基于GoogLeNet改進模型的蘋果葉病診斷系統設計*
2021-08-13 09:47:34宋晨勇白皓然孫偉浩馬皓冉
中國農機化學報 2021年7期
關鍵詞:模型
宋晨勇,白皓然,孫偉浩,馬皓冉
(青島農業大學機電工程學院,山東青島,266109)
0 引言
2018年,蘋果的全球貿易量達到了5 000 kt,年人均消費量8.2 kg,是消費量最大的水果之一[1]。近年來,由于病原體的變種以及蘋果保護措施的不足,蘋果病害的種類數量逐漸增加。而傳統的基于知識庫的專家系統在處理復雜多變的自然數據過程中有著局限性,隨著農業信息化和物聯網的發展,通過葉片外觀和視覺癥狀識別蘋果疾病的病變自動診斷系統將會在規模化農業生產中得到越來越多的關注。
從20世紀80年代開始,計算機視覺技術在作物病蟲害識別領域中得到了廣泛研究和發展[2-7]。張靜等[2]采用葉片紋理特征提取識別黃瓜斑疹病和角斑病。隨著計算機視覺技術和機器學習理論的逐漸完善,科研工作者運用判別式分析方法、匹配方法和機器學習方法進行植物病害分類識別,取得了良好效果。胡小平等[3]利用BP網絡預測小麥條銹病的嚴重程度,獲得了較高的準確率。以上研究在提取病斑圖像的特征參數方面,大多是以提取單變量特征參數為主,因此在識別效率方面尚待提高。
伴隨著數據的爆炸增長和計算機硬件的發展,深度學習在圖像識別領域取得了巨大進步,擴大了精準農業領域的計算機視覺范圍。大量的學者將深度學習理論應用到農作物病害識別的研究中,取得了良好的效果[8-15]。王細萍等[8]利用深層架構卷積神經網絡和時變沖量學習相結合進行多階段特征融合,并取得了良好的效果。楊國亮等[12]的研究通過參數指數非線性(PENL)函數改進殘差網絡,在一定程度上提高植物病害的識別準確度。這些研究取得了較好的效果,但沒有考慮模型中大量的網絡參數導致模型響應時間過長的問題。因此,設計出一種能優化低延遲和高識別率之間關系的識別模型在蘋果農業實際生產具有重要意義。
本文以蘋果為研究對象,利用機器學習理論,圍繞蘋果病害診斷進行了系統性研究,從減少網絡參數數量和訓練收斂時間著手,提出了基于深度學習的GoogLeNet改進模型,優化低延遲和高識別率之間關系,以期提高以蘋果葉銹病和斑點落葉病為例的蘋果病害的識別準確率,實現蘋果病害實時、便利的圖像自動識別,為蘋果病害防治防控提供一種可行的診斷方法。
1 樣本采集與處理
本文分析了數據集的特征,并使用基于幾何變換和圖像操作的數據增強方法,對數據集進行了預處理。數據增強整體過程如圖1所示。
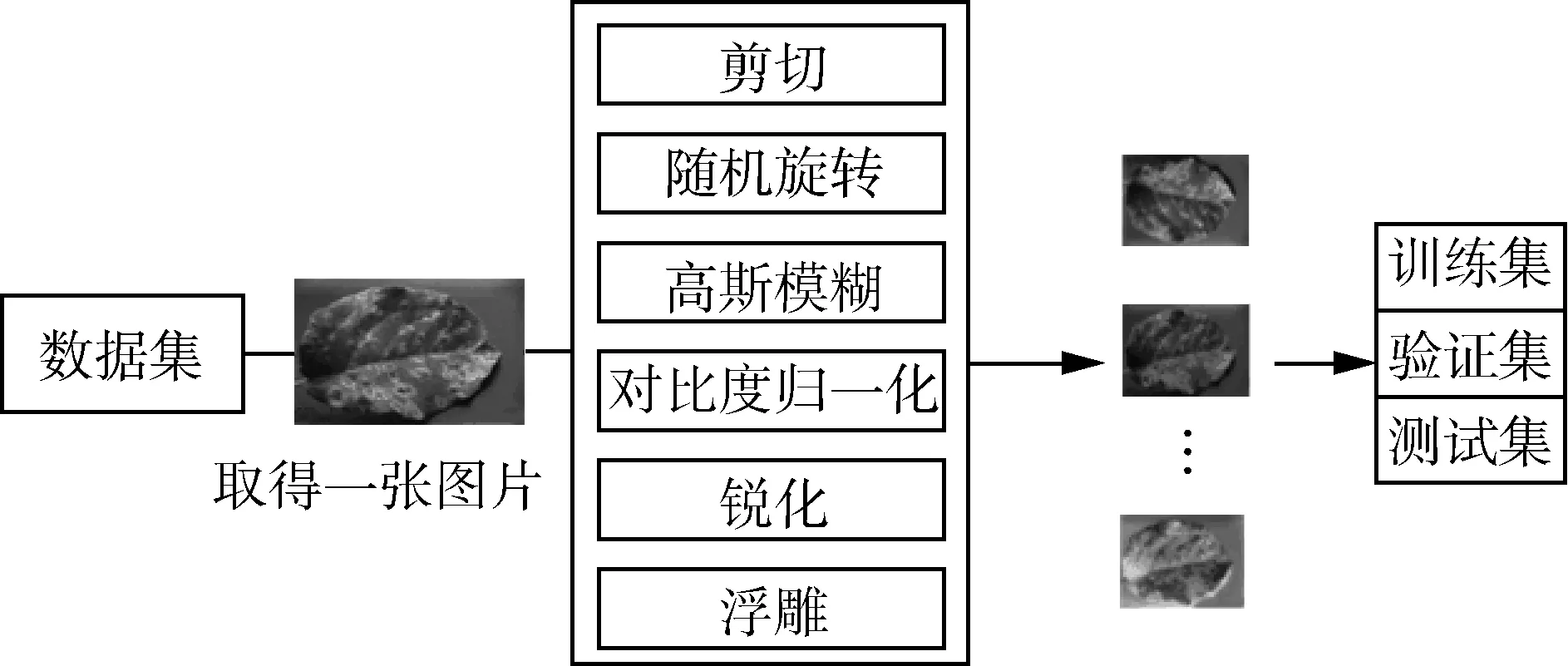
圖1 數據增強整體過程Fig. 1 Data enhancement process
1.1 樣本采集
通過人工拍攝,并借助百度圖片、谷歌等不同網站來源共采集了100幅圖像,其中包括不同時期的正常蘋果葉片、蘋果銹病葉片及蘋果斑點落葉病葉片的圖片,如圖2所示。

