大數據戰略、知識管理能力與中國企業創新
2021-06-02 09:48:10
產經評論 2021年2期
一 引 言
隨著新一代信息技術在經濟社會各領域的深度融入,以及移動互聯網技術的不斷發展推動,社會信息化進程進入大數據時代,數據量呈現爆發式增長,數據資源已成為國家重要的戰略資源和核心創新要素。據國際權威機構Statista調查和預測,2020年全球大數據市場的收入規模將達到560億美元。我國在“十三五”規劃建議中明確提出:“實施國家大數據戰略,推進數據資源開放共享。”充分釋放和利用海量數據資源的價值,總結提煉數據中蘊含的規律和經驗,預測經濟社會發展的趨勢并提供決策輔助,將使社會經濟發展發生重大變革,同時推動新一代信息技術與各行業的深度耦合和交叉創新,為國家發展帶來戰略性機遇(1)來源于國務院印發的《促進大數據發展行動綱要》(國發〔2015〕50號)。。
創新是知識經濟的重要特征。大數據的研究和應用通過海量數據特征和關聯關系的抽取,可以與不同產業相融合,挖掘和分析行業與領域內有價值的數據,獲得用戶行為信息,發現市場機會,提升信息技術水平,從而促進創新,驅動整體經濟良性增長。鑒于大數據對創新和經濟發展的潛在影響,美國、日本、歐盟等經濟體都將大數據視作戰略資源,并將大數據提升為國家戰略。2014年,我國在政府工作報告中首次提出了“大數據戰略”,接著在2015年和2016年分別發布了《國務院關于印發促進大數據發展行動綱要的通知》、《國務院關于印發“十三五”國家戰略性新興產業發展規劃的通知》和《大數據產業發展規劃(2016-2020年)》等文件,明確指出大數據是新一代信息技術產業的重要構成和基礎,并提出要“形成若干創新能力突出的大數據骨干企業,培育一批專業化數據服務創新型中小企業,培育10家國際領先的大數據核心龍頭企業和500家大數據應用及服務企業。形成比較完善的大數據產業鏈,建設10-15個大數據綜合試驗區,創建一批大數據產業集聚區,形成若干大數據新型工業化產業示范基地”。
政策效應是學術界的研究熱點,例如“營改增”政策對產業結構、宏觀經濟(陳釗和王旸,2016)[1]及企業價值的影響(王桂軍和曹平,2018)[2],財政支出政策的社會經濟效應(李娜等,2018)[3],國家生態工業示范園政策對城市工業部門高質量發展的促進作用(周鳳秀和溫湖煒,2019)[4],戰略性新興產業政策對企業創新的促進作用(邢會等,2019)[5]等。現有對我國大數據戰略效應的研究較少,喻煒和王鳳生(2016)[6]構建了由企業、消費者和政府組成的三階段子博弈精煉納什均衡模型分析大數據戰略問題。此外還有對主要發達國家大數據政策的對比研究(張勇進和王璟璇,2014)[7],以及對大數據政策的文本量化研究(周京艷等,2016)[8]。綜上可見,鮮有針對大數據戰略的定量分析,本文擬采用DID和機器學習方法,基于2013-2018年我國宏觀經濟數據和上市公司信息,審視大數據戰略對中國企業創新產出的效應和影響機制,探討大數據產業發展過程中的關鍵因素。
二 研究假設
(一)大數據戰略對企業創新產出的激勵效應
2016年,國務院在《“十三五”國家戰略性新興產業發展規劃》中指出:“未來5到10年是全球新一輪科技革命和產業變革從蓄勢待發到群體迸發的關鍵時期,信息經濟繁榮程度將是國家實力的重要標志,要實施網絡強國戰略,加快建設‘數字中國’,推動物聯網、云計算和人工智能等技術向各行業全面融合滲透,構建萬物互聯、融合創新、智能協同、安全可控的新一代信息技術產業體系”。當前各國都將產業數字化創新作為經濟發展的高度側重點,互聯網、人工智能與農業、傳統制造業、服務業深度融合的“全產業鏈”競爭時代已經到來。2019年,全球互聯網用戶數量達到41億,活躍社交媒體用戶達到37.25億,產業數字化在各國的數字經濟中已占據主導地位。邊緣計算、區塊鏈、物聯網云計算和大數據等創新技術不斷涌現,推動產業高速迭代、創新模式和業態發展,并不斷出現涌現式創新。
