NRS-SVM兩階段遺傳算法的多晶硅鑄錠配料質量分析
2021-05-21 12:09:38徐靜林黃麗霞張雪英李鳳蓮杜海文于麗君
太原理工大學學報 2021年3期
關鍵詞:分類
徐靜林,黃麗霞,張雪英,李鳳蓮,杜海文,于麗君,馬 秀
(1.太原理工大學 信息與計算機學院,太原 030024;2.山西省中電科新能源技術有限公司,太原 030024)
隨著光伏行業的迅猛發展,多晶硅電池憑借其較高的性價比一直占據著光伏市場的主導地位[1]。鑄造多晶硅是多晶硅電池制作過程中的一個重要環節,提高多晶硅的鑄造質量是保證電池質量的關鍵。目前多晶硅鑄造生產工藝已經相對成熟,所以生產工藝對最終多晶硅生產質量的影響相對較小,而配料在高效多晶硅鑄錠生產過程中起著決定性的作用,對高效多晶硅鑄錠的電學性能有著至關重要的影響,同時有效合理的配料工藝對成本也有著關鍵性的影響。所以,對多晶硅鑄錠配料數據的分析有較大的工業價值。
20世紀80年代以前一般都是靠人工對多晶硅鑄錠質量進行分析,這種方法效率低且準確率不高。隨著大數據技術的發展,許多新的數據分析方法開始用于工業生產中。例如文獻[2]利用核主元分析(KPCA)提取特征向量,將提取后的主元作為SVM的輸入,對故障進行診斷和分類。文獻[3]提出一種DB小波與RBP神經網絡的方法對短期電力負荷預測,但訓練樣本過大時,訓練速度會很慢。文獻[4]提出將鄰域粗糙集與支持向量機結合,進行固結系數預測,減輕了SVM的訓練負擔,但由于實際數據中,數據變化較大,鄰域半徑取值及分類器參數基本是憑經驗和反復實驗來確定,所以如何準確快速得到鄰域半徑及SVM分類器中懲罰系數c與核函數參數g的取值,在工業生產分析的實用性方面有很大的研究意義。基于以上分析,本文提出一種鄰域粗糙集-支持向量機模型與遺傳算法相結合的兩階段遺傳算法(NRS-SVM-GA),該算法通過遺傳算法優化NRS-SVM參數,并將遺傳算法分兩個階段進行,根據每個階段的目的提出相應的適應度函數及終止條件。第一階段在代數觀點下的鄰域近似質量和約簡集合長度基礎上,提出了新的約簡性能評價函數,并將其作為遺傳算法第一階段的適應度函數,通過搜索鄰域半徑參數得到該適應度函數下最佳的約簡集合;其次,在SVM的分類精度及第一階段約簡結果基礎上提出第二階段適應度函數,通過調整懲罰系數c及核函數參數g訓練出準確率較高的分類模型。該方法不僅克服了以往根據經驗或實驗選擇參數的弊端,而且避免了通過分類器來評價約簡性能所帶來的時間消耗,且實現了NRS-SVM快速自動化特征提取及分類預測。
1 相關原理簡介
1.1 鄰域粗糙集理論
粗糙集作為一種屬性約簡方法,能夠有效地分析低維且不完備的工業生產數據。但Pawlak粗糙集定義在經典等價關系和等價類基礎之上[5],只適合處理名義型變量,對于實際生活中普遍存在的數值型變量卻不能直接處理。胡清華等[6]將鄰域概念引入到粗糙集中,克服了經典粗糙集不能直接處理數值型數據的缺陷,但鄰域半徑的取值一般采用經驗值或者通過反復實驗獲得,極大限制了工業應用的自動化程度,且會導致輸出結果不穩定。因此,本文對鄰域半徑參數進行優化,提高其在工業應用中自動化程度。鄰域粗糙集相關原理如下:
給定一個鄰域決策系統NDT(U,C∩D,V,f),其中U為對象的非空無限集合,稱為論域,C為條件屬性,D為決策屬性,V為各屬性值的集合,f是信息函數,表示樣本、屬性和屬性值之間的映射關系。
定義1[6]對于任意的xi∈U,B?C,xi在屬性子集B上的σ-鄰域定義為:
σB(xi)=|xjxi∈U,ΔB(xi,xj)≤σ| .