(a) 正常蘋果葉片

(b) 蘋果銹病葉片

(c) 蘋果斑點落葉病葉片圖2 正常蘋果葉片與有病狀葉片圖Fig. 2 Images of normal and diseased apple leaves
網絡來源的所有圖片都是通過Python腳本進行下載,下載圖片全部經過人工篩選,并且請相關專家對篩選圖像進行了多次評估,確保了樣本標簽的準確性。
1.2 圖像處理
1.2.1 數據增強
隨著訓練數據集的擴展,深度卷積神經網絡的性能將進一步提高[16]。為了擴大樣本數量,保證模型訓練對數據的需求,故對已采集圖片進行數據增強處理。通過隨機旋轉、裁剪圖像,銳化圖像,隨機噪聲變換和模糊等變換,或改變圖片對比度等方法擴展圖像數據,具體方法如表1所示。蘋果葉病圖像數據增強情況如表2所示,增強圖片具體示例如圖3~圖5所示。

表1 圖像數據增強方法說明Tab. 1 Description of image data enhancement methods

表2 蘋果葉病原始圖像數據和擴展后的圖像數據分布情況Tab. 2 Number of apple leaf original images data andenhanced images data

(a) 原圖

(b) 裁剪

(c) 旋轉

(d) 銳化

(e) 模糊

(f) 噪聲變換

(g) 改變對比度圖3 經過不同方法處理的正常蘋果葉片圖像Fig. 3 Normal apple leaf image processed by different methods

(a) 原圖

(b) 裁剪

(c) 旋轉

(d) 銳化

(e) 模糊

(f) 噪聲變換

(g) 改變對比度圖4 經過不同方法處理的蘋果銹病圖像Fig. 4 Apple rust images processed by different methods

