基于開行方案的高速鐵路客流分配方法研究
2021-05-13 02:59:22李文卿倪少權楊渝華
鐵道學報 2021年3期
關鍵詞:分配
李文卿,倪少權,2,3,楊渝華,文 迪
(1.西南交通大學 交通運輸與物流學院,四川 成都 610031;2.西南交通大學 全國鐵路列車運行圖編制研發培訓中心,四川 成都 610031;3.西南交通大學 綜合交通運輸智能化國家地方聯合工程實驗室,四川 成都 610031)
基于開行方案的客流分配方法用以在給定開行方案下估計客流在各條列車服務路徑上的分配情況,進而評估票價收入和所有旅客的廣義出行費用,是開行方案評估反饋循環的重要組成部分。
國內外學者對客流分配方法進行了大量研究。最早的客流分配方法是在制定開行方案之前,將旅客按照一定的規則預分配至物理路徑上[1-2],此類方法忽略了旅客的自由選擇和列車服務對旅客的影響。隨著研究者逐漸重視旅客的效用,以及旅客出行選擇行為研究的深入,基于列車開行方案的客流分配方法研究受到了更多關注。此類研究多采用基于圖論的尋路算法和配流算法結合的求解框架,為描述旅客基于列車服務的旅行過程,需建立一個由節點和加權弧組成的服務網絡,節點表示旅客在旅行過程中的不同狀態,弧段表示旅客的不同旅行過程,弧的權重表示相應旅行過程的廣義費用,通過尋路算法求解各點對之間旅客廣義出行費用最小的路徑,最后通過配流算法按一定規則將客流量加載到路徑上。研究考慮了哪些旅行過程決定了服務網絡的結構,進而決定了節點和弧段的數量,最終影響尋路算法的求解效率。文獻[3]從適用問題、節點和弧段數量等角度對不同結構的服務網絡進行了分析,文獻[4-8]建立了不同結構的服務網絡進行客流分配。上述研究假設旅客能完全知悉網絡中各條路徑的阻抗且一定選擇廣義費用最小的路徑,屬于單路徑確定性配流。文獻[9-10]認為旅客對路徑阻抗的認知可能有偏差且個人選擇行為帶有一定的隨機性,因此基于廣義費用按概率將客流分配至多條備選路徑上更加合理。根據是否基于用戶均衡定理,配流算法可以分為用戶均衡配流和非用戶均衡配流兩個范疇。基于用戶均衡定理的研究認為,列車上旅客數增加會使列車的擁擠度即路徑的阻抗增加,因此高速鐵路(以下簡稱高鐵)客流分配和公路交通流分配具有相似性,應滿足用戶均衡定理;文獻[11-12]認為高速列車不存在擁擠,并且高鐵的旅客出行選擇過程并不是實時占用列車能力,而是在購票的一瞬間占用列車能力,因此不滿足用戶均衡定理的適用條件。是否引入用戶均衡定理對配流結果有較大影響,因此有待于進一步研究。
在上述研究的基礎上,本文以提高客流分配方法的準確性和求解效率為目的,從尋路算法和配流算法兩個維度展開研究。在高鐵系統中,路徑搜索建立在開行方案即列車服務的基礎上,因此本文提出一種直接基于開行方案搜索的兩階段尋路算法,與既有研究相比,避免了建立復雜的服務網絡與冗余的節點搜索,算法的求解效率得到了顯著提升。由于列車定員與列車運行圖的限制,高鐵系統中乘車路徑的容量和阻抗通常是確定的,因此用戶均衡定理不適用于高鐵客流分配,本文對此進行了分析與證明。最后使用成渝地區高鐵網絡客流分配案例驗證了方法的有效性。
1 問題分析
客流分配方法的本質是模擬旅客為了實現位移選擇乘車方案的過程,要求準確地描述旅客出行選擇行為。
