面向電力的SDN設備監測研究
2021-05-31 03:10:04程瑋
保山學院學報 2021年2期
程 瑋
(廈門海洋職業技術學院,福建 廈門 361100)
近年來,隨著計算機網絡規模大幅度提升,傳統的網絡架構已不能滿足云計算、服務器虛擬化等新應用的需求。此時,基于傳統網絡結構的軟件定義網絡(SDN)應運而生。SDN網絡適應了應用的快速變化,但仍然面臨著與傳統網絡相同的問題,即當鏈路中出現故障時,不能及時準確地進行定位分類。關于故障定位,傳統網絡研究眾多,如榮飛、朱語博等人基于子模塊電壓分組檢測,研究了MMC子模塊開路故障診斷定位方法[1];趙建文、李璞等人基于AGM曲線能量,對配電網故障區段定位方法進行了研究[2]。但這些故障定位方法沒有考慮到SDN網絡結構的特性,因此并不適用于SDN網絡鏈路的故障定位。為此,本研究探討了一種基于CNN?SVM的SDN網絡鏈路故障定位算法,并從多角度對算法進行了評估。
1 系統框架
根據研究的目的,采集并處理控制器數據以及對定位應用層中的故障,將SDN網絡鏈路故障定位系統設計如圖1所示。SDN系統主要由數據層、控制層、應用層、MySQL數據庫組成[3]。
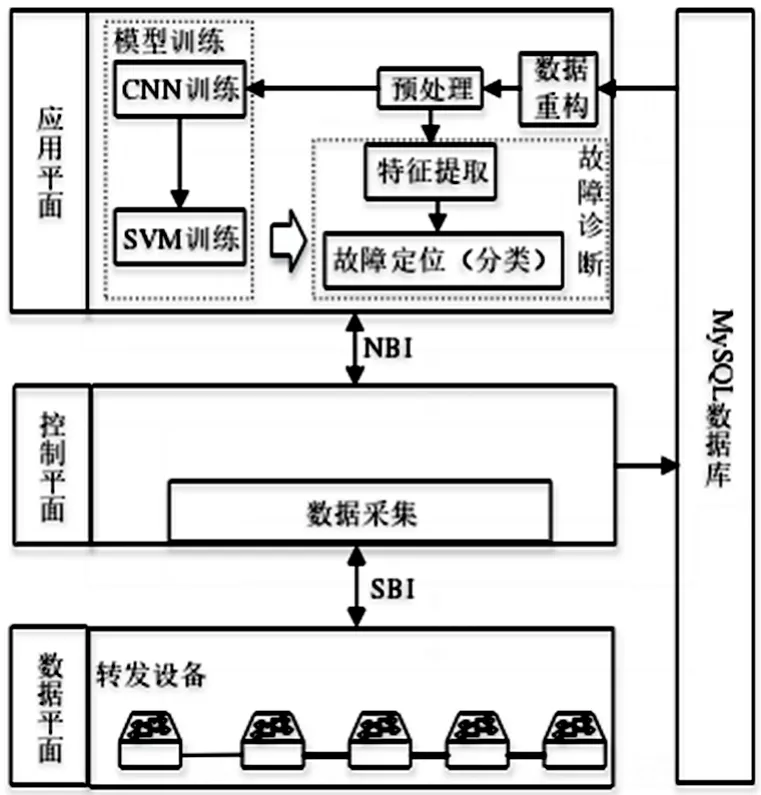
圖1 SDN網絡鏈路故障定位系統框架
控制層主要的功能是接收來自數據層的帶寬、時延等數據[4],并將其存入MySQL數據庫中。通常情況下,這些數據不能通過OpenFlow協議直接獲得,因此需要通過計算或自行測量等方式獲得。
應用層包括數據預處理、模型訓練、故障定位等子模塊[5]。首先,從MySQL數據庫中讀取數據,并對數據進行重構、預處理。然后將處理后的數據輸入模型,應用卷積神經網絡(CNN)和SVM分類器進行訓練。最后通過特征提取和故障定位分類,實現故障診斷。
2 基本算法
2.1 CNN-SVM算法