(a) 原圖

(b) 裁剪

(c) 旋轉

(d) 銳化

(e) 模糊
(f) 噪聲變換

(g) 改變對比度圖5 經過不同方法處理的蘋果斑點落葉病圖像Fig. 5 Images of apple spotted leaf disease processed by different methods
1.2.2 數據集制作
在數據增強之后共9 905張圖像,其中將絕大部分數據用作GoogLeNet模型的訓練和驗證,少量數據用作模型測試,GoogLeNet模型和改進模型的訓練集,驗證集和測試集的比例約為50∶10∶1。數據集具體分配情況如表3所示。

表3 GooLeNet模型的數據集分布情況Tab. 3 Data set distribution of GoogLeNet model
1.2.3 圖像預處理
在劃分數據集后,為了改善模型特征提取性能,必須對葉片圖像進行預處理。首先對圖像進行標準化操作,減少由于陽光強度變化引起的顏色變化,降低過擬合風險。并且在定位準確、圖像完整的情況下根據葉片在圖像中的位置直接進行標準切割,減少試驗中圖像因采集方式或者拍攝距離的差異所導致的誤差。GoogLeNet改進模型使用299×299的標準切割圖片,具體效果如圖6所示。
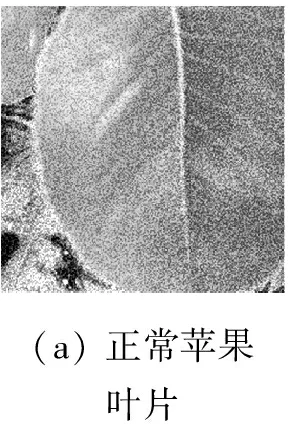
圖6 預處理后的299×299蘋果葉片圖
圖片切割操作是由基于OpenCV框架的Python腳本自動計算,最后利用基于Tensorflow框架的Python腳本生成GoogLeNet改進模型的數據文件。
2 模型改進及測試
2.1 GoogLeNet模型介紹