現實中,旅客的出行選擇分為兩個階段,第一階段為根據公布的列車運營計劃尋找所有可行的乘車方案。如果某一列車的停站包括旅客出行起訖點,則該列車為一個可行的直達乘車方案,如果不存在直達乘車方案,則需要尋找由至少2列車組成的換乘方案。由于換乘不僅會給旅客帶來額外的廣義費用,還會增加旅途的不確定性,旅客會優先考慮中轉換乘次數最少的乘車方案;第二階段為根據各個備選乘車方案的廣義費用確定最佳乘車方案,最后通過購票預訂相關的列車服務。上述過程和現有的客流分配方法存在一定的差異,主要體現在以下2個方面。
1.1 與現有尋路算法的差異
現實中旅客的“尋路”是先根據列車運營計劃尋找可行的乘車方案,最終選擇廣義費用最小的方案。而現有的基于圖論的尋路算法是在搜索過程中考慮最小化廣義費用,即依據旅行過程的廣義費用尋找最佳方案。為了全面地考慮旅行過程,后者需要根據開行方案設置大量的虛擬列車節點,在每次搜索過程中獲取單個源點到所有其他節點的最短路,但最終僅有OD節點之間的最短路被利用了。換言之,大量的節點搜索是冗余的,因為本質上只有關于OD節點間可行的乘車方案的節點是有意義的,而開行方案本身已充分包含尋找可行的乘車方案的所有信息。由于開行方案問題不涉及時間窗,根據區間運行時間標準,車站乘降、停站、換乘時間標準和票價標準等已知信息即可確定廣義費用最小的乘車方案。
1.2 與現有配流算法的差異
現有高鐵客流分配方法的核心思想大多為用戶均衡理論,該理論的適用環境須滿足以下假設:①出行者可以最大限度獲知起訖點間各條路徑的阻抗信息;②出行者可以在任意情況下自由選擇路徑;③大多數出行者是理性的,一般會選擇阻抗最低的路徑;④在一定范圍內,路徑的阻抗會受到其使用者人數的影響,二者一般呈正比例關系。
與完全滿足上述條件的公路系統不同,盡管鐵路系統滿足條件①和條件③,但顯然并不滿足條件②和條件④。條件②意味著即使某條路徑發生擁堵,但只要該條路徑的阻抗低于其他路徑,出行者依然可以選擇。但在鐵路系統中,出行者選擇路徑體現為通過購票預訂列車席位,會受到列車定員和售票策略的制約。為了保證高鐵良好的服務質量,一般不允許超員或僅發售少量無座票,因此當某條路徑涉及的相關列車的席位售罄時,便不再允許出行者進入;針對條件④,路徑阻抗通常表示為使用該路徑需支出的廣義費用,主要由時間和票價組成,在大多數公共交通系統中,運輸工具內部的擁擠度也是考慮因素之一。但在鐵路系統中,路徑由一列或多列高速列車構成,其時間由列車運行圖決定,票價由票價率和運輸距離決定,二者基本固定不變,且由于不允許超員,車廂內的擁擠度亦不需考慮,因此,各條路徑的廣義費用不會受到使用人數變化的影響。
綜上所述,由于高鐵系統不完全滿足用戶均衡定理的適用條件,所以高鐵客流分配不會達到用戶均衡狀態,第2節對此推論進行數學證明。
2 關于用戶均衡定理不適用于高鐵客流分配的證明
鐵路系統路徑示意見圖1:o、d為一對起訖點;l1、l2為o、d之間的兩條路徑;t1、t2為阻抗函數,A1、A2分別為l1和l2中席位數最少列車的定員;q1、q2為各條路徑負載客流量,q1、q2未知;q為總客流需求量,q已知且q1+q2=q。
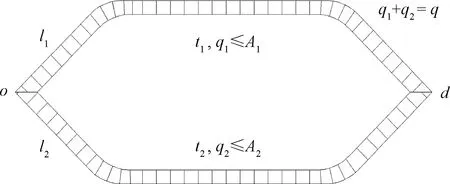
圖1 鐵路系統路徑示意圖
由用戶均衡定理可知,在滿足所有假設的情況下,當所有出行者均選定自己的路徑不做改變時,所有被使用路徑的阻抗相同且為最小值,任意出行者改變其選擇都會使自身的廣義出行費用增加,此時系統達到用戶均衡狀態。路徑流量q1、q2與下列優化問題的最優解等價
(1)
s.t.
