深度學習模型融合正則化方法在高維數據特征篩選中的應用研究*
2021-03-16 09:54:18栗思思盧宇紅宋佳麗
中國衛生統計 2021年1期
王 萌 王 策 栗思思 盧宇紅 宋佳麗 李 康 侯 艷△
【提 要】 目的 探索基于深度學習模型聯合正則化方法在小樣本高維數據特征篩選中的優勢。方法 通過模擬實驗和實際數據分析比較深度學習模型單獨及聯合正則化方法在小樣本高維特征篩選準確性方面的差異;采用測試集中C指數作為兩種模型泛化能力評價指標。結果 在小樣本研究中單純的深度學習模型在變量之間存在復雜相關性時會表現過擬合,而深度學習模型聯合正則化的方法比單獨的深度學習模型在測試集中體現出防止過擬合的作用,具有更好的泛化能力。通過比較不同正則化的方法,發現深度學習聯合組 lasso相比于lasso在測試集中表現出更好的泛化能力。結論 深度學習模型聯合正則化的方法在小樣本高維數據特征篩選中可以防止過擬合,保證外部測試具有較好的預測效果。
模型介紹
深度學習模型融合正則化方法是指在常規深度學習的輸入層與第一隱藏層之間加入正則化方法,剔除對結局變量作用較小的特征組,從而進行特征篩選,以保證使用較少且重要的特征來訓練深度學習模型,避免出現過擬合現象[4]。深度學習與正則化融合方法的示意圖如圖1所示。由于高維組學數據具有特征個數較多、樣本量少、數據結構較為復雜等特點,傳統的深度學習模型學習數據的特征時常常嘗試兼顧所有的數據點,很容易出現過擬合現象。考慮在深度學習模型學習特征的信息前首先利用正則化方法對高維組學數據篩選出對結局變量影響較大的特征,再作為輸入變量放入深度學習結構中,可能會具有更為有效的防止過擬合,同時提高模型學習效率等優點。
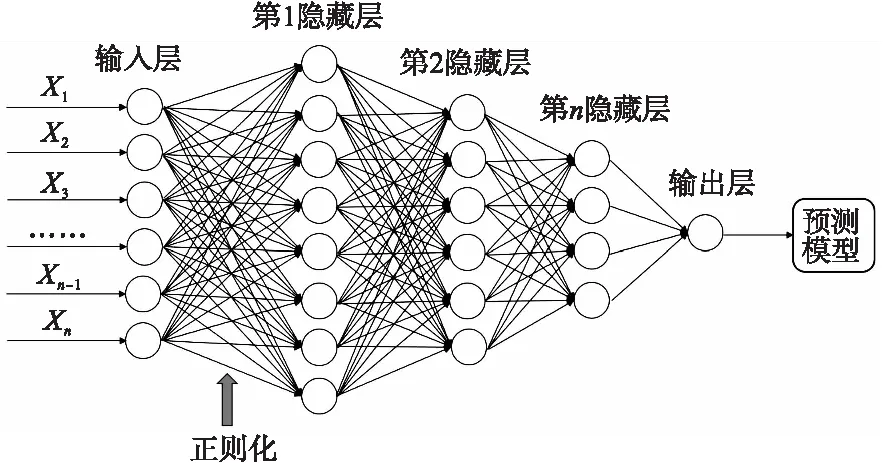
圖1 深度學習與正則化融合方法的示意圖
1963年Tikhonov提出正則化不但具有降維的作用[5],同時可以有效防止模型過擬合[6]。正則化主要思想是在估計參數時,引導損失函數的最小值朝著約束方向迭代。正則化的方法有很多,例如lasso、自適應lasso、彈性網等,近年來由于組lasso(group lasso)能夠實現生物學有對結局指標類別的篩選,即篩選出對結局變量影響較大的特征組,進而在此類特征組中進一步篩選特征,此種思想在實際應用中較為常用[7]。以下為組lasso的參數估計表達式:
(1)
