基于雙向特征金字塔和深度學(xué)習(xí)的圖像識(shí)別方法
2021-05-21 04:47:32趙升,趙黎
哈爾濱理工大學(xué)學(xué)報(bào) 2021年2期
趙 升,趙 黎
(1.昆明醫(yī)科大學(xué)第三附屬醫(yī)院 PET/CT中心,昆明 650118;2.昆明醫(yī)科大學(xué) 基礎(chǔ)醫(yī)學(xué)院,昆明 650500)
0 引 言
計(jì)算機(jī)視覺(jué)是一個(gè)多學(xué)科交叉的領(lǐng)域, 主要研究從靜態(tài)圖像或者視頻流中自動(dòng)提取、分析和理解有價(jià)值信息的理論和方法[1]。圖像物體識(shí)別與檢測(cè)(圖像識(shí)別)是指從靜態(tài)圖像或視頻流中識(shí)別及定位出其中感興趣的物體,是計(jì)算機(jī)視覺(jué)領(lǐng)域的一個(gè)基礎(chǔ)性任務(wù)。近年來(lái),得益于深度學(xué)習(xí)理論和方法的長(zhǎng)足發(fā)展,圖像識(shí)別也取得了許多新的突破[2-4]。然而,多尺度圖像識(shí)別依然是一項(xiàng)極具挑戰(zhàn)性的任務(wù)。一幅圖像所包含的物體有大有小,多尺度圖像識(shí)別旨在可以識(shí)別出圖像中不同大小的物體。現(xiàn)有的圖像識(shí)別方法通常對(duì)大小適中的物體識(shí)別精度較好,對(duì)過(guò)大或者過(guò)小的物體識(shí)別精度都較差。多尺度圖像識(shí)別依然是當(dāng)前的難點(diǎn)和前沿問(wèn)題。
當(dāng)前,基于深度神經(jīng)網(wǎng)絡(luò)的物體識(shí)別方法可以分為兩類(lèi):?jiǎn)尾襟E圖像識(shí)別方法和雙步驟圖像識(shí)別方法。顧名思義,單步驟圖像識(shí)別方法只有一個(gè)步驟,即通過(guò)對(duì)位置、比例和縱橫比進(jìn)行常規(guī)或密集采樣實(shí)現(xiàn)物體識(shí)別。雙步驟圖像識(shí)別方法分為兩個(gè)步驟:第一步驟為稀疏物體識(shí)別方案集生成模型,第二步驟為方案集中物體識(shí)別方法的分類(lèi)與回歸。區(qū)別于單步驟圖像識(shí)別方法,雙步驟圖像識(shí)別方法可輸出每個(gè)步驟的中間結(jié)果以更好地診斷圖像識(shí)別性能。相較于雙步驟圖像識(shí)別方法,單步驟圖像識(shí)別方法通常具有較高的計(jì)算效率和相對(duì)較低的識(shí)別精度。在單步驟圖像識(shí)別方法中,保持圖像采集邊框尺度和物體大小的一致是提高圖像識(shí)別精度的關(guān)鍵。因此,高層次的語(yǔ)義特征和密集的尺度覆蓋是提高單步驟圖像識(shí)別方法精度的有效途徑。然而,當(dāng)前大多數(shù)深度神經(jīng)網(wǎng)絡(luò)對(duì)圖像邊框的大小都是固定不變的,其使得現(xiàn)有大多數(shù)基于深度神經(jīng)網(wǎng)絡(luò)的方法都無(wú)法徹底解決多尺度圖像識(shí)別。