大數據對第一產業的創新推動作用主要體現在通過大數據的應用來降低現代農業發展過程中的試錯成本,提高決策的準確性、時效性。精準農業不僅帶來高產,更重要的是提高生產效率。《農業部關于推進農業農村大數據發展的實施意見》中指出:“農業農村大數據已成為現代農業新型資源要素,是提高農業生產精準化、智能化水平,推進農業資源利用方式轉變的重要推手。大數據將在生產智能化、自然災害預測月報、動植物病蟲害監測預警、農業環境資源精準監測、農產品質量全程追溯、農產品產銷信息平臺等領域發揮巨大作用,形成新的產業增長機會”。大數據對第二產業的創新推動作用主要體現在工業互聯網領域,《工業和信息化部關于工業大數據發展的指導意見》中明確提出了“貫徹落實國家大數據發展戰略,促進工業數字化轉型,激發工業數據資源要素潛力,加快工業大數據產業發展”的目標。大數據與第三產業的融合已產出眾多創新成果,如電子商務、電子政務、網絡帶貨、網約車等,各種基于大數據的電子服務創新開辟了大量細分市場,拉動了內需,不斷促進經濟發展。綜上所述,提出假設H1。
假設H1:大數據戰略正向影響企業的創新產出。
(二)知識管理能力在大數據戰略和創新產出之間的中介效應
信息技術產業發展最重要的推動力是知識的學習和傳播,對應著信息產業創新系統的重要功能是促進顯性和隱性知識的學習以及有效擴散。大數據的本質是為了能更好地利用海量數據揭示出我們不知道的規律,解釋和說明事物,判斷事物間的聯系和邏輯,最終形成知識,不斷拓展知識領域,實現創新。近年國外研究者提出的“BD2K”概念,就是著眼于大數據與知識之間的聯系和轉換(Bourne et al.,2015[9];Margolis et al.,2014[10]),并引申發展出大數據與知識工程(Hota et al.,2015)[11]、大數據與知識管理等多個研究領域(Baoan,2014)[12]。知識經濟時代,知識和技術等無形資產已成為企業競爭優勢的重要來源,是企業的戰略資產(Lai和Lin,2012[13];Stump et al.,2002[14])。創新技術推動了產品和服務開發,企業擁有的知識資源是其技術創新能否成功的關鍵影響因素,良好的知識管理能力已經成為企業的核心能力之一。知識管理融合了現代信息技術、知識經濟理論和企業現代管理理念,是匹配于知識經濟時代的管理思想與方法。Davenport et al.(1998)[15]將知識管理定義為收集、分配和有效使用知識資源的過程。Bhatt(2001)[16]認為知識管理是創建、驗證、呈現、分發和應用知識的過程。McDermott 和 O’Connor(2002)[17]指出,企業可以通過持續改進或根本性創新來促進業務發展,這兩種方法都是通過吸收組織內部的新知識和相關知識而開展的。郝亞美(2016)[18]認為知識管理的實施有助于提高研發型企業的核心競爭力,建立知識管理體系是研發型企業與傳統企業的本質區別。魏江等(2004[19],2007[20])提出企業集群功能整合和知識整合是促進集群企業創新能力躍遷的必要條件,通過知識嵌入能推動企業形成創新網絡從而獲得競爭優勢。大數據是云計算實施的基礎,云計算為企業知識管理系統提供存儲空間和高性能運算能力,公有云的建設將使得中小型企業獲得和大型企業同樣的知識管理系統能力。此外,大數據與可視化以及數據挖掘的結合,使得知識管理系統更加智能化,運行速度更快,知識的表現形式更加多元化,有利于知識在組織內部的高效傳播,優化企業的知識結構和使用流程,促進創新產出。
2016年,為加快實施國家大數據戰略,貫徹落實國務院《促進大數據發展行動綱要》,國家發展改革委員會連同工業與信息化部、中央網信辦,批復同意貴州省、京津冀、珠江三角洲、上海市、河南省、重慶市、沈陽市、內蒙古八大區域開展國家大數據綜合試驗區建設,圍繞不同定位,開展系統性、整體性、協同性大數據綜合試驗探索。設立國家大數據綜合試驗區是大數據戰略中的一項重要舉措,從大數據制度創新、公共數據開放共享、大數據創新應用、大數據產業聚集、大數據要素流通、數據中心整合利用、大數據國際交流合作等方面嘗試推動我國大數據創新發展。自設立以來,綜合試驗區獲得融資的大數據創投項目近千個,新申請大數據類技術發明專利超過8000項,并對上下游產業、制造業和服務業形成了強大的推動力。設立大數據綜合試驗區有助于提高區域知識集聚度和隱性知識的學習水平,從而增強企業的知識管理能力,提升創新產出。因此,提出假設H2。
假設H2:知識管理能力在大數據戰略和中國企業創新產出之間起正向中介作用。
(三)數字化成本在大數據戰略和創新產出之間的中介效應