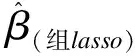
深度學習模型輸出層的特征是綜合全部特征變量的信息篩選得到的一個或多個特征,將其與各類模型相結合進行有效地預測,便于評估篩選變量結果準確性的指標。本文通過模擬實驗和實例數據來評價深度學習聯合正則化是否可以篩選出有效特征,提高模型的泛化能力。
模擬實驗
1.模擬數據的產生
(1)特征數與樣本含量的設定
在實際的組學數據中常常具有成千上萬個基因,增加了數據處理與分析的困難性,為了使模擬數據與TCGA中真實的數據結構相似且便于計算,我們在模擬實驗中設置特征的個數p=800,樣本量n=500,此時符合實際組學數據中基因的數量遠遠多于患者數量的特點。
梅黎明指出,“鄉村振興戰略的內涵十分豐富,將‘四化’同步發展提升為‘農業農村優先發展’,將‘社會主義新農村建設’提升為‘鄉村振興戰略’,將‘農業現代化’提升為‘農業農村現代化’,將‘統籌城鄉’提升為‘城鄉融合’。”
(2)特征組的設定
考慮到組學數據中特征間具有相關性,在分析數據時應將具有相關性的特征分為一組,在模擬實驗中設每個組內有4個特征,即將8000個特征平均分為2000個組,同時假定5個組即20個特征對生存有影響。
(3)生存時間及生存結局的設定
本文以Cox比例風險模型作為深度學習模型的預測模型探索方法的有效性,這里模擬500名患者的生存時間和生存結局。每個患者潛在生存時間可表示為:
(2)
βX={β1X1,β2X2,…,βg-1Xg-1,βgXg}
共有g個組,在第j個特征組中:
βjxj={βj1xj1,βj2xj2,βj3xj3,βj4xj4}
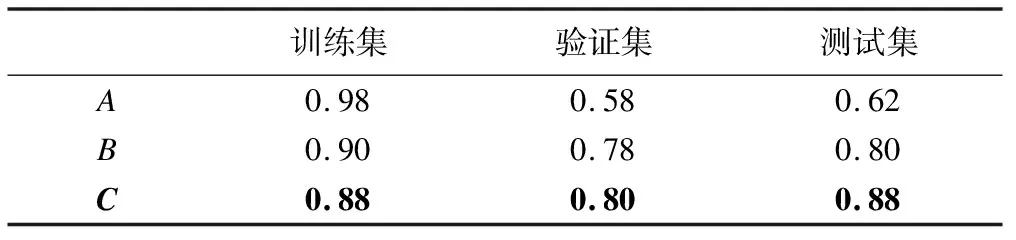
1≤j≤g,βj1xj1,βj2xj2,βj3xj3,βj4xj4為第j組內4個特征及其系數。設T1為服從參數為λ指數分布的刪失時間,若T1≥T,則生存結局為死亡;若T1 2.評價方法及指標 隨機抽取數據集的60%、20%和20%分別作為訓練集、測試集和驗證集,訓練次數為5000次。首先在訓練集中訓練深度學習模型,然后在驗證集中采用梯度下降法不斷對模型的超參數進行調整,尋求最佳模型,最后在測試集中評估其泛化能力。選擇測試集中C指數客觀地評估深度學習模型單獨及聯合正則化方法后的泛化能力。 3.模擬實驗的結果 使用模擬數據集分別訓練聯合組lasso和lasso的深度學習模型與單純的深度學習模型,每經過一次訓練后記錄訓練集、驗證集和測試集中的C指數,隨著訓練次數的增加,相應的C指數發生改變如圖2所示。 