特征金字塔是解決不同尺度圖像語(yǔ)義特征提取的有效途徑。近年來(lái),特征金字塔已被應(yīng)用于現(xiàn)有基于深度神經(jīng)網(wǎng)絡(luò)的圖像識(shí)別方法,以解決多尺度圖像識(shí)別問(wèn)題。基于特征金字塔的圖像識(shí)別方法利用不同尺度特征映射來(lái)識(shí)別不同尺度的物體。2016年,Liu等[5]提出了基于特征金字塔的多尺度圖像識(shí)別方法——Single Shot Detector(SSD)。SSD首先根據(jù)原始圖像生成多個(gè)不同尺度的特征圖像,而后從多個(gè)不同尺度的特征圖識(shí)別不同尺度的物體。然而,淺層特征映射中的小尺度語(yǔ)義信息限制了SSD的分類(lèi)和回歸能力。為解決該問(wèn)題,Zhou等[6]提出了Scale-Transferrable Detection Network(STDN)算法。STDN算法在DenseNet的最后環(huán)節(jié)嵌入尺度轉(zhuǎn)移模塊來(lái)生成具有大尺度語(yǔ)義信息的高分辨率特征映射。此外,許多研究[7-9]還探索了自上而下的特征金字塔特征融合方法以提升圖像識(shí)別的精確度。自上而下的特征金字塔融合方式將大尺度特征的語(yǔ)義信息融入小尺度特征,有助于小尺度物體識(shí)別。然而,大尺度物體識(shí)別依然是一個(gè)未解決的問(wèn)題。因此,如何使用小尺度特征的語(yǔ)義信息豐富大尺度特征,提升大尺度物體識(shí)別精確度,是實(shí)現(xiàn)多尺度圖像識(shí)別的關(guān)鍵。
當(dāng)前,大多數(shù)最先進(jìn)的單階段圖像識(shí)別方法大都采用枚舉圖像錨框(anchor box)的方法;然而,錨框往往需要特別設(shè)計(jì)。Faster r-cnn[2]采用人工選擇錨框,Yolo9000[10]采用統(tǒng)計(jì)學(xué)方法(如聚類(lèi))設(shè)定錨框;然而,人工或統(tǒng)計(jì)學(xué)方法所選擇的錨框往往無(wú)法適應(yīng)多尺度圖像識(shí)別。為解決該問(wèn)題,Yang等人[11]提出了MetaAnchor方法。MetaAnchor利用權(quán)重預(yù)測(cè)獲得動(dòng)態(tài)錨框函數(shù),從而一定程度上解決了圖像物體的多尺度問(wèn)題。為了覆蓋圖像中不同形狀的物體,預(yù)定義的錨框往往需要設(shè)定多個(gè)不同的縱橫比。