大數據的廣泛深入應用,使人類社會逐漸走向數據經濟時代,提升數據存儲、運營和應用能力成為企業創新發展和獲得競爭優勢的重要途徑,當前主要互聯網企業的數據成本甚至達到20%-40%。另一方面,大數據中心建設、創新應用等措施所帶來的新技術轉型升級壓力也可能導致企業數字化成本明顯提升,據統計,部分知識密集型企業的數字化成本已占總成本的30%-40%,主要支出為數據庫的建設和維護費用、機房維護費用、電費支出等,成本的增長使企業創新意愿受到影響,從而可能影響創新產出,因此進一步提出假設H3。
假設H3:企業的數字化成本在大數據戰略和中國企業創新產出之間起正向中介作用。
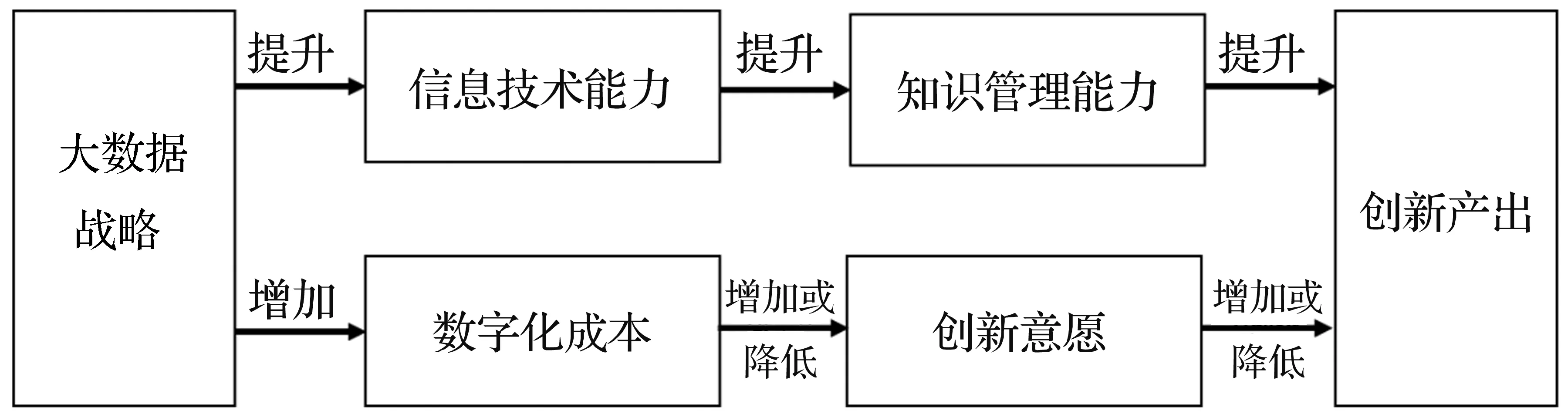
圖1 研究假設
三 研究方法
(一)雙重差分法(DID)
雙重差分法是政策評估的常用方法,通過監測實驗組和控制組間差距的變化情況來消除不隨時間變化的不可觀測因素。應用DID方法必須滿足兩個關鍵條件:一是必須存在一個具有試點性質的政策沖擊;二是必須具有一個相應的至少兩年(政策實施前后各一年)的面板數據集。劉瑞明和趙仁杰(2015)[21]用雙重差分法驗證了國家高新區政策對地區經濟發展的促進效應;曹平和王桂軍(2018)[22]運用DID、PSM-DID和DDD方法,從創新數量和創新質量雙視角研究了“營改增”對服務業企業技術創新意愿的影響。參考這些研究的方法,把2016年國家大數據綜合試驗區政策的制定視為一次自然實驗,采用DID方法評估前后的政策效應變化。具體模型設計如下:
Innovit=α0+α1Treati+α2Policyit+α3Treati×Policyit+α4Xit+εi, t
(1)
其中Innovit表示第i個企業在第t年的創新水平,虛擬變量Treati是對樣本企業的分組,Treati=1代表位于國家大數據綜合試驗區的上市企業,即實驗組;Treati=0代表位于國家大數據綜合試驗區外其它地區的上市企業,即控制組;Policyit表示國家大數據綜合試驗區政策的影響時間,政策提出當年及以后年份取值為1(2016-2018年),之前的年份取值為0(2013-2015年)。Treatit×Policyit是企業分組與時間分組的交互項。
(二)機器學習方法
Kleinberg et al.(2015)[23]認為,政策問題是一個預測問題,政策效應評估就是依據現有數據預測一個政策能達到的效果,并與實際達到的效果對比。從這個角度看,政策可以被視為一種風險嘗試,一種藥物。Varian(2014)[24]通過整合包括訓練集、驗證范例、修正機器學習中過擬合問題等在內的各類特征來改進計量經濟學模型,實現大數據方法與計量經濟學的融合。其研究表明恰當的機器學習模型預測精度可提高50%以上,達到較好的預測效果,并實現一定程度上的因果推斷。機器學習在政策效應和因果推斷已有不少應用研究成果,例如運用LASSO方法(高華川和白仲林,2019)[25]對政策進行評估,以及隨機森林方法(劉衛東等,2019)[26]的應用。Athey(2017)[27]認為機器學習在因果推斷和政策評估中具有很強的應用前景,應當更多將因果樹和隨機森林等機器學習技術與現有的計量經濟理論相結合。Chernozhukov et al.(2017)[28]認為,機器學習的理論要求相對于傳統統計方法較弱,使用隨機森林、LASSO、Ridge、增強樹等各種現代的機器學習方法,以及這些方法的混合來估計高維回歸中的參數具有可行性。Tiffin(2019)[29]使用傳統計量經濟學方法和機器學習方法估計金融危機對經濟增長的負面效應,得到相同的結論,并認為機器學習方法在交互效應、非線性效應、異質性效應的研究方面更具優勢。
本文參考已有研究的做法,結合研究目標,選擇LASSO方法(特征縮減方法)、因果森林方法(樹型模型方法)和卷積神經網絡三種機器學習方法進行對比研究,各種方法的解釋性(因果性)依次遞減,但是預測性遞增。
1.效應評估的機器學習方法
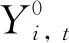
控制組的效應為:
實驗組的平均效應為:
(2)
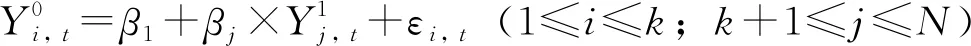
(3)
(4)
此時政策干預的效應估計為:
平均效應估計為:
