基于Cox-nnet的彌漫性大B細胞淋巴瘤預后預測模型*
2021-03-16 10:19:20鄭楚楚張巖波黃雪倩余紅梅陽楨寰范雙龍趙志強羅艷虹
中國衛生統計 2021年1期
鄭楚楚 張巖波 王 蕾 黃雪倩 余紅梅 陽楨寰 邢 蒙 范雙龍 趙志強 羅艷虹△
【提 要】 目的 基于一種新的神經網絡架構Cox-nnet構建彌漫性大B細胞淋巴瘤的預后預測模型,及早發現高危和低危患者,為進一步的臨床治療提供參考。方法 首先構建兩種常用的低維生存數據的Cox-nnet和Cox模型,驗證Cox-nnet是否適用于低維的生存數據,然后通過單因素Cox回歸和參考相關文獻篩選用于構建彌漫性大B細胞淋巴瘤(diffuse large B-cell lymphoma,DLBCL)模型的協變量,分別構建DLBCL的Cox-nnet和Cox模型。結果 最終選入構建DLBCL預后預測模型的協變量有25個,Cox-nnet的一致性指數(0.724)比Cox(0.685)提升了5.7%。肝硬化數據的Cox-nnet一致性指數(0.818)比Cox(0.804)提升了1.7%,乳腺癌數據的Cox-nnet一致性指數(0.660)比Cox(0.600)提升了10%。結論 Cox-nnet適用于低維的生存數據,基于Cox-nnet構建的彌漫性大B細胞淋巴瘤預后預測模型性能與傳統的Cox回歸相比較有較大提升。
彌漫性大B細胞淋巴瘤(diffuse large B-cell lymphoma,DLBCL)是非霍奇金淋巴瘤(non-hodgkin lymphoma,NHL)中常見的一種侵襲性B細胞淋巴瘤,約占非霍奇金淋巴瘤的30%左右,其可侵及各個年齡段的患者,且臨床表現各異[1-3]。聯合免疫化學療法R-CHOP(利妥昔單抗、環磷酰胺、阿霉素、長春新堿、潑尼松)是目前DLBCL最常用的前期治療方法,約50%~60%的患者被治愈[4]。R-CHOP療法顯著改善DLBCL患者的預后,使其生存率達到60%~90%。但是不同患者對治療的反應各異,對于那些對R-CHOP療法耐藥或者病情緩解后復發的患者來說,預后較差[5-6]。因此對DLBCL患者進行預后分析可以及早發現高危和低危患者,從而進一步為臨床醫生制定DLBCL患者個性化治療方案提供參考。