(2)
0≤qi≤Ai?i∈{1,2}
(3)
由于高鐵系統的路徑阻抗不受出行者選擇的影響,阻抗函數t1和t2為常量,由a1和a2表示。
式(1)可以改寫為
(4)
將式(2)等價變換為q2=q-q1代入式(4)中,得到新的目標函數
min[(a1-a2)q1+a2q]
(5)
式中:a1、a2、q為已知量且均為正數,若要得到最優解,分為以下3種情況討論:
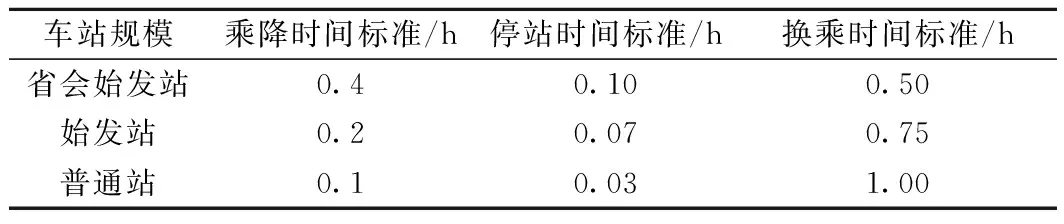
(1)當a1>a2時,a1-a2>0,只有當q1取最小值時得到最優解,最優解為q2=min{A2,q},q1=max{0,q-q2}。所有旅客會優先選擇阻抗較低的路徑l2直至滿載,未能成功預訂l2列車席位的剩余客流只能選擇路徑l1。在該狀態下,所有旅客均無法通過改變其出行選擇降低自身的廣義出行費用,但t1和t2顯然不相等,且t1>t2恒成立,不滿足用戶均衡狀態。
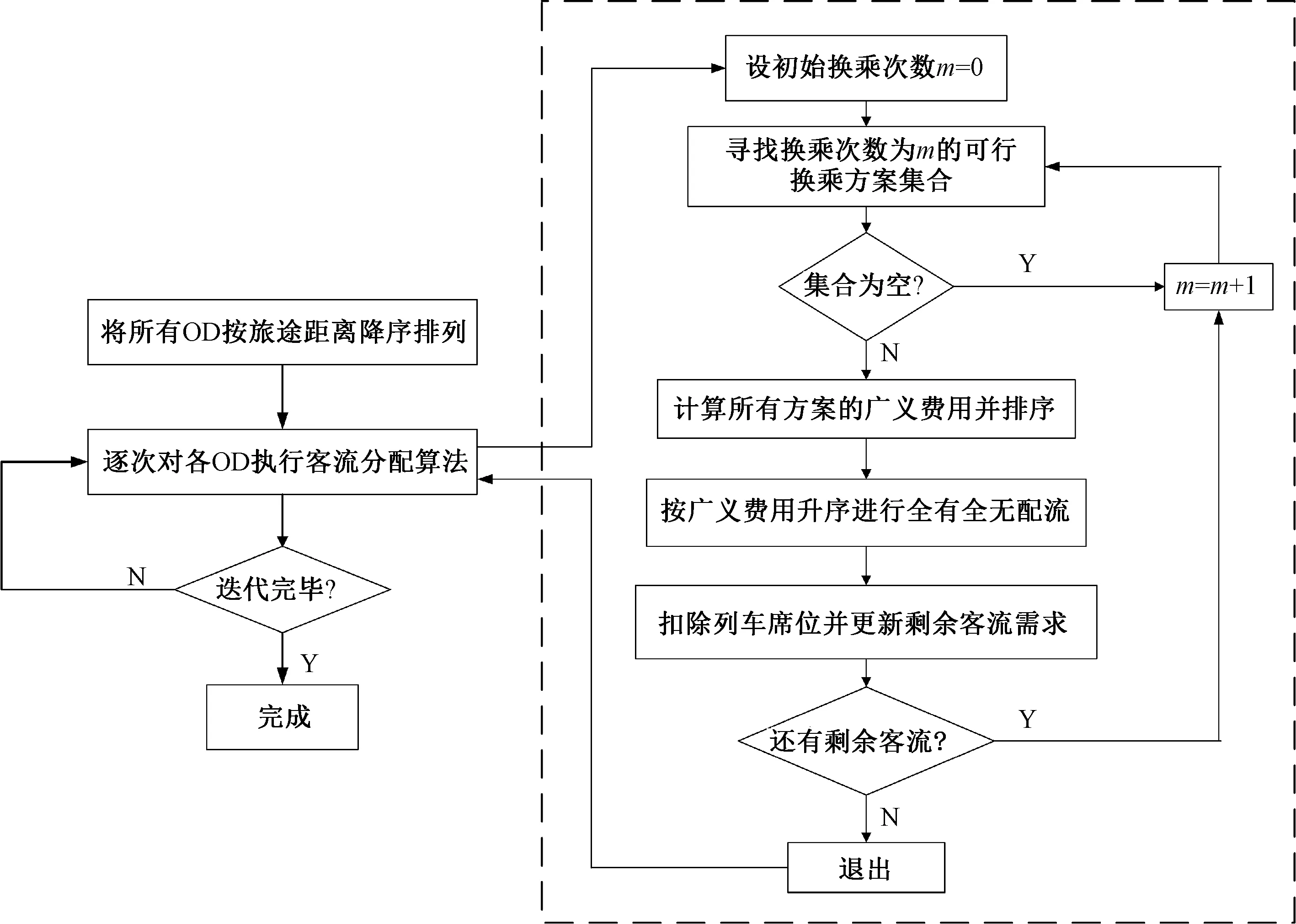
(2)當a1 (3)當a1=a2時,式(5)等價為常數函數,無論q1取任何值,目標函數均不發生變化,任何滿足約束條件式(2)和式(3)的解均可作為最優解。在該狀態下,盡管t1=t2恒成立,但任意旅客改變其出行路徑均不會使自身的廣義出行費用發生變化,不滿足用戶均衡狀態。 綜上所述,用戶均衡定理并不適用于高鐵客流分配。 算法分為基于開行方案搜索的兩階段k短路算法和全有全無配流算法兩部分。 旅客選擇高鐵出行的必要條件為起訖點間有列車服務,分為直達與換乘兩種情況,直達要求至少有一列車的停站序列同時包含起訖點,換乘要求至少有兩列車的停站序列中分別包含起點和訖點且相關列車可以組成完整的出行鏈。