(5)
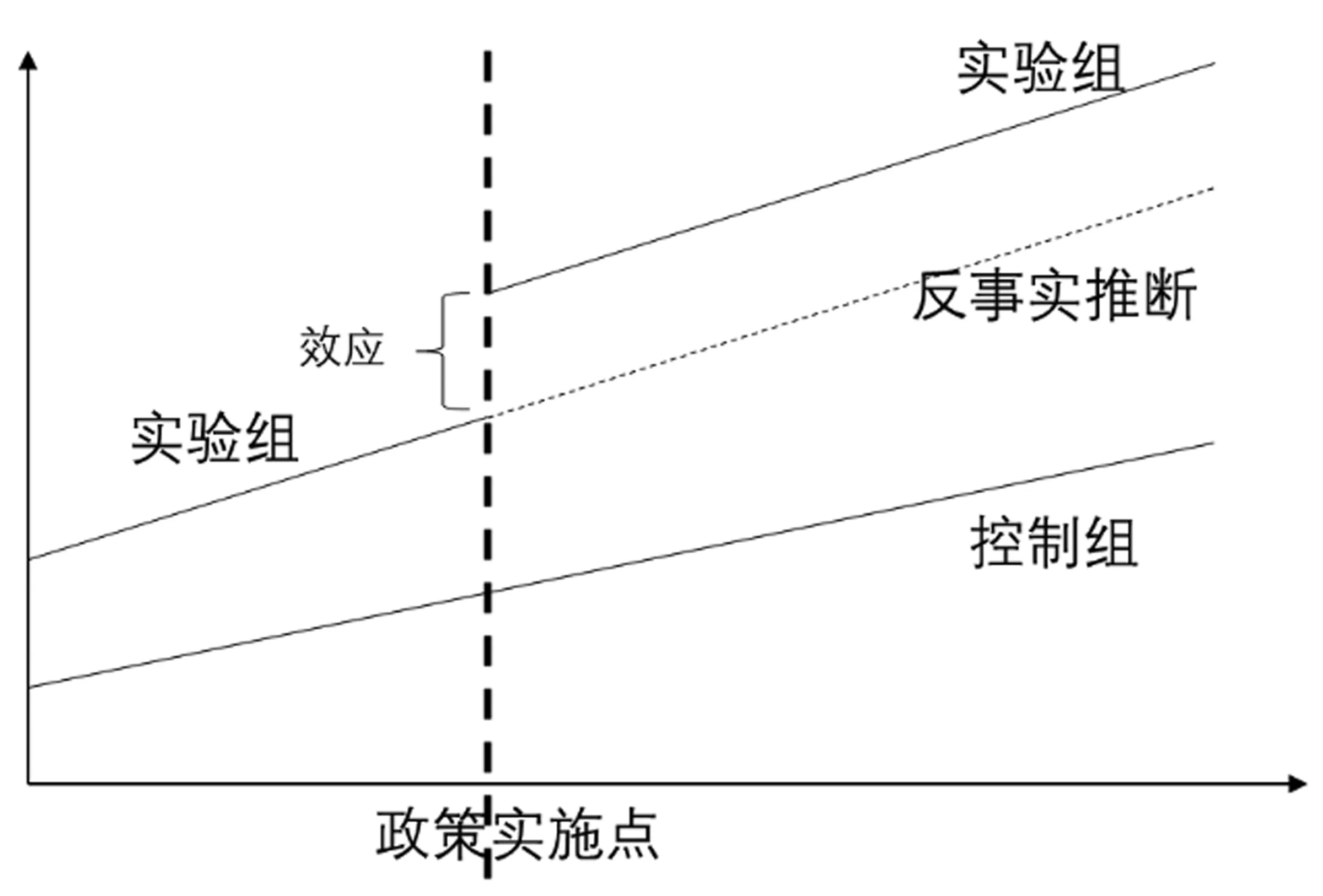
圖2 機器學習的效應評估思路
將樣本按照“訓練集-驗證集-測試集”進行區分,其中訓練集用于估計模型,驗證集(又稱為開發/保持集)用于監控樣本外預測誤差,測試集用于評估所選模型的樣本外預測誤差。
2.LASSO方法
正則化是避免由于變量和特征過多導致過擬合的有效手段,線性回歸的L1正則化通常被稱為LASSO回歸,通過構造一個懲罰函數得到一個較為精煉的模型,保留了子集收縮的優點,是一種處理具有復共線性數據的有偏估計。LASSO方法的步驟為完成每次機器學習訓練后計算損失Loss值,加入懲罰函數后采用最小角回歸法計算損失Loss的極小值,不斷與因變量進行擬合,直至收斂至預設閾值為止。構造懲罰函數的方式如下:
首先把式(2)的實驗組平均效應改寫為線性函數形式:
(6)
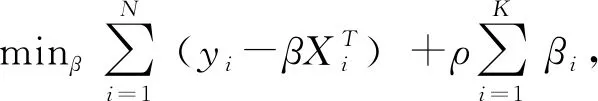
3.因果森林方法
在機器學習領域,回歸樹是利用樹形結構遞歸地將數據劃分為不同的子樣本,并將每個子樣本下yi的平均值作為最終預測值的一種統計方法。本文參考Athey和Imbens(2015)[30]的因果樹方法,把回歸樹方法中重點關注的預測值均方誤差改進為處理效應的均方誤差。首先在訓練集樣本中隨機選取一部分,用于劃分空間即構造樹的結構,其他樣本被用來估計處理效應,估計結果就是每一個劃分空間中的處理效應及其相應的置信空間。因果樹的構造如下:

(7)
其中K表示樹中的葉子個數,代表模型的復雜度,α.K代表懲罰項,可以加速分裂和收斂。
基于生成的因果樹,有條件的平均效應按以下公式計算:
(8)
(9)
4.CNN卷積神經網絡
區別于傳統的BP神經網絡,卷積神經網絡是基于神經元局部感受野的概念而設計的,通過針對某個局部的樣本信息進行數據挖掘和分析,應用卷積(Convolution)操作實現特征的抽取,在縱向上形成新的“視界”,將一段時間窗口周期內的企業相關數據作為一個整體來衡量,通過不同的卷積核和池化進行典型化抽取,在保持數據本身存在的關聯性的同時加快迭代速度并提升運算效率,以期獲得更深層次的結果。
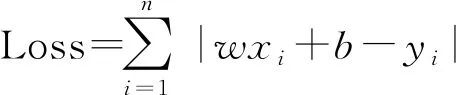

圖3 非線性關系下的條件平均效應評估
四 數據和變量
專利內化了創新的主要特征“新穎性”,我國的專利分為發明、實用新型和外觀設計三類,發明專利是企業技術競爭優勢的重要構成,因此選擇專利申請數量的自然對數和發明專利申請數量的自然對數作為創新代理變量。
Gold et al.(2011)[31]認為,知識管理包含基礎建設和管理流程兩部分,管理流程指獲取、轉化、應用和保護知識方面的能力。企業研發投入與知識管理基礎建設密切相關,而合格的知識型員工才能執行知識管理流程并承載知識,知識管理的核心是知識型員工的管理,企業研發人員數量可以作為知識型員工的代表變量。本文選擇知識管理基礎投入(研發資金投入)、知識管理流程投入(管理投入)、知識員工比例(研發人員數量)作為研究變量。Tanriverdi(2005)[32]認為,企業要更快地應對高速變化的市場競爭,必須具備知識管理能力,包括技術知識管理能力、客戶知識管理能力、產品知識管理能力和運作知識管理能力。市場是企業知識管理能力的最佳衡量標準,企業學習和管理知識是為了快速地進行知識的共享與應用,以加快產品更新速度,縮短產品研發周期并降低成本,最終達到快速占領市場的目標。因此,本文進一步加入知識應用投入(市場投入)、知識累積度(企業年限)作為知識管理能力的衡量指標。
其他的控制變量包含創新環境和企業自身條件兩方面。參考曹平和王桂軍(2018)[22]、曹平和陸松(2020)[33]等的做法,同時考慮數據獲取的難易度,選取區域經濟實力(GDP)、區域人員能力(信息技術產業從業人員數量)、用戶參與(大專以上學歷人員數量)、政府支持(政府補貼)、區域產學研協作能力(高校和科研院所數量)、金融環境(外資比例)、盈利能力(營業利潤率)、成長能力(所有者權益比例)、營運能力(資產周轉率)、資本結構(資產負債率)、現金流量(總資產現金回收率)和企業績效(托賓Q值)作為控制變量。因為8個國家大數據綜合試驗區包括區域、省份和城市,因此在數據選擇時進行了輻射范圍的推論。首先認定京津冀大數據綜合試驗區直接輻射京津冀地區的企業,珠江三角洲大數據綜合試驗區直接輻射廣東省的企業,沈陽市大數據綜合試驗區直接輻射遼寧省企業,其余貴州、上海、河南、重慶和內蒙古均直接輻射本省(直轄市)企業。不在八大試驗區范圍內的省份為間接輻射省份。基于這個推論,創新環境指標均選取企業所在省(直轄市)的相關指標。
