基于深度強化學習的汽車自動緊急制動策略*
2021-05-24 05:45:26黃舒?zhèn)?/span>何少煒金智林
汽車技術(shù) 2021年5期
關(guān)鍵詞:策略
黃舒?zhèn)?何少煒 金智林
(南京航空航天大學,機械結(jié)構(gòu)力學及控制國家重點實驗室,南京 210016)
主題詞:高級駕駛輔助系統(tǒng) 自動緊急制動 深度強化學習 制動安全性 乘坐舒適性
1 前言
汽車自動緊急制動(Automatic Emergency Braking,AEB)系統(tǒng)作為一種新型主動安全技術(shù),可以在駕駛員制動不及時的情況下對車輛進行自動制動,避免碰撞事故的發(fā)生。
當前,AEB系統(tǒng)的控制策略一般基于安全距離和安全時間對車輛的碰撞風險進行評估[1-2],其中基于碰撞時間(Time To Collision,TTC)的縱向避撞算法性能較好,使用廣泛[3]。蘭鳳崇等[4]通過構(gòu)建分層控制實現(xiàn)自動緊急制動,上層控制器基于設(shè)定的TTC閾值選取分級制動減速度,下層控制器對制動力進行控制,能夠有效避免碰撞,但由于制動減速度為有限的離散值,不能很好地適應變化的工況,且制動過程的加速度波動較大,舒適性較差。劉樹偉[5]使用模糊控制策略對制動壓力進行控制,使制動減速度變化平緩,在一定程度上提高了制動過程的舒適性。楊為等[6]基于碰撞風險評估與車輛狀態(tài)設(shè)計模糊控制制動策略,輸出的制動減速度在一定范圍內(nèi)平穩(wěn)變化,較定值分級制動策略舒適性更好,但制動減速度的變化范圍仍然較小。通過設(shè)計制動規(guī)則的方式難以實現(xiàn)制動減速度在自動緊急制動過程中的連續(xù)變化,故考慮制動減速度的連續(xù)變化是AEB 系統(tǒng)制動策略設(shè)計中的重要問題。
強化學習是以目標為導向的學習工具,在學習過程中,智能體通過與環(huán)境的交互來學習更符合長期回報的策略[7-8]。谷歌團隊提出深度確定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法,實現(xiàn)強化學習在連續(xù)動作空間決策與控制中的應用[9],隨后,越來越多的研究將強化學習應用于智能駕駛技術(shù)。其中,徐國艷[10]等在DDPG 算法基礎(chǔ)上增大樣本空間,進行無人車避障學習,在TORCS 平臺進行避障效果仿真。Zhu[11]和Zhou[12]運用深度強化學習構(gòu)建自動駕駛跟車系統(tǒng),提高了智能車在交叉路口的行駛效率、燃油經(jīng)濟性和安全性。An[13]提出結(jié)合深度強化學習和車輛通信的變道系統(tǒng),在不需要車輛動力學模型的情況下實現(xiàn)了直線駕駛和避撞動作的學習。
本文將深度強化學習應用在自動緊急制動系統(tǒng)制動策略的設(shè)計中,得到的制動策略可以根據(jù)車輛安全狀態(tài)的改變實時調(diào)整期望制動加速度,實現(xiàn)對制動過程的更精細控制,提高乘坐舒適性。
2 AEB系統(tǒng)結(jié)構(gòu)及動力學模型
本文構(gòu)建的AEB仿真系統(tǒng)結(jié)構(gòu)如圖1所示,系統(tǒng)由強化學習制動決策模塊、制動執(zhí)行模塊、主車動力學模型、前車運動學模型和獎勵函數(shù)5個部分組成。強化學習制動決策模塊基于兩車信息和獎勵函數(shù)輸出的獎勵值進行制動策略學習,輸出期望減速度,經(jīng)制動執(zhí)行模塊轉(zhuǎn)化為制動力作用于主車動力學模型,實現(xiàn)車輛自動緊急制動。