圖2反應了不同模型的訓練過程中,訓練集、驗證集和測試集中C指數的變化情況。訓練未加入正則化的深度學習模型時(圖A所示),驗證集和測試集C指數無明顯波動,由表1可知當不同數據集的C指數保持不變時,訓練集的C指數較驗證集和測試集中C指數0.62高的多,由此可見,未加入正則化深度學習的模型存在過擬合的風險,可能不具有較好的泛化能力。加入lasso(圖B所示)和組lasso(圖C所示)的深度學習模型在訓練過程中驗證集和測試集的C指數均有顯著增大的趨勢,且訓練分別至約為2000次和3000次,驗證集和測試集的C指數趨向穩定。圖B和圖C中測試集C指數達到穩定時分別為0.80和0.88。深度學習模型中加入正則化,通過在訓練集中不斷訓練以及在驗證集中對模型超參數的不斷調整獲得的深度學習模型具有很好的泛化能力,在一定程度上可以有效防止訓練深度學習模型時出現過擬合,且組lasso防止模型過擬合的效果優于lasso。 圖2 不同模型訓練集、驗證集和測試集中C指數隨訓練次數增加的變化情況 表1 相同模型不同情況下三個數據集中穩定的C指數 1.數據的來源及整理 從TCGA癌癥基因庫中下載共計630名卵巢癌患者的mRNA、蛋白質組學以及臨床信息,將模擬實驗中所闡述的方法及評價指標應用于上述實例數據。在上述數據中選擇原發卵巢癌患者同時剔除缺失生存結局、生存時間的患者,最終保留196名包含有組學數據和臨床信息的原發卵巢癌患者;剔除大于等于70%患者中缺失的特征,若小于70%的患者缺失某個特征值,對其缺失值采取中位數填補[9]。對填補缺失值后的組學數據進行Z標準化。在實例數據中,共有18717個特征,mRNA和蛋白組學中受同一基因調控的特征分為一個特征組。 2.實例分析結果 如圖3所示,隨著訓練次數不斷增加,同時模型在不斷的優化,此時融入組lasso模型測試集的C指數明顯增加,最高可達到0.67,且明顯高于常規深度學習模型測試集的C指數。對兩種模型測試集C指數的中位數進行Wilcoxon秩和檢驗,檢驗得到的P值小于0.0001,二者中位數的差值具有統計學意義,即融入組 lasso模型的測試集C指數中位數高于常規深度學習模型的測試集C指數的中位數。由此可見在模型中加入組lasso可以提高模型的C指數,且融入組lasso模型相比于常規深度學習模型具有更好的泛化能力,過擬合風險相對更低。 