變量設定如表1所示。
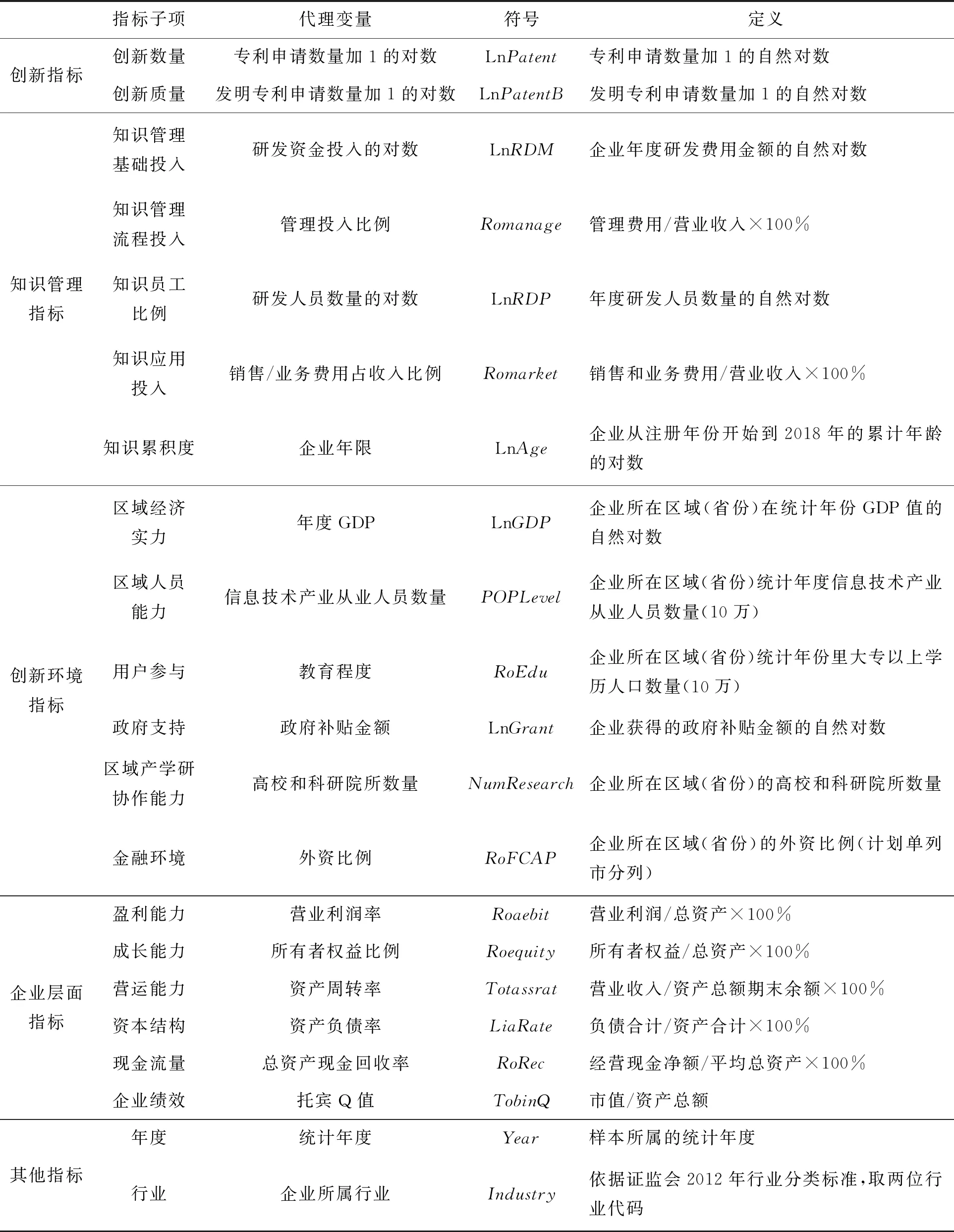
表1 變量設定
本文以國家大數據綜合試驗區政策實施前后3年為時間窗口,選取2013-2018年數據進行研究,2016年為效應作用點,2013-2015年為政策前時間面板,2016-2018年為政策生效后觀察面板。宏觀數據從《中國工業統計年鑒》、《中國電子信息產業統計年鑒》和《中國信息產業年鑒》中獲取,專利相關數據通過國家知識產權局網站進行手工收集,企業層面數據則來自于國泰安和萬德數據庫的上市公司數據以及部分上市公司的年報,在剔除金融、保險、ST、*ST及主變量存在嚴重缺失的公司樣本后,最后得到1107家上市公司的6642條觀測數據。為了消除極端值的影響,對主要連續型變量進行了1%的Winsorize縮尾處理。主要變量描述性統計特征分析如表2所示,樣本上市公司專利申請數量(對數)和發明專利申請數量(對數)平均值分別為2.756和1.854,中位數分別為2.113和1.737,最小值均為0,最大值分別為8.341和6.128。
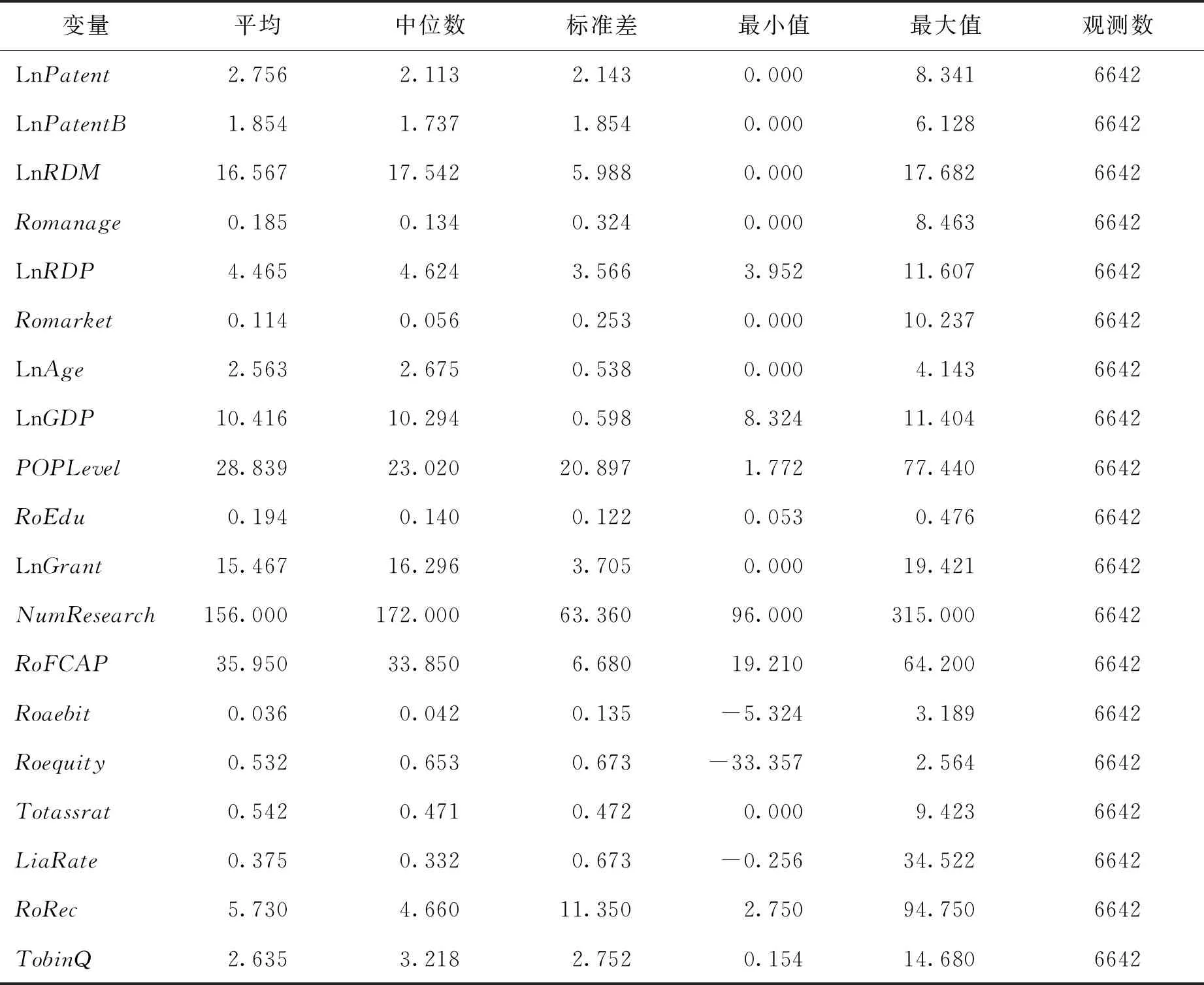
表2 主要變量的統計特征
五 實證結果及分析
(一)政策效應分析
表3為DID估計結果,列(1)在加入控制變量的同時對年份固定效應和行業固定效應進行了控制,結果顯示交互項Treat×Policy的回歸系數為0.625且在1%的水平上顯著。列(2)利用固定效應模型(FE)對企業固定效應進行了控制,可以看到Treat×Policy的回歸系數為0.422,對比列(1)有所下降,但仍在5%的水平上顯著。因此不能從統計上拒絕假設H1。

表3 DID檢驗結果
采用雙重差分方法進行政策效應評估需要滿足外生性要求,即政策對樣本的選擇應該是隨機的,具體到大數據綜合試驗區政策上,很顯然被選中的8個省市不是隨機的,但是樣本上市公司在注冊時并沒有預見到該政策,因此從企業層面上看這個政策是隨機的。而大數據綜合試驗區對被影響產業的選擇是非隨機的,很明顯信息技術產業和服務業將會受到更大和更直接的影響,如果各產業在實驗組和控制組之間分布不均勻,此時政策變量將存在一定的內生性,需要采用工具變量法進行處理。
受空調制冷、UPS不間斷電源和超大用電負荷等因素的影響,大數據中心的能耗非常巨大。根據統計,2017年,中國數據中心耗電量為1221.5億千瓦時。數據中心的巨大能耗受到重點關注。2019年,工信部、國家機關事務管理局和國家能源局出臺《關于加強綠色數據中心建設的指導意見》,要求到2022年,“數據中心平均能耗基本達到國際先進水平,新建大型、超大型數據中心的電能使用效率值達到1.4以下”。很明顯在選定大數據綜合試驗區時,考慮了向煤炭基地及其他用電資源富余地區的傾斜,因此可以考慮將自然稟賦作為工具變量。參考鄧明和魏后凱(2016)[34]的做法,加總五大能源工業的工業產值,然后除以各省總人數,得到人均能源工業總產值,作為自然稟賦的度量標準,相關數據從各年度的《中國工業經濟統計年鑒》中獲取,計算2013-2015年窗口期內的各省數據并進行平均。可以認為,自然稟賦與現代企業創新之間沒有直接相關的聯系,滿足工具變量法的“排他性約束”。
設置工具變量IV,IV=1表示窗口期內自然稟賦指標高于平均值的省、市和自治區,IV=0表示其他省、市和自治區,利用兩階段最小二乘法(2SLS)進行估計。可以看到一階段回歸中IV和IV×Policy的系數均在1%水平上顯著,且Kleibergen-Paap Wald統計量和Kleibergen-Paap LM統計量所對應的p值均遠小于1%,說明工具變量具備較好的識別能力。二階段回歸的結果顯示,Treat×Policy的系數值為正,且在5%的水平上顯著,說明在緩解了政策實施可能存在的內生性問題之后結論保持不變。