根據系統整體架構可知,傳統CNN算法控制層采集的數據雖然可組成二維數組,但它無法提取到不同網絡鏈路間的數據空間相關性,不適用于SDN網絡鏈路故障定位,因此還需對該結構進行改進。本研究在此基礎上,提出一種基于CNN?SVM算法的SDN網絡鏈路故障定位模型,其結構如圖2所示。該模型主要包括數據輸入層、特征提取層、softmax函數層、SVM分類層四個部分[6],一方面可解決傳統CNN網絡無法提取不同鏈路的數據空間相關性,另一方面利用SVM算法提高了故障定位的正確率。
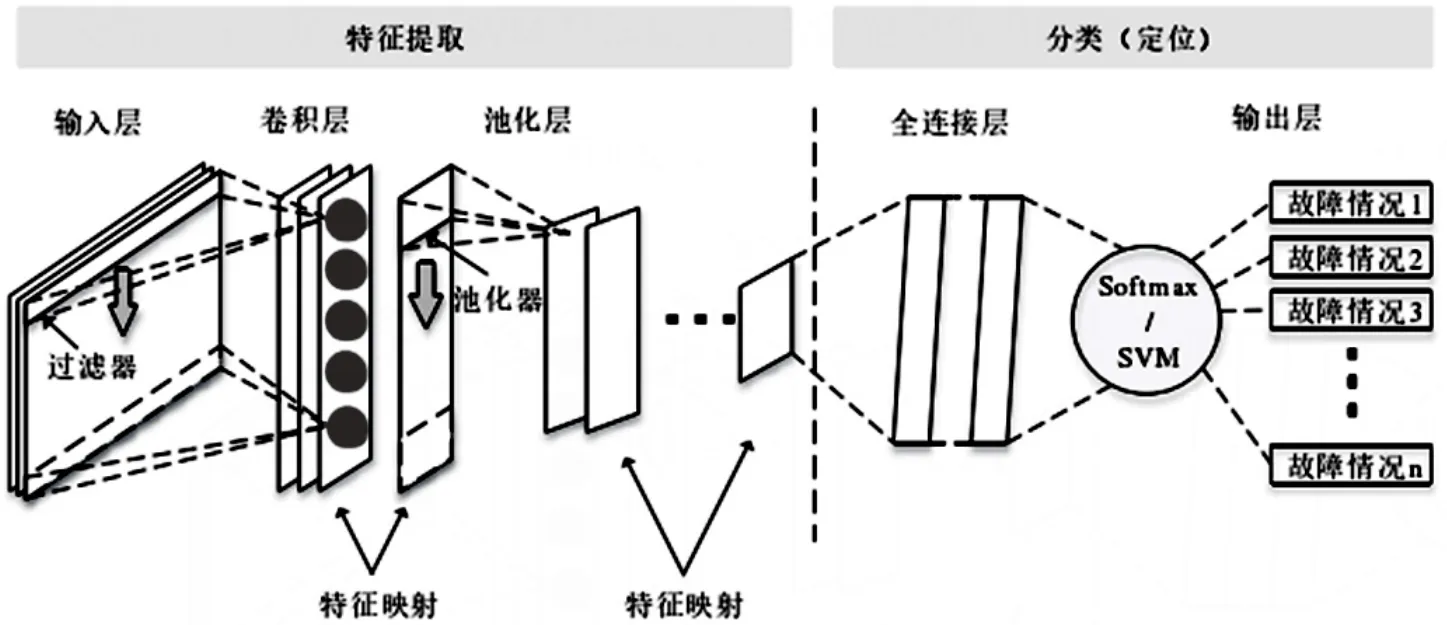
圖2 CNN-SVM算法模型
2.2 CNN-SVM算法結構
2.2.1 數據輸入層
數據輸入層主要功能是接收和處理SDN網絡底層的原始監測數據[7]。由于CNN模型只能接收二維或三維數據,因此這些數據一般不能直接應用于CNN模型中,故需要對它們進行轉化。本研究將一定長度的時間窗口和同一時間窗口中檢測到的網絡數據構成為圖像數據,以便于輸入CNN模型。
2.2.2 特征提取層
特征提取層包括激活層、卷積層和池化層,是整個模型的核心組成部分[8]。其中,卷積層主要是通過卷積核提取局部向量的時空相關特征,而卷積核又通過輸入數據的結構改變移動方向,實現卷積提取操作,具體如圖3所示。

圖3 卷積詳細過程
令SDN網絡鏈路中K個間隔時間內某一時刻采集到J=Nlinks+Nstatus個監測數據。其中,Nlinks鏈路數目,Nstatus表示每條鏈路上的數據個數。那么,CNN?SVM算法可通過K*J個節點的輸入層接收SDN網絡底層的原始監測數據。由此可得,特征映射中節點的輸入值:
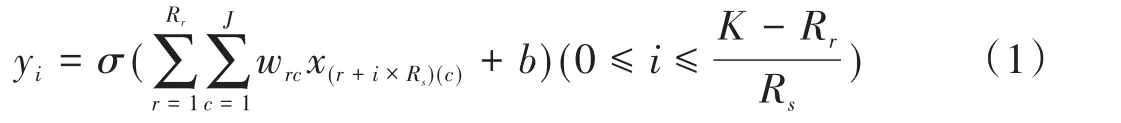
式中,Rr和Rs分別表示卷積核的行大小和步長。由于CNN?SVM算法CNN結構中可接收的是標準二維特征映射,而上述操作通過卷積核得到的局部特征為一維特征映射,因此需要在接下來的池化層中使用P*1的池化器沿卷積核時間軸移動方向進行降維處理。