GoogLeNet結構有22層,由于網絡層次數量,神經元數量和訓練數據的增加,GoogLeNet模型具有比以前的深度學習結構更多的特征[17]。GoogLeNet模型使用稀疏網絡結構來改善過度擬合和過度占用內存的缺點,它使用金字塔模型來增加寬度,并提出“初始模塊”的概念,“初始模塊”的主要思想是指由一系列易獲得的稠密子結構來近似和覆蓋卷積網絡的局部稀疏結構。GoogLeNet結構中共使用了11個初始模塊,3個分類器。每個初始模塊包括多個平行卷積層,并且采用最大池化層用于同時捕獲不同的特征,并且將任意n×n的卷積核都分解成兩個1×n,n×1的一維卷積核,如圖7所示。1×1卷積核實現了卷積核跨通道的交互和信息整合,并通過卷積核通道數的降維或升維,使模型網絡結構更緊湊,參數數量顯著地減少[18]。
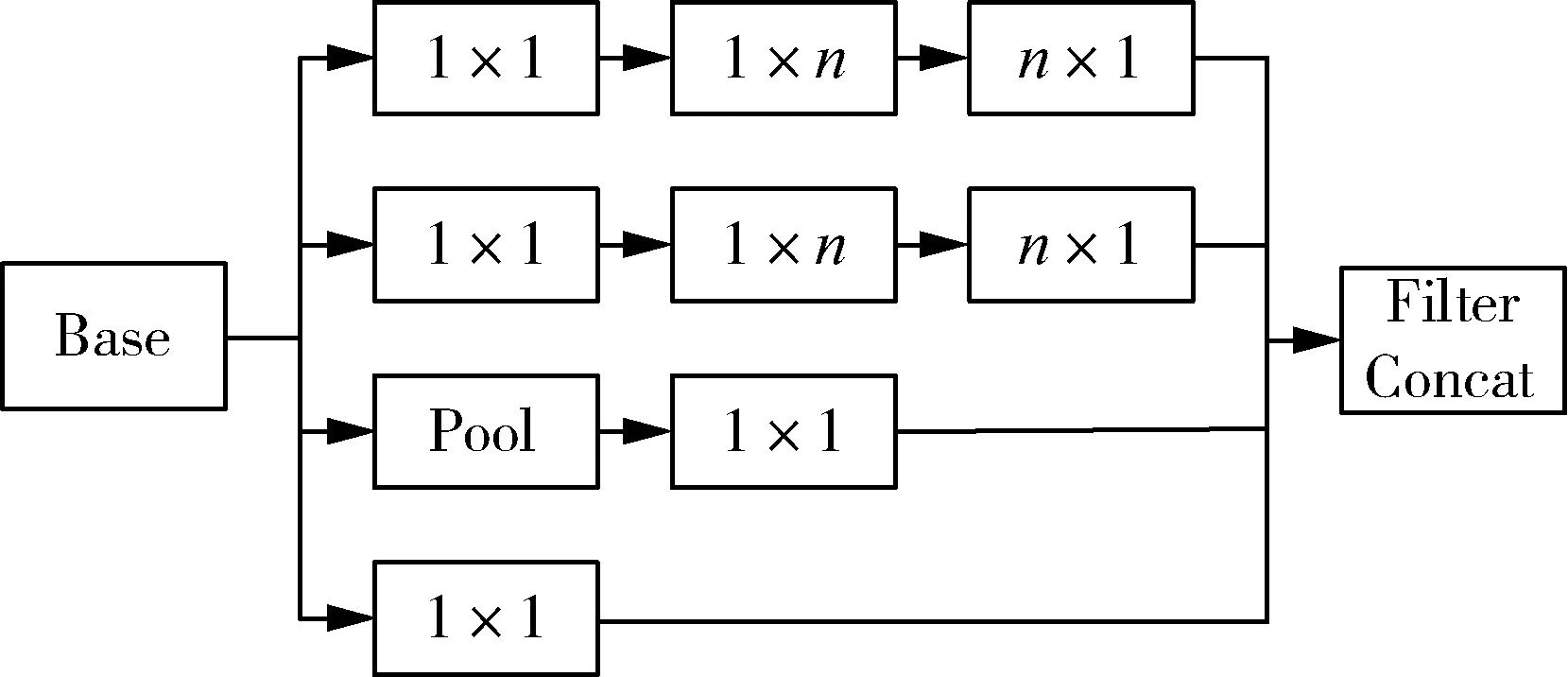
圖7 1×n和n×1卷積核的Inception結構Fig. 7 Inception structure of 1×n andn×1 convolution kernels
2.2 GoogLeNet模型改進
為了使模型更適應樣本數據集,通過綜合衡量模型性能和參數數量尋找初始模塊和分類器數量的最佳組合。GoogLeNet改進模型使用了1個分類器和4個初始模塊,模型結構如圖8所示。
模型采用隨機梯度下降(Stochastic gradient descent,SGD)算法進行優化。模型的超參數設置如表4所示。其中 GoogLeNet改進模型的初始學習率都比原模型縮小10倍,分別為0.001,GoogLeNet改進模型批次容量為GoogLeNet模型的2倍。
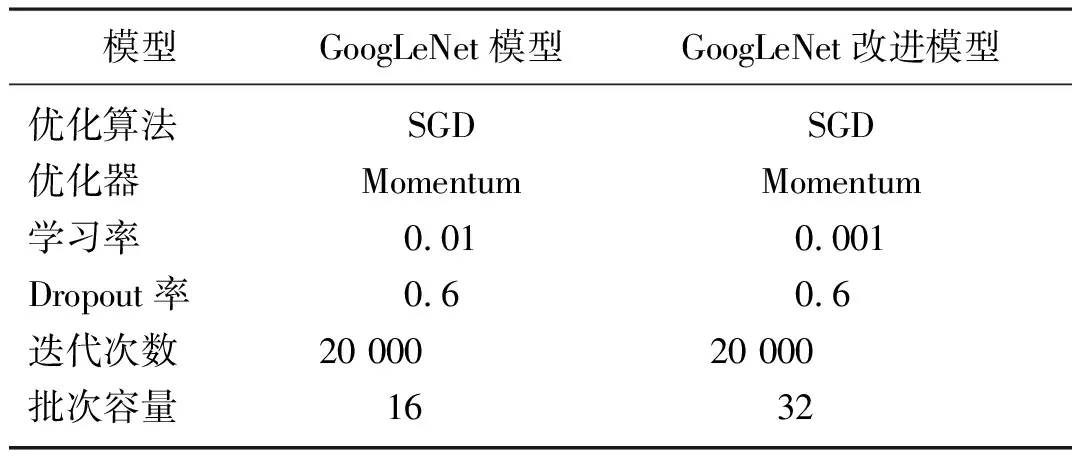
表4 GoogLeNet、GoogLeNet改進模型的超參數設置Tab. 4 Hyper-parameter settings ofGoogLeNet, improved GoogLeNet