(1)
式中:σ≥0,ΔB為兩樣本點之間歐式距離。
由于在實際工業生產中,決策屬性大多都為數值型數據,在進行屬性約簡時仍需將其離散化處理,本文將鄰域粒度概念擴展到決策屬性中,重新定義了論域U對決策屬性D的劃分,這樣不需要再對數值型決策進行離散化處理,且相比離散化處理細化了決策對論域的劃分。
定義2 給定一個決策系統NDT(U,C∩D,V,f),xi在決策屬性D上的決策劃分情況為:
D(xi)=|xixi∈U,ΔD(xi,xj)≤σ| .
(2)
定義3 給定一個決策系統NDT(U,C∩D,V,f),B?C生成U上的鄰域關系NB,σB(xi)表示對象xi在屬性B下的鄰域,決策屬性集D關于條件屬性B的下近似和上近似分別為:
NBDi=|xiσB∈Di,xi∈U| .
(3)
(4)
那么數據的邊界域定義為:
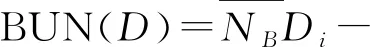
(5)
定義4[7]給定一個決策系統NDT(U,C∩D,V,f),對?B?C,決策屬性D關于條件屬性B的鄰域近似質量可以定義為:
(6)
式中:正域POSB(D)=NBD.
1.2 支持向量機理論
支持向量機作為一種有效的分類模型,可以在一定程度上檢驗鄰域粗糙集屬性約簡結果的可靠性,且常作為屬性約簡評價指標之一。其原理是先將所有的訓練向量映射到一高維空間中,然后在這個空間中構建一個最大間隔超平面。支持向量機的核函數主要分為4種:線性核、RBF(radial basis function,徑向基)核、多項式核和Sigmoid核。本文采用RBF核。
如果要構建一個SVM,就需要先選擇SVM的懲罰因子c及核函數參數g.懲罰因子c控制學習復雜度,理論上隨著c的增大復雜度逐漸增高,但當c大到一定程度,超過空間復雜度的最大值時,對支持向量機的性能就不會再產生影響。核函數參數g的改變實質上是支持向量機向高維度投影的特征空間的復雜度改變,當核參數增大時,投影空間復雜度降低,線性可分程度也降低;而當核參數趨于0時,特征空間的復雜度會趨于無窮,此時雖然將任意數據映射為線性可分,但會造成過擬合現象。因此需要針對數據集設置合理的懲罰因子c及核函數參數g,從而獲得較好的分類效果。但在實際工業數據分析中,對于參數c、g的尋優會耗費大量時間,影響分析效率。本文針對屬性約簡后的多晶硅配料數據,對SVM參數進行優化,減少其訓練時間。
1.3 NRS-SVM模型標準遺傳算法
NRS-SVM模型已經廣泛應用于數據的特征提取及分類預測[8],雖然目前針對SVM參數尋優問題已有相對成熟的尋優算法,但對于鄰域半徑參數往往使用經驗值或者多次試驗獲得,最終通過對比不同鄰域半徑取值下分類器的分類精度來得到相對較好的鄰域半徑取值,這樣會造成大量由分類器所帶來的時間消耗,同時也極大限制了工業應用中NRS-SVM的自動化程度。NRS-SVM模型標準遺傳算法通過分類器分類精度及約簡集合長度來綜合評價約簡性能,當搜索鄰域半徑取值時會產生多個約簡結果,需要對每個約簡結果都進行分類,產生巨大時間消耗。因此,本文提出NRS-SVM兩階段遺傳算法。
2 NRS-SVM兩階段遺傳算法