2.2.3 Softmax函數層
傳統CNN模型中,全連接層輸出的值一般不符合概率分布[9],因此本研究引入Softmax函數層以解決該問題。令模型訓練輸入樣本為x,其對應標簽為yˉ;n個類別。則x被分為j類的概率可表示為P(y+j|x);模型具有n個量化的概率值。將n個概率值輸入Softmax函數層,應用式(2)可得到一個符合概率分布的n維向量。
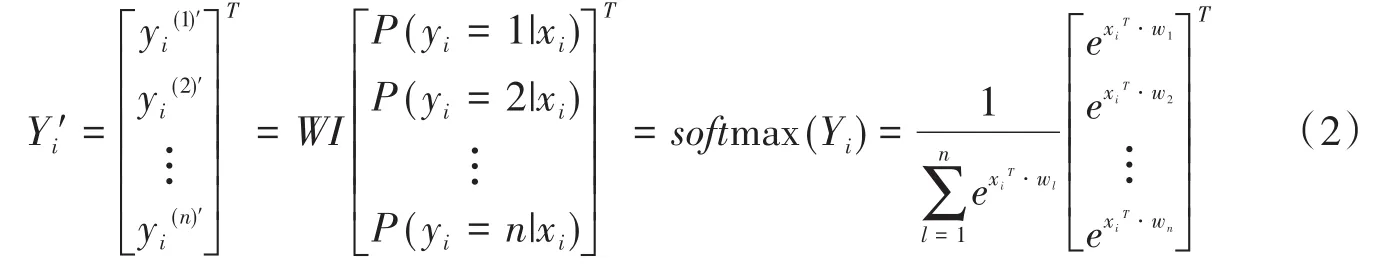
式中,Y′i表示Softmax函數對樣本i進行處理后的輸出值,其取值范圍[0,1];P(yi=n|xi)表示樣本i屬于n類的概率。將Softmax函數分類結果與樣本實際標簽進行比較,可得出模型的損失誤差。本研究中,由于CNN?SVN算法的輸入標簽為分類標簽,故決定采用交叉熵損失函數。交叉熵損失函數的定義如下式(3)所示。

式中,i表示第i個樣本,j表示n個分類中第j個分類;表示第i樣本的實際標簽。通過不斷調整式中參數,可使損失函數L(w)值最小。
2.2.4 SVM分類器
SVM分類器是一種用于處理多分類、高維模式識別等問題的經典二多分類模型[10],其模型結構如圖4所示。SVM分類器主要由hinge損失和核技巧兩個部分組成,其中核技巧包括線性核和非線性核。本研究采用非線性核作為SVM分類器的核技巧,并以非線性SVM分類器作為CNN?SVM算法的分類器,以解決非線性的多分類問題。
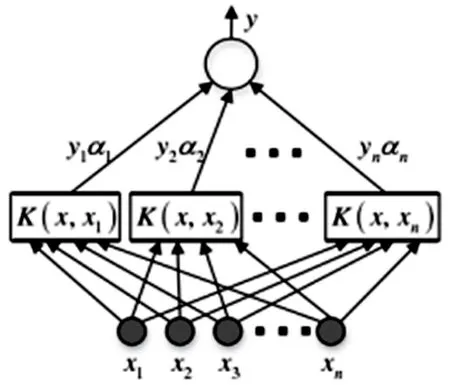
圖4 SVM模型結構
假設訓練集為J={(X1,y1),...,(Xi,yi),...,(Xn,yn)},Xi(Xi∈χ=Rn)表示第i個輸入的特征向量,yi=(yi∈ψ={+1,?1})表示xi的分類標簽。一般而言,SDN網絡底層采集到的故障數據為線性不可分,因此根據式(5)向訓練集中引入松弛變量ξi,即可將該線性不可分的問題轉化為軟間隔最大化的問題。