圖8 GoogLeNet改進模型結構Fig. 8 GoogLeNet improved model structure
2.3 模型測試與分析
在計算機上通過Tensorflow框架,Pycharm開發環境和Python語言訓練和測試模型。Tensorflow框架是Google用于數據流圖的數值計算開源軟件庫,其已經成功實現了深度學習算法,實現了異構分布式系統上大規模高效率的學習。Tensorflow為模型培訓,測試和調整參數提供了完整的工具包,部署模型可以在中央處理單元(CPU)和圖形處理單元(GPU)上運行。NVIDIA cuDNN是用于深度神經網絡的GPU加速庫。它強調性能、易用性和低內存開銷,將Tensorflow與cuDNN庫集成可以大幅提高CNN模型訓練速度。
GoogLeNet原模型的初始學習率為0.01,優化器動量為0.9,損失函數使用對數損失函數。為了使模型測試結果更有說服力,本研究分別使用準確率,精準率,召回率,F1值衡量模型的性能。準確率,即提取出的正確樣本數與總樣本數之比,經過第20 000次迭代后,GoogLeNet原模型驗證集準確率為98.1%,損失值為0.77,如圖9所示。GoogLeNet改進模型的驗證集準確率為98.3%,損失值為0.04,如圖10所示。
精準率是正確的正例樣本數與預測為正例的樣本數的比值,召回率是正確的正例樣本數與樣本中的正例樣本數的比值,F1值為正確率和召回率的調和平均值。GoogLeNet模型與改進模型的精準率,召回率,F1值測試結果如表5所示。

(a) 損失值曲線圖

(b) 準確率曲線圖圖9 GoogLeNet模型的測試集損失值和準確率Fig. 9 Validation set loss and accuracy ofthe GoogLeNet model

(a) 損失值曲線圖

(b) 準確率曲線圖圖10 GoogLeNet改進模型的測試集損失值和準確率Fig. 10 Validation set loss and accuracy ofGoogLeNet improved model
GoogLeNet模型與改進模型的平均準確率只相差0.2%。在精準率方面,GoogLeNet改進模型比原模型提高了2.1%,召回率上,GoogLeNet改進模型比原模型提高了1.2%,在銹病上的召回率提高了4.0%,在F1值方面,GoogLeNet改進模型比原模型提高了1.7%,這表明改進模型有效地提升了模型的性能。

表5 GoogLeNet模型和GoogLeNet改進模型對比結果Tab. 5 Comparison results of GoogLeNet model andGoogLeNet improved model
在運行時間上,相同運行環境下,兩個模型的運行時間差異卻很明顯,GoogLeNet模型的訓練時間需要大約4.5 h,GoogLeNet改進模型的訓練時間大幅減少,只需要大約2.5 h,減低了44.44%,并且GoogLeNet改進模型的模型參數僅為GoogLeNet模型的17.5%,表明模型運行時間的大幅降低得益于模型參數數量的減少,具體如表6所示。改進的GoogLeNet模型在保持模型識別性能的前提下降低了網絡參數數量,提高了模型的訓練和識別效率。

表6 GoogLeNet原模型以及改進模型的參數數量及分布Tab. 6 Number and distribution of parameters of theoriginal GoogLeNet model and the improved model
3 系統設計與實現
病害識別系統主要由用戶登錄模塊、賬號注冊模塊、圖像識別模塊、識別記錄日志模塊四個模塊組成。病害識別系統設計具體流程如圖11所示。

