α*為支持向量對應的拉格朗日乘數;b*為分類閾值;x為待分類的測試樣本;xi(i=1,2,…,N)為N個訓練樣本。
對于線性不可分的問題,如圖1(b)所示。允許個別樣本分類錯誤近似實現可分,權衡考慮最大分類間隔和最小錯分樣本數,引入正松弛項ξi和代價系數C兩個參數,最終求出最優分類判決函數與式(6)同。
對于非線性可分的問題,如圖1(c)所示。利用核函數將低維空間中的非線性問題轉換到高維空間中的線性可分問題,在高維空間中求最優分類面。求出最優分類判決函數為[9]:
(7)
式中,α*、b*、x、xi與式(6)同;SV為支持向量的集合。
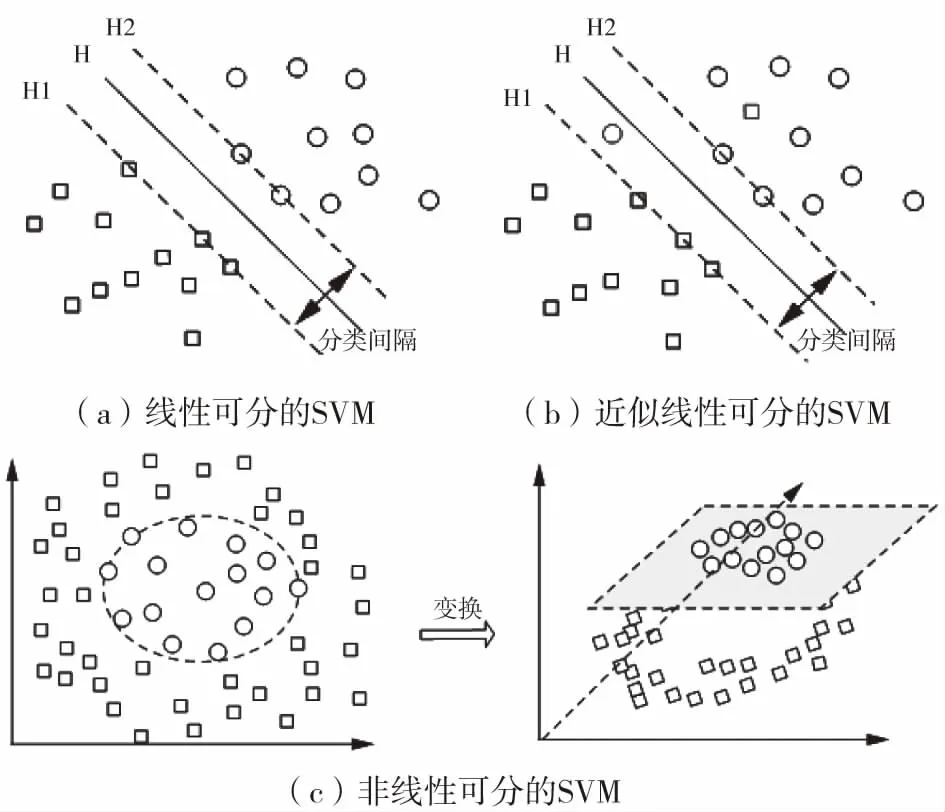
圖1 不同情況下的SVM分類識別模型Fig.1 SVM classification and recognition modelsunder different conditions
茶葉病害的識別屬于多特征的非線性可分問題,不同的核函數表現不同的SVM算法,對茶葉病害的正確識別有比較大的影響。常用的核函數為[10]:
1)線性核函數(Linear):
K(x,y)=x·y
(8)
2)多項式核函數(Polynomial):
K(x,y)=[γ(x·y)+c]d
(9)
式中,d為確定映射空間的維度。
3)徑向基核函數(RBF):
(10)
4)Sigmoid核函數:
K(x,y)=tanh[γ(x·y)+c]
(11)
2 材料與方法
2.1 茶葉病害圖像獲取和處理
貴州省梵凈山區茶葉資源極其豐富,有野生茶樹,有實生茶樹,也有無性系茶園,非常利于茶葉病害樣本的采集,采集時間為3月至5月早晨6∶00~8∶00的生長旺盛、病癥明顯的時間段,自然光照條件下采用Canon G35X110Z數碼相機進行采集,圖像大小為2200×1836像素,存儲格式為JPG,采集了茶炭疽病、茶餅病和白星病3種較為常見的病害3×60共180幅圖片,從每種病害中分別選取包含病斑、大小為90×90dpi的子圖像80幅。
由于紋理特征是灰度圖像在空間以一定形式變換產生的圖案,因此在提取紋理特征前需要對采集的彩色圖像進行灰度處理;為了抑制噪聲對圖像質量的影響,要對病害圖像進行中值濾波平滑處理。如圖2所示。