針對NRS-SVM模型參數問題,采用遺傳算法對其進行參數尋優。遺傳算法(genetic algorithm,GA)起源于對生物系統研究的計算機模擬研究,是模擬生物界遺傳形式和參考生物進化理論而形成的一種可以并行隨機搜索的優化方法,它把自然界生物自然選擇優秀個體的方法引入到優化參數問題形成的串聯編碼群體中,參照自然界適者生存的選擇辦法,按照所選擇的適應度函數對個體進行測試和選擇,通過選擇、交叉和變異等步驟對個體進行篩選,使適應度好的個體得以保留[9]。近年來,遺傳算法作為一種模擬生物進化和遺傳規律搜索尋優方法,具有通用性強、全局最優、搜索速度快等優點,目前已成為解決各種復雜問題的有力工具[10]。
本文提出基于NRS-SVM的兩階段遺傳算法(NRS-SVM-GA),即采用兩個階段標準的遺傳算法,每個階段的不同在于適應度函數和終止條件設置不同。第一階段的目的是尋找到較優的約簡集合,第二階段的目的是訓練出準確率較高的分類模型。這樣,第一階段通過搜索最佳鄰域半徑參數λ(本文采用標準差下的鄰域半徑δ=Dst/λ)來保證數據較高的鄰域近似質量和相對較少的配料特征個數,進而將第一階段約簡結果作為第二階段SVM的輸入。由于以往都是通過分類器下的分類精度來評價約簡性能,而本文第一階段屬性約簡的適應度函數沒有用SVM分類精度作為約簡性能評價指標,所以不用再對第一階段得出的每個約簡集合都進行SVM分類,極大減少了運算量;第二階段直接使用第一階段的約簡結果,通過搜索最佳懲罰因子c及核函數參數g來訓練出較高的分類模型。算法流程如圖1所示。算法中各參數設置如表1所示。
2.1 適度函數
2.1.1第一階段適應度函數
適應度函數為兩階段遺傳算法的核心部分,一個好的適應度函數既可以滿足所要達到的目的,同時也可以減少算法的復雜程度。本文所提算法NRS-SVM-GA中,第一階段的目的是通過尋找最佳鄰域半徑來準確地刻畫基本信息粒子,從而保證數據較高的鄰域近似質量且保留相對較小的約簡集合,由式(3)-式(6)可看出,較高的鄰域近似質量可以保證數據較高的正域,正域越大,邊界域越小,知識的不確定性越小,數據的分類性能就越好。根據以上目的,提出第一階段適應度函數:

圖1 算法流程圖Fig.1 Algorithm flow chart

表1 算法參數設置Table 1 Algorithm parameter setling
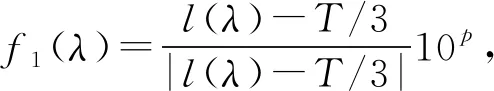
(7)
式中:l為約簡集合長度;T為所有條件屬性個數;γB(λ)為鄰域近似質量。為了防止在某些λ取值下約簡集合個數過少致使核屬性被約簡,導致數據的分類性能嚴重下降,所以,通過(l(λ)-T/3)來保證最終約簡集合長度不少于總長度的1/3,若小于1/3則適應度為負數,直接淘汰。這在一定程度上防止了核屬性被約簡的情況,且為了減少其對最終適應度大小的影響,將其比上本身的絕對值使其大小歸為±1;(1-l(λ)/T)來保證約簡集合長度越小越好的原則;μ為鄰域近似質量與約簡集合長度的可信度參數;同時為了使遺傳算法收斂更快,采用指數函數。