圖11 病害識別系統設計圖Fig. 11 Design diagram of disease identification system
3.1 系統技術與開發環境
病害識別系統技術路線由卷積神經網絡和Torndao框架兩部分構成,在模型構建上采用Tensorflow框架構建病害識別網絡,Python語言進行樣本標識和處理,使用sqlite3和peewee數據庫存儲數據。在網絡視圖上基于python、html、javascript和CSS(Cascading Style Sheets)構建網頁服務端,使用Torndao框架進行系統前后端交互,系統技術路線如圖12所示。

圖12 蘋果病害圖像在線識別系統技術路線圖Fig. 12 Apple disease image online recognitionsystem technical route
3.2 病害識別系統的具體實現
病害識別系統的用戶登錄模塊使用render的方法引入編寫的登錄靜態網頁login.html,并將登錄用戶名字“loginUsername”和登錄密碼“loginPassword”分配給當前訪問用戶的用戶名“Username”和密碼“Password”變量,并通過json進行數據轉換,默認返回響應碼“200”則表示“登錄成功”,如果默認返回響應碼“500”則表示“用戶名或密碼錯誤”,并以同樣的形式設置了賬號注冊模塊。
在圖像識別模塊中,主要包括模型導入、圖片上傳及處理、圖像識別、識別結果呈現等四個部分,具體實現流程為注冊登錄完成后界面會顯示提取照片,手動輸入需要辨別的蘋果病害圖像,網頁中會顯示圖片中植物的病狀,并且給出葉片患病的概率。在模型導入中將訓練好的GoogLeNet模型參數文件使用load_weights函數導入,并使用compile函數編譯參數文件。在圖片上傳部分中,網頁前端使用form表單的形式進行上傳,并在網站后端調用Image庫讀取圖片數據,利用Image.new函數創建一幅給定模式和尺寸的圖片,以適應圖片識別模型的要求,判斷獲取上傳圖片的尺寸與創建圖片是否一致,若不一致則使用Image.resize函數對圖像進行填充或裁剪,并且將修改圖片格式統一轉換為RGB格式,最后利用paste函數將轉換好的圖片粘貼匹配到創建的圖像上。最后得到的圖片識別結果將會存放在本地文件夾件中,并在網頁前端羅列出病害的可能性。
在識別記錄日志模塊中,網頁將會記錄每一次的病害識別結果,通過對識別結果的簡單統計以幫助果農了解果樹生長狀況,減小經濟損失。
3.3 系統測試
為了測試系統的穩定性和準確性,故從待測圖片中隨機挑選圖片進行測試,測試界面及結果如圖13所示,測試結果顯示葉片患有蘋果斑點落葉病的概率為80.1%。
通過對測試集150張圖片進行評估,葉片測試的平均準確率達到了96.0%,詳細測試結果如表7所示,圖14是部分葉片測試過程的識別記錄。經過評估,系統表現出了良好的穩定性,并且實現了對蘋果葉病的準確識別。
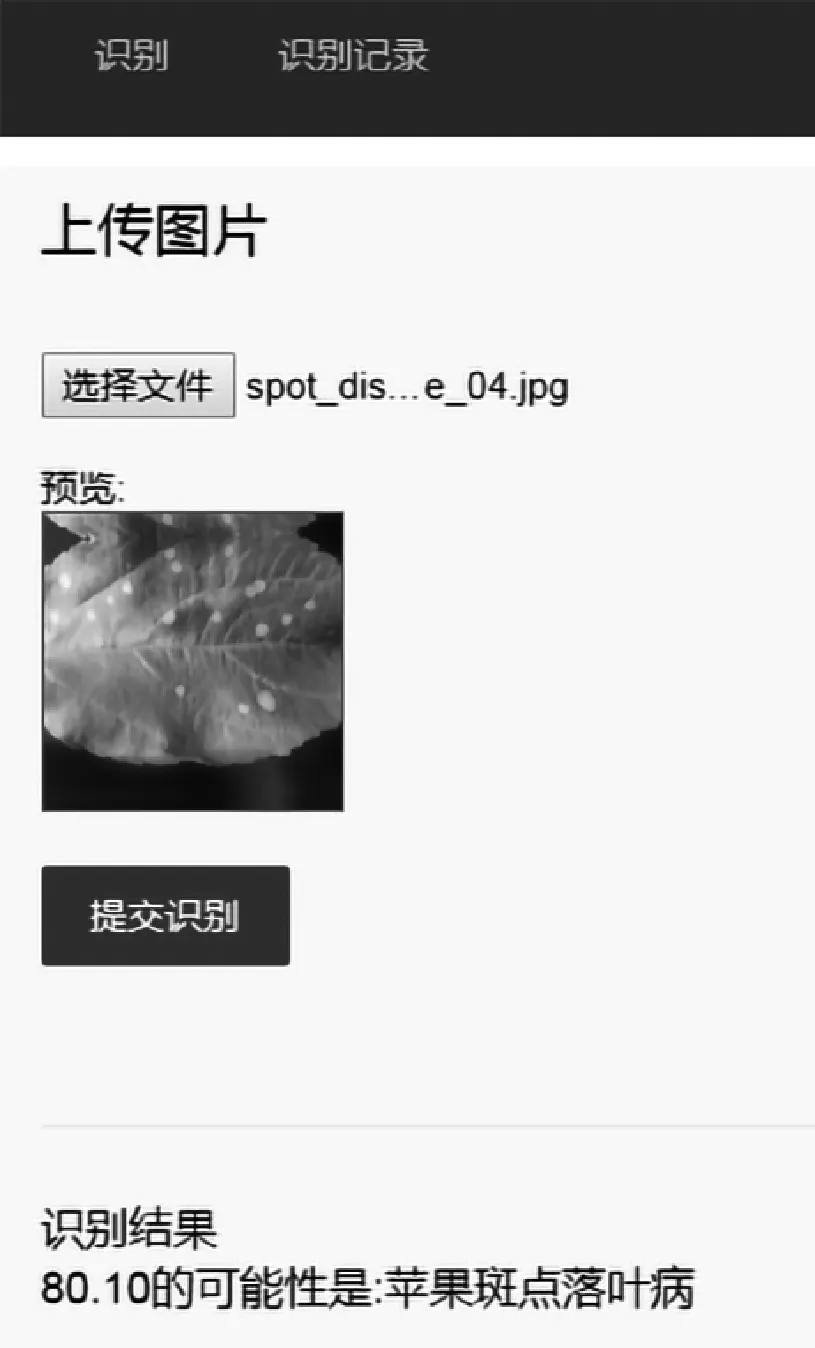
圖13 預測分析界面Fig. 13 Analysis interface