Cox比例風險回歸模型是預后分析中最常用的模型。但是Cox比例風險回歸模型受線性基線的影響,需滿足等比例風險和協變量之間相互獨立這兩個假設,實際數據往往難以滿足這些假設[7],例如影響疾病預后的因素錯綜復雜,很難滿足這兩個假設。人工神經網絡(artificial neural network,ANN)是一種基于生物神經網絡結構和功能建立的計算模型,具有類似于人腦的信息處理、學習和存儲功能[8]。ANN對數據分布無任何要求,可以處理復雜非線性關系[9],近年來ANN也被廣泛應用于疾病的預后分析中,并表現出了較優的預測性能,但是ANN將生存分析問題簡化為分類問題進行分析預測[10-14],這在一定程度上會導致預測精度的下降。
Travers Ching等人提出了一種新的神經網絡架構Cox-nnet[15],該神經網絡架構沒有將預后分析作為分類處理,而是將神經網絡和Cox回歸相結合,該方法對于高通量組學數據有較高的預測準確度。本研究旨在探討對于低維的生存數據,Cox-nnet的預測性能是否優于Cox回歸,并構建DLBCL患者預后預測模型,從而為臨床醫生預測患者死亡風險并指導臨床治療提供參考。
資料與方法
1.資料獲取
本研究收集了某醫院355例2013-2017年確診為彌漫性大B細胞淋巴瘤患者的臨床隨訪數據,隨訪截止時間為2018年1月,將死亡作為研究終點,刪失比例為67%。我們還分別從Github網站(https://github.com/traversc/cox-nnet/tree/gh-pages/examples/PBC)和R軟件中獲取兩種低維生存數據,分別為:PBC(肝硬化數據)和WPBC(乳腺癌數據),具體數據特征及來源見表1。

表1 兩種低維生存數據的描述
2.方法及原理
(1)單因素Cox回歸篩選變量
根據單因素Cox回歸分析結果并參考B-Cell Lymphomas,Version 3.2019 Featured Updates to the NCCN Guidelines(2019年3月修訂版)及相關文獻[16-24],最終篩選出25個變量用于構建DLBCL患者預后預測模型。具體變量及賦值見表2。本研究中使用SPSS 22.0進行單因素Cox回歸篩選變量,檢驗水準α=0.05。本研究中GCB、CD3、CD5、CD20、CD21、CD10、BCL6、BCL2、MUM1、CMYC、p53是否陽性這些因素有較重要的臨床意義,無論其有無統計學意義均選入模型。
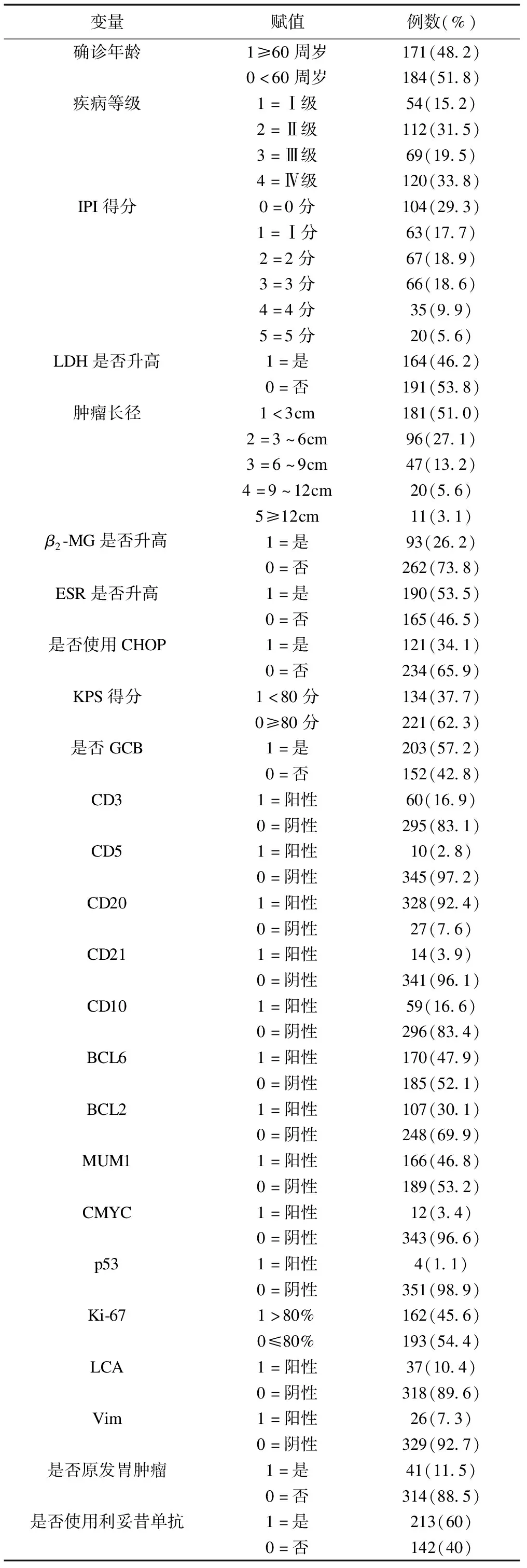
表2 355例DLBCL患者臨床特征及賦值
(2)Cox比例風險回歸
