SAS宏程序%HPGLIMMIX在大樣本數據廣義線性混合模型參數估計中的應用*
2021-03-16 10:19:24西安交通大學醫學部公共衛生學院流行病與衛生統計學系710061
中國衛生統計 2021年1期
西安交通大學醫學部公共衛生學院流行病與衛生統計學系(710061)
吳晨璐# 米白冰# 陳方堯 裴磊磊 史青云 趙亞玲△ 顏 虹△
【提 要】 目的 SAS軟件中目前實現廣義線性混合模型的過程步主要包括PROC GLIMMIX和PROC NLMIXED,兩種方法在實際應用中各有側重。本文介紹一個可以提高廣義線性混合模型運行效率的SAS宏程序%HPGLIMMIX的使用方法及其結果解讀。方法 通過實例數據,介紹%HPGLIMMIX分析正態分布和二項分布數據的過程,并展示采用%HPGLIMMIX分析大樣本數據的性能優勢。結果 對于小樣本正態分布和二項分布數據,采用%HPGLIMMIX和GLIMMIX、NLMIXED分析的用法基本一致。對于大樣本數據,%HPGLIMMIX可進行模型擬合并可有效節省時間及計算資源。結論 %HPGLIMMIX可有效提升大樣本數據的廣義線性混合模型擬合的效率。NLMIXED過程可以快速準確地進行參數估計。
隊列和臨床試驗等醫學研究中經常遇到重復測量的縱向數據。此類數據不滿足觀測時點間的獨立性假設,故不宜采用傳統的線性模型(linear models,LM),而應采用納入隨機效應項的混合模型(mixed model,MM)進行分析[1]。混合模型適用于結局為連續變量、分類變量或等級變量的數據[2]。隨著數據來源及收集技術的不斷發展,大樣本隊列、多中心臨床研究日益增多。這些研究常收集十幾萬例研究對象的長期、多次觀測值,產生高維復雜縱向數據。廣義線性混合模型(generalized linear mixed model,GLMM)廣泛應用于這類數據的分析處理,但其參數估計可能會因為計算內存不夠而無法輸出結果[3],導致其應用受限。針對上述情況,本文介紹可進行高效廣義線性混合模型擬合估計的SAS宏程序“%HPGLIMMIX”[3],展示其在大樣本數據參數估計上的優勢,并結合實際數據分析案例探討其具體使用方法,供廣大科研工作者進行大樣本數據的GLMM擬合及參數估計時參考使用。
廣義線性混合模型簡介
GLMM是廣義線性模型和線性混合模型的結合,由于其可應用于指數分布家族的任意一種分布類型,且引入了隨機效應項來解釋數據間的相關性、過度離散、異質性等問題[4],故可將連續變量(正態)或離散變量(二分類或多分類資料)作為反應變量,使其近20年來在生物醫學領域特別是縱向數據分析中廣受歡迎[3]。
GLMM在模型中引入隨機效應項ui,一般表達式為[5]:
設計矩陣由固定效應X與隨機效應Z兩部分組成,隨機效應項ui可以解釋由于不可測因子引起的類間異質性和同一類內觀測到的相關。
在隨機效應存在的情況下,廣義線性混合模型默認通過偽似然法(pseudo-likelihood)來估計參數,也可以選擇最大似然法(maximum likelihood)來進行參數估計。在SAS統計軟件包中,GLMM可通過PROC GLMMIX、PROC NLMIXED及PROC GENMOD等過程步實現,以PROC GLMMIX最為常用。
SAS宏程序%HPGLIMMIX及其參數介紹
PROC GLIMMIX過程可處理多數情況下的GLMM擬合,但當涉及到大樣本數據時,特別是隨機效應項水平較多時,該程序擬合常難以收斂。對于大樣本高維縱向數據,若結局變量為滿足正態分布的連續型變量時,可采用自SAS 9.2開始引入的PROC HPMIXED過程步構建線性混合模型;但對結局為分類和等級變量的大樣本縱向數據的GLMM建模,SAS統計軟件包至今尚未提供相應的分析模塊。2014年,Xie L和Madden L[3]編寫了“高性能廣義線性混合模型宏(%HPGLIMMIX)”來解決大樣本數據GLMM建模的問題。和PROC GLIMMIX過程步類似,%HPGLIMMIX宏也使用限制性殘差偽似然法(restricted pseudo-likelihood,REPL)擬合模型,但為適應數據量大的特征,%HPGLIMMIX宏參考了HPMIXED的過程[6],應用了稀疏矩陣技術來解決混合效應,使其適用于高性能計算(high performance),改良了計算過程,提高了計算效率,適用于觀測值較多的大樣本數據的GLMM擬合。