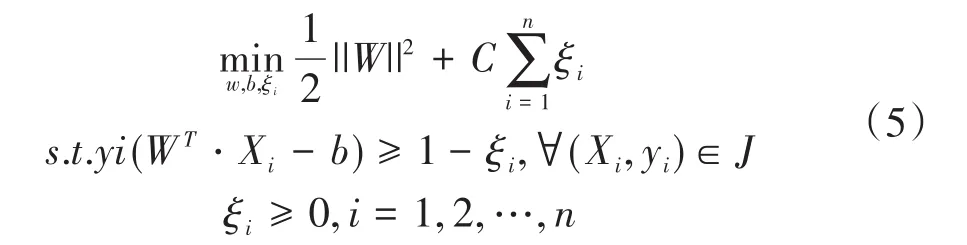
式中,W、b均表示為訓練參數;C表示懲罰因子。一個樣本對應一個松弛變量,一個松弛變量即為一個hinge損失函數:
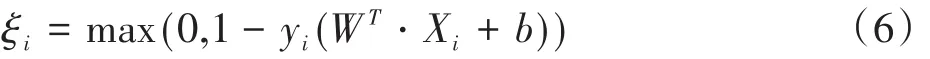
通過不斷調節W、b可以使目標函數最小化。然后選擇適當的懲罰因子以及核函數,利用拉格朗日乘子法可求解式(5)的對偶問題,得到W的最優解W*。最后通過W*分量wi*計算b的最優解b*:

式中,k(?,?)為核函數。在線性可分中,核函數可由樣本實例的之間的內積進行表示;在線性不可分問題中,首先需要將線性不可分轉化為線性可分,通過SVM將樣本空間映射到一個高緯度的特征空間,獲得了樣本在這個特征空間的線性可分,再求得樣本實例之間的內積用以表示核函數。但由于特征空間維度較高,因此直接計算內積十分困難。為避免該問題,本研究用決定用非線性SVM核函數替換線性SVM的內積。
設輸入空間為□,□*□的對稱函數為k(?,?),則 k為核函數對于任意數據D={X1,X2,…,Xn},核矩陣K總是半正定:
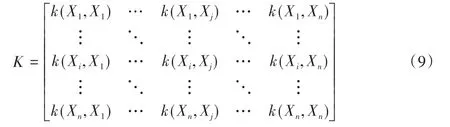
實際上,每一個核函數對于任意輸入空間的(Xi,Xj)均存在一個從輸入空間到特征空間的映射φ(□)使k(Xi,Xj)滿足條件:
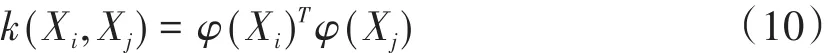
常用的核函數主要包括高斯核、多項式核、拉普拉斯核、sigmoid核等,由于高斯核更具有普適性,因此本研究采用高斯核作為SVM的核函數。
3 基于CNN-SVM的SDN網絡鏈路故障定位算法
基于CNN?SVM的SDN網絡鏈路故障定位算法避免了人工提取特征的誤差性,使SDN網絡鏈路故障定位更加精確,其故障定位主要分為三個步驟,如圖5所示。
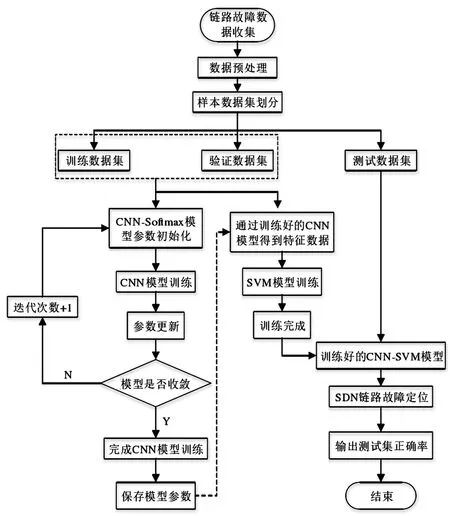