將開行方案中的列車集合分為4個子集:a. 同時包含起訖點的列車;b. 包含起點但不包含訖點的列車;c. 不包含起點但包含訖點的列車;d. 不包含起訖點的列車,子集a中的列車可以滿足旅客直達的需要,若不存在直達列車,以預期換乘次數遞增的規則搜索子集b、 c、 d以尋找可以組成完整出行鏈的列車集合。搜索出行鏈的思路為:若預期換乘一次,則在子集b和子集c中各選出一列列車,選取規則為兩列車的停站序列的交集非空,代表存在換乘站可使旅客完成換乘出行;若預期換乘兩次,則在子集b、c、d中各選取一列列車,選取規則為子集b、c中兩列車的停站序列交集為空,子集b、d中兩列車和子集c、d中兩列車的停站序列交集非空,代表旅客可以從子集b中的列車換乘到子集d中的列車,再換乘到子集c中的列車完成出行;若預期換乘次數大于兩次,則需要再從子集d中選擇一列車,選取規則與前一情境類似,關鍵是組成起訖點間的完整出行鏈。由于換乘會給旅客帶來較大不便,一般旅客會偏好換乘次數少的路徑。因此在配流過程中,按換乘次數遞增的規則,逐步搜索可行的路徑集合,根據各時間標準、票價率和站間距等已知信息計算各條路徑的廣義出行費用。隨后對可行路徑集中的所有路徑按廣義出行費用進行排序,利用全有全無法將客流按廣義費用從低到高的順序逐次加載到相應的路徑上。 當客流量較大時,需要考慮長途與短途、直達與換乘的旅客出行選擇沖突。根據鐵路售票策略,本文采用先長途后短途、先直達后換乘的規則。具體思路為:按旅途距離從高到低的順序,對所有OD對按旅客預期換乘次數遞增的順序優先分配長途和直達旅客的列車席位,再分配短途和換乘旅客的列車席位,每次分配后需要扣除已加載客流列車的可供分配席位,直至配流完畢。