由式(7)可以看出可信度參數μ的取值決定了適應度函數對約簡集合長度或鄰域近似質量的側重度,所以可信度參數取值直接影響最終約簡結果。對于可信度參數μ,取[0,1]之間以0.1為步長的10組數字,采用多晶硅G6和G7產品配料數據,比較不同μ下的鄰域近似質量和約簡集合長度來衡量可信度取值。實驗結果如下圖所示:
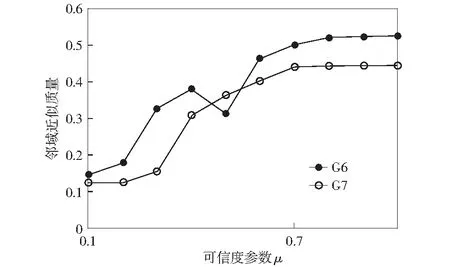
圖2 兩類多晶硅產品在不同μ下的鄰域近似質量比較Fig.2 Field approximation mass comparison of two polysilicon products under diflerent reliability parameters
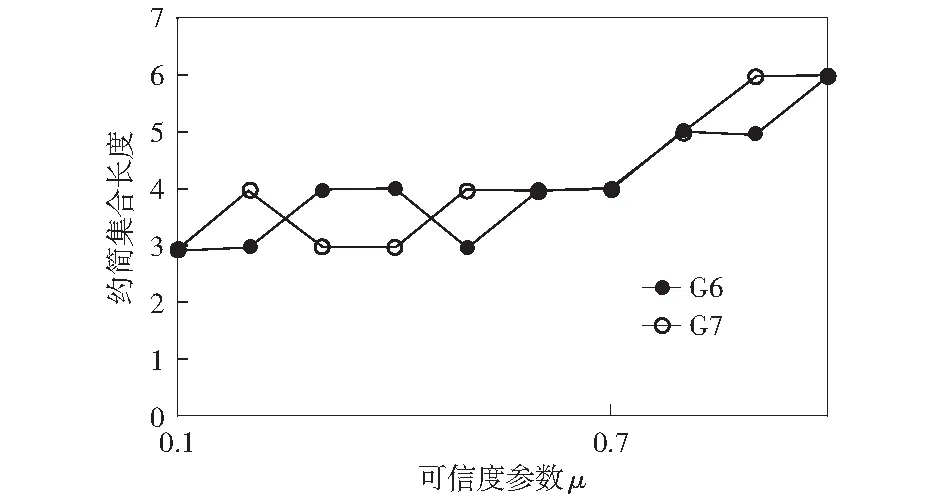
圖3 兩種多晶硅產品在不同μ下的約簡集合長度比較Fig.3 Comparison of approximately combined set lengths of two kinds of polysilicon products under different reliability parameters
由圖2和圖3可以看出當可信度為0.7時,G6和G7數據的鄰域近似質量達到相對較大值且趨于穩定,且都可以保持相對較小的約簡集合長度4.同時考慮實際需求,對于工業數據的屬性約簡,約簡結果的可靠性往往更加值得關注,所以本文的可信度取0.7.
2.1.2第二階段適應度函數
將第一階段輸出的約簡集合作為第二階段的輸入。第二階段的目的是通過尋找最佳的懲罰因子c及核函數參數g來訓練出準確率較高的分類模型。所以將第二階段的適應度函數設置為測試集的預測精度(accuracy),且為了綜合評價NRS-SVM-GA模型,將第一階段得到的約簡集合長度(l)的適應值也寫入適應度函數中,并設置其權重各占0.5,第二階段適應度函數為:
(8)
同時本文采取k-折交叉驗證(KCV),首先將原始數據隨機地分成k個互不相交的子集,每個子集的大小大致相等。用其中的一個子集作為測試集,其余子集的合集作為訓練集,共進行k次訓練和測試,每次選擇不同的測試集,這樣會得到k個模型,并用k個模型最終測試結果評價指標的平均數作為此KCV下的性能指標[11]。此外,在分類訓練時對特征類別做標簽化處理,按照工廠標準認為少子壽命值大于5.8 ms為合格類,小于5.8 ms為不合格類。
2.2 算法終止條件
由于算法兩個階段的目標不同,所以設置的終止條件也不同。
第一階段的目標是得到較短的約簡集合和較大的鄰域近似質量,所以終止條件設為:當鄰域近似質量大于某個峰值且約簡集合長度為當前種群中的最小值時算法終止,根據大量多晶硅實際數據實驗,這里將鄰域近似質量峰值設為0.8;但在傳代過程中可能出現無法滿足上述終止條件的情況,所以如果滿足連續傳代個體最佳適應度保持N次不變或達到最大傳代次數時算法也終止,考慮到算法的效率,將N設為5.
第二階段的目的是訓練出較好的分類模型,即較高的分類精度。所以直接將終止條件設為:當連續傳代個體最佳適應度N次不變或達到最大傳代次數時算法終止,同樣考慮算法效率將N設為5.