圖1 AEB仿真系統(tǒng)結(jié)構(gòu)
為了降低動力學模型的復雜度,且不影響模型準確性,作出如下假設(shè):以前輪轉(zhuǎn)角作為模型的輸入;將車輛簡化為單軌模型;忽略車輛側(cè)傾、垂向和俯仰運動。
將動力學模型簡化為具有縱向、側(cè)向和橫擺運動的3自由度模型,如圖2所示,動力學方程為:
式中,m為車輛質(zhì)量;vx、vy分別為車輛縱向與橫向速度;Fxf、Fxr分別為前、后輪切向力;Fyf=k1α1、Fyr=k2α2分別為前、后輪橫向力;k1、k2分別為前、后輪側(cè)偏剛度;α1、α2分別為前、后輪側(cè)偏角;δ為前輪轉(zhuǎn)角;Iz為車輛繞z軸的轉(zhuǎn)動慣量;ω為車輛橫擺角速度;lf、lr分別為質(zhì)心與前、后軸的距離。
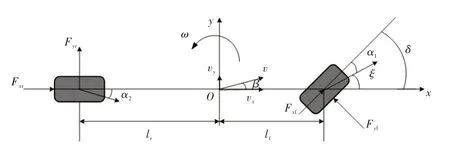
圖2 3自由度動力學模型
α1、α2與車輛運動參數(shù)有關(guān):

式中,β=vx/vy為質(zhì)心側(cè)偏角;ξ=β+lfω/vy為前輪速度與x軸的夾角。
車輛在緊急制動過程中發(fā)動機不提供扭矩,動力學模型的輸入變量為制動力,則前、后輪縱向力為:

式中,F(xiàn)bf、Fbr分別為前、后輪制動力;g為重力加速度;f為滾動阻力系數(shù)。
制動執(zhí)行機構(gòu)進行期望制動力的分配,前、后車輪制動力分別為:

式中,aμ為期望制動減速度。
3 制動策略
3.1 狀態(tài)量及動作量設(shè)計
為了設(shè)計和驗證自動緊急制動策略,使用MATLAB的駕駛場景設(shè)計器(Driving Scenario Designer)構(gòu)建AEB仿真場景,在Simulink中搭建強化學習自動緊急制動策略,感知模塊選用Simulink環(huán)境提供的標準信息,如圖3所示,感知的狀態(tài)量包括主車速度ve、主車加速度ae、主車與前車的相對距離dr和相對速度vr,其中:

式中,vf為前車速度。

圖3 AEB測試場景示意
狀態(tài)量可表示為:

制動決策模塊根據(jù)狀態(tài)量St和當前學習到的制動策略μAEB,決定輸出期望制動減速度aμ,減速度被限制在0~9 m/s2范圍內(nèi),動作量可表示為:

3.2 獎勵函數(shù)
獎勵函數(shù)決定了制動決策模塊的制動策略。獎勵計算模塊根據(jù)每一時刻的狀態(tài)量計算獎勵值輸出至決策模塊,引導決策模塊學習規(guī)則制定者需要的制動策略。獎勵函數(shù)為:

式中,rd為主車制動至停止時與前車距離的獎勵值。
獎勵函數(shù)計算了當前時刻碰撞時間與主車以當前減速度制動停止時間的差值,為防止出現(xiàn)分母為0,獎勵值趨于無窮大的情況,統(tǒng)一在分母中加0.1。初始條件下,主車速度大于前車速度,且制動減速度較小,該部分獎勵值為負,隨著制動減速度的增大,主車速度下降,該部分獎勵值逐漸增大,當主車速度降至小于前車速度后,該部分獎勵值仍隨主車速度的下降而增大,引導制動策略使主車制動至停止。若主車在距離前車5~8 m的區(qū)間內(nèi)停止,則附加高額的獎勵值rd。經(jīng)試驗,取rd=200可以使制動策略在該區(qū)間內(nèi)使車輛制動至停止。
3.3 強化學習算法
為在連續(xù)動作空間輸出期望制動加速度,強化學習算法選用深度確定性策略梯度DDPG算法。DDPG算法在演員評論家(Actor-Critic)網(wǎng)絡框架的基礎(chǔ)上,基于深度Q 網(wǎng)絡的經(jīng)驗回放和目標網(wǎng)絡結(jié)構(gòu)對確定性策略梯度算法進行了改進[14]。
自動緊急制動策略強化學習算法如圖4 所示。在每個仿真時刻,演員網(wǎng)絡依據(jù)當前狀態(tài)St輸出動作量At到AEB 仿真環(huán)境,同時演員網(wǎng)絡與評論家網(wǎng)絡進行參數(shù)的迭代更新。演員網(wǎng)絡與評論家網(wǎng)絡都包含獨立的評估網(wǎng)絡與目標網(wǎng)絡,以解決單一神經(jīng)網(wǎng)絡的訓練過程不穩(wěn)定問題。演員網(wǎng)絡與評論家網(wǎng)絡分別表征制動策略與制動價值函數(shù)。制動策略依據(jù)制動狀態(tài)輸出期望制動減速度aμ,制動價值函數(shù)計算出給定狀態(tài)及采取的制動動作下的長期回報。在演員網(wǎng)絡和評論家網(wǎng)絡更新的過程中,首先計算提取出每份經(jīng)驗預估回報Uk:

式中,Sk、Sk+1、Rk分別為提取的第k組經(jīng)驗的初始狀態(tài)、下一時刻狀態(tài)和獎勵;λ為折損系數(shù),代表制動策略學習過程中長期價值所占的比重;Q′AEB為目標網(wǎng)絡制動狀態(tài)價值函數(shù);μ′AEB為目標網(wǎng)絡制動策略。

圖4 自動緊急制動策略強化學習算法
隨后,評論家網(wǎng)絡的求解器使用式(10)計算制動價值函數(shù)與預估回報的偏差L,并運用梯度下降算法朝著偏差L減小的方向更新評估網(wǎng)絡制動價值函數(shù)的參數(shù):

式中,QAEB為網(wǎng)絡制動價值評估函數(shù);N為提取經(jīng)驗的份數(shù);E為從經(jīng)驗回放池中提取出的多組用于訓練的狀態(tài)量與對應獎勵的集合。
演員網(wǎng)絡的求解器使用式(11)計算平均長期回報qa,并運用梯度下降算法朝著qa梯度下降最快方向更新評估網(wǎng)絡制動策略參數(shù):

目標網(wǎng)絡的參數(shù)值則是在完成了一個最小數(shù)據(jù)集的訓練后,使用緩慢更新(Soft Update)算法進行更新:
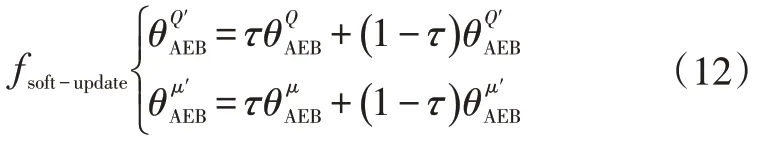
3.4 神經(jīng)網(wǎng)絡結(jié)構(gòu)
激活函數(shù)選用線性整流(Rectified Linear Unit,ReLU)激活函數(shù)與雙曲正切激活函數(shù):

評論家網(wǎng)絡的結(jié)構(gòu)如圖5 所示,具有2 個輸入與1個輸出。演員網(wǎng)絡結(jié)構(gòu)如圖6所示,為單輸入單輸出的神經(jīng)網(wǎng)絡,用以表達制動策略。選用Adam求解器進行優(yōu)化求解,強化學習的訓練參數(shù)如表1所示。

圖5 評論家網(wǎng)絡結(jié)構(gòu)

圖6 演員網(wǎng)絡結(jié)構(gòu)

表1 訓練參數(shù)
4 實例仿真分析
為驗證自動緊急制動策略的控制效果,參考中國新車評價規(guī)程(C-NCAP)測試規(guī)則[15],通過改變兩車的初始位置、初速度和初始制動減速度,設(shè)計了前車靜止、前車慢行、前車減速3種直線工況。主車動力學模型參數(shù)如表2所示。
參考文獻[4]中的分級制動策略,設(shè)計傳統(tǒng)分級制動AEB制動策略與強化學習AEB制動策略的對比測試方案。碰撞時間tTTC、制動預警時間tfcw和各級制動時間tbn的計算公式為:

式中,afcw=4 m/s2為駕駛員制動預警減速度;treact=1.2 s 為駕駛員反應時間;ab1=3.8 m/s2、ab2=5.3 m/s2、ab3=9.8 m/s2分別為第1級、第2級、第3級制動減速度。
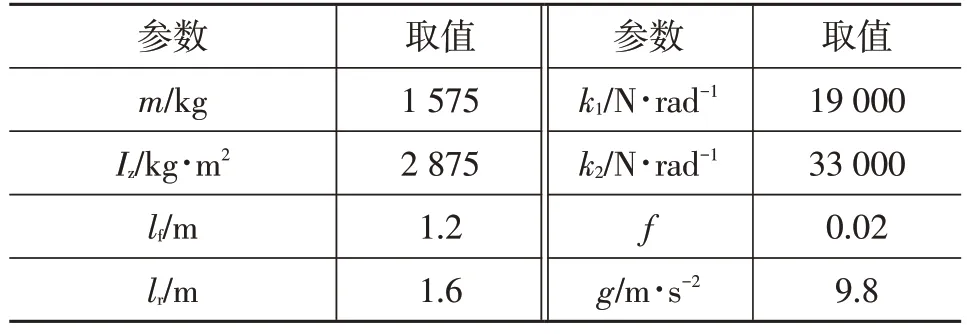
表2 車輛參數(shù)
tb1<tTTC≤tfcw時,傳統(tǒng)AEB制動策略開始介入,采取第1 級制動減速度ab1;tb2<tTTC≤tb1時,傳統(tǒng)AEB 制動策略采用第2 級制動減速度ab2;tTTC≤tb2時,傳統(tǒng)AEB 制動策略采用第3級制動減速度ab3。
4.1 直線行駛工況
直線行駛前車靜止工況兩車初始距離為24 m,前車靜止,主車以30 km/h 速度行駛。實例仿真得到強化學習各回合獎勵如圖7 所示,初始學習階段,制動策略的獎勵經(jīng)歷了振蕩下降,10 個回合后,獎勵大幅上升,并穩(wěn)定在0 附近,制動決策模塊獲得獎勵較高的策略,且實現(xiàn)收斂。

圖7 前車靜止工況強化學習獎勵
圖8所示為前車靜止工況的主車制動減速度、兩車相對距離及相對速度仿真結(jié)果。從圖8中可以看出,前車靜止時,強化學習AEB 與傳統(tǒng)AEB 系統(tǒng)都能有效制動,車輛停止時與前車的距離都在8 m左右。傳統(tǒng)AEB制動策略在tTTC<tfcw后開始介入,采用第1級制動減速度制動至車輛停止。強化學習AEB系統(tǒng)的制動策略是使用較小的制動力長時間制動,保持一定的制動減速度,車速變化均勻,具有更好的舒適性。
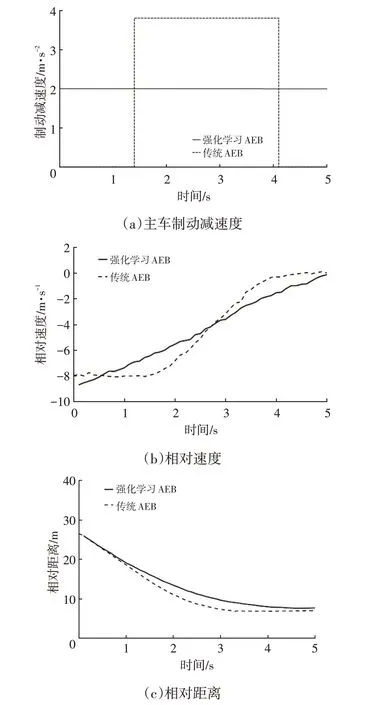
圖8 直道行駛前車靜止工況仿真結(jié)果
直道行駛前車慢行工況下,兩車初始距離15 m,前車以20 km/h 速度行駛,主車以30 km/h 速度行駛,仿真結(jié)果如圖9所示。由圖9a可見,由于存在噪聲引起的隨機性探索,學習過程的獎勵存在一定波動,但總體上策略收斂。傳統(tǒng)分級制動AEB 系統(tǒng)在2 s后才開始制動,兩車最小距離小于5 m,而強化學習AEB系統(tǒng)在兩車相距較遠時即以小制動減速度進行制動,隨著兩車距離的減小,制動減速度逐漸增大,保持兩車相對距離大于7.5 m,將兩車最小距離控制在更安全的范圍內(nèi),并且制動減速度的增長是連續(xù)的,速度的變化也更平緩,制動過程舒適性更好。強化學習AEB系統(tǒng)的制動減速度在最初2 s 出現(xiàn)了小幅振蕩,這是制動策略學習過程中加入的隨機噪聲帶來的隨機性探索造成的。若想減小振蕩,可以減小隨機噪聲方差或在獎勵函數(shù)中加入對制動減速度變化率的懲罰項。