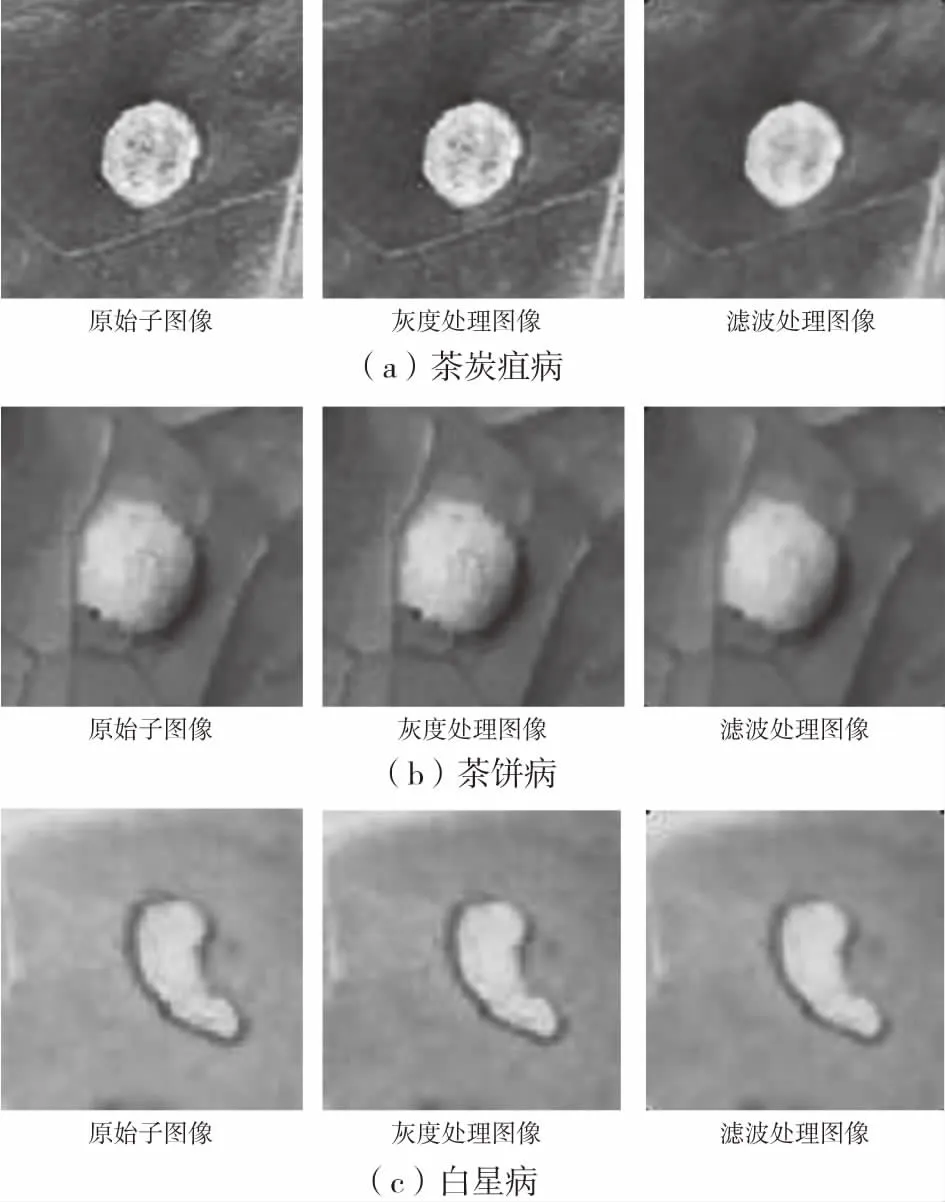
圖2 茶葉病害圖像預處理Fig.2 Preprocessing of tea disease images
2.2 實驗工具的選擇和SVM多分類識別器的建立
采用Matlab 8.0實現編程,采用Matlab圖像處理工具箱進行圖像處理。Matlab SVM工具箱主要通過svmtrain()函數實現識別模型的訓練和svmclassify()函數實現模型的分類識別功能。但是它是一個二分器,只能用于兩類樣本的識別,為了解決多類樣本的識別問題,本研究提出投票最大策略建立SVM多分類識別器。算法如下:
1)將茶炭疽病、茶餅病和白星病3類樣本兩兩組成訓練集,得到3個SVM二分類器,即(炭疽病,茶餅病)、(炭疽病,白星病)、(茶餅病,白星病)。
2)將炭疽病、茶餅病和白星病3類樣本的票數初始化為0。
3)將測試樣本x使用(炭疽病,茶餅病)分類,如果分類器將x判定為炭疽病,則炭疽病的票數增1,否則茶餅病的票數增1;將測試樣本x使用(炭疽病,白星病)分類,如果分類器將x判定為炭疽病,則炭疽病的票數增1,否則白星病的票數增1;將測試樣本x使用(茶餅病,白星病)分類,如果分類器將x判定為茶餅病,則茶餅病的票數增1,否則白星病的票數增1。
4)最后,計算將測試樣本x分別判定為炭疽病、茶餅病和白星病的票數,誰的票數最大,該測試樣本x就最終判定為該類病害。
3 結果與分析
3.1 不同核函數的SVM識別性能
從每種茶葉病害的紋理特征數據中隨機選取100個樣本作為訓練集、30個樣本作為測試集。上述5種紋理特征作為特征向量,分別采取徑向基核函數、線性核函數、Sigmoid核函數、多項式核函數的SVM。訓練參數設置:松弛項ξi=0.0038、代價系數C=26,其中:RBF核函數中的γ=1/3;Sigmoid核函數中γ=1/2,c=1;Polynomial核函數中的d=3,γ=1,c=1。識別結果如表1。
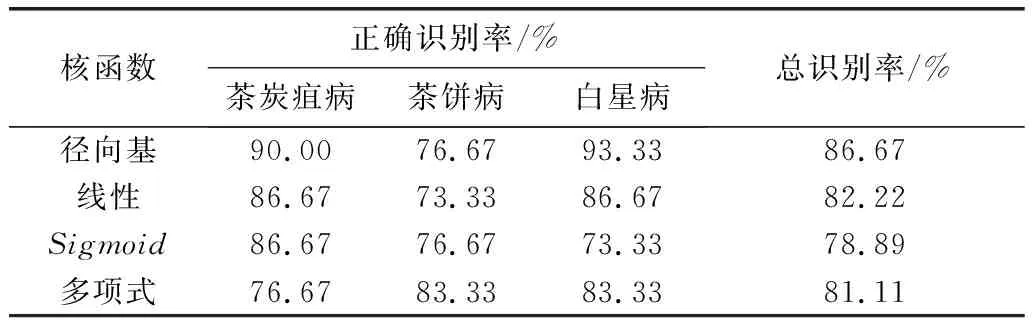
表1 不同核函數的SVM識別性能Tab.1 Recognition performance of SVM based ondifferent kernel functions