完整算法流程見圖2。 圖2 算法流程圖 表1 符號定義 o,d∈Ht (6) 若t滿足 (7) 若t滿足 (8) 若t滿足 (9) (10) (11) 由于高鐵成網后直達率較高且旅客一般不考慮換乘次數較高的路徑,為了簡化表述,在此不考慮m>2的情況。 m={0,1,2}時的o,d之間的備選乘車方案搜索過程見圖3。 圖3 備選乘車方案搜索過程 (12) 式中:δ和η分別為時間因素和費用因素的權重,δ,μ≥0且δ+μ=1。 (13) (14) 將所有備選乘車方案按Co,d的升序排列,即可快速枚舉出o,d之間k取任意值的k短路。 最后,在滿足列車容量約束的條件下將客流依次加載到最優乘車方案中的相關列車上,直至o,d間的總客流加載完畢或席位耗盡。 算法步驟如下: Step1將所有OD按旅途距離的降序進行排列,設OD總數為N,序號為n,令n=0。 (15) 式中:α,β,γ分別為所有起訖點中可不換乘到達,需換乘1次到達和需換乘2次到達的比例,α+β+γ=1且α,β,γ∈[0,1]。 不同算法時間復雜度的對比結果見表2。 表2 不同算法時間復雜度的對比結果 圖4 不同算法的時間復雜度變化對比圖 圖5 不同參數的算法1時間復雜度變化對比圖 采用2018年4月10日起執行的成渝地區部分高鐵網絡及列車開行方案進行驗算,見圖6。包含4種不同速度等級的線路和46個車站,其中包括4個省會始發站、20個非省會始發站和24個普通站,日開行超過250對不同等級的高速列車,為1 035個OD對提供優質的列車服務。經測算,在既有物理網絡和開行方案條件下,約72%OD對可以直達,約28%的OD對可經1次換乘到達(α≈0.72,β≈0.28,γ=0)。 