圖5 基于CNN-SVM的SDN網絡鏈路定位算法流程
步驟1:訓練CNN模型。對采集到的SDN網絡狀態數據進行重構和預處理操作,將處理后的數據作為輸入數據。然后利用softmax函數和反向傳播算法訓練CNN模型,得到最小化損失函數,完成對CNN模型的訓練。
步驟2:訓練SVM。使用訓練好的CNN模型提取原始數據中具有代表性的特征,實現對SVM的訓練。
步驟3:故障定位。利用訓練好的CNN?SVM對SDN網絡鏈路進行故障定位。
3.2 基于CNN-SVMSDN網絡鏈路狀態基本參數
SDN網絡中存在多條鏈路,而這些鏈路可能同時出現故障。因此,為使CNN?SVM算法可同時定位多條鏈路故障,應確保控制器采集到的數據能全面反映網絡中所有鏈路的狀態。通常情況下,反映網絡鏈路狀態的參數眾多,包括鏈路時延、鏈路吞吐量、鏈路丟包率等,只有綜合利用這些參數,才能更準確地對SDN網絡鏈路狀態進行判斷。這些參數一般不能由SDN控制器直接獲取,需要通過數據計算獲取。
4 仿真實驗
為驗證提出的基于CNN?SVM的SDN鏈路故障定位算法的有效性,本研究在pycharm中,采用Python從超參數對模型的影響、模型故障定位結果兩個方面完成了對CNN?SVM的SDN鏈路故障定位算法的仿真實驗,并通過與標準CNN模型比較,對提出的算法性能進行了分析。
4.1 CNN超參數對模型的影響
CNN是本研究提出的基于CNN?SVM的SDN鏈路故障定位算法的特征提取部分,因此其超參數對特征提取結果的影響,直接影響整個CNN?SVM故障定位算法的準確度。為使實驗參數設置合理,本研究以最小損失函數和softmax函數作為分類函數,探究了除CNN結構(如表1所示)以外的其他超參數,包括激活函數、優化算法、批處理大小對CNN模型的影響。

表1 本實驗采用的CNN結構參數
4.1.1 激活函數對模型的影響