調用%HPGLIMMIX宏語句的主要框架代碼如下[3]:
%Hpglimmix(DATA=〈數據集名稱〉
STMTS=%Str(
CLASS〈分類變量〉;
MODEL〈響應變量〉=〈解釋變量1 解釋變量2…〉/SOLUTION;
RANDOM〈隨機效應〉/SUBJECT=〈分區組變量〉;
ESTIMATE/LSMEANS固定效應/〈需輸出的統計量〉…;),
ERROR=〈分布類型〉,LINK=〈鏈接函數〉,
TECH=〈參數估計優化方法〉,
OPTIONS=〈空間分離的選項關鍵詞〉
)RUN;
在調用宏程序的過程中,各參數意義及其使用如下:
STMTS:用%Str來指定分析步驟,定義方法與PROC GILMMIX類似,但殘差分布類型和鏈接函數不在MODEL處定義,另由專門參數ERROR和LINK定義。
ERROR:定義殘差分布類型,具體選擇見表1。當定義ERROR=User時,需要同時定義ERRVAR(方差函數)和ERRDEV(偏差函數);默認的分布類型為二項分布。
LINK:定義鏈接函數,每種分布類型對應默認的鏈接函數見表1。

表1 GLMM中常用分布及其鏈接函數[3,7-8]
TECH:參數估計優化方法,默認為Newton-Raphson Ridge法(NRRIDG),其他方法見表2。
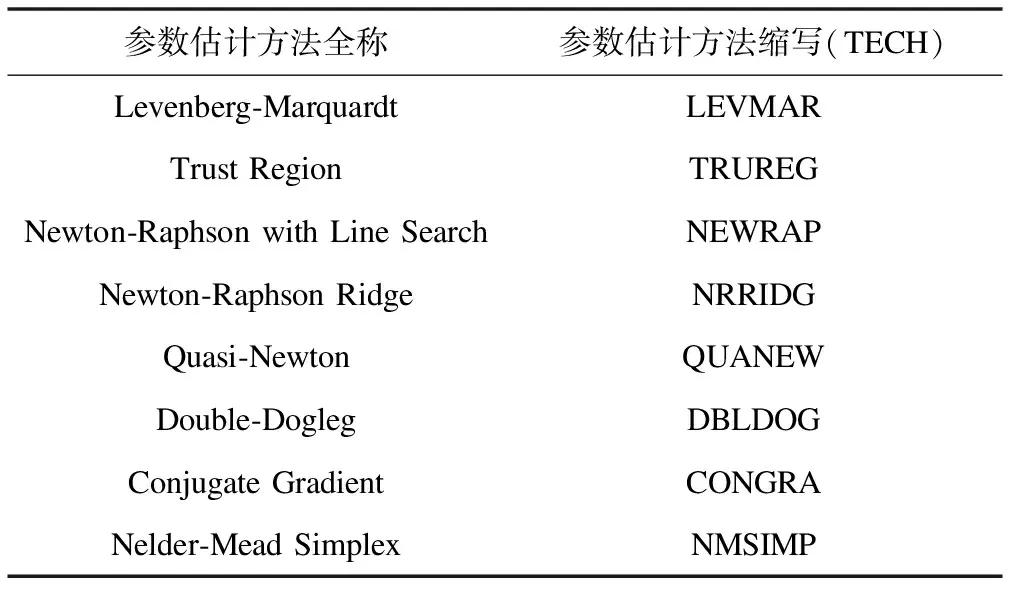
表2 GLMM中常用的參數估計方法[3]
OPTIONS:定義輸出選項;PROCOPT用來指定HPMIXED步驟的選項;MAXIT用來定義最大迭代次數,默認值為20;OFFSET用來定義位移變量(offset variable,默認無該變量),僅在采用泊松分布的鏈接函數時使用。
SAS宏程序%HPGLIMMIX宏應用舉例
以下應用實例分別展示:①該宏程序在分析結果上與GLIMMIX及NLMIXED過程的一致性(例1和例2);②在大樣本數據參數估計上的性能優勢(例3)。
1.SAS宏程序%HPGLIMMIX基本用法
基于兒童生長曲線研究數據[9],比較幾種方法的分析結果。該數據系27名兒童(11女,16男)在8、10、12、14歲的生長發育測量數據,假設反應變量y(兒童垂體中央到翼突上頜裂的距離,單位為mm)為正態分布,自變量child為兒童序號、gender為性別(其中1代表男性,0代表女性)、time為測量次數、age為年齡(歲)。其數據步見圖1-a,使用%HPGLIMMIX宏的程序步見圖1-b,使用GLIMMIX步驟的程序見圖1-c,使用NLMIXED步驟的程序見圖1-d。

圖1 生長曲線數據SAS代碼及日志
由各程序步運行日志圖1-e、圖1-f和圖1-g可知,分析觀測值較少的數據時,%HPGLIMMIX宏的運行時間(1秒)比GLIMMIX(實際時間0.14秒,CPU時間0.10秒)及NLMIXED(實際時間0.51秒,CPU時間0.40秒)長。
圖2分別為采用%HPGLIMMIX宏、GLIMMIX和NLMIXED分析27名兒童相關數據的主要參數估計結果。可見,%HPGLIMMIX宏和GLIMMIX程序得出的模型及參數估計基本一致。
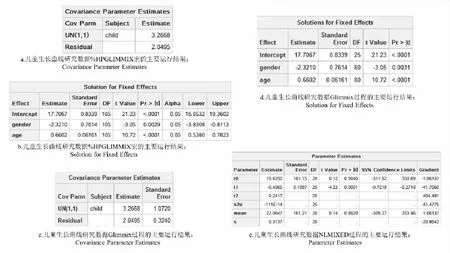
圖2 生長曲線數據的主要結果
2.分類結局變量中%HPGLIMMIX的應用
基于對局部使用乳霜是否有助治愈感染的多中心臨床試驗數據[8],介紹%HPGLIMMIX宏在二項分布結局變量分析中的應用。反應變量Y(治愈率)服從二項分布,X表示事件發生數(治愈),n表示試驗總數。此數據集共包括8個臨床試驗中心,研究對象共273例,其中試驗組130例,對照組143例。