3 實驗分析
針對多晶硅鑄錠生產的配料數據集,分別從運行時間和最終適應度兩方面來對比標準遺傳算法與兩階段遺傳算法。
3.1 實驗數據
本實驗采用中電科2019年下半年多晶硅鑄錠生產配料數據,其中包含G6和G7兩種產品,每種產品包含8個配料類別,分別為免洗原生多晶塊料、非免洗原生多晶塊料、碎多晶鋪底、碎片、中料、循環料、提純錠芯(自產)、提純錠芯(外購),屬性值為配料質量,最終評價指標為少子壽命值,屬性值為其壽命值。其中G6產品有500個樣本,G7產品有520個樣本。G6與G7產品由于生產工藝及原料質量存在差異,導致少子壽命值評價標準不同,G6產品為少子壽命值大于5.8合格,G7產品為少子壽命值大于6.2合格。表2為G6產品的部分數據示例。
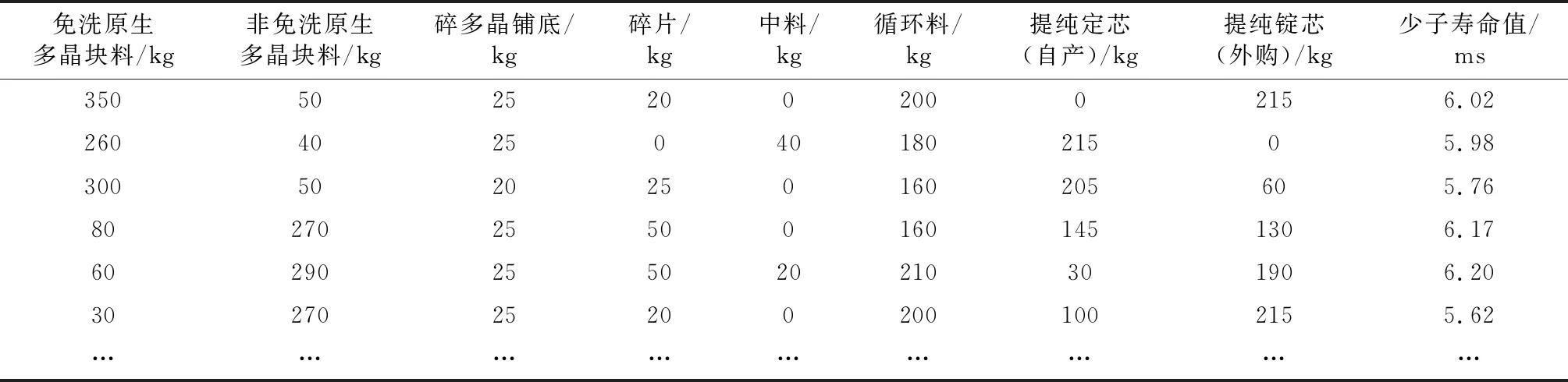
表2 G6多晶硅生產配料部分數據Table 2 Some date of polysilicon G6 production ingredients part of data
3.2 標準遺傳算法參數設置
為了確保實驗具有可比性,標準遺傳算法參數與表1設置相同,由于標準遺傳算法要同時滿足得到較短約簡集合和較高的分類精度,所以適應度函數設為兩階段遺傳算法的第二階段適應度函數:
(9)
終止條件與兩階段遺傳算法第二階段終止條件相同。
3.3 結果分析
由于多晶硅鑄錠生產的配料數據集中在G6和G7兩種產品上,因此本文分別使用標準遺傳算法和兩階段遺傳算法進行約簡和分類,每種算法都進行20次實驗,運行時間和適應度取其均值。兩種算法的運行時間如圖4所示,適應度如表3所示。
由圖4可以看出,兩階段遺傳算法在運行時間上遠少于標準遺傳算法,這是由于標準遺傳算法要同時進行約簡和分類兩項操作,每產生一個約簡集合都要進行一次分類訓練,通過分類的結果來評價約簡性能,這樣極大地增加了算法的運算量。假設約簡要進行n次循環,對每個約簡結果的分類訓練要進行m次循環,那么標準遺傳算法的時間復雜度為T(n)=n+mn=O(mn),而兩階段遺傳算法將約簡和分類操作單獨進行,第一階段屬性約簡的適應度函數不包含第二階段的分類結果,所以極大減少了運算量,時間復雜度為T(n)=n+m=O(n+m).