圖3 未加入正則化與融入組 lasso兩種模型測試集C指數隨訓練次數的變化 實驗結果顯示,使用常規深度學習模型進行預測時模型的C指數中位數僅為0.57,且模型驗證集的損失函數并沒有減小,此時模型存在過擬合。實際中癌癥高維組學數據的樣本量較少且與結局變量無關的特征較多是導致深度模型出現過擬合的主要原因。在訓練常規的深度學習模型時需要大量的樣本,但是在實際癌癥組學數據的研究中,樣本量較少限制了模型的學習能力,與此同時數據中又存在大量與結局變量無關的特征,因此模型不能充分且有效地學習從而導致模型的預測性能降低。此時我們需要正則化方法對癌癥高維組學數據進行降維,為訓練模型選擇與結局變量高度相關的特征或者特征組(癌癥高維組學數據中具有分組信息),在樣本量較少的情況下提高模型的學習效率和預測的準確性,降低模型過擬合的風險。 實際癌癥高維組學數據中,大部分特征都不是相互獨立的,常規的深度學習模型并不能對彼此之間具有相關性的輸入特征進行分組,所以加入組lasso的深度學習模型更適合處理實際的癌癥高維組學數據。眾所周知,實際癌癥組學數據中特征個數以及它們之間的相關性使數據結構較為復雜,在模擬實驗中是將所有特征均勻分組,即每特征組中特征個數相等,而在卵巢癌患者的組學數據中某些基因可能同時調控多個組學的不同特征,亦可能僅調控一個組學特征,因此并不能保證每個特征分組內的特征個數相等,在一定程度上也增加了數據結構的復雜性。但模型中融入正則化方法可以使模型在小樣本的數據中具有較強的學習能力,防止模型過擬合,減少無用功,節約運算時間。 雖然本研究通過在深度學習模型中加入正則化方法使得在實際組學數據中訓練模型較少的出現過擬合,但是如果將同一通路中組學特征分為一組,需要考慮同一組學特征出現在不同的通路中,換言之,同一特征同時出現在不同的特征組中時,本文所述的lasso、組lasso不再適用,它們能夠改善過擬合的問題,但不能徹底解決,在未來的研究中我們嘗試將重疊lasso應用于深度學習模型中,改善用組間具有重疊特征的組學數據訓練深度學習模型時出現的過擬合問題。隨著高維組學數據研究不斷發展,正則化方法在進行高維特征篩選方面具有較好的應用前景。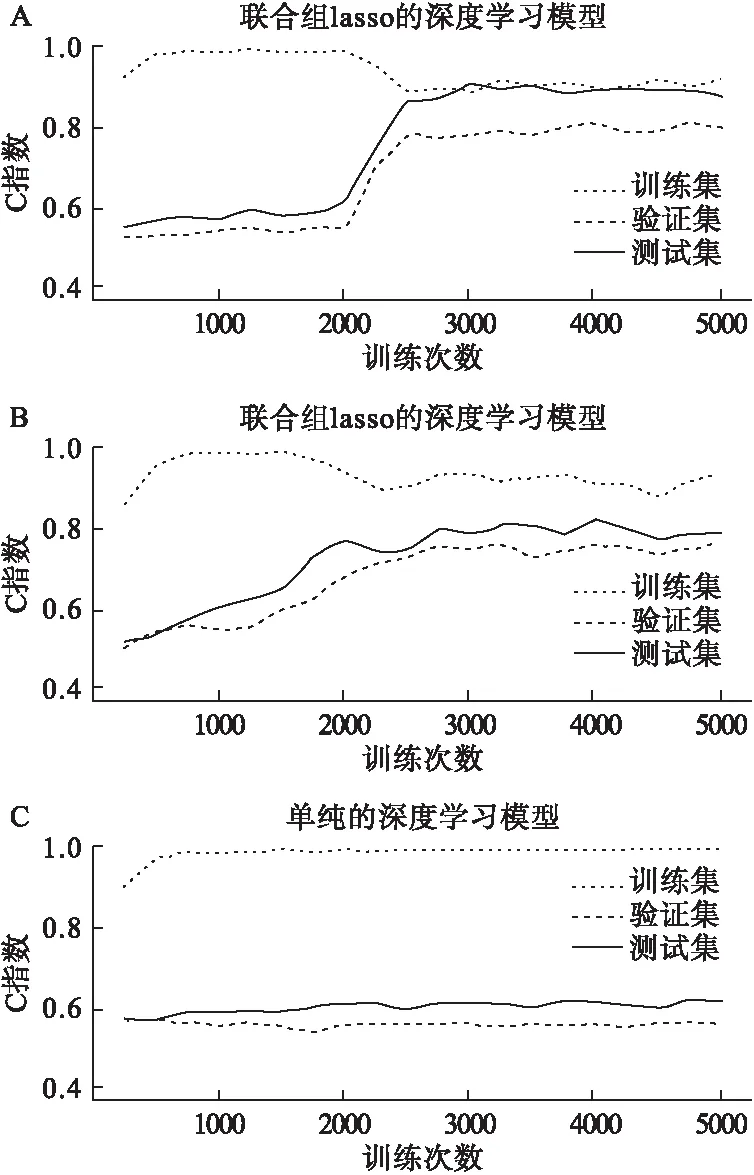
實例分析

討 論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