YOLO v3[4]利用每個(gè)金字塔特征圖上不同長(zhǎng)寬比的3個(gè)錨盒進(jìn)行圖像識(shí)別;RetinaNet[12]則采用9個(gè)不同的錨框以實(shí)現(xiàn)圖像不同尺度和形狀物體的密集覆蓋。然而,錨框數(shù)量越多,錨函數(shù)中的參數(shù)會(huì)急劇增多,特別是物體類(lèi)別數(shù)量大的情況下。RefineDet[14]通過(guò)過(guò)濾負(fù)面錨框,在保證圖像識(shí)別效率的同時(shí),取得了最新最好的準(zhǔn)確率。然而,RefineDet[14]本質(zhì)上還是基于自上而下的特征金字塔特征融合方法。
在保證圖像識(shí)別效率的情況下,針對(duì)現(xiàn)有單階段圖像識(shí)別方法所存在的問(wèn)題,本文提出一種特征金字塔語(yǔ)義信息雙向融合的多尺度圖像識(shí)別方法(bidirectional feature fusion-based detector,BFFD)。該方法通過(guò)特征金字塔中不同尺度特征語(yǔ)義信息的雙向融合,提升圖像多尺度物體識(shí)別的精確度。也即,特征金字塔中小尺度特征語(yǔ)義信息可以融入大尺度特征,且大尺度特征語(yǔ)義信息也可融合進(jìn)小尺度特征。基于此,本文的主要貢獻(xiàn)包括:①提出一種特征金字塔語(yǔ)義信息雙向融合方法bidirectional feature fusion(BFF)。BFF通過(guò)高分辨率歸一化方法實(shí)現(xiàn)不同尺度特征的語(yǔ)義信息,為多尺度圖像識(shí)別建立特征基礎(chǔ)。②提出一種基于特征金字塔雙向融合的多尺度圖像識(shí)別方法BFFD。BFFD嵌入特征金字塔語(yǔ)義信息雙向融合方法BFF,而后通過(guò)嵌入深度神經(jīng)網(wǎng)絡(luò),實(shí)現(xiàn)高精度的多尺度圖像識(shí)別。③驗(yàn)證了所提多尺度圖像識(shí)別方法的性能。通過(guò)大量的對(duì)比實(shí)驗(yàn)驗(yàn)證了本文所提出的BFFD算法能有效提升現(xiàn)有方法的多尺度圖像識(shí)別性能。
1 圖像特征金字塔雙向融合模型及圖像識(shí)別方法
圖1為本文所提出特征金字塔雙向融合的多尺度圖像識(shí)別方法BFFD的總體架構(gòu)。BFFD首先通過(guò)深度神經(jīng)網(wǎng)絡(luò)提取不同尺度的特征映射,并作為特征金字塔語(yǔ)義信息雙向融合方法BFF的輸入。而后,BFF通過(guò)語(yǔ)義信息雙向融合生成多尺度特征互補(bǔ)語(yǔ)義信息,實(shí)現(xiàn)對(duì)特征映射的細(xì)化。最后,根據(jù)學(xué)習(xí)到的特征圖生成分類(lèi)閾值和邊框,并通過(guò)非最大值抑制(non-maximum suppression,NMS)得到最終結(jié)果。