常見的激活函數包括sigmoid、tanh、relu,一定程度上影響了CNN模型的訓練效果。通常情況下,這些激活函數由歷史經驗獲取,缺乏可靠性。因此本研究在實驗中,以批處理大小為100,迭代次數為500,優化算法為Adam對以上常見激活函數進行了比較,得到如表2所示的實驗結果。由表可知,在訓練時間為135 s左右,tanh函數的訓練準確度最高,達到95.89%;relu函數的測試準確度最高,達到95.01%。由此可以看出,relu函數的泛化性更高,故本研究采用relu函數作為CNN的激活函數。
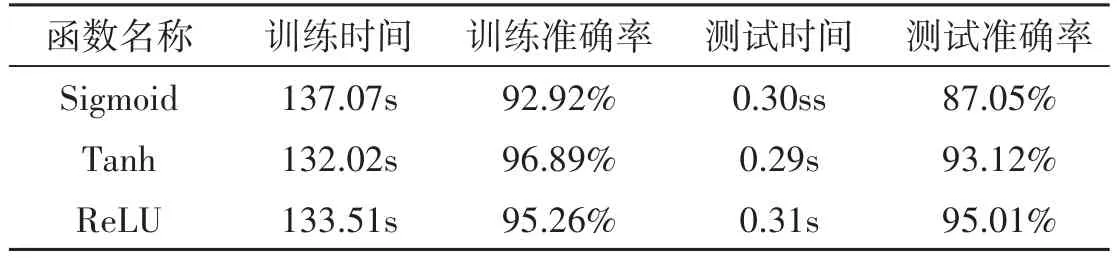
表2 常見激活函數實驗結果比較
4.1.2 優化算法對模型的影響
研究以批處理大小為100,迭代次數為500,激活函數為relu的條件下,采用常見的優化算法包括SGD、Adagarad、Adam、AdaDelta對模型訓練進行了比較,得到如下表3所示的實驗結果。由表可知,Adam優化算法無論是訓練時間、測試時間,還是訓練準確率或測試準確率均由于其他優化算法,因此本研究采用Adam作為CNN模型的優化算法。
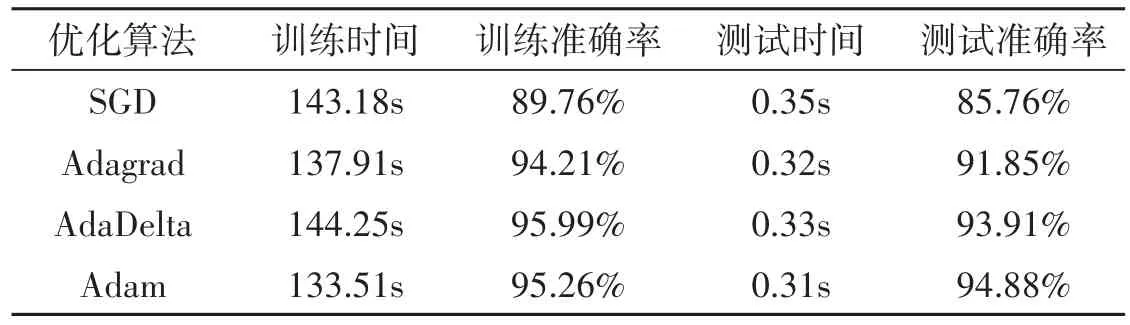
表3 常見優化算法實驗結果比較
4.1.3 不同批處理大小對模型的影響
研究以迭代次數為500,激活函數為relu,Adam為優化算法的條件下,通過實驗研究了不同批處理大小對模型的影響,實驗結果如下表4所示。由表可知,隨著批處理大小增大,模型的平均訓練時間逐漸縮短,模型的訓練準確率先增后減,在批處理大小為64時,模型的訓練準確率逐漸降低。因此,綜合考慮訓練時間和訓練準確率,本研究認為批處理大小為64時,可得到最優的模型訓練結果。
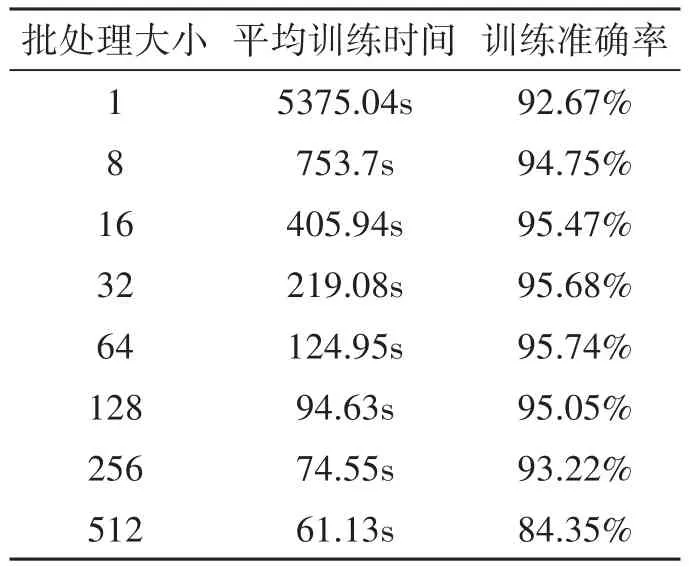
表4 不同批處理大小對模型訓練的影響結果
綜上可確定CNN?SVM故障定位算法模型中CNN的部分超參數,其中,激活函數為rulu,優化算法為Adam,批處理大小為64。
4.2 模型故障定位結果與分析