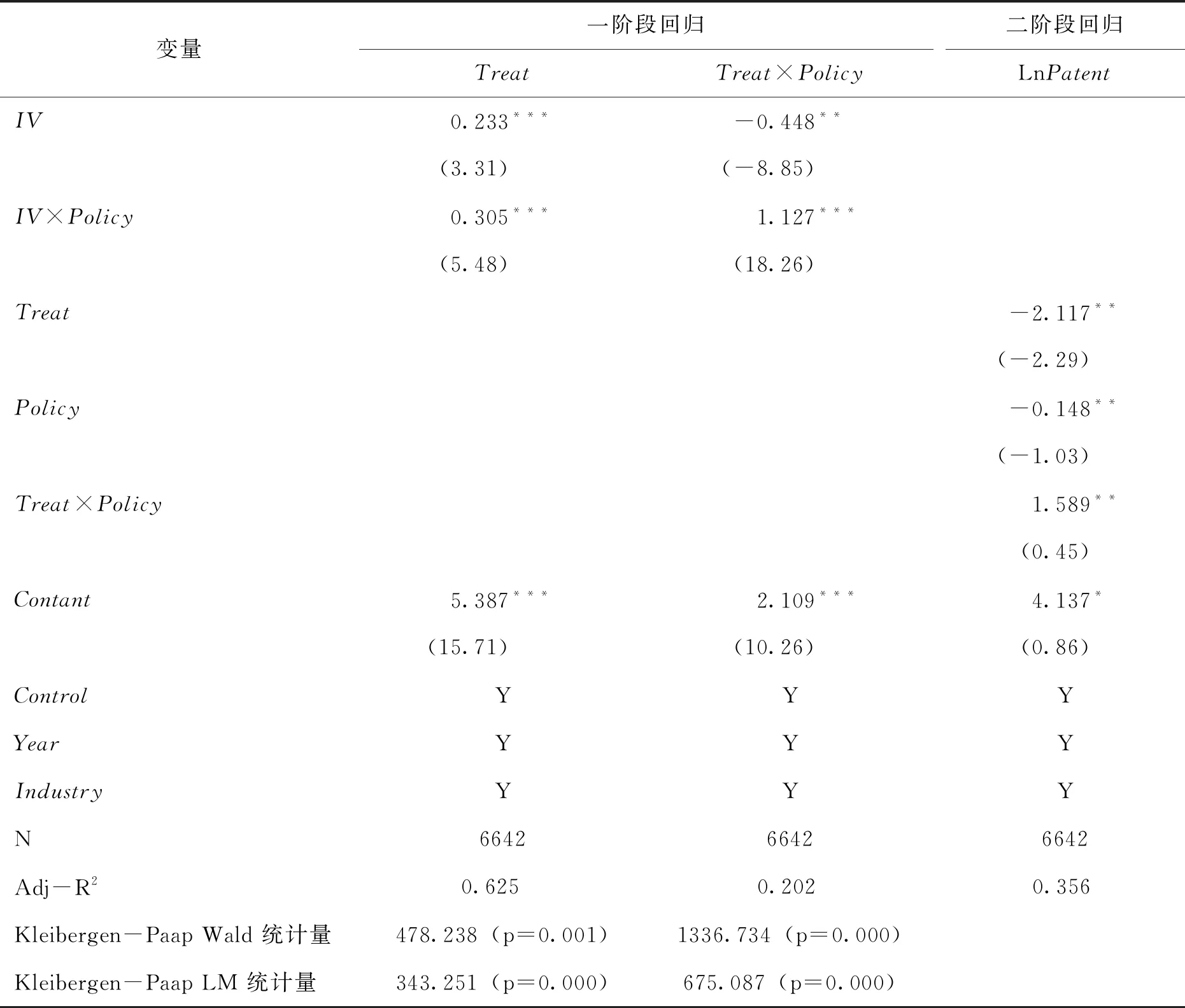
表4 工具變量法解決內生性問題
表5為機器學習方法的估計結果。具體做法是先從控制組樣本中抽取訓練集和驗證集,進行模型訓練,并用實驗組在政策實施之前的樣本作為測試集進行誤差調整,運用構造好的模型進行實驗組的反事實推斷,然后評估在給定限制條件下政策的平均效應。將數據樣本通過設計的模型進行訓練和測試,初始學習率按照Smith(2015)[35]的方法設置為0.001。采用不同的算法改變學習率,選擇不同的測試集與訓練集比例,分別統計迭代到500次和迭代1000次以后的Loss值。結果顯示在初始學習率為0.01,隨機指定測試集和測試集(按70%和30%的比例)的情況下收斂較好,1000次迭代的Loss值低于0.01。同時設計了一個4層BP神經網絡以對比模型的擬合優度。其中輸入層設置16個節點;輸出層5個節點;隱藏層2層,按照經驗公式估算,第一層設置14個節點,第二層設置7個節點。采用同樣的梯度下降方法和激勵函數,迭代次數設置為1000次,運行結果顯示,本文采用的機器學習方法在收斂時間和擬合優度上均優于BP神經網絡。
從表5結果可以看到,LASSO、因果樹(CT)和卷積神經網絡(CNN)三種方法的RMSE均小于0.1,LASSO方法和因果樹的RMSE小于0.05,模型具有較好的預測性能。根據模型進行反事實推斷計算出來的條件平均效應CATE均為正且大于0.3,參考Athey和Imbens(2016)[30]的研究結論,不能否定假設H1。
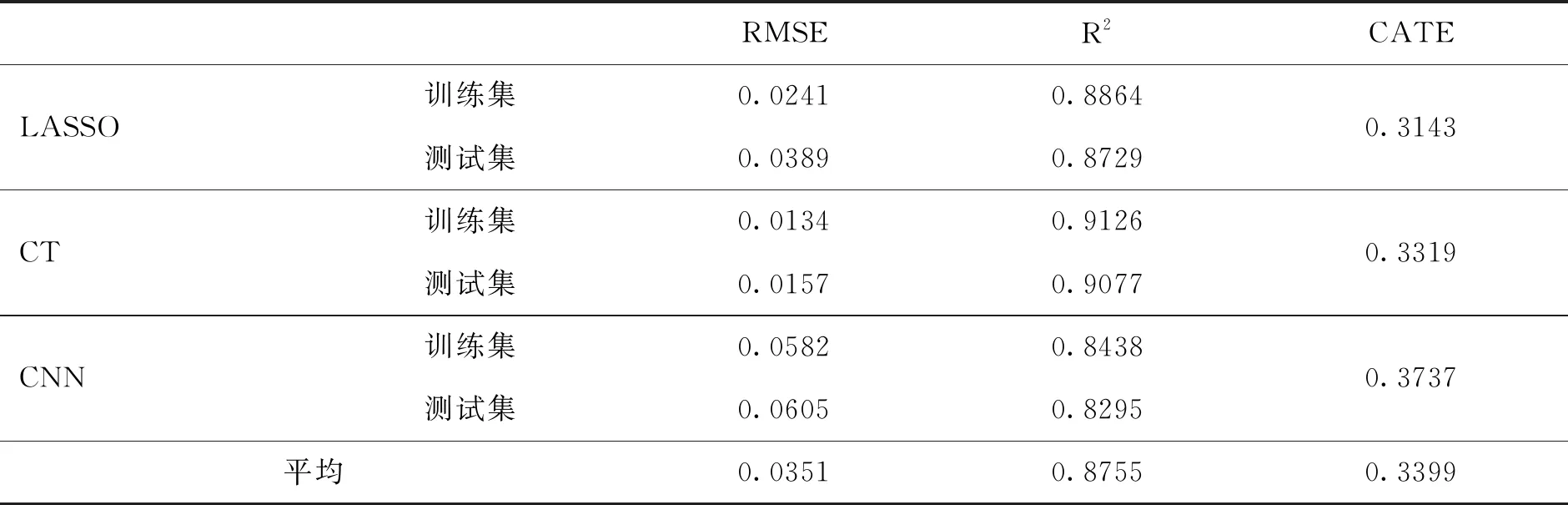
表5 機器學習的政策效應評估結果
(二)中介效應
為了研究知識管理和數字化成本在大數據戰略和企業創新之間的作用,進一步進行中介效應檢驗。如上文所述,知識管理(KM)由知識管理基礎投入(研發資金投入)、知識管理流程投入(管理投入)、知識員工比例(研發人員數量)、知識應用投入(市場投入)、知識累積度(企業年齡)五個子項構成,采用專家評分法(Delphi方法)和問卷調查法進行綜合評分并制定權值后(AHP方法)即可計算,得到企業的知識管理能力水平。數字化成本通常包括研發成本、生產成本、保存成本以及維護和支持成本,其中后面幾項在統計數據和企業年報中均沒有明確的項目對應,而研發成本占據數字化成本較大比例,因此本文先將研發成本和年度變量作為被解釋變量與解釋變量進行OLS回歸,估計出隨機擾動項作為數字化非預期成本,研發成本與數字化非預期成本分別除以企業年度總成本后相加,得到企業年度數字化成本支出水平,所有的數據進行z-score標準化處理。
在式(1)的基礎上構建中介效應檢驗模型如下:
Innov(i,t)=α0+α1Treati+α2Policyit+α3Treati×Policyit+α4Xit+μ1
(10)
KM(i,t)=β0+β1Treati+β2Policyit+β3Treati×Policyit+β4Xit+μ2
(11)
DC(i,t)=β0+β1Treati+β2Policyit+β3Treati×Policyit+β4Xit+μ2
(12)
Innov(i,t)=γ0+γ1Treati+γ2Policyit+γ3Treati×Policyit+γ4KMit+γ5Xit+μ3
(13)
Innov(i,t)=γ0+γ1Treati+γ2Policyit+γ3Treati×Policyit+γ4DCit+γ5Xit+μ3
(14)
其中KM(i,t)代表知識管理中介變量,DC(i,t)為數字化成本中介變量,μ為隨機擾動項。
中介效應采用Sobel檢驗方法,由β3×γ4系數衡量,從表6結果可以看到,列(1)Treat×Policy的系數為正,且在1%的水平上顯著,說明大數據戰略確實促進了企業的知識管理能力,列(2)中知識管理能力(KM)的系數為0.335,且在5%的水平上顯著,因此無需再進行Sobel檢驗。計算β3×γ4=0.071,表示大數據戰略通過知識管理能力對企業創新的間接影響效應占總效應(0.422)的16.83%,即知識管理能力有一定的中介效應。一方面,說明大數據戰略還有其他路徑推動企業創新;另一方面,也說明當前企業的數字化轉型還處于初級階段,大數據戰略推動知識管理能力發展并最終促進企業創新的效果還有提升空間。對數字化成本的檢驗結果顯示,β3為負且不顯著,γ4不顯著,說明來自數字化成本的中介效應不顯著。