圖6 成渝地區部分高鐵網絡拓撲圖 按全國平均收入水平設置旅客平均單位時間價值為30元/h。票價按區間距離乘以票價率計算。δ和η分別設為0.6、0.4。G、D字頭的高速列車票價率分別設為0.45、0.4元/km。區間運行時間標準為區間距離和列車運營速度之比。車站乘降、停站和換乘時間標準按不同的車站規模確定,見表3。所有算法使用Matlab R2015a優化器進行測試,運行環境為Intel core i7-7700HQ四核處理器、8 GB內存的計算機。 表3 車站時間標準參數設置 分別使用算法1、算法2和算法3求解所有OD對的最短路或k短路(k=3),結果見表4。 表4 尋路算法運算時間對比 算法2和算法3的運算時間分為2部分:構建服務網絡時間和尋路時間。構建服務網絡需要遍歷1次開行方案,當所有OD對均可直達時,算法1同樣只需遍歷1次開行方案,因此算法1的運算時間與算法2、3的構圖時間相近。由于需要搜索大量節點,算法2的運算時間是算法1的3倍以上。由于算法3需要重復進行k次搜索,所以運算時間遠長于算法1和算法2。 按包含車站規模和區間里程對所有OD對進行降序排序,按順序基于算法1求得各OD對的k短路及其廣義出行費用,使用全有全無配流法將客流需求量一次性分配到對應路徑上。運算時間約4.5 s,客流分配統計結果見表5。 表5 客流分配結果統計 客流分配方法作為鐵路運輸計劃評估反饋循環中的重要組成部分,在開行方案優化過程中需要多次調用,其運算效率和合理性對開行方案優化的速度和質量有重要影響。基于高鐵客流分配的特點,本文從尋路算法和配流算法兩個維度對高鐵客流分配方法進行了研究。 