傳統Cox比例風險回歸模型(Cox proportional hazards regression model)是生存分析中使用最廣泛的預測模型,是一種半參數模型,可用于生存時間分布未知且含有刪失數據的資料[25]。具體的模型表達式為:
xi為個體的協變量;h(t|xi)為具有協變量xi的個體在時刻t的風險函數;h0(t)為基準風險函數,即協變量xi全部為0的條件下t時刻的風險函數;β為各協變量所對應的偏回歸系數,解釋了個體的相對風險比。由模型表達式可知Cox比例風險回歸模型假設協變量與風險函數之間是線性組合的關系。本研究使用R軟件中Survival包中的coxph函數擬合Cox回歸模型。
(3)Cox-nnet
Cox-nnet是由Travers Ching等人提出的一種新的人工神經網絡模型。該人工神經網絡模型將人工神經網絡與Cox回歸相結合,包括輸入層、隱藏層、Cox回歸層,Cox回歸層輸出結果為預后指數,具體的Cox-nnet神經網絡結構見圖1。該模型表達式為:

圖1 Cox-nnet神經網絡架構
θi=G(Wxi+b)Tβ
其中xi為隱藏層的輸入,W為輸入層與隱藏層的權重系數矩陣,b為輸入層對于每個隱藏層節點的偏置項,G是tanh激活函數:
Cox-nnet中使用偏似然對數作為損失函數:
Cost(β,W)=pl(β,W)+λ(‖β‖2+‖W‖2)
使用Dropout正則化[26]防止過擬合并使用5折交叉驗證來尋找最優正則化參數,一致性指數作為交叉驗證性能評價指標。本研究使用Python軟件中的Cox-nnet包擬合Cox-nnet模型,具體參數設置為:隱藏層節點數為輸入層特征數的平方根的整數部分;交叉驗證的正則化參數范圍為(-6.5,-0.5);使用Nesterov梯度下降法[27]訓練模型;學習率為0.01;衰減率為0.9;停止閾值為0.995;最大迭代次數1000次。
(4)評價指標
本研究使用一致性指數[28]評價模型的預測準確度。在含有刪失數據的生存分析中,一致性指數是最常用的評價指標,它指的是預測結果與實際結果一致的對子數占有用的對子數的百分比。首先在全部觀察單位中隨機配對產生所有可能的對子數;其次計算有用對子數,去除兩種無用對子數:(1)有較短生存時間的刪失個體(2)兩個個體生存時間相同,但是都為刪失個體;然后計算預測結果與實際結果一致的對子數;最后計算一致性指數,即預測一致的對子數占有用對子數的百分比。一致性指數越大表明預測性能越好。本研究中使用R軟件中的Hmisc包中的rcorr.cens函數計算一致性指數。