完成上述CNN模型訓練后,將CNN全連接層的輸出輸入SVM中并進行訓練,然后將訓練好的CNN?SVM模型對SDN網路鏈路中的故障進行定位。本次實驗通過網格搜索確定了懲罰因子和gamma參數分別為10和0.1,以徑向基函數作為SVM的核函數,對基于CNN?SVM的SDN網路鏈路故障定位算法的查準率p、查全率r、F1?測度通過式(11)進行了計算,得到表5所示的計算結果。由表5可知,本研究提出的CNN?SVM算法的查準率、查全率、F1?測度均高于93%,說明該算法基本可滿足SDN網絡鏈路故障定位。
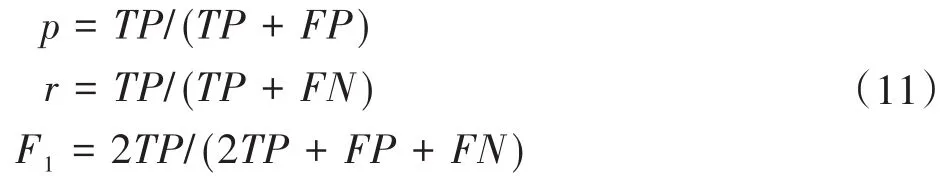

表5 CNN-SVM算法的查準率p、查全率r、F1-測度
為更好地分析CNN?SVM算法的漏報、誤報率,本研究將表5中8種故障情況,每種故障情況有300個測試樣本,共2 400個測試樣本的故障定位結果進行了整理,得到如下圖6所示的多類混淆矩陣。圖6中,橫行表示查全率相關信息,豎列表示查準率相關信息,對角線上數據則表示每種故障正確分類的樣本數。由圖可知,在所有測試樣本中,有2 318個故障定位診斷正確,準確率約為96.58%,說明本研究提出的CNN?SVM算法具有良好的故障定位性能,可同時定位SDN網絡中多條鏈路的故障問題。此外,圖中鏈路的故障數目對算法診斷的效果并沒有太大影響,這說明本研究提出的CNN?SVM算法的故障診斷性能不會明顯受到故障數目的影響。
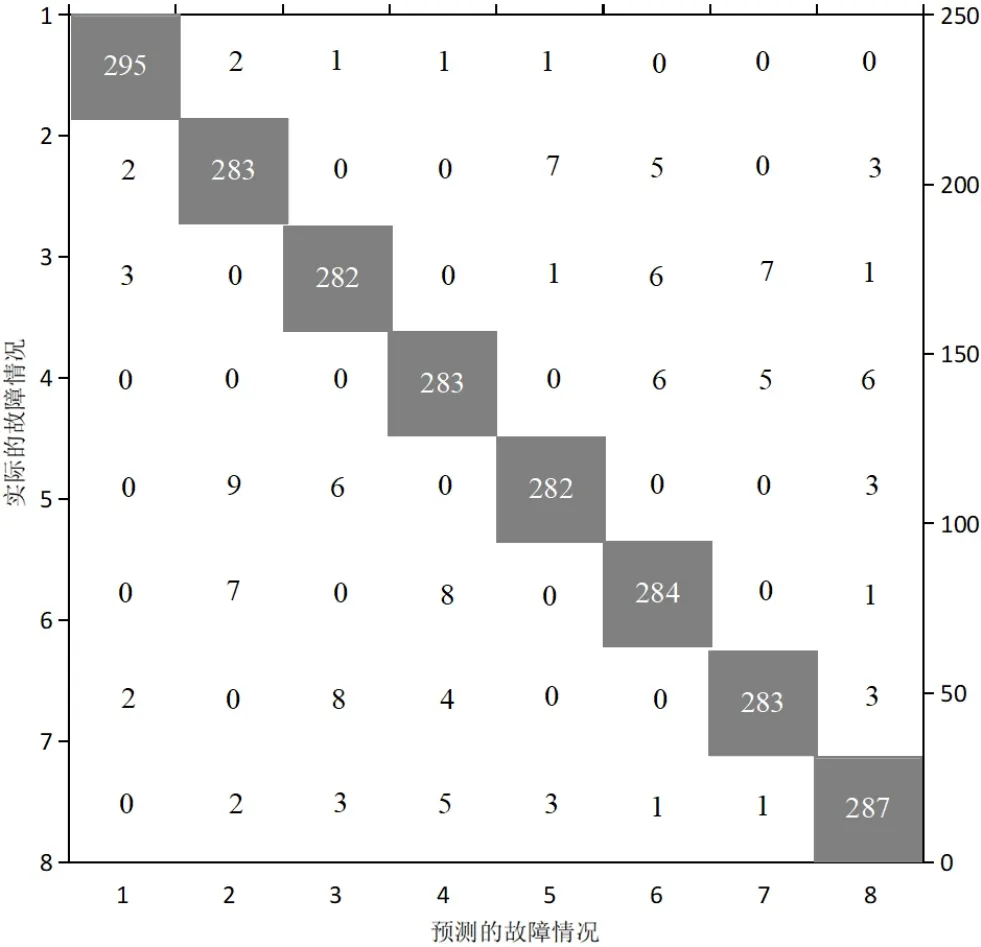
圖6 多類混淆矩陣結果
4.3 算法比較
為探究CNN?SVM算法模型的優勢,本研究在激活函數為rulu,優化算法為Adam,批處理大小為64的相同條件下,將該算法模型與標準CNN算法模型(卷積核大小為3*3,池化核為2*2,分類函數為softmax)進行比較。