表6 DID中介效應檢驗結果
利用Matlab中的靈敏度分析(Sensitivity Analysis)模塊進行分析,分別設置4個模型,其中模型1和模型2分別衡量Treat×Policy對知識管理能力KM和數字化成本DC的輸出敏感度,模型3和模型4衡量Treat×Policy分別和知識管理能力KM以及數字化成本DC聯合輸入對企業創新的輸出敏感度,結果顯示知識管理能力KM在模型1中的敏感度為0.195,在模型3中的敏感度為0.359,對于企業創新的輸出具有一定影響力。而數字化成本在模型2和模型4中的檢驗結果均顯示其對企業創新輸出的敏感度較低。

表7 機器學習中介效應檢驗結果
(三)穩健性檢驗
政策相互干擾是影響DID估計結果的一個重要因素。通過對這段時間內各級政府頒發的各項政策文件進行研讀,本文認為國家的大數據戰略是逐步遞進的,前后無不一致之處,前期主要是思路方面的引領,最終成型的政策是《大數據綜合試驗區推進(實施)方案》的頒布。其次進行平行趨勢檢驗,參照羅知等(2015)[36]的做法,首先以2016年為政策基準年,生成政策實施前后3年時間的虛擬變量與處理組虛擬變量的交互項,將這些交互項作為解釋變量進行回歸,交互項系數反映的就是特定年份實驗組和控制組之間的差異。
(15)
結果顯示,政策時點前的虛擬變量與實驗組虛擬變量的交互項系數均不顯著,政策實施后二年的系數顯著為正且數值逐漸變大(圖4),這表明大數據綜合試驗區政策實施前實驗組和控制組之間不存在顯著差異,政策實施后對企業創新產生了影響,平行趨勢假設成立。

圖4 平行趨勢檢驗結果
進一步采用安慰劑效應檢驗結果的穩健性。具體做法是保持方法和模型不變,改用2010-2015年的數據來進行安慰劑效應測試,設定2010-2012年樣本為實驗組,2013-2015年為控制組。DID方法結果顯示交互項Treat×Policy的系數不顯著,機器學習方法的結果顯示CATE值平均為0.0875,出現大幅降低,這進一步說明在2016年的政策時間點之前,實驗組和控制組企業在趨勢上不存在顯著差異。
最后,通過改變企業創新代理變量的方式進行穩健性檢驗,采用發明專利申請數量來代表企業創新的質量,在DID方法中交互項系數在5%水平上顯著為正,在機器學習方法中CATE平均值為0.3014,接近用所有專利申請數量作為代理變量時的效應水平。
(四)分樣本研究
為了進一步檢驗大數據綜合試驗區政策對我國不同類型企業的影響,按照政策關聯性和企業規模分樣本進行研究。首先,考慮到信息技術企業直接受到大數據綜合試驗區政策影響,按政策關聯性將樣本分為信息技術企業和其他企業進行研究。對信息技術企業的DID雙重差分法研究結果顯示,信息技術企業樣本的Treat×Policy系數在1%水平上顯著為正,其他企業樣本的Treat×Policy系數在5%水平上顯著為正,大數據綜合試驗區政策對信息技術企業的創新促進力度更大。按企業規模區分,結果顯示大數據綜合試驗區政策更能提升大型企業的創新水平。可能原因在于,大型企業有更大的動力和資源進行大數據應用建設,通過提升整體的信息化和數字化水平而促進創新。
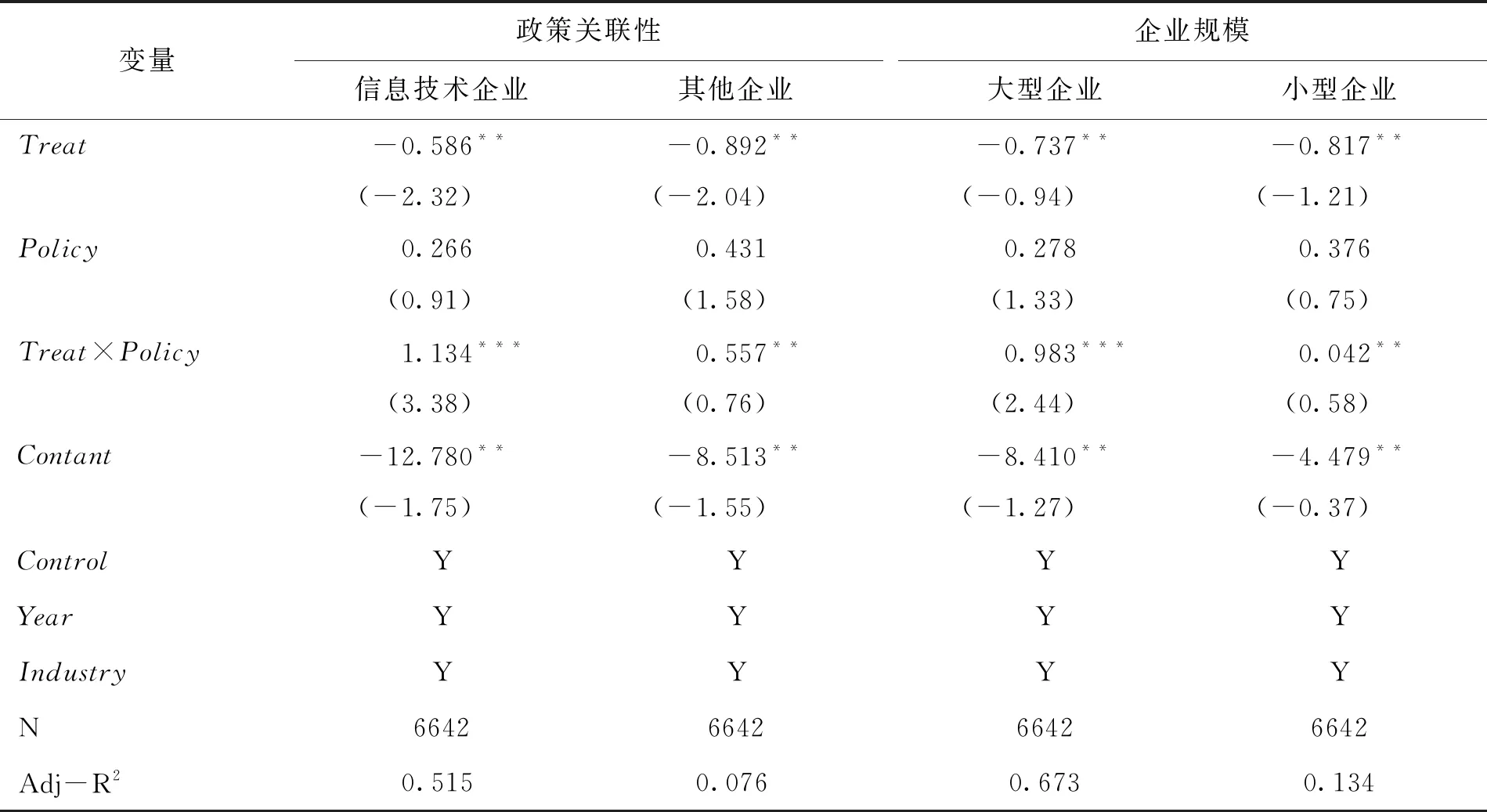
表8 分樣本回歸(DID)
機器學習方法得到同樣的結論,LASSO、因果樹和CNN方法的模型擬合RMSE均達到要求,采用機器學習方法得到的信息技術企業政策效應相較其他企業多53.78%,大數據綜合試驗區政策通過對信息技術企業的直接推動,帶來新的技術及促進商業模式和市場模式改變,間接增強了其他企業的創新意愿。結論中還可以看到大型企業的政策效應相較中小型企業更高,和上述DID方法研究得到的結論一致。因此,政策制定應該考慮向信息技術企業之外的企業傾斜,并加大對中小企業的扶持力度,以期實現整個產業的迭代升級。
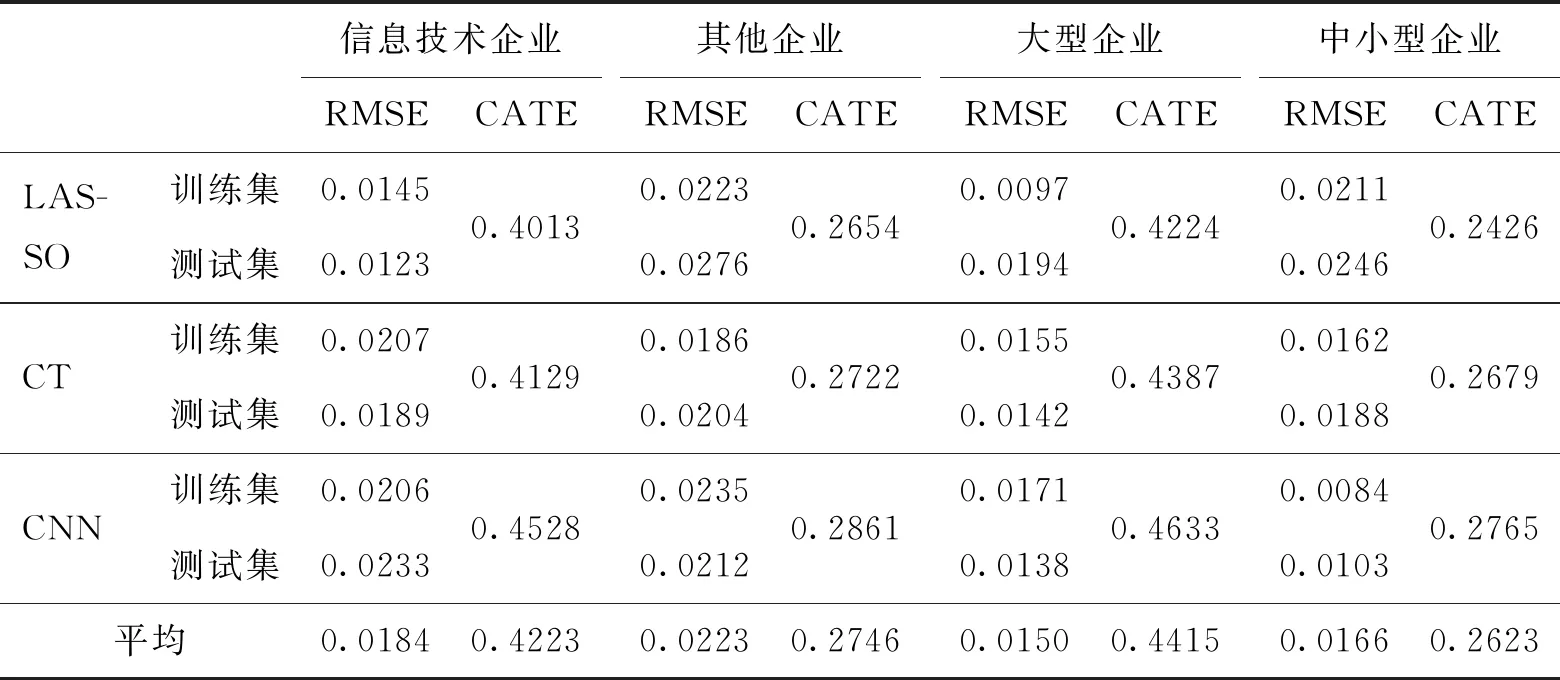
表9 分樣本回歸(機器學習)
六 總結與進一步討論