BFF包括特征融合和自適應(yīng)特征優(yōu)化兩個(gè)步驟。特征融合歸一化不同尺度圖像語(yǔ)義特征,得到超分辨率的特征映射。自適應(yīng)特征優(yōu)化通過(guò)全連接層實(shí)現(xiàn)圖像多尺度信息的雙向融合,生成每個(gè)金字塔級(jí)別的特征映射。而后,BFFD分別用分類(lèi)網(wǎng)絡(luò)來(lái)實(shí)現(xiàn)分類(lèi)預(yù)測(cè),用邊界回歸網(wǎng)絡(luò)輸出邊框回歸。
多尺度問(wèn)題是圖像物體識(shí)別的重要問(wèn)題之一。現(xiàn)有基于金字塔的方法大多采用自頂向下(自上而下)的方式。圖像語(yǔ)義信息單向從大尺度特征單向流轉(zhuǎn)、匯聚到小尺度特征。其使得小尺度特征的物體識(shí)別效果較好,而大尺度特征的物體識(shí)別效果并無(wú)太大改善。顯然,大尺度特征映射也同樣可以通過(guò)小尺度語(yǔ)義信息進(jìn)行完善,從而解決較大物體的邊界模糊問(wèn)題。為解決該問(wèn)題,本文提出一種特征金字塔語(yǔ)義信息雙向融合BFF算法。BFF算法通過(guò)特征語(yǔ)義信息的雙向增強(qiáng),保證小尺度物體識(shí)別精確度的基礎(chǔ)上提升大尺度物體識(shí)別精確度。自頂向下的特征金字塔融合方法和BFF算法之間的比較如圖2所示。

圖1 特征金字塔雙向融合的多尺度物體 識(shí)別方法(BFFD)框架圖Fig.1 The framework of Bidirectional Feature Fusion-based Detector(BFFD)
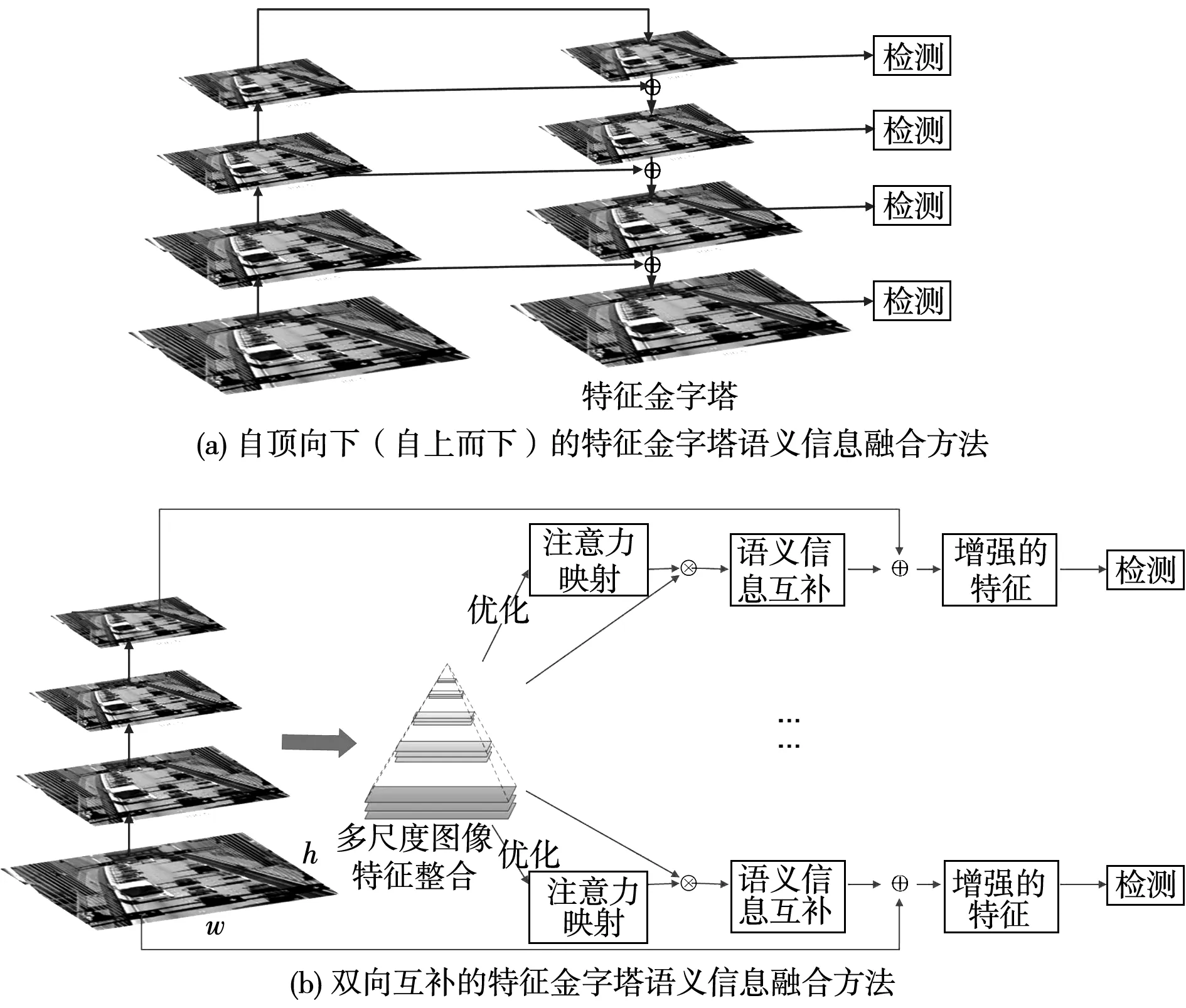
圖2 特征金字塔雙向融合方法(BFF)與 自頂向下融合方法對(duì)比示意圖Fig.2 Comparison diagram of Bidirectional Feature Fusion(BFF) and top-down fusion method
本文采用歸一化方法將特征金字塔中不同尺度特征映射到統(tǒng)一尺度,實(shí)現(xiàn)多尺度圖像特征的融合。具體地,本文借鑒超分辨率方法[13],通過(guò)不同的抽樣因子來(lái)實(shí)現(xiàn)尺度歸一化操作。假設(shè)輸入圖像特征用三維矩陣表示為(D·r2)×H×W,其中r為抽樣因子。尺度歸一化是在r2通道的同一空間對(duì)元素進(jìn)行周期性重排。故有
L(d,y,x)=S([d/r2],y+[mod(d,r2)/r],x+mod(mod(d,r2),r))
(1)