%HPGLIMMIX宏的使用見圖3-a,基于GLIMMIX的程序見圖3-b,基于NLMIXED的程序見圖3-c。此例中,%HPGLIMMIX宏因使用的默認起始值算法不同,需要更多迭代次數來達到收斂。三種方法運行的結果基本相同,在此不再贅述。

圖3 二項分布數據的SAS代碼
上述兩例說明%HPGLIMMIX宏的基本用法,其分析結果與GLIMMIX步驟一致,但在分析小樣本數據時,其節省時間、提高效率的優勢難以體現[3]。
3.大樣本數據中%HPGLIMMIX的應用
為體現%HPGLIMMIX宏在大樣本數據分析時的優勢,采用“中國健康與營養調查(Chinese health and nutrition surveys,CHNS)”1991年~2011年的營養調查數據[10-13]進行實例驗證。該數據屬于大樣本高維縱向數據,故引入隨機效應項并使用混合模型進行分析[14]。在分析成年人的能量攝入變化時,先使用GLIMMIX構建模型,反應變量為日能量攝入量(d3kcal),固定效應包括調查年份(wave)、性別(gender)、城鄉(urban_cat4)、教育程度(edu_cat4)、地區(area)、收入(income)、年齡(age_group6)、民族(nationality_cat2)及婚姻狀況(marry_cat3),個體ID(indiv)作為隨機效應項,鏈接函數為identity;使用LSMEANS對調整后各調查年份的能量攝入進行估計。SAS程序、日志見圖4-a和圖4-b。
由于此數據集樣本量大,導致GLIMMIX過程因數據溢出無法擬合。NLMIXED與GLIMMIX情況類似,均未能擬合模型。下面采用%HPGLIMMIX宏進行模型構建及參數估計,SAS程序見圖4-c。%HPGLIMMIX宏的主要運行結果及能量攝入量的調整值見圖4-d和圖4-e。

圖4 CHNS數據的SAS代碼、日志及結果
通過上述分析可見,%HPGLIMMIX宏可以進行大樣本的模型擬合,解決實際工作中因數據量過大導致內存不夠、模型無法擬合的問題。
討 論
在大樣本高維復雜縱向數據的分析中,%HPGLIMMIX宏解決了SAS自帶的HPMIXED語句無法擬合離散型數據GLMM模型的問題。其參數估計默認采用的雙重迭代線性化法(doubly iterativelinearization method,DILM),可在保證足夠參數估計精度的情況下大量節約內存和運行時間,降低時間成本。既往研究證明在高維復雜數據的分析實踐中,%HPGLIMMIX宏可以節約高達90%的運行時間,特別是在考慮隨機效應時,節省時間的效果更明顯[3]。但需注意的是,盡管在模型參數估計時使用了相同的偽似然算法DILM,%HPGLIMMIX宏和GLIMMIX過程在使用中仍存在一些差異[3]。此外,盡管DILM和MLE(maximum likelihood estimation)在方法學上差別不大,但MLE無法處理大樣本數據,且二者在參數估計上的差別僅在樣本量特別小等極端情況下才會出現[15]。
綜上所述,%HPGLIMMIX宏是一個新的、高效、可靠的廣義線性混合模型建模方法,適合進行大樣本縱向數據的分析,研究者可根據數據的特點合理選用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
核科學與工程(2021年4期)2022-01-12 06:30:26
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
今日農業(2020年19期)2020-12-14 14:16:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
中學物理·高中(2016年12期)2017-04-22 11:53:03
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