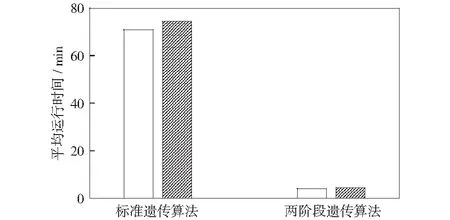
圖4 兩種算法運行時間對比Fig.4 Comparison of the running time of the two algorithms
由表3可以看出,標準遺傳算法的約簡結果會出現核屬性被約簡掉的情況,導致分類精度直線下降,但適應度仍然較高,如產品G6的約簡集合長度為2,但分類精度降低到73.22%.這是由于標準遺傳算法的適應度函數是為了得到較少的約簡集合個數和較高的分類精度,但忽略了某些鄰域半徑參數λ值下,為了達到約簡個數越小適應度越高的目的,會使核屬性也被約簡掉,導致數據的分類精度大幅度下降,但由于約簡集合個數較少,適應度仍然會保持較高的狀態。而兩階段遺傳算法在第一階段給出了在約簡個數不能少于總個數1/3的前提下,約簡個數越少越好的原則,在一定程度上防止了數據核屬性被約簡掉的情況,且保證了數據整體較高的鄰域近似質量,使邊界域變小,從而降低數據的不確定性,同時也保證了數據的可分性。

表3 標準遺傳算法與兩階段遺傳算法適應度對比Table 3 Comparison of fitness between standard genetic algrithm and two-stage genetic algrithm
對比表3中兩種算法可以看出,兩階段遺傳算法中G6配料數據集中有12次適應度基本保持在0.704 4左右,G7數據有15次適應度基本保持在0.702 1左右;而標準遺傳算法G6數據集中有17次出現核數性被約簡掉的情況,G7數據集有18次核數性被約簡掉的情況。由此可見,兩階段遺傳算法的穩定性遠高于標準遺傳算法。
取兩階段遺傳算法中適應度最高的G6和G7運行結果作為最終的多晶硅鑄錠配料約簡和分類結果,圖5以柱狀圖形式表示出G6產品與G7產品的配料對少子壽命值影響所占權重。
由圖5可見,G6產品中提純錠芯(外購)對少子壽命值影響最大,而G7產品中提純錠芯(自產)對少子壽命值影響最大;碎片、中料和循環料對G6和G7產品的少子壽命值均有一定影響且影響程度基本相同;免洗原生料、非免洗原生料和碎多晶對G6和G7產品的少子壽命值均無影響,該結果與實際專家給定值相符。
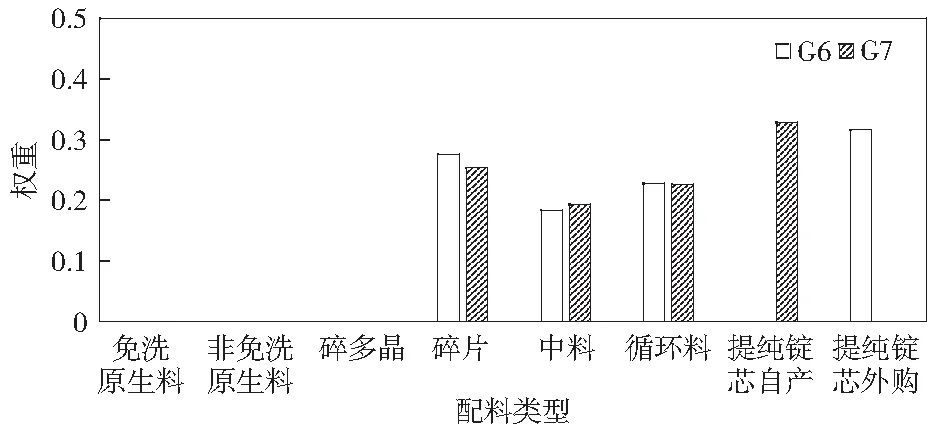
圖5 G6和G7產品配料對少子壽命值影響所占權重Fig.5 The weight of G6 and G7 product ingredients on minority carrier lifetime
對于G6產品的屬性約簡結果為碎片、中料、循環料和提純錠芯外購,并對其進行SVM預測,預測準確率可達到90.88%;G7產品的屬性約簡結果為碎片、中料、循環料、提純錠芯(自產),SVM的預測準確率可達90.43%,對實際多晶硅生產有一定的指導意義。
4 結論
傳統的鄰域粗糙集鄰域半徑取值采用經驗值或者多次實驗的方法來獲得,往往不能快速有效地獲取鄰域半徑,大大限制了鄰域粗糙集在實際生產中的應用。本文采用遺傳算法優化NRS-SVM模型參數,并將遺傳算法分為兩階段進行,第一階段提出通過代數觀下的鄰域近似質量及約簡集合長度來綜合評價約簡性能,避免了以往通過分類器來評價約簡性能所帶來的時間消耗;將第一階段約簡結果直接作為第二階段SVM分類器的輸入,將其與標準遺傳算法對比,實驗結果表明,該算法在多晶硅鑄錠配料數據集中平均運行時間在5~7 min,相比標準遺傳算法平均減少了70 min,極大減少了工業數據分析中的時間消耗,且輸出結果穩定,實現了NRS-SVM自動化特征提取及分類預測,為工業生產提供重要參考價值。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