(5)構建模型
本研究中將數據集劃分為80%的訓練集和20%的測試集,訓練集分別用于構建Cox-nnet和Cox模型,測試集用于測試這兩個模型的預測準確度,重復采樣并構建模型100次,取中位一致性指數來比較Cox-nnet和Cox模型預測準確性,并使用配對Wilcoxon符號秩檢驗比較兩種模型的一致性指數差異是否具有統計學意義。檢驗水準α=0.05。
結 果
1.單因素Cox篩選變量結果
表3給出了單因素Cox回歸篩選變量的結果,由單因素Cox回歸結果可知,在本研究中DLBCL患者確診年齡、疾病等級、IPI得分、LDH是否升高、腫瘤長徑、β2-MG是否升高、ESR是否升高、KPS得分、是否原發胃腫瘤這些因素對患者生存的影響有統計學意義。
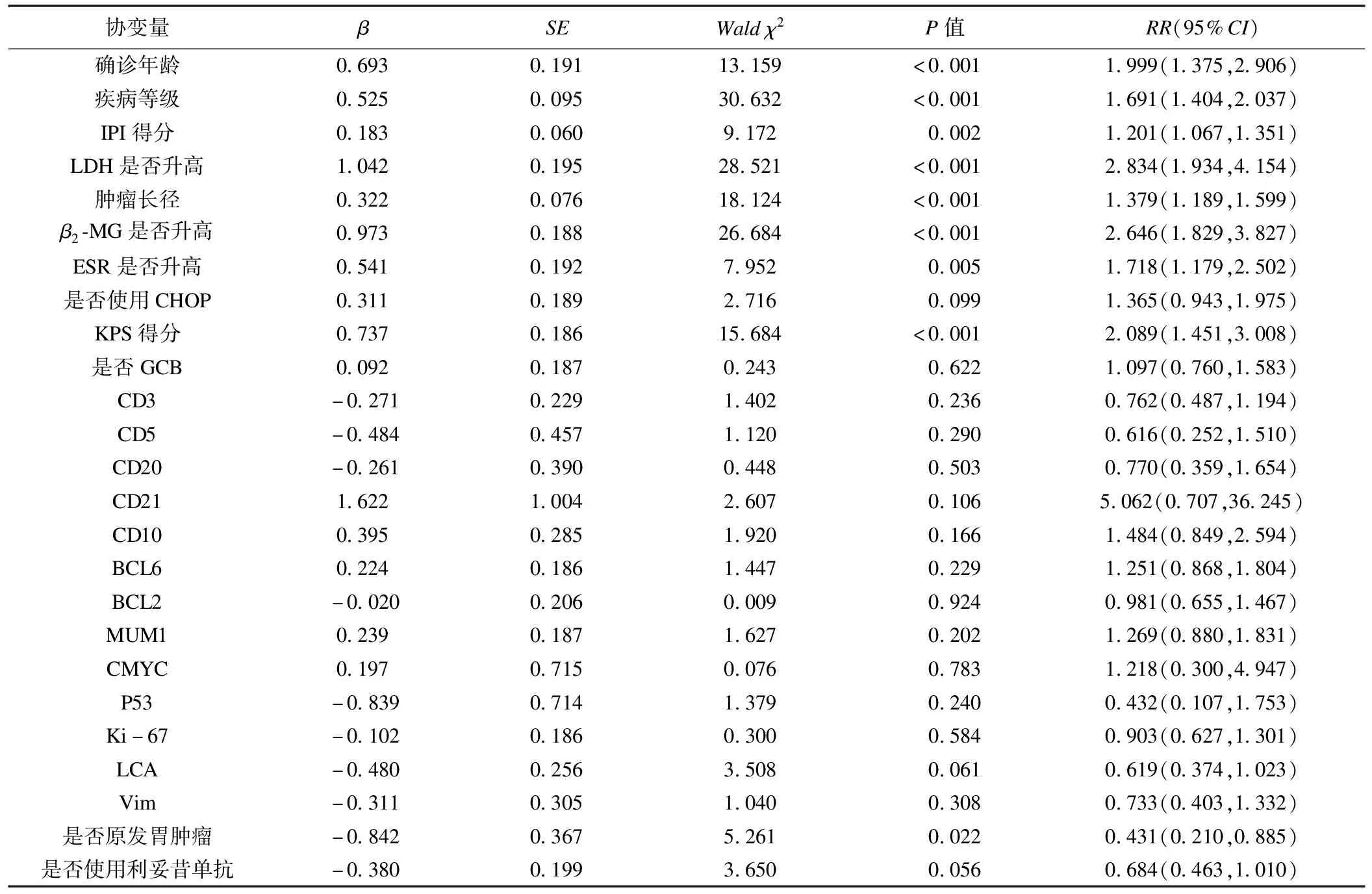
表3 單因素Cox回歸結果
2.Cox-nnet與Cox模型間的比較
由表4可知,DLBCL的Cox-nnet和Cox的一致性指數差異有統計學意義,Cox-nnet比Cox提升了5.7%。表5中顯示,PBC和WPBC的Cox-nnet和Cox的一致性指數差異也均有統計學意義,其中PBC的Cox-nnet一致性指數比Cox提升了1.7%;WPBC的Cox-nnet一致性指數比Cox提升了10%。

表4 DLBCL的Cox-nnet和Cox模型一致性指數
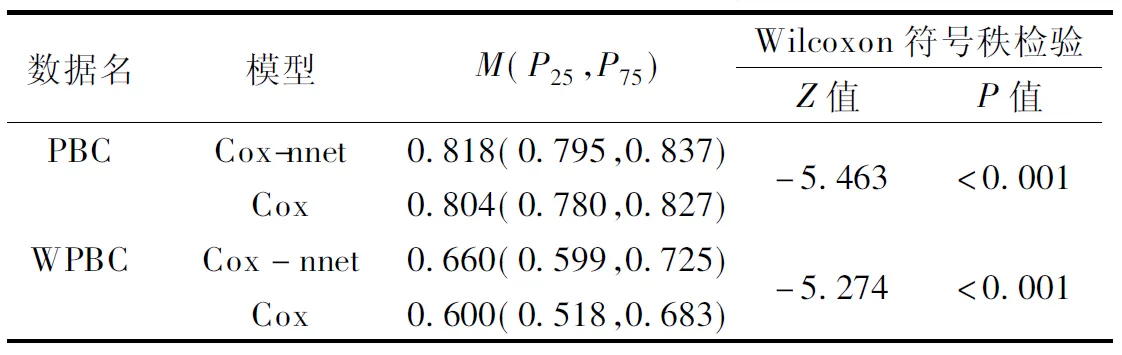
表5 兩種疾病的Cox-nnet和Cox模型一致性指數
討 論
標準的Cox比例風險回歸模型是最常用的生存分析方法,它是一種半參數模型,不需要估計基準風險函數,可用于生存時間分布未知且含有刪失數據的資料。但是Cox回歸受線性基線的影響,假設協變量之間是相互獨立的,且對協變量個數和樣本量之間的比例有一定的要求,這在實際中很難滿足。尤其在大數據時代,我們想利用患者的更多信息去更加精準地預測事件的發生風險,從而為臨床醫生為患者提供精準治療提供參考,這些信息之間往往存在復雜的非線性關系,而ANN可以處理變量之間復雜的非線性關系。近年來,隨著ANN技術的不斷成熟,其也被廣泛應用于生存分析中。黃德生等[29]應用ANN構建了time-coded model和single-time point model,證明ANN可以用于肺癌預后預測,預測性能與Cox無區別。賀憲民[30]等以Cox-snell殘差為ANN輸出訓練網絡,其研究結果表明:在處理非線性資料時,ANN預測性能優于Cox。文獻[10-14,31-34]分別將生存分析問題轉化為分類問題構建ANN用于癌癥的預后預測,并且表現出了較優的預測性能。