實驗結果表明:不同核函數的SVM識別性能不同。徑向基核函數對茶葉病害的識別性能最好,總識別率達到了86.67%,線性核函數和多項式核函數稍差,Sigmoid核函數的性能最低。所以,徑向基核函數的SVM比較適合于茶葉炭疽病、茶餅病和白星病紋理特征下的識別。
3.2 不同訓練樣本數的SVM識別性能
從每種茶葉病害的紋理特征數據中隨機選取120、90、60、30個樣本作為訓練集,每種茶葉病害另外分別選取30個作為測試集。采取徑向基核函數的SVM型,識別結果如表2。訓練參數設置:松弛項ξi=0.0038、代價系數C=26,RBF核函數中的γ=1/3。
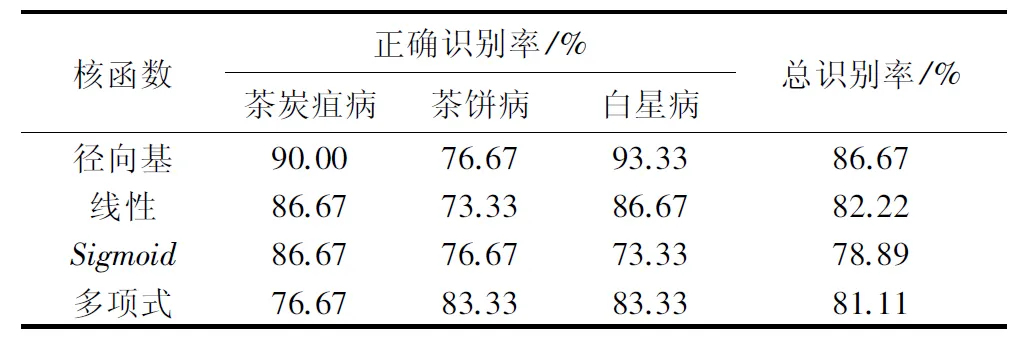
表2 不同訓練樣本數的SVM識別性能Tab.2 Recognition performance of SVM based ondifferent numbers of training samples
從表2可以看出,不同訓練樣本數的SVM識別性能不同。當訓練樣本在120和90的時候,識別率差別不是很大,都有比較高的識別率;當訓練樣本減到60和30的時候,識別率稍微下降,還在可以接受的范圍內。這表明減少訓練樣本數對識別結果的影響不是很大,SVM穩定性好,在解決小樣本分類的問題上有獨特的優勢。這是因為訓練樣本數快速的減少對支持向量數(即圖1(a)(b)中H1和H2上面的樣本點數)的減少影響比較小,只要樣本中占少數的支持向量不變,分類模型基本保持不變,不會嚴重的影響到最優分類面,即分類判決正確率不會有太大的變化。
4 結論與展望
本文利用紋理特征和SVM的識別方法對茶葉病害進行識別,以灰度共生矩陣構造了5個紋理特征參數,茶葉病害識別結果表明:以對比度、相關性、能力、熵和同質性為紋理特征比較適合于茶葉病害的識別,識別率比較高;RBF核函數的SVM識別性能最好;SVM識別方法比較適合于訓練樣本數較少的病害識別。
本文以Matlab 8.0作為數據處理工具,對茶葉病害的SVM識別方法進行編程和實驗,不能做到在茶園中實時識別。采用Python語言進行算法編程并移植到機器中以對茶葉病害進行實時診斷,促進機器學習和人工智能在農作物病害識別中的應用,這將是以后研究的重點。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