圖9 直道行駛前車慢行工況仿真結(jié)果
直道行駛前車減速工況下,兩車初始距離為40 m,主車與前車初速度均為50 km/h,前車以4 m/s2的減速度制動至停止結(jié)束,仿真結(jié)果如圖10所示。由圖10可知:制動策略實現(xiàn)了收斂;強化學習AEB和傳統(tǒng)AEB系統(tǒng)都能使主車完全停止,保持兩車5 m 以上安全距離;強化學習AEB 系統(tǒng)的制動減速度更小,但制動持續(xù)時間長,速度的變化更為平緩。仿真結(jié)果表明,強化學習AEB 系統(tǒng)滿足C-NCAP 測試標準要求,同時兼顧了舒適性。

圖10 直道行駛前車減速工況仿真結(jié)果
4.2 彎道工況
研究中,考慮車輛的側(cè)向運動與橫擺運動,以實現(xiàn)彎道自動緊急制動功能。在彎道工況中,設(shè)計前車靜止與前車慢行2種工況進行仿真。前車靜止工況中,主車在半徑40 m的定曲率弧形道路上以恒定的前輪轉(zhuǎn)角行駛,主車速度30 km/h,前車靜止,兩車初始距離25 m。前車慢行工況中,前車以20 km/h 的速度沿弧形道路勻速行駛,主車初速度為30 km/h,兩車初始距離15 m。
在彎道行駛前車靜止工況中,主車保持2 m/s2的制動減速度持續(xù)制動至停車,主車與前車保持了7.5 m 的距離。兩車相對速度與相對距離如圖11所示。

圖11 彎道行駛前車靜止工況仿真結(jié)果
彎道行駛前車慢行工況仿真結(jié)果如圖12所示。在整個制動過程中,制動減速度控制在2 m/s2以下,速度變化平緩。制動減速度隨著兩車距離的減小逐漸增大,在主車速度降至前車速度以下后,強化學習AEB 系統(tǒng)減小了制動減速度將車輛制動至停止,兩車的最小距離為8.7 m,保證了安全性。在這兩種工況下,強化學習制動策略都實現(xiàn)了收斂。


圖12 彎道行駛前車慢行工況仿真結(jié)果
5 結(jié)束語
本文應用深度強化學習算法設(shè)計了適用于車輛3自由度動力學模型的自動緊急制動策略,得到的強化學習自動緊急制動策略滿足C-NCAP 自動緊急制動測試標準,在彎道制動工況也能有效制動,且收斂性好,改善了制動過程乘坐舒適性。在后續(xù)研究中還需針對制動加速度的小幅振蕩問題、獎勵函數(shù)形式以及神經(jīng)網(wǎng)絡結(jié)構(gòu)加以改進,力求得到更符合人類駕駛員習慣的制動策略。
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:42
中學生數(shù)理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年9期)2018-10-08 02:29:48
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:10
數(shù)學大世界(2018年1期)2018-04-12 05:39:14
幸福(2017年18期)2018-01-03 06:34:53
中國衛(wèi)生(2016年8期)2016-11-12 13:26:50