本研究應用的新的ANN架構,Cox-nnet沒有將生存分析問題轉換為分類問題,而是將ANN與Cox相結合,既利用了ANN處理非線性的能力,同時也保留了傳統的Cox比例風險回歸方法,Cox-nnet的隱含層還實現了數據降維。該方法最初被應用于高通量的組學數據,表現出了較優的預測性能。本研究分別構建了DLBCL和兩種常用的低維生存數據的Cox-nnet與Cox模型,其中基于WPBC構建的Cox-nnet的一致性指數較Cox提升最多,為10%;其次為DLBCL,Cox-nnet的一致性指數較Cox提升了5.7%;PBC的Cox-nnet一致性指數較Cox提升了1.7%。這表明Cox-nnet適用于低維的生存數據,基于Cox-nnet所構建的DLBCL患者預后預測模型性能優于傳統的Cox回歸。Cox-nnet對生存資料的限制較少,預測性能優于Cox,當所分析資料不滿足Cox假設時,Cox-nnet是一種很好的選擇。
本研究的不足之處在于只探討了兩個常用生存數據,其他類型的生存數據還有待探討;本研究所構建的基于Cox-nnet的DLBCL患者預后預測模型性能雖然優于Cox,但其性能還有待提升。由于生存分析中存在很多刪失數據,這造成了刪失與死亡之間的數據不平衡,數據不平衡在一定程度上影響模型的預測性能[35]。所以本研究下一步將探討生存分析的數據不平衡對模型預測性能的影響,進一步提高模型的預測性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
公民與法治(2022年5期)2022-07-29 00:47:28
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
歷史教學問題(2021年4期)2021-11-05 07:02:34
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國公共安全(2017年11期)2017-02-06 05:28:08
光學精密工程(2016年6期)2016-11-07 09:07:19
燕山大學學報(2015年4期)2015-12-25 02:19:49