表7 測試結果Tab. 7 Test results

圖14 識別記錄模塊視圖Fig. 14 View of the recognition record module
4 結論
本文對基于深度學習的卷積神經網絡改進模型用于蘋果葉病識別進行了研究并得到了以下的結論與成果。
1) 在識別蘋果正常葉片、銹病葉和斑點落葉病葉片的過程中,本研究在GoogLeNet模型的Inception結構基礎上建立了改進模型,并使用四種指標(準確率,精準率,召回率,F1值)綜合衡量模型的性能。實驗結果表明,GoogLeNet改進模型的精準率,召回率,F1值比原模型分別提高了2.1%,1.2%,1.7%,并且GoogLeNet改進模型的識別精準率達到98.3%,具有良好的穩定性和泛化能力,在蘋果病害識別中具有明顯優勢。
2) 新模型減少了inception模塊上的數量,在模型前段增加了卷積層和池化層的數量,極大的減少模型的參數數量,減小了模型過擬合的風險。實驗結果表明GoogLeNet改進模型的訓練時間比原模型減低了44.44%,并且GoogLeNet改進模型的模型參數僅為原模型的17.5%,模型文件占用的設備內存明顯減少,提升了模型的響應速度。
3) 基于Tornado框架建立了蘋果病害識別系統,建立了用戶登錄模塊、賬號注冊模塊、圖像識別模塊、識別記錄日志模塊四個模塊,并對系統進行測試,結果表明葉片測試的平均準確率達到了96.0%,系統表現出良好的穩定性,并實現了對蘋果銹病,斑點落葉病的準確識別。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