其中:L為大尺度圖像特征;S為小尺度圖像特征。顯然,輸出特征只有原始通道的1/r2倍。本文通過(guò)特征向量串聯(lián)的方式實(shí)現(xiàn)歸一化后多尺度特征的融合。

(2)
(3)
(4)
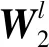
σ(x)=max(0,x)
(5)
(6)
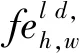
最后,將所提出的BFF算法嵌入到圖像識(shí)別神經(jīng)網(wǎng)絡(luò),形成一種新的基于特征金字塔語(yǔ)義信息雙向融合BFF算法的圖像識(shí)別方法BFFD。在具體實(shí)現(xiàn)上,BFFD通過(guò)將所提出的BFF算法嵌入到RefineDet[14]實(shí)現(xiàn)。VGG[15]在保證具有相同感知野的條件下,通過(guò)提升網(wǎng)絡(luò)的深度,在一定程度上提升了神經(jīng)網(wǎng)絡(luò)的效果。VGG有兩種結(jié)構(gòu),分別是VGG16和VGG19,兩者并沒(méi)有本質(zhì)上的區(qū)別,只是網(wǎng)絡(luò)深度不一樣。相較于VGG19,VGG16具有相對(duì)較少的網(wǎng)絡(luò)層數(shù)、較快的運(yùn)算效率和相當(dāng)?shù)男Ч1疚乃岢龅腂FFD算法選用VGG16[15]作為骨干網(wǎng)絡(luò)。同時(shí),根據(jù)RefineDet對(duì)VGG16的參數(shù)做了一定的采用了修改。首先,通過(guò)子采樣參數(shù)將VGG16的fc6和fc7轉(zhuǎn)換為卷積層convfc6和convfc7。由于conv4-3和conv5-3具有不同的特征尺度,本文使用L2標(biāo)準(zhǔn)化將conv4-3和conv5-3中的特征范數(shù)縮放到10和8,然后在反向傳播過(guò)程中學(xué)習(xí)尺度。輸入大小設(shè)置為512×512。為了生成多層次的圖像特征,RefineDet的TCB模塊替換為本文所提出的BFF算法。
2 實(shí)驗(yàn)驗(yàn)證
本部分首先介紹實(shí)驗(yàn)設(shè)置,包括實(shí)驗(yàn)環(huán)境、數(shù)據(jù)集、對(duì)比方法和評(píng)測(cè)指標(biāo)等。而后,通過(guò)與多種對(duì)比方法的實(shí)驗(yàn)比對(duì),系統(tǒng)驗(yàn)證所提BFFD方法能有效提升多尺度圖像識(shí)別。
2.1 實(shí)驗(yàn)設(shè)置