CNN?SVM算法模型與標準CNN算法模型的訓練時間、測試時間、測試準確率的比較結果如下表6所示。由表可知,CNN?SVM算法模型的訓練時間和測試時間均低于標準的CNN模型,且其準確率更高,說明本研究提出的CNN?SVM提高了算法故障定位的性能。
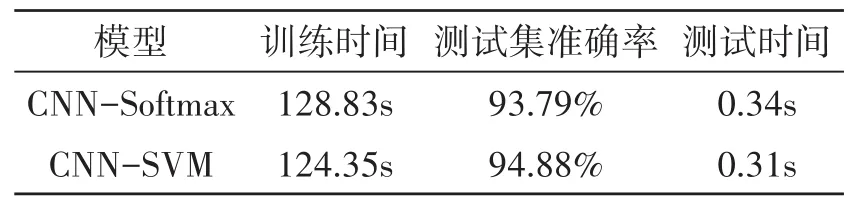
表6 CNN-SVM模型與標準CNN模型性能比較
CNN?SVM算法模型與標準CNN算法模型的查準率、查全率、F1?測度比較結果如下圖7、8、9所示。由圖可知,CNN?SVM算法模型在查準率、查全率和F1?測度方面均優于標準CNN模型,說明CNN?SVM算法模型具有更好的故障分類和定位的能力。

圖7 CNN-SVM與標準CNN查準率比較圖
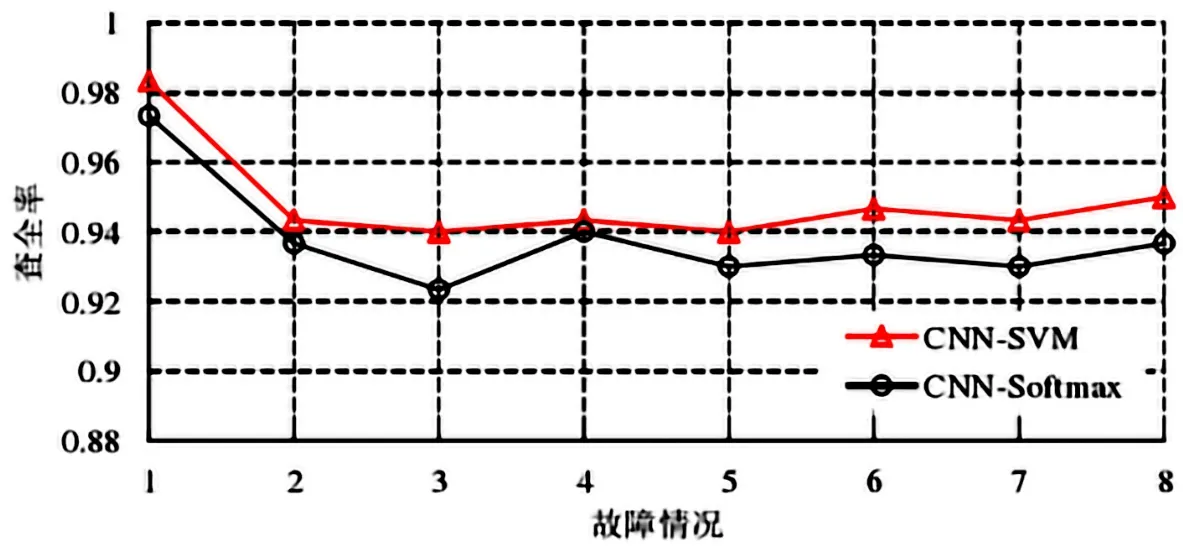
圖8 CNN-SVM與標準CNN查全率比較圖
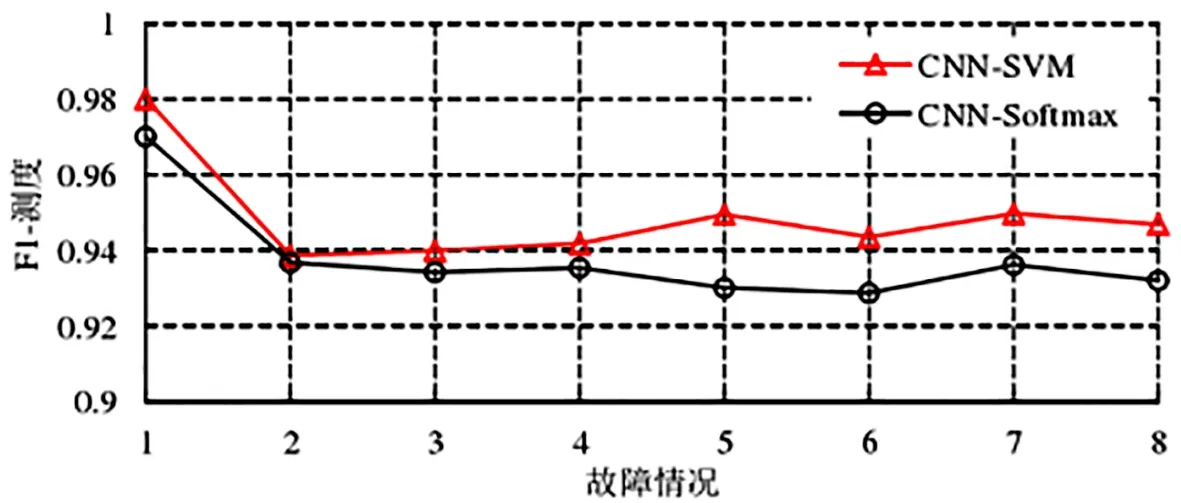
圖9 CNN-SVM與標準CNN的F1-測度比較圖
5 結語
本研究根據SDN網絡系統結構特點,在標準的CNN算法和SVM分類器基礎上,提出一種基于CNN?SVM的SDN網絡鏈路故障定位算法模型。在該模型中,以CNN作為故障數據的特征提取器,以SVM分類器作為故障的定位分類器,實現了對SDN網絡鏈路的故障定位。然后。最后,為提出的CNN?SVM算法的有效性,本研究設計了相關的實驗。實驗結果表明,本研究提出的CNN?SVM提高了傳統CNN算法在SDN網絡鏈路中的故障定位的精確度,具有良好的故障分類和定位的能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
核科學與工程(2015年4期)2015-09-26 11:59:03
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維修與保養(2015年2期)2015-04-17 01:30:34