同基于圖論的尋路算法相比,本文提出的算法會產生2種時間結余:①無需構建服務網絡所節約的時間;②基于開行方案針對OD進行精確搜索而無需搜索冗余節點所節約的時間。此外,當高鐵網絡的連通性提升時,算法的運算時間會進一步降低。 由于高鐵不存在擁擠現象,將適用于公路交通流分配的用戶均衡定理直接引入高鐵客流分配是不合理的。本文對用戶均衡定理不適用于高鐵客流分配進行了證明。高鐵客流分配實際上是旅客購票的過程,因此全有全無配流更符合實際,且由于避免了為實現均衡而反復迭代,顯著提高了算法的運算效率。 通過考慮每列車的時間窗或在售票周期內根據售票策略動態改變列車停站序列,本文提出的算法可以拓展到基于列車運行圖的客流分配問題或考慮售票策略的客流分配問題,能否在上述問題中取得較好結果有待進一步研究。3 基于開行方案搜索的客流分配算法
3.1 算法思路
3.2 符號定義

3.3 算法設計
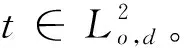
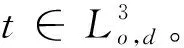
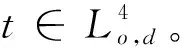
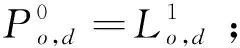
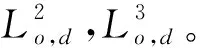
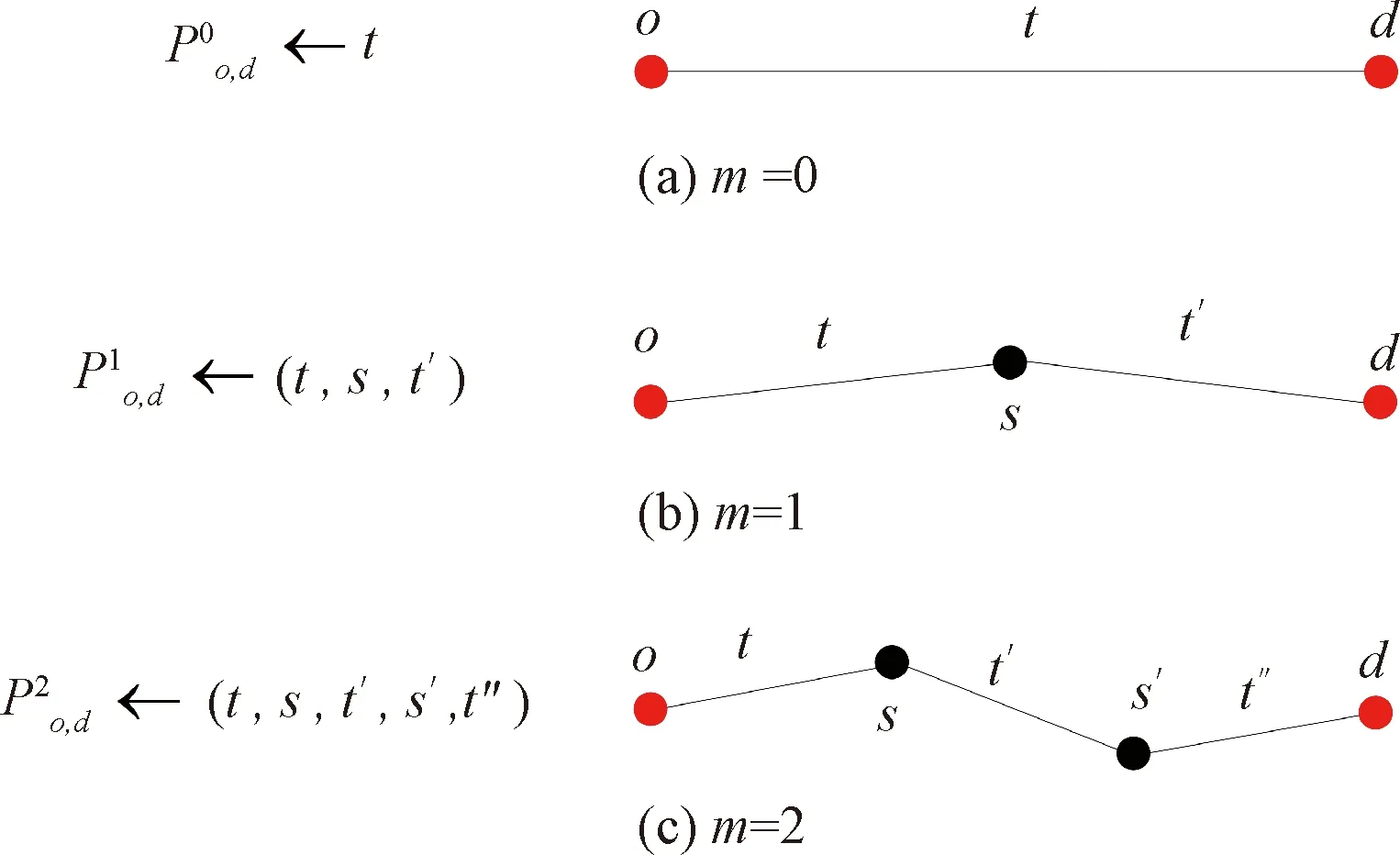
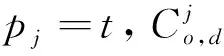
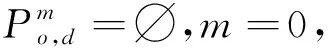
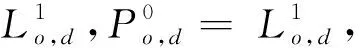