實(shí)驗(yàn)環(huán)境。實(shí)驗(yàn)環(huán)境為4個(gè)英偉達(dá)1080TI GPU,CUDA 8.0和CUDNN 7.0。實(shí)驗(yàn)訓(xùn)練的批大小設(shè)置為32。在實(shí)驗(yàn)中,VGG16采用ImageNet 2012數(shù)據(jù)集[16]進(jìn)行預(yù)訓(xùn)練。不失一般性,初始狀態(tài)下的訓(xùn)練學(xué)習(xí)率設(shè)置為2×10-3。在訓(xùn)練到第300和350個(gè)周期時(shí),訓(xùn)練學(xué)習(xí)率分別調(diào)整為2×10-4和2×10-5。在訓(xùn)練到第400個(gè)周期時(shí),訓(xùn)練結(jié)束。
數(shù)據(jù)集。實(shí)驗(yàn)的數(shù)據(jù)集包括:PASCAL VOC[17]和MS COCO[18]。PASCAL VOC和MS COCO數(shù)據(jù)集分別包含20和80個(gè)物體類(lèi)別。在PASCAL VOC數(shù)據(jù)集中,訓(xùn)練數(shù)據(jù)集為PASCAL VOC的trainval訓(xùn)練數(shù)據(jù)集,測(cè)試數(shù)據(jù)集為PASCAL VOC的測(cè)試數(shù)據(jù)集。在MS COCO數(shù)據(jù)集中,訓(xùn)練數(shù)據(jù)集為trainval35k,其內(nèi)包含8萬(wàn)張圖片;余下為測(cè)試數(shù)據(jù)集。
對(duì)比方法。由于BFFD采用VGG16作為骨干網(wǎng)絡(luò);因此,對(duì)比方法選用同樣為VGG16的圖像識(shí)別方法,包括Faster R-CNN(Faster)[2],ION[19],MR-CNN[20],SSD[5]和RefineDet[14]。
評(píng)價(jià)指標(biāo)。本文選用平均精確度AP(average precision)和mAP(mean average precision)平均精度均值作為多尺度物體識(shí)別性能的核心指標(biāo)。AP和mAP的定義如下:
(7)
(8)
其中:R為召回率集合;p(r)為召回率為r時(shí)的精確度;I為分類(lèi)總數(shù);AP(i)為分類(lèi)i的平均精確度。
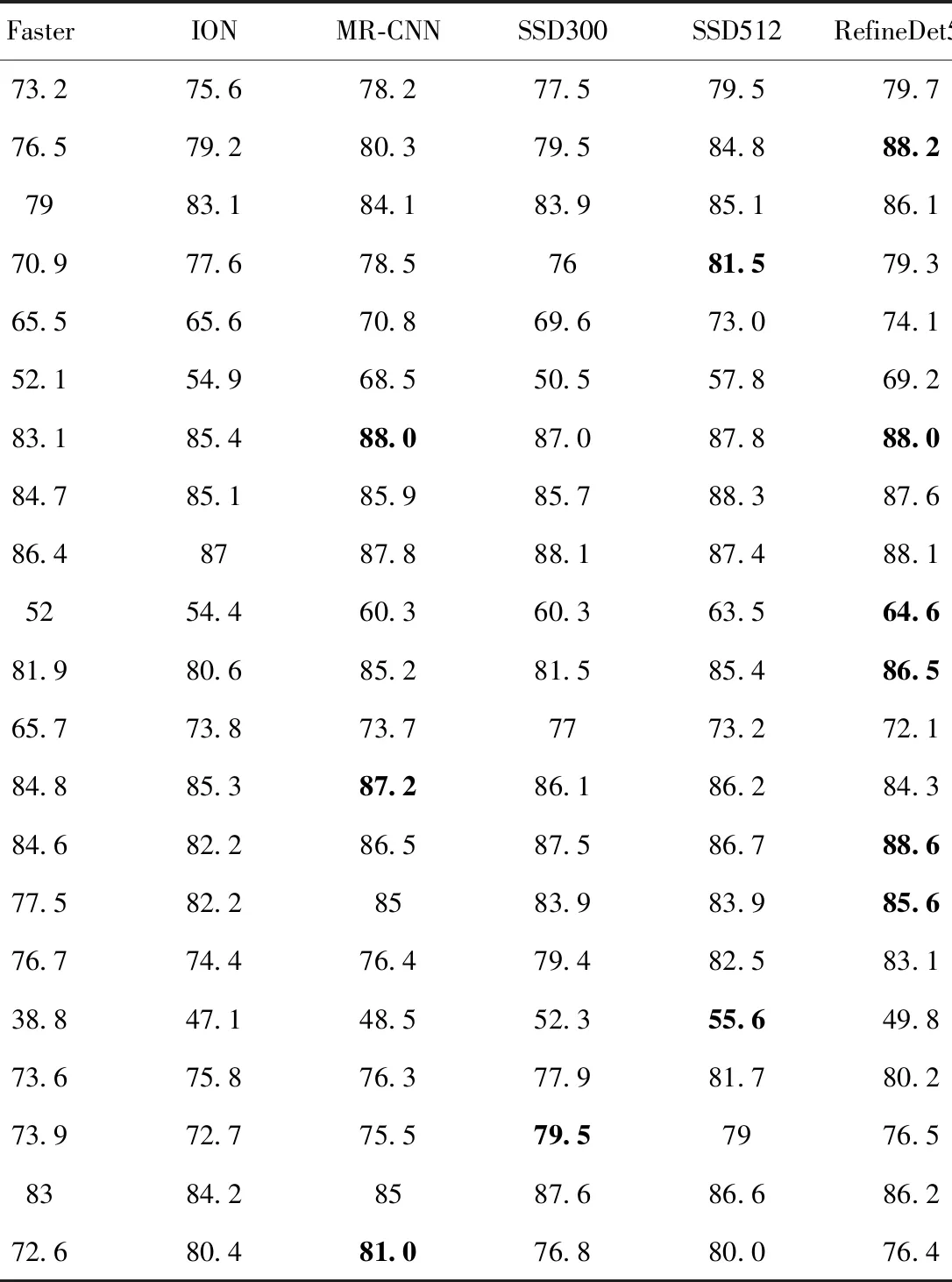
表1 PASCAL VOC數(shù)據(jù)集實(shí)驗(yàn)結(jié)果(粗體為最佳結(jié)果)Tab.1 Experimental results of PASCAL VOC data set (bold is the best result)
2.2 實(shí)驗(yàn)結(jié)果