根據2010年發布的《國務院關于加快培育和發展戰略性新興產業的決定》和2016年國務院《“十三五”國家戰略性新興產業發展規劃》(國發〔2016〕67號)中的定義,大數據產業是新一代信息技術產業發展的重要構成,也是工業4.0和其他產業轉型升級的重要基礎,對數據資源的掌控和應用已成為重要的國家戰略和創新的核心要素。大數據對于創新知識發掘和知識管理是一種高效率的新技術,會對企業創新產生深刻影響。我國政府也高度關注大數據產業,通過各種政策不斷促進其高速發展。本文分析大數據戰略對企業創新的促進作用,采用傳統的DID方法和近年來發展較快的機器學習方法開展聯合研究,將國家2016年頒布大數據綜合試驗區政策作為一項自然實驗,基于2013-2018年中國上市公司數據的實證結果表明,政策一定程度上提升了中國企業尤其是知識密集型企業的創新水平,促進效應部分來自于政策對于企業知識管理能力的影響。但是知識管理能力的中介效應并不是特別突出,原因一方面在于知識管理能力是一個漸進式的提高過程,并非短期內的政策刺激就能實現;另一方面在于大數據本身的特性決定了技術外包和能力租用對于中小企業是一個短期內效益較高的選擇,因此忽略自身的知識管理能力提升。這也是本文發現大數據戰略并未通過提升數字化成本而影響創新產出的一個主要原因。分樣本回歸結果顯示大數據戰略對信息技術企業和大型企業的創新促進作用更加突出,政策制定應該考慮向其他企業適當傾斜,并加大對中小企業的扶持力度,例如設置大數據和數字化改造的專項扶持資金,以實現整體產業的迭代升級。
在政策效應研究方面,DID方法是傳統的優秀方法,但是必須嚴格做好假設,保障平行趨勢。機器學習是人工智能的重要領域,目的是通過對樣本特征的深度挖掘,獲得準確的預測,并且實現對非線性關系的模擬與趨近,二者在方法論上存在共通之處,且一定程度上能夠互補。機器學習在政策評估方面主要的應用是反事實模擬,即使用預處理和對照觀測的數據,預測如果沒有政策影響,外源觀測結果會發生什么變化,將這一預測與政策實施后的實際結果進行比較,可以得到政策的平均處理效應。政策往往帶有明顯傾向性,對于大數據綜合試驗區政策,資源稟賦(電費)和先發優勢的影響無法忽視,相較于DID方法,機器學習可以在一定程度上緩解內生性并發掘非線性關系。本文使用了LASSO、因果樹和CNN卷積神經網絡三種方法進行政策效應評估,得到的結論與DID方法基本一致。但是機器學習目前有實質性的限制,即無法獲得不確定性估計量,在因果關系判定上存在缺陷,后續必須進一步做好理論基礎支撐研究,提高置信度。
根據研究結論,得到主要的產業發展政策含義為:首先,與美國、德國和日本等發達國家相比,我國的基礎產業尤其是制造業領域仍然處于較為初級的生產階段,大數據是推動制造業智能化水平提升和工業4.0升級的基礎支撐手段。大數據戰略會促進生產企業的信息技術能力和知識管理能力提升,從而對整體產業的創新水平有正向作用,企業方面應以大數據綜合試驗區政策頒布為契機主動實現數字化轉型,以數字化帶動自主創新。其次,政府方面應保障公平的市場競爭環境并加強知識產權保護力度,出臺相關政策促進產業間基于大數據的數字化創新,鼓勵產業間大數據的相互流動與協同創新,對大數據應用進行有效監管,確保信息安全和數據安全。同時還應當通過政策和有效措施推動大數據基礎建設與大數據應用之間的銜接,確保大數據的技術優勢能夠向傳統工業和服務業轉移,推動整體產業的數字化轉型升級和創新發展。再次,知識管理能力在大數據戰略和企業創新產出之間起到一定的中介作用,后續應當繼續推動高校和研究機構開展大數據和云計算的基礎研究,著重培養數字化轉型人才,激勵配套技術創新,進一步推進產業發展。最后,大數據產業的能耗較高,應當做好電費政策配套,在給予電費優惠推動產業發展的同時加強綠色數據中心建設。同時做好產業布局規劃,避免發展過于粗放,各地盲目投入大數據產業園區項目造成資源閑置和浪費。
猜你喜歡
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
核科學與工程(2021年4期)2022-01-12 06:30:26
今日農業(2020年19期)2020-12-14 14:16:52
云南畫報(2020年9期)2020-10-27 02:03:26
中學物理·高中(2016年12期)2017-04-22 11:53:03
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