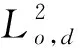
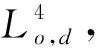
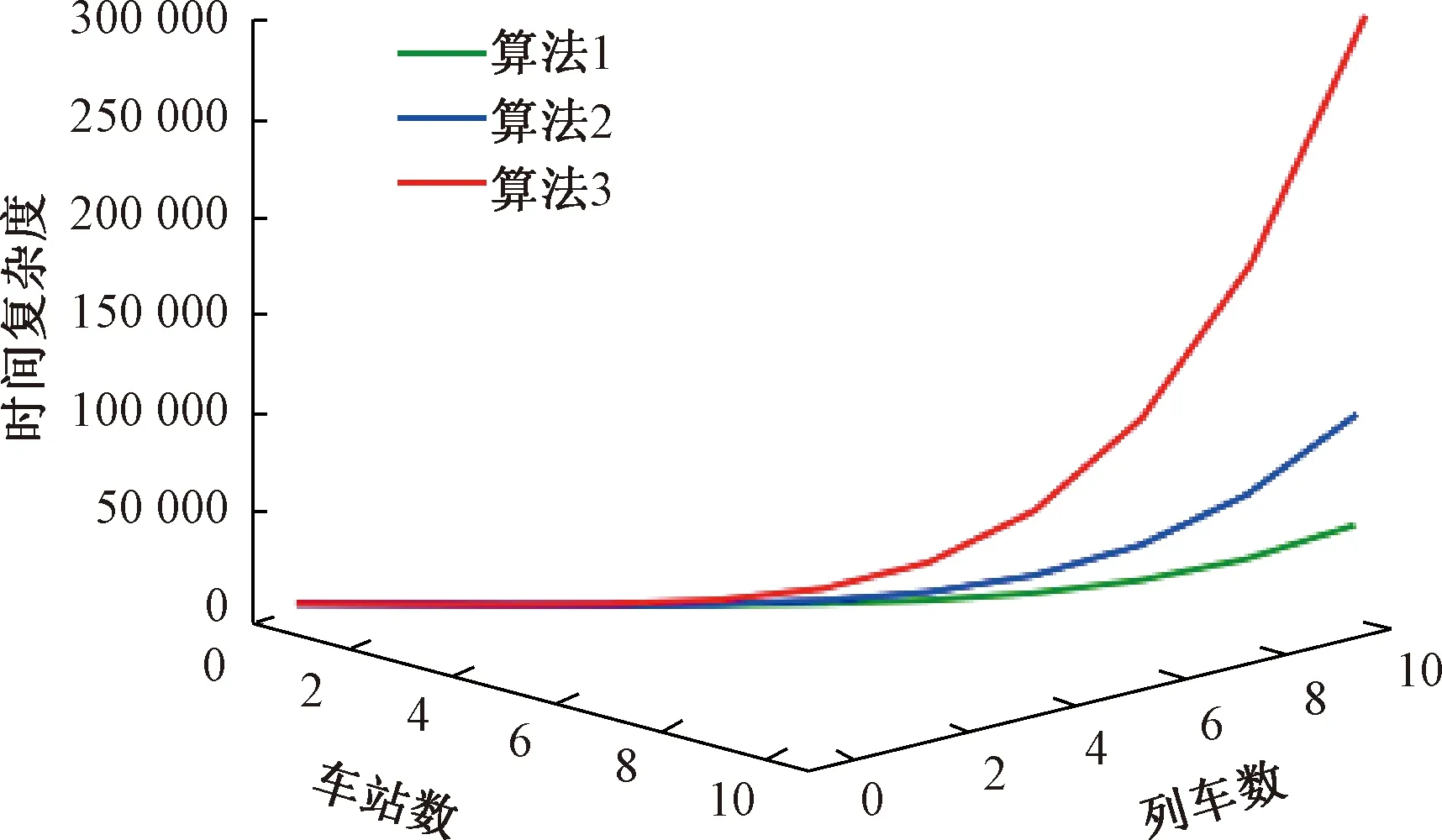
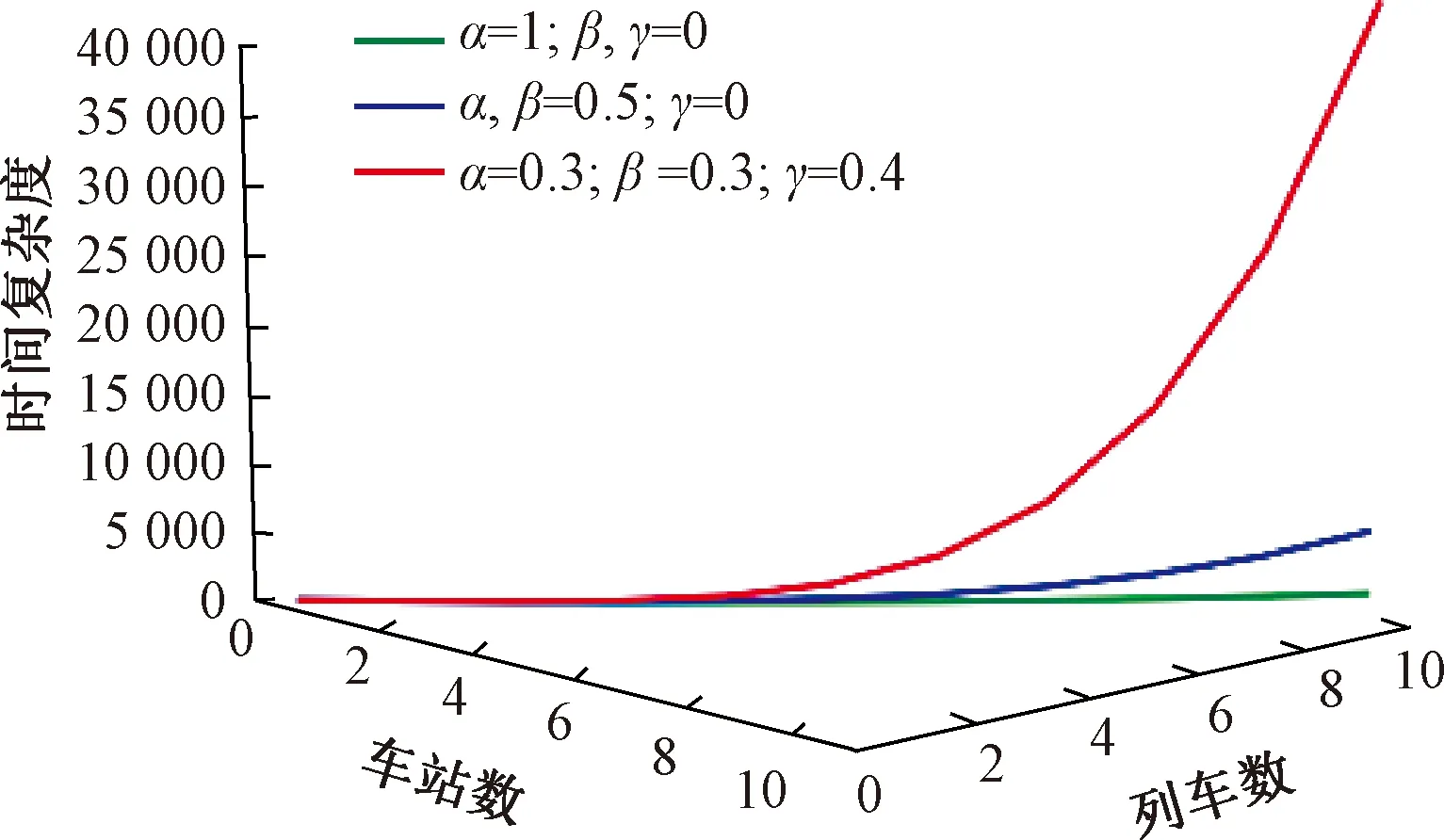
3.4 算法時間復雜度分析與比較
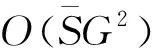

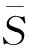
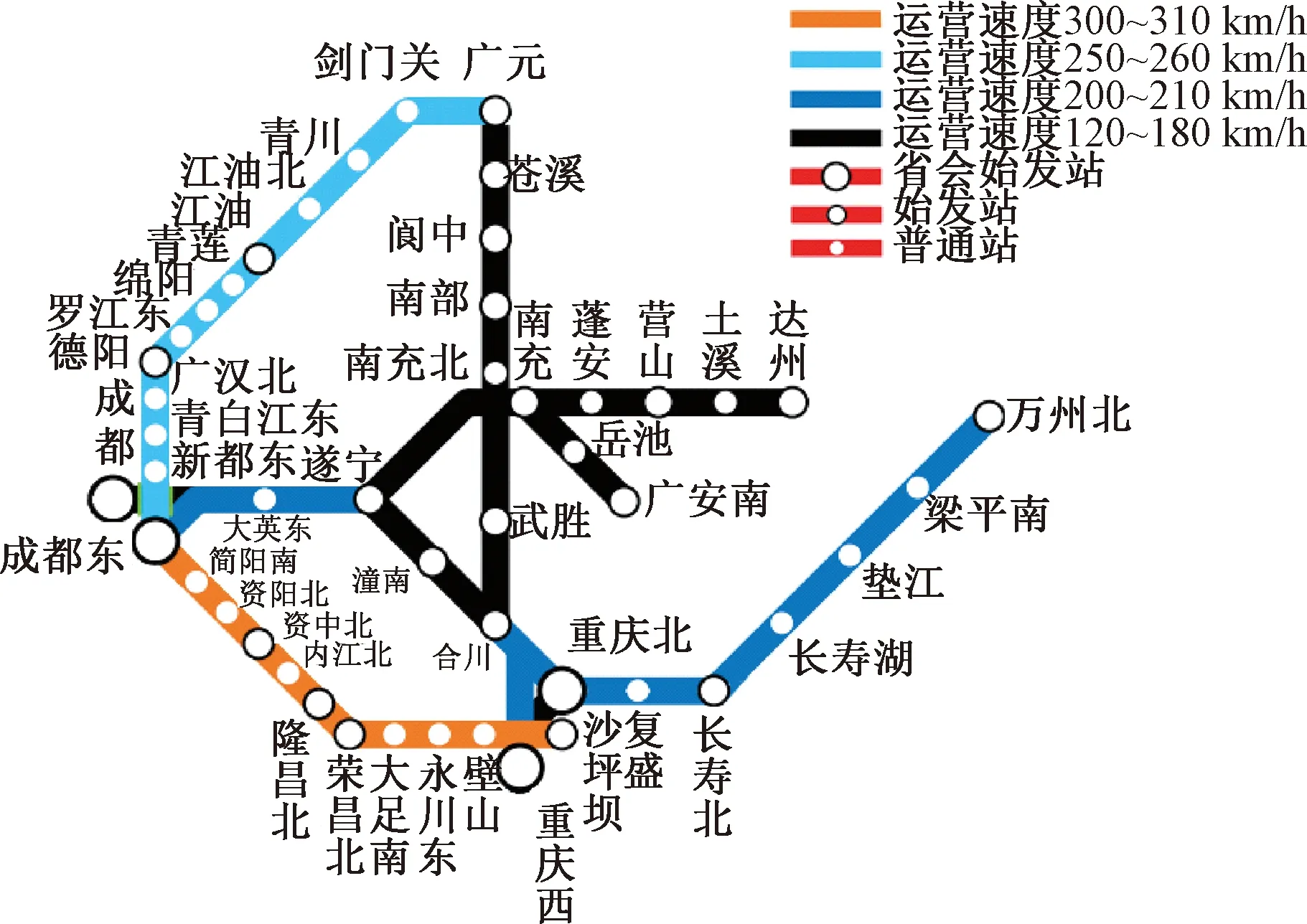
4 算例驗證
4.1 參數設置
4.2 算法測試

5 結論
猜你喜歡
天水行政學院學報(2022年4期)2022-11-18 09:02:36
艦船科學技術(2022年13期)2022-08-11 09:30:02
鐵道通信信號(2020年9期)2020-02-06 09:15:22
漢語世界(The World of Chinese)(2019年3期)2019-07-01 02:37:48
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
中學生數理化·中考版(2018年10期)2018-12-07 00:44:52
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
中央社會主義學院學報(2017年1期)2017-04-16 05:34:07
中國衛生(2014年12期)2014-11-12 13:12:40