表1為PASCAL VOC數(shù)據(jù)集中20類(lèi)物體的實(shí)驗(yàn)結(jié)果。本文所提出的BFFD算法在20類(lèi)中的自行車(chē)、船、瓶子、小汽車(chē)、貓、桌子、人、羊和火車(chē)等9類(lèi)物體取得了最好的圖像識(shí)別準(zhǔn)確率;其次是RefineDet512算法(輸入512×512的RefineDet算法),其在飛機(jī)、公交車(chē)、椅子、牛、馬和摩托車(chē)等6類(lèi)物體中取得最好的識(shí)別準(zhǔn)確率。再接著是SSD算法和MR-CNN算法。最后是Faster算法和ION算法。顯然,BFFD算法在大多數(shù)類(lèi)別的圖像識(shí)別中都取得了最好的精確率。BFFD算法在PASCAL VOC數(shù)據(jù)集上的平均精度均值是80.4%,是所有算法中最好的。RefineDet512、SSD512、SSD300、MR-CNN、ION和Faster的平均精度均值分別為79.7%、79.5%、77.5%、78.2%、75.6%和73.2%。顯然,BFFD算法的多尺度圖像識(shí)別平均精度均值較RefineDet512要高0.7%。
為了進(jìn)一步驗(yàn)證所提BFFD方法多尺度圖像識(shí)別的精確度,本部分還在MS COCO數(shù)據(jù)集上進(jìn)行了進(jìn)一步的驗(yàn)證。在實(shí)驗(yàn)中,OHEM++和Faster為雙步驟圖像識(shí)別方法,其他方法都為單步驟圖像識(shí)別方法。在圖像識(shí)別中,圖像越精細(xì),也即原始輸入圖像大小越大,圖像中信息相對(duì)較多,則圖像識(shí)別效果相對(duì)較好。在單步驟對(duì)照方法中,本文對(duì)最新的SSD和RefineDet,以及BFFD算法都設(shè)置圖像輸入大小為512×512,以開(kāi)展實(shí)驗(yàn)結(jié)果對(duì)比。
表2為MS COCO數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果。其中,F(xiàn)PS(frame per second,幀數(shù))為每秒檢測(cè)圖像的數(shù)量,其數(shù)值直接采用文[3]的實(shí)驗(yàn)結(jié)果。顯然,在相同輸入條件下,BFFD算法較SSD512算法和RefineDet算法都具有較低的FPS值。也即,BFFD算法的運(yùn)算效率要優(yōu)于SSD512和RefineDet算法。實(shí)驗(yàn)還驗(yàn)證了不同IoU(intersection-over-union,交并比)對(duì)圖像識(shí)別精度的影響。在實(shí)驗(yàn)中,IoU分別設(shè)置為0.5,0.75和0.95。不難看出,隨著IoU數(shù)值的增大,所有算法的平均精度值都降低。然而,在3種不同的IoU實(shí)驗(yàn)中,BFFD算法都取得了最好的多尺度圖像識(shí)別平均精度。由于RefineDet是圖像識(shí)別較好的算法;為此,本部分重點(diǎn)對(duì)比本文所提BFFD算法跟RefineDet算法。顯然,在IoU分別為0.5、0.75和0.95時(shí),BFFD算法的平均精度分別為58.4%、39.1%和33.8%,比RefineDet算法分別提高3.9%,3.6%和0.8%。最后,實(shí)驗(yàn)還驗(yàn)證了在IoU = 0.75時(shí),不同尺度物體的識(shí)別精度。從表2可知,BFFD算法對(duì)小尺度、中尺度和大尺度物體的識(shí)別精度分別為16.6%、37.8%和45.2%,其比RefineDet算法分別提高了0.4%、1.4%和0.8%。實(shí)驗(yàn)結(jié)果,本文所提BFFD算法能有效提升多尺度物體的識(shí)別精度。
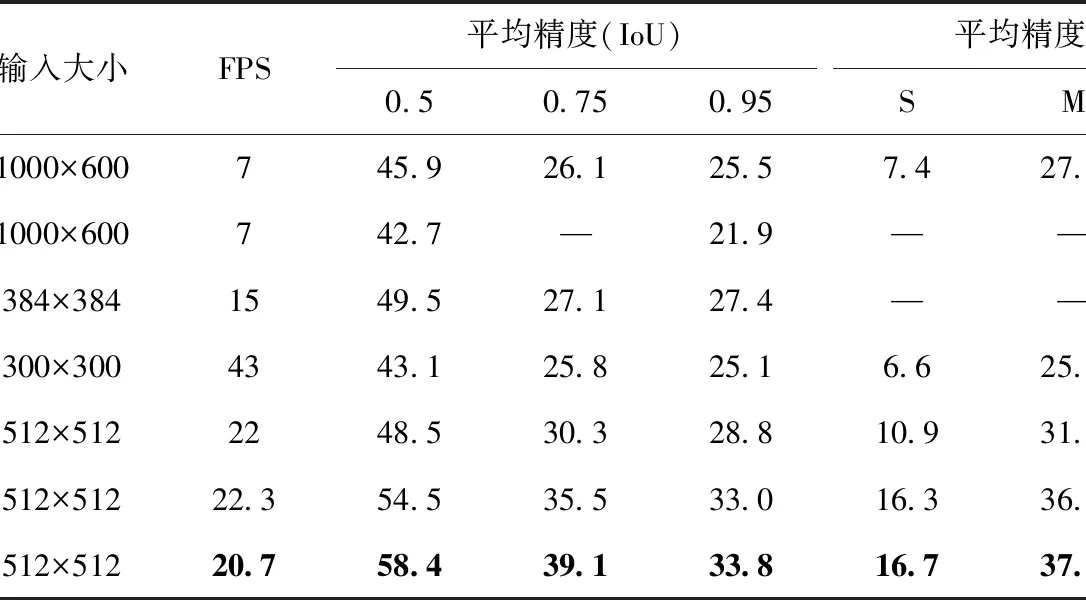
表2 MS COCO數(shù)據(jù)集實(shí)驗(yàn)結(jié)果(粗體為最佳結(jié)果)Tab.2 Experimental results of MS COCO data set (bold is the best result)
3 結(jié) 論
引入特征金字塔是解決多尺度物體識(shí)別的有效途徑之一。然而,現(xiàn)有基于特征金字塔的物體識(shí)別方法大多采用自上而下的特征語(yǔ)義信息融合方式,無(wú)法有效提升大尺度物體識(shí)別精確度。為此,本文提出一種基于特征金字塔語(yǔ)義信雙向融合方法BFF。而后,將BFF嵌入深度神經(jīng)網(wǎng)絡(luò),形成一種特征金字塔雙向語(yǔ)義信息互補(bǔ)的圖像識(shí)別方法BFFD。BFFD在保持小尺度物體識(shí)別精確度的前提下,提升大尺度物體識(shí)別的精確度,從而實(shí)現(xiàn)多尺度物體識(shí)別精確度。實(shí)驗(yàn)結(jié)果表明:本文所提方法可以在PASCAL VOC數(shù)據(jù)集上取得80.4%的平均準(zhǔn)確度均值,比現(xiàn)有方法提升了0.7%。本文所提方法在MS-COCO數(shù)據(jù)上,采用不同的交并比在不同尺度的物體識(shí)別上都比現(xiàn)有方法具有更高的平均準(zhǔn)確度。實(shí)驗(yàn)結(jié)果驗(yàn)證了本文所提方法能有效提升圖像多尺度物體識(shí)別的精確度。
引入圖像去噪[21]、去霧等[22]算法,從圖像源提升待識(shí)別圖像的質(zhì)量也是提升圖像識(shí)別的有效途徑。在未來(lái)研究中,將通過(guò)引入圖像去噪[21]和去霧等[22]方法以進(jìn)一步提升圖像物體識(shí